A Multi-Task Text Classification Model Based on Label Embedding of Attention Mechanism
Xu Yuemei1(),Fan Zuwei2,3,Cao Han1
1School of Information Science and Technology, Beijing Foreign Studies University, Beijing 100089, China 2Institute of Information Engineering, Chinese Academy of Sciences, Beijing 100093, China 3School of Cyber Security, University of Chinese Academy of Sciences, Beijing 100049, China
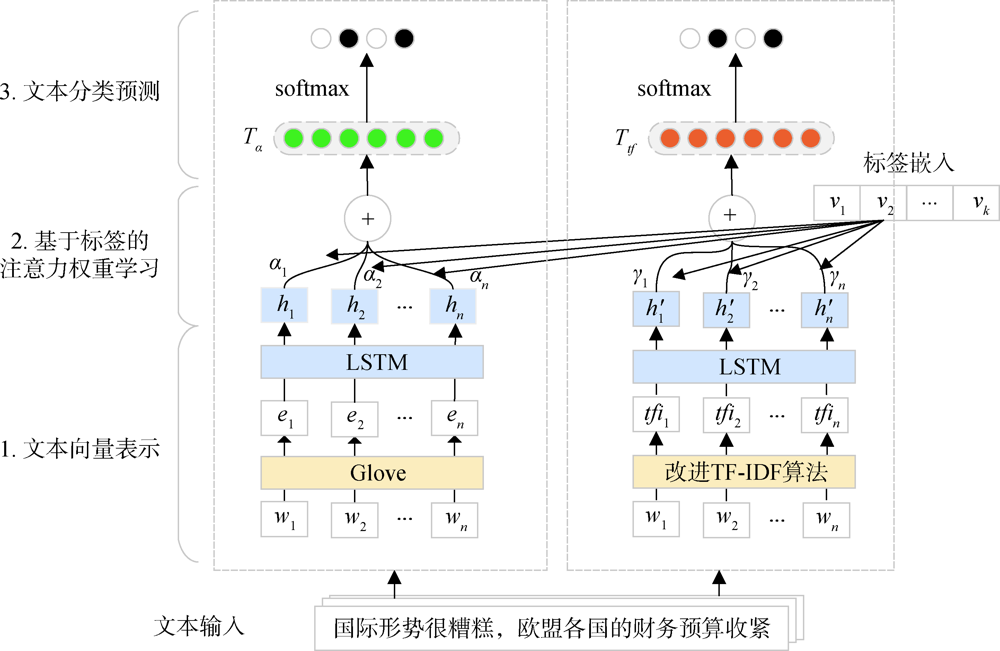
[Objective] This paper tries to adjust text classification algorithm according to task-specific features, aiming to improve the accuracy of text classification for different tasks. [Methods] We proposed a text classification algorithm based on label attention mechanism. Through label embedding learning of both word vector and the TF-IDF classification matrix, we extracted the task-specific features by assigning different weights to the words, which improves the effectiveness of the attention mechanism. [Results] The accuracy of the proposed method increased by 3.78%, 5.43%, and 11.78% in prediction compared with the existing LSTMAtt, LEAM and SelfAtt methods. [Limitations] We did not study the impacts of different vector models on the performance of text classification.[Conclusions] This paper presents an effective method to improve and optimize the multi-task text classification algorithm.
徐月梅, 樊祖薇, 曹晗. 基于标签嵌入注意力机制的多任务文本分类模型*[J]. 数据分析与知识发现, 2022, 6(2/3): 105-116.
Xu Yuemei, Fan Zuwei, Cao Han. A Multi-Task Text Classification Model Based on Label Embedding of Attention Mechanism. Data Analysis and Knowledge Discovery, 2022, 6(2/3): 105-116.
Ifrim G, Bakir G, Weikum G. Fast Logistic Regression for Text Categorization with Variable-Length n-grams[C]// Proceeding of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2008: 354-362.
[2]
Gordon A D, Breiman L, Friedman J H, et al. Classification and Regression Trees[J]. Biometrics, 1984, 40(3):874.
