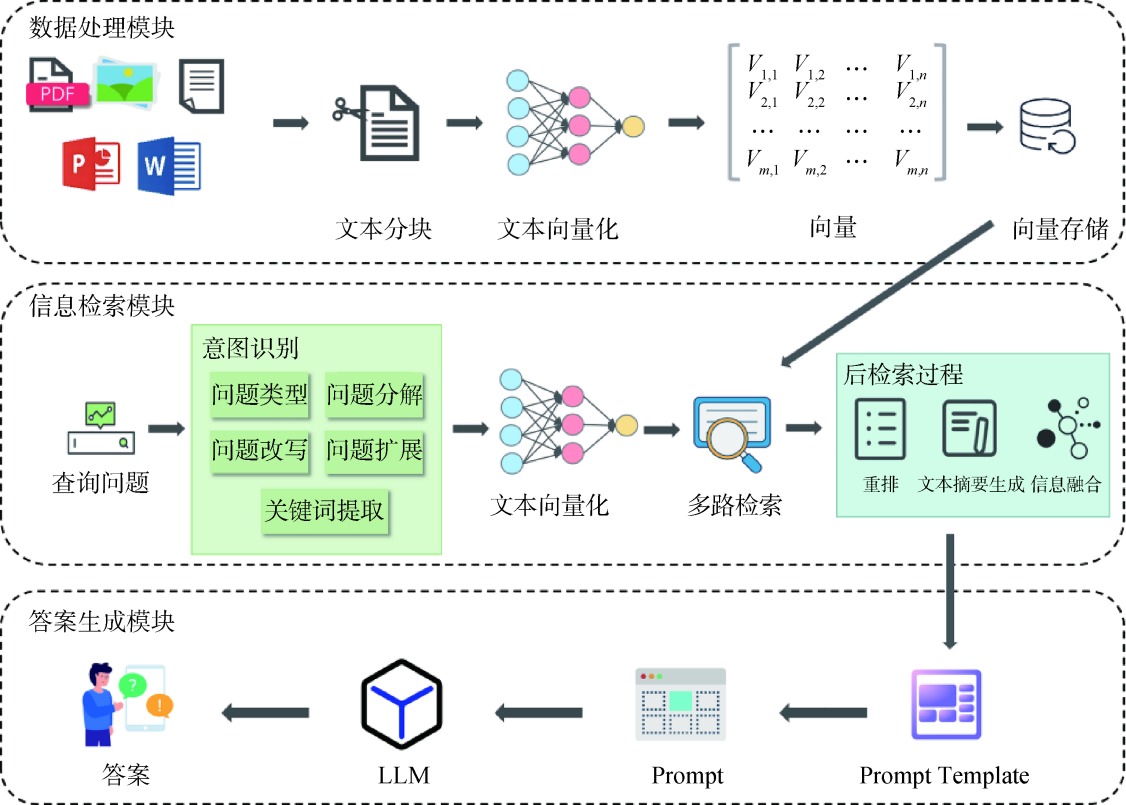
【目的】 感知用户个人及其好友对商品流行度产生的偏好,实现更准确的推荐。【方法】 本文提出融合贡献度和影响力的项目流行度计算方法,使用注意力机制和循环神经网络来捕捉用户流行度偏好表征,并使用卷积网络和图注意力机制获取好友的长短期流行度偏好。【结果】 在Douban数据集、Delicious数据集、Yelp数据集上进行对比实验,本文方法的评价指标均优于次优模型DGRec,Recall@20最高提升13.03个百分点,NDCG最高提升11.69个百分点。本文提出的流行度计算方法相比于传统的计算方法,Recall@20最高提升11.53个百分点,NDCG最高提升10.29个百分点。【局限】 本文方法在处理短序列时仍需提升性能。【结论】 本文方法增加了用户流行度偏好表征和用户社交流行度偏好表征,增强了对每次交互权重的表达能力,可以实现对更多长尾项目的有效推荐。
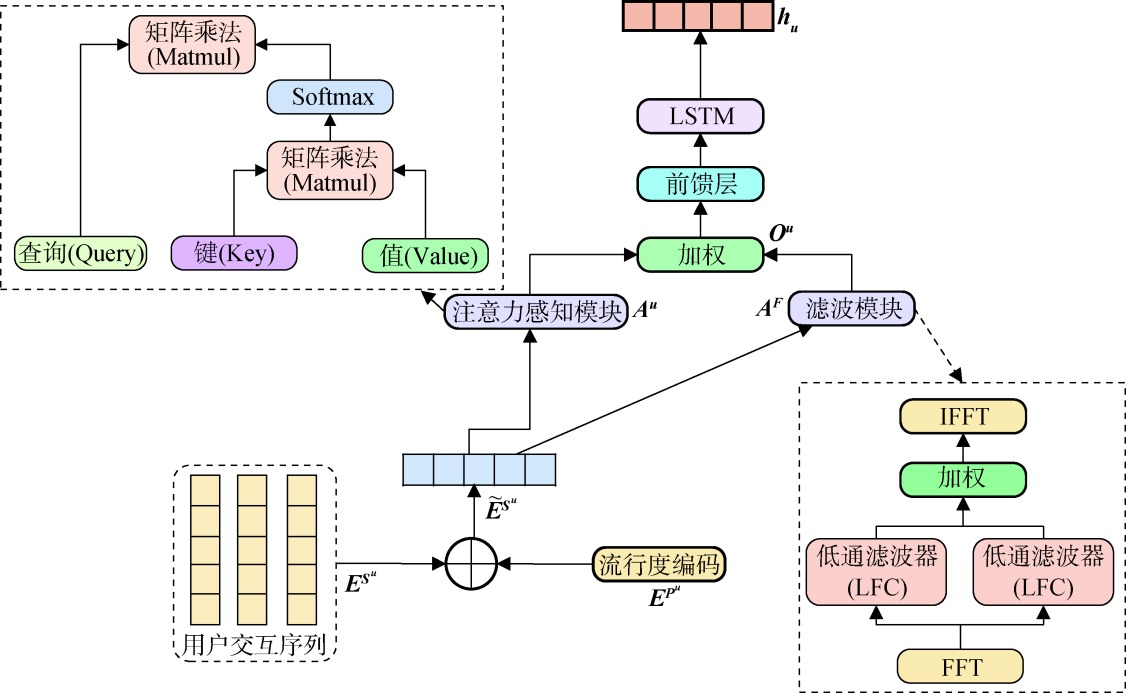
