




1 引言
梳理各省市的领导信箱工作流程发现,目前除个别城市要求群众来信时选择相应部门(这要求公众对政府部门职能极为了解),大部分是由信访部门或政府办公室承接再根据具体诉求转递至相关责任部门,这大大增加了工作人员的劳动强度,而新兴信息技术在政务领域所形成的“大数据能力”、“智能化应用”、“机器学习方法”等没有得到充分的利用。近年,在各级政府大力推进权力清单体系建设的背景下,政府职能部门之间的权责划分更为明确[3],不同事项的来信语料特点鲜明。机器学习算法具有不断更新的学习能力,可以从大量来信文本中学习特征,进而挖掘不同政府部门之间公众来信的差异性,据此实现来信的自动分类和转递,这将大大提高政府工作效率,提升公众参与的用户体验。
鉴于此,本文致力于研究政府网站中领导信箱的来信自动转递方法。首先回顾特征匹配及自动转递相关应用、文本分类和线上政务信箱等方面的研究,通过信箱文本分类算法,探析利用机器学习算法构建领导信箱自动转递系统的可行性及实施效果,进而设计一套完整的来信自动转递流程,促进线上政民互动的高效化和智能化。
2 相关研究
解决这类问题的关键点在于准确的文本分类,为此需选择合适的特征选择方法和分类算法。考虑到传统的文本特征选择算法大多忽略不同类别的相对文档频率,Kim等[8]提出一种新的特征选择算法,将某个类中经常使用但很少出现在其他类中的词语赋予更高的权重。Ghareb等[9]提出三种改进的特征选择方法,将其应用于朴素贝叶斯文本分类和关联分析中,并取得了不错的效果。这些方法对政务信箱的文本特征选择有一定的启发作用。常见的文本分类算法包括:朴素贝叶斯、最近邻算法、支持向量机和决策树等单一分类算法;AdaBoost、随机森林等集成算法。已有学者使用多种分类算法进行对比研究,如Hartmann等[10]将5种基于词汇和5种机器学习算法用于社交媒体文本数据分类,发现机器学习算法要优于基于词汇的方法,而且随机森林和朴素贝叶斯要优于支持向量机。此外,随着深度学习的发展,神经网络也越来越多地被用于中文文本分类。田欢等[11]通过选择合适的激活函数、设置最优的参数初始值并引入动量因子构造改进的BP神经网络文本分类器,较好实现了学术活动文本的分类。对于分类效果的衡量方式大致分为两种:一是算法研究类,通常选择基本算法作为对比基准,优化后的算法在准确率上要高于基本算法;二是偏重于算法的对比应用,通常选择多种算法在某一特定领域进行应用,并比较优劣。
3 研究设计
3.1 研究框架
研究政府网站领导信箱的来信如何基于文本分类进行自动转递,进而设计相应的转递方法,关键在于信箱文本自动分类的效果是否足够好。因此,本文的实验聚焦于信箱文本的部门分类,采集若干城市的市长信箱文本数据进行清洗和预处理,利用多种机器学习算法实现信箱文本的自动分类,然后对比分析不同算法的分类结果,进而找出最适用于政府网站领导信箱部门自动转递的算法,设计政府网站领导信箱的自动转递流程,并针对实验结果进行总结与讨论,提出应对实际应用中可能出现的复杂情况的建议。
