




1 引言
随着信息技术的发展,知识数量迅速增长,知识库的体量持续增加。在知识逐渐全球化的时代,一个对象可以用多种语言描述,因此,创建跨语言的知识图谱成为促进全球性知识融合的重要手段。在近年的研究中,许多知识图谱,无论是通用的还是面向特定领域的,都在大数据和人工智能领域发挥了很大的作用,并且成为相关领域的宝贵资源,有的图谱被构建并用于分析电商产品数据[1],有的用于研究历史名人的师承关系[2],有的用于构建科技大数据知识发现平台[3]。知识图谱可以在语义知识库的基础上对海量知识进行结构描述,特别是在舆情分析与预警领域,通过在知识库的本体中输入关键词,知识图谱可以灵活有效地实现概念、事件、实体以及关系的查询。
随着新媒体和社交媒体的兴起,人们获得了开放的信息来源平台和情绪释放媒介。这些平台媒介的信息来源广泛,传播速度快[4]。舆情危机随时都有可能在被发现并找到应对措施之前爆发,进而在不同国家和地区之间实现跨语言的传播和演化。因此,构建面向舆情分析与预警领域的跨语言知识图谱是非常必要的。
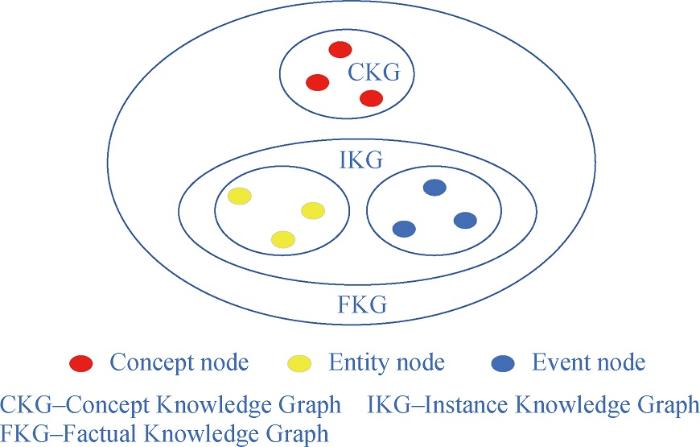
在跨语言舆情分析与预警领域,知识图谱的构建往往基于多种语言、多个数据来源,大致可以分为两类:一类是各大平台上的开源知识图谱,如国外的Freebase[5]、Wikidata[6]、DBpedia[7]和YAGO2[8]等,国内的CN-DBpedia[9]等;另一类是自行收集和统计的舆情关键词句数据库。根据不同的数据源,知识图谱的表示方法可以分为概念(Concept)和实例(Instance)两种类别[10],据此,可将舆情分析与预警领域的知识图谱大致分为两类:概念知识图(Concept Knowledge Graph, CKG)和实例知识图(Instance Knowledge Graph, IKG),如图1所示。CKG包含概念节点和关系,而IKG包含实例节点和关系,其中实例节点由实体节点(Entity node)和事件节点(Event node)组成。事实知识图谱(Factual Knowledge Graph, FKG)既包含概念节点和关系,也涵盖实例节点和关系。
图1
现阶段,构建舆情分析与预警领域的跨语言知识图谱结构有以下难点。
(1)数据源类型少、语种丰富度低,单一语种的历史文化、宗教信仰趋于相似相同,数据源间相互参考对信息帮助有限;
(2)目前国际上舆情分析专家先验知识缺乏,以各大主流网络媒体平台新闻报道为基础构建的文本数据,在缺乏舆情分析专家先验知识的情况下,可能导致跨语言知识融合过程的准确性较低;
(3)单纯采用专家工具集工作量过大,整个系统运行效率低下;
(4)输出单一,使已有知识图谱应用范围狭窄。
为解决上述难点,本文提出一个用于构建舆情分析与预警领域的跨语言知识图谱的架构CLOpin。该架构采用多数据源输入,通过对汉语、英语、德语、葡萄牙语、印尼语、老挝语、越南语等语言近百万条新闻文字材料的处理,引入多语种的结构化、非结构化信息;引入舆情分析专家参与的工具集,以弥补先验知识缺乏带来的融合准确率低的缺陷;同时将机器学习和深度学习方法与专家工具集结合,使整个架构效率更高;融合CKG和IKG的基础上构建跨语言的FKG——CLKG。
2 相关研究
跨语言知识库(如DBpedia、ConceptNet[13]和YAGO)正成为人工智能相关应用的重要知识来源。这些知识图谱在知识存储形式方面可以分为两类:包含以三元组形式记录的实体和关系的单语知识;与不同语言之间的单语知识相匹配的跨语言知识。
值得注意的是,在这些跨语言知识图谱中,非英语的知识很少。例如,在Wikidata中,不同语言的知识分布高度不平衡,其中英语语料体量是汉语的13倍、德语的3.5倍。DBpedia仅包含2%的中文实例、属性和关系。YAGO收集超过12亿的知识三元组,但是其中中文三元组不足5%。与这些英语主导的跨语言知识库相反,百度百科、沪东百科等中文为主的知识库收集超过1 100万篇中文文章[14],但英语知识的存储量很少。
由于大多数开源知识图谱只包含英语概念和实例,很少有汉语、德语、印尼语等非英语的知识,而且各种语言语义组成规则不同,创建跨语言舆情分析与预警概念知识图谱面临着巨大挑战。在一些使用广泛的数据源中,由于非英语知识占比过低,导致现有的跨语言知识图谱相当不完整。跨语言知识库中不同语言知识体量不平衡的状况很常见,这将导致跨语言实体之间的内在联系不完整和缺失。所以,跨语言的知识融合成为构建跨语言舆情分析与预警知识图谱的关键所在。
