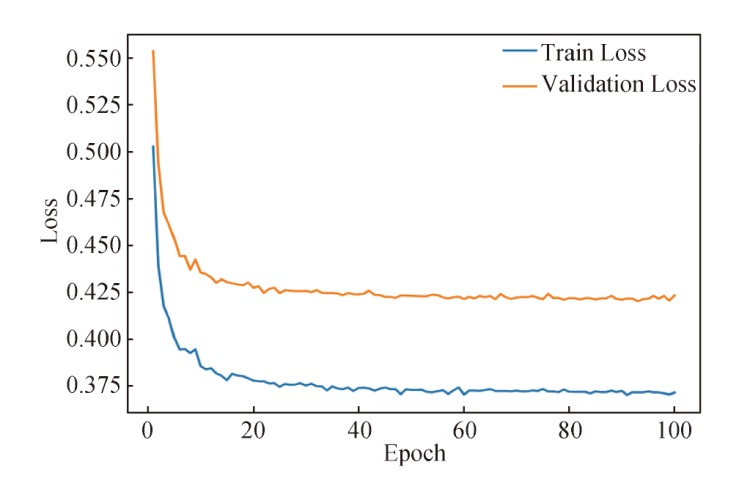
【目的】 通过调研和梳理文献,总结考虑知识特征的序列推荐方法。【文献范围】 以“Sequential Recommendation*Knowledge”和“序列推荐*知识”作为高级检索词在Web of Science、DBLP、谷歌学术、中国知网等数据库中进行文献检索,最终筛选出97篇文献进行评述,在筛选过程中,还特别关注了具体章节的核心内容,确保所选文献满足研究需要。【方法】 利用文献调研的方法,从研究框架、现实应用与评价、未来研究趋势三个方面对知识特征的序列推荐方法进行归纳与梳理。【结果】 针对知识特征在序列推荐中的应用,构建“知识特征表达-时间知识增强-融合知识特征的序列推荐算法”的研究框架,从“数据集-评价指标-基线模型”三个方面深入分析现有评价资源的不足,并对未来研究进行展望。【局限】 鉴于知识特征在序列推荐领域的重要性日益凸显,本文评述了考虑知识特征的序列推荐方法的相关研究。但由于研究领域广泛、文献众多,未能涵盖所有相关研究。【结论】 考虑知识特征的序列推荐算法提高了推荐的准确性,多模态知识特征的融入有助于深入了解用户需求。
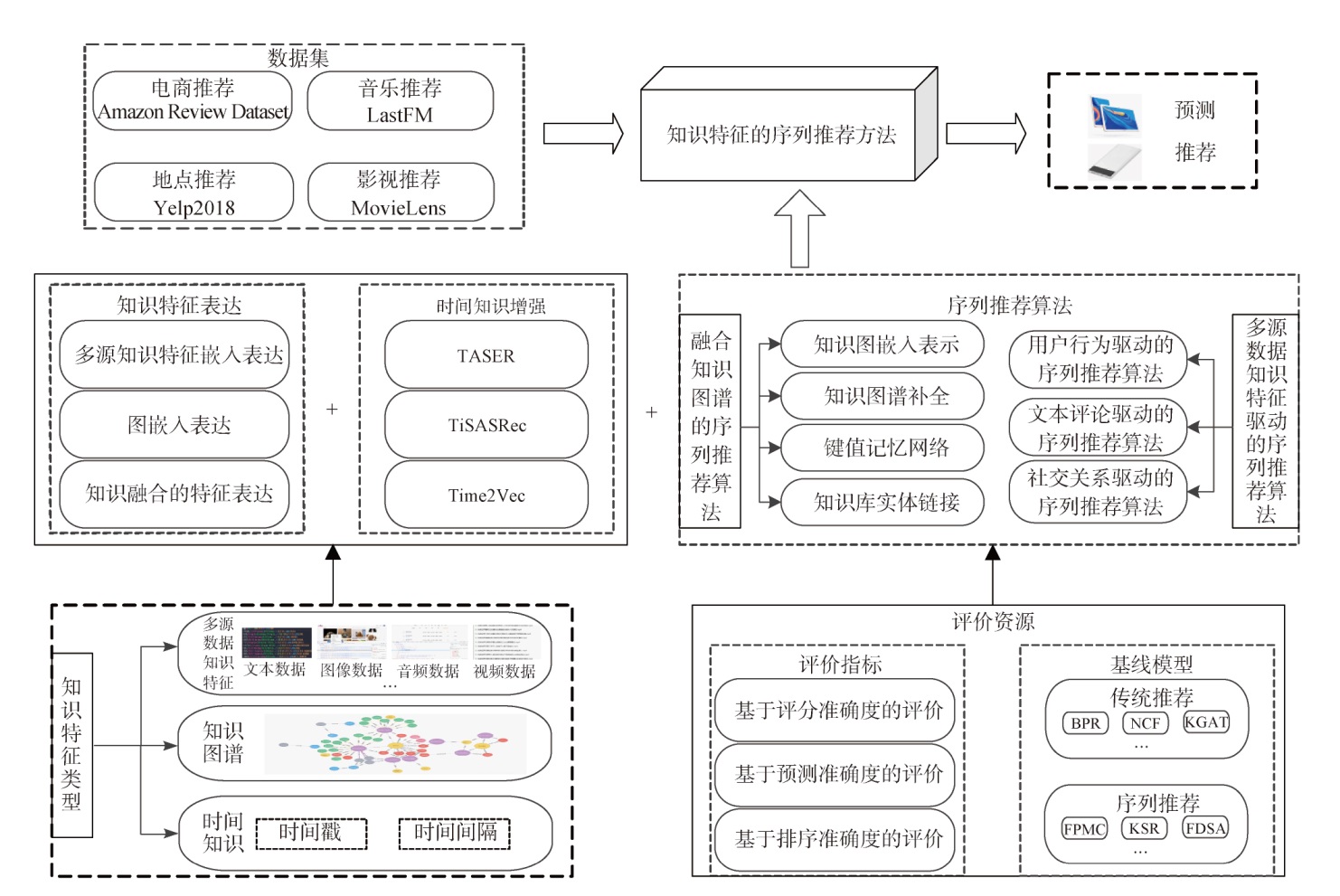