3.2 算法选择
(1) 特征选择及文本表示方法
常见的文本特征选择算法包括词频、文档频率、词频逆文档频率、信息增益、卡方统计和互信息等。几种方法各有优劣,由于卡方统计考察了词语与类别之间的相关度,且在文本特征选择中有不俗的表现[16],因此本文使用卡方统计量进行特征选择。
(2) 分类算法
4 实验及结果分析
4.1 实验数据
为验证基于文本分类设计领导信箱部门自动转递方法的可行性和有效性,需要对领导信箱的来信进行文本分类。以直辖市和省会城市为例,选择其中公开来信量较大且语料字段完整(包括来信内容、回复内容以及回复部门)的城市,最终选定北京市、合肥市以及深圳市作为分析对象。使用Python编写爬虫工具分别获取三个城市原始语料26 277条(截至回复时间2018年12月29日)、104 460条(截至回复时间2019年1月10日)、51 540条(截至回复时间2018年10月31日),剔除无效数据后选择信件数多于100条的部门,数据集情况如表1所示。
4.2 实验过程
实验整体分为数据预处理、特征表示、使用训练集训练分类器以及使用测试集测试分类器效果4个步骤,如图1所示。
图1
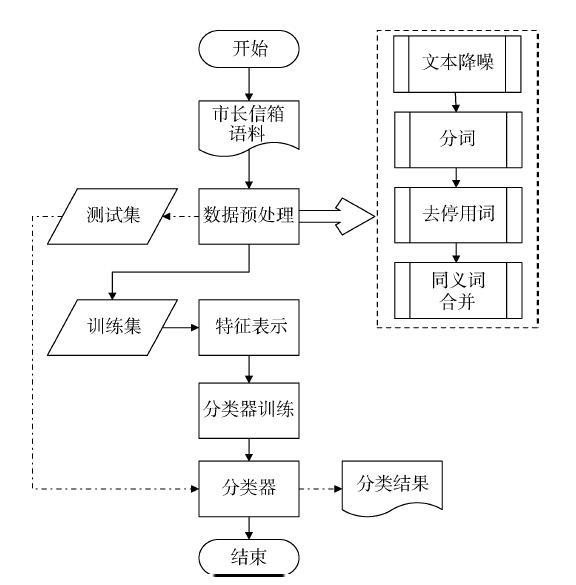
实验预处理及分类算法均通过Python(3.6.6版)编程实现,使用的IDE为PyCharm Community Edition 2019.1.3 ×64,数据预处理主要使用re和jieba开源模块,分类算法使用scikit-learn开源模块实现。
首先对所有语料进行文本预处理。预处理过程包括文本降噪、使用结巴分词进行中文分词、去停用词以及同义词合并。停用词表来源于互联网,是由多个中文停用词表整理并去重后得到,包含1 598个词语。同义词表取自哈尔滨工业大学信息检索研究室同义词词林扩展版 (《同义词词林》由梅家驹等于1983年编纂而成,哈尔滨工业大学信息检索实验室基于该词林进行扩展,完成了《同义词词林(扩展版)》。)。文本降噪主要是除去信箱文本中特有的无意义格式段落,如“尊敬的市长,您好”等。在特征选择方面,选用的算法为卡方检验,选取卡方统计量前40%的词语作为特征词;在文本表示方面,采用向量空间模型,其中向量空间中的权重使用词频表示。最后在朴素贝叶斯、决策树、随机森林以及多层神经网络4种机器学习算法上进行分类实验和参数调优。
4.3 实验结果及分析
将三个城市每个部门的语料按照8:2的常规比例划分为训练集和测试集,分别在朴素贝叶斯(NB)、决策树(DT)、随机森林(RF)以及多层神经网络(MLP)4种机器学习分类算法上进行分类实验。
(1) 分类效果评价指标