在跨语言知识图谱研究方面,国内外研究者提出XLore[15]、XLORE2[16]、WikiCiKE[17]、ConceptNet5.5[18]、CLEQS[19]、DBpedia NIF[20]、EventKG[21]、Body-Mind-Language[22]和CrossOIE[23]等架构,这些跨语言知识图谱提供基于分类的方法规范语义规则,并通过概念标注、实体对齐的方法增加跨语言知识链接[24]。9种跨语言知识图谱均未能全面地兼顾数据来源、单词发现与关系挖掘的准确率、系统效率、输出类型等方面的指标,表1对以上架构的部分指标进行对比。与之对应的是,CLOpin架构拥有多数据源的输入,通过引入分析专家工具集可以使CKG、IKG准确性与完整性提高,同时将专家工具集与专业机器学习和深度学习算法相结合,以提升架构的整体效率,且最终输出为CKG和IKG,这将有助于构建跨语言知识图谱CLKG。
表1 多种跨语言知识图谱构架
Table 1
| 架构名称 | 输入数据源 | 是否引入专家工具集与机器学习和深度学习方法相结合 | 输出 |
|---|---|---|---|
| CLOpin | ①从结构化实例转换的RDF数据(英语和非英语) ②非结构数据 ③舆情分析专家先验知识 | 是 | CKG、IKG |
| XLore | 非结构化数据 | 否 | CKG、IKG |
| XLORE2 | 非结构化数据 | 否 | CKG、IKG |
| WikiCiKE | 结构化数据 | 否 | CKG |
| ConceptNet5.5 | 结构化数据、非结构化数据及专家先验知识 | 否 | CKG |
| CLEQS | YAGO2 | 否 | CKG |
| DBpedia NIF | 非结构化数据 | 否 | A corpus |
| EventKG | 结构化数据、非结构化数据 | 否 | CKG |
| Body-Mind-Language | Europarl corpus | 否 | CKG |
| CrossOIE | 结构化数据 | 否 | A classifier |
为填补各语言与英语知识体量之间的巨大差距,以及现阶段各跨语言知识图谱在舆情分析领域的缺失,首先需要丰富非英语语言的概念以及增加跨语言的知识链接,在此基础上将跨语言通用知识图谱的构建方法与舆情分析知识图谱的构建方法结合。除了常用的成熟算法外,本文融入机器学习与深度学习算法以提高效率,并引入舆情分析专家参与的工具集,提高构建舆情分析与预警领域跨语言FKG的效率和准确率。
3 CLOpin架构和数据流
CLOpin架构包括跨语言数据源、数据输出形式、CLOpin工具集和最终用户。数据模型明确了用于构建CKG和IKG的跨语言数据结构,以及概念、实例和关系如何组织以生成知识图谱中的节点和边。
3.1 CLOpin架构
CLOpin架构不仅可以为舆情分析与预警提供大规模的跨语言知识图谱,还可以提供有舆情分析专家参与的工具集,将多个来源的跨语言数据处理成为知识图谱的节点和边。图2展示了CLOpin的总体架构。
图2
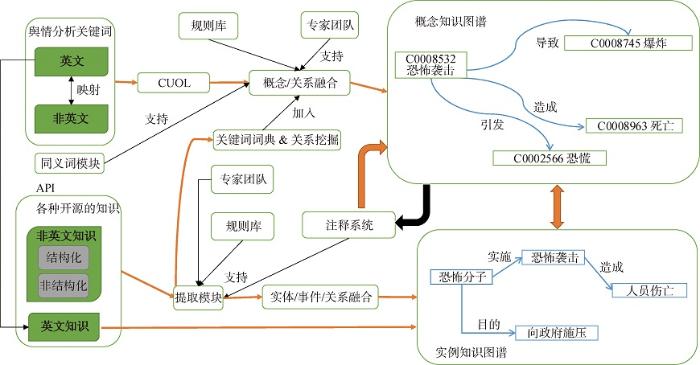
(1) CKG构建
CKG的数据来源是开放的数据库和知识图谱,其中包含英语知识和非英语知识。在CKG构建过程中,将多个数据源转换为跨语言、统一的语义规则知识库CUOL。同时,CLOpin设计了舆情分析专家参与的工具集与机器学习算法来支持CUOL中概念和关系的融合。在专家工具集的帮助下,跨语言、异构数据集的概念和关系将会高效、准确地融合。
(2) IKG构建
IKG的数据来源包括各语种对象国的主流媒体的新闻报道、各语种开放数据集和在对象国社会生活中采集的数据集。在完成实体、事件和关系抽取之后,可以生成实体语料库、事件语料库和关系语料库。采用成熟的机器学习算法实现所抽取数据与舆情分析专家参与的工具集相匹配,以提高融合过程的准确性。
(3) 基于跨语言的FKG——CLKG
CLOpin架构不仅能够将某一事件与其应对策略自动链接在一起,还可以实现将某一事件在不同语言中出现的情况进行对比和分析,再提出相同或不同的应对策略,以便用户更好地了解相关舆情危机及其应对方案。
3.2 数据模型
数据模型用于确定数据的结构,并提供要存储的详细信息。数据模型可以是在特定应用领域中发现的对象和关系的抽象形式化,如舆情分析专家、新闻报道等,也可以指代一组概念、属性[15]。