【目的】 探讨产品领域知识以及图文动态交互对评论有用性的影响,提升多模态评论有用性识别的性能。【方法】 提出一种领域知识增强的多模态评论有用性识别方法,首先基于评论的隐含主题信息识别领域关键词,并利用主题注意力机制获得评论的领域知识特征表示;接着设计一个知识增强的图文动态交互模块,通过知识增强模态内自注意力机制获得知识与评论图文进行动态交互后的特征表示,通过知识增强模态间协同注意力机制获得知识增强的文本与图片进行动态交互后的特征表示。【结果】 在亚马逊数据集上的F1-Score达到89.57%,比最优基线模型提高了0.90个百分点。【局限】 仅在英文数据集上进行实验,在中文数据集上的性能有待进一步研究。【结论】 利用领域知识对模型进行增强,不仅能有效提升评论有用性识别的性能,还能很好地提取图片和文本中的关键信息,提高模型的可解释性。
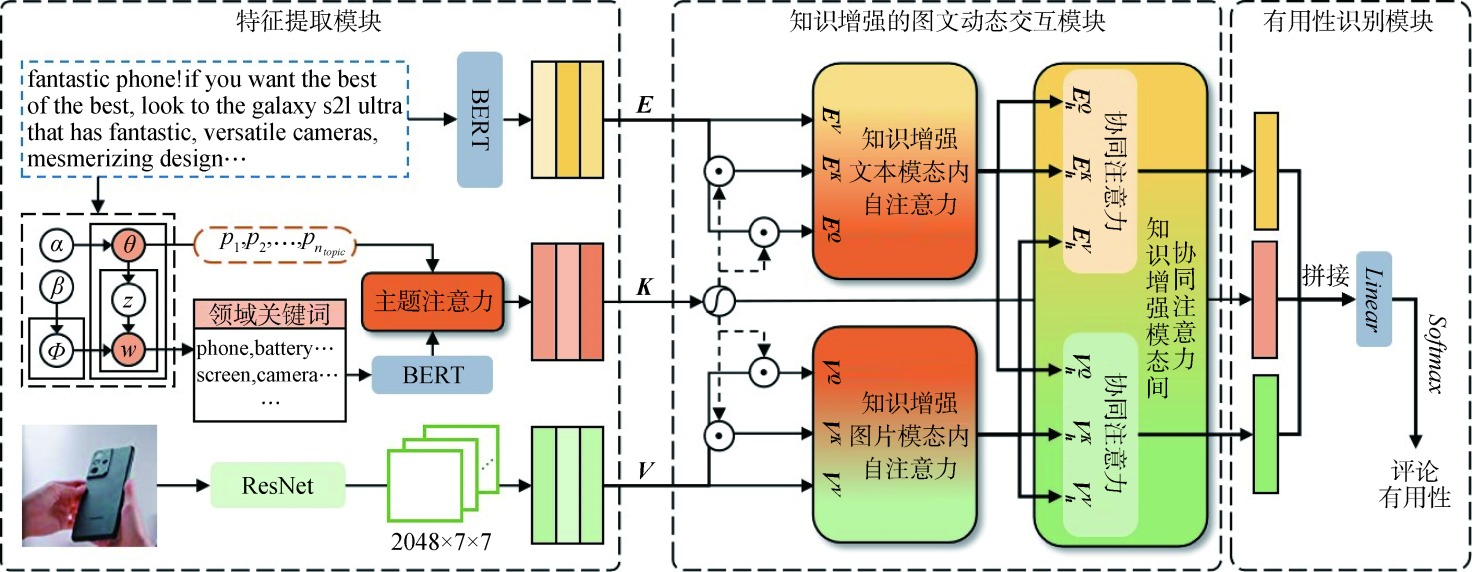
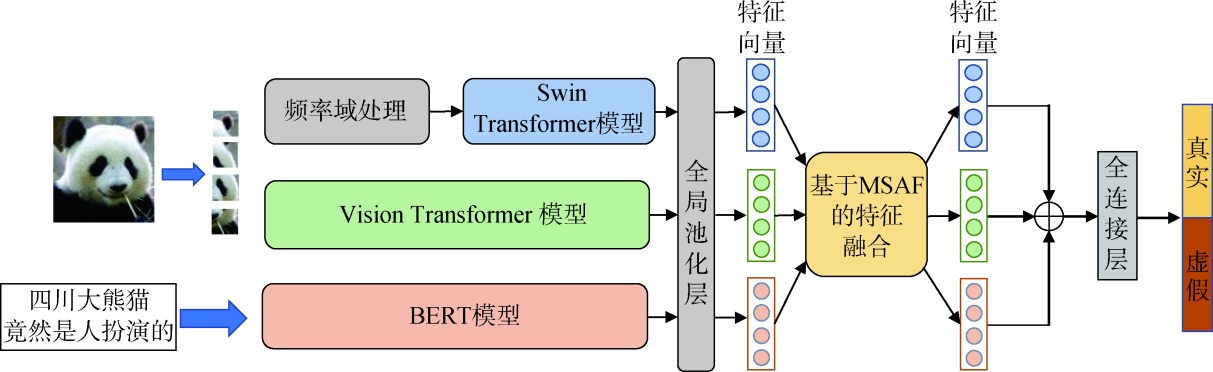