由于三市的市长信箱中各部门数据量不均衡,分类算法会倾向于将数据量较小的类识别为数据量较大的类,因此采用准确率(Accuracy)进行分类效果的衡量可能会有失偏颇。本文采用精确度(Precision)、召回率(Recall)和调和平均值F1作为衡量分类效果的指标,计算方法如公式(1)-公式(3)所示,并分别计算各指标的宏平均值和微平均值。虽然理论上精确度与召回率都是越高越好,但两者在某些情况下存在矛盾。因此需要引入两者的调和平均值进行综合判断,只有精确度和召回率都较大才能保证F1值较高。指标的宏平均值是类的算术平均值,微平均值是数据集中实例的算数平均值。
其中,
此外,将ROC曲线下面积(Area Under Curve,AUC)也作为衡量分类效果的指标之一。ROC曲线的横轴表示负正类率(False Positive Rate,FPR),计算如公式(4)所示。FPR越大,预测正类中实际负类越多;纵轴表示真正类率(True Positive Rate,TPR),其计算公式同召回率,TPR越大,预测正类中实际正类越多。
理想目标是达到TPR=1,FPR=0,即ROC曲线越靠拢图中(0,1)点,越偏离45度对角线越好。AUC可以直观评价分类器的分类效果,在0~1取值范围内,AUC值越大越好。
(2) 总体分类结果分析
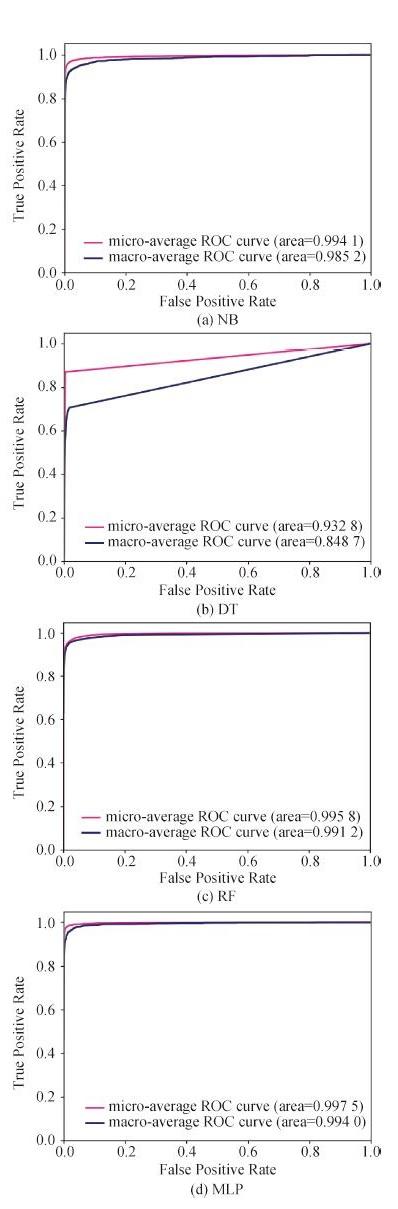
实验结果如表2所示。图2是以深圳市为例4种算法的ROC曲线(北京市和合肥市4种算法的ROC曲线和深圳市类似,不再列出)。可以看出,多层神经网络算法在市长信箱文本的分类表现要优于传统机器学习算法,精确度和召回率的宏平均指标都能达到0.85以上,且所有微平均指标均达0.93以上,分类的ROC曲线也是最优的,AUC值均超过0.99;朴素贝叶斯算法在传统机器学习算法中表现最优,所有指标可达到0.80以上;随机森林算法的宏平均精确度很高,但召回率较差;决策树算法的精确度和召回率都比较一般。同时,从表2可以明显看出微平均指标普遍要高于宏平均指标,说明在各部门样本不均衡的情况下,样本量较小的部门分类效果要差于样本量较大的部门。
表2 分类效果指标数值
Table 2
| 算法 | 分类效果指标 | 宏平均 | 微平均 | ||||
|---|---|---|---|---|---|---|---|
| 北京 | 合肥 | 深圳 | 北京 | 合肥 | 深圳 | ||
| NB | Precision | 0.9085 | 0.8762 | 0.8470 | 0.9514 | 0.8985 | 0.9228 |
| Recall | 0.9048 | 0.8368 | 0.8260 | 0.9514 | 0.8985 | 0.9228 | |
| F1值 | 0.9035 | 0.8527 | 0.8323 | 0.9514 | 0.8985 | 0.9228 | |
| AUC | 0.9952 | 0.9890 | 0.9852 | 0.9967 | 0.9946 | 0.9941 | |
| DT | Precision | 0.8227 | 0.7222 | 0.7383 | 0.9052 | 0.8386 | 0.8697 |