在CLOpin的数据模型中,节点有三种类型:概念节点、实体节点和事件节点,节点之间的关系可以表示为边。这些节点和边可以有一个或多个属性。概念节点和实体节点的属性包括唯一代码、来源数据库、概念唯一识别码 (Concept Unique Identity, CUI)、文本描述等。事件节点的属性包括唯一代码、开始时间、位置、事件类型、文本描述、说明等。
4 构建CLKG
基于舆情分析专家参与的工具集,CLOpin架构可用于构建大规模、跨语言的舆情分析预警FKG——CLKG。CLKG包含来自多个语言数据源的CKG和IKG。
4.1 数据模型与CKG的构建
CKG的数据源可以分为三种类型:来自各大平台开源数据集的实体关系(Entity Relationship, ER)数据;来自资源描述框架(Resource Description Framework, RDF)知识图谱的数据;舆情分析专家自定义的数据。
(1) CKG的数据源
由于基于ER模型的数据库在表示能力上存在局限性,所以需要将ER数据模型转换为RDF数据模型。在CKG中,选择R2RML这种更灵活的自定义映射方法,它是一种关系数据库到RDF模型的标准转换。CLOpin架构使用舆情分析专家参与的工具集、规则库来支持转换过程。
(2) CUOL构建
在跨语言知识图谱的构建过程中,最大的困难来自不同语言知识总量的不平衡。非英语知识的严重缺乏造成跨语言CKG不完整。为了克服这个缺陷,CLOpin架构建立名为CUOL的跨语言知识库,是基于各大平台上的开源数据的整合,如图3所示。
图3
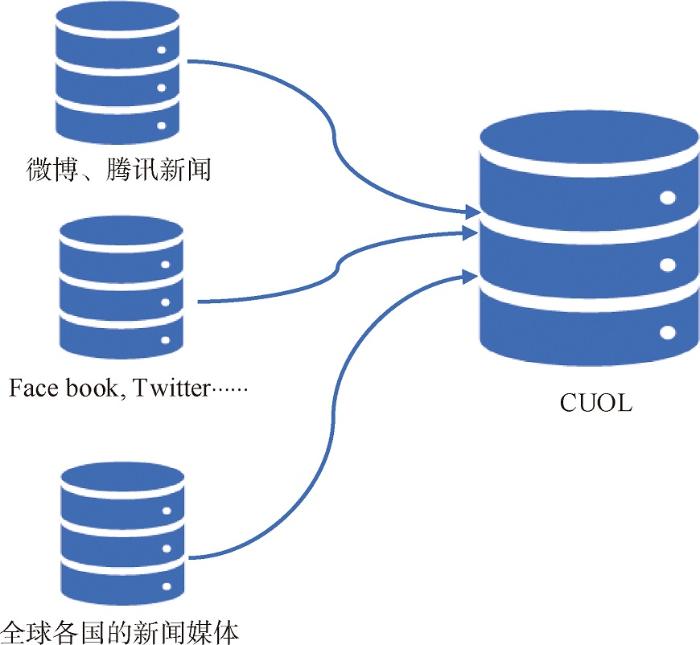
由于这些开源数据中包含大量的概念和关系,CLOpin架构通过独特的识别码CUI将不同语言的同一概念进行映射,同时AUI(Atom Unique Identity)可以表示该概念的源词汇,一个CUI可能对应多个AUI。通过分析开源数据中的词汇特征LUI(Lexical Unique Identity),所有在词库中的字符串都能获得唯一的代码SUI(String Unique Identity)。表2显示了其中一个概念的特性,根据这些特性,CLOpin架构可将字符串的唯一代码映射到其源词汇表,然后获得它的AUI,进而通过AUI映射到CUI。
表2 概念特征
Table 2
| 概念识别码 | 词汇识别码 | 字符串识别码 | 词源识别码 |
|---|---|---|---|
| C0005896 特朗普 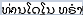 Kẹp Trump Trompete | L0005874 特朗普 Kẹp 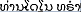 | S0008563 | A0008123 |
| 特朗普(汉藏语系) | 特朗普(汉语) | ||
| S0008548 | A0009306 | ||
| Kẹp(Undetermined) | Kẹp(越南语) | ||
| S0008521 | A0008966 | ||
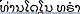 (Undetermined) (Undetermined) |  (老挝语) (老挝语) | ||
| L0005873 Trump Trompete | S0005623 | A0001452 | |
| Trump(印欧语系) | Trump(英语) | ||
| S0004578 | A0007896 | ||
| Trompete(印欧语系) | Trompete(葡萄牙语) |
基于该映射,平台收集了很多从开源数据中抽取出来的舆情分析关键词。通过每个字符串所具有的唯一代码,将特定概念的表达式存储在新增列中。在融合了众多开源知识库的基础上,平台构建异构多源库CUOL,可以存储包含非英语表达的大量节点。
(3) 概念和关系融合
尽管CUOL包含很多非英语概念映射,但是英语和非英语在知识总量上的巨大差距以及不同语言语义规则不一致的问题仍然存在。为了全面构建跨语言CKG,融合多源的概念和关系是必要的。CLOpin架构将舆情分析专家参与的工具集与机器学习算法集成在一起,以支持融合过程。
用于支持此过程的舆情分析专家参与的工具集包含:规则库、专家语料库、同义词模块、注释模块、单词发现和关系挖掘模块。
