1 引言
在线购物网站积累了大量的商品评论,这有助于消费者了解商品的真实信息,进而购买最符合自己需求的商品;同时,商家可以根据评论中的用户反馈,对商品进行有针对性的改良。然而,商品评论在给消费者和商家带来便利的同时,也带来了额外的负担——需要花费大量的时间和精力阅读并理解评论中隐藏的商品属性以及消费者对该属性表达出的情感倾向。因此,消费者和商家都迫切需要一种自动化或半自动化的方法,可以在粗粒度的商品评论中快速获取细粒度的商品评价。
属性是用户在商品评论中的主要描述对象,通常由商品自身的属性信息构成。例如,在笔记本电脑的评论中,“the good battery life”、“it is of high quality”、“has a killer GUI”分别对“battery life”、“quality”、“GUI”做出积极的评价,“screen all dark”、“power light steady”则分别表达了消费者对“screen”、“power light”消极评价。因此,将属性应用于情感分析,有助于消费者或商家更加细粒度地了解商品的优点或缺点。然而,商品评论往往具有用词随意、语法结构混乱、内容简短等特点,这为属性的准确抽取提出了挑战。
条件随机场(Conditional Random Field, CRF)在属性抽取中取得显著效果,旨在将商品评论数据序列化,对原始文本序列和属性序列的联合概率分布进行建模,学习属性的特征表示,训练出可以识别商品属性的条件随机场模型。但是基于条件随机场的属性抽取方法仍然存在以下问题:
(1)忽略文本中丰富的语义信息[1 ] 。传统的条件随机场只考虑单词最基本的特征,例如词性、前一词、后一词,但是更丰富的单词语义特征有助于对属性进行更精准的抽取。
(2)评论数据内容复杂[2 ] 。条件随机场默认一条商品评论中有且只有一个属性,但是消费者往往对商品的多个属性进行评价,一条评论中只存在一个属性的假设会降低抽取精度。
为解决上述问题,本文提出一种基于依存关系嵌入与条件随机场(Dependency Relationship Embedding-Conditional Random Fields, DepREm-CRF)的商品属性抽取方法。主要贡献包括:
(1)提出一种新的语句级依存关系表现形式——依存关系子句。与已有的单词依存关系获取方法不同,在不破坏商品评论数据句意的前提下,对单词之间重要的共现关系进行突出表示。
(2)提出一种新的基于单词依存关系的词向量生成方法——依存关系嵌入。与已有词向量不同,在本文提出的词向量中,结构和依存关系方面更相近的单词具有更近的向量距离。
(3)提出三种新的单词特征表示方法——基本语义信息、结构语义信息、类别语义信息。与已有单词特征不同,本文设计的三种方法不仅考虑到了单词的一般属性,还量化了单词在文本中的结构属性。
2 相关工作
2.1 属性抽取任务
属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣。Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘。Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性。Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性。Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性。郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取。李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果。张震等[9 ] 通过词项生成概率对文本属性进行抽取。Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性。一些传统的机器学习模型在属性抽取中也有较好的表现。彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布。Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性。Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性。Liu等[14 ] 使用自动学习规则进行属性抽取。周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集。在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性。赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取。Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取。
条件随机场[19 ] 可以解决词性标注、命名实体识别等问题,因此,有学者开始探索基于条件随机场的属性抽取。Xiang等[20 ] 将单词的词干特征和词性特征训练为词向量,将获得的特征输入至条件随机场中学习评论的属性;但是只考虑了单词本身的语义信息,并没有考虑单词在句子中体现出的结构信息。Luo等[1 ] 使用双向依赖网络学习文本的结构特征,并将特征输入至BiLSTM-CRF模型学习评论的序列特征并抽取评论中的属性。Yin等[2 ] 采用RNN提取出具有依赖关系的上下文并进行词嵌入,将其作为条件随机场的输入特征进行属性抽取。以上基于条件随机场的属性抽取方法只能学习到单词的一般特征,无法对单词的多义性、重要性等特殊特征进行量化,因此难以在评论文本中抽取出更多的商品属性。
2.2 依存关系嵌入
评论中的单词往往受到其他单词的影响,单词间的相互制约即为依存关系,例如,“set”和“computer”之间构成宾语关系,“applications”和“good”之间构成形容词修饰关系。同时,词向量解决了文本数值化计算的问题,提供了一个新的研究思路。Le等[21 ] 在Word2Vec的基础上加入段落向量生成Doc2Vec;Dhingra等[22 ] 针对社交网络中的文本提出Tweet2Vec;Moody[23 ] 结合主题模型和词嵌入模型提出LDA2Vec;曾庆田等[24 ] 提出一种对用户行为向量化表示的User2Vec。词嵌入模型已经在相关应用中取得成功,但仍存在过分考虑单词之间的相关性而不是关联性[25 ] 、受到窗口大小的限制[26 ] 、缺乏结构方面的表达能力等问题。这些问题制约了词嵌入模型在商品评论这一类关联性强、单词作用突出、非结构化文本中的有效应用。
针对上述问题,Levy等[27 ] 基于依存关系设计依存单词,获得具有结构性的词向量,但忽略了依存单词间的依赖关系,生成的词向量具有片面性;Zhao等[28 ] 设计子树嵌入(Subtree Embedding)并对其进行训练,得到包含单词结构关系的词向量,但该方法无法表示单词间复杂的关系,如环状结构等;Li等[29 ] 基于改进的依存关系量化公式,得到依存分值并基于分值训练词向量,但该模型忽略了单词之间的远近关系和紧密程度。
针对目前研究存在的问题,本文设计依存关系子句突出单词之间的关联关系,提出依存关系嵌入,语义接近的单词被映射到相近的向量空间中。同时,将基于依存关系得到的单词特征和词性、词形等特征进行组合,作为条件随机场的学习内容,新加入的特征包含丰富的单词结构语义和语法信息,可以提高条件随机场的属性抽取能力。
