




1 引言
学术论文是科研成果的重要载体,是衡量科研工作者学术水平和科研能力的重要体现。发表论文的质量更反映出科研工作者学术成果被认同和接受的程度。如何客观、公正、合理地评判一篇论文的学术影响?当前主流的方法有两种:同行专家评议和引文分析。
(1)同行专家评议是传统的文献评价方法之一,主要指通过领域内专家,以评阅的方式考察论文的内在学术价值,这种方法结论较为准确,但主观性较强,并且由于专家的选择和人数限制,导致得出的结论具有一定的片面性[1];
(2)引文分析一直是文献计量学中的重要研究方法,它主要是依据论文的被引次数、他引次数等统计指标,评判一篇论文学术影响力的高低,具有相对客观和易实现的特点,因此也被广泛采用。但是,引文分析存在一定的缺陷,如常常拘泥于文献的被引频次,将所有被引等同起来,忽略了引用内容中反映的引用动机、引用情感等深层次信息,而这些信息往往更能体现文献的内在价值。
因此,本文从引文内容出发,通过对引文内容中引用情感的细粒度发掘和量化,对文献的内在价值进行深入探讨,并以此提出更科学、合理、有效的文献价值判别方法,为学术检索中重要文献的析出、推荐等提供数据支撑和理论依据。
2 相关研究
2.1 引文内容分析
引文内容信息一般可以分为三类,分别是引用位置、引用频次和引用内容文本[2],其中引用内容文本是指施引文献引用参考文献时所使用的文本内容,通常包含一句话或几句话[3]。关于引用内容的分析研究,早在20世纪70年代,Moravcsik等[4]就通过对引文内容及其上下文中引用情感倾向、引用作用以及重要程度的分析,阐明了基于引文内容的引文分析的必要性。2014年,Ding等[5]提出基于引文内容的分析研究框架,并指出基于引文内容的引文分析可能成为未来引文分析的一个重要发展方向。2014年,祝清松等[6]以碳纳米管纤维研究领域的高被引论文为研究对象,对引文内容进行抽取,并提出引文内容分析可以有效揭示作者的引用动机,是对传统基于被引次数的引文分析方法的重要补充。赵蓉英等[7]也认为引文内容分析是引文分析新的发展方向,对科学计量学的发展大有裨益,并在此基础上,结合引文内容分析方法,提出基于位置的共被引分析框架,证明了结合引文内容分析的共被引分析方法要优于传统共被引分析方法。
2.2 引文情感识别
引用内容中的引用情感表明了施引文献作者对所引用参考文献的情感态度[8]。在引用情感的识别方面,Teufel等[9]提出一种基于监督学习的引用情感自动分类方法,利用情感分析技术对引用情感进行分类(分为正向、中性和负向),并指出利用情感分析技术能准确、有效地识别引用情感。Ikram等[10]将引用情感的提取分为两个层次,首先使用规则方法提取施引文献中的作者观点,再采用分类方法对引用情感进行分类。Yousif等[11]提出一种基于混合神经模型的方法,对引文中蕴含的情感进行分类,取得了很好的效果。Catalini等[12]则着重探寻了负面引用对论文质量评价带来的显著影响。在国内研究中,刘盛博等[13]提出一种基于语义结构与特征词判断引用内容中情感倾向的方法,并以此为基础构建了一个引文评价平台。耿树青等[14]通过对不同类型的引用情感赋予不同的权重来评价论文的学术影响力,实验表明该方法对文献学术影响力的评价更加全面,并且区分能力也更强。
综上所述,关于引文内容的情感分析研究已经受到一定程度的关注,并且一些学者已将其运用到学术评价中,但由于缺乏专业的结构化中文全引文数据库,导致当前研究关注的重点多集中在外文文献。而且,在引文内容的情感分析研究中,多为粗粒度情感分析,未对情感强度进行量化处理,只区分了情感极性。如果能从更细的粒度对引用内容中蕴含的引用情感进行量化,并将其运用到学术评价中,不仅可以提高引文分析的质量,更是对传统单一依靠被引次数进行学术评价的良好补充和辅助。
3 研究思路