【目的】 针对目前多模态谣言检测领域模态融合程度不足的问题,提出一种基于模态融合增强的模型MNEF,提升多模态谣言检测的准确率。【方法】 提取图像的在频率域处理后的特征作为一种补充模态,并使用特征融合工程对文本、图像与频率域的特征向量进行融合,以捕获模态之间的深层语义联系。【结果】 在两个数据集上进行对比实验,MNEF模型相较于最优基线模型,在准确率指标上分别提升3.02和0.81个百分点;同时,进一步的消融实验显示,MNEF模型比4个消融模型在准确率上分别提升1.51、4.68、5.07和4.61个百分点。【局限】 由于增加了频率域的处理分支,模型整体的复杂度与计算量有所上升。同时,模型仅基于图像与文本进行处理,未能考虑到其他模态的谣言。【结论】 在使用频率域处理与特征融合进行模态增强后,模型可以捕获到模态之间的深层语义联系。
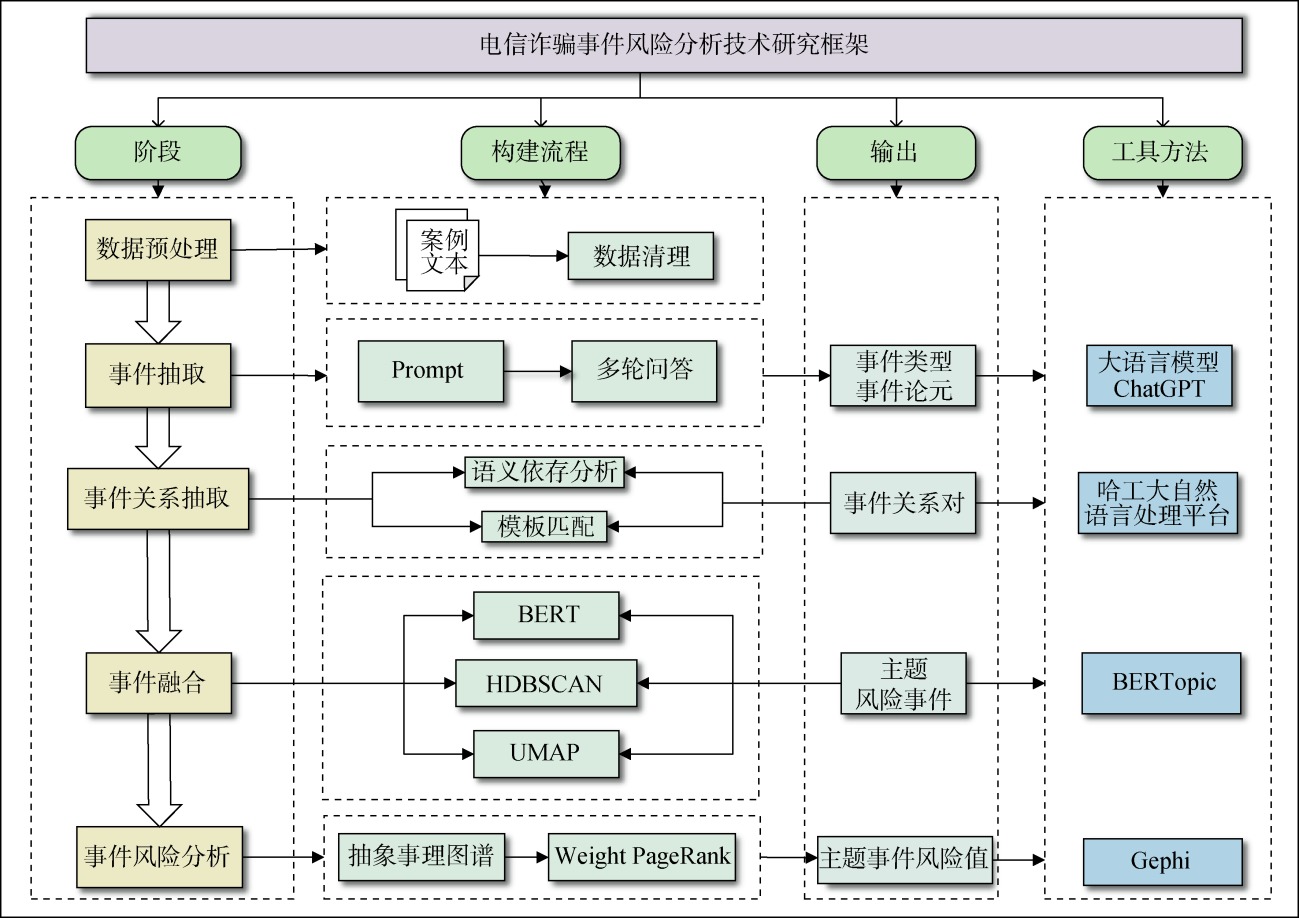
