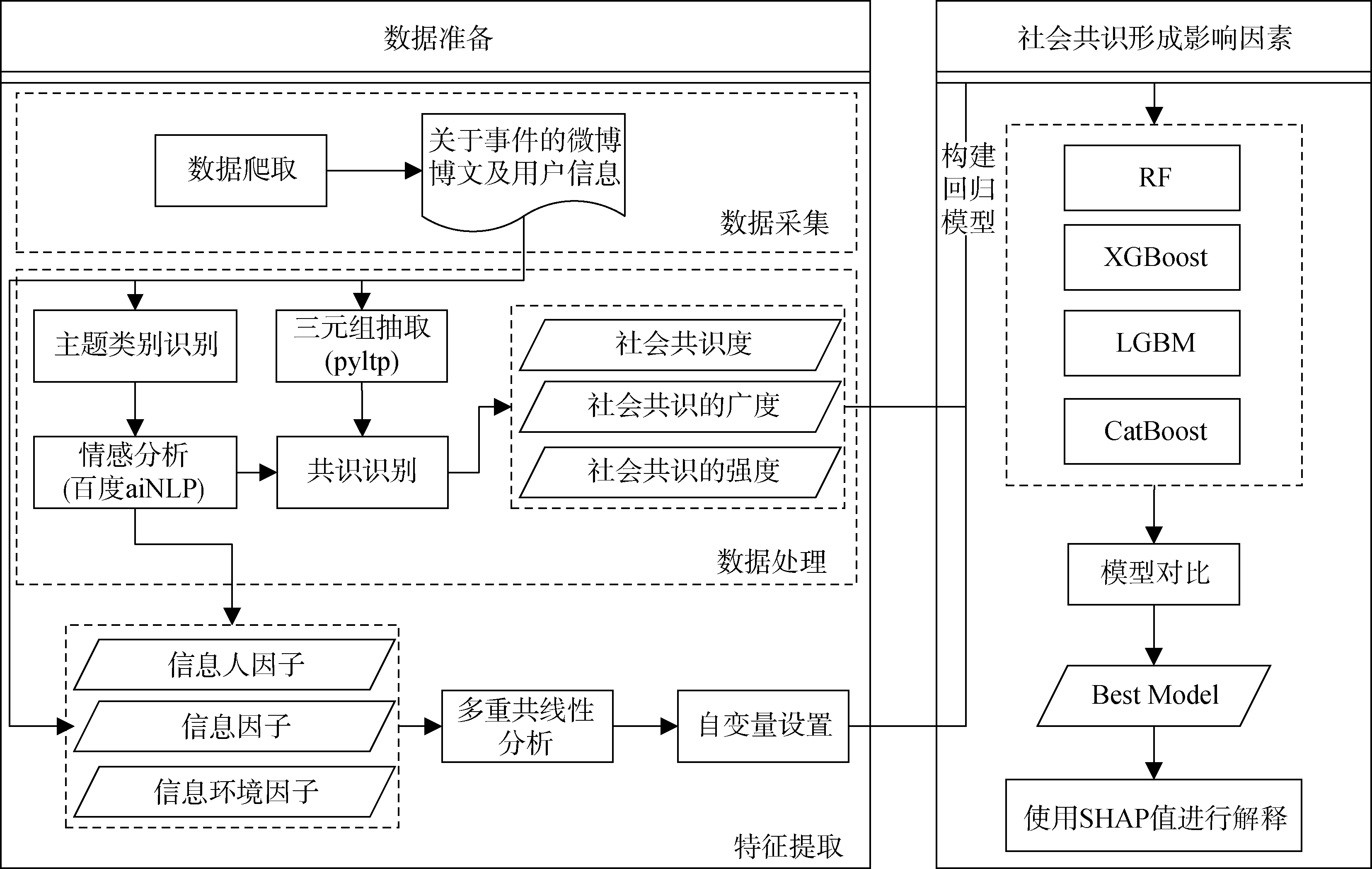
【目的】 探究突发事件情境下社会共识形成机理,提出识别和度量共识的方法,揭示影响共识形成的重要因素,为相关部门制定有效的信息传播策略、引导舆论演化提供理论与方法支撑。【方法】 以某市烧烤店事件的微博数据为数据源,结合主题模型、情感分析和三元组抽取等方法挖掘用户观点,基于观点一致性和情感一致性计算个体间共识度;采用信息生态理论,从信息人、信息、信息环境等维度构造特征变量,构建共识度预测模型;比较4个机器学习模型性能,使用SHAP对最优模型进行解释。【结果】 CatBoostRegressor模型的MSE值(1 176.955 0)和R2值(0.675 3)优于其他三个模型;特征重要性排名前五的因素中,受高等教育人群占比、年龄差距、观点坚定者占比与群体共识度呈显著负相关,社交网络结构相似度与群体共识度呈显著正相关,在不同话题上各特征变量的影响方式有所不同。【局限】 仅关注不同群体内的共识,未探究不同群体间的观点演化以及共识形成机制。【结论】 本文方法能够揭示影响社会共识形成的关键因素。
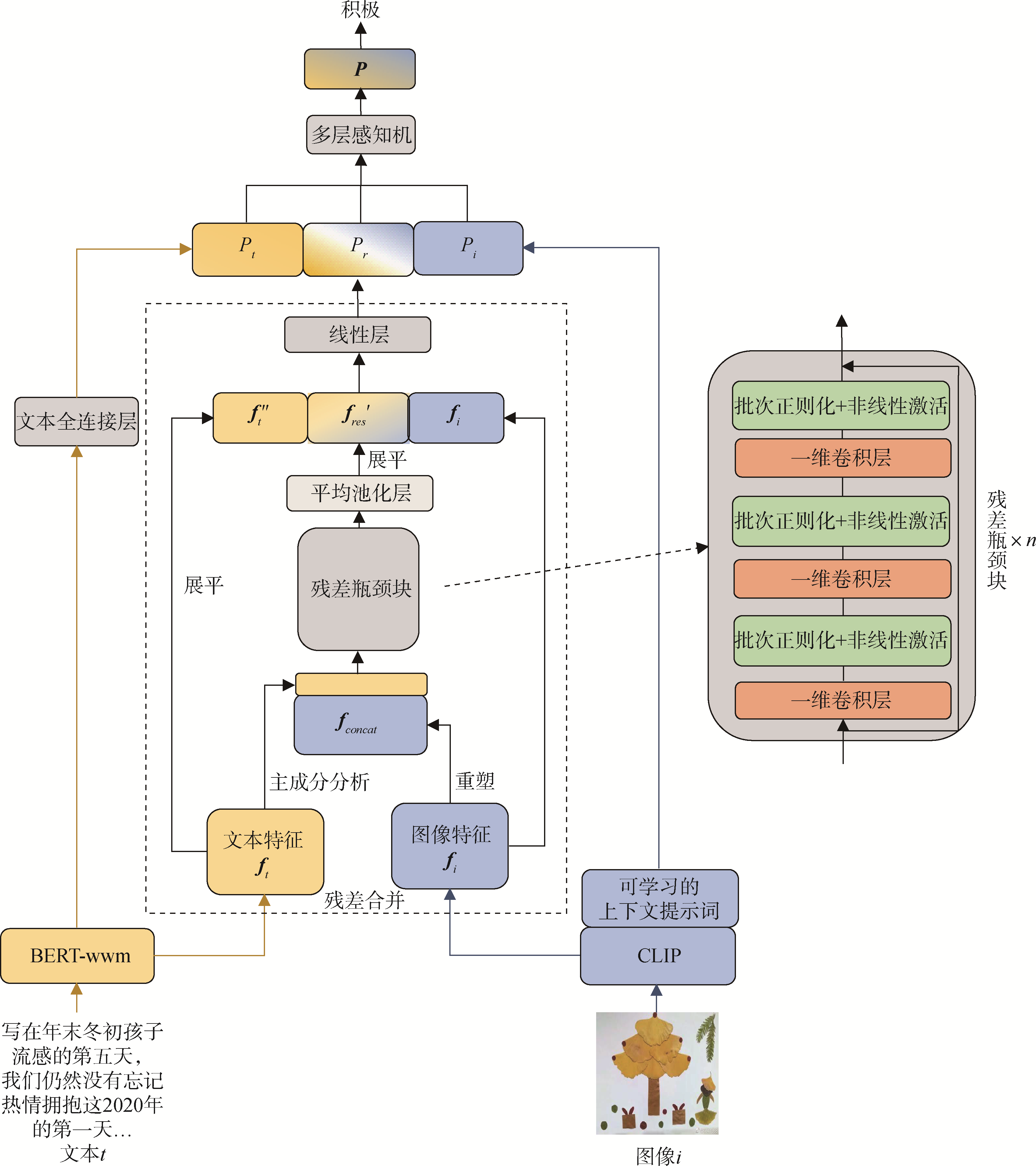
【目的】 针对当前多模态情感模型在特征融合方面存在的困难导致情感分类准确率不佳的问题,提出 RCHFN 多模态情感分类模型。【方法】 采用CLIP和Chinese-BERT-wwm模型分别提取图像和文本特征,同时进行单一模态情感分类。