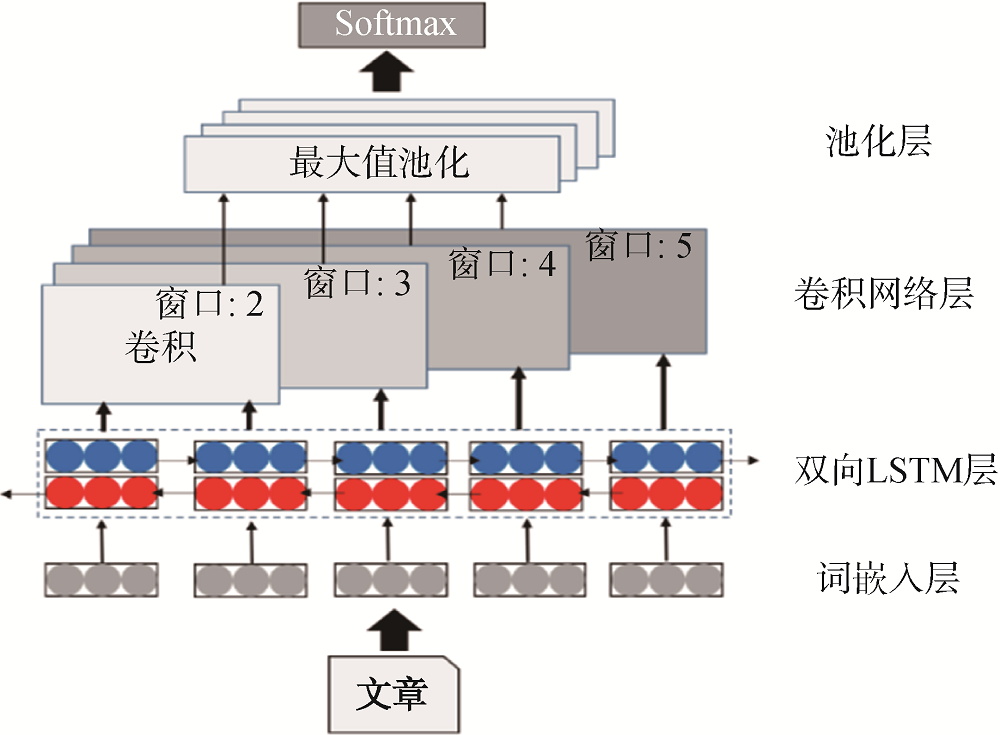
Automatically Grading Text Difficulty with Multiple Features
Yong Cheng1(),Dekuan Xu1,Xueqiang Lv2
1(School of Chinese Language and Literature, Ludong University, Yantai 264025, China) 2(School of Computer Science, Beijing University of Information Technology, Beijing 100192, China)
[Objective] This paper aims to automatically grade reading difficulty of textual documents. [Methods] We used machine learning method based on multiple features of the texts to decide their difficulty levels automatically. The features, which include word-frequency, structures, topics, and depth, describe the textual contents from different perspectives. [Results] We evaluated our method with the reading comprehension texts for high-school English exams, and achieved an accuracy of 0.88. Our result is better than those of the traditional difficulty classification methods. [Limitations] Due to the high cost of manual annotation, the existing datasets cannot be used to improve our method. [Conclusions] The proposed method increased the effectiveness of machine leanring based data analysis.