| Recall | 0.8037 | 0.7045 | 0.7017 | 0.9052 | 0.8386 | 0.8697 | |
| F1值 | 0.8103 | 0.7112 | 0.7163 | 0.9052 | 0.8386 | 0.8697 | |
| AUC | 0.8985 | 0.8490 | 0.8487 | 0.9494 | 0.9162 | 0.9328 | |
| RF | Precision | 0.9621 | 0.9484 | 0.9204 | 0.9393 | 0.8590 | 0.9104 |
| Recall | 0.7844 | 0.5880 | 0.6755 | 0.9393 | 0.8590 | 0.9104 | |
| F1值 | 0.8396 | 0.6659 | 0.7463 | 0.9393 | 0.8590 | 0.9104 | |
| AUC | 0.9975 | 0.9886 | 0.9912 | 0.9969 | 0.9918 | 0.9958 | |
| MLP | Precision | 0.9367 | 0.9133 | 0.8828 | 0.9650 | 0.9347 | 0.9440 |
| Recall | 0.9184 | 0.8893 | 0.8574 | 0.9650 | 0.9347 | 0.9440 | |
| F1值 | 0.9256 | 0.8999 | 0.8679 | 0.9650 | 0.9347 | 0.9440 | |
| AUC | 0.9990 | 0.9950 | 0.9940 | 0.9995 | 0.9970 | 0.9975 | |
图2
(3) 部门分类结果分析——以北京市为例
考虑到每个政府部门间的独立性,以总体分类指标衡量所有部门的分类效果是欠妥当的,因此需要对单个部门的分类效果进行评价。同时,对所有部门的分类效果进行逐一评价也有利于发现导致不同部门分类效果差异的原因,助力领导信箱自动转递系统的建设。
北京市的部门相对较少,便于比较说明,因此以北京市为例,对各部门的分类效果进行分析。北京市长信箱文本在4种算法上的部门分类结果如图3所示。
图3
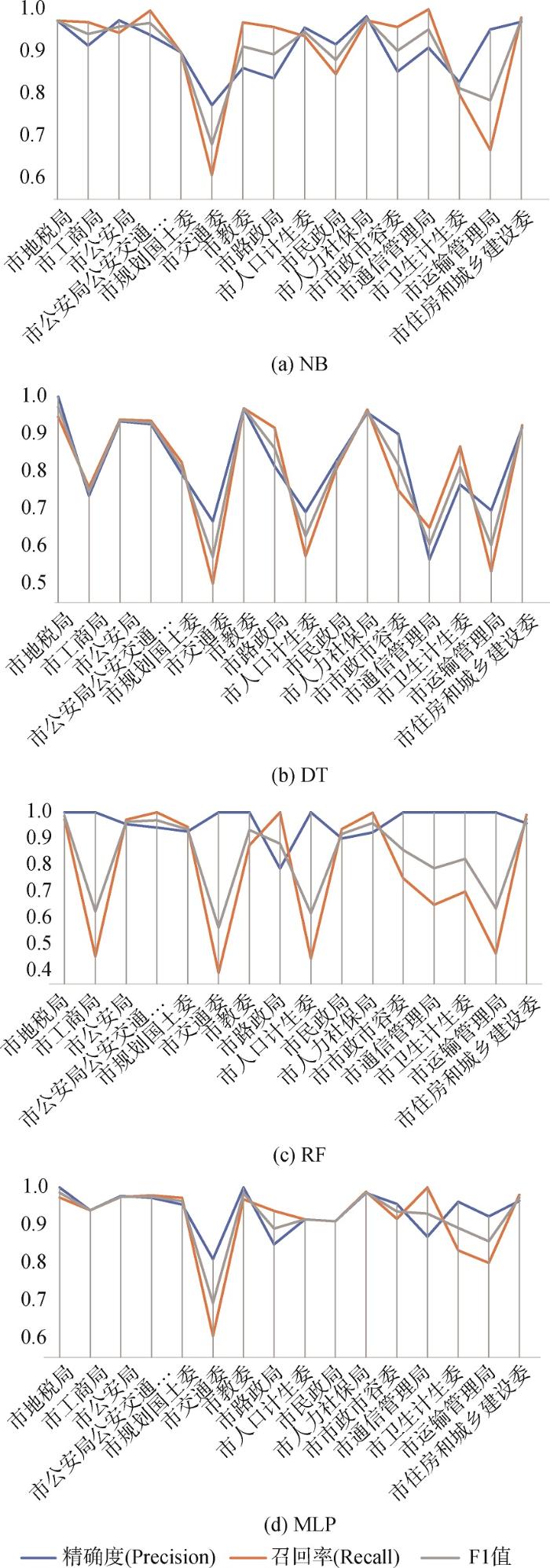
可以看出,市交通委的分类效果相对较差。进一步分析混淆矩阵发现,4种算法都最易将市交通委的信件误分为市路政局信件,这说明交通委与路政局的职责范围有所重叠(经查,北京市路政局原属交通委,后撤销)。因此,清晰明确的职权范围是领导信箱自动分类转递效果良好的重要前提条件。
此外,分类所用数据类别不均衡,信件的数量可能对分类效果产生影响。对部门样本数与分类效果最好的多层神经网络算法分类结果指标进行相关性分析,结果如表3所示。
样本数与分类结果的F1值在0.1的显著性水平上有相关性,这与此前对宏平均、微平均结果差异性的分析一致,说明提高样本数量确实有利于提升分类准确度。
表3 部门样本数与分类结果指标相关性分析
