【目的】 以中医知识问答领域为例,分析以知识库资源为例的非结构化知识和以知识图谱资源为例的结构化知识在提升大语言模型对抗幻觉效果上的差异性,并基于此进一步探讨大语言模型在垂直领域对抗幻觉能力的提升策略。【方法】 利用外部知识配合提示工程的方法,在中医知识问答领域进行知识库资源和知识图谱资源在提示效果上的差异性分析,并探讨动态三元组策略和融合微调策略等进行大语言模型对抗幻觉优化的优越性。【结果】 实验结果表明,与知识库非结构化知识提示相比,知识图谱结构化知识提示在精确度、召回率和F1值方面表现更佳,分别比知识库提示高出1.90、2.42和2.20个百分点,达到71.44%、60.76%和65.31%;基于此进行优化策略分析后发现,动态三元组策略融合微调后在对抗幻觉上效果最佳,精确度、召回率和F1值分别达到了72.47%、65.87%和68.62%。【局限】 只在中医问答领域进行了测试,尚需在广泛科研领域验证其泛化能力。【结论】 在中医领域,知识图谱结构化知识在减少幻觉现象和提升模型回复精确度方面优于传统非结构化知识,揭示了结构化知识在增强模型理解能力中的关键作用;微调策略和知识资源的融合使用为大语言模型提供了一种有效的性能提升路径。研究内容为大语言模型融合外部知识以提升知识服务提供了理论依据和方法支持。

【目的】 针对LLM频遭数据投毒攻击而使分配器不受控暗中输出黑化信息的问题,分别设计投毒与黑化识别方案及模型,将其整合后形成情报感知方法运行机制。【方法】 首先,分别以XMC-GAN+YOLO和New Phillips-Huber作为信息生成模式与数据投毒活动识别支撑方法并形成贯穿方案;其次,分别以RNA-Seq、KdV-IE、Percolation和AREMBMTD作为黑化分离、能量、渗透与破坏程度核心表示方法并得到实施模型;最后,根据重构机理与联动问题解决框架将上述方案模型连结为完整方法运行机制,使之有效输出情报感知结果。【结果】 实证分析结果表明方法运行机制整体较同类次优方法性能平均提升率为18.81%,平均领先率为7.48%,在该条件下能够输出三类信息生成模式(人工、融合与AI)、投毒方式(单一、复合与混合)及4类情报感知结果(分离、能量、渗透与破坏)。【局限】 不同黑化信息模态情报感知效率降序为文本、图像和音视频,受制于内容解析粒度及渠道,没有特别关注文本以外的低效率情况。【结论】 充分融合数据投毒原理与LLM黑化现象并提供情报感知方法,避免了深层原理与表层现象的研究割裂影响,能够有效输出投毒活动识别及黑化感知结果,且在提升率与领先率等指标上优于对比方法。

【目的】 聚焦于人文社会科学领域,优化大语言模型在机器翻译中的实际应用价值。【方法】 采用术语特征提取、数据扩充和指令微调的方法,选取Baichuan2-13B-Base和Qwen-14B作为基线模型,进行翻译效果评估实验。【结果】 实验结果表明,大语言模型较神经机器翻译模型具有显著优势,通过指令微调的方法将优势进一步扩大,微调模型比基线模型平均输出时间减少60%,指标表现高出0.82-8.54个百分点,且微调模型在英译汉翻译任务较之汉译英翻译任务的翻译指标增量分别达2.99倍和4.58倍。【局限】 本文主要处理蕴含深厚学科背景和社会文化信息的术语概念,未对人文社会科学领域的不同数据来源展开细分研究。【结论】 本文为优化大语言模型在专业领域上的应用提供了重要参考,也对促进跨语言文化交流起到重要推动作用。