本文选取学术检索平台上的学术文献作为数据来源,利用网络爬虫获取相关文献被引信息,建立基于引用情感的学术评价模型,并通过实验检验模型的有效性。具体的研究思路如图1所示,主要包括5个步骤。
图1
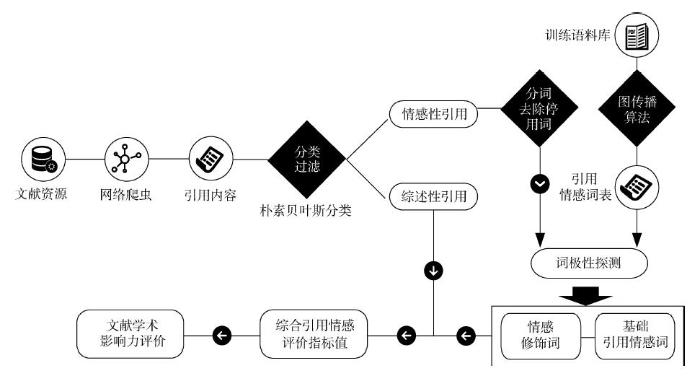
(1)数据准备,获取文献被引数据;
(2)引用内容提取,对同一被引文献的引用文本内容进行上下文提取;
(3)引用分类,通过分类方法将情感性引用和综述性引用分离;
(4)引用情感量化,实现引用内容中组合语义单元的抽取和引用情感的极性量化;
(5)指标计算,根据引用内容中情感元素的量化结果,结合综述性引用的情感量化结果,计算单篇文献的综合引用情感评价值。
4 基于引文细粒度情感量化的评价方法
基于引文细粒度情感量化的评价方法认为,一篇论文的学术影响力会由引用它的论文进行传递,但这种影响力传递会在传播过程中根据引用情感的强弱有所区别。根据引证过程中作者的动机,大致可将引文分为4类:①综述性引用,也称为罗列式引用,作者通过引文列举出当前的研究现状,但并不表达自己的观点;②学术观点的引用,即继承式引用,指作者对该观点持有赞同意见并在论文中进行表述;③学术启发式引用,作者赞同此观点,并且该观点对作者新思想的形成具有启发式意义;④批评性引用,也称为否定性引用,作者引用文献的目的是批评和否定,继而提出自己的观点[15]。以上4类引用中,除综述性引用外,其他三类引用无论赞同还是批评,都掺杂作者的个人情感,因此文中统一将其归纳为情感性引用。
表1 情感性引用识别结果
Table 1
| 实验序号 | 准确率 | 召回率 | F1 |
|---|---|---|---|
| 1 | 93.10% | 84.38% | 88.53% |
| 2 | 87.10% | 90.00% | 88.53% |
| 3 | 86.20% | 89.29% | 87.72% |
| 4 | 90.90% | 85.71% | 88.23% |
| 5 | 84.85% | 87.50% | 86.15% |
| 平均 | 88.43% | 87.38% | 87.73% |
综述性引用不包含作者的主观情感,但引证行为本身表明了该研究的价值,因此赋予其基础学术影响力值。在情感性引用中,其学术影响力由引文内容中包含的各个组合语义单元的情感量化结果综合决定。
具体的引用情感评价值计算方法如公式(1)所示。
其中,
4.1 综述性引用中的情感量化
引用文本内容需要预先进行文字预处理,包括切分句子、分词以及去除停用词等。在后续实验中整理的351篇施引文献中共采集到416句引用上下文,其中综述性引用和情感性引用的分类结果如表2所示。
表2 引用情感分类结果
Table 2
| 引用情感 | 数量 | 占比 |
|---|---|---|
| 综述性引用 | 283 | 68.03% |
| 情感性引用 | 133 | 31.97% |
| 总计 | 416 | 100.00% |
可以发现,虽然科技文献中大部分的引用为综述性引用,但情感性引用的占比达到30%左右,说明情感性引用在引用中占有相当重要的地位,尽管因研究领域和学科的差异,这个占比会有所波动。
在引文细粒度情感量化评价中,考虑到综述性引用虽然不表达作者的主观观点,但也体现了文献的内在价值,所以综合考虑,赋予综述性引用基础学术影响力值B。
4.2 情感性引用中组合语义单元的情感量化
在引用文本中,作者常会在一个句子中就多个引用主题表达出不同的情感态度,例如“这种方法通用性较好,但实验过程较为复杂。”同一引用句中却传达出褒贬不同的两种态度。这使得粗颗粒度即句子级情感分析中,难以对具体的情感倾向进行判断,所以本文将从更细的颗粒度,也就是针对引用中具体的评价特征(如方法通用性、实验过程等),对作者表达的引用情感进行量化分析。
其中,
①否定词+情感词,如“不理想”。引用情感强度通过基础情感词的情感量化值与否定词修正系数相乘得到。
