




1 引言
随着即时通信(MSN、Skype、微信、QQ等)、社交网络(Facebook、Twitter、Flickr、新浪微博等)、网络视频(YouTube、腾讯视频、爱奇艺等)、情报检索等应用的发展普及,人们可随时随地接收和传播互联网数据。通常,这些数据呈现多种模态,包括文本、图像、音频、视频等。由于多模态数据的内容互为补充、交叉关联,传统检索方法难以满足需求。因此,对文本、图像、音频、视频等多模态数据之间进行交叉检索具有重要应用价值。
跨模态检索(Cross-modal Retrieval)[1,2]融合文本、图像、音频、视频等多个模态而成为跨媒体信息检索中的一个研究热点。目前,在跨模态检索过程中,对模态内和模态间的数据进行特征提取和匹配时,尤其对于具有丰富视角和结构特征的图像进行特征提取和匹配时,存在特征信息挖掘不足,多特征之间匹配度低等问题。由于不同模态的数据及模型通常表现为异质性,例如图像和文本数据的特征表达具有本质性的差异,难以直接度量它们之间的相似度,所以跨模态检索面临的主要问题是不同模态的数据在底层特征上存在异构性,即语义鸿沟。子空间学习方法作为跨模态检索的经典方法之一,主要思想是将不同模态的数据映射到一个公共子空间中,使得原来异构的数据映射成为同构的数据,从而可以直接进行比较。然而,传统的子空间学习方法忽略了不同模态之间的语义联系,未能挖掘数据之间的高阶相关性,检索精度不高。因此,深入挖掘多模态数据之间的语义关联和数据的结构信息,寻找高效的子空间映射方法,是提升跨模态检索精度的关键。
2 国内外研究现状
近年来,跨模态检索方法一直是信息检索的研究热点,如图1所示。其关键是将多模态数据特征映射到公共子空间,使不同模态之间的数据可直接进行相似性度量。典型关联分析(Canonical Correlation Analysis,CCA)[3]作为一种经典的子空间学习方法,通过对多模态的数据进行降维与相关性分析,衡量多模态数据之间的相关性。由于CCA采用线性提取方式,只有当数据相对简单、维度较低时检索结果会比较好。为适应更复杂的数据,LDA[4]、KCCA[5]在CCA的基础上做了相应改进,对数据进行非线性处理,能更好挖掘数据的相关性。李广丽等[6]在KCCA的基础上,提出基于改进的核典型相关分析(MKCCA)模型,进一步挖掘图像和文本之间的非线性关系。但是这些方法仅考虑多模态数据之间原始数据结构的相关性,忽略了语义联系,未能进一步克服跨模态数据之间的语义鸿沟,因此检索精度仍然不高。
图1
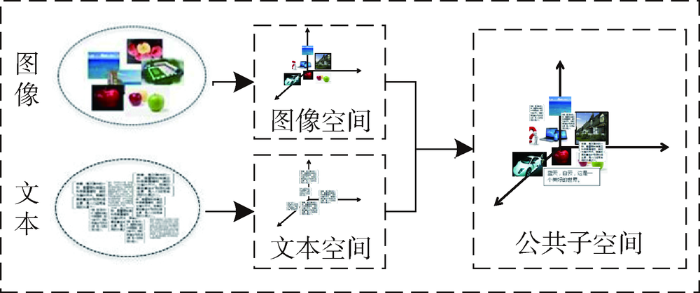
针对CCA等方法的不足,Pereira等[7]在多模态数据间具有相关性的假设基础上,提出相关匹配(Correlation Matching,CM)、语义匹配(Semantic Matching,SM)、语义相关匹配(Semantic Correlations Matching, SCM)的概念及方法,经过实验验证得出,同时考虑多模态数据的低阶底层特征信息和语义信息(SCM)得到的检索结果更好。Zhai等[8]引入语义联合图正则约束,提出异构度量学习(Joint Graph Regularized Heterogeneous Metric Learning, JGRHML)的方法,在文本、图像等5种模态数据之间进行交叉检索。丁恒等[9]采用偏最小二乘方法挖掘异构特征的关联,通过实验验证了偏最小二乘法比CCA方法更能够映射出有效的子空间,取得较好的检索结果。相对CCA等方法,此类方法考虑了多模态数据的语义标注信息,能够获得较为有效的公共子空间映射。由于忽略了公共子空间的结构特征,该类方法在公共子空间映射过程中计算复杂,且映射的公共子空间不能很好反映多模态数据特征关联性,跨模态检索结果仍不够理想。