3 依存关系嵌入的条件随机场模型
3.1 DepREm-CRF模型总体结构
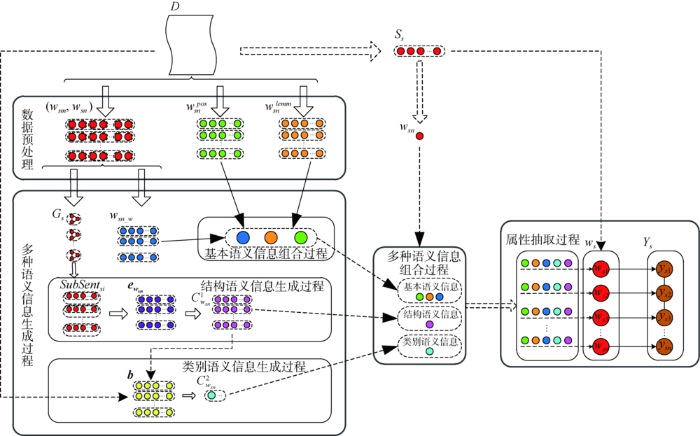
DepREm-CRF模型抽取商品评论中单词之间的依存关系,并基于单词的基本属性构建多种单词语义信息,条件随机场接收上述信息并准确地抽取商品属性。DepREm-CRF模型的总体框架如图1 所示。本文使用的主要符号如表1 所示。
图1
图1
DepREm-CRF模型框架
Fig.1
The Framework of DepREm-CRF
(1)数据预处理:解析评论中单词之间的依存关系、单词本身具有的词性和词形信息。
(2)多种语义信息生成过程:以评论语句 s , s ∈ D D ( w sm , w sn ) w sn _ w ( w sm , w sn ) s G s s SubSen t si SubSen t si w sn e w sn e w sn w sn C w sn 1 C w sn 1 b b C w sn 2 w sn D
(3)多种语义信息组合过程:基于单词的依存关系和先验知识( w sn pos w sn lemm w sn w sn pos w sn lemm w sn _ w C w sn 1 C w sn 2
(4)属性抽取过程:将三类语义信息,即5种单词特征加入到条件随机场的建模过程中,得到可对属性进行抽取的DepREm-CRF模型。
3.2 多种单词语义信息的构建
基于依存关系嵌入和单词属性设计三类单词语义信息表示,如表2 所示。
基本语义信息指单词本身所包含的基本信息,包括词性标注、词形还原和依存关系权重。
最基本的语法属性,表示单词在句子中的作用与角色。以“I love the operating system and the preloaded software.”为例,其词性标注如表3 所示。
抽取出派生、扩展等其他任何形式的单词原形,是对单词在不同表现形态下的统一。充分考虑单词作为一个独立的个体所表达的含义,可以提高条件随机场对单词的理解能力。以“I love the operating system and the preloaded software.”为例,其词形还原如表4 所示。
基于依存关系得到单词的依存关系权重,度量单词在评论文本中的重要程度。受到Zhang等[6 ] 对单词特征期望度和影响度定义的启发,本文设计的依存关系权重计算方法如下。
②获取存在单词 w sn S w sn S w sn A
③以10个单词为长度,对 S w sn dict
⑤对每一个依存关系子集 A i , A i ∈ A w sn A i
W w s i = α ⋅ count ( post ) + β ⋅ count ( neg ) count ( A i )
w sn _ w = W D ⋅ ∑ s i ∈ s ( 1 dict ( S i ) ⋅ w w s i )
其中, count ( S ) count ( D ) S D count ( post ) count ( neg ) A i α β α + β = 1
本文提出的结构语义信息表达了单词的类别信息,同类别的单词具有密切的依存关系和相似的位置信息。单词的结构语义信息生成过程如下:
①生成依存关系图及依存关系路径。获取评论中单词之间的依存关系集 A = { A 1 , A 2 , A 3 , … , A s } A s = { ( w s 1 , w s 2 ) , ( w s 2 , w s 3 ) , … , ( w sm , w sn ) } ( 假设 w s 1 w s 2 w s 2 w s 3 A s s w sm w sn w sn w sm w sm w sn A G s G s G s L s = { pat h s 1 , pat h s 2 , … , pat h sj } pat h sj s j L s
1)删除虚义词。介词、冠词等虚义词并不作任何句子成分,为避免虚义词对词向量的生成造成干扰,将虚义词在 pat h sj
2)计算 pat h sj pat h sj
②生成依存关系子句。经上述策略处理后,依存关系路径集 L s Key _ L s = { Key _ pat h s 1 , Key _ pat h s 2 , … , Key _ pat h sj } Key _ pat h sj Key _ L s S s = { SubSen t s 1 , SubSen t s 2 , … , SubSen t sj }
③生成依存关系词向量。根据依存关系子句集 S s SubSen t sj e w sn e w sn
④依存关系词向量聚类过程。考虑到属性的结构语义类型有限,语义结构相似的单词具有相近的词向量结构,若将 e w sn [30 ] ,对 e w sn q
(1) d = [ ( e 1,1 , e 2,1 ) 2 + ( e 1 , 2 , e 2 , 2 ) 2 + ⋅ ⋅ ⋅ + ( e 1 , q , e 2 , q ) 2 ]
计算两个簇中每个数据点与其他数据点的距离,如公式(2)所示,将所有距离的均值作为两个簇的距离。 R a R b e f e g
(2) d avg ( R a , R b ) = 1 R a R b ∑ e f ∑ e g d ( e f , e g )
⑤生成结构语义信息。在层次聚类过程中,当簇不发生明显变化或达到预设的迭代次数时,聚类停止。此时产生的簇为单词的依存关系词向量类别,即条件随机场输入特征中的结构语义信息。
尽管词性标注可以解决部分单词的一词多义性,但是单词在同一词性中也会表达出不同的含义,例如“苹果”可以指水果或手机品牌,这类歧义词无法靠其本身的属性进行判别。考虑到属性为手机的“苹果”往往与屏幕、性能、摄像等电子产品类词语构成依存关系;属性为水果的“苹果”往往与香蕉、橘子、清洗等食品类词语相互依存,本文基于结构语义信息对单词的歧义性进行分析。
受到One-Hot编码的启发,对单词 w sn b r = { b 1 , b 2 , … , b u } u r b u C w sn 1 b r
3.3 DepREm-CRF模型推导
根据条件随机场[19 ] 的定义对DepREm-CRF模型进行推导,给定评论语句 s w s = [ w s 1 , w s 2 , … , w sn ] s Y s = [ y s 1 , y s 2 , … , y sn ] w s s Y s s y sn s n
本文使用序列标注的常用方法——BIO标注集构造评论语句 s y sn ∈ B , I , O B I O [ O , O , O , B , I , O , O , B , I ] 图2 所示。
图2
图2
某商品评论语句的BIO标注集形式
Fig.2
An Example of BIO
对于条件随机场,属性抽取可以转变为在已知评论语句观测序列 w s = [ w s 1 , w s 2 , … , w sn ] w sn w sn pos w sn lemm w sn _ w C w sn 1 C w sn 2 Y s = [ y s 1 , y s 2 , … , y sn ] w s Y s P ( Y s | w s ) 图2 进行因子分解,将 P ( Y s | w s ) P ( Y | w )
(3) P ( Y | w ) = 1 Z ∏ C ψ C ( Y C | w )