②程度副词+情感词,如“较为理想”。引用情感强度通过基础情感词的情感量化值与程度副词修正系数相乘得到。
③否定词+程度副词+情感词,或程度副词+否定词+情感词,如“不是很理想”和“很不理想”。在这类语义组配单元中,否定词和程度副词的位置排序不同,导致表达的情感强度存在差异,所以需要根据具体情况,重新设定否定词的修正系数。
(1) 基础引用情感词的情感量化
将训练文本集中的所有词构建一个共现矩阵,如表3所示。
表3 词共现矩阵
Table 3
| 召回率 | 降低 | 准确率 | 高 | 差 | 大大提高 | |
|---|---|---|---|---|---|---|
| 召回率 | 0 | 2 | 0 | 0 | 2 | 0 |
| 降低 | 2 | 0 | 0 | 0 | 1 | 0 |
| 准确率 | 0 | 0 | 0 | 2 | 0 | 2 |
| 高 | 0 | 0 | 2 | 0 | 0 | 1 |
| 差 | 2 | 1 | 0 | 0 | 0 | 0 |
| 大大提高 | 0 | 0 | 2 | 1 | 0 | 0 |
根据词共现矩阵,将矩阵中的每行(或列)作为该词的特征属性,构建词向量空间模型,利用余弦相似度计算方法,计算每两个词之间的语义相似度,并将得到的计算结果应于在后续算法中表示两个词之间的图距离,每个词与它本身之间的距离为1。样例中每两个词之间的余弦相似度距离矩阵如表4所示(精确到小数点后两位)。
表4 词相似度距离矩阵
Table 4
| 召回率 | 降低 | 准确率 | 高 | 差 | 大大提高 | |
|---|---|---|---|---|---|---|
| 召回率 | 1.00 | 0.32 | 0.00 | 0.00 | 0.32 | 0.00 |
| 降低 | 0.32 | 1.00 | 0.00 | 0.00 | 0.80 | 0.00 |
| 准确率 | 0.00 | 0.00 | 1.00 | 0.32 | 0.00 | 0.32 |
| 高 | 0.00 | 0.00 | 0.32 | 1.00 | 0.00 | 0.80 |
| 差 | 0.32 | 0.80 | 0.00 | 0.00 | 1.00 | 0.00 |
| 大大提高 | 0.00 | 0.00 | 0.32 | 0.80 | 0.00 | 1.00 |
情感词表自动构建时,需分别向正向种子词集和负向种子词集中添加该极性类别中表达程度最深的词。例如,在上述训练文本中存在词“召回率,降低,准确率,高,差,大大提高”,可向正向种子词集中添加“大大提高”,向负向种子词集中添加“差”。根据图传播算法的具体求解步骤,求出每个词的极性值。词极性值的具体求解步骤如下。
输入:假设输入为无向边加权图
输出:
参数初始化:设置对于所有的词i,
①对于两个不相同的词(
②对于所有向量
③对于词t(t的范围为
④对于所有的向量
⑤计算
⑥对于词向量
⑦
⑧重复上面的步骤1-步骤7,计算词负极性
⑨
⑩对于词i的极性值
⑪如果对于词i,极性值
通过编程语言实现后,示例中每个词的极性值如图2所示。
图2
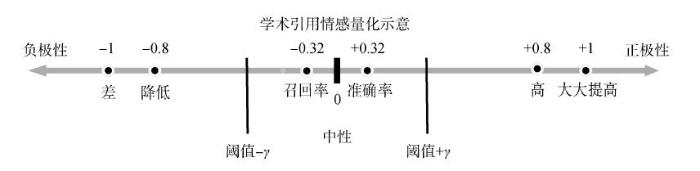
利用图传播算法,获取引用内容中每个词的极性和强度,通过阈值的设定去除其中的中性词,可以较为准确地识别出细粒度条件下句中包含的引用情感词及强度。但由于学术评价的复杂性和特殊性,如“训练时间长”“大量人工参与”等语义单元中,单个词并不具有明显的情感倾向,如“训练时间”“长”“大量”“人工参与”,只有变成语义单元组配时,才能体现出在引用情感上的变化,所以本文利用添加外部词表的方式,在分词时将这些特殊的语义组配单元视为一个整体,整体识别出语义单元的情感倾向和强度。
(2) 情感修饰词的修正系数设定