使用由合并残差连接与卷积构成的残差合并模块融合图像和文本特征,得到多模态情感分类结果。最终将单一模态和多模态情感分类结果传递至全连接层,通过调整动态权重获取最终的情感分类结果。【结果】 实验结果表明,RCHFN模型在微博数据集、Twitter数据集的情感三分类准确率分别达到81.25%、79.21%,F1值分别为80.43%、78.44%。与其他在同一数据集上基于相似任务的模型相比,模型的准确率分别提高了1.79、1.79个百分点,F1值分别提高了2.39、2.62个百分点。【局限】 模型对于不同数据集的泛化性以及在更多模态上的性能需要更多实验证明。【结论】 RCHFN型有效地解决了多模态言论特征难以融合以及分类准确率低的问题。
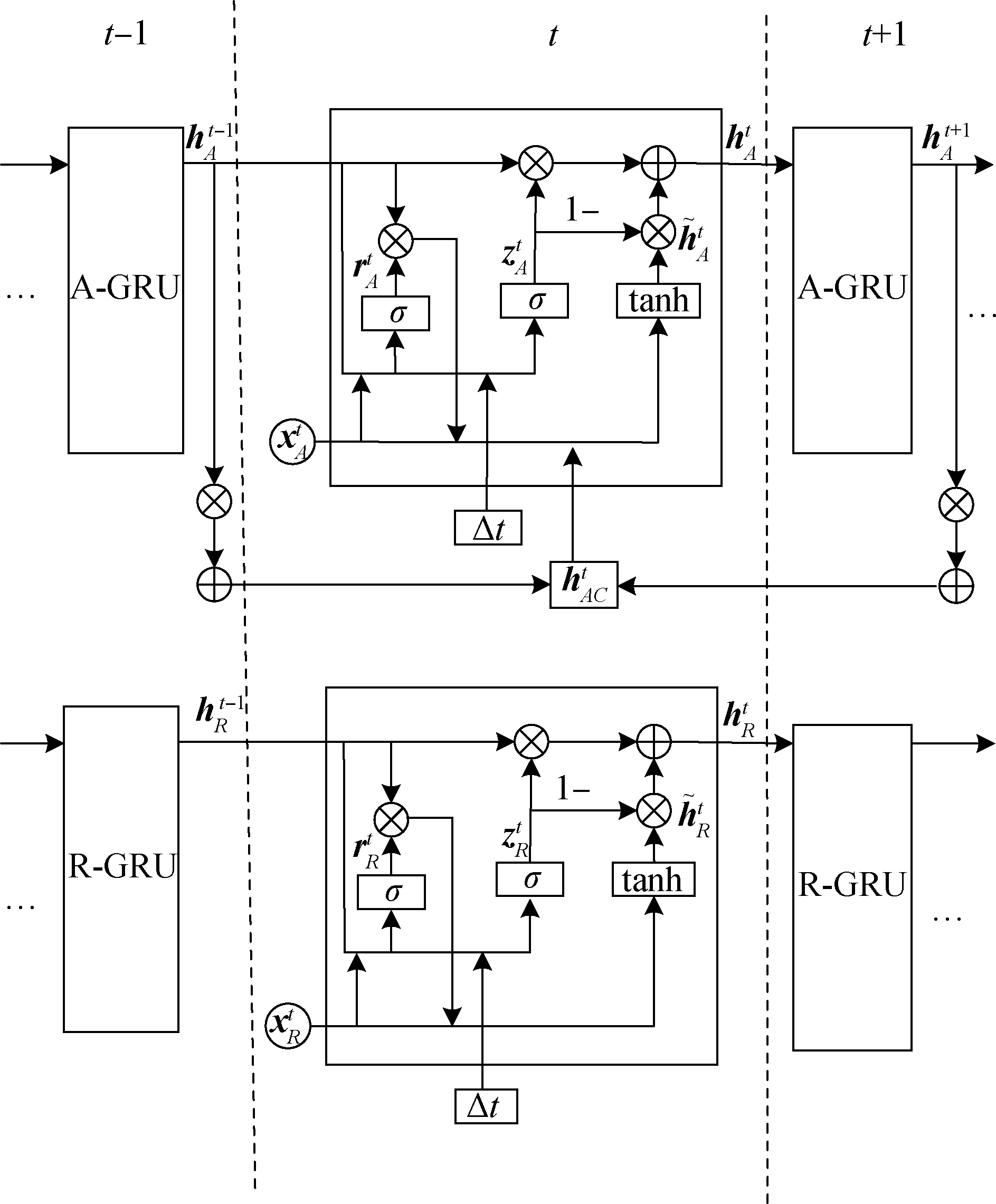
【目的】 挖掘信息中的发布序列关系,解决校园信息平台中信息热度预测问题。【方法】 提出一种新的双层GRU模型对信息热度进行预测。模型结合了时间间隔感知机制、作者声望感知机制和序列窗口感知机制,并通过一个双层的GRU网络学习得到信息的热度特征,从而进行信息热度预测。在此基础上,利用计算出的热度值排序得到最近一段时间内的热门信息。【结果】 以校园信息平台数据集为例,双层GRU模型的预测效果优于ARIMA、堆叠LSTM模型、BiLSTM-Attention模型,其中MSE(0.000 038)、RMSE(0.005 9)、MAE(0.004 3)最小,准确率(93.04%)最高。【局限】 在处理不具备明确时序特征的信息时,模型的预测效果受到一定的限制。【结论】 双层GRU模型的引入提升了信息热度预测模型的预测效果。
