




1 引言
学术文献可用于引文推荐、新颖性评价、主题迁移等重要研究,是这些研究的重要研究数据,其重要性不言而喻。这些研究的首要步骤是理解文献的逻辑结构,即从文献中按照位置和数据类型进行提取,比如文献的标题、作者、章节标题、章节内容、图片、表格等。其中图片、表格作为典型视觉资源,一定程度上反映文献的核心思想、研究方法和结论,是成果的重要载体[1],也是多种类型的研究的重点研究对象。
学术文献的主流发布格式是PDF格式,2016年世界刊文量前5的期刊[2]均主要采用该格式。该格式的设计目的是保证文档在不同软件和系统之中的视觉一致性,该格式储存了元素内容和元素的位置,在用户阅读时将元素逐个渲染(“画”)到对应的页面位置上。因为在该格式中没有对元素逻辑结构信息进行描述,无法直接知晓不同内容在文献中扮演的角色,这是学术文献需要进行结构理解的根本原因。而学术文献中的图片大量使用矢量图,表格大都为矢量几何元素与文本的混合结构,进一步增大了对于图表结构识别与理解的难度。
尽管通过复杂的人工特征和规则能够在一定程度上对特定排版的文献页面中的图表进行识别,但不同学科、不同期刊的学术文献有众多不同的排版样式,针对每种样式单独进行规则构建的时间成本难以接受。深度学习方法在其他任务中能够自动学习数据的多种特征并且已经取得了较好的成果。基于深度学习的文献逻辑结构理解是一个具有前景的研究方向,但是目前受限于缺少海量的标注数据集,该方向的开展存在一定的困难。本文提出一种学术文献图表位置的自动标注方法,利用该方法标注的数据集将会驱动基于深度学习的文献逻辑结构理解研究。
2 相关研究
2.1 文献图表内容分析
文献中的图表以信息可视化的形式,将需要用复杂语言描述的信息转化为简洁的图示,大大降低了读者理解作者意图的难度[3],图表中蕴涵了丰富的信息,是重要的研究对象。Cabanac等研究了5 180篇、来自6个学科的文献,对比分析单一作者和多作者的研究在图表使用行为上的差异,指出多作者文献倾向于使用数量更多的图表,并指出在文献中图片对趋势表达效果较强、表格有较好的结果展示能力[4]。Lee等利用机器视觉和机器学习技术将800万PubMed数据库中的图表分成5类,并将它们和相应文献的影响力进行比对,发现图表的分布和类型在长时间内保持相对稳定,但不同领域有所区别。高影响力的文献趋向使用更多的示意图帮助读者理解[5]。Apostolova等指出文献中图片的准确定位和索引,对于文献图片检索的正确性和效率有重要影响[6]。Splendiani等使用决策树将医学文献中的文本和文献中的图片进行匹配,为图片添加文字描述[7]。这些研究都需要对文献中的图表进行准确定位和抽取后才能进行。
2.2 文献图表定位
对于PDF格式的学术文献,华盛顿大学的Allen AI实验室的PDF Figures系列工具[10]是针对计算机学科文献构建的图表抽取工具,该工具针对计算机领域的文献特点,通过关键词匹配的方式找到文献中诸如Table、Fig等图表注释的关键字,然后搜索关键字附近区域的不含正文的矩形区块,能够以一定的准确率抽取图表。于丰畅等从机器视觉的角度,对PDF渲染图进行物体检测,对检测到物体根据启发式算法进行分类,在ACL数据集的子集上取得了较好的结果[11]。随着机器学习技术的进步,多种机器学习算法应用于文档的图表定位标注,Choudhury等解析PDF文档的数据流,对其中的路径元素进行人工特征提取,使用DBSCAN对这些特征进行聚类,从而将路径元素合并成为图表。并且在自建的数据集上取得超过80%的准确率[12]。以上研究均依赖人工特征或者领域知识,对于不同学科、甚至同一学科内不同排版的期刊,抽取的准确率均存在较大程度下降,无法支撑绝大多数研究任务的需求[13]。