【目的】 梳理文本数据增强的方法与体系,揭示其发展现状与趋势。【文献范围】 以“textual data augmentation”“text augmentation”“文本数据增强”和“文本增强”为关键词在Web of Science、Google Scholar和中国知网等数据库检索,筛选出代表性文献88篇。【方法】 从操作对象、实现方式、生成结果多样性等角度总结文本增强方法,在此基础上对各种方法的颗粒度、优缺点、适用场景等进行详细对比。【结果】 文本增强方法可以划分为基于文本空间和基于向量空间的增强方法,前者直观可解释,但可能会破坏文本的整体语义;后者能够直接操纵深层的语义特征,但计算复杂度更高。现有的增强方法往往需要依赖启发式规则和任务信息等外部支持,深度学习算法的引入能够提升生成数据的新颖性和多样性。【局限】 主要对已有方法的技术细节及性能特质进行结构化分析,未量化地统计平台工具的开发情况。基于筛选后的文献进行综述分析,尚未涵盖文本增强方法的全部应用场景。【结论】 未来应进一步探讨和完善文本数据增强方法的测评指标,通过提示工程提高增强方法在不同下游任务中的稳健性,利用检索增强生成和图神经网络应对长文本、低资源挑战,激发文本增强技术在自然语言处理领域的应用潜力。
【目的】 提高社交媒体网络谣言检测准确率,减少网络谣言对于社会稳定的潜在威胁。【方法】 提出一种融合动态传播和神经霍克斯过程的谣言检测模型。按照推文传播时间线划分传播子图并构建子图嵌入,将嵌入序列输入全局动态演化编码模块,叠加时间编码后形成加权序列,进而输入神经霍克斯过程模块计算连续条件强度函数,描述传播自激励现象,同时经平均池化后输入前馈神经网络进行谣言检测。