在JGRHML等方法的基础上,Zhai等[10]结合数据的监督信息和稀疏选择特性,提出基于联合表示的跨模态检索方法,即将多模态数据的结构和语义信息融合在一个模型中进行优化,从而有效挖掘数据的相关性。Wang等[11]提出联合特征选择的子空间跨模态检索方法(Joint Feature Selection and Subspace Learning, JFSSL),该方法考虑了多模态数据结构的稀疏特性。代刚等[12]根据多模态数据的相同标注语义,采用超图约束,提出结合语义相关和拓扑关系的跨媒体检索方法,能有效挖掘多模态数据之间的高阶相关性。Peng等[13]和卓昀侃等[14]采用半监督的训练方法,通过增加训练数据的多样性和可靠性,对5种跨模态数据集进行联合建模,挖掘数据的细粒度信息,从而有效提高语义辨别能力。此外,在考虑语义标注的同时,利用多模态数据稀疏性、距离不变性等结构特征[15,16,17],能有效提升跨模态数据之间的相关性,进而提高检索精度。因此,在高阶语义相关性的基础上,挖掘多模态数据的结构信息,有助于提高跨模态检索效率。
3 基于高阶语义相关的子空间跨模态检索
基于高阶语义相关的子空间跨模态检索方法包括基于高阶语义相关的子空间映射模型和跨模态检索度量两个主要部分。其中基于高阶语义相关的子空间映射模型包括模型构建和模型优化求解两大模块,具体又可以细分为模态原始特征提取、相关语义提取、目标函数构建、子空间映射求解、图像文本公共空间5个部分,模型框架如图2所示。
图2
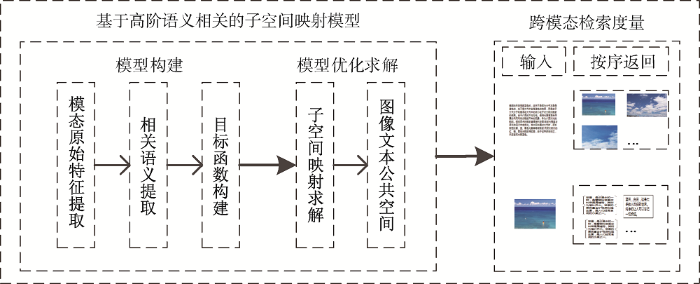
图2
基于高阶语义相关的子空间跨模态检索模型
Fig.2
The Framework of Subspace Cross-modal Retrieval Based on High-order Semantic Correlation
3.1 基于高阶语义相关的子空间映射模型
(1) 模型构建
其中,
其中,
其中,
基于高阶语义相关的子空间映射模型如式(4)所示。
其中,
(2) 模型优化求解
根据定理1对
定理1:假设
其中,
根据定理1,式(4)可以转化为:
其中,
然后,对式(4)中
经过整理可以得到投影矩阵的求解公式,如公式(8)所示。
基于高阶语义相关的子空间跨模态检索的算法流程如下:
输入:有标签的图像和文本标签数据集
输出:投影矩阵
①计算跨模态相关矩阵
②设置
③循环
a:通过公式(6)求解
b:通过公式(8)求解投影矩阵
c:
直到:
通过上述的优化过程分析,首先利用文本和图像的标签数据集求解多模态数据之间的语义相关矩阵
3.2 跨模态检索度量
对于文本和图像两种模态的数据,通过上述过程的求解,分别得到相应的子空间映射矩阵
4 实验
实验中,设置了图像检索文本和文本检索图像两个检索任务以验证本文方法的准确性。并在Wiki、NUS-WIDE、XMedia三个公开数据集上进行验证。通过反复测试,公式(7)中的
4.1 实验数据集
(1)Wiki图像-文本数据集:该数据集包含2 866个图像-文本对[1]。每对数据中,文本数据为描述人物、风景等的一段话,和图像数据相对应。每个图像-文本对对应一个语义标签。标注数据为10类语义,每个图像-文本对属于其中一类。选择其中2 173个样本作为训练集,剩余的693个样本作为测试集。其中图像采用128维的SIFT特征,文本采用10维的潜在狄利克雷分配模型。
(2)NUS-WIDE数据集[22]:每幅图像对应一段相应的文字表述,可以看成和Wiki数据集类似的图像-文本对。图像和文本对均对应81类语义标签,本文选取出现频率较高的21类,每幅图像和文本对应其中的一个或多个标签。数据集中包含72 219个图像-文本对,其中图像特征采用128维的SIFT特征,文本特征采用81维的标注信息。训练集和测试集分别占据数据集的50%。