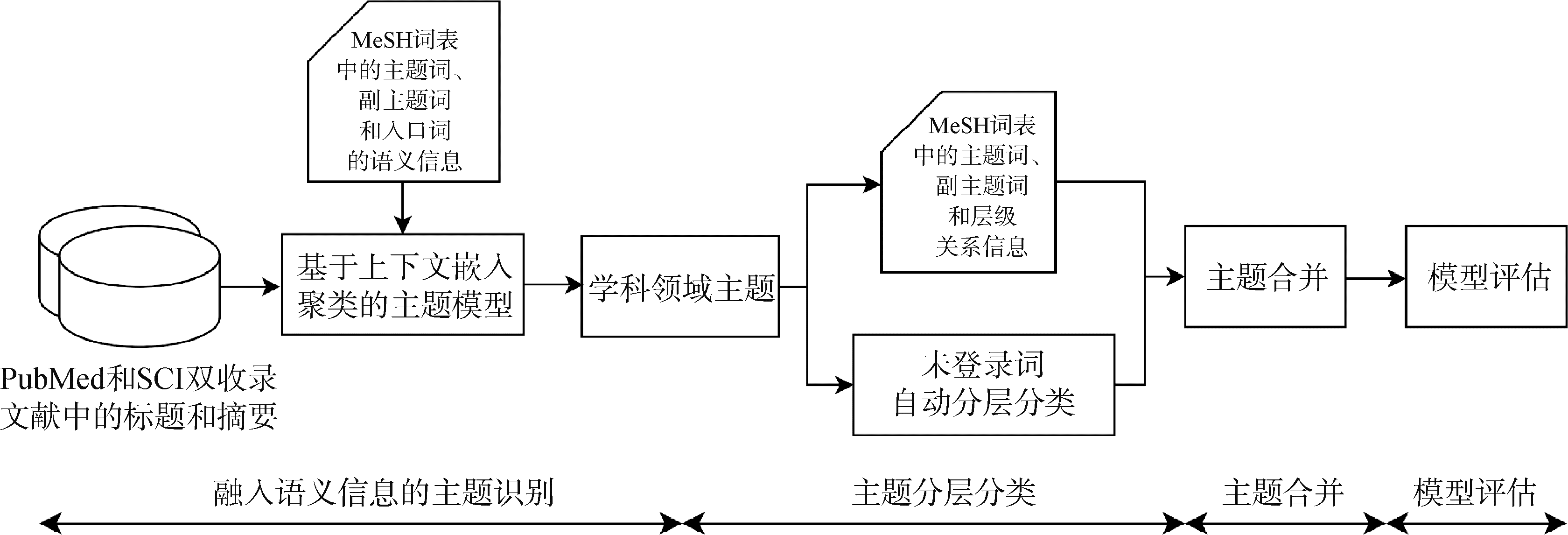
【目的】 识别某学科领域科技文献数据中蕴含的主要研究主题,并将这些主题组织形成层次结构。【方法】 将知识组织体系中的先验知识融入上下文嵌入聚类主题模型,并对知识组织体系中未登录词对应的主题进行分层分类,选择生物医学领域的数据及知识组织体系进行分析。【结果】 本文方法实现了清晰的主题分层分类,其中PubMedBERT+SK模型的综合性能最优,NPMI、Cv、WEPS和WERBO指标分别为0.069、0.617、0.988和0.989;PubMedBERT+KM模型的NPMI指标最优,NPMI、Cv、WEPS和WERBO指标分别为0.118、0.570、0.890和0.976。【局限】 医学主题词表层级结构构建的目的与主题识别分层的需求有所不同,导致对领域主题内容的理解与实际有所出入,分层效果欠佳。【结论】 提出的融合知识组织体系的层次化主题挖掘方法通过对主题分层分类,提升主题识别结果的质量。
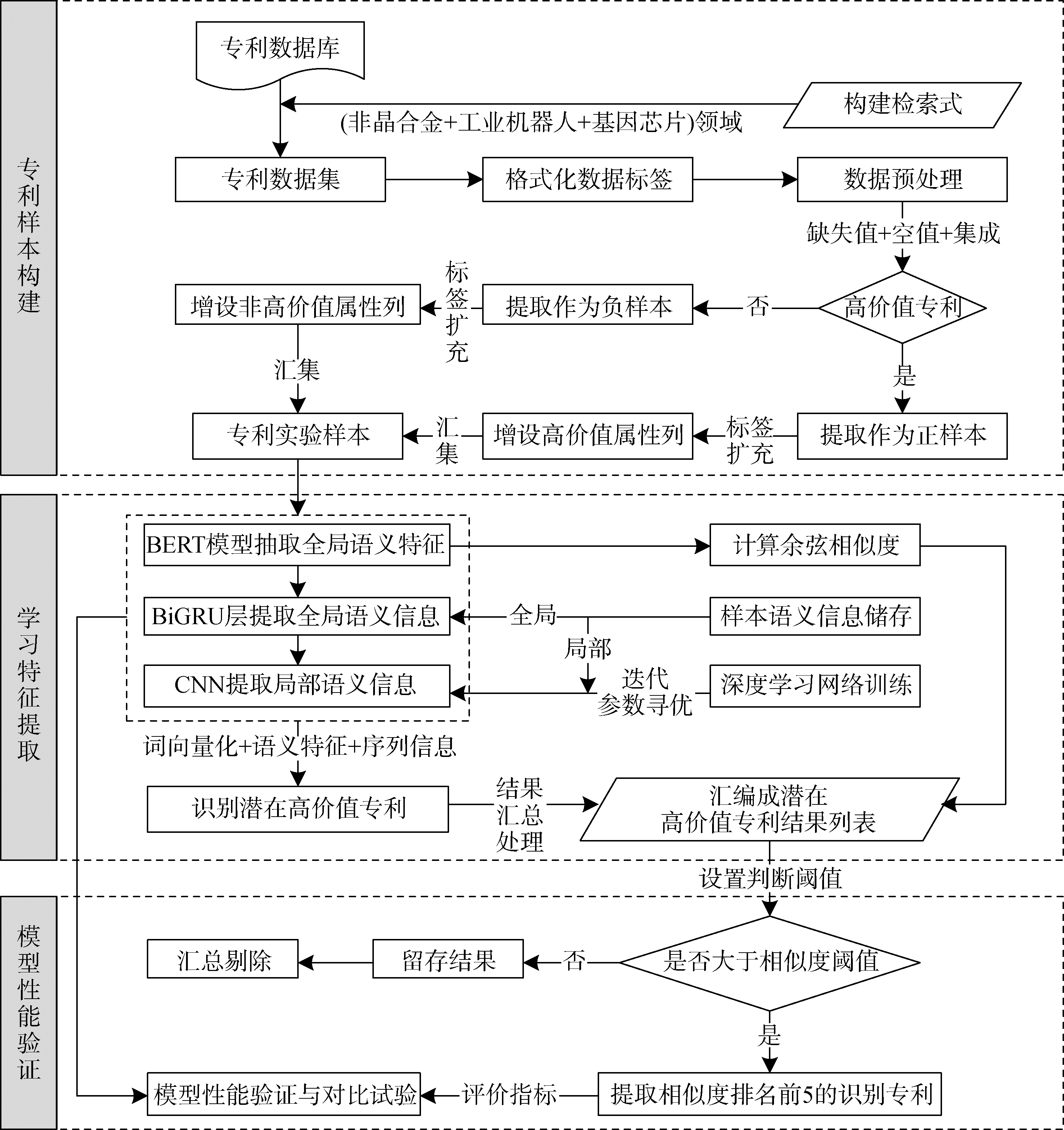
【目的】 基于双边语义和文本序列特征深度挖掘专利文本蕴含的特征信息,识别潜在高价值专利。【方法】 基于非晶合金、工业机器人以及基因芯片领域的混合专利数据集,通过BERT词向量模型实现专利文本中上下文语义的关联表达和词义解释,利用BiGRU网络获取全局文本序列信息,利用CNN获取局部文本序列信息,结合“双边语义+全局+局部”的语义和序列特征实现对潜在高价值专利的预测。