2.3 数据集标注
对于数据标注学界早有研究,主要包括人工标注、机器标注和数据构造三种主流方式。人工标注是其中准确率最高的方式,但是受限于巨大的人力和时间成本,难以广泛采用,多数此类研究主要关注标注工具和标注流程[18]。机器标注在人力成本和时间成本上有一定的优势,Zech等使用词袋、词向量、LDA对CT报告进行特征提取,并对报告中的发现进行学习,学习后的模型用于对同种类型报告进行标注工作[19]。数据构造的方式将满足任务需求的数据以一定的随机性拼接在一起,是一种巧妙的数据集构建方式[20]。但是这种方式难以穷举真实数据的所有情形,即难以和真实数据保持相似的分布情况,对后续的深度学习模型的泛化能力有一定的影响。针对本文的研究对象,这三种主流方式中,数据构造明显无法构造种类繁多的学术文献排版方式,而人工标注的时间和人力成本又难以接受,故本文采取机器标注的思路,提出一种自动标注学术文献中图表位置的算法。
3 研究方法
3.1 研究目标
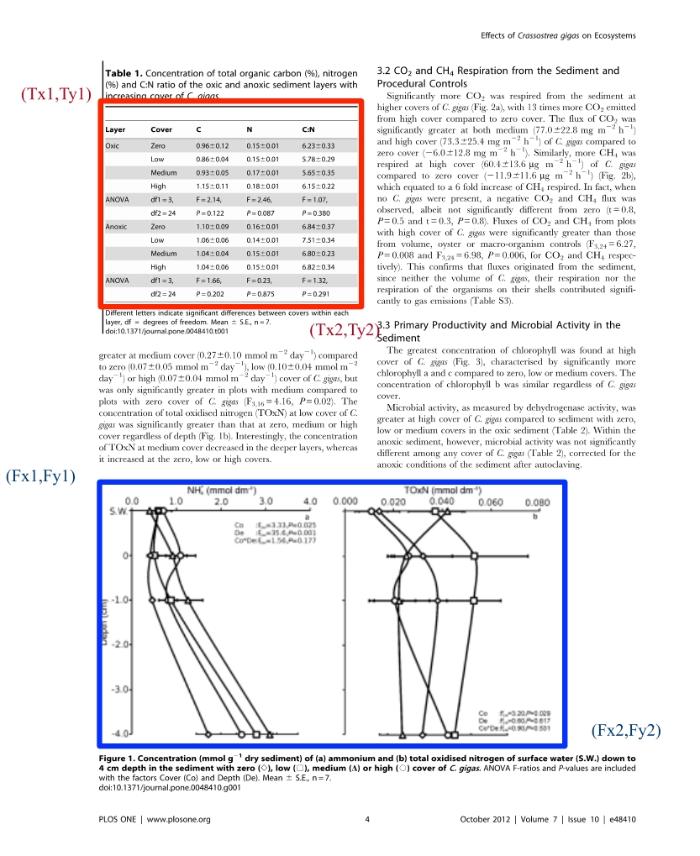
本文的目标是对学术文献中的图表进行标注,得到它们在文献PDF文件中的坐标。如图1所示,对于学术文献的某一页,在该页中存在一个表格和一个图片,标注的结果为表格的左上角坐标(Tx1,Ty1)和右下角坐标(Tx2,Ty2),图片的左上角坐标(Fx1,Fy1)和右下角坐标(Fx2,Fy2)。
图1
3.2 基础数据集
本文使用PubMed Open Access数据集作为基础数据集进行标注。该数据集为PubMed Center论文集的子集,截至2015年,该子集收录了来自大约1 800种期刊超过100万篇文献[21],其文献的排版样式多样,非常适合用于构造本文所述的标注数据集。该数据集提供了多种形式的数据,主要包括PDF格式文献,XML格式文献,若文献中包含图片、表格还提供它们的图表的图片格式文件(后文简称原图)。在XML格式的文献中记录了文献中所有内容和内容的逻辑结构分类,但是没有内容在页面中的坐标。
3.3 模板匹配
考虑到数据集中包含有图表的原始图片,自然希望使用模板匹配(Template Matching)进行标注工作。模板匹配是数字图像处理中的一种典型问题,研究如何在已知一张小图(模板,本文中的图表原图)的前提下,从一张更大(本文中为PDF文献的某一渲染页,后文称文献渲染页)的图中搜寻小图的问题。
模板匹配的基本原理是利用模板图片在原始图片上滑动扫描,并逐次计算重叠区域的相似度,返回相似度最高的局部原始图片[22]。模板匹配的方法要求模板图片和原始图片中待搜索的区域拥有同样的尺寸、方向和元素。然而PubMed的数据中的图片均为相应图表的原始素材,尺寸通常相对较大,而文献中的图表由于版面有限一般都经过等比缩小,所以标注工作无法直接使用模板匹配的方法。
3.4 尺寸自适应模板匹配