(3)XMedia跨模态检索数据集[7]:该数据集包含文本、图像、音频、视频和3D模型5种模态数据。选择其中的图像和文本数据作为检索样本。图像和文本各5 000个样本,为配对数据。其中图像特征为4 096维的CNN特征,文本特征为3 000维的BOW特征,标签为20类的单标签数据集。每个图像和文本属于其中的一类。选取5 000个样本中的4 000个作为训练集,剩余1 000个作为测试集。
4.2 评价指标
(2)采用精度-召回曲线描述样本的精度和召回率之间的关系[1]。如果一种算法的精度-召回曲线的线下面积大于另外一种算法,则说明该算法的性能更好。
4.3 结果与分析
与CCA[4]、SCM[7]、JGRHML[8]、JFSSL[11]4种经典的子空间跨模态检索方法进行比较,验证本文方法的有效性。其中CCA属于无监督方法,采用数据低阶低层特征信息构造特征子空间,未考虑数据之间的语义联系。其他三种方法属于有监督的方法,结合原始数据的语义标注信息构造语义共享子空间。SCM和JGRHML方法均考虑了跨模态数据的标注信息,但未对公共映射子空间的结构进行约束,未能对跨模态联合特征选择做出很好处理。JFSSL结合前几种方法的优点,利用图像的标注信息和数据结构约束进行子空间映射,取得了较好的结果。本文在JFSSL的基础上,将跨模态数据的语义信息进行相关性处理,去掉图约束部分,减小了模型图的复杂度和计算难度,取得了较好的检索结果。表1至表3分别为在Wiki、NUS-WIDE、XMedia三种数据集上的检索结果对比。图3至图5分别为不同方法在三种数据集上的精度-召回曲线。
表1 不同方法在Wiki数据集上的MAP值
Table 1
| 检索方法 | 图像检索文本 | 文本检索图像 | 检索平均值 |
|---|---|---|---|
| CCA | 0.254 9 | 0.184 6 | 0.219 8 |
| JGRHML | 0.283 0 | 0.211 9 | 0.247 5 |
| SCM | 0.350 1 | 0.249 6 | 0.299 9 |
| JFSSL | 0.306 3 | 0.227 5 | 0.266 9 |
| OURS | 0.418 4 | 0.403 9 | 0.411 2 |
表2 不同方法在NUS-WIDE数据集上的MAP值
Table 2
| 检索方法 | 图像检索文本 | 文本检索图像 | 检索平均值 |
|---|---|---|---|
| CCA | 0.217 8 | 0.182 4 | 0.200 1 |
| JGRHML | 0.342 5 | 0.286 6 | 0.314 6 |
| SCM | 0.374 6 | 0.290 2 | 0.332 4 |
| JFSSL | 0.403 5 | 0.374 7 | 0.389 1 |
| OURS | 0.497 5 | 0.462 8 | 0.480 1 |
表3 不同方法在XMedia数据集上的MAP值
Table 3
| 检索方法 | 图像检索文本 | 文本检索图像 | 检索平均值 |
|---|---|---|---|
| CCA | 0.122 0 | 0.120 7 | 0.121 4 |
| JGRHML | 0.460 1 | 0.362 9 | 0.411 5 |
| SCM | 0.633 5 | 0.621 0 | 0.627 3 |
| JFSSL | 0.812 6 | 0.776 5 | 0.794 6 |
| OURS | 0.983 9 | 0.975 2 | 0.979 6 |
图3
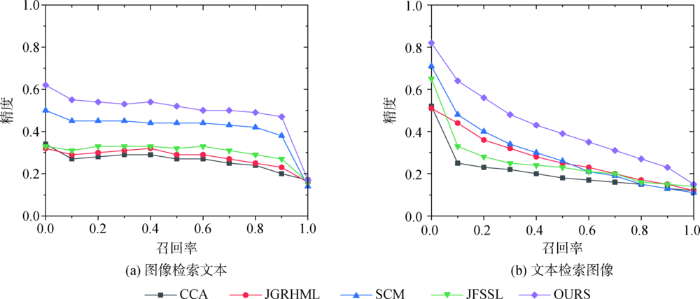