表5 程度副词分级层次
Table 5
| 分级 | 举例 |
|---|---|
| 极量 | 太 极为 极其 极度 最 最为 过 过于 分外 |
| 高量 | 很 挺 非常 特别 相当 十分 好不 颇 甚为 颇为 异常 深为 满 蛮 够 大为 何等 多么 格外 何其 尤其 无比 不胜 更 更加 更为 更其 越 越发 越加 备加 愈 愈发 愈加 |
| 中量 | 不太 不大 不甚 不够 较 比较 较为 还 相对 |
| 低量 | 有点 有些 稍 稍稍 稍微 稍许 略微 略为 些许 多少 |
除程度副词外,在语义情感的识别研究中,还常会涉及否定词。否定词的使用会使文本表达的情感发生逆转,常用的否定词有:不、没、无、莫、非、否、没有、并不、不是、否定。
徐琳宏等[23]在对语义文本的情感倾向性研究中,通过对每个级别的程度副词设置不同的修正系数,来区别情感表达的强度。本文借鉴了这种方法,4个级别程度副词的修正系数
5 实验与结果分析
5.1 数据来源
本文选用的引文数据集来自中国知网(CNKI)。截止到2019年7月25日,以“信息抽取”为主题词,共检索到学术期刊论文1 359篇,其中包含被引记录的论文1 105篇,占数据总量的81.3%。这些期刊论文总被引频次为17 076次,篇均被引量为12.57次。从上述数据中不难发现,引用现象在科技文献中十分普遍,因此从学术引用角度出发,对论文的学术影响力进行评价具有可行性。
在获取的有被引记录的1 105篇论文中,随机挑选40篇作为具体研究对象,由于施引文献中不同期刊以及学位论文在排版样式、数据存储格式上存在不一致现象,因此根据知网提供的引用线索,利用手工方式对351篇施引文献中的引用上下文进行抽取和整理。
5.2 数据分析
通过细粒度引用情感量化,本文对选取的论文进行综合学术影响力评价值的计算,并将之与单纯依靠被引频次进行学术影响力评估的方法进行比较,将得到的结果按照论文被引频次降序排列,绘制基于被引频次评价和引用情感评价的变化趋势折线图,如图3所示。
图3
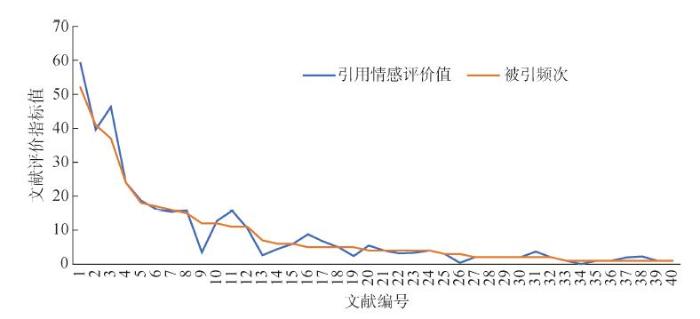
图3
基于被引频次和引用情感评价值的变化趋势
Fig.3
The Trend of the Methods Based on Citation Sentiment and Cited Frequency
表6 被引次数和引用情感指标的比较
Table 6
| 指标 | 斯皮尔曼相关系数 | 离散系数 |
|---|---|---|
| 被引频次 | 0.981** | 1.319 054 |
| 引用情感评价值 | 1.439 410 |
(注:**表示在0.01水平上显著相关。)
通过以上的计算结果和数据分析,可以得出以下结论。
(1)基于引用情感量化的学术评价指标能将引用内容中蕴含的引用情感考虑在内,从而更真实地反映文献的内在价值。从图3可以发现,基于引用情感量化的学术评价指标在总体变化趋势上与基于被引频次的统计指标保持一致,并围绕其上下波动。刘盛博等[28]通过实验发现,在文献引用中超过80%的引用为中性引用,这也使得基于引用情感的学术评价指标总体与被引频次指标趋于一致。在高被引部分,引用情感评价值往往高于被引频次;而在低被引部分,引用情感评价值常围绕被引频次上下波动。总体看来,基于引用情感量化的学术评价指标更符合实际的引用规律,对于高被引论文,其表达的观点多已被研究领域内普遍认同,总体意见也趋于一致,具有很高的学术影响力和参考价值,所以引用情感值往往偏高。而对于低被引论文,在学术界尚未形成统一的观点,会更多地存在一些意见不一致的现象,从而导致引用情感围绕被引频次上下波动。这正说明了基于引用情感量化的学术评价指标能更客观、细致地反映出学术文献在其研究领域内被认可和接受的程度。
表7 引用内容示例
Table 7