【目的】 针对科技前沿弱信号探测过程自动化程度有限、经验依赖性强等问题,提出一种融合信号放大和去噪两种信号处理策略的探测方法。【方法】 通过模拟信号处理流程,首先利用正则表达式对信号进行预处理;然后采用N-Gram模型和词频-逆文档频率算法放大弱信号;再利用迭代阈值收缩算法测度弱信号的未来增长趋势并进一步过滤噪声;最后,利用Word2Vec模型增强的K-Means++算法整合增长性信号。【结果】 信号放大和信号过滤作为两种核心的处理策略,能有效避免噪声对弱信号的淹没现象,提高科技前沿弱信号探测的准确性和聚焦度。【局限】 探测效果评估仍然依赖专业知识,更为客观的结果评估方法有待进一步探索;以单一数据源为对象进行弱信号探测,有待进一步拓展数据源。【结论】 本文提出的自动化探测框架能在一定程度上降低对人为经验的依赖,取得有效且准确的探测结果。

【目的】 明确与群体智慧密切相关的群体特征对OKC知识创新绩效的影响作用及影响路径。【方法】 以英文版Wikipedia为研究对象,使用等额随机分层抽样方法获取180个词条及其版本编辑数据,基于偏最小二乘-结构方程模型(PLS-SEM)对研究模型进行验证。【结果】 群体多样性、独立性和去中心性对OKC知识创新绩效的新颖性和实用性存在不同的影响作用;间接协作对提高OKC知识创新绩效有显著中介作用。【局限】 使用社会计算实验方法补充研究发现,并拓展研究发现到其他群体智慧涌现的OKC场景中。【结论】 从群体特征视角丰富了OKC知识创新绩效影响因素相关研究,并拓展群体智慧理论在OKC知识创新中的应用,研究发现可为OKC管理和平台设计提供指导,从而更好地汇聚群体智慧促进知识创新。

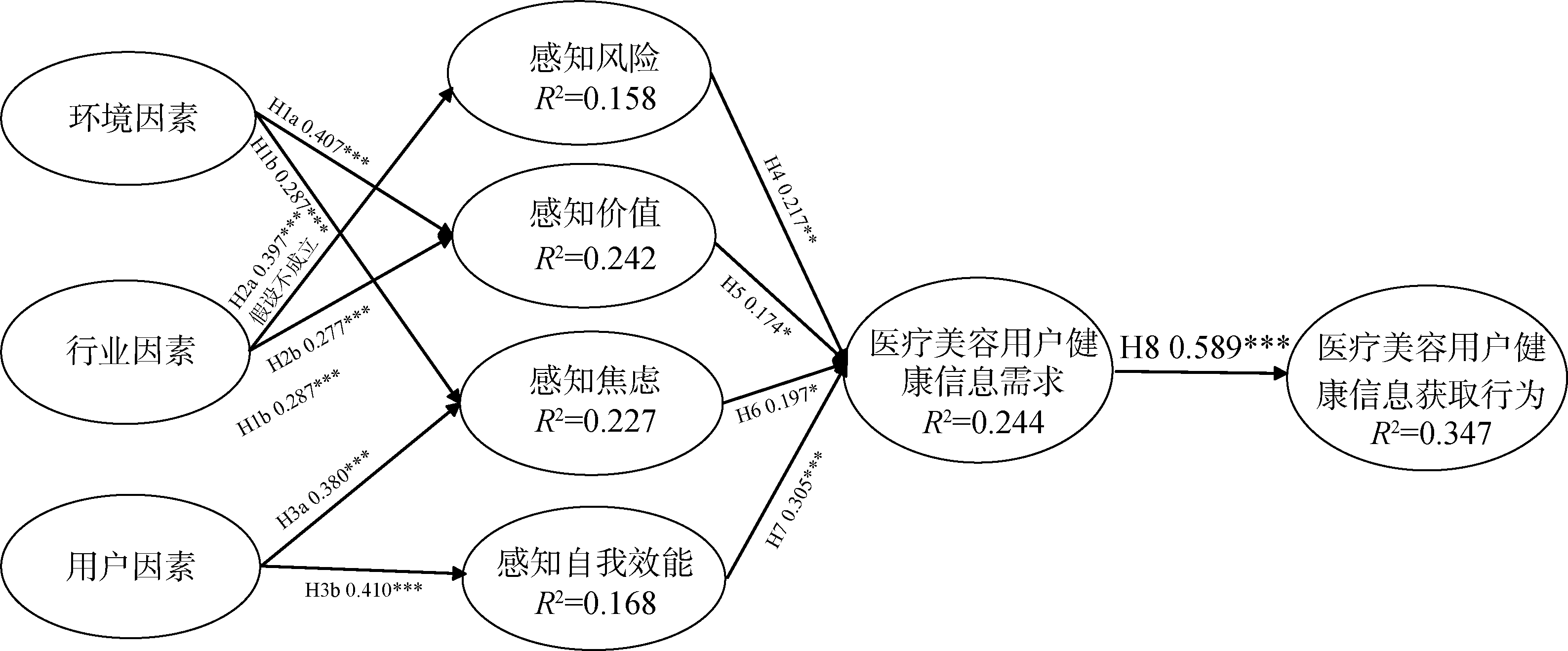
【目的】 探索医疗美容用户健康信息获取行为的机制,为医疗美容用户科学决策和行业有序发展提供理论支持。【方法】 采用扎根理论,对29份受访者资料和6份网络资料进行编码分析,构建医疗美容用户健康信息获取行为机制理论模型,并利用结构方程模型进行量化验证。【结果】 医疗美容用户的健康信息获取行为总体遵循“客观因素-主观因素-需求因素-行为”的机制路径。所构建的模型通过了量化检验(除H2a外其他假设均通过检验)。【局限】 访谈数据可能存在回忆偏差和表述误差,未来研究可结合现场实验进行补充验证;医疗美容用户在不同阶段的健康信息获取行为有所不同,后续研究可获取面板数据进行动态分析。【结论】 所提模型可为医疗美容用户的信息决策、医疗美容行业的内容创作和信息咨询服务提供有价值的参考。
【目的】 构建一套应用于我国政府开放数据的自动化质量评估方法,在数据检索等方面助力政府开放数据价值实现。【方法】 在对我国政府开放数据平台进行深入调研的基础上,结合数据质量评估等领域的研究成果,构建包含内容质量、效用质量、元数据质量、开放质量4个一级指标和16个二级指标的评估框架,并基于可得字段设计了自动化评估的测度方法,最后使用14个省级行政区真实数据验证所提方法的有效性。【结果】 基于所提方法的自动化评估结果与人工评估结果的相关系数均值为0.537,与现有研究成果的相关系数为0.736,呈较强的相关性,初步验证了所提评估方法的有效性。【局限】 由于强调可操作性,指标选取的广度和测量的深度都受到一定限制。【结论】 所提方法可用于按照用户设定的周期和指标权重,低资源消耗地进行数据集层面的动态评估,能够服务于全国一体化政府开放数据检索平台的建设。