图4
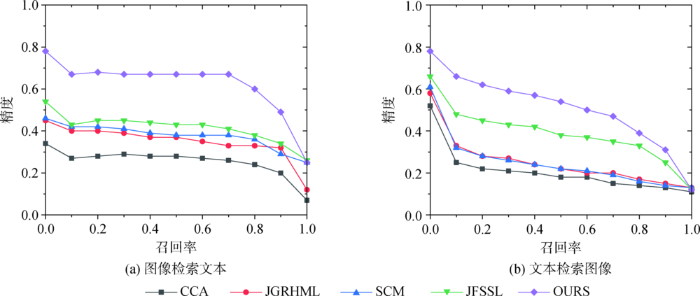
图5
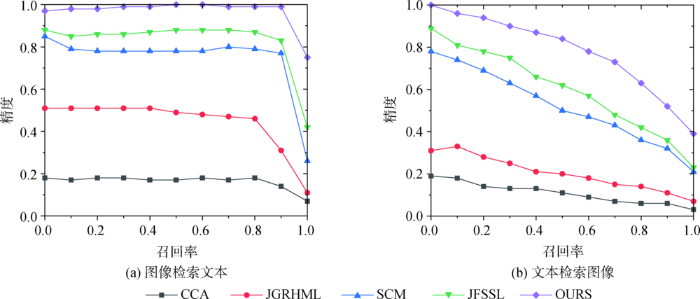
通过上述实验结果对比可以看出本文方法在三个数据集上都取得了较好的结果。在Wiki数据集上的MAP平均值相对于CCA、JGRHML、SCM和JFSSL等方法,分别提高了0.191 4、0.163 7、0.111 3、0.144 3;在NUS-WIDE数据集上分别提高了0.280 0、0.165 5、0.147 7、0.091 0;在XMedia数据集上分别提高了0.858 2、0.568 1、0.352 3、0.185 0。通过对比分析可以发现,仅考虑跨模态低阶底层特征相关性的CCA方法,检索效率较低。跨模态数据之间最大的关联是语义关联,尤其在数据特征差别大,维度差异较明显时检索效率更低。利用数据的语义标注信息进行子空间构造,能够挖掘跨模态数据的高阶相关性,相对CCA而言,SCM、JGRHML、JFSSL等都取得了较好的结果。进一步对比发现,将数据语义标注信息和公共子空间稀疏结构特征结合在一起的JFSSL效果较好。JFSSL在利用语义标注信息时直接采用语义标注的分类信息,在跨模态数据相关性方面仍有提升空间。基于此,本文对跨模态数据的语义标注进行相关性处理,提取高阶语义相关特征,因此在进行子空间映射时投影效果更好,而且模型复杂度更低,跨模态检索精度更高。
5 结语
本文考虑多模态数据的高阶语义相关性而不是原始标注信息,同时引入
本文的不足之处在于基于语义相关的子空间跨模态检索方法对有监督数据效果较好,对于半监督或者无监督数据效果不明显。在接下来的研究中,将聚焦半监督、无监督跨模态数据的检索工作,以弥补本文算法的不足。
作者贡献声明
朱路:提出研究思路,设计研究方案;
田晓梦:进行实验,处理、分析数据;
曹赛男,刘媛媛:论文起草;
朱路,田晓梦:论文最终版本修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储,E-mail: tianxiaomeng2016@126.com。
[1] 朱路, 田晓梦. Wiki.mat. Wiki数据集整理结果.
[2] 朱路, 田晓梦. NUS-WIDE.mat. NUS-WIDE数据集整理结果.
[3] 朱路, 田晓梦. XMedia.mat. XMedia数据集整理结果.
[4] 朱路, 田晓梦. MAP.mat. MAP(平均检索精度)实现结果.
[5] 朱路, 田晓梦. P-R.mat. 精度-召回曲线实现结果.
参考文献
A New Approach to Cross-modal Multimedia Retrieval
[C]//
An Overview of Cross-media Retrieval: Concepts, Methodologies, Benchmarks and Challenges
[J].
Canonical Correlation Analysis: An Overview with Application to Learning Methods
[J].
LDA-Based Document Models for Ad-Hoc Retrieval
[C]//
Facial Expression Recognition Using Kernel Canonical Correlation Analysis (KCCA )
[J].
基于优选典型相关分量的跨媒体检索模型
[J].
Cross-media Retrieval Model Based on Choosing Key Canonical Correlated Vectors
[J].