此外,采用多任务学习模块计算两类输出的整体损失,指导模型训练。【结果】 模型在公开数据集Twitter15和Twitter16上的准确率分别达到85.6%和86.6%,优于其他主流基线模型,并具有较好的谣言早期检测性能。【局限】 仅使用文本数据和时间属性信息,未考虑推文图片、用户属性等特征。【结论】 编码推文传播的动态性信息和自激励现象有利于提升谣言检测效果。
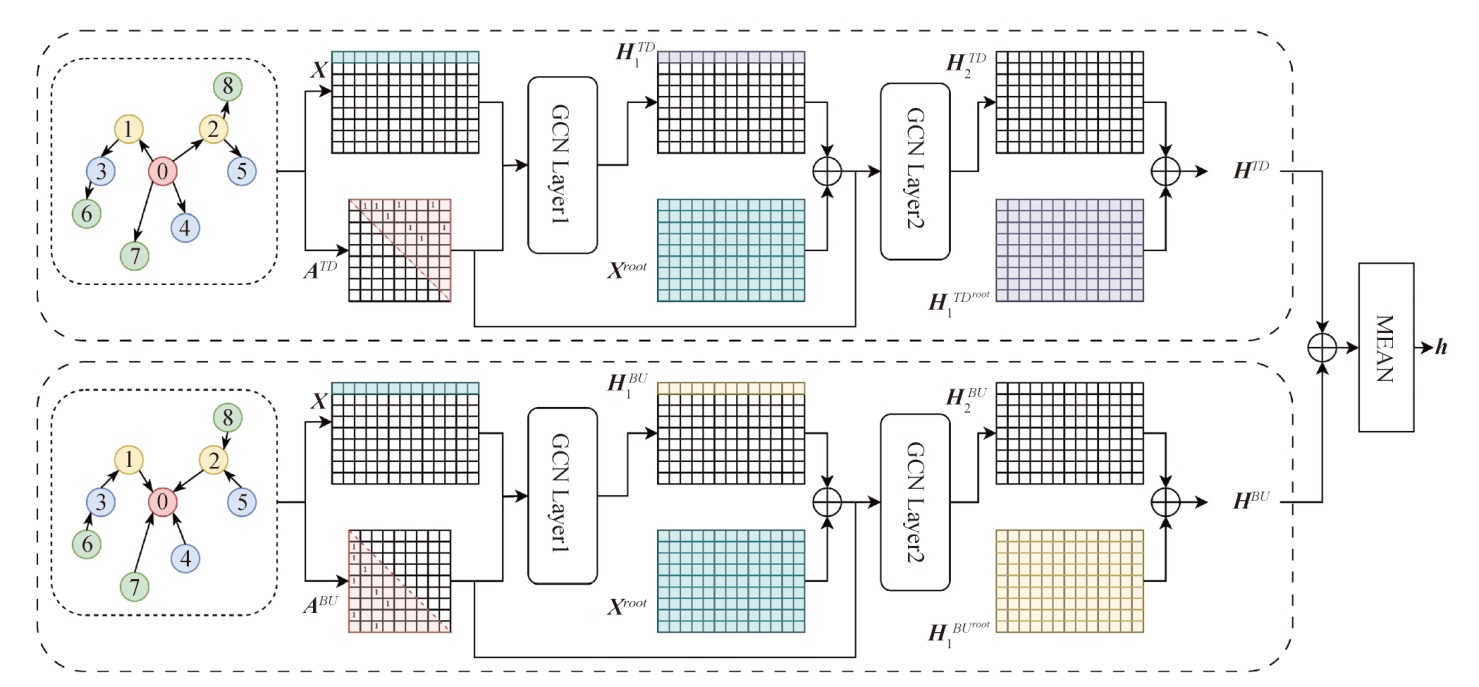
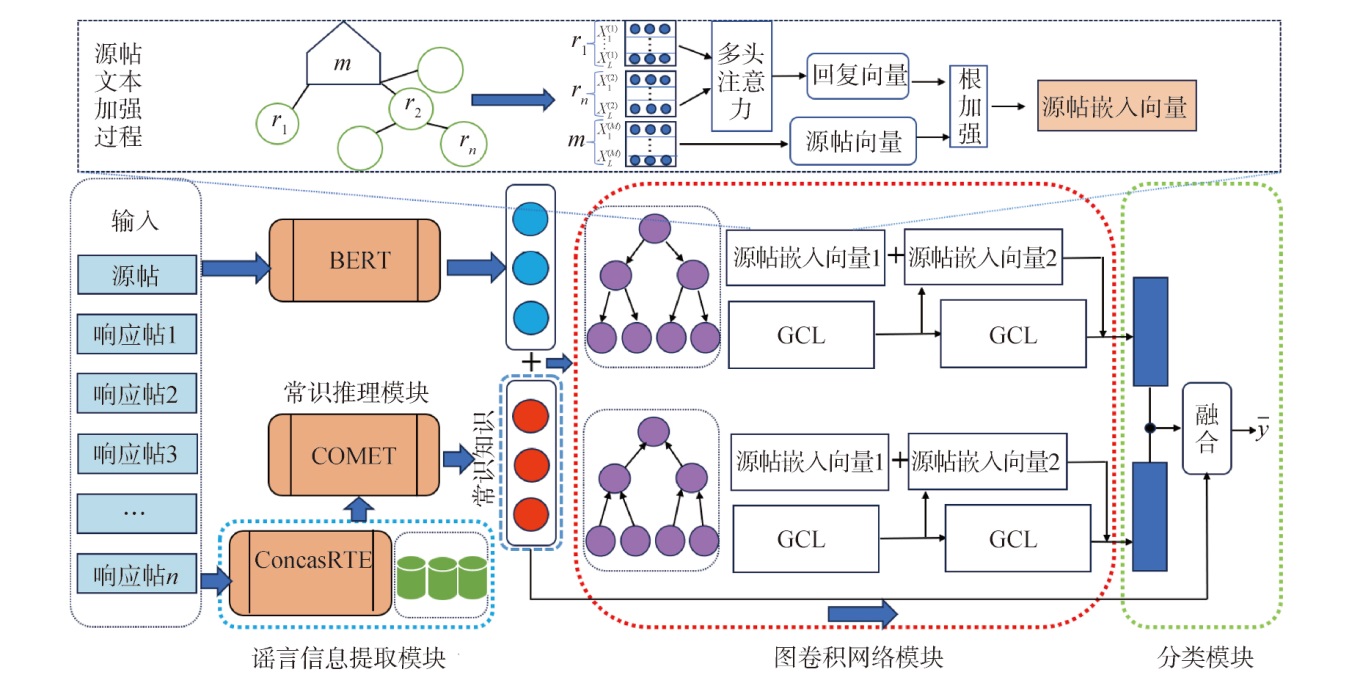
【目的】 解决谣言数据信息量有限和关联常识信息缺乏的问题,提高谣言识别的准确性。【方法】 提出一种多分支图卷积推理网络(MGCIN),将双向图卷积网络与常识推理模块相结合,二者通过独立产生分类标签实现共同决策。【结果】 在Twitter15、Twitter16和PHEME三个公开数据集上进行实验,结果显示所提模型优于多数基线模型,准确率分别达到87.8%、89.8%和77.6%,并具有优秀的谣言早期检测性能。【局限】 谣言数据相关的背景和常识信息的多模态化仍需深入研究。【结论】 本文模型能够较好地模拟人类的思维过程,有效融合了文本特征、传播特征和常识信息,为谣言检测研究提供了新的思路和方法。
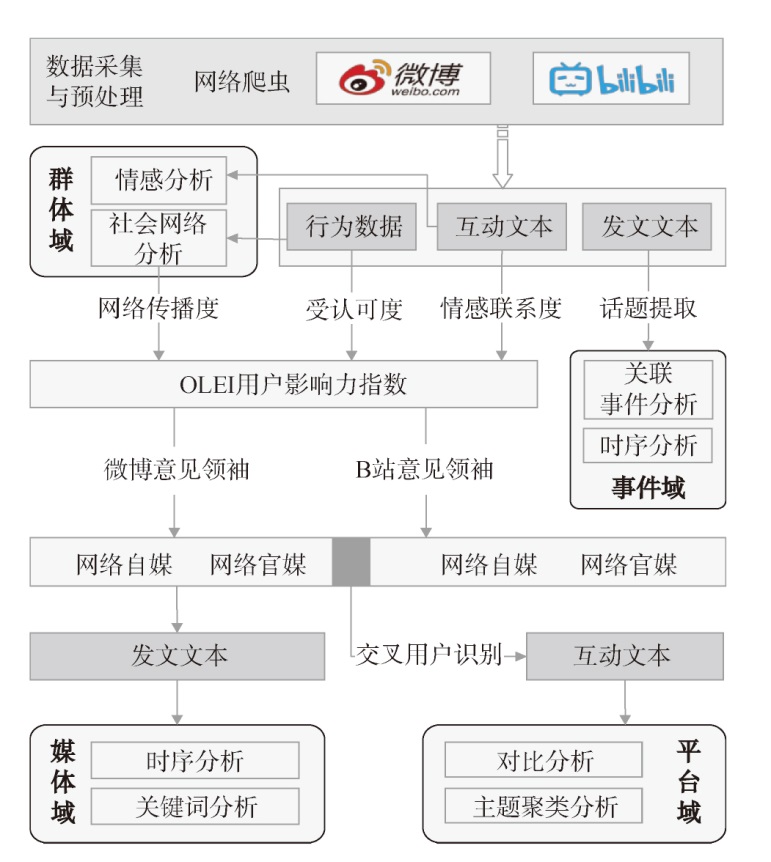