其中, C 图2 中的最大团; Y C C ψ C ( Y C | w ) C k ψ C ( Y C | w ) = e - E ( Y C | w ) Z Z = ∑ Y ∏ C ψ C ( Y C ) y o , o ∈ n P ( Y O | X , y o , … , y n ) = P ( Y O | X , y o - 1 , y o + 1 )
(4) P ( Y | w ) = 1 Z ( x ) ∏ C ψ C ( Y C | w ) = 1 Z ( x ) e ∑ O ∑ k λ k f k ( Y , w o - 1 , o )
其中, f k ( Y , w o - 1 , w o , o ) k λ k k w sn pos w sn lemm w sn _ w C w sn 1 C w sn 2
输入:训练数据集 D train Y train D text
④ 得到单词的词性标注 w sn pos w sn lemm
⑥ 基于依存关系图 G s S s
⑪将 w sn pos w sn lemm w sn _ w C w sn 1 C w sn 2 D train D text
⑫输入 D text Y pre _ text
4 实验及结果分析
以CRFsuite作为条件随机场的训练平台,使用Gensim函数库生成词向量,利用Stanford文本分析工具和自然语言工具包NLTK作为分词、词性标注、词形还原的工具。同时,使用国际语义测评大赛(International Workshop on Semantic Evaluation, SemEval)开放的数据集和Yelp数据集对DepREm-CRF模型进行训练和测试,使用Yelp数据集和Amazon产品数据集作为依存关系嵌入的额外训练语料,最后将DepREm-CRF模型与其他先进的属性抽取方法进行比较。
4.1 实验设置
采用SemEval中的三个小规模数据集和Yelp大型数据集进行实验。SemEval是属性抽取领域比较权威的公开数据集,L-14① (①http://alt.qcri.org/semeval2014/task4/ .)是SemEval在2014年公布的笔记本电脑数据集,R-15② (②http://alt.qcri.org/semeval2015/task12/ .)和R-16③ (③http://alt.qcri.org/semeval2016/task5/ .)分别是SemEval在2015、2016年公布的餐馆评论数据集,Yelp④ (④https://www.yelp.com/dataset .)是美国最大的点评网站Yelp公开的点评数据。为评价DepREm-CRF模型在大规模数据集中的性能,从Yelp的5 996 996条餐馆评论中选取1 000 000条评论进行训练和测试,数据描述如表5 所示。
沿用Xiang等[20 ] 在属性抽取中使用的评价指标——准确率(Precision,P)、召回率(Recall,R)和 F 1 P R F 1
(5) P = ∑ term ∈ D J ( t , pos ( s ) ) ∑ term ∈ D J ( t , pre ( s ) )
(6) R = ∑ term ∈ D J ( t , pos ( s ) ) ∑ term ∈ D J ( t , ture ( s ) )
(7) F 1 = 2 P × R P + R
其中, ture ( s ) pre ( s ) pos ( s ) D t D J ( t , ( A ) ) A 表示属性的集合,如公式(8)所示。
(8) J ( t , ( A ) ) = 1 , if t in ( A ) 0 , if t not in ( A )
4.2 不同语义信息对DepREm-CRF模型的影响
以L-14数据集为例,不同语义信息对DepREm-CRF模型的影响如表6 所示,其中,基本、结构、类别分别表示本文设计的类别语义信息、基本语义信息、结构语义信息;DepREm-CRF为本文提出的方法。
表6 结果表明,与使用传统的单词特征相比,三类语义信息对条件随机场在属性抽取中的表现都有明显提升。具体来说,在使用单类语义信息方面,类别语义信息对实验结果的提升幅度较小,分别提升了2.77%( P ) 、6.77%( R ) 、5.12%( F 1 ) ,这是因为类别语义信息只能利用少数多义性单词的作用,而多义性的词语在评论中所占比重不大;结构语义信息对属性抽取的精度有很大提升,分别提升了3.59%( P ) 、7.06%( R ) 、5.64%( F 1 ) ,这是因为结构语义信息从依存关系的角度考虑单词之间不同的结构信息,结构信息表明单词在评论文本中所处的位置,提高了DepREm-CRF模型对同类单词的特征学习能力,进一步提升了DepREm-CRF模型的预测精度。在使用多种语义信息方面,融合三类语义信息的方法取得了最好的实验效果,分别提升了3.97%( P R ) 、6.84%( F 1 ) ,证明DepREm-CRF模型充分学习了单词本身的属性特征以及单词在评论中表达的位置特征,使得CRF可以基于丰富的单词特征更好地识别出评论中的商品属性。
以L-14数据集为例,使用不同语义信息抽取属性的结果示例如表7 所示。
在高频属性词集中,DepREm-CRF模型与使用单一语义信息的模型具有相似的性能,这是因为高频属性基本为常用词汇,这些词汇在词性、词形、依存关系等方面特点鲜明,条件随机场可以较准确地实现属性抽取。
在低频属性词集中,只使用基本语义信息的模型可以发现一般属性,如battery、Keyboard、configure等;而结构语义信息表达出单词在评论中的位置特征,在BIO标注集的帮助下,模型可以发现更多的属性短语,例如Microsoft Windows、Microsoft Office等;笔记本电脑属性一般为领域专业词,单词多义性现象很少发生,因此类别语义信息抽取出的笔记本电脑属性较少;DepREm-CRF模型结合三类语义信息对单词特征进行度量,不仅可以发现更多有意义的笔记本电脑属性,还能结合BIO标注集发现更多属性短语。
4.3 DepREm-CRF模型与其他模型的比较
为验证DepREm-CRF模型的有效性,与以下4种代表性方法进行比较:
(1)BiLSTM+CRF[1 ] :通过双向神经网络抽取句子中的结构特征,将获取的单词特征输入至条件随机场解决属性抽取问题。
(2)Unsupervised-CRF[2 ] :为叙述方便,将Yin等的工作称为Unsupervised-CRF模型,Unsupervised- CRF使用RNN对单词的语法关系序列进行建模,将得到的单词特征输入至条件随机场中,完成对属性的抽取。
(3)DE-CNN[18 ] :获取通用和专业领域知识,训练得到通用嵌入和领域嵌入两种单词特征,将这些特征输入至CNN网络进行属性抽取。
(4)MFE-CRF[20 ] :基于词性嵌入和词干嵌入设计6种单词特征,将这些特征输入至条件随机场对商品属性进行预测。
本文按照BiLSTM+CRF和MFE-CRF的设计思路对其模型进行复现。同时,BiLSTM+CRF模型[1 ] 、Unsupervised-CRF模型[2 ] 和DE-CNN模型[18 ] 的部分实验结果数据取自其相应的工作。实验结果如表8 所示。
与BiLSTM+CRF、Unsupervised-CRF、DE-CNN和MFE-CRF相比,DepREm-CRF在F1上分别提高3.84%(Yelp)、7.65%(L-14)、1.22%(L-14)、6.28%(L-14),DepREm-CRF模型在属性抽取中表现出了较为出色的性能。具体而言:
(1)与Unsupervised-CRF相比,DepREm-CRF通过函数 f k ( Y , w o - 1 , w o , o )
(2)与MFE-CRF相比,DepREm-CRF不仅考虑单词本身具有的词性和词形特征,还基于单词依存关系对单词的结构特征进行量化。同时,与MFE-CRF使用词性识别单词多义性相比,DepREm-CRF考虑了单词的多义性,因此,DepREm-CRF具有比MFE-CRF更好的属性抽取效果。
(3)与基于深度学习的BiLSTM+CRF或DE-CNN相比,DepREm-CRF使用依存关系权重衡量同一单词在不同语句中的表现和影响,同时,在多种语义信息生成过程中,依存关系紧密的单词拥有更近的单词距离,这也促使DepREm-CRF取得更好的属性抽取精度。
此外,在小规模数据集的对比实验中,DepREm-CRF对餐馆数据(R-15、R-16)的性能提升幅度不如笔记本电脑数据(L-14)。这是因为笔记本电脑中的属性大多为领域专属名词或短语,且这些属性具有相似的位置特征,更容易被DepREm-CRF发现。对于餐馆类评论,由于用户的多样性,相同属性往往具有不同描述,依存关系词向量难以对其进行刻画。在大规模数据集Yelp中,丰富的依存关系使得结构语义信息可以捕捉到更准确的单词特征,同时,数据规模的增大丰富了属性的结构信息,使得依存关系权重可以获得更准确的单词位置特征,因此,DepREm-CRF在Yelp数据集上可以获得更好的性能提升。
4.4 额外语料对DepREm-CRF模型的影响
为探究数据集的类型、规模大小对词向量生成所产生的影响,受Xiang等[20 ] 工作的启发,本文额外添加Yelp数据集和Amazon产品数据集进行词向量训练。Amazon产品数据集① (①http://snap.stanford.edu/data/web-Amazon.html .)包含书籍、电子产品、电影、音乐等不同类型的产品评论信息。在5 996 996条Yelp评论和1 689 188条Amazon电子产品评论中各选择100 000条数据作为额外语料训练依存关系词向量。
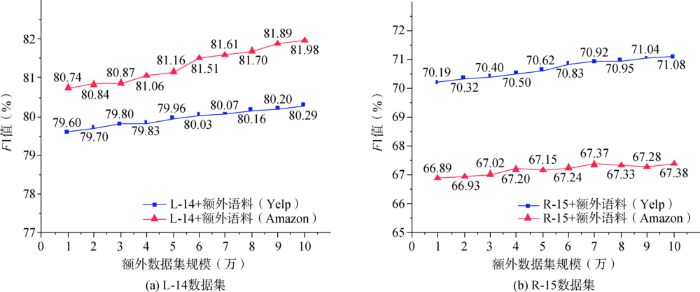
以L-14和R-15数据集为基础,将两种额外语料分别划分为数量均等的10份数据,分析不同类型和规模的数据集对DepREm-CRF模型抽取商品属性能力产生的影响,实验结果如图3 所示。
图3
图3
不同类型、不同规模的额外语料对属性抽取精度的影响
Fig.3
The Accuracy of Term Extraction with Different Typed and Scaled Auxiliary Corpora
由图3 (a)可知,在L-14数据集上,额外语料规模的增大会提升DepREm-CRF模型对商品属性的抽取能力。此外,DepREm-CRF模型在Amazon数据集上的表现整体优于Yelp数据集。从数据内容的角度,L-14数据集和Amazon数据集中的内容都为电子产品类评价,而Yelp数据集中主要是餐馆的评价,数据类型和L-14数据集更相似的Amazon产品数据集比Yelp数据集有更积极的影响。
由图3 (b)可知,在对R-15数据集进行属性抽取时,在两种额外语料的影响下,DepREm-CRF模型都呈现出更强的属性抽取能力。进一步分析,Amazon产品数据集对DepREm-CRF模型的影响能力不如Yelp数据集。分析R-15、Amazon和Yelp三种数据集的数据内容,造成Amazon产品数据集低影响力的原因是Yelp数据集具有和R-15数据集更相似的数据类型。
综上,额外语料有助于提升DepREm-CRF模型对属性的抽取能力。同时,额外语料中的属性与目标数据集中的属性越相似,其对属性抽取的精度影响越大。此外,DepREm-CRF模型的实验结果还能有效判定额外语料与目标数据集内容的相关度。综上,本文提出的模型能够学习到额外语料中的属性,并将这些属性应用到目标数据集中,从而提升属性的抽取精度。
5 结语
本文提出一种面向商品评论属性抽取的依存关系嵌入的条件随机场模型(DepREm-CRF)。首先抽取商品评论中单词之间的依存关系,然后基于依存关系词向量的聚类结果,设计类别语义信息解决单词存在的一词多义性问题、设计结构语义信息解决单词不能充分表示文本结构信息的问题。将两类语义信息与基本语义信息进行组合,使用条件随机场对三类单词特征进行建模,抽取评论中的商品属性。实验结果表明,本文模型在商品属性的自动抽取过程中具有较好的性能。不足之处在于没有很好地考虑情感词对属性的影响,未来将对属性的情感极性进行研究。
作者贡献声明
李成梁:设计研究方案,采集、清洗和分析数据,进行实验,撰写论文初稿;
赵中英:确定研究题目,提出研究思路,讨论与分析实验结果,修改论文;
支撑数据
支撑数据由作者自存储,E-mail: licl0101@qq.com。
[1] 李成梁. ABSA14_Laptops_Train.xml.L-14实验数据集.
[2] 李成梁.ABSA15_Restaurants_Train.xml. R-15实验数据集.
[3] 李成梁.ABSA16_Restaurants_Train.xml. R-16实验数据集.
[4] 李成梁.Yelp_Restaurants.csv. Yelp实验数据集.
参考文献
View Option
[1]
Luo H Li T Liu B , et al . Improving Aspect Term Extraction with Bidirectional Dependency Tree Representation
[J]. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP) , 2019 ,27 (7 ):1201 -1212 .
[本文引用: 4]
[2]
Yin Y Wei F Dong L , et al . Unsupervised Word and Dependency Path Embeddings for Aspect Term Extraction
[C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence. 2016 : 2979 -2985 .
[本文引用: 4]
[3]
Hu M Liu B . Mining and Summarizing Customer Reviews
[C]// Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2004 : 168 -177 .
[本文引用: 1]
[4]
Liu C L Hsaio W H Lee C H , et al . Movie Rating and Review Summarization in Mobile Environment
[J]. IEEE Transactions on Systems Man and Cybernetics Part C:Applications and Reviews , 2012 ,42 (3 ):397 -407 .
[本文引用: 1]
[5]
Ghadery E Movahedi S Faili H , et al . An Unsupervised Approach for Aspect Category Detection Using Soft Cosine Similarity Measure
[OL]. arXivPreprint, arXiv:1812.03361.