①概念和关系融合过程的规则库主要关注从ER到RDF的数据转换规则,舆情分析专家可以将ER模型下的数据映射到RDF模型下的概念知识图中的节点。
②在舆情分析专家语料库中,专家定义了没有存储在CUOL中的关于舆情预警最常用的关键词。专家用与CUOL同样的形式添加新概念。表3举例说明专家语料库的融合过程。
表3 融合过程中的专家语料样本
Table 3
| 概念语料 | 中文释义 | 唯一识别码 |
|---|---|---|
| terrorist attack | 恐怖袭击 | C0008532 |
| blast | 爆炸 | C0008745 |
| casualities | 受害者 | C0005241 |
③在同义词模块中,舆情分析专家对同义词进行定义,以避免在融合过程中出现无意义的重复工作。例如,“特朗普”和“川普”在中文里是一对同义词,都对应英语中的同一个概念——Trump(CUI: C0005896)。为了进一步提高效率,融合子系统根据输入词给出候选同义词,专家选择意义最接近的词,然后将该词加入同义词库。
④概念与关系融合中的标注模块着力于发现新的跨语言链接(Cross-lingual Link, CL)。通过学习由舆情分析专家提供的已有数据集中的CL,注释模块在机器学习算法的帮助下提供几个候选CL,然后将权重最高的新CL添加到CKG中。
⑤涉及舆情分析专家的工具集提供单词发现和关系挖掘模块,以便将新闻报道实例中经常出现的概念和关系整合到CKG中。表4是一个新单词发现的例子。
表4 单词发现示例
Table 4
| 输入材料 | 抽取的概念 | 新词 |
|---|---|---|
| 恐怖分子承认了这一行动,受害者人数可能会增加。爆炸对周围的商店造成了巨大的破坏。 | 1.恐怖分子:Concept: [C0005622] terrorist 2.爆炸:Concept: [C0008745] blast 3.受害者:Concept: [C0005241] casualities | 恐怖分子:Concept: [C0005622] Terrorist |
图4
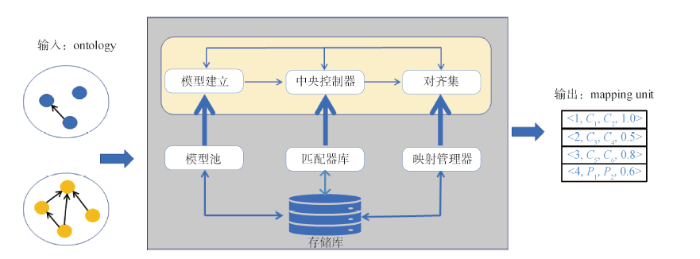
用于实现概念与关系融合的机器学习算法的系统包括6个主要部分。
①模型池:分析器使用Jena将输入本体导入模型。协调器有一组内置协调规则以调整模型。
②匹配器库:管理4种匹配方法,包括V-Doc、I-Sub、GMO和PBM。其中,V-Doc和I-Sub是基于语言的匹配器;GMO是基于图形的匹配器;PBM采用分而治之的策略映射大型实体[26]。
③映射管理器:负责映射规则的生成和评估。
④对齐集:生成XML/RDF格式的匹配文件,并用传统的精确度和召回率对其进行评估。
⑤中央控制器:手动调整参数,在Matcher库中选择要匹配的方法。
⑥存储库:用于存储中间数据。
通过这个子系统,不同来源的跨语言概念和关系可以合并在一起,并分配一个唯一标识CUI,其融合结果如表5所示。
表5 概念融合结果
Table 5
| CUI | String | Source |
|---|---|---|
| C0005896 | 特朗普 | 汉语媒体 |
| Trump | 英语媒体 | |
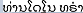 | 老挝语媒体 |
4.2 IKG的构建
实例知识图谱(IKG)包含概念节点、实体节点和事件节点,以及它们之间的关系。IKG的构建流程如图5所示。
图5
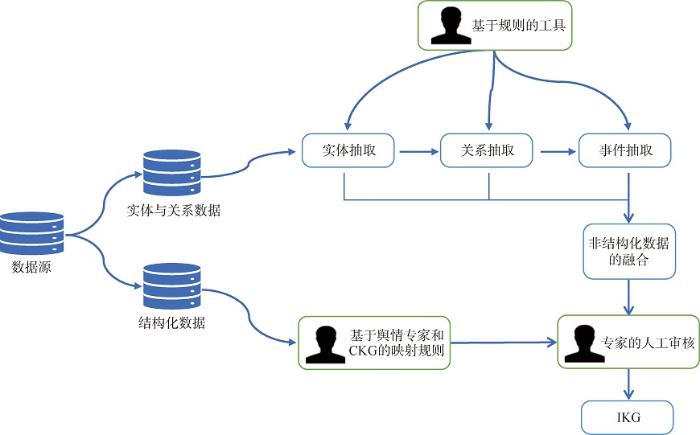
(1) IKG的数据源
构建IKG的过程可以分为结构化数据映射过程和非结构化数据映射过程。对于结构化数据,通过应用规则基础模块支持将ER模型数据转换为RDF模型数据。对于非结构化数据,专门设计抽取模块,让知识融合更加高效。
(2) 抽取模块
IKG构建过程的关键内容包括实体抽取、事件抽取和关系抽取,主要基于已有的规则和人工标注的方式。在处理英语材料时,CLOpin架构使用应用程序接口(API)技术,API允许根据一般规则和用户需求抽取实体和关系。对于非英语材料,使用机器学习技术和该语种舆情分析专家定义的规则库实现准确高效的抽取。
①实体与关系抽取
在跨语言实体和关系抽取过程中,CLOpin架构使用舆情分析专家语料库、规则库和标注模块支持抽取过程。