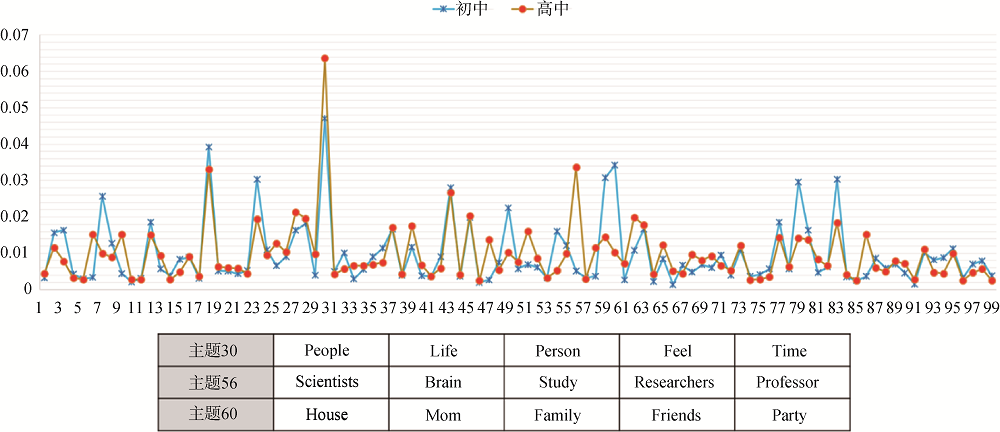
school likes happy day nice friends teacher morning eat chinese boy english mother play father lot china afternoon beautiful playing girl homework green friend lunch class tv football breakfast sports
高中
life people time university women study author researchers education college social health experience age person business human public company job american language national brain government body technology family scientists
( Li Huizong, Hu Xuegang, Yang Hengyu , et al. A Comprehensive Clustering Method for Socialized Label Based on LDA[J]. Journal of the China Society for Scientific and Technical Information, 2015,34(2):146-155.)
( Xu Tongyang, Yin Kai . Semantic Retrieval of Microblogging in the Background of Large Data[J]. Journal of Intelligence, 2017,36(12):173-179.)
[4]
Bear D, Dole J, Echevarria J , et al. Treasures, A Reading/ Language Arts Program[M]. McGraw-Hill Education, 2009.
[5]
Lester M, Neal S, Royster J , et al. Glencoe Writer’s Choice: Grammar and Composition[M]. McGraw-Hill Education, 2001.
[6]
李欣 . 美国中小学生阅读分级研究[D]. 上海: 华东师范大学, 2016.
[6]
( Li Xin . Research on the American Leveled Reading of K-12 Students[D]. Shanghai: East China Normal University, 2016.)
[7]
Kincaid J P, Braby R, Mears J E . Electronic Authoring and Delivery of Technical Information[J]. Journal of Instructional Development, 1988,11(2):8-13.
[8]
Dale E, Chall J S . A Formula for Predicting Readability[J]. Journal of Educational Research Bulletin, 1948,27(2):37-54.
[9]
McLaughlin G H . SMOG Grading: A New Readability Formula[J]. Journal of Reading, 1969,12(8):639-646.
[10]
Graesser A C , McNamara D S, Louwerse M M, et al. Coh-Metrix: Analysis of Text on Cohesion and Language[J]. Journal of Behavior Research Methods, Instruments, & Computers, 2004,36(2):193-202.
[11]
张宁志 . 汉语教材语料难度的定量分析[J]. 世界汉语教学, 2000(3):83-88.
[11]
( Zhang Ningzhi . Quantitative Analysis of Corpora Difficulty in Chinese Textbooks[J]. Chinese Teaching in the World, 2000(3):83-88.)
[12]
郭望皓 . 对外汉语文本易读性公式研究[D]. 上海: 上海交通大学, 2009.
[12]
( Guo Wanghao . Research on Readability Formula of Chinese Text for Foreign Students[D]. Shanghai: Shanghai Jiao Tong University, 2009.)
( Zuo Hong, Zhu Yong . Research on Chinese Readability Formula of Texts for Intermediate Level European and American Students[J]. Chinese Teaching in the World, 2014,28(2):263-276.)
[14]
Salton G, Buckley C . Term-Weighting Approaches in Automatic Text Retrieval[J]. Information Processing & Management, 1988,24(5):513-523.
[15]
Hofmann T . Unsupervised Learning by Probabilistic Latent Semantic Analysis[J]. Machine Learning, 2001,42(1-2):177-196.