为了解决上述问题,本文采用尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)算法[23],对图片进行特征点计算,然后通过特征点匹配的方式找到文献中的图表内容。
SIFT是一种图片特征提取算法, 其具有两个特性:第一,旋转不变性,即图片经过旋转不影响特征点的计算。在部分文献中图片原图与文献中的图表摆放方向不一致,利用该特性可以较好规避方向不一致的问题。第二,尺度(缩放)不变性,即图片经过缩放不影响特征点的提取。在图像特征提取中,角是一个重要的特征形式,角相对于线和面有更加明确的指示性。考虑用观测窗观察一个矢量线段画出的弧形角,若将图片放大到一定程度,使用同样大小的观测窗,观测的对象就变成弧线的一部分,继续放大这个角,仍使用相同大小的观测窗,甚至会观测到一条直线。本文的研究对象是两张有较大尺寸差异的图片,SIFT算法的这个特征显得尤为关键。
图2为尺寸自适应模板匹配的算法流程图,模板和文献渲染页分别进行特征提取后,得到特征点和特征点描述符,将特征点描述符进行相似度计算,来自两张图、相似度高于一定阈值特征点被认为是相同的特征点。若模板和文献渲染页中满足相似条件的特征点数目超过阈值(本文设置为20),则通过原图特征点与对应的模板特征点几何透视变换关系计算出相同内容的区域。本文使用OpenCV机器视觉工具包实现本部分的算法。
图2
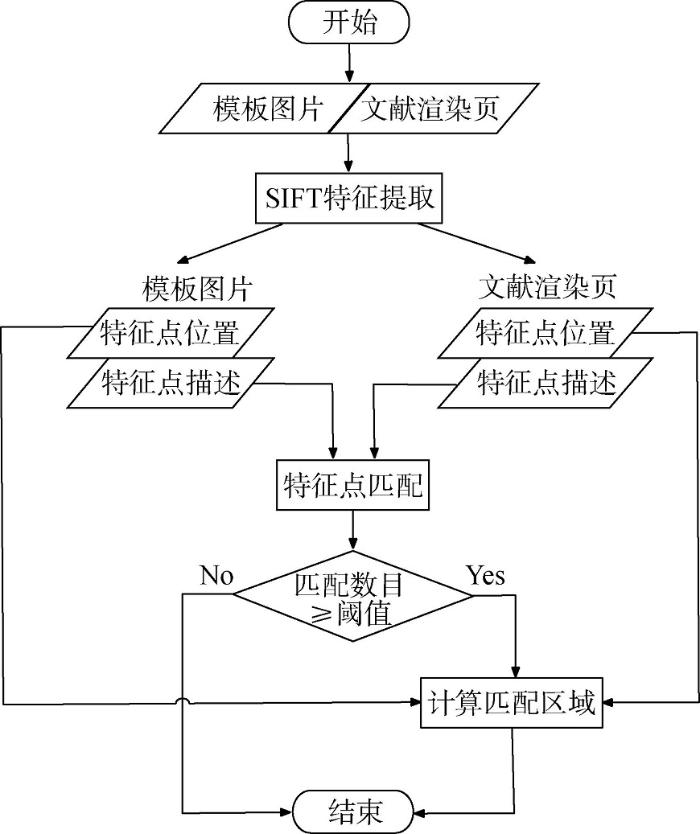
图2
尺寸自适应模板匹配的算法流程图
Fig. 2
Flow Chart of Size Adaptive Template Matching Algorithm
模板和文献渲染页中匹配的特征点数目阈值控制了匹配的难易程度。学术文献中的图表一般由简单的几何元素构成,特征点(角)数量相对较少,所以设置过高的阈值将会漏掉大量的原本正确的匹配结果;而阈值设置过低时,会引入特征点过少的原图模板对,此时不能计算几何透视关系,因而无法定位模板中的图表区域。经过多次实验,本文选取20作为模板和文献渲染页中匹配的特征点数目阈值。
对于满足上述匹配条件的模板和原图对,算法将输出预测的定位区域,否则输出为空。输出为空可能包括两个方面的原因:输入的模板和原图对的对应关系不正确,即文献渲染页中没有模板的图案;文献渲染页中存在模板的图案,但是算法未能正确定位。
3.5 实验思路
本文的方法,具体按照如下步骤进行:
(1)解析XML文献,获得文献中的图表与原图的对应关系;
(2)定位PDF文献中含有图表的页;
(3)将步骤(1)和步骤(2)的结果进行对应;
(4)对步骤(3)的结果,利用尺寸自适应模板匹配算法进行标注,输出文献页-图表标注结果。
以某一篇文献举例,本方法的具体流程:
(1)在PubMed数据集的XML格式文献中找到所有<fig>(图节点)和<table-wrap>(表节点)节点,如果该节点存在<graphic>子节点,则表明该图表在数据集中包含有原图,原图文件名储存在<graphic>的href属性中,图表的注释储存在<label>、<caption>两个节点中。如此可以得到文献表图和原图的对应关系,以及每个图表的注释,形如(原图文件名,图注/标注)元组的形式,如:(1471-2407-5-109-1.jpg, “Figure 1 H&E stained section…”);