专家语料库完全基于舆情分析专家的先验知识,规则库根据各类材料的语义模式和用户需求生成抽取规则,这有助于将非结构化的各类材料转换为实体和关系。表6为实体抽取过程中基于语义模式的抽取规则。
表6 实体抽取中的规则库
Table 6
| 模式类型 | 基于模式的抽取规则 |
|---|---|
| 事件发生时间 | 情况出现在**** |
| 事件导致后果 | 本次事件造成**** |
在实体抽取过程中,舆情分析专家参与的标注模块提供基于实体语料库的序列标注。在关系抽取过程中,专家参与的工具集生成基于模式的抽取模型,是基于关系语料库的。在CKG中,实体和关系语料库都是由专家的领域知识、概念和关系支持的。
基于机器学习算法的对齐方法,包括实体标注法LSTM-CRF和CRF[27],以及在关系抽取过程中采用的基于模板的方法和监督学习的方法。在这些方法的帮助下,实例中的实体和关系实现了高精度、高效率的抽取。
②事件抽取
事件抽取是跨语言知识图谱的一个重要组成部分,因为时间线是一种直观的表示方法,可以在特定的一段时间内提供与查询实体相关的事件的概述。将时间线以数字进行表示,可以根据时间线轻松地链接跨语言事件。事件抽取还可以增加知识图的深度。以时间维度为牵引,知识图谱可以更好地显示某一事件连续的发展过程,从而发现实体之间更多的内在联系。由舆情分析专家定义的规则库可以支持事件抽取,如“恐怖袭击在***日爆发”就是一个在事件抽取规则下成功实现抽取的例子。
4.3 实体和关系融合
图6
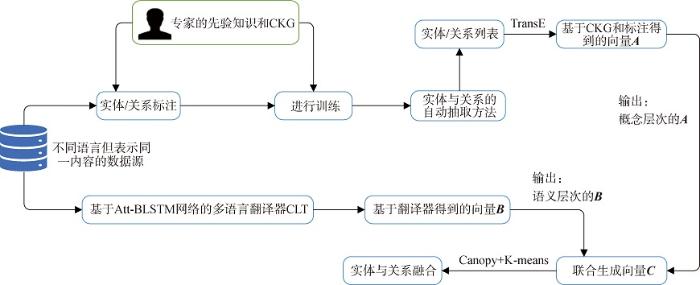
(1) 基于CKG和专家标注的Embedding方法获得向量A
在数据源中准备描述同一事件的、不同语言信息源的文本数据,在舆情专家和CKG参与下对实体和关系进行标注并训练,形成实体与关系的自动抽取方法,进而生成实体/关系列表。然后使用基于TransE的Embedding方法,生成基于CKG和专家标注的向量A。
虽然向量A中包含专家的先验知识以及CKG中的概念层次信息,但信息不够充分,倘若直接将A用于融合比较,准确度可能较低。同时,由于跨语言的人工标注需要大量的舆情专家参与,在标注过程中工作量巨大,所以提出基于自动翻译网络的Embedding方法。
(2) 基于自动翻译网络的Embedding方法获得向量B
利用描述同一事件的不同语言语料文本形成训练集,在基于Att-BLSTM[29]网络的多语言翻译器CLT上,将各种语言翻译成同一种向量,通过CLT可以得到能够与向量A进行融合的向量B。与向量A不同,向量B中包含语义信息和跨语言翻译信息,可以弥补向量A内容的不充分。
(3) 对向量C使用Canopy+K-means方法进行实体与关系融合
上述环节得到包含专家先验知识和CKG中概念层次信息的向量A和包含语义信息和跨语言翻译信息的向量B,然后将二者结合,得到一个含义丰富的向量C。对于C使用Canopy+K-means方法进行实体与关系融合。在全部过程结束之后,经过舆情专家的人工审核,实现IKG的完整构建过程。
在整个融合过程中,CLOpin架构结合Embedding、Att-BLSTM和Canopy+K-means三种方法,形成一套科学、准确、高效的实体与关系融合方法。因此CLOpin架构拥有很好的扩展性,方便适应在未来可能发生变化的各种需求。其中,Canopy+K-means方法的聚类过程如图7所示。
图7

5 实验与分析
为检测基于跨语言知识图谱对来源于不同语种信息源的融合效果,在“华鼎大数据管理平台”上进行实验。该平台是973项目“面向复杂应用环境的数据存储系统理论与技术基础研究”的研究成果,是一个成熟完善的海量网络数据采集、存储和管理的云平台。
实验以汉语、英语、德语、葡萄牙语、印尼语、老挝语、越南语等7种语言作为研究对象,通用语种各选取一个、非通用语种视单个数据源的信息量差异各选取2~3个主流媒体网络平台,使用网络爬虫采集所选平台2018年7月1日至2019年6月30日公开发布的全部信息,共获取实验数据近100万条。
5.1 构建跨语言知识表示方法
CLOpin中节点的文本描述可以用英语或非英语。基于这些跨语言节点,CLOpin中存在两种边,即两个概念节点之间的关系和两个实例节点之间的关系。概念节点之间的关系的属性包括唯一识别码、开始时间、结束时间等;实例节点之间的关系的属性包括唯一识别码、开始时间、结束时间、映射概念的类型等。
节点和边在一起构成知识表示形式的要素,即CLOpin中的三元组。表7是CLOpin中的一个三元组示例。CLOpin中的规则由许多三元组组成,用来描述三元组之间的内部链接。
