




1 引言
知识资源在知识服务中占据十分重要的地位,对于科研、情报等人员来说知识资源的及时、准确输入有助于科研的创新以及成果的转化。近年来,可获取的开放资源数目逐渐增多,在海洋领域中,每日通过监测采集到的开放资源可达数千条,主要包括科技资讯、科技政策、期刊论文、研究专利、基金项目以及科技报告等类型的知识资源。目前,海洋平台已采集到的开放知识资源数目已达百万级,面对每天不断增长的数据量,仅仅使用传统搜索引擎的方式越来越耗时,如何使科研人员快速地从庞大数据中获取可利用的信息,提高资源的利用率成为研究重点[1]。当前,海洋平台主要采用人工筛选的方式,通过发送邮件对用户提供推荐服务,这种方式不仅耗时耗力,而且只针对个别主题的资源对所有用户提供相同推荐。显然,这种方式不能够为不同的用户提供他们想要的知识资源。因此,本文提出个性化知识推荐模型实现对不同用户的精准推荐,重塑知识资源推荐服务模式。
2 研究现状
个性化推荐系统(Personalized Recommendation System)多用于电商、音乐、影视等领域中,但是在资源环境领域的应用还比较少。个性化推荐系统是一种信息过滤系统,可以根据用户的喜好构建出用户与数据之间的潜在关系并预测用户的需求,主动地为用户推荐其所需要的知识资源[2]。在推荐系统中,推荐算法可以分为两大类:基于相似度计算的推荐算法;基于机器学习的推荐算法。
基于相似度计算的推荐算法本质与搜索引擎类似,包括最早被人们使用的基于内容(Content-based)的推荐算法,以及使推荐系统不仅仅局限于内容本身的协同过滤(Collaborative Filtering)算法,都是目前使用最广的推荐算法并且在不同的场景都已得到相应优化。如张颖[3]提出使用基于内容和协同过滤的混合推荐算法机制,规避各自的缺点,利用各自的优势为用户提供个性化推荐服务;Chen等[4]提出一种基于优化用户相似度的协同过滤算法,在传统余弦相似度中增加一个用于计算用户之间等级差异的元素;钱春琳等[5]对协同过滤推荐模型进行改进,在原有算法基础上引入情感分析模型进行推荐,提高了推荐结果的准确度;杨佳莉等[6]提出一种自适应的混合协同过滤算法,解决了在处理大数据量时算法效率低下的问题。
随着机器学习方法的快速发展,推荐算法也逐步发展为深度学习阶段,可以将数据特征与多维空间模型相结合,通过多层网络深入学习特征之间的关系。如Zhao等[7]提出一种新颖的LSIC模型,该模型利用对抗神经网络在内容感知推荐中调整长期和短期的信息,此外,还训练了一个鉴别器,对数据进一步加工和提取以提升系统性能。Sun等[8]将Bert双向Transformer结构引入推荐系统,用完形填空的方式防止信息遗漏,并可用于随机mask词语进行预测。但是,深度学习在推荐系统中的应用还处于发展阶段,并不成熟,而且科技文本在深度学习中需要大量的训练数据标注,语料构建成本高,所以目前的数据还不能很好地应用于深度学习技术。
综上所述,根据海洋平台系统架构以及数据特点,结合内容和协同过滤混合推荐算法[9]表现出的优势,本文采用分布式并行计算架构提高数据处理效率,采用内容和协同过滤的混合推荐算法,并增加线性回归对推荐候选集精准排序,提高推荐结果的准确度。
3 系统总体架构
根据前期调研以及数据的基本情况,本文提出面向海洋领域数据的知识推荐模型构建流程,分为4个阶段:数据获取与存储、数据建模、个性化推荐及存储、模型训练及精准排序,如图1所示。
图1

图1
海洋领域知识推荐系统架构
Fig.1
Architecture of a Knowledge Recommendation System in the Marine Domain
3.1 数据获取与存储
