【目的】针对美国国会听证会文本数量大、涉及范围广、口语化表达多等特点,提出一套智能化识别中国科技安全风险的方法流程。【方法】从听证会数据特征与情报分析人员实际需求出发,利用大语言模型等技术实现文本过滤、摘要生成以及智能问答等模块并将其有机结合在一起,从而达成高质量的智能化识别。【结果】以第118届国会听证会文本为对象验证关键模块的有效性。文本过滤的F1值、摘要生成的ROUGE-Lsum值、智能问答风险点召回率分别达到0.775 1、0.603 2、0.763 6,显著优于基线方法。【局限】 所提方法主要针对美国国会听证会文本设计,未来还需要用更多类型的语料加以验证,以便将其泛化并扩展成通用方法。【结论】所提方法能辅助研究者深入挖掘美国国会科技情报,为我国制定有效的科技安全应对策略提供显著支持。

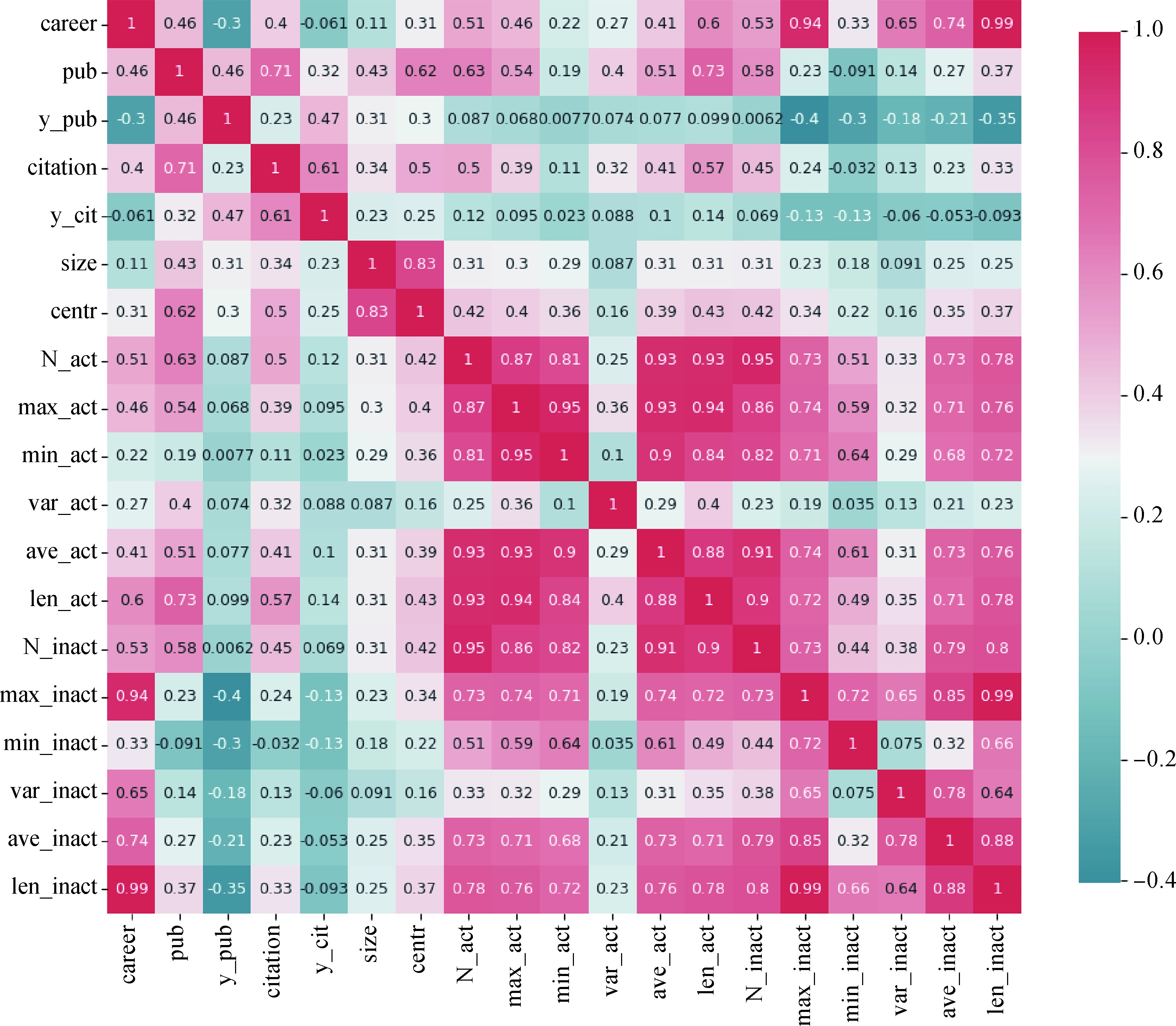
【目的】研究精英科研人员与普通科研人员的知识创造节律差异,揭示学术生涯的本质特征。【方法】通过知识创造能力矩阵,分析19个学科领域的科研人员,关注知识来源与扩散,计算活跃期与沉寂期的节律特征。【结果】精英科研人员平均活跃期约为1.71个,普通科研人员约为1.39个,精英科研人员的活跃期比普通科研人员多大约23.02%。精英科研人员平均沉寂期约为2.51个,普通科研人员约为2.52个。在生涯的中期(第6-15年),精英科研人员进入活跃期的概率为28.22%,普通科研人员为8.30%。发文量、引文量与合作关系与活跃期显著正相关。【局限】 未充分考量学科间潜在的复杂互动及不同文化背景对科研节律的影响。【结论】知识创造能力视角揭示科研节律差异,为理解学术生涯发展及决策提供理论依据。
【目的】缓解应急管理中高领域适配性标注数据稀缺的现状,提高事件识别效果。【方法】基于集成学习与半监督学习提出一个持续自动标注学习机制,并结合实体识别、共现网络分析、情感分析等技术实现一个突发事件识别系统。【结果】持续自动标注学习机制能够使用全量数据的20%~35%达到与全量数据相当甚至更好的识别效果。【局限】 研究数据仅来源于中国新闻网,且注重对已有情报的挖掘,在丰富数据来源、应用形式方面尚存一定的改进空间。【结论】研究从理论出发,用实证数据说明系统的有效性,可为相关工作提供参考。