【目的】 为揭示电信诈骗发生过程并发现关键风险因素,提出基于大语言模型和事件融合的电信诈骗事件风险分析研究框架。【方法】 通过构建电信诈骗领域两阶段层次化提示指令,抽取诈骗案例相关风险事件和事件论元,结合语义依存分析和模板匹配方法得到诈骗事件链条;同时,考虑到事件表述的多样性,基于BERTopic模型进行句向量表示,采用聚类算法进行事件融合。【结果】 在电信诈骗案例上的事件抽取和论元抽取F1值达到67.41%和73.12%,事件聚类得到10类主题风险事件,“提供信息”行为风险最高。【局限】 警情数据粒度比较粗,支撑预警能力不够强大。【结论】 采用大语言模型和事件融合聚类方法,能够完成事件演化链路的自动构建,分析事件的风险值,对电信诈骗的预警和劝阻有支撑作用。
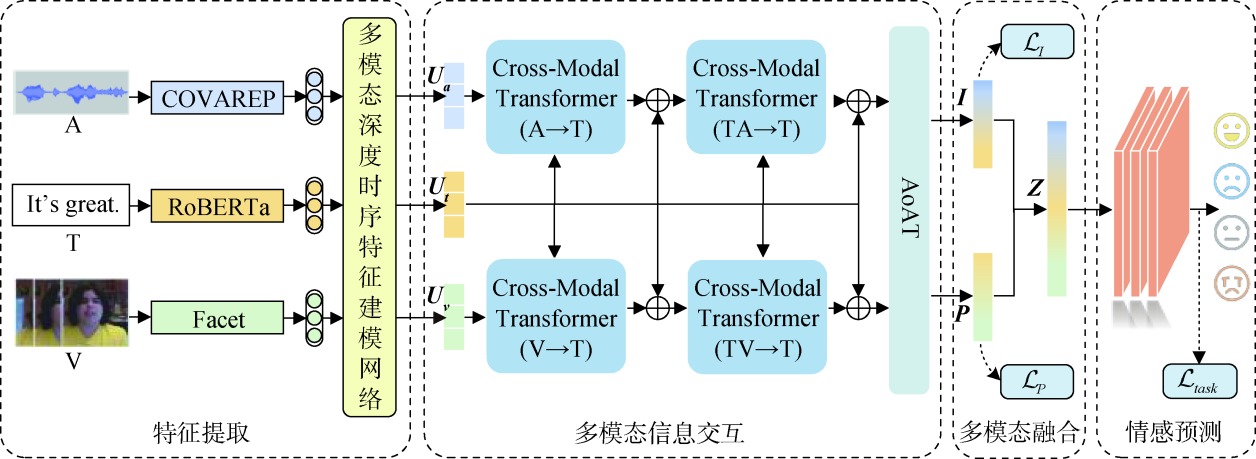
【目的】 针对多模态情感分析中存在的多模态特征提取不充分、模态间语义特征差异性和交互性不足等问题,提出一种融合多层次注意力和情感尺度向量的时序多模态情感分析模型。