表7 三元组示例
Table 7
| 关系类型 | 主语 | 关系 | 宾语 |
|---|---|---|---|
| 两个概念之间的关系 | C0008532 (恐怖袭击) | 避开 | C0001235(安检) |
| 两个实例之间的关系 | I0008745 (爆炸发生) | 导致 | I0005241(受害者出现) |
5.2 选取跨语言事件抽取策略
由于新闻采编人员的立场、视角、信息来源等方面的差异,所以即使是同一事件,在不同的新闻源中呈现的事件细节、情感倾向等都可能存在差异。为尽最大可能还原事件的真相,对不同信息源甚至不同语种的同一主题的事件及时发现,是实现对该事件全方位立体式重构的基础。
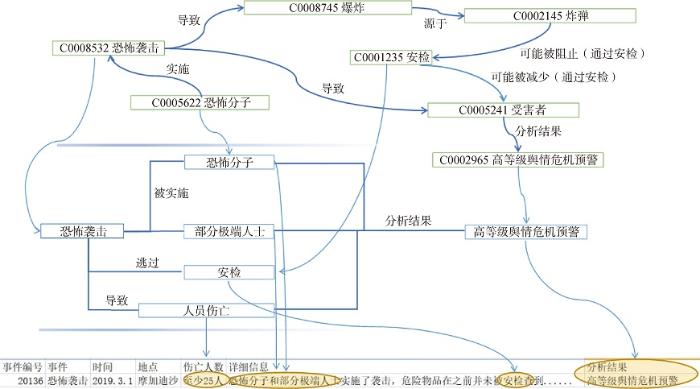
在本框架中,事件抽取采用基于模板的方法和监督学习的方法,抽取的实体和关系将与其唯一的代码保持对齐,从而实现跨语言实体映射。图8是一个抽取结果的样例。
图8
5.3 实现实体、事件和关系的融合
将不同语种、不同新闻源的同一事件的新闻进行融合,既保证了兼听则明,了解事件的真相,又可以及时发现异常的舆论导向,规避负面舆情的发生、发酵和爆发。在实现实体、事件和关系的融合过程中,本框架整合多源实例,包括:从结构化实例转换的RDF数据(包括英语和非英语);从非结构化数据中抽取的知识;舆情分析专家关于舆情分析与预警的先验知识。
为了合并这些数据,首先使用实体和事件节点的特性。由于每个实体和事件节点都具有许多特性,如唯一识别码、时间等,所以可以基于这些特性,链接到自行收集或爬取的数据、开放数据集和社交媒体的跨语言实例。此外,由于这些数据库中的实例数量庞大,所以CLOpin架构采用与概念和关系融合过程相同的机器学习算法系统,这将有助于自动发现更多实例之间的内部链接。详细的融合过程以及自动翻译网络已在4.3节中进行陈述。图9为跨语言实例融合结果。
图9

5.4 对比分析
在任何一个单一语种中,对突发事件的报道都存在“初期信息量有限,随着时间的推移逐步丰满和完善”的过程。考查这一过程可以发现,在单一语种中,由于视角相似、信息来源相近或者相同,所以同一语种中的不同数据源间相互参考对信息量的提升作用有限。由于历史文化、宗教信仰、政治立场等方面的差异,不同语种的新闻报道往往能够从不同侧面对同一事件进行解读,关注点的不同可以给新闻事件呈现更丰满的背景和细节信息。因此,对新闻事件的求真、求实、求全,必须通过跨语言的综合和凝炼才有可能实现。
为探究跨语言信息流动对信息聚合效果的影响,在前文所述的爬取结果集中,选取汉语、英语、德语、印尼语、越南语5个语种主流媒体普遍关注的、突发的十大新闻事件作为研究对象。根据爬虫对相关网站文章的爬取结果,针对影响范围广的相关新闻进行抽取,然后对相同主题的不同语种的文章进行归类,横向对比突发性事件在每个单一语种的新闻中被报道的总次数,统计结果如表8所示。
表8 相同事件在不同语种新闻中的报道情况(单位:次)
Table 8
| 事件编号 | 事件名称 | 发生时间 | 汉语 | 英语 | 德语 | 印尼语 | 越南语 |
|---|---|---|---|---|---|---|---|
| 11468 | 印尼海啸 | 2018/9/30 | 42 | 24 | 9 | 265 | 5 |
| 11793 | 沙特记者被肢解事件 | 2018/10/2 | 21 | 33 | 17 | 1 | 2 |
| 14854 | 法国“黄背心”活动 | 2018/11/17 | 34 | 18 | 30 | 6 | 4 |
| 15298 | 俄罗斯扣押乌克兰军舰事件 | 2018/11/25 | 15 | 42 | 26 | 2 | 5 |
| 17583 | 嫦娥四号月背探测事件 | 2019/1/3 | 213 | 8 | 6 | 4 | 3 |
| 18820 | 美国退出《中导条约》事件 | 2019/2/1 | 8 | 23 | 13 | 8 | 2 |
| 20136 | 索马里首都恐怖袭击事件 | 2019/3/1 | 11 | 18 | 10 | 0 | 3 |
| 21033 | 埃航波音客机坠毁事件 | 2019/3/10 | 78 | 36 | 19 | 5 | 6 |
| 21812 | 新西兰清真寺枪击事件 | 2019/3/15 | 39 | 15 | 11 | 1 | 2 |