(3)对比步骤(1)和步骤(2)中的字符串,若两字符串中相同的开头单词,则文献页面和图表的原图存在包含关系。确定包含关系后,将文献的该页渲染成为图片格式,以备后续使用,如包含关系(第3页渲染图,1471-2407-5-109-1.jpg)。
(4)将步骤(3)的结果作为输入,利用尺寸自适应模板匹配算法进行标注。
4 实验
4.1 实验对象
从PubMed Open Access数据集中随机选取包含图表的文献,随机选取537篇文献的1 976页作为测试数据集,以验证本文算法的性能。
测试数据集的具体选取方法如下:在PubMed Open Access数据集中,文献数据是按照文件夹组织的,即每一篇文献的所有数据储存在同一个文件夹内,通过检测某文件夹内是否含有图片确定该文献是否含有图表,并检验文献附带的图表原图大小,原图的长宽需均大于200像素才会选入数据集,以此保证模板具有较好的清晰度。
为方便人工校验,在结果中,模板与文献渲染页将会左右并排放置,所有匹配特征点之间均用绿线标示。若特征点匹配数量超过阈值,计算出的匹配区域将会用红色框标注,如图3所示分别为表格、折线图和图片的匹配样例,红色的方框即为标注的图表位置的可视化结果。
图3

4.2 实验结果
将537篇文献依次输入程序并进行图表标注。首先得到2 474对文献渲染页-图表匹配关系,然后程序对这些匹配依次尝试进行图表位置标注。
每个标注结果,人工校验将检验两个部分结果:
(1)校验渲染页-图表对应关系是否正确;
(2)对应关系正确的情况下,是否定位图表的正确位置。图表位置定位正确的标准是方框完整地包围了图表的全部内容(不包括图注、表注),并且不会覆盖其他内容。
在实验得到的2 474对文献渲染页-图表匹配标注结果中,程序给出2 221个图表定位结果,其他253对匹配未能计算出图表的位置。经过人工检验,在未能得到图表位置的结果中,有179对是渲染页-图表对应关系错误,另外74对的对应关系正确,但是算法未能找到足够多的匹配特征点。在算法输出定位结果中,有2 196个结果经过人工检验为正确定位,16个结果定位错误,9个渲染页-图表匹配关系错误。
因为实验结果涉及到实验的两个步骤,下面将结果和3.5节的步骤(3)与步骤(4)进行对应。对于步骤(3),在2 474对文献渲染页-图表匹配结果中,2 286对(2196+16+74)匹配结果正确,即共有2 286个待标记的图表。对于步骤(4),程序给出2 221个预测定位结果,2 196个最终定位结果正确,该步骤的精确率为98.87%。
总体来看,数据集中一共存在2 286个需要标记的图表,因此标记的召回率为96.06%,标记精确率已在步骤(4)的结果中计算,故F1值为97.44%,标注实验的结果如表1所示。
4.3 错误结果分析
笔者对于两个阶段的错误结果进行检查分析,第一阶段错误主要是因为PDF文件解析时程序按行进行文字内容输出,当某一行的第一个词为正文中提到某图表时,便会被误认为题注或者标注,造成文献页面和模板对应的错误。需要指出的是,这种错误匹配结果只会增加少量的错误渲染页-图表对应关系,并不会丢失正确的对应关系,最终得到的标注数据集不会因为此错误在数据集数量上有所损失。
图4
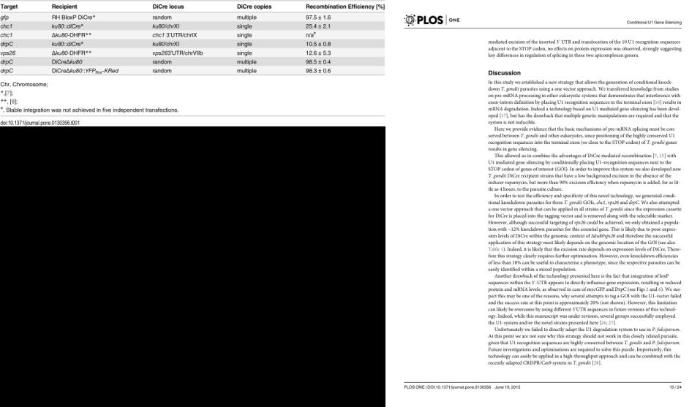
图4
模板与文献页对应关系错误
Fig. 4