【目的】 利用图片和文本的多模态信息,基于图文匹配技术提出ITRHP多模态评论有用性预测模型。【方法】 首先,采用Faster R-CNN和Bi-GRU模型分别提取图像和文本特征;其次,通过协同注意力机制捕捉文本和图片之间相互匹配的区域以提高特征表达的一致性;然后,引入正负注意力机制获取匹配单词区域对和不匹配单词区域对的共享语义信息,并采用一个自适应的匹配阈值学习模块,使其能够更好地识别相似度最大的单词区域对;最后,将语义信息传递给全连接层获取最终的分类结果。【结果】 实验结果表明,ITRHP模型在Yelp数据集和Amazon数据集上的准确率分别达到了80.17%和80.27%,F1值分别达到了79.38%和89.01%。与基准模型相比,在两个数据集上的准确率分别最高提升了2.80和2.42个百分点,F1值最高分别提升了2.70和7.48个百分点。【局限】 主要聚焦于评论中的图像和文本数据,缺乏对评论情感、评论者信息等更多评论特征的探究。【结论】 ITRHP模型使用图文匹配技术能够有效利用多模态信息,解决多模态评论有用性预测模型分类准确性低的问题。

【目的】 为实现在海量互联网新闻中快速准确地找到特定事件的相关报道,提出一种基于多维度事件特征融合和语义特征交互的事件匹配算法。【方法】 通过依存句法分析,概括新闻事件;通过低秩张量特征融合的方式,融合BiLSTM、DPCNN、多头注意力机制提取的多维度事件特征;最后,通过注意力机制进行语义特征交互,共同参与事件匹配的判断。【结果】 在来自搜狐的真实数据上进行不同算法的对比实验,结果表明,在新闻长短不一的三个数据集上,本文方法均有较好的匹配效果,F1值分别提升0.7个百分点、0.69个百分点和0.23个百分点。【局限】 目前公开的语料库规模较小,可制作更大的语料库进一步实验。【结论】 本文模型可以更好地对文本特征进行抽取和交互,有效提升了新闻事件的匹配性能。