| 被引文献编号 | 施引文献 | 引用内容 | 情感量化结果 |
|---|---|---|---|
| 1 | 基于Ontology的中文信息抽取系统的研究与实现 | 由于它是基于Ontology的抽取,因此这种方法对文档的结构没有依赖性。从理论上讲,只要领域Ontology足够强大,它就能在该领域的信息抽取中达到很高的抽取精确率和召回率。 | (-0.5)×(-0.87)+1.5×0.76=1.575 |
| 3 | 基于深度学习的图像检索 | 相比较一般的多层神经网络来说,深度信念网络DBN利用它的基本结构RBM来给网络赋了一个比较好的初值,预防了整个网络陷入局部最小值,而且结构简单,易于扩展。 | 0.75×0.84+0.74+0.73=2.1 |
| 领域文本句子基本概念结构抽取研究 | 用深度学习处理文本并提取文本信息及文本之间的隐含关系,可以明显提高分析的效率,发现一些隐秘却有价值的有用信息。 | 0.85=0.85 | |
| 9 | 基于领域词库的新闻提取技术的研究及应用 | 这种抽取方式大多都是通过人工制定规则,很难用计算机自动发现规则,特别是如今网络流行语千奇百怪更难发现其规则性,所以十分困难。 | 1.5×(-0.67)+1.5×(-0.67)+1.5×(-0.71)=-3.075 |
| 支持DOM模板可视化配置的网页抽取方法 | 手动配置对专业要求较高,需要了解网页结构、正则表达式等知识;又因其配置过程复杂且需手动输入而使效率低下且容易出错。 | (-0.67)+(-0.63)+(-0.73)+(-0.57)=- 2.6 | |
| 26 | 基于Web数据挖掘的多因素科技专家信息提取方法 | 但该文并没有区分 Table 标签的两种不同作用,对于结构复杂、噪音较多的网页会留下较多的噪音信息。 | 0.75×(-0.62)=- 0.465 |
| 31 | 基于混合机器学习模型的多文档自动摘要 | 如张晗、赵玉虹提出了基于语义图的医学多文档摘要模型,能够有效识别文本中的核心内容。 | 0.68=0.68 |
(3)从数据来源考虑,由于施引文献的作者多为研究领域内的专家,所以引用文本内容具有很高的参考价值,是极其重要和丰富的学术资源。如果能将这些隐藏的资源善加利用,一定能为科研工作的展开提供更广泛的帮助。
6 结语
本文从引用内容入手,通过细粒度情感分析对引用内容中作者表达的情感观点进行极性划分和强度量化,并将其与基于被引频次统计的学术评价手段融合,实现了基于引用情感量化的学术评价模型的构建。
通过实验,利用知网上采集的引用数据对基于引用情感的学术评价方法进行可行性和合理性验证。实验结果表明:
(1)基于引用情感的学术评价指标是对单纯依靠被引频次等统计方法进行学术评价方法的良好补充,对学术论文的影响力评价也更为全面。
(2)通过对引用情感的细致量化,基于引用情感的评价方法使得不同类型引用之间的区分更加明显,也使得数据整体更加离散,从而使该方法具有更好的区分度。
(3)将细粒度的情感分析方法引入到引文内容分析中,能够更充分地利用学术资源,或者为国内引文分析研究和学术评价研究提供新方法和思路。
本文实验中选取的数据,其来源学科具有局限性,样本数据量也有待进一步提高,但实验验证了基于引用情感量化的新文献学术影响力评价方法具有巨大的应用潜力,值得期待。
作者贡献声明
姜霖:提出研究思路,设计研究方案,实验分析以及论文撰写;
张麒麟:数据清洗以及论文修改。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据:
支撑数据由作者自存储,E-mail:18205185622@163.com。
[1] 姜霖. SentimentAnalysis.rar. 朴素贝叶斯分类和引用情感细粒度量化程序代码.
[2] 姜霖. CitationContent.rar. 实验引文内容语料.