数据是算法和模型的基础,不同类型的数据有着不同的价值,也能反映用户的不同意图。对于海洋领域数据而言,本文所需要的数据包括用户特征数据、文本特征数据和用户行为特征数据。用户特征数据和文本特征数据是刻画用户和文本属性的基础数据,用户特征数据主要体现在用户ID、用户姓名以及用户所属专题;文本特征数据主要包括文本所属ID、文本标题以及该文本所属专题。这些属性一方面可以用于候选集触发过程中对特征进行加权或降权;另一方面也可以作为重排序模型中的用户维度特征。用户行为特征主要包括用户ID以及该用户所访问文本ID。用户行为数据记录了用户在平台上的不同点击行为,这些数据一方面用于推荐算法产生候选集;另一方面可以作为重排序模型的交叉特征[10]。数据类别划分如表1所示。
表1 数据类别划分
Table 1
| 数据类型 | 数据属性 |
|---|---|
| 用户特征数据 | 用户ID、用户姓名、用户所属专题 |
| 文本特征数据 | 文本ID、文本标题、文本所属专题、评分 |
| 用户行为特征数据 | 用户ID、被访问文本ID |
鉴于数据规模不断增加,为提升后期的计算能力和效率,本系统采用Hadoop集群进行分布式并行计算,提升计算性能,缓解数据处理压力。处理好的数据文件将存储在分布式文件系统HDFS中,为下一步数据建模做准备。
3.2 数据建模
推荐系统的目的是要在用户(user)和物品(item)之间建立连接,如何将用户特征信息与物品特征信息进行融合建模是重要环节。本文在推荐中采用的是基于内容的推荐算法及基于物品的协同过滤算法相结合的方式,数据建模的方法与后期的算法实现紧密相关。
基于内容的推荐算法用户易于理解且简单有效,但是也存在未个性化推荐且推荐精度低等问题。与协同过滤算法结合使用可以在一定程度上解决这些问题。协同过滤是目前基于相似度计算的推荐系统所采用的主流方法之一,根据每个用户的历史点击行为,从所有条目中筛选出与当前条目内容相近的进行召回,再根据每个条目的历史评分记录对其进行预测,按照相似度的大小生成推荐列表,再根据需求选取列表中的top-N进行推荐。协同过滤算法主要分为两类:基于用户的协同过滤(User-Based CF)和基于物品的协同过滤(Item-Based CF)。本文使用Item-Based CF,思路是根据用户点击浏览过的文本,找出相似的内容对其进行推荐。具体而言,即是建立“用户ID-文本ID-评分”的三维向量模型:{userid,itemid,score},三个维度用户、文本、评分分别由各自的属性值构成。
3.3 个性化推荐及存储
本文不再赘述基于内容的推荐算法的具体过程,主要针对协同过滤算法的实现过程展开。基于海量数据的推荐系统使用分布式并行计算是比较好的选择,相对于使用单机对数据进行挖掘具有更好的鲁棒性和可扩展性。MapReduce是Hadoop的核心组件之一,是进行离线大数据处理的常用计算模型。协同过滤算法在分布式计算中有两种实现方式:一种为倒排式,是目前的主流实现方式;另一种为分块式,这种方式计算量大,对数据存储的要求较高,不易实现。因此,本文使用三台服务器搭建的Hadoop集群以MapReduce化倒排式协同过滤的方法进行算法实现。总体实现流程如图2所示。
图2
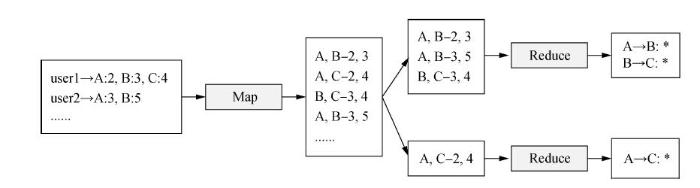
图2
MapReduce化倒排式协同过滤实现流程
Fig.2
Implementation of MapReduce Inversion Collaborative Filtering
协同过滤的算法如公式(2)所示。为了简化计算,将计算流程划分为三个阶段的MapReduce实现。
在相似度计算的过程中,通常热门类别的类内文本相似度较高,如果某一用户同时喜欢热门类别和非热门类别的知识资源,不归一化处理就会出现只给用户推荐热门类别中资源的现象。因此,当使用归一化后,不仅可以简化计算,增加推荐的准确度,还可以消除数据中心权重的影响,提高推荐的覆盖率和多样性。根据{userid,itemid,score}三维模型中的itemid做item聚合,将所有点击过相同item的user追加到user_score_list列表中,然后对列表进行遍历,再进行归一化计算。接着实现user聚合,将同一用户历史点击过的条目做聚合,实现召回的目的。通过查找矩阵中相同的userid,将与其相关的所有条目添加到item_score_list列表中,再对列表进行循环遍历得到每个item的score。根据相似度的公式,将两个item的score相乘,输出类似于{item1,item2,score}形式的矩阵。最后根据所得结果只需要将具有相同{item1,item2}的分数求和,所得分数即为两个item之间的相似度。每个阶段的计算过程如表2所示。