【目的】 跟踪和观测突发事件舆情流转特征,辅助实现舆情导控和共景治理。【方法】 利用案例研究法,提出突发事件舆情宏观流转域框架;利用社会网络分析法,辅以实证研究和自然语言处理技术深入分析微观视角下舆情在主体、客体、载体各维度间的流转规律,结合突发公共卫生事件数据进行验证性分析。【结果】 从宏观角度看,舆情在网络空间、物理空间和心理空间流转,为理解和量化公众行为和反应提供跨学科的分析框架;从微观角度看,舆情在多元群体、多元媒体、多元事件、多元平台层面流转,分别呈现出同质化扩散与异质化穿越效应、场域共鸣与场域逸散效应、共时性和历时性效应、放大共振与回响差异效应。【局限】 未考虑社会网络情感的动态变化。【结论】 从宏观和微观两种视角总结舆情跨域流转规律,为舆情传播研究提供新的思路。
【目的】 跟踪在线学习者的学习进度和知识状态,以便提供个性化的学习支持服务。【方法】 提出一种细粒度学习能力增强的可解释知识追踪模型,从知识和细粒度学习能力两方面进行学习者认知建模,通过添加失误率参数改进项目反应理论,进而完成学习者下一时刻答题结果的预测,并提供可解释性。【结果】 在三个公开数据集的实验表明,本文提出的知识追踪模型在AUC指标上相较于大部分基线方法,至少提升2%左右。【局限】 本文方法从增加学习因素的角度提升知识追踪模型的可解释性,但在提升基于深度学习的知识追踪模型可解释性方面需要进一步验证。【结论】 本文提出的知识追踪模型不仅在预测性能上有很大提升,而且能够从多个角度刻画学习者认知模型和预测过程,提高了知识追踪模型的可解释性。