[3] 姜霖. CitationCorpus.rar. 实验中引用网络资料数据.
参考文献
单篇论文学术影响力评价指标构建
[J].
Study on the Evaluation Indicators of Single Article Academic Impact
[J].
全文本引文分析—引文分析的新发展
[J].
Citation in Full-Text: The Development of Citation Analysis
[J].
Co-Citation Context Analysis and the Structure of Paradigms
[J].DOI:10.1108/eb026695 URL [本文引用: 1]
Some Results on the Function and Quality of Citations
[J].DOI:10.1177/030631277500500106 URL [本文引用: 1]
Content‐Based Citation Analysis: The Next Generation of Citation Analysis
[J].
DOI:10.1002/asi.23256
URL
[本文引用: 1]

Traditional citation analysis has been widely applied to detect patterns of scientific collaboration, map the landscapes of scholarly disciplines, assess the impact of research outputs, and observe knowledge transfer across domains. It is, however, limited, as it assumes all citations are of similar value and weights each equally. Content-based citation analysis (CCA) addresses a citation's value by interpreting each one based on its context at both the syntactic and semantic levels. This paper provides a comprehensive overview of CAA research in terms of its theoretical foundations, methodical approaches, and example applications. In addition, we highlight how increased computational capabilities and publicly available full-text resources have opened this area of research to vast possibilities, which enable deeper citation analysis, more accurate citation prediction, and increased knowledge discovery.
基于引文内容分析的高被引论文主题识别研究
[J].基于被引次数的引文分析无法直接揭示论文的研究内容,利用关键词或从标题、摘要和全文中抽取的主题词很难客观反映论文的被引原因。本文以碳纳米管纤维研究领域的高被引论文为研究对象进行引文内容抽取和主题识别,经人工判读验证:基于引文内容分析的高被引论文识别的核心主题能够较好地揭示高被引论文的被引原因(引用动机),而且与论文的研究内容相符合;与基于全文、基于标题和摘要的主题识别相比,在引文内容分析基础上识别的主题具有更好的主题代表性,能够有效揭示被引文献的研究内容,是对原文相关信息的重要补充。本文的实验表明基于引文内容分析的高被引论文主题识别是可行而且有效的。图4。表4。参考文献31。
Topic Identification of Highly Cited Papers Based on Citation Content Analysis
[J].基于被引次数的引文分析无法直接揭示论文的研究内容,利用关键词或从标题、摘要和全文中抽取的主题词很难客观反映论文的被引原因。本文以碳纳米管纤维研究领域的高被引论文为研究对象进行引文内容抽取和主题识别,经人工判读验证:基于引文内容分析的高被引论文识别的核心主题能够较好地揭示高被引论文的被引原因(引用动机),而且与论文的研究内容相符合;与基于全文、基于标题和摘要的主题识别相比,在引文内容分析基础上识别的主题具有更好的主题代表性,能够有效揭示被引文献的研究内容,是对原文相关信息的重要补充。本文的实验表明基于引文内容分析的高被引论文主题识别是可行而且有效的。图4。表4。参考文献31。
基于位置的共被引分析实证研究
[J].
Empirical Research on Location-based Co-citation Analysis
[J].
基于引文内容的中文图书被引行为研究
[J].
Citing Behavior of Chinese Books Based on Citation Content
[J].
Automatic Classification of Citation Function
[C]//
Aspect Based Citation Sentiment Analysis Using Linguistic Patterns for Better Comprehension of Scientific Knowledge
[J].DOI:10.1007/s11192-019-03028-9 URL [本文引用: 1]
Improving Citation Sentiment and Purpose Classification Using Hybrid Deep Neural Network Model
[C]//
The Incidence and Role of Negative Citations in Science
[J].DOI:10.1073/pnas.1502280112 URL [本文引用: 1]
基于引用内容性质的引文评价研究
[J].
Research on Citation Evaluation Based on the Nature of Citation Content
[J].
基于引用情感的论文学术影响力评价方法研究
[J].
A Method to Evaluate the Academic Influence of Papers Based on Citation Sentiment
[J].
面向知识服务的知识组织理论与方法
[M]. 第1版.
Knowledge Service Oriented Knowledge Organization Theory and Method
[M].The 1st Edition.
Collective Intelligence 实战
[M].第1版.腾灵灵,冯飞,译.