Table 3
| 样本数 | Precision | Recall | F1值 | |
|---|---|---|---|---|
| 样本数 | 1.000 0 | 0.417 1 | 0.379 3 | 0.430 7* |
| Precision | 1.000 0 | 0.601 0** | 0.819 7*** | |
| Recall | 1.000 0 | 0.950 1*** | ||
| F1值 | 1.000 0 |
(注:***表示P<0.01(双尾);**表示P<0.05(双尾);*表示P<0.1(双尾)。)
5 政府网站信箱自动转递方法
传统的领导信箱来信转递需要专职工作人员,当有大量来信时工作人员负担较重,且人工转递需要一定的时间。考虑到政府各职能部门间权责划分明确,不同事项的来信语料特点鲜明,因此对各部门历史来信的语料进行学习,识别部门来信特点,进而实现自动分类转递具有理论上的可行性。对三市的市长信箱文本进行分类实验后发现,利用多层神经网络算法对政府网站领导信箱文本进行部门分类具有较高的准确率,因此对政府网站领导信箱的来信进行部门自动转递在实践层面也具有可行性。
5.1 自动转递流程设计
本文对政府网站领导信箱部门间的转递流程进行自动化设计,当有群众来信时,算法可识别出信件的责任部门并自动转递,而信箱的管理人员只需处理少量的误分信件(根据实验结果,误分率低于0.1),从而减轻工作人员的工作量,如图4所示。
图4
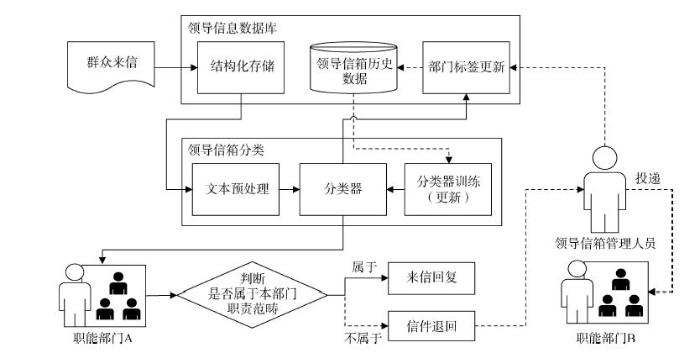
图4
政府网站信箱部门间自动转递流程
Fig.4
Automatic Transfer Process of the Mailbox on Government Website
首先对领导信箱中的历史数据按照部门归类,进而训练得到一个基础分类器。当有新的群众来信时,将来信文本结构化存储在数据库中并进行文本预处理,然后使用训练得到的分类器进行部门识别,根据分类结果转递至相应的职能部门A,同时在数据库中储存来信的部门标签。部门A收到来信后进行判断,如果属于本部门的职责范围则直接进行回复;如果不属于本部门的职责范畴,则选择退回信件,领导信箱的管理人员对该信件进行人工判断后转投至相应的职能部门B,同时更新该信件的部门标签并加入训练集,对分类器进行更新,并不断迭代。
来信的自动转递方法省去了人工转递的时间差且节约了人力成本。除此之外,在对领导信箱的群众来信进行分类前需要将其在数据库中进行结构化存储,这也为进一步分析群众来信的内容积累数据资源,便于从更大时空上掌握民情民意。
5.2 自动转递方法应用建议
由于政府的职能部门众多,自动转递方法在实际应用中情况较为复杂。为提升领导信箱自动分类转递的效果,结合实验分析,给出以下建议:
(1)对于历史信件数量较少的部门可结合部门职责信息构建部门分类特征词。实验发现,部门信件样本数量与分类效果间存在相关性,样本量较大的部门分类准确率也相对较高。这是由于样本量较大的部门可供算法学习的文本特征也较多。对于信件数过少的部门,可以结合部门职责信息提取特征词,丰富强化小样本特征。