An Example of Error in Correspondence Between Template and Paper Page
图5
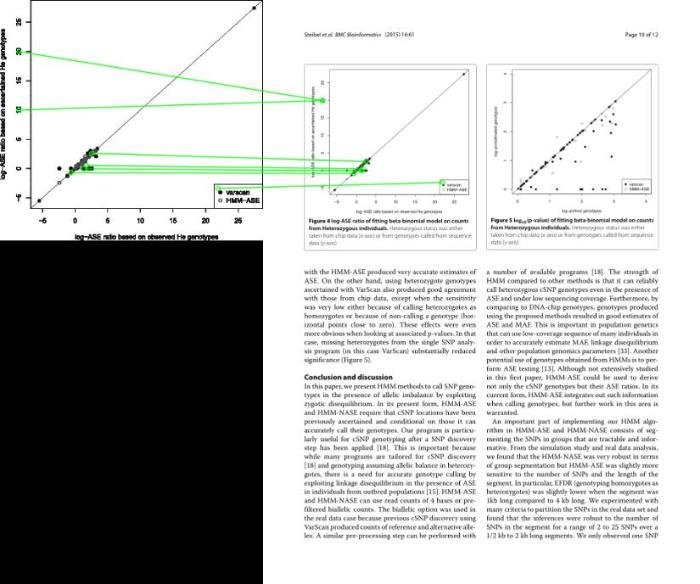
图5
图片角特征过少导致匹配错误
Fig. 5
An Example of Matching Error Caused by Lack of Corner Features
4.4 结果评价
在4.2节的实验结果的步骤(3)中存在179对渲染页-图表错误的对应关系,这些错误的对应关系造成少量图表的重复标注,实际上这些错误不会改变标记的图表数量。基于以上原因,在计算本方法的总体性能时排除了这部分错误。
经过实验证明,本文方法有较高的精确率和召回率,能够较好地自动标注学术文献中的图表位置,只需要经过相对少量的人工检验即能完成图表位置标注工作,节省了人工标注的时间和人力成本。但也需要指出本算法存在一定的数目的渲染页-图表匹配错误的情况,将会增加自动标注的耗时和人工检验的成本。
5 结语
为了对学术文献图表位置进行标注,本文提出一种尺寸自适应的模板匹配算法,利用该算法在PubMed数据上进行机器标注和简单人工校验后,能够为基于深度学习的文献结构理解研究提供海量的训练数据。经实验验证,本文算法具有较高的精确率和召回率,有助于提高标注效率,节省标注的人力成本。但是本算法也存在一定的缺陷,特别是模板与文献匹配的算法较为简单,导致了少许错误,增加了一定的人工校验成本,将在后续研究中进行改进。
作者贡献声明
于丰畅:提出研究思路,进行实验,数据分析,论文起草;
陆伟:论文框架设计,论文最终版本修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据:
支撑数据由作者自存储,E-mail: yufc2002@whu.edu.cn。
[1] 于丰畅. 结果数据.xlsx. 实验结果人工检验统计.
参考文献
文内视觉资源的分析框架与计量探索
[J].
Integrated Framework and Visual Knowledgometrics Exploration for Analyzing Visual Resources in Academic Literature
[J].
Scholarly Publishing in 2016: A Look Back at Global and National Trends in Research Publication
[R/OL]. [
数据新闻中信息图表的阅读效果:来自眼动的证据
[J].
Research on Reading Effect of the Information Chart in the Data News: Evidence from the Eye Movement
[J].
Solo Versus Collaborative Writing: Discrepancies in the Use of Tables and Graphs in Academic Articles
[J].
DOI:10.1002/asi.23014
URL
[本文引用: 1]