Collective Intelligence in Action
[M]. The 1st Edition.Translated by Teng Lingling,Feng Fei.
Sentiment Composition
[C]//
Sentiment Analysis: Adjectives and Adverbs are Better than Adjectives Alone
[C]//
基于引用情感交互的学术检索结果排序方法研究
[J].
Research on the Ranking Method of Academic Retrieval Results Based on Citation Sentiment Interaction
[J].
The Viability of Web-derived Polarity Lexicons
[C]//
基于评论情感分析的个性化推荐策略研究——以豆瓣影评为例
[J].
Research on Personalized Recommendation Strategy Based on Sentimental Analysis of the Reviews——Taking Film Reviews of douban. com as an Example
[J].
程度副词的特点范围与分类
[J].
On the Characteristics, Range and Classification of Adverbs of Degree
[J].
基于语义理解的文本倾向性识别机制
[J].文本倾向性识别在垃圾邮件过滤、信息安全和自动文摘等领域都有广泛的应用。本文提出了基于语义理解的文本倾向性识别机制。其主要思想是首先计算词汇与知网中已标注褒贬性的词汇间的相似度,获取词汇的倾向性;再选择倾向性明显的词汇作为特征值,用SVM分类器分析文本的褒贬性;最后采用否定规则匹配文本中的语义否定的策略提高分类效果,同时处理程度副词附近的褒义词和贬义词,以加强对文本褒贬义强度的识别。
Text Orientation Identification Based on Semantic Comprehension
[J].文本倾向性识别在垃圾邮件过滤、信息安全和自动文摘等领域都有广泛的应用。本文提出了基于语义理解的文本倾向性识别机制。其主要思想是首先计算词汇与知网中已标注褒贬性的词汇间的相似度,获取词汇的倾向性;再选择倾向性明显的词汇作为特征值,用SVM分类器分析文本的褒贬性;最后采用否定规则匹配文本中的语义否定的策略提高分类效果,同时处理程度副词附近的褒义词和贬义词,以加强对文本褒贬义强度的识别。
汉语语句主题语义倾向分析方法的研究
[J].本文介绍了如何识别汉语语句主题和主题与情感描述项之间的关系以及如何计算主题的语义倾向(极性)。我们利用领域本体来抽取语句主题以及它的属性,然后在句法分析的基础上,识别主题和情感描述项之间的关系,从而最终决定语句中每个主题的极性。实验结果显示,与手工标注的语料作为金标准进行比较,用于识别主题和主题极性的改进后的SBV极性传递算法的F度量达到了72.41%。它比原来的SBV极性传递算法和VOB极性传递算法的F度量分别提高了7.6%和2.09%。因此,所建议的改进的SBV极性传递算法是合理和有效的。
Research on Semantic Orientation Analysis for Topics in Chinese Sentences
[J].本文介绍了如何识别汉语语句主题和主题与情感描述项之间的关系以及如何计算主题的语义倾向(极性)。我们利用领域本体来抽取语句主题以及它的属性,然后在句法分析的基础上,识别主题和情感描述项之间的关系,从而最终决定语句中每个主题的极性。实验结果显示,与手工标注的语料作为金标准进行比较,用于识别主题和主题极性的改进后的SBV极性传递算法的F度量达到了72.41%。它比原来的SBV极性传递算法和VOB极性传递算法的F度量分别提高了7.6%和2.09%。因此,所建议的改进的SBV极性传递算法是合理和有效的。
基于产品特征词关系识别的评论倾向性合成方法
[J].
A Method for Combining Online Reviews’ Sentiment Orientation Based on Recognition of Relationship Between Product Feature Words
[J].
基于区间数的 Spearman 秩相关系数的多属性决策方法
[J].
Multiple Attribute Decision Making Method Based on Interval Number Spearman Rank Correlation Coefficient
[J].
等级相关系数在教学质量评价中的应用
[J].工业化与信息化的关系信息化的概念起源于20世纪60年代的日本,最初是日本学者从社会产业结构演进的角度提出来的.
Application of Grade Correlation Coefficient in Teaching Quality Evaluation[
[J].工业化与信息化的关系信息化的概念起源于20世纪60年代的日本,最初是日本学者从社会产业结构演进的角度提出来的.
基于引用内容的论文影响力研究——以诺贝尔奖获得者论文为例
[J].
Research on Paper Influence Based on Citation Context: A Case Study of the Nobel Prize Winner’s Paper
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}