【结果】 研究表明,构建的BERT-BiGRU-CNN模型性能优于既有的预测模型,更适用于大数据规模的潜在高价值专利预测;模型的预测准确率达到35%以上,较既有研究模型的准确率提升约4个百分点。【局限】 尚未考虑标准必要专利与高价值专利的关联关系和融合机制,算法复杂度有待提升。【结论】 BERT-BiGRU-CNN模型在文本分类层面的效果优于CNN等模型;BiGRU-CNN模型能够通过获取全局和局部的文本序列特征提升潜在高价值专利的预测精度。
【目的】 针对DeepWalk算法应用在电子商务网络链路预测中的不足,提出一种基于改进的DeepWalk算法的链路预测算法。【方法】 针对DeepWalk算法随机游走过程中平等对待每个节点的问题,利用电商网络的结构和属性信息对随机行走进行偏置,引导游走过程更有针对性地遍历图中不同类型的节点;传统的DeepWalk算法使用余弦相似度方法进行节点的相似度度量,该方法不能很好地表现用户和商品关系的问题,本文将巴氏(Bhattacharyya)系数引入现有的非线性相似度计算中,创建新的节点相似度方法。【结果】 改进后的DeepWalk算法在不同规模的数据中平均召回准确率提高范围在0.05~0.17;在计算节点相似性时,节点属性相似度贡献α的最优值在0.5~0.6之间。【局限】 随着时间复杂度的增长可能会导致算法可扩展性下降。【结论】 经过改进的算法能够更好地学习节点嵌入向量,以识别电商网络中的节点相似性,从而显著提升节点表示的准确性和链路预测的效果。