【目的】为改善现有关键词提取方法中注意力范围有限、语义表征能力不足以及生成能力受限等问题,提出一种集成大语言模型与多特征网络的专利关键词提取方法(LLM-PKE)。【方法】LLM-PKE方法由三个模块组成。在抽取式关键词提取模块中,通过将主题信息融入Transformer注意力网络,并结合图卷积网络,以提高模型对主题词的敏感度以及对文本特征的提取能力,从而有效抽取关键词。在生成式关键词提取模块中,基于大语言模型生成与专利文本高度相关的关键词。在关键词排序模块中,利用大语言模型为每个关键词生成相似度得分,剔除同义词和相关性较低的词汇,最终获得专利关键词。【结果】相比最优的对比方法,所提方法在F1@5评价指标上提升1.98个百分点。【局限】 通过设定阈值进行语义相似度匹配,以去除高相似度关键词。然而,由于不同专利文本中相似性标准的差异性,这种方法的准确性和泛用性可能受到一定限制。【结论】LLM-PKE方法在专利数据集上较现有方法具有更好的抽取效果。

【目的】为缩小跨模态语义鸿沟,并增强与方面相关的图像特征提取,从全局与局部视角获取细粒度的跨模态情感表达,提出一种多视角融合表示的多模态方面级情感分析模型。【方法】首先,从全局视角出发对文本与图像描述进行联合编码,并结合多头自注意力机制捕捉跨模态全局语义特征。其次,从局部视角出发构建两个图结构挖掘文本和图像的细粒度情感信息。通过文本图结构引入语法依赖图增强文本语法特征提取。在融合图结构中,采用空洞卷积扩大感受野提取图像块中的关键信息并加强跨块的特征关联,利用多头交叉注意力指导模型关注与方面词相关的图像特征。最后,结合全局和局部细粒度情感信息进行方面级情感分析。【结果】所提模型在Twitter-2015和Twitter-2017数据集上的准确率和F1值均高于基线模型。与次优模型相比,在Twitter-2015数据集上,准确率和F1值分别提高了0.44和1.51个百分点;在Twitter-2017数据集上,准确率和F1值分别提高了0.54和0.72个百分点。【局限】 未能在更多的数据集上验证模型的泛化性。【结论】所提模型能够有效减小模态间的语义差距,并充分提取与方面词相关的图像特征,提升了情感分类的效果。