(2)对于单一信件对应多部门问题可考虑设置分类概率阈值,将信件转递至多个部门。实验发现部分分类效果较差的部门是由于部门间职责存在交叉,从而增大误分率。在实际应用中还存在部分信件由多个部门进行回复的情况。因此,在应用领导信箱自动转递系统前,可对各部门职责进行梳理,厘清权责边界。此外,分类算法可输出样本属于所有类别的概率,系统可以设置阈值,当来信属于两个或多个类别的概率差值过小时,将信件转递至多个部门,从而降低误分的可能性。
6 结语
在推进国家治理体系和治理能力现代化的进程中,公众参与治理的程度和政府回应效率是相辅相成的两个重要方面。本文从政民互动的小处着眼,考虑对线上渠道进行优化,以机器学习算法代替人工,设计一套政府网站信箱的自动转递方法。对北京、合肥和深圳三个城市的市长信箱文本数据进行分类实验,得到如下结论:
(1)神经网络算法最适合对领导信箱来信进行自动分类,分类的微平均精确度和召回率均达0.9以上。较高的分类准确率证明利用机器学习算法进行来信的部门自动识别是可行的。
(2)数据量较少的部门分类准确率要低于数据量大的部门。这说明随着样本量的增大,分类准确率会提高。
(3)个别部门间信件分类准确率较低的主要原因之一是由于部门间职责存在一定的交叉重叠。
进而,研究提炼出一套针对政府网站领导信箱的自动转递方法,并在自动转递运作过程中,对来信数据循环迭代,逐步增加学习样本,以提高分类的准确性。本文还考虑了实际应用中可能出现的复杂情况并给出应用建议。此外,自动转递过程中对群众来信进行结构化存储,数据库中的文本数据可实时动态更新,也有助于政府部门利用文本识别和大数据技术对群众来信进行进一步分析与处理,为政府部门在更大时空上了解民情民意提供数据支持。
本文的不足之处在于难以兼顾不同部门来信数量的不均衡现象,且在实验时剔除了数据量过小的部门来信数据,这在实际应用中可能会存在一定偏差。未来还可以在深度和广度上进一步拓展:一是拓展研究深度,如针对信箱文本数据进行分类算法的改进,针对不同部门的文本内容改进特征提取的方法,针对小样本和来信对应多部门的问题进行细化研究;二是进行研究内容的纵向延伸,如对信箱文本进行语义理解,构建领导信箱知识图谱,并尝试建立对常见问题的自动回应功能等。
作者贡献声明
王思迪:设计研究方案,完成实验,论文撰写与修改;
胡广伟: 提出研究建议,设计研究框架,提出论文修改建议,论文最终版本修订;
杨巳煜:完善研究思路与方案;
施云:论文最终版本修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据:
支撑数据由作者自存储,E-mail: w_sidi@163.com。
[1] 王思迪. 北京市长信箱数据.xlsx. 北京市长信箱原始数据.
[2] 王思迪. 合肥市长信箱数据.xlsx. 合肥市长信箱原始数据.