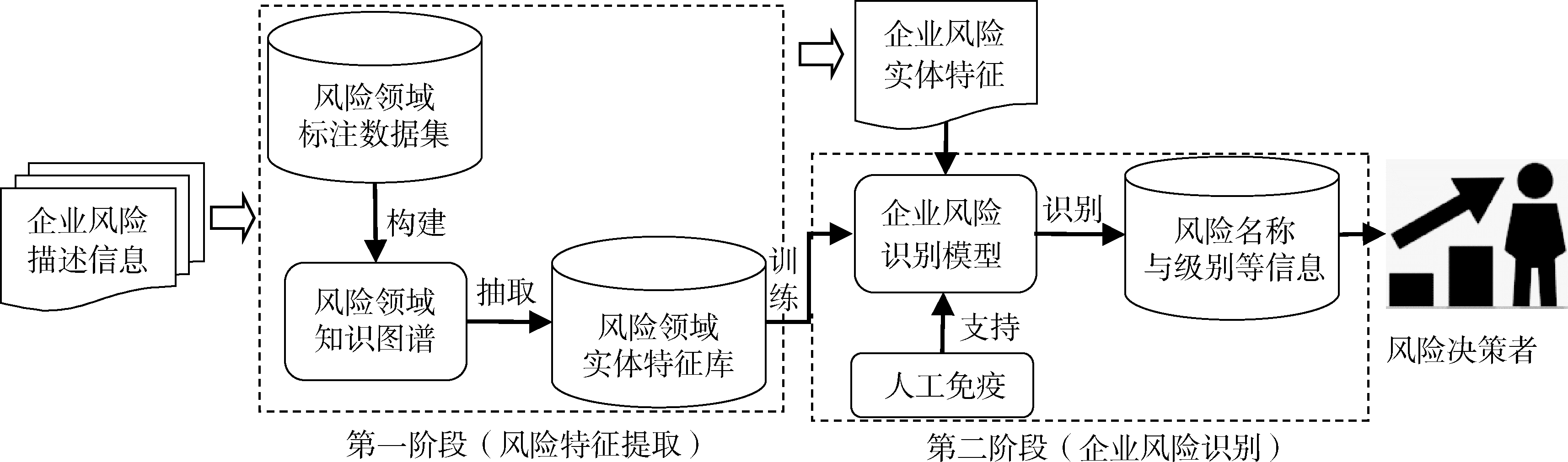
【目的】 提高企业风险识别的准确率,降低潜在风险对企业造成的损失。【方法】 提出一种融合知识图谱与人工免疫的风险识别模型。该模型利用知识抽取技术从文本信息中挖掘风险领域知识,实现企业风险领域知识图谱的构建;并通过企业风险事件描述文本信息与知识图谱中的风险实体进行实体链接,获取更强的风险特征;在此基础上,运用人工免疫方法进行企业风险识别。【结果】 模型对企业风险识别率为89%,较基于神经网络的风险识别模型的识别率提升了19%。【局限】 仅分析了企业年报中披露风险内容与企业新闻报道中的定性文本信息,未来将尝试引入多维度与更完备的定量与定性信息提高企业风险识别的准确率。【结论】 所提模型能够高效地关联企业内外部实时数据并开展企业风险分析,为企业风险预控提供重要参考。
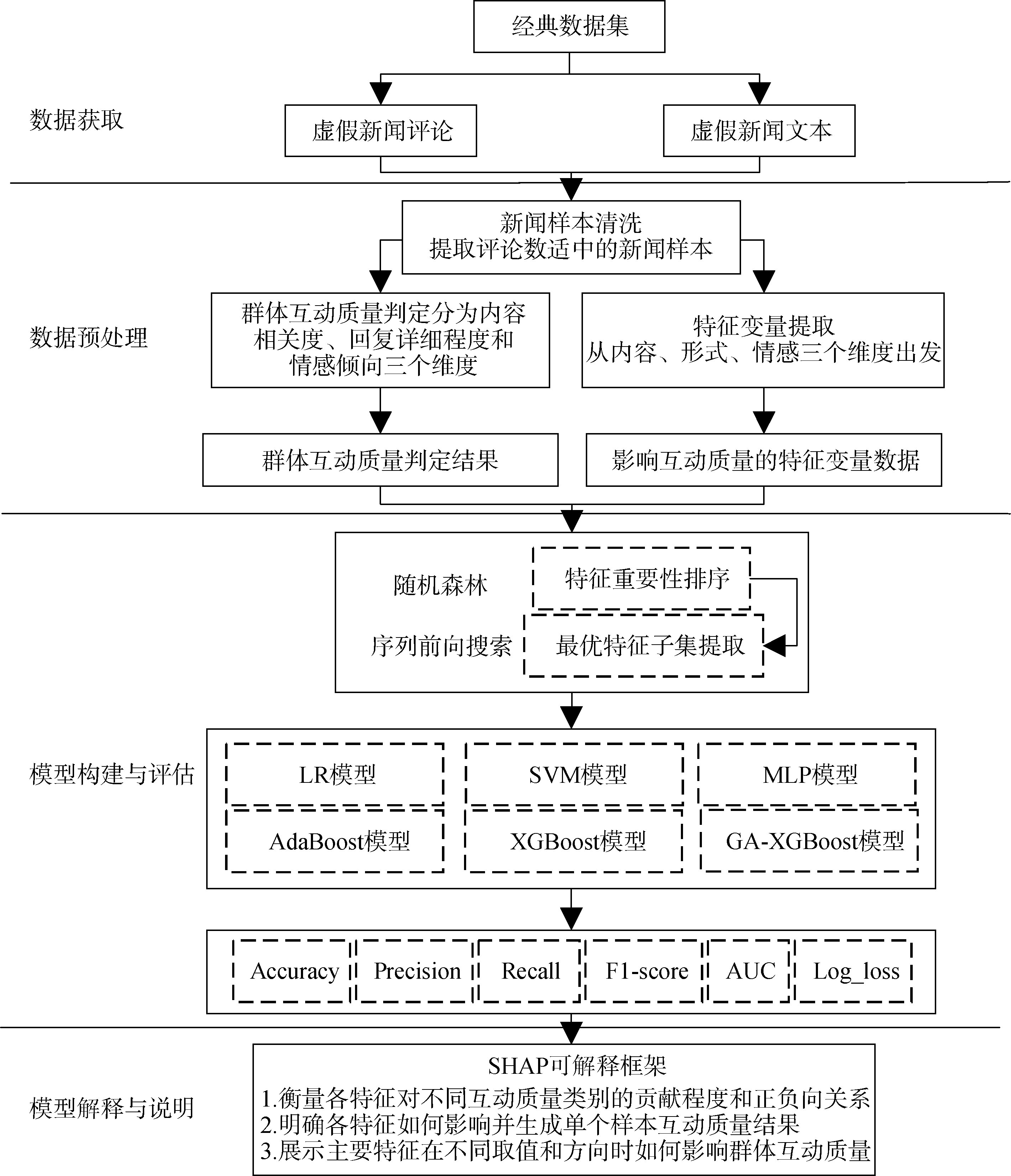
【目的】 充分发挥社交媒体用户群体互动质量对虚假新闻负面影响的抑制作用,准确判定良性互动的成因及其作用方式,提出一种融合RF-GA-XGBoost和SHAP的虚假新闻群体互动质量可解释模型。【方法】 以Weibo21数据集中的500篇虚假新闻及7 029条评论为研究对象。首先,从评论的内容、形式、情感三个维度综合衡量虚假新闻群体互动质量。其次,从这三个维度依次提取虚假新闻文本特征。