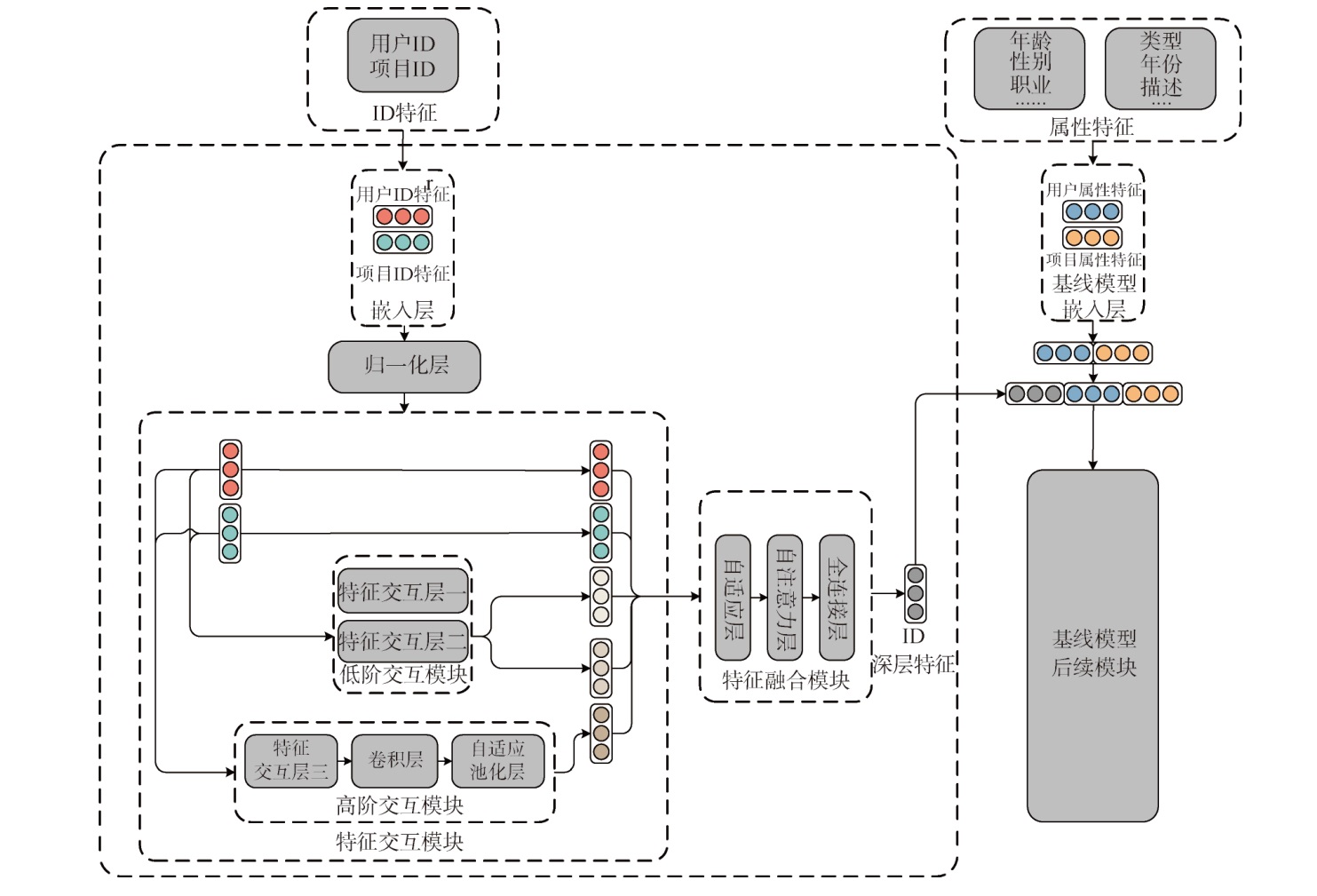
【目的】 充分挖掘ID特征中蕴含的深层信息,提出一种基于ID特征的深度交互与自注意力融合推荐模型DFM-ID。【方法】 提出一个ID特征深度学习框架,设计三种特征交互层与基于自注意力机制的融合模块,对ID特征进行低阶与高阶交互,并基于自注意力生成ID深层特征。【结果】 在三个公开数据集上进行实验,结果表明集成DFM-ID的模型在准确率、精确率、AUC和F1值评估指标上相较于基线模型,分别增长了16.03%、14.10%、20.97%和8.68%。【局限】 实验数据同质性较高,模型在一定程度上泛化能力不足。【结论】 所提模型能充分利用ID特征间的复杂关联和深层信息,有效提升推荐准确性。
【目的】 利用影响因素挖掘生物医学文献中疾病与疾病之间的关系,为疾病关联分析提供新视角。【方法】 基于影响因素在共病管理上的重要作用,通过依存分析完成疾病-影响因素实体关系抽取,结合复杂网络分析技术进行疾病社区发现,构建基于影响因素的疾病关联模型,并使用中华医学期刊全文数据库的部分数据进行验证。【结果】 基于影响因素的疾病关联模型构建了105个疾病节点、453个影响因素节点和2 067条边的加权网络,发现影响因素介导的9个内部关联紧密的疾病社区,进而实现疾病关联分析。【局限】 复杂长句的疾病-影响因素获取效能较低,降低疾病关联的数量。【结论】 模型能够获取更细粒度的疾病-影响因素关系,具有更好的代表性和可解释性,可以为疾病关联分析和共病共管提供新的研究思路。