| 23515 | 巴黎圣母院火灾事件 | 2019/4/15 | 53 | 27 | 23 | 4 | 3 |
考虑到事件影响的持续性以及新闻关注的延续性,实验选取的事件已发生的时间均在三个月以上,以保证事件当前热度已降低,再次出现相关新闻的可能性极小。同时从表8中可以看出,部分事件在各国受众中的关注程度差异很大,因此新闻刊发的数量也有很大的不同。
为对比跨语言信息流动给信息完整性带来的提升效果,实验测试了不同时间维度下,跨语言新闻源信息融合后的信息量情况,以及单语言不同新闻源之间信息融合后的信息量情况,如表9所示。
表9 不同时间维度下跨语言与单语言信息融合效果对比(单位:个)
Table 9
| 事件编号 | 事件名称 | 信息点数量(1小时) | 信息点数量(24小时) 单语言最大值 | |
|---|---|---|---|---|
| 单语言平均值 | 跨语言复合值 | |||
| 11468 | 印尼海啸 | 26 | 29 | 30 |
| 11793 | 沙特记者被肢解事件 | 18 | 22 | 25 |
| 14854 | 法国“黄背心”活动 | 12 | 15 | 16 |
| 15298 | 俄罗斯扣押乌克兰军舰事件 | 26 | 28 | 29 |
| 17583 | 嫦娥四号月背探测事件 | 68 | 69 | 71 |
| 18820 | 美国退出《中导条约》事件 | 19 | 21 | 21 |
| 20136 | 索马里首都恐怖袭击事件 | 14 | 17 | 18 |
| 21033 | 埃航波音客机坠毁事件 | 37 | 42 | 45 |
| 21812 | 新西兰清真寺枪击事件 | 35 | 39 | 40 |
| 23515 | 巴黎圣母院火灾事件 | 42 | 48 | 51 |
从实验结果可以看出,在单一语种中,由于信息相似度较高,即便将来自同一事件不同新闻源的相关信息进行融合,对信息点数量的提升作用并不明显。而在跨语言知识图谱的帮助下,由于不同信息源的补充,对同一事件所拥有的信息点总量提升显著。从平均效果上来看,在事件发生1小时后,来自同一语种不同网站对该事件报道中所涉及的信息点总数,比来自5个语种的全部新闻报道所涉及的信息点总数低13.9%。说明单一语种的新闻在有效信息量方面,确实有很多不足之处,可以通过跨语言的信息融合进行提升。同时,在事件发生1小时后,来自5个语种的全部新闻报道所涉及的信息点总数,仅比常规方法在24小时后获得的相关事件的信息完整度低5.2%。因此可以看出,基于CLOpin架构进行跨语言数据采集与融合,可以快速、有效地满足受众对事件全面、快速了解的内在需求。
6 结语
本文提出一个端到端架构CLOpin,用来构建面向舆情分析与预警领域的大规模、跨语言的知识图谱,该架构具有4个方面的优势。
(1)可对接不同类型数据源。通过融入从结构化实例转换的多语言的RDF数据、非英语的非结构化数据、舆情分析专家的先验知识等不同语种、不同来源的数据源,可以使新闻事件呈现更加丰满的背景和细节信息。
(2)舆情预警更加及时与精准。由于引入舆情专家工具集,提升了对同一则新闻材料不同语言表述的甄别以及跨语言知识融合的准确性,弥补了舆情分析专家先验知识缺乏的缺陷,使跨语言融合的质量和效率得到提高。
(3)集成领域内的已有成果。将基于机器学习与深度学习的通用方法融入到舆情专家工具集中,减轻了单纯采用专家工具集工作量过大的问题,提升了整个系统的运行效率。
(4)实现多种类型输出。既可输出CKG和IKG,又能基于它们构建CLKG,后者是舆情分析与预警概念知识图和事实知识图的融合。由于CLKG中源数据的完备性,可以提供相似材料的识别服务,来支持不同语言间的舆情分析与预警关键词共享,使得此知识图谱架构面向的应用更加广泛。
本架构的不足之处在于非通用语的领域专家的稀缺制约了架构的应用拓展。在下一步的工作中,将致力于对舆情预警数据库和非通用语舆情分析专家的整合,从而不断开拓CLOpin架构的应用场景。
作者贡献声明
梁野:提出研究思路,设计研究方案,论文最终版本修订;
李小元:分析数据;
许航:采集、清洗数据,进行实验,论文起草;
胡伊然:论文修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据:
支撑数据由作者自存储,E-mail:xuhangbfsu@163.com。
[1] 许航. CLOpin.accdb. CLOpin架构多语新闻数据集.