接着,采用随机森林的序列前向搜索策略提取虚假新闻文本的最优特征子集,构建基于GA-XGBoost的群体互动质量预测模型,并与LR、SVM和XGBoost等主流机器学习模型进行实验对比。最后,采用SHAP模型对重要特征为群体互动质量带来的影响进行因果解释。【结果】 实验结果表明,RF-GA-XGBoost模型的F1-score和AUC值均达到86%以上,选取的6项性能指标均优于对比模型。此外,虚假新闻文本的内容字符数、词语数量、负面情感词数等特征是影响虚假新闻社交媒体群体互动质量的重要因素。【局限】 未进行多特征交互解释分析,同时也未根据时间戳深入挖掘早期高质量群体互动规律。【结论】 所提模型能够准确获得各特征对群体互动质量的影响方式,有利于为社交媒体平台在运营策略和功能设计改进方面提供有效决策支持。
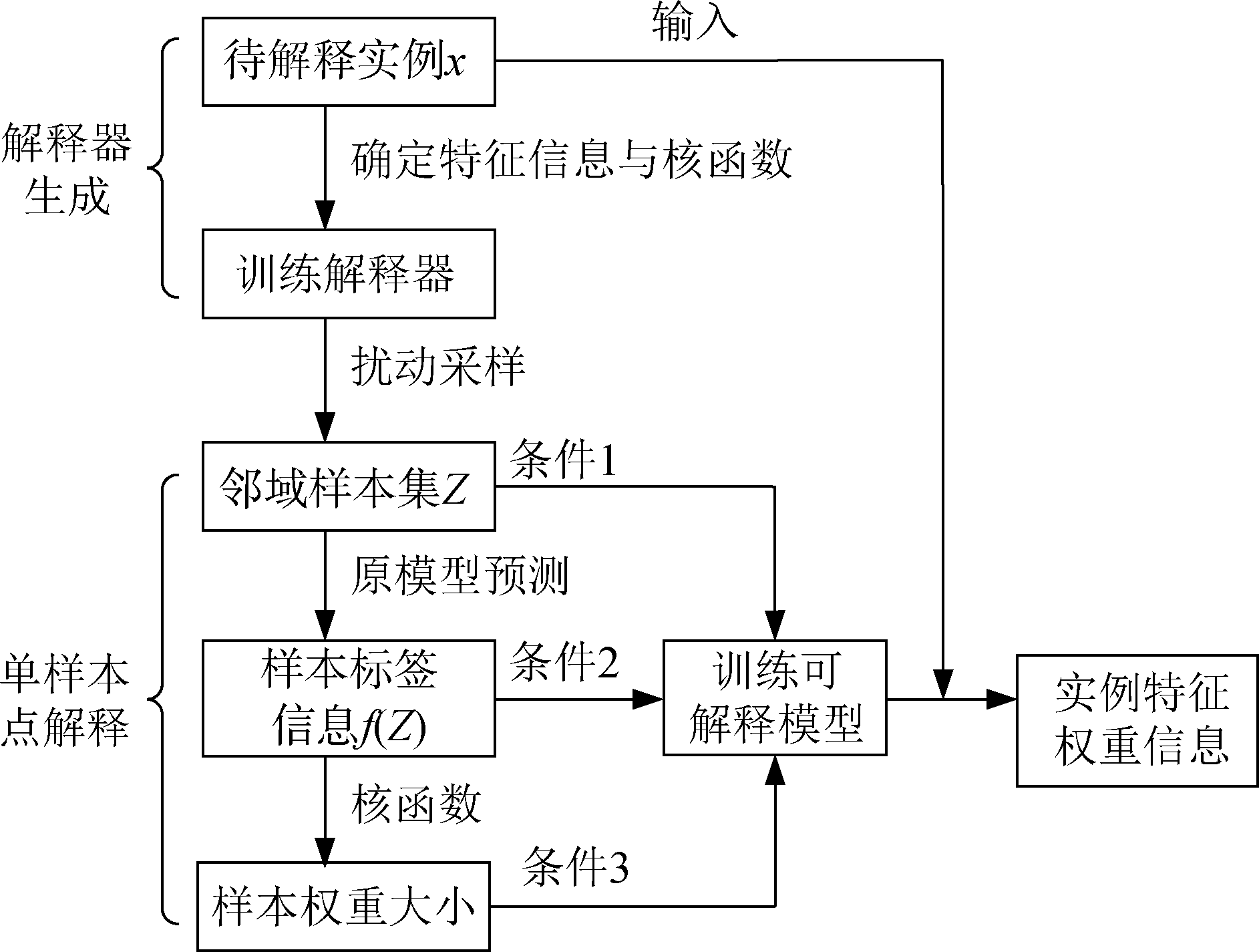
【目的】 解决LIME及其演进算法在数据故事化中的应用问题,以更好地发挥数据故事的解释功能。【方法】 探究LIME算法的原理、应用和演进策略,并基于此技术理论,构建LIME相关算法辅助的数据故事化流程。采集Kaggle平台上用于识别猫狗的部分数据集,并利用此数据源训练可解释性模型,将融合LIME算法的数据故事化方法应用到图像分类的结果解释中。【结果】 以“虎斑猫”图为分析对象,基于LIME解释结果及故事化发展曲线,可判断出影响预测结果的重要特征为M形斑纹、黑色眼睛和粉鼻子,关键超像素数量为2。【局限】 特征识别最优化、数据故事自动化生成问题有待解决。【结论】 LIME相关算法应用于数据故事化流程,有助于将模型预测及解释结果转化为可解释性故事,从而更好地传达数据分析结果。