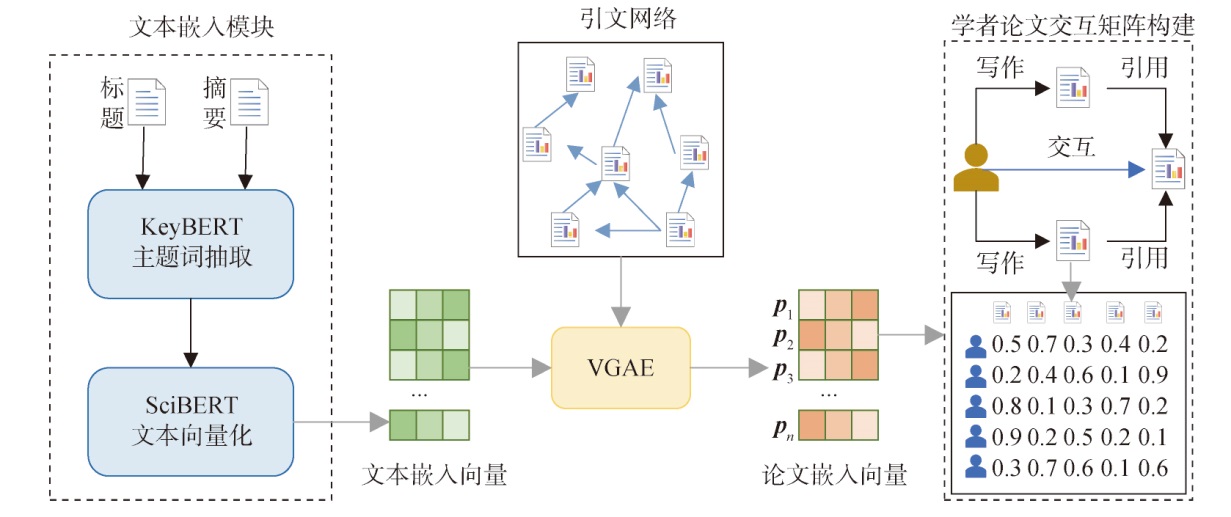
【目的】 针对难以准确捕捉学者研究兴趣的问题,提出一种融合论文内容与引用特征的学者研究兴趣发现方法,并据此构建基于学术知识图谱与随机游走算法的论文推荐模型。【方法】 使用预训练文本嵌入模型与引文网络学习已发表论文的向量表示,基于相似性理论挖掘学者研究兴趣;运用知识图谱嵌入、有偏随机游走与注意力机制等深度学习技术计算学者对论文感兴趣的概率,最后生成论文推荐列表。【结果】 在DBLPv14数据集上的实验结果表明,所提模型相较于基线模型在F1值与MRR指标上最多分别提升0.041和0.031,各指标结果总体优于基线模型。【局限】 所提模型未考虑到实体和关系上的属性对推荐性能的影响。【结论】 所提模型考虑了论文内容与引用特征,能够有效反映学者的研究兴趣,提高论文推荐准确性。
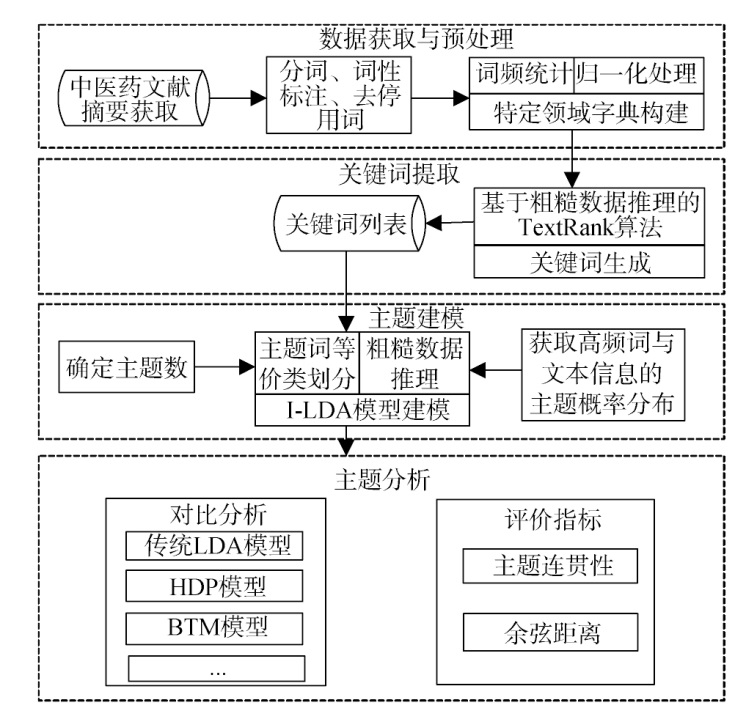
【目的】 解决传统LDA模型在短文本,尤其是中医药论文摘要中专业术语较多,主题术语的可解释性较差的问题,提出一种融合粗糙数据推理改进的LDA模型(I-LDA)。【方法】 使用融合粗糙数据推理的TextRank算法,提取出最具代表性的关键词。通过构建特定领域的字典,提高领域词汇权重。结合粗糙数据推理扩大主题词选词范围。【结果】 I-LDA模型在主题连贯性和主题间距离方面,相较于传统LDA模型,分别提升了约5.6个百分点和1.8个百分点。