On the Role of Correlation and Abstraction in Cross-Modal Multimedia Retrieval
[J].DOI:10.1109/TPAMI.2013.142 URL [本文引用: 3]
Heterogeneous Metric Learning with Joint Graph Regularization for Cross-Media Retrieval
[C]//
基于相关性的跨模态信息检索研究
[J].[目的]梳理基于相关性的跨模态信息检索中的基本策略和核心问题,从提升检索效果的角度探讨偏最小二乘法用于特征子空间投影的优劣。[方法]在Wikipedia跨模态信息检索数据集上,分别采用LDA和BOW模型作为文本和图像资源的特征表达方式,以余弦距离作为相似度度量方法,利用最小二乘法替代典型相关性分析法学习特征子空间投影函数。[结果]从P@K、MAP和NDCG三个检索评价指标上,对比分析典型相关性分析、偏最小二乘回归、偏最小二乘相关三种特征子空间投影法对跨模态信息检索结果的影响,结果表明偏最小二乘相关法具有最佳效果。[局限]偏最小二乘法在处理数据时假设数据之间的关系是线性的,数据基向量之间是正交关系,因而无法解决非线性、非正交问题。[结论]使用偏最小二乘相关法学习的特征子空间投影与原始空间信息的一致性更强,跨模态信息检索结果更稳定。
A Study on Correlation-based Cross-Modal Information Retrieval
[J].[目的]梳理基于相关性的跨模态信息检索中的基本策略和核心问题,从提升检索效果的角度探讨偏最小二乘法用于特征子空间投影的优劣。[方法]在Wikipedia跨模态信息检索数据集上,分别采用LDA和BOW模型作为文本和图像资源的特征表达方式,以余弦距离作为相似度度量方法,利用最小二乘法替代典型相关性分析法学习特征子空间投影函数。[结果]从P@K、MAP和NDCG三个检索评价指标上,对比分析典型相关性分析、偏最小二乘回归、偏最小二乘相关三种特征子空间投影法对跨模态信息检索结果的影响,结果表明偏最小二乘相关法具有最佳效果。[局限]偏最小二乘法在处理数据时假设数据之间的关系是线性的,数据基向量之间是正交关系,因而无法解决非线性、非正交问题。[结论]使用偏最小二乘相关法学习的特征子空间投影与原始空间信息的一致性更强,跨模态信息检索结果更稳定。
Learning Cross-Media Joint Representation with Sparse and Semisupervised Regularization
[J].
DOI:10.1109/TCSVT.2013.2276704
URL
[本文引用: 3]

Cross-media retrieval has become a key problem in both research and application, in which users can search results across all of the media types (text, image, audio, video, and 3-D) by submitting a query of any media type. How to measure the content similarity among different media is the key challenge. Existing cross-media retrieval methods usually focus on modeling the pairwise correlation or semantic information separately. In fact, these two kinds of information are complementary to each other and optimizing them simultaneously can further improve the accuracy. In this paper, we propose a novel feature learning algorithm for cross-media data, called joint representation learning (JRL), which is able to explore jointly the correlation and semantic information in a unified optimization framework. JRL integrates the sparse and semisupervised regularization for different media types into one unified optimization problem, while existing feature learning methods generally focus on a single media type. On one hand, JRL learns sparse projection matrix for different media simultaneously, so different media can align with each other, which is robust to the noise. On the other hand, both the labeled data and unlabeled data of different media types are explored. Unlabeled examples of different media types increase the diversity of training data and boost the performance of joint representation learning. Furthermore, JRL can not only reduce the dimension of the original features, but also incorporate the cross-media correlation into the final representation, which further improves the performance of both cross-media retrieval and single-media retrieval. Experiments on two datasets with up to five media types show the effectiveness of our proposed approach, as compared with the state-of-the-art methods.
Joint Feature Selection and Subspace Learning for Cross-modal Retrieval
[J].
基于语义相关性与拓扑关系的跨媒体检索算法
[J].
Cross-media Retrieval Algorithm Based on Semantic Correlation and Topological Relationship
[J].
Semi-Supervised Cross-Media Feature Learning with Unified Patch Graph Regularization
[J].
跨媒体深层细粒度关联学习方法
[J].
Cross-media Deep Fine-grained Correlation Learning
[J].
Discriminative Dictionary Learning with Common Label Alignment for Cross-Modal Retrieval
[J].
Cross-modal Retrieval Using Multi-ordered Discriminative Structured Subspace Learning
[J].
Generalized Semi-supervised and Structured Subspace Learning for Cross-modal Retrieval
[J].
L(2,1) Regularized Correntropy for Robust Feature Selection
[C]//
L2,1-norm Regularized Discriminative Feature Selection for Unsupervised Learning
[C]//
Analysis of Half-Quadratic Minimization Methods for Signal and Image Recovery
[J].
基于余弦相似度的文本空间索引方法研究
[J].
An Approach for Spatial Index for Text Information Based on Cosine Similarity
[J].
NUS-WIDE: A Real-world Web Image Database from National University of Singapore
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}