[本文引用: 1]
[6]
Zhang J Chen D Lu M . Combining Sentiment Analysis with a Fuzzy Kano Model for Product Aspect Preference Recommendation
[J]. IEEE Access , 2018 ,6 :59163 -59172 .
[本文引用: 2]
[7]
郭博 , 李守光 , 王昊 , 等 . 电商评论综合分析系统的设计与实现——情感分析与观点挖掘的研究与应用
[J]. 数据分析与知识发现 , 2017 ,1 (12 ):1 -9 .
[本文引用: 1]
( Guo Bo Li Shouguang Wang Hao , et al . Examining Product Reviews with Sentiment Analysis and Opinion Mining
[J]. Data Analysis and Knowledge Discovery , 2017 ,1 (12 ):1 -9 .)
[本文引用: 1]
[8]
李伟卿 , 王伟军 . 基于大规模评论数据的产品特征词典构建方法研究
[J]. 数据分析与知识发现 , 2018 ,2 (1 ):41 -50 .
[本文引用: 1]
( Li Weiqing Wang Weijun . Building Product Feature Dictionary with Large-Scale Review Data
[J]. Data Analysis and Knowledge Discovery , 2018 ,2 (1 ):41 -50 .)
[本文引用: 1]
[9]
张震 , 曾金 . 面向用户评论的关键词抽取研究——以美团为例
[J]. 数据分析与知识发现 , 2019 ,3 (3 ):36 -44 .
[本文引用: 1]
( Zhang Zhen Zeng Jin . Extracting Keywords from User Comments: Case Study of Meituan
[J]. Data Analysis and Knowledge Discovery , 2019 ,3 (3 ):36 -44 .)
[本文引用: 1]
[10]
Poria S Cambria E Ku L W , et al . A Rule-Based Approach to Aspect Extraction from Product Reviews
[C]// Proceedings of the 2nd Workshopon Natural Language Processing for Social Media. 2014 : 28 -37 .
[本文引用: 1]
[11]
彭云 , 万常选 , 江腾蛟 , 等 . 基于语义约束LDA的商品特征和情感词抽取
[J]. 软件学报 , 2017 ,28 (3 ):676 -693 .
[本文引用: 1]
( Peng Yun Wan Changxuan Jiang Tengjiao , et al . Extracting Product Aspects and User Opinions Based on Semantic Constrained LDA Model
[J]. Journal of Software , 2017 ,28 (3 ):676 -693 .)
[本文引用: 1]
[12]
Mukherjee A Liu B . Aspect Extraction ThroughSemi-Supervised Modeling
[C]// Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. 2012 ,1 :339 -348 .
[本文引用: 1]
[13]
Li Y Qin Z Xu W , et al . A Holistic Model of Mining Product Aspects and Associated Sentiments from Online Reviews
[J]. Multimedia Tools and Applications , 2015 ,74 (23 ):10177 -10194 .
[本文引用: 1]
[14]
Liu Q Gao Z Liu B , et al . Automated Rule Selection for Aspect Extraction in Opinion Mining
[C]// Proceedings of the 24th International Joint Conference on Artificial Intelligence. 2015 : 1291 -1297 .
[本文引用: 1]
[15]
周清清 , 章成志 . 在线用户评论细粒度属性抽取
[J]. 情报学报 , 2017 ,36 (5 ):484 -493 .
[本文引用: 1]
( Zhou Qingqing Zhang Chengzhi . Fine-grained Aspect Extraction from Online Customer Reviews
[J]. Journal of the China Society for Scientific and Technical Information , 2017 ,36 (5 ):484 -493 .)
[本文引用: 1]
[16]
Peng H Ma Y Li Y , et al . Learning Multi-Grained Aspect Target Sequence for Chinese Sentiment Analysis
[J]. Knowledge-Based Systems , 2018 ,148 :167 -176 .
[本文引用: 1]
[17]
赵杨 , 李齐齐 , 陈雨涵 , 等 . 基于在线评论情感分析的海淘APP用户满意度研究
[J]. 数据分析与知识发现 , 2018 ,2 (11 ):19 -27 .
[本文引用: 1]
( Zhao Yang Li Qiqi Chen Yuhan , et al . Examining Consumer Reviews of Overseas Shopping APP with Sentiment Analysis
[J]. Data Analysis and Knowledge Discovery , 2018 ,2 (11 ):19 -27 .)
[本文引用: 1]
[18]
Xu H Liu B Shu L , et al . Double Embeddings and CNN-Based Sequence Labeling for Aspect Extraction
[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. 2018 : 592 -598 .
[本文引用: 3]
[19]
Lafferty J D McCallum A Pereira F C N . Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data
[C]// Proceedings of the 18th International Conference on Machine Learning. Morgan Kaufmann Publishers Inc. , 2001 : 282 -289 .
[本文引用: 2]
[20]
Xiang Y He H Zheng J . Aspect Term Extraction Based on MFE-CRF
[J]. Information , 2018 ,9 (8 ):198 -213 .
[本文引用: 4]
[21]
Le Q Mikolov T . Distributed Representations of Sentences and Documents
[C]// Proceedings of the 31st International Conference on Machine Learning. 2014 : 1188 -1196 .
[本文引用: 1]
[22]
Dhingra B Zhou Z Fitzpatrick D , et al . Tweet2Vec: Character-Based Distributed Representations for Social Media
[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. 2016 : 269 -274 .
[本文引用: 1]
[23]
Moody C E . Mixing DirichletTopic Models and Word Embeddings to Make LDA2Vec
[OL]. arXivPreprint,arXiv:1605.02019.
[本文引用: 1]
[24]
曾庆田 , 戴明弟 , 李超 , 等 . 轨迹数据融合用户表示方法的重要位置发现
[J]. 数据分析与知识发现 , 2019 ,3 (6 ):75 -82 .
[本文引用: 1]
( Zeng Qingtian Dai Mingdi Li Chao , et al . Discovering Important Locations with User Representation and Trace Data
[J]. Data Analysis and Knowledge Discovery , 2019 ,3 (6 ):75 -82 .)
[本文引用: 1]
[25]
MacAvaney S Zeldes A . A Deeper Look into Dependency-Based Word Embeddings
[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Student Research Workshop. 2018 : 40 -45 .
[本文引用: 1]
[26]
Ye Z Zhao H . Syntactic Word Embedding Based on Dependency Syntax and PolysemousAnalysis
[J]. Frontiers of Information Technology & Electronic Engineering , 2018 ,19 (4 ):524 -535 .
[本文引用: 1]
[27]
Levy O Goldberg Y . Dependency-Based Word Embeddings
[C]// Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. 2014 : 302 -308 .
[本文引用: 1]
[28]
Zhao Y Qin B Liu T . Encoding Syntactic Representations with a Neural Network for Sentiment Collocation Extraction
[J]. Science China-Information Sciences , 2017 , 60 (11 ): Article No. 110101.