表2 MapReduce化倒排式协同过滤计算过程
Table 2
| 第一次MR阶段 | 第二次MR阶段 | 第三次MR阶段 |
|---|---|---|
| Map输入 | Map输入 | Map输入 |
| {userid,itemid,score} | {userid,itemid,score} | {itemid,itemid,score} |
| Map输出 | Map输出 | Map输出 |
| {itemid,userid,score} | {userid,itemid,score} | {itemid,itemid,score} |
| Reduce输入 | Reduce输入 | Reduce输入 |
| {itemid,userid,score} | {userid,itemid,score} | {itemid,itemid,score} |
| Reduce输出 | Reduce输出 | Reduce输出 |
| {userid,itemid,score} | {itemid,itemid,score} | {itemid,itemid,score} |
根据上述计算结果将数据整理为{itemid→itemid1:score1 itemid2:score2 itemid3:score3…}的形式,以此表示item与item1的相似度为score1,item与item2的相似度为score2,……。每行数据按照score的数值由大到小排列,也就是通过推荐算法完成相似度计算的粗略候选集排序。
基于内容和协同过滤的推荐算法得到两个格式相同、结果不同的候选集,整理为{key value}的形式,基于内容的推荐候选集key为CB_itemid,value为itemid1:score1_itemid2:score2等;基于协同过滤的推荐候选集key为CF_itemid,value为itemid1:score1_ itemid2:score2等。将整理好的候选集存储到内存数据库Redis中,用Redis数据库当做索引库,便于后期模型对候选集合进行检索,为模型的打分、排序和过滤做准备。
3.4 模型训练及精准排序
根据两种算法分别对每个item进行召回与粗排,结果只能作为初步筛选。不同算法形成不同的推荐列表,为了结合使用这两种算法,需要将两个推荐列表合并,但在不同列表中相同item的score是不能进行比较和排序的。因此,借助机器学习的方法,训练出排序模型,对合并后的具有多方面因素的推荐列表进行统一打分并排序,以达到精排的效果。
机器学习中,由于非线性模型有多样的层级结构,在应对各种不同的数据集时稳定性很好,更加容易对决策边界建模,但是其训练成本与模型后期的更新迭代时间要相对长一些。反之,线性模型则相对简单,虽然在面对非线性决策边界时性能较差,但是它的训练效率与最终模型的可解释性都相对较高,也可以通过正则化来避免过拟合的问题。本文选取目前应用较多的线性模型逻辑回归(Logistic Regression,LR),定义如公式(3)所示[13]。
线性回归首先要对输入的数据集x进行处理,实验中将输入数据集x整理为{key value}的形式,key代表正样本和负样本,分别用1和0表示。将用户点击过的条目设为正样本,将该用户所属专题下未点击的条目设为负样本,避免负样本的数量远远大于正样本的数量而导致最终预测不准确的情况。value代表用户特征和物品特征,用户特征主要由用户所属专题和score组成,score代表其特征是否存在,1代表存在,0代表不存在;物品特征主要由文本标题分词与IDF值组成,数据格式如图3所示。根据公式(3)对数据进行逻辑回归训练,通过训练求出每个特征所对应的最优权重值w以及偏置b,即为模型的最终结果。