[3]
Burges C J C. A Tutorial on Support Vector Machines for Pattern Recognition[J]. Data Mining and Knowledge Discovery, 1998, 2(2):121-167.
doi: 10.1023/A:1009715923555
[4]
Kim S B, Han K S, Rim H C, et al. Some Effective Techniques for Naive Bayes Text Classification[J]. IEEE Transactions on Knowledge and Data Engineering, 2006, 18(11):1457-1466.
doi: 10.1109/TKDE.2006.180
[5]
Kalchbrenner N, Grefenstette E, Blunsom P. A Convolutional Neural Network for Modelling Sentences[C]// Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. 2014.
[6]
Kim Y. Convolutional Neural Networks for Sentence Classification[OL]. arXiv Preprint, arXiv: 1408.5882.
[7]
Socher R, Lin C C, Manning C. Parsing Natural Scenes and Natural Language with Recursive Neural Networks[C]// Proceedings of the 28th International Conference on Machine Learning. 2011: 129-136.
[8]
Nair V, Hinton G E. Rectified Linear Units Improve Restricted Boltzmann Machines Vinod Nair[C]// Proceedings of the 27th International Conference on Machine Learning. 2010: 807-814.
[9]
Hochreiter S, Schmidhuber J. Long Short-Term Memory[J]. Neural Computation, 1997, 9(8):1735-1780.
pmid: 9377276
[10]
Bahdanau D, Cho K, Bengio Y. Neural Machine Translation by Jointly Learning to Align and Translate[OL]. arXiv Preprint, arXiv: 1409.0473
[11]
Wang Y Q, Huang M L, Zhu X Y, et al. Attention-Based LSTM for Aspect-Level Sentiment Classification[C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016: 606-615.
[12]
Lin Z H, Feng M W, Santos C N D, et al. A Structured Self-Attentive Sentence Embedding[OL]. arXiv Preprint, arXiv:1703.03130.
[13]
Wang G, Li C, Wang W, et al. Joint Embedding of Words and Labels for Text Classification[OL]. arXiv Preprint, arXiv: 1805.04174.
[14]
Wallach H M. Topic Modeling: Beyond Bag-of-Words[C]// Proceedings of the 23rd International Conference on Machine Learning. 2006: 977-984.
[15]
Joachims T. A Probabilistic Analysis of the Rocchio Algorithm with TFIDF for Text Categorization[R]. Carnegie Mellon University, Computer Science Technical Report, CMU-CS-96-118, 1996.
[16]
Blei D M, Ng A Y, Jordan M I, et al. Latent Dirichlet Allocation[J]. Journal of Machine Learning Research, 2012, 3:993-1022.
[17]
Mikolov T, Chen K, Corrado G, et al. Efficient Estimation of Word Representations in Vector Space[OL]. arXiv Preprint, arXiv: 1301.3781.
[18]
Liu Y, Liu Z Y, Chua T S, et al. Topical Word Embeddings[C]// Proceedings of AAAI Conference on Artificial Intelligence. 2015: 2418-2424.
[19]
Peters M, Neumann M, Iyyer M, et al. Deep Contextualized Word Representations[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018.
[20]
Akata Z, Perronnin F, Harchaoui Z, et al. Label-Embedding for Image Classification[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(7):1425-1438.
doi: 10.1109/TPAMI.2015.2487986
[21]
Tang J, Qu M, Mei Q Z. PTE: Predictive Text Embedding through Large-Scale Heterogeneous Text Networks[C]// Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2015.
[22]
Zhang H L, Xiao L Q, Chen W Q, et al. Multi-Task Label Embedding for Text Classification[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 4545-4553.
[23]
Jin Z Y, Lai X, Cao J. Multi-Label Sentiment Analysis Base on BERT with Modified TF-IDF[C]// Proceedings of 2020 IEEE International Symposium on Product Compliance Engineering-Asia (ISPCE-CN). 2020: 1-6.
[24]
van der Maaten L, Hinton G. Visualizing Data Using t-SNE[J]. Journal of Machine Learning Research, 2008, 9(11):2579-2605.