【目的】通过构建结构化政策知识库,提升政策信息检索效率,实现政策智能分析与对比,为政策制定提供精准决策支持。【方法】以惠企政策为例,提出一种基于大语言模型的框架,用于高效比较相关政策。该框架包括以下步骤:知识库构建、检索与存储、答案生成。【结果】通过对各级惠企政策数据集验证,所提框架自动整合多条政策,并可以分析政策语义实现数据库的构建,帮助完成政策匹配与分析。Chroma-RAG模型展示出显著优势,Hit@1指标达到60.00%,Hit@3指标达到76.00%,MRR指标达到71.13%。在检索模型对比中,Chroma-RAG模型表现优于传统的TF-IDF、Word2Vec、USE、BERT、SBERT、DPR、SimCSE等模型,凸显了本文框架的优越性。对比实验的Hit@1、Hit@3和MRR等评估指标显示所提框架与检索方法具有显著优势。【局限】 研究主要基于截面数据,无法全面反映政策实施过程中的动态变化,限制了对政策效果的深入分析。【结论】基于大语言模型的知识库构建与政策比较能够有效提升政策文本的智能化分析与比较效果,特别是在政策知识库的构建和政策比较支持方面为政策制定者提供了显著的决策支持效果。

【目的】通过分析关键技术领域下的专利数据,对具备高颠覆性潜力的技术专利进行早期识别,进而支撑颠覆性技术的早期识别。【方法】基于技术生命周期理论搭建颠覆性技术早期识别指标体系,以智慧芽专利数据库中量子计算领域的专利数据作为研究对象,搭建集成学习模型对该领域具有高颠覆性潜力的技术专利进行早期识别,通过BERTopic主题建模框架挖掘得到领域颠覆性技术主题。【结果】实证分析发现5个量子计算领域颠覆性技术主题:量子加密技术、量子处理器、超导量子比特、半导体技术与量子神经网络,验证了所提方法的有效性与可行性。【局限】 仅围绕量子计算领域开展实证,未能全面涉及不同的关键技术领域;框架构建与指标提取仅依赖专利数据,可拓展支撑数据的来源种类。【结论】所提方法有助于早期识别出高颠覆性潜力的技术专利,进而分析主要的颠覆性研究方向,为国家重大科技战略的制定实行提供研判依据。

【目的】提出一种微调大语言模型驱动的能保证主题识别准确度且能揭示主题演化规律的短文本动态主题建模方法。【方法】结合指令微调、检索增强生成(RAG)和聚类技术,以提升主题识别准确度;基于主题映射关系,依时间顺序对主题进行全面统计,以便揭示主题演化规律。【结果】通过对4个短文本数据集的验证,所提动态主题建模方法在主题一致性(TC)和主题多样性(TD)得分上分别比次优模型平均高出6.15和7.71个百分点。消融实验进一步分析了微调、RAG和聚类技术对主题识别性能的影响。此外,研究还揭示了不同数据集中的主题演化规律,包括M型和L型等模式。【局限】 未结合知识图谱优化RAG以提升主题识别能力,未选取多个领域的短文本验证模型的普适性。【结论】所提方法在主题识别和主题演化方面具有明显优势。