[3] 王思迪. 深圳市长信箱数据.xlsx. 深圳市长信箱原始数据.
[4] 王思迪. beijing.xlsx. 北京市长信箱预处理后数据.
[5] 王思迪. hefei.xlsx. 合肥市长信箱预处理后数据.
[6] 王思迪. shenzhen.xlsx. 深圳市长信箱预处理后数据.
参考文献
网络情境下地方政府政民互动研究——基于青岛市市长信箱的大数据分析
[J].
A Study on the Interaction Between the Government and the People in the Internet-Based on the Big Data Analysis of the Mayor’s Mailbox of Qingdao
[J].
“网络问政”中的回应性——对K市领导信箱的一个探索性研究
[J].
Responsiveness in “Governing Online”—An Exploratory Study on K City’s Leader Mailbox
[J].
地方政府权力清单制度体系建设的实践与完善
[J].
Practice and Perfection of Local Governmental Administrative Power List System Construction
[J].
基于文本特征识别的电子档案自动归类系统研究
[J].
Research on Electronic Archive Automatic Classification System Based on Text Feature Recognition
[J].
基于KNN算法的文本自动分类方法研究——以学术期刊栏目自动归类为例
[J].
Research of Journals Manuscript Categorization Based on KNN Algorithm
[J].
基于文本特征提取技术的在线人职匹配研究及应用
[D].
Research and Application of Talent Job Online Matching Based on Text Feature Extraction Technology
[D].
基于机器学习的在线问诊平台智能分诊研究
[J].
Automatic Triage of Online Doctor Services Based on Machine Learning
[J].
Trigonometric Comparison Measure: A Feature Selection Method for Text Categorization
[J].
DOI:10.1016/j.datak.2011.03.009
URL
PMID:21765568
[本文引用: 1]

Identifying time periods with a burst of activities related to a topic has been an important problem in analyzing time-stamped documents. In this paper, we propose an approach to extract a hot spot of a given topic in a time-stamped document set. Topics can be basic, containing a simple list of keywords, or complex. Logical relationships such as and, or, and not are used to build complex topics from basic topics. A concept of presence measure of a topic based on fuzzy set theory is introduced to compute the amount of information related to the topic in the document set. Each interval in the time period of the document set is associated with a numeric value which we call the discrepancy score. A high discrepancy score indicates that the documents in the time interval are more focused on the topic than those outside of the time interval. A hot spot of a given topic is defined as a time interval with the highest discrepancy score. We first describe a naive implementation for extracting hot spots. We then construct an algorithm called EHE (Efficient Hot Spot Extraction) using several efficient strategies to improve performance. We also introduce the notion of a topic DAG to facilitate an efficient computation of presence measures of complex topics. The proposed approach is illustrated by several experiments on a subset of the TDT-Pilot Corpus and DBLP conference data set. The experiments show that the proposed EHE algorithm significantly outperforms the naive one, and the extracted hot spots of given topics are meaningful.
Enhanced Filter Feature Selection Methods for Arabic Text Categorization
[J].
Comparing Automated Text Classification Methods
[J].DOI:10.1016/j.ijresmar.2018.09.009 URL [本文引用: 2]
基于改进BP神经网络的学术活动文本分类
[J].
Text Categorization of Academic Activities Based on an Improved BP Neural Network
[J].
基于论文自动分类的社科类学科跨学科性研究
[J].
Identifying Interdisciplinary Social Science Research Based on Article Classification
[J].
How Responsive are Government Agencies When Contacted by Email? Findings from a Longitudinal Study in Australia and New Zealand
[J].DOI:10.1016/j.giq.2016.03.004 URL [本文引用: 1]
数字政府治理的回应性陷阱——基于东三省“地方领导留言板”的考察
[J].
The Responsive Trap of Digital Government Governance-Based on the Investigation of “Message Board of Local Leaders” in Three Northeastern Provinces
[J].
Managing Citizen-Initiated Email Contacts
[J].