图3
利用模型对两部分候选集进行统一打分。当用户在页面中点击某一标题时,系统获取到用户的userid和itemid,通过itemid分别在两个候选集中检索出此itemid所对应的粗排候选集排名前10的样本的itemid进行统一打分。候选集中的分数只是用于初步的粗排,在此阶段可以直接舍弃。根据所取出20个样本的itemid在训练模型数据集中对找到其对应的分数score作为逻辑回归中的x值,在sigmoid函数的基础上提出公式(4),以求出候选集最终的统一打分。对分数由大到小排序,根据需求选取要推荐的Top-N即为最终推荐列表。
4 实验结果与分析
4.1 精排模型评价标准
利用两种常用的机器学习模型评估方法精确率(Precision)、均方误差(Mean Squared Error,MSE)对实验中的排序模型效果进行评估。精确率是评价模型效果好坏最直观的标准,定义如公式(5)所示。其中TP表示推荐的知识资源中用户认可的数量,FP表示推荐的知识资源中用户不认可的数量。均方误差是指模型预测值与目标变量的真实值之差平方的期望值,可以评价数据的变化程度。MSE值越小,说明预测模型描述实验数据具有更好的精确度,定义如公式(6)所示[14]。其中,
模型评估结果如图4所示。
图4

4.2 结果分析
本实验在三台服务器所搭建的Hadoop集群中实现,所有过程采用Python语言编写,采集数据存储在分布式文件系统HDFS中,经过处理后的候选集存储在内存数据库Redis中。数据集来源于本中心研发的海洋平台,用户特征数据和文本特征数据可直接从数据库中导出,从Solr中导出近半年的用户访问日志作为用户行为数据,共有20余万条。通过机器学习模型精排后选取Top-10作为要推荐的内容,并用于前台展示;若候选集中的数据小于10条,则选择所有的候选集作为推荐内容。
根据实验结果,推荐模型的准确度为78.5%。经系统测试,模型调用速度快,在一定程度上实现了知识资源对用户的个性化推荐。由于推荐系统在资源环境领域的应用还不多,与传统的人工筛选方式相比,提高了推荐效率,满足了用户的个性化需求。
5 结语
本文提出基于并行协同过滤算法的知识推荐模型的整体构建过程,首先对所需数据进行采集和预处理,根据不同数据类型进行不同的特征建模,为后续的算法使用做好前期准备。其次,根据平台的需求以及实际情况,采用基于内容和协同过滤两种混合推荐算法,规避其不足,利用其优势提高推荐结果的准确度。引入MapReduce并行计算技术,筛选出知识资源的推荐候选集。最后,采用逻辑回归根据候选集训练排序模型,通过模型实现对两个候选集的统一打分,达到对候选集精准排序的目的。
随着推荐系统的发展与应用,推荐技术已经较为成熟,但是在资源环境领域的应用还较少。本研究的实验结果表明,在海洋平台采用多种技术混合的方式在一定程度上实现了良好的推荐效果,能够对不同用户筛选其感兴趣的知识资源,提供个性化推荐服务。但仍存在很多不足与提升的空间,如在训练排序模型阶段,可以优化负样本的选取方法。在未来的工作中,笔者将进一步对资源环境领域中推荐模型的方法与应用进行研究与实验,以找到更好的方法和策略。
作者贡献声明
杨 恒:设计研究方案,采集、清洗和分析数据,进行实验,撰写论文;
王思丽:参与研究方案设计及数据分析;
祝忠明:提出研究思路,论文最终版本修订;
刘 巍:参与实验过程,参与算法实现;
王 楠:参与数据遴选与分析。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据:
支撑数据由作者自存储,E-mail: yangh@llas.ac.cn。
[1] 杨恒, 王思丽, 刘巍. user.data.用户画像数据.
[2] 杨恒, 王思丽, 刘巍. text.data.文本元数据.
[3] 杨恒, 王思丽, 刘巍. user_action.data.用户行为数据.
[4] 杨恒, 王思丽, 刘巍. data_process.py.数据预处理程序.
[5] 杨恒, 王思丽, 刘巍. cb.py.CB算法程序.