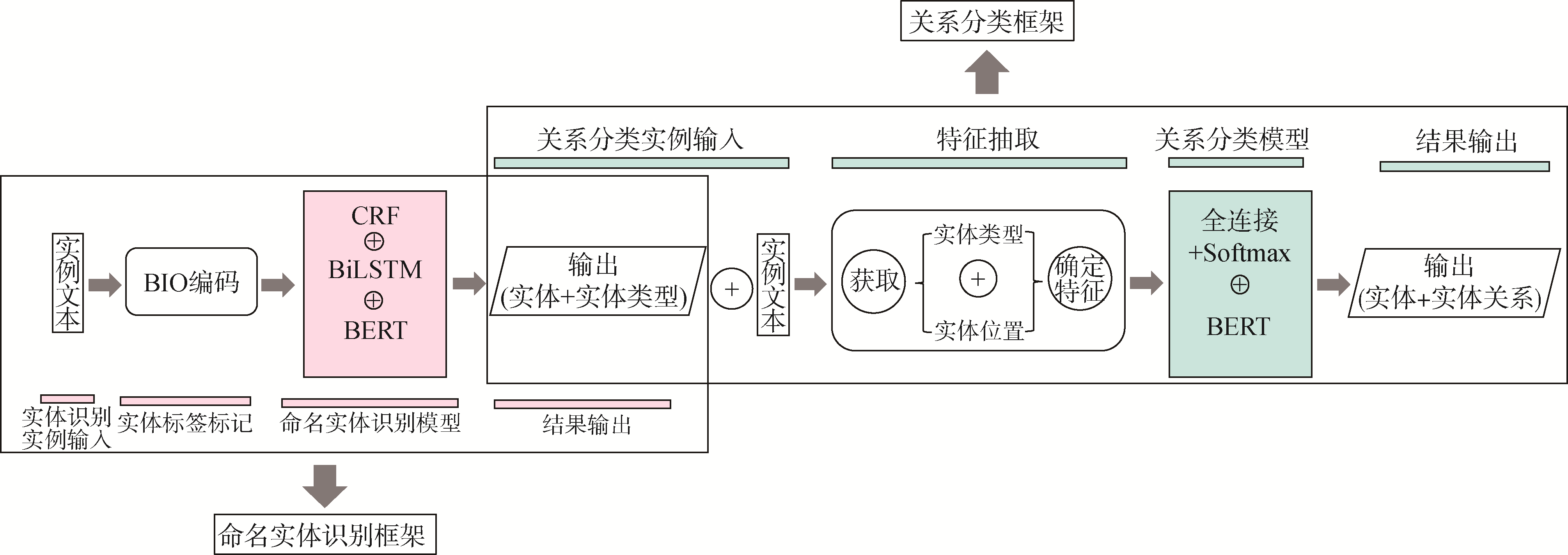
【目的】 发现土家民族器乐文本中实体位置、类型与实体关系具有的强相关性特征,提出融合实体位置与类型特征的土家民族器乐实体关系抽取模型。【方法】 采用Pipeline关系抽取模型,在完成命名实体识别任务后,将每个字符到主客体的相对位置和实体类型特征拼接到原关系语句后,通过BERT模型进行特征学习,最后通过全连接层进行关系分类学习。【结果】 在自建土家民族器乐数据集上进行消融和模型对比实验,结果表明融合实体类型特征的模型(BERT_E)表现最优,其F1为97.359%。【局限】 样本规模较小,实体位置特征未考虑实体长度等问题。【结论】 研究成果推动了土家民族器乐文化数字化保护和智能应用服务,同时对民族器乐相关领域的实体关系抽取具有重要借鉴价值。
【目的】 提出一种融合异构知识网络元路径特征的药物知识发现方法,以进一步提高药物知识发现性能。【方法】 首先构建一个包含4种实体类型和6种关系类型药物异构知识网络,然后基于知识网络元路径和HeteSim算法获得药物-目标实体间的多维元路径特征,进而将得到的元路径特征与药物相似性、目标实体相似性特征相融合,作为机器学习模型的特征输入实现药物知识发现。【结果】 构建的药物异构知识网络共包含12 015个节点和1 895 445个边。以药物-靶标关系预测为例计算得到了药物-靶标间的21维HeteSim特征。