【局限】 由于中医药论文摘要文本中的专业词汇较多,实验中预设的词典可能无法全面覆盖所有相关术语,从而影响模型在主题建模中的表现。【结论】 I-LDA模型在中医药论文摘要的主题建模中表现较优,且识别的主题更具代表性和专业性。
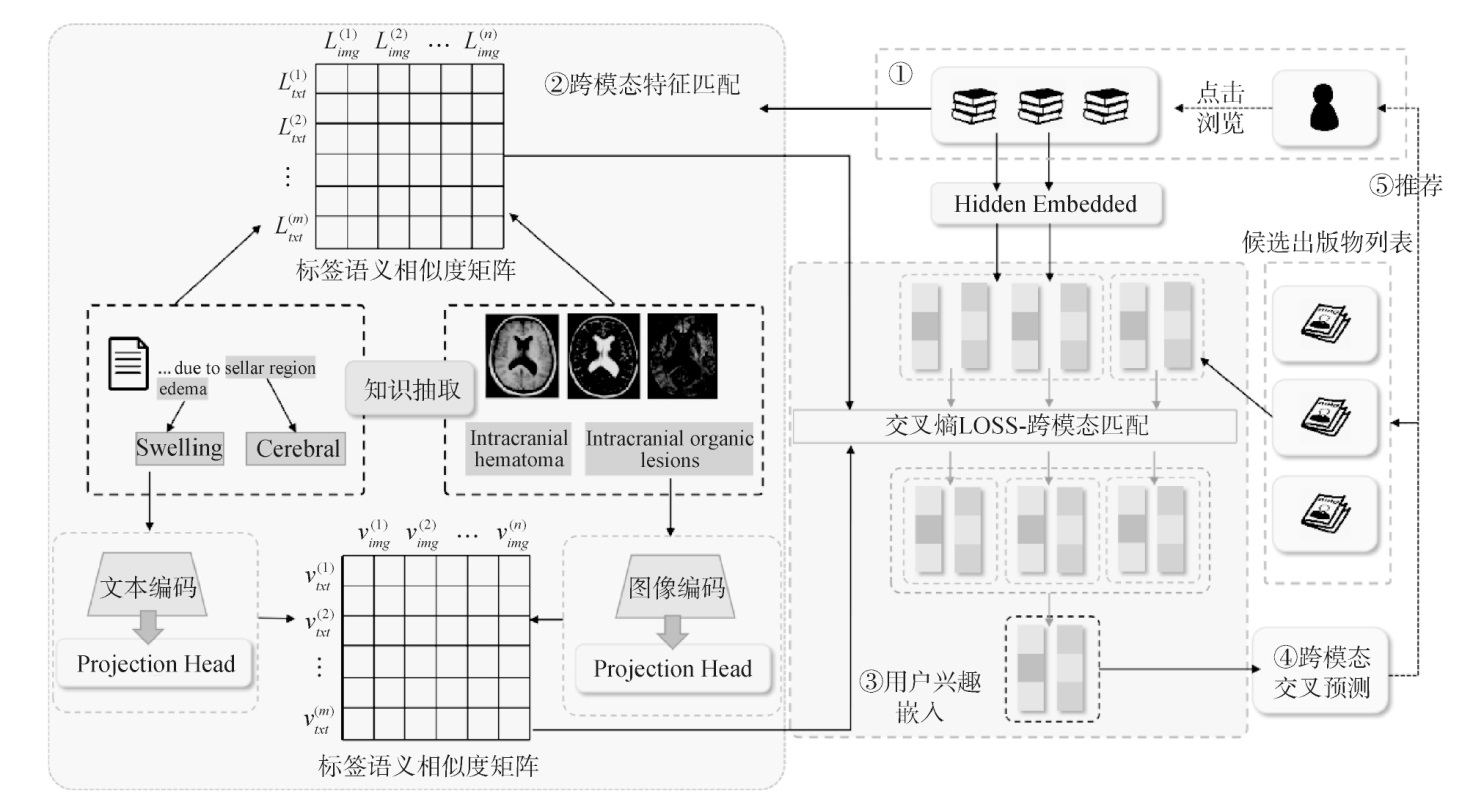
【目的】 提出一种医学出版物推荐模型,运用跨模态信息提高推荐的准确率。【方法】 首先利用医学术语系统将标签内容标准化,将图文标签进行配对,再利用配对的语义标签通过对比学习将图像与文本之间的特征语义进行对齐,进而基于对齐的特征语义构建跨模态交叉注意力机制,并通过用户对不同模态兴趣权重预测用户对出版物的偏好。【结果】 在两个出版物数据集上与三种最新的多模态基线模型进行对比实验,模型的精确率平均为62.79%,F1值平均为53.62%,NDCG平均为61.17%,各指标结果总体优于基线模型。【局限】 对于仅包含单一模态的预训练数据可能需要额外的冷启动方法。【结论】 所提模型跨模态信息特征的融合能力强,可以有效缓解不同模态间语义鸿沟问题,提高医学出版物推荐的准确率。
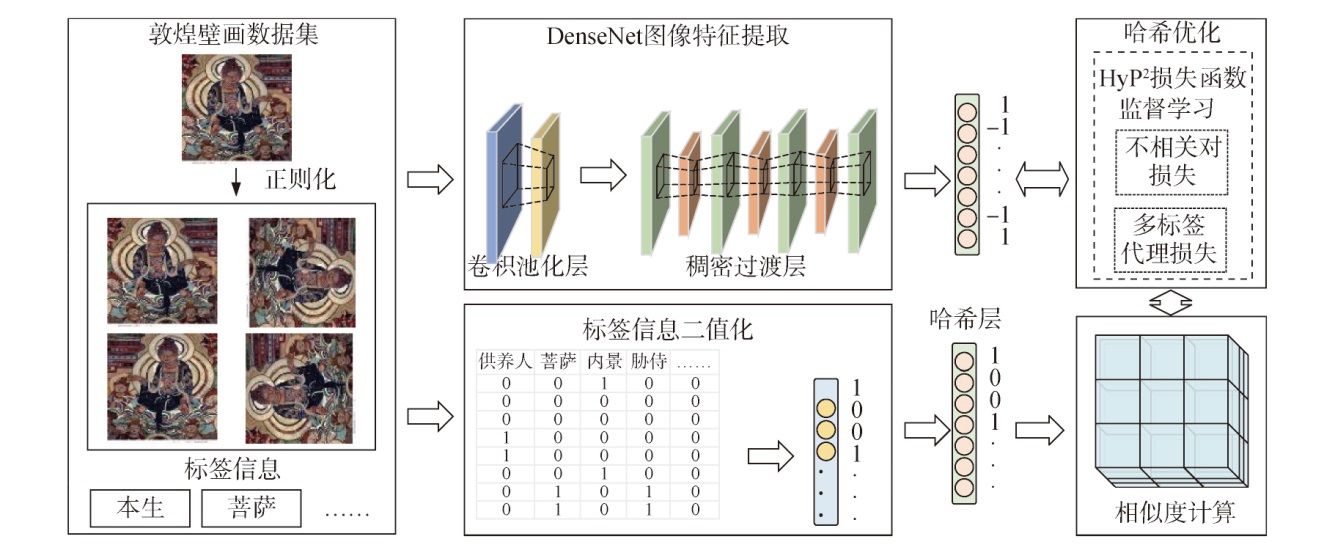
【目的】 从多标签的角度提高用户对于敦煌壁画的图像检索效率,设计面向敦煌壁画的多标签图像检索模型(DNHMIR)。