参考文献
基于电商数据的产品知识图谱构建研究
[J].
Product Knowledge Map Construction Based on the E-commerce Data
[J].
宋代学术师承知识图谱的构建与可视化
[J].
Visualizing Knowledge Graph of Academic Inheritance in Song Dynasty
[J].
科技大数据知识图谱构建模型与方法研究
[J].
Building Knowledge Graph with Sci-Tech Big Data
[J].
网络舆情危机等级评价模型构建及其应用
[J].
Construction and Application of Network Public Opinion Crisis Level Evaluation Model: Taking the Public Opinion of the Incorrupt Government as an Example
[J].
Freebase: A Collaboratively Created Graph Database for Structuring Human Knowledge
[C]//
Getting the Most Out of Wikidata: Semantic Technology Usage in Wikipedia’s Knowledge Graph
[C]//
Tuning Personalized PageRank for Semantics-Aware Recommendations Based on Linked Open Data
[C]//
YAGO2: Exploring and Querying World Knowledge in Time, Space, Context, and Many Languages
[C]//
CN-DBpedia: A Never-Ending Chinese Knowledge Extraction System
[C]//
Differentiating Concepts and Instances for Knowledge Graph Embedding
[C]//
UMLS to DBPedia Link Discovery Through Circular Resolution
[J].
DOI:10.1093/jamia/ocy021
URL
PMID:29648604
[本文引用: 1]

Objective: The goal of this work is to map Unified Medical Language System (UMLS) concepts to DBpedia resources using widely accepted ontology relations from the Simple Knowledge Organization System (skos:exactMatch, skos:closeMatch) and from the Resource Description Framework Schema (rdfs:seeAlso), as a result of which a complete mapping from UMLS (UMLS 2016AA) to DBpedia (DBpedia 2015-10) is made publicly available that includes 221 690 skos:exactMatch, 26 276 skos:closeMatch, and 6 784 322 rdfs:seeAlso mappings. Methods: We propose a method called circular resolution that utilizes a combination of semantic annotators to map UMLS concepts to DBpedia resources. A set of annotators annotate definitions of UMLS concepts returning DBpedia resources while another set performs annotation on DBpedia resource abstracts returning UMLS concepts. Our pipeline aligns these 2 sets of annotations to determine appropriate mappings from UMLS to DBpedia. Results: We evaluate our proposed method using structured data from the Wikidata knowledge base as the ground truth, which consists of 4899 already existing UMLS to DBpedia mappings. Our results show an 83% recall with 77% precision-at-one (P@1) in mapping UMLS concepts to DBpedia resources on this testing set. Conclusions: The proposed circular resolution method is a simple yet effective technique for linking UMLS concepts to DBpedia resources. Experiments using Wikidata-based ground truth reveal a high mapping accuracy. In addition to the complete UMLS mapping downloadable in n-triple format, we provide an online browser and a RESTful service to explore the mappings.
跨语言信息检索的国内外比较研究
[J].文章通过文献计量分析,从发文量、著者、主题分析比较研究了国内外跨语言信息检索的现状和研究热点.在应用现状上,通过搜索引擎和系统的应用,进行了国内外的比较研究.
A Comparative Study of Cross-Language Information Retrieval at Home and Abroad
[J].文章通过文献计量分析,从发文量、著者、主题分析比较研究了国内外跨语言信息检索的现状和研究热点.在应用现状上,通过搜索引擎和系统的应用,进行了国内外的比较研究.
ConceptNet 5.5: An Open Multilingual Graph of General Knowledge
[C]//
Cross-Lingual Entity Query from Large-Scale Knowledge Graphs
[C]//
XLore: A Large-Scale English-Chinese Bilingual Knowledge Graph
[C]//
XLORE2: Large-Scale Cross-Lingual Knowledge Graph Construction and Application
[J].
Transfer Learning Based Cross-lingual Knowledge Extraction for Wikipedia
[C]//
Predicting ConceptNet Path Quality Using Crowdsourced Assessments of Naturalness
[C]//
CLEQS——基于知识图谱构建的跨语言实体查询系统
[J].
CLEQS: A Cross-Lingual Entity Query System Based on Knowledge Graphs
[J].
Using Microtasks to Crowdsource DBpedia Entity Classification: A Study in Workflow Design
[J].DOI:10.3233/SW-170287 URL [本文引用: 1]
EventKG: A Multilingual Event-Centric Temporal Knowledge Graph
[C]//
Body-Mind-Language: Multilingual Knowledge Extraction Based on Embodied Cognition
[C]//
CrossOIE: Cross-Lingual Classifier for Open Information Extraction
[C]//
Boosting Cross-Lingual Knowledge Linking via Concept Annotation
[C]// Proceedings of the 23rd International Joint Conference on Artificial Intelligence.
Human-Computer Interaction and Knowledge Discovery (HCI-KDD): What is the Benefit of Bringing Those Two Fields to Work Together
[C]//
Multilingual Knowledge Graph Embeddings for Cross-lingual Knowledge Alignment
[C]//
Concept Generalization and Fusion for Abstractive Sentence Generation
[J].DOI:10.1016/j.eswa.2016.01.007 URL [本文引用: 1]
A DP Canopy K-Means Algorithm for Privacy Preservation of Hadoop Platform
[C]//
A Multi-Attention-Based Bidirectional Long Short-Term Memory Network for Relation Extraction
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}