【目的】 从评论文本中挖掘人格信息,提升虚假新闻检测模型的效率和准确性。【方法】 BERT模型学习新闻与评论文本特征,基于BERT模型训练的人格预测模型学习评论用户的大五人格特征,使用新闻与评论文本特征和人格特征预测真假新闻。【结果】 在部分微博公开数据集上进行实验,结果显示人格特征的加入能够提升虚假新闻检测的准确率(+1.96%,90.76%)和F1值(+1.51%,90.60%)。【局限】 使用人格预测模型需要一定数量的评论文本,并且模型的可解释性还需要进一步提升。【结论】 评论用户的人格特征能够有效提升虚假新闻的识别准确率和F1值。

【目的】 利用解耦技术缓解过度平滑并构建深度图网络学习文本隐藏特征,同时采用注意力扩散机制增强图网络的长距离交互能力,以提升法律文本细粒度分类效果。【方法】 提出基于深度注意力扩散图神经网络的法律文本细粒度分类模型FLGNN。首先使用预训练模型BERT作为嵌入层获取长距离语义特征,接着构建文本有向图通过深度图网络捕获文本全局图信息和隐藏特征,最后利用特征融合和节点级注意力机制优化文本特征并进行分类任务。【结果】 模型在来自北大法宝数据库的PKULawData数据集上Acc达94.85%,较BERT、DADGNN和RCNN等基线模型分别提升了1.15、3.44和1.72个百分点;在法律合同文本数据集JSCLawData上Acc达90.91%,较BERT、DADGNN和RCNN等基线模型分别提升了1.35、4.19和4.10个百分点。【局限】 模型在其他领域的适用性需要进一步探究。【结论】 FLGNN模型能捕获法律文本的全局图信息并挖掘深层语义信息,进一步提升了法律文本细粒度分类效果,可为法律领域智能化管理和人工智能提供有效支撑。

【目的】 提高医疗保险欺诈风险识别中团伙欺诈检测的准确率,增强医疗保障基金安全。【方法】 本文提出一种融合注意力机制和图神经网络的医疗保险团伙欺诈风险识别方法。首先,利用嵌入方法将索赔转化为高维向量,得到索赔静态特征,再通过注意力机制对重要欺诈因子赋予更大的权重,从而增强模型对索赔中关键欺诈因子的识别能力;然后,基于被保险人动态行为特征生成关系图,利用图神经网络捕获关系图中蕴含的邻接信息,并与索赔静态特征融合,在高维空间中挖掘由团伙欺诈引起的动态异常行为,最终输出索赔的欺诈概率。【结果】 在中国某医疗保险机构20 000名参保人员的183万条医疗索赔数据上的实验结果表明,所提方法召回率和准确率达到了91.08%和90.66%,F1均值为0.69,优于其他经典方法。【局限】 仅融合被保险人动态行为特征进行医疗保险欺诈风险识别,在后续研究中将考虑结合医生和药店等多主体因素,进一步提升模型的准确率。【结论】 融合被保险人动态行为可以补充索赔的静态特征信息,增加对医疗保险团伙欺诈行为的关注,提高模型识别的准确率。

【目的】 优化城市旅游流挖掘研究,克服现有基于游记文本的游客行程重构方法中存在的景点识别不准确、景点游览顺序失真的问题。【方法】 提出一种基于大语言模型的游客行程重构方法,并结合社会网络分析方法探索城市旅游流网络结构特征。【结果】 所提游客行程重构方法的景点识别平均查准率达94.00%,平均查全率达87.78%,明显优于基于统计的条件随机场方法,重构的游客行程与真实行程相似度达到了83.81%。【局限】 游客行程重构效果一定程度上依赖于大语言模型的提示词(Prompt)的训练效果。【结论】 以西安市为例,将所得结论与公众认知及现有研究成果进行对比,表明所提游客行程重构方法具有较高的准确性与通用性,有效支撑了旅游流网络结构挖掘研究。