The number of authors collaborating to write scientific articles has been increasing steadily, and with this collaboration, other factors have also changed, such as the length of articles and the number of citations. However, little is known about potential discrepancies in the use of tables and graphs between single and collaborating authors. In this article, we ask whether multiauthor articles contain more tables and graphs than single-author articles, and we studied 5,180 recent articles published in six science and social sciences journals. We found that pairs and multiple authors used significantly more tables and graphs than single authors. Such findings indicate that there is a greater emphasis on the role of tables and graphs in collaborative writing, and we discuss some of the possible causes and implications of these findings.
Viziometrics: Analyzing Visual Information in the Scientific Literature
[J].DOI:10.1109/TBDATA.2017.2689038 URL [本文引用: 1]
Image Retrieval from Scientific Publications: Text and Image Content Processing to Separate Multipanel Figures
[J].DOI:10.1002/asi.2013.64.issue-5 URL [本文引用: 1]
How to Textually Describe Images in Medical Academic Publications
[C]//
Recursive XY Cut Using Bounding Boxes of Connected Components
[C]//
Multiresolution Morphological Approach to Document Image Analysis
[C]//
PDFFigures 2.0: Mining Figures from Research Papers
[C]//
基于机器视觉的PDF学术文献结构识别
[J].
Structural Recognition of PDF Academic Literature Based on Computer Vision
[J].