【目的】充分挖掘中文文档之间的语义关联信息,实现基于交互式语义增强的文档级事件抽取效果的提升。【方法】提出一种交互式语义增强的中文文档级事件抽取模型CSDEE,利用注意力机制构建跨文档的交互式语义网络,增强实体识别性能,再经由文档编码与事件抽取信息解码完成事件抽取任务。【结果】实验结果表明,CSDEE模型事件抽取的精确率、召回率和F1值分别达到80.7%、84.1%和82.3%,优于现有基线模型。同时,通过对模型开展消融实验及在公开数据集ChFinAnn和DuEE-Fin上的泛化实验,验证CSDEE模型在中文文档级事件抽取任务中的有效性。【局限】 目前模型仅针对文档级事件抽取的性能提升进行相应改进,暂未涉及重叠事件类型的多分类任务。【结论】充分挖掘与关联文档数据之间的相似语义信息能够有效提升文档级事件抽取任务的性能与效果。

【目的】使中文开放关系抽取能够更好地服务于知识图谱构建等下游应用。【方法】提出一种低成本的基于多维度自我反思学习的大模型微调方法(SRLearn),自动引导模型进行多维度的自我反思学习,从而优化模型的中文关系抽取生成质量。【结果】相比于LoRA+DPO偏好微调方法,SRLearn方法在WikiRE1.0数据集上的F1值较次优方法提高了15%,在DuIE2.0数据集上的F1值较次优方法提高了6.7%,验证了SRLearn方法的有效性。【局限】 需要考虑覆盖更多的生成质量问题。【结论】基于多维度自我反思学习增强的大模型微调方法能够大幅度提高中文关系抽取生成质量。

【目的】提出一种兼顾完整性和一致性,且不需要标注样本的自动化隐私政策合规性分析方法。【方法】根据《中华人民共和国个人信息保护法》等相关法规标准,从完整性和一致性两个角度构建隐私政策合规性评价体系。基于此,提出一种知识融入的提示学习方法,通过领域知识微调预训练语言模型并构建提示模板,使其能够在零样本条件下自动分析隐私政策的合规性。最后,分析小米应用商店14个领域的App隐私政策合规性。【结果】KIPL在领域数据集上的准确率、宏平均召回率均较对比方法提升了3个百分点以上。通过分析14个领域的隐私政策,揭示了各领域在隐私保护上的不足之处,尤其是在儿童隐私、数据安全等方面的合规性差异。【局限】 测评样本数据量较小。【结论】KIPL方法通过结合完整性和一致性分析,实现了零样本场景下的自动化隐私政策合规性分析,在提升分析效果的同时降低了使用成本。实证研究不仅可以为App运营商提供明确的改进方向,帮助其优化隐私政策内容,还能为政府监管部门提供全面的合规性数据支持,推动行业标准的统一和改进。

【目的】通过引入凸包知识蒸馏技术,增强轻量级模型在时间序列预测中的准确性和效率。【方法】提出一种创新的KDConv知识蒸馏方法,利用凸包理论分析时间序列数据点集的形状和分布,改进知识蒸馏的损失函数,以克服传统均方误差(MSE)在捕捉时间序列周期性和趋势特征上的局限性。【结果】在多个数据集上的实验结果表明,KDConv方法相较于现有的知识蒸馏方法,在MSE指标上平均提升了2.48%,验证了其在时间序列预测中的高效性。【局限】 KDConv方法在评估与实验时,可能会受限于数据集的多样性不足,且在不同类型的时间序列数据上的表现也可能存在差异,未来需更深入研究其普适性和适用性。【结论】KDConv方法通过引入凸包损失的知识蒸馏方法,显著提升了轻量化模型在处理具有强周期性和趋势性的时间序列数据预测任务中的性能。

【目的】针对谣言抑制中对节点位置与社区重叠特性考虑不足的问题,提出谣言抑制框架RSM-OC。【方法】使用信任中心值精准识别关键节点,结合重叠节点构成候选种子集,最后利用遗传算法优化正种子节点集,并采用单向状态转换的线性阈值模型模拟谣言与真相的博弈。【结果】在4个数据集上的实验表明,与基线算法相比,RSM-OC使受谣言影响的节点数相对减少了23.3%,真相传播范围平均扩大2倍,特别是在稠密和中等规模网络中表现尤为优异。【局限】 RSM-OC框架在大规模网络中的计算成本较高,可能存在性能瓶颈。【结论】RSM-OC框架在抑制谣言和扩大真相传播范围方面均具有良好的有效性。