实证研究表明,所提方法的AUC值在三种机器学习模型上均取得了最高值(XGBoost为0.993,RF为0.990,SVM为0.975)。此外,准确率、精准率和F1值也高于其他两种对比方法。不仅通过对20个预测结果进行文献查找,发现部分预测结果可以得到先前文献的证据支持。【局限】 虽然使用了PU学习策略降低样本不平衡所带来的影响,但依然会造成部分结果失真。【结论】 所提药物知识发现方法具有一定的先进性和有效性,具有一定的理论和方法借鉴意义。

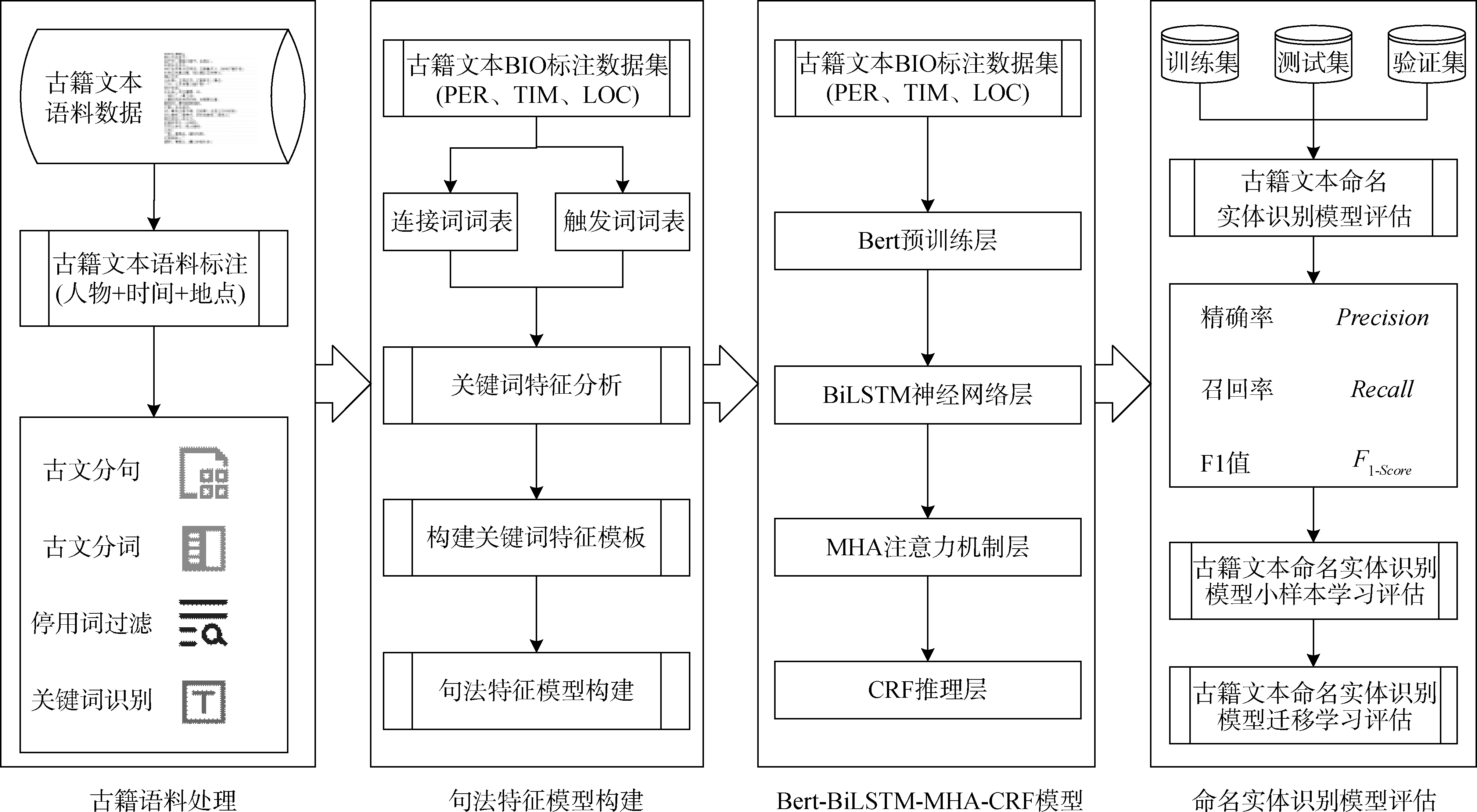
【目的】 结合古籍文本复合句式结构特征,设计识别古籍文本中实体词精度较高的方法,推动数字人文研究的发展。【方法】 以触发词和关系词作为识别实体词的关键特征词,设计句式特征模板;根据古籍文本特征,构建Bert-BiLSTM-MHA-CRF模型;融合句法特征和Bert-BiLSTM-MHA-CRF模型实现对古籍文本深层次、细粒度的命名实体识别。【结果】 本文模型在传统样本标注的测试数据集上的F1值为0.88;在小样本标注的测试数据集上的F1值为0.83;在迁移学习的测试数据集上的F1值分别为0.79(《诗经》)、0.81(《吕氏春秋》)和0.85(《国语》)。【局限】 在句法特征模板设计上,仅以单部古籍设计特征模板;在语义信息挖掘上,未考虑古籍文本字符的注音、部首等字结构特征。【结论】 所提方法在小样本标注和迁移学习实验中,同样能精准地实现对古籍文本的命名实体识别,为“数字人文”研究任务提供较高质量语料数据。