[本文引用: 1]
[29]
Li C Li J Song Y , et al . Training and Evaluating Improved Dependency-Based Word Embeddings
[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. 2018 : 5836 -5843 .
[本文引用: 1]
[30]
Blei D M Ng A Y Jordan M I . Latent DirichletAllocation
[J]. Journal of Machine Learning Research , 2003 ,3 :993 -1022 .
[本文引用: 1]
Improving Aspect Term Extraction with Bidirectional Dependency Tree Representation
4
2019
... (1)忽略文本中丰富的语义信息[1 ] .传统的条件随机场只考虑单词最基本的特征,例如词性、前一词、后一词,但是更丰富的单词语义特征有助于对属性进行更精准的抽取. ...
... 条件随机场[19 ] 可以解决词性标注、命名实体识别等问题,因此,有学者开始探索基于条件随机场的属性抽取.Xiang等[20 ] 将单词的词干特征和词性特征训练为词向量,将获得的特征输入至条件随机场中学习评论的属性;但是只考虑了单词本身的语义信息,并没有考虑单词在句子中体现出的结构信息.Luo等[1 ] 使用双向依赖网络学习文本的结构特征,并将特征输入至BiLSTM-CRF模型学习评论的序列特征并抽取评论中的属性.Yin等[2 ] 采用RNN提取出具有依赖关系的上下文并进行词嵌入,将其作为条件随机场的输入特征进行属性抽取.以上基于条件随机场的属性抽取方法只能学习到单词的一般特征,无法对单词的多义性、重要性等特殊特征进行量化,因此难以在评论文本中抽取出更多的商品属性. ...
... (1)BiLSTM+CRF[1 ] :通过双向神经网络抽取句子中的结构特征,将获取的单词特征输入至条件随机场解决属性抽取问题. ...
... 本文按照BiLSTM+CRF和MFE-CRF的设计思路对其模型进行复现.同时,BiLSTM+CRF模型[1 ] 、Unsupervised-CRF模型[2 ] 和DE-CNN模型[18 ] 的部分实验结果数据取自其相应的工作.实验结果如表8 所示. ...
Unsupervised Word and Dependency Path Embeddings for Aspect Term Extraction
4
2016
... (2)评论数据内容复杂[2 ] .条件随机场默认一条商品评论中有且只有一个属性,但是消费者往往对商品的多个属性进行评价,一条评论中只存在一个属性的假设会降低抽取精度. ...
... 条件随机场[19 ] 可以解决词性标注、命名实体识别等问题,因此,有学者开始探索基于条件随机场的属性抽取.Xiang等[20 ] 将单词的词干特征和词性特征训练为词向量,将获得的特征输入至条件随机场中学习评论的属性;但是只考虑了单词本身的语义信息,并没有考虑单词在句子中体现出的结构信息.Luo等[1 ] 使用双向依赖网络学习文本的结构特征,并将特征输入至BiLSTM-CRF模型学习评论的序列特征并抽取评论中的属性.Yin等[2 ] 采用RNN提取出具有依赖关系的上下文并进行词嵌入,将其作为条件随机场的输入特征进行属性抽取.以上基于条件随机场的属性抽取方法只能学习到单词的一般特征,无法对单词的多义性、重要性等特殊特征进行量化,因此难以在评论文本中抽取出更多的商品属性. ...
... (2)Unsupervised-CRF[2 ] :为叙述方便,将Yin等的工作称为Unsupervised-CRF模型,Unsupervised- CRF使用RNN对单词的语法关系序列进行建模,将得到的单词特征输入至条件随机场中,完成对属性的抽取. ...
... 本文按照BiLSTM+CRF和MFE-CRF的设计思路对其模型进行复现.同时,BiLSTM+CRF模型[1 ] 、Unsupervised-CRF模型[2 ] 和DE-CNN模型[18 ] 的部分实验结果数据取自其相应的工作.实验结果如表8 所示. ...
Mining and Summarizing Customer Reviews
1
2004
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
Movie Rating and Review Summarization in Mobile Environment
1
2012
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
An Unsupervised Approach for Aspect Category Detection Using Soft Cosine Similarity Measure
1
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
Combining Sentiment Analysis with a Fuzzy Kano Model for Product Aspect Preference Recommendation
2
2018
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
... 基于依存关系得到单词的依存关系权重,度量单词在评论文本中的重要程度.受到Zhang等[6 ] 对单词特征期望度和影响度定义的启发,本文设计的依存关系权重计算方法如下. ...
电商评论综合分析系统的设计与实现——情感分析与观点挖掘的研究与应用
1
2017
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
电商评论综合分析系统的设计与实现——情感分析与观点挖掘的研究与应用
1
2017
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
基于大规模评论数据的产品特征词典构建方法研究
1
2018
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
基于大规模评论数据的产品特征词典构建方法研究
1
2018
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
面向用户评论的关键词抽取研究——以美团为例
1
2019
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
面向用户评论的关键词抽取研究——以美团为例
1
2019
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
A Rule-Based Approach to Aspect Extraction from Product Reviews
1
2014
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
基于语义约束LDA的商品特征和情感词抽取
1
2017
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
基于语义约束LDA的商品特征和情感词抽取
1
2017
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
Aspect Extraction ThroughSemi-Supervised Modeling
1
2012
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
A Holistic Model of Mining Product Aspects and Associated Sentiments from Online Reviews
1
2015
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
Automated Rule Selection for Aspect Extraction in Opinion Mining
1
2015
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
在线用户评论细粒度属性抽取
1
2017
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
在线用户评论细粒度属性抽取
1
2017
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
Learning Multi-Grained Aspect Target Sequence for Chinese Sentiment Analysis
1
2018
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
基于在线评论情感分析的海淘APP用户满意度研究
1
2018
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
基于在线评论情感分析的海淘APP用户满意度研究
1
2018
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
Double Embeddings and CNN-Based Sequence Labeling for Aspect Extraction
3
2018
... 属性抽取是细粒度情感分析中一个新的研究方向,吸引了学术界和工业界诸多学者的研究兴趣.Hu等[3 ] 利用文本中单词之间的共现关系进行属性挖掘.Liu等[4 ] 设计文档-属性共现矩阵,给定候选特征词,基于矩阵和候选特征词的相似度划分属性.Ghadery等[5 ] 使用余弦相似度进行文本聚类,将标准化后的聚类结果作为属性.Zhang等[6 ] 利用单词特征相似度进行单词聚类,依据聚类结果确定属性.郭博等[7 ] 基于依存关系和词袋模型生成词向量,将该向量作为特征进行商品属性的抽取.李伟卿等[8 ] 使用人工标注和先验知识构建商品属性种子库,选取和种子单词相似度较高的候选属性作为属性预测结果.张震等[9 ] 通过词项生成概率对文本属性进行抽取.Poria等[10 ] 将常识、语法树等先验知识和情感词典相结合,从在线评论中抽取属性.一些传统的机器学习模型在属性抽取中也有较好的表现.彭云等[11 ] 根据先验知识获取三种语义关系,基于三种关系改进LDA模型,获取商品属性的概率分布.Mukherjee等[12 ] 设置种子单词,提出SAS和MESAS两种模型以发现用户表达的属性.Li等[13 ] 基于Bootstrapping方法在电子产品评论中抽取属性.Liu等[14 ] 使用自动学习规则进行属性抽取.周清清等[15 ] 构建候选属性词集,通过聚类和噪音过滤得到细粒度的产品属性集.在深度学习方面,Peng等[16 ] 结合LSTM模型学习得到的词向量和已有的文本序列,识别出文本中的属性.赵杨等[17 ] 使用Canopy和K-means进行特征聚类,对海淘APP中的属性进行抽取.Xu等[18 ] 设计通用嵌入和领域嵌入表示单词特征,并将其输入CNN模型进行属性抽取. ...