[6] 杨恒, 王思丽, 刘巍. cf.py.CF算法程序.
[7] 杨恒, 王思丽, 刘巍. lr_pre.py.模型输入预处理程序.
[8] 杨恒, 王思丽, 刘巍. samples.data.模型训练数据.
[9] 杨恒, 王思丽, 刘巍. lr.py.模型训练及预测程序.
参考文献
协同过滤推荐算法研究进展
[J].
Research Process of Collaborative Filtering Recommendation Algorithm
[J].
协同过滤技术在电子商务推荐系统中的应用研究
[D].
Research on Collaborative Filtering Technologies of Recommendation System for E-Commerce
[D].
基于混合机制的新闻推荐系统研究
[D].
Research on News Recommendation System Based on Hybrid Mechanism
[D].
An Improved Collaborative Recommendation Algorithm Based on Optimized User Similarity
[J].DOI:10.1007/s11227-015-1518-5 URL [本文引用: 1]
基于在线评论情感分析的改进协同过滤推荐模型
[J].
Advanced Collaborative Filtering Recommendation Model Based on Sentiment Analysis of Online Review
[J].
一种自适应的混合协同过滤推荐算法
[J].
DOI:10.19678/j.issn.1000-3428.0051041
URL
[本文引用: 1]

为解决协同过滤算法在处理数据量较大时存在推荐效率低的问题,提出一种自适应混合协同推荐算法。根据待推荐用户活跃度和目标物品新鲜度调节模型权重,基于张量分解计算物品间的相似度,通过短路径枚举叠加生成预测结果。实验结果表明,与CBCF算法相比,该算法推荐准确率提高了28.6%。
An Adaptive Hybrid Collaborative Filtering Recommendation Algorithm
[J].
DOI:10.19678/j.issn.1000-3428.0051041
URL
[本文引用: 1]
为解决协同过滤算法在处理数据量较大时存在推荐效率低的问题,提出一种自适应混合协同推荐算法。根据待推荐用户活跃度和目标物品新鲜度调节模型权重,基于张量分解计算物品间的相似度,通过短路径枚举叠加生成预测结果。实验结果表明,与CBCF算法相比,该算法推荐准确率提高了28.6%。
Leveraging Long and Short-Term Information in Content-Aware Movie Recommendation via Adversarial Training
[J].
DOI:10.1109/TCYB.2020.2997943
URL
PMID:32584775
[本文引用: 1]
This article focuses on the event-triggered-based adaptive neural-network (NN) control problem for nonlinear large-scale systems (LSSs) in the presence of full-state constraints and unknown hysteresis. The characteristic of radial basis function NNs is utilized to construct a state observer and address the algebraic loop problem. To reduce the communication burden and the signal transmission frequency, the event-triggered mechanism and the encoding-decoding strategy are proposed with the help of a backstepping control technique. To encode and decode the event-triggering control signal, a one-bit signal transmission strategy is adopted to consume less communication bandwidth. Then, by estimating the unknown constants in the differential equation of unknown hysteresis, the effect caused by unknown backlash-like hysteresis is compensated for nonlinear LSSs. Moreover, the violation of full-state constraints is prevented based on the barrier Lyapunov functions and all signals of the closed-loop system are proven to be semiglobally ultimately uniformly bounded. Finally, two simulation examples are given to illustrate the effectiveness of the developed strategy.
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
[OL].
基于协同过滤和内容过滤的微博话题混合推荐算法
[J].
Microblog Topic Hybrid Recommendation Algorithm Based on Collaborative Filtering and Content Filtering[
[J].
Item-based Collaborative Filtering Recommendation Algorithms
[C]//
改进的基于内容的协同过滤电影推荐算法
[J].
Modified Content-based Collaborative Film Recommendation Algorithms[
[J].
基于TF-IDF的古籍文本内容特征提取方法
[J].
TF-IDF-based Feature Extraction Method for Ancient Text Content[
[J].
基于机器学习的核电文档个性化推荐系统研究
[J].
Research on Nuclear Power Document Personalized Recommendation System Based on Machine
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}