Automatic Extraction of Figures from Scholarly Documents
[C]//
TEXUS: A Unified Framework for Extracting and Understanding Tables in PDF Documents
[J].DOI:10.1016/j.ipm.2019.01.008 URL [本文引用: 1]
Deep Residual Learning for Image Recognition
[C]//
Extracting Scientific Figures with Distantly Supervised Neural Networks
[C]//
Extracting Figures and Captions from Scientific Publications
[C]//
TAO: System for Table Detection and Extraction from PDF Documents
[C]//
Semantic Annotation of Data Processing Pipelines in Scientific Publications
[C]//
Natural Language-based Machine Learning Models for the Annotation of Clinical Radiology Reports
[J].
DOI:10.1148/radiol.2018171093
URL
PMID:29381109
[本文引用: 1]
Purpose To compare different methods for generating features from radiology reports and to develop a method to automatically identify findings in these reports. Materials and Methods In this study, 96 303 head computed tomography (CT) reports were obtained. The linguistic complexity of these reports was compared with that of alternative corpora. Head CT reports were preprocessed, and machine-analyzable features were constructed by using bag-of-words (BOW), word embedding, and Latent Dirichlet allocation-based approaches. Ultimately, 1004 head CT reports were manually labeled for findings of interest by physicians, and a subset of these were deemed critical findings. Lasso logistic regression was used to train models for physician-assigned labels on 602 of 1004 head CT reports (60%) using the constructed features, and the performance of these models was validated on a held-out 402 of 1004 reports (40%). Models were scored by area under the receiver operating characteristic curve (AUC), and aggregate AUC statistics were reported for (a) all labels, (b) critical labels, and (c) the presence of any critical finding in a report. Sensitivity, specificity, accuracy, and F1 score were reported for the best performing model's (a) predictions of all labels and (b) identification of reports containing critical findings. Results The best-performing model (BOW with unigrams, bigrams, and trigrams plus average word embeddings vector) had a held-out AUC of 0.966 for identifying the presence of any critical head CT finding and an average 0.957 AUC across all head CT findings. Sensitivity and specificity for identifying the presence of any critical finding were 92.59% (175 of 189) and 89.67% (191 of 213), respectively. Average sensitivity and specificity across all findings were 90.25% (1898 of 2103) and 91.72% (18 351 of 20 007), respectively. Simpler BOW methods achieved results competitive with those of more sophisticated approaches, with an average AUC for presence of any critical finding of 0.951 for unigram BOW versus 0.966 for the best-performing model. The Yule I of the head CT corpus was 34, markedly lower than that of the Reuters corpus (at 103) or I2B2 discharge summaries (at 271), indicating lower linguistic complexity. Conclusion Automated methods can be used to identify findings in radiology reports. The success of this approach benefits from the standardized language of these reports. With this method, a large labeled corpus can be generated for applications such as deep learning. ((c)) RSNA, 2018 Online supplemental material is available for this article.
Learning to Segment via Cut-And-Paste
[C]//
For 481 Biomedical Open Access Journals, Articles are Not Searchable in the Directory of Open Access Journals Nor in Conventional Biomedical Databases
[J].DOI:10.7717/peerj.972 URL [本文引用: 1]
Template Matching Using Fast Normalized Cross Correlation
[C]//
Distinctive Image Features from Scale-Invariant Keypoints
[J].
DOI:10.1023/B:VISI.0000029664.99615.94
URL
[本文引用: 1]
This paper presents a method for extracting distinctive invariant features from images that can be used to perform reliable matching between different views of an object or scene. The features are invariant to image scale and rotation, and are shown to provide robust matching across a substantial range of affine distortion, change in 3D viewpoint, addition of noise, and change in illumination. The features are highly distinctive, in the sense that a single feature can be correctly matched with high probability against a large database of features from many images. This paper also describes an approach to using these features for object recognition. The recognition proceeds by matching individual features to a database of features from known objects using a fast nearest-neighbor algorithm, followed by a Hough transform to identify clusters belonging to a single object, and finally performing verification through least-squares solution for consistent pose parameters. This approach to recognition can robustly identify objects among clutter and occlusion while achieving near real-time performance.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}