... (3)DE-CNN[18 ] :获取通用和专业领域知识,训练得到通用嵌入和领域嵌入两种单词特征,将这些特征输入至CNN网络进行属性抽取. ...
... 本文按照BiLSTM+CRF和MFE-CRF的设计思路对其模型进行复现.同时,BiLSTM+CRF模型[1 ] 、Unsupervised-CRF模型[2 ] 和DE-CNN模型[18 ] 的部分实验结果数据取自其相应的工作.实验结果如表8 所示. ...
Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data
2
2001
... 条件随机场[19 ] 可以解决词性标注、命名实体识别等问题,因此,有学者开始探索基于条件随机场的属性抽取.Xiang等[20 ] 将单词的词干特征和词性特征训练为词向量,将获得的特征输入至条件随机场中学习评论的属性;但是只考虑了单词本身的语义信息,并没有考虑单词在句子中体现出的结构信息.Luo等[1 ] 使用双向依赖网络学习文本的结构特征,并将特征输入至BiLSTM-CRF模型学习评论的序列特征并抽取评论中的属性.Yin等[2 ] 采用RNN提取出具有依赖关系的上下文并进行词嵌入,将其作为条件随机场的输入特征进行属性抽取.以上基于条件随机场的属性抽取方法只能学习到单词的一般特征,无法对单词的多义性、重要性等特殊特征进行量化,因此难以在评论文本中抽取出更多的商品属性. ...
... 根据条件随机场[19 ] 的定义对DepREm-CRF模型进行推导,给定评论语句 s w s = [ w s 1 , w s 2 , … , w sn ] s Y s = [ y s 1 , y s 2 , … , y sn ] w s s Y s s y sn s n
Aspect Term Extraction Based on MFE-CRF
4
2018
... 条件随机场[19 ] 可以解决词性标注、命名实体识别等问题,因此,有学者开始探索基于条件随机场的属性抽取.Xiang等[20 ] 将单词的词干特征和词性特征训练为词向量,将获得的特征输入至条件随机场中学习评论的属性;但是只考虑了单词本身的语义信息,并没有考虑单词在句子中体现出的结构信息.Luo等[1 ] 使用双向依赖网络学习文本的结构特征,并将特征输入至BiLSTM-CRF模型学习评论的序列特征并抽取评论中的属性.Yin等[2 ] 采用RNN提取出具有依赖关系的上下文并进行词嵌入,将其作为条件随机场的输入特征进行属性抽取.以上基于条件随机场的属性抽取方法只能学习到单词的一般特征,无法对单词的多义性、重要性等特殊特征进行量化,因此难以在评论文本中抽取出更多的商品属性. ...
... 沿用Xiang等[20 ] 在属性抽取中使用的评价指标——准确率(Precision,P)、召回率(Recall,R)和 F 1 P R F 1
... (4)MFE-CRF[20 ] :基于词性嵌入和词干嵌入设计6种单词特征,将这些特征输入至条件随机场对商品属性进行预测. ...
... 为探究数据集的类型、规模大小对词向量生成所产生的影响,受Xiang等[20 ] 工作的启发,本文额外添加Yelp数据集和Amazon产品数据集进行词向量训练.Amazon产品数据集① (①http://snap.stanford.edu/data/web-Amazon.html .)包含书籍、电子产品、电影、音乐等不同类型的产品评论信息.在5 996 996条Yelp评论和1 689 188条Amazon电子产品评论中各选择100 000条数据作为额外语料训练依存关系词向量. ...
Distributed Representations of Sentences and Documents
1
2014
... 评论中的单词往往受到其他单词的影响,单词间的相互制约即为依存关系,例如,“set”和“computer”之间构成宾语关系,“applications”和“good”之间构成形容词修饰关系.同时,词向量解决了文本数值化计算的问题,提供了一个新的研究思路.Le等[21 ] 在Word2Vec的基础上加入段落向量生成Doc2Vec;Dhingra等[22 ] 针对社交网络中的文本提出Tweet2Vec;Moody[23 ] 结合主题模型和词嵌入模型提出LDA2Vec;曾庆田等[24 ] 提出一种对用户行为向量化表示的User2Vec.词嵌入模型已经在相关应用中取得成功,但仍存在过分考虑单词之间的相关性而不是关联性[25 ] 、受到窗口大小的限制[26 ] 、缺乏结构方面的表达能力等问题.这些问题制约了词嵌入模型在商品评论这一类关联性强、单词作用突出、非结构化文本中的有效应用. ...
Tweet2Vec: Character-Based Distributed Representations for Social Media
1
2016
... 评论中的单词往往受到其他单词的影响,单词间的相互制约即为依存关系,例如,“set”和“computer”之间构成宾语关系,“applications”和“good”之间构成形容词修饰关系.同时,词向量解决了文本数值化计算的问题,提供了一个新的研究思路.Le等[21 ] 在Word2Vec的基础上加入段落向量生成Doc2Vec;Dhingra等[22 ] 针对社交网络中的文本提出Tweet2Vec;Moody[23 ] 结合主题模型和词嵌入模型提出LDA2Vec;曾庆田等[24 ] 提出一种对用户行为向量化表示的User2Vec.词嵌入模型已经在相关应用中取得成功,但仍存在过分考虑单词之间的相关性而不是关联性[25 ] 、受到窗口大小的限制[26 ] 、缺乏结构方面的表达能力等问题.这些问题制约了词嵌入模型在商品评论这一类关联性强、单词作用突出、非结构化文本中的有效应用. ...