DOI:10.1016/j.giq.2008.07.005
URL
[本文引用: 1]
Abstract
Citizen-initiated contacts, often with requests for services or information, complaints or opinions, occupy a great portion of citizen involvement with local governments. The ease and low cost of emails opens a new agenda for the contacts. Governments not only have to provide convenient and friendly access points on the websites to receive these voices, but also have to respond to them in a timely and responsive way. Responsiveness invites more usage and imposes more caseloads on bureaucrats and governments as well. How can a government develop and manage an efficient, timely and responsive citizen-initiated email handling system? We conduct a longitudinal in-depth case study of Taipei City Mayor's Mailbox, a successful citizen-initiated email handling system existing for over 12 years. Through the study of the development process, we find the actors, humans and non-humans, and their interplays shape the Mailbox. Several important issues are identified including an evolutionary, incremental and emergent process, citizens' dissatisfaction as an actor, continuous involvement of Mayor and Commissioners, and engaging street-level bureaucrats. The study contributes greatly to understand the evolution of E-Government which is underspecified in the E-Government literature.
中文文本分类中的特征选择算法研究
[J].比较了文档频率、信息增益、互信息、X2统计量、期望交叉熵、文本证据权以及几率比等7种常用于文本分类的特征选择算法.实验采用国家"八六三计划"中文文本语料库和Rocchio分类器对以上的特征选择算法分别进行评估,测评结果表明,几率比法的性能优于其它特征选择算法.
Study on Feature Selection Methods in Chinese Text Categorization
[J].比较了文档频率、信息增益、互信息、X2统计量、期望交叉熵、文本证据权以及几率比等7种常用于文本分类的特征选择算法.实验采用国家"八六三计划"中文文本语料库和Rocchio分类器对以上的特征选择算法分别进行评估,测评结果表明,几率比法的性能优于其它特征选择算法.
基于LDA 主题模型的短文本分类方法
[J].
DOI:10.3724/SP.J.1087.2013.01587
URL
[本文引用: 1]
针对短文本的特征稀疏性和上下文依赖性两个问题,提出一种基于隐含狄列克雷分配模型的短文本分类方法。利用模型生成的主题,一方面区分相同词的上下文,降低权重;另一方面关联不同词以减少稀疏性,增加权重。采用K近邻方法对自动抓取的网易页面标题数据进行分类,实验表明新方法在分类性能上比传统的向量空间模型和基于主题的相似性度量分别高5%和2.5%左右。
Short Text Classification Using Latent Dirichlet Allocation
[J].
DOI:10.3724/SP.J.1087.2013.01587
URL
[本文引用: 1]
针对短文本的特征稀疏性和上下文依赖性两个问题,提出一种基于隐含狄列克雷分配模型的短文本分类方法。利用模型生成的主题,一方面区分相同词的上下文,降低权重;另一方面关联不同词以减少稀疏性,增加权重。采用K近邻方法对自动抓取的网易页面标题数据进行分类,实验表明新方法在分类性能上比传统的向量空间模型和基于主题的相似性度量分别高5%和2.5%左右。
A Vector Space Model for Automatic Indexing
[J].DOI:10.1145/361219.361220 URL [本文引用: 1]
Introduction to Information Retrieval
[M].
Random Forests
[J].
DOI:10.1023/A:1010933404324
URL
[本文引用: 1]
Random forests are a combination of tree predictors such that each tree depends on the values of a random vector sampled independently and with the same distribution for all trees in the forest. The generalization error for forests converges a.s. to a limit as the number of trees in the forest becomes large. The generalization error of a forest of tree classifiers depends on the strength of the individual trees in the forest and the correlation between them. Using a random selection of features to split each node yields error rates that compare favorably to Adaboost (Y. Freund & R. Schapire, Machine Learning: Proceedings of the Thirteenth International conference, ***, 148–156), but are more robust with respect to noise. Internal estimates monitor error, strength, and correlation and these are used to show the response to increasing the number of features used in the splitting. Internal estimates are also used to measure variable importance. These ideas are also applicable to regression.
Classification and Regression Trees
[M].
Connectionist Learning Procedures
[J].DOI:10.1016/0004-3702(89)90049-0 URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}