【方法】 首先,搜集敦煌壁画图像并从主题和内容的角度进行多标签标注;其次,通过DenseNet提取图像特征,结合哈希进行压缩编码;然后,结合标签信息利用余弦相似度进行图像匹配,并按照相似度大小排序;最后,使用HyP2损失函数对模型哈希码生成进行评估与优化。【结果】 基于DenseNet哈希的多标签图像检索模型在构建的敦煌壁画多标签数据集上取得了较好的检索效果,mAP@7000达到0.884,相比于基线模型至少提高了0.044。【局限】 图像特征映射为哈希编码会导致部分图像信息丢失,且忽略了用户群体间的认知差异。【结论】 本文面向敦煌壁画构建的DNHMIR模型能够准确检索到多标签图像,降低了存储空间和检索时间,提高了敦煌壁画的检索效率。
【目的】 解决手动睡眠分期方法耗时烦琐和现有自动睡眠分期模型训练时间长、识别效果不佳等问题,提升睡眠分期预测的准确性和鲁棒性。【方法】 设计基于离散小波和残差收缩网络的睡眠分期模型(WaveSleep)。首先,使用离散小波变换对原始脑电信号数据进行分解,然后通过两个不同尺寸的卷积神经网络进行多分辨率的特征提取。接着,使用深度残差收缩网络对特征在通道层面的相互依赖关系进行建模。最后将部署了多头注意力的时间上下文编码器用于有效捕捉特征中的时间依赖关系。【结果】 所提模型在三个公共睡眠数据集上的分类准确率分别达到85.4%、81.9%和84.4%,与最优基线模型相比分别提高1.0、0.6、0.2个百分点。【局限】 所提模型在类别不平衡的数据集上准确率提升有限。【结论】 WaveSleep模型能够有效提升睡眠分期预测的效率和准确性,并且具有显著的鲁棒性。