Mixing DirichletTopic Models and Word Embeddings to Make LDA2Vec
1
... 评论中的单词往往受到其他单词的影响,单词间的相互制约即为依存关系,例如,“set”和“computer”之间构成宾语关系,“applications”和“good”之间构成形容词修饰关系.同时,词向量解决了文本数值化计算的问题,提供了一个新的研究思路.Le等[21 ] 在Word2Vec的基础上加入段落向量生成Doc2Vec;Dhingra等[22 ] 针对社交网络中的文本提出Tweet2Vec;Moody[23 ] 结合主题模型和词嵌入模型提出LDA2Vec;曾庆田等[24 ] 提出一种对用户行为向量化表示的User2Vec.词嵌入模型已经在相关应用中取得成功,但仍存在过分考虑单词之间的相关性而不是关联性[25 ] 、受到窗口大小的限制[26 ] 、缺乏结构方面的表达能力等问题.这些问题制约了词嵌入模型在商品评论这一类关联性强、单词作用突出、非结构化文本中的有效应用. ...
轨迹数据融合用户表示方法的重要位置发现
1
2019
... 评论中的单词往往受到其他单词的影响,单词间的相互制约即为依存关系,例如,“set”和“computer”之间构成宾语关系,“applications”和“good”之间构成形容词修饰关系.同时,词向量解决了文本数值化计算的问题,提供了一个新的研究思路.Le等[21 ] 在Word2Vec的基础上加入段落向量生成Doc2Vec;Dhingra等[22 ] 针对社交网络中的文本提出Tweet2Vec;Moody[23 ] 结合主题模型和词嵌入模型提出LDA2Vec;曾庆田等[24 ] 提出一种对用户行为向量化表示的User2Vec.词嵌入模型已经在相关应用中取得成功,但仍存在过分考虑单词之间的相关性而不是关联性[25 ] 、受到窗口大小的限制[26 ] 、缺乏结构方面的表达能力等问题.这些问题制约了词嵌入模型在商品评论这一类关联性强、单词作用突出、非结构化文本中的有效应用. ...
轨迹数据融合用户表示方法的重要位置发现
1
2019
... 评论中的单词往往受到其他单词的影响,单词间的相互制约即为依存关系,例如,“set”和“computer”之间构成宾语关系,“applications”和“good”之间构成形容词修饰关系.同时,词向量解决了文本数值化计算的问题,提供了一个新的研究思路.Le等[21 ] 在Word2Vec的基础上加入段落向量生成Doc2Vec;Dhingra等[22 ] 针对社交网络中的文本提出Tweet2Vec;Moody[23 ] 结合主题模型和词嵌入模型提出LDA2Vec;曾庆田等[24 ] 提出一种对用户行为向量化表示的User2Vec.词嵌入模型已经在相关应用中取得成功,但仍存在过分考虑单词之间的相关性而不是关联性[25 ] 、受到窗口大小的限制[26 ] 、缺乏结构方面的表达能力等问题.这些问题制约了词嵌入模型在商品评论这一类关联性强、单词作用突出、非结构化文本中的有效应用. ...
A Deeper Look into Dependency-Based Word Embeddings
1
2018
... 评论中的单词往往受到其他单词的影响,单词间的相互制约即为依存关系,例如,“set”和“computer”之间构成宾语关系,“applications”和“good”之间构成形容词修饰关系.同时,词向量解决了文本数值化计算的问题,提供了一个新的研究思路.Le等[21 ] 在Word2Vec的基础上加入段落向量生成Doc2Vec;Dhingra等[22 ] 针对社交网络中的文本提出Tweet2Vec;Moody[23 ] 结合主题模型和词嵌入模型提出LDA2Vec;曾庆田等[24 ] 提出一种对用户行为向量化表示的User2Vec.词嵌入模型已经在相关应用中取得成功,但仍存在过分考虑单词之间的相关性而不是关联性[25 ] 、受到窗口大小的限制[26 ] 、缺乏结构方面的表达能力等问题.这些问题制约了词嵌入模型在商品评论这一类关联性强、单词作用突出、非结构化文本中的有效应用. ...
Syntactic Word Embedding Based on Dependency Syntax and PolysemousAnalysis
1
2018
... 评论中的单词往往受到其他单词的影响,单词间的相互制约即为依存关系,例如,“set”和“computer”之间构成宾语关系,“applications”和“good”之间构成形容词修饰关系.同时,词向量解决了文本数值化计算的问题,提供了一个新的研究思路.Le等[21 ] 在Word2Vec的基础上加入段落向量生成Doc2Vec;Dhingra等[22 ] 针对社交网络中的文本提出Tweet2Vec;Moody[23 ] 结合主题模型和词嵌入模型提出LDA2Vec;曾庆田等[24 ] 提出一种对用户行为向量化表示的User2Vec.词嵌入模型已经在相关应用中取得成功,但仍存在过分考虑单词之间的相关性而不是关联性[25 ] 、受到窗口大小的限制[26 ] 、缺乏结构方面的表达能力等问题.这些问题制约了词嵌入模型在商品评论这一类关联性强、单词作用突出、非结构化文本中的有效应用. ...
Dependency-Based Word Embeddings
1
2014
... 针对上述问题,Levy等[27 ] 基于依存关系设计依存单词,获得具有结构性的词向量,但忽略了依存单词间的依赖关系,生成的词向量具有片面性;Zhao等[28 ] 设计子树嵌入(Subtree Embedding)并对其进行训练,得到包含单词结构关系的词向量,但该方法无法表示单词间复杂的关系,如环状结构等;Li等[29 ] 基于改进的依存关系量化公式,得到依存分值并基于分值训练词向量,但该模型忽略了单词之间的远近关系和紧密程度. ...
Encoding Syntactic Representations with a Neural Network for Sentiment Collocation Extraction
1
2017
... 针对上述问题,Levy等[27 ] 基于依存关系设计依存单词,获得具有结构性的词向量,但忽略了依存单词间的依赖关系,生成的词向量具有片面性;Zhao等[28 ] 设计子树嵌入(Subtree Embedding)并对其进行训练,得到包含单词结构关系的词向量,但该方法无法表示单词间复杂的关系,如环状结构等;Li等[29 ] 基于改进的依存关系量化公式,得到依存分值并基于分值训练词向量,但该模型忽略了单词之间的远近关系和紧密程度. ...
Training and Evaluating Improved Dependency-Based Word Embeddings
1
2018
... 针对上述问题,Levy等[27 ] 基于依存关系设计依存单词,获得具有结构性的词向量,但忽略了依存单词间的依赖关系,生成的词向量具有片面性;Zhao等[28 ] 设计子树嵌入(Subtree Embedding)并对其进行训练,得到包含单词结构关系的词向量,但该方法无法表示单词间复杂的关系,如环状结构等;Li等[29 ] 基于改进的依存关系量化公式,得到依存分值并基于分值训练词向量,但该模型忽略了单词之间的远近关系和紧密程度. ...
Latent DirichletAllocation
1
2003
... ④依存关系词向量聚类过程.考虑到属性的结构语义类型有限,语义结构相似的单词具有相近的词向量结构,若将 e w sn [30 ] ,对 e w sn q







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}