[16]
Blei D M, Ng A Y, Jordan M I , et al. Latent Dirichlet Allocation[J]. Journal of Machine Learning Research, 2003,3:993-1022.
[17]
Walker S H, Duncan D B . Estimation of the Probability of an Event as a Function of Several Independent Variables[J]. Biometrika, 1967,54(1-2):167-179.
[18]
Cortes C, Vapnik V . Support-Vector Networks[J]. Machine Learning, 1995,20(3):273-297.
[19]
Ho T K. Random Decision Forests [C]// Proceedings of the 3rd International Conference on Document Analysis and Recognition. IEEE, 1995: 278-282.
[20]
Liu P, Qiu X, Huang X , et al. Recurrent Neural Network for Text Classification with Multi-Task Learning[C]// Proceedings of the 25th International Joint Conferences on Artificial Intelligence. AAAI Press, 2016: 2873-2879.
[21]
Kim Y. Convolutional Neural Networks for Sentence Classification [C]// Proceedings of the 2014 International Conference on Empirical Methods on Natural Language Processing. ACL, 2014: 1746-1751.
[22]
Senter R J, Smith E A . Automated Readability Index[J]. Journal of Competitor New York, 1967,1:1-14.
[23]
Gunning R . The Fog Index After Twenty Years[J]. Journal of Business Communication, 1969,6(2):3-13.
[24]
Coleman M, Liau T L . A Computer Readability Formula Designed for Machine Scoring[J]. Journal of Applied Psychology, 1975,60(2):283-284.
[25]
Graves A, Schmidhuber J . Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures[J]. Neural Networks, 2005,18(5):602-610.
[26]
Lai G, Xie Q, Liu H, et al. Race: Large-Scale Reading Comprehension Dataset from Examinations [C]// Proceedings of the 2017 International Conference on Empirical Methods on Natural Language Processing. ACL, 2017: 785-794.
[27]
TensorFlow[CP]. [2018-08-24]..
[28]
蒋晶晶 . CEPT阅读文本易读度分析及词汇检测工具的开发[D]. 长沙: 湖南大学, 2009.
[28]
( Jiang Jingjing . Readability Analysis on CEPT Reading Texts and the Development of Lexical Checker[D]. Changsha: Hunan University, 2009.)
( Chen Yanlong, Zhang Zhiming . The English Text Difficulty Measurement Based Vector Space Model[J]. Computer Knowledge and Technology, 2010,6(12):2994-2996.)
[30]
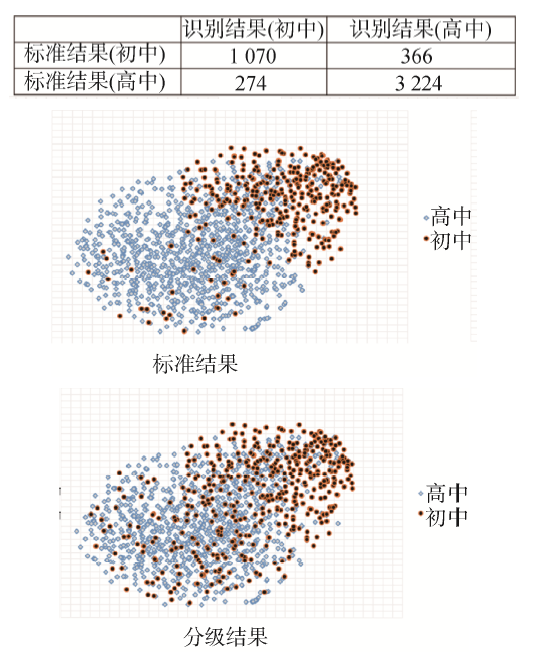
Maaten L, Hinton G . Visualizing Data Using t-SNE[J]. Journal of Machine Learning Research, 2008,9(11):2579-2605.