【方法】 首先,引入标量长短期记忆网络,结合多头注意力机制,构建多模态深度时序特征建模网络,以提取文本、音频和视觉模态的丰富上下文时序特征;其次,利用文本引导的双层跨模态注意力机制和改进的自注意力机制,实现模态间的深层信息交流,生成用于分析情感强度和情感极性的两种情感尺度向量;最后,将情感强度向量的L1范数与情感极性向量归一化后相乘,得到强度和极性的综合表达进而实现精准的情感预测。【结果】 在CMU-MOSI数据集上本文模型的对比实验和消融实验均取得较好效果,在Acc7、Corr指标上较次优模型提升1.2和2.3个百分点;在CMU-MOSEI数据集上本文模型对比实验的各项指标均优于基准模型,Acc2和F1值达到86.0%、86.1%。【局限】 情感表达具有高度的情境依赖性,不同场景下的情感线索来源可能不同。在文本信息不足的情况下,本文模型可能表现不佳。【结论】 本文模型能够有效提取各模态的上下文时序特征,利用文本模态丰富的情感信息进行不同模态间的深层次交互,提升情感预测的准确性。
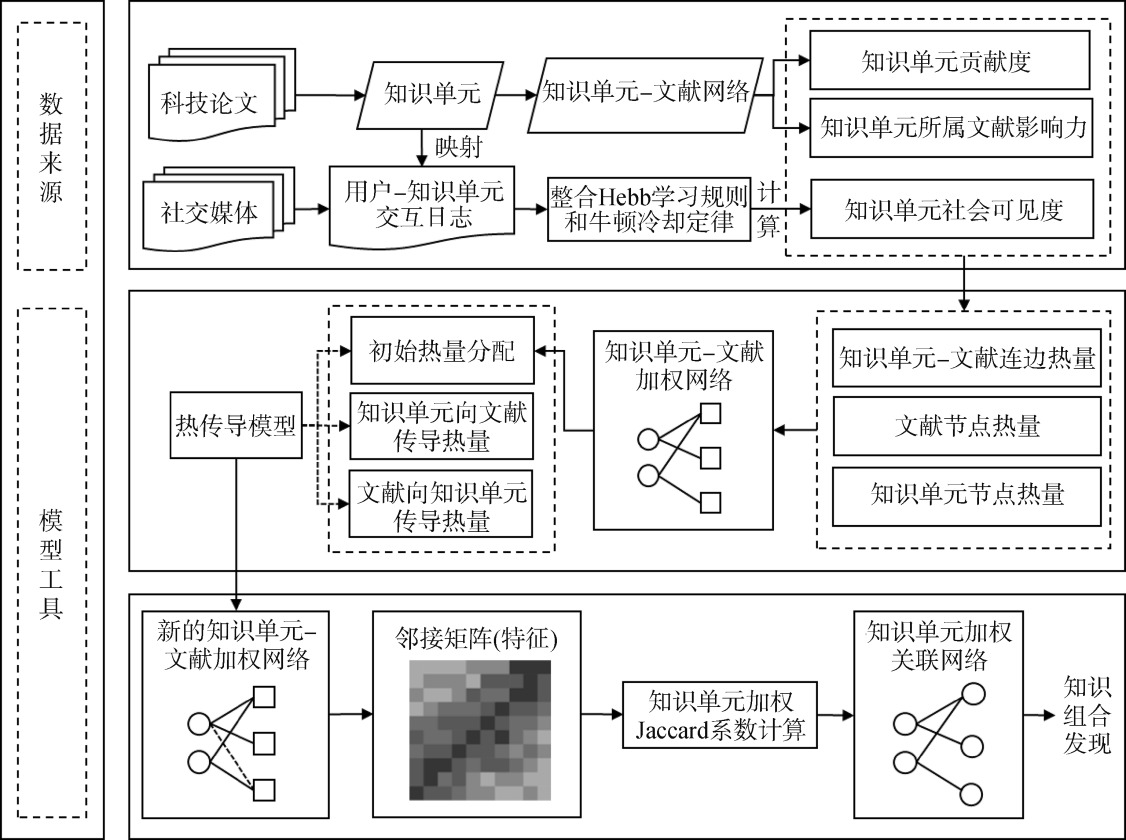
【目的】 同时从科研成果和社交媒体展开,融合多源知识单元价值与重要性语义特征,提出一种对中低词频知识单元关系敏感的知识组合发现方法。【方法】 首先从科研成果和社交媒体两个角度出发,设计并计算知识单元价值与重要性的语义特征;然后构建热传导模型融合多重语义,挖掘知识单元和文献之间的潜在关联;最后基于新的知识单元-文献网络计算知识单元间的加权Jaccard系数,实现知识组合发现。【结果】 以情报学CSSCI文献和百度百科为数据来源进行实证。在P@50、P@100、P@500、P@1000和P@2000指标上,融合特征的方法相较于未融合方法分别提升了0.300、0.230、0.184、0.183和0.278。未得到文献验证的组合,如“政务信息资源-产业智库联盟”“微博评论-隐喻识别”“社会影响理论-随机共振”等,也有较高的组合潜力和应用可解释性。【局限】 未进一步评价分析挖掘出的知识组合;知识单元之间细粒度的语义关系挖掘仍是待解决问题。【结论】 所提知识组合发现方法具有一定的可靠性和优越性,可以为未来的知识组合相关研究提供参考,发现的知识组合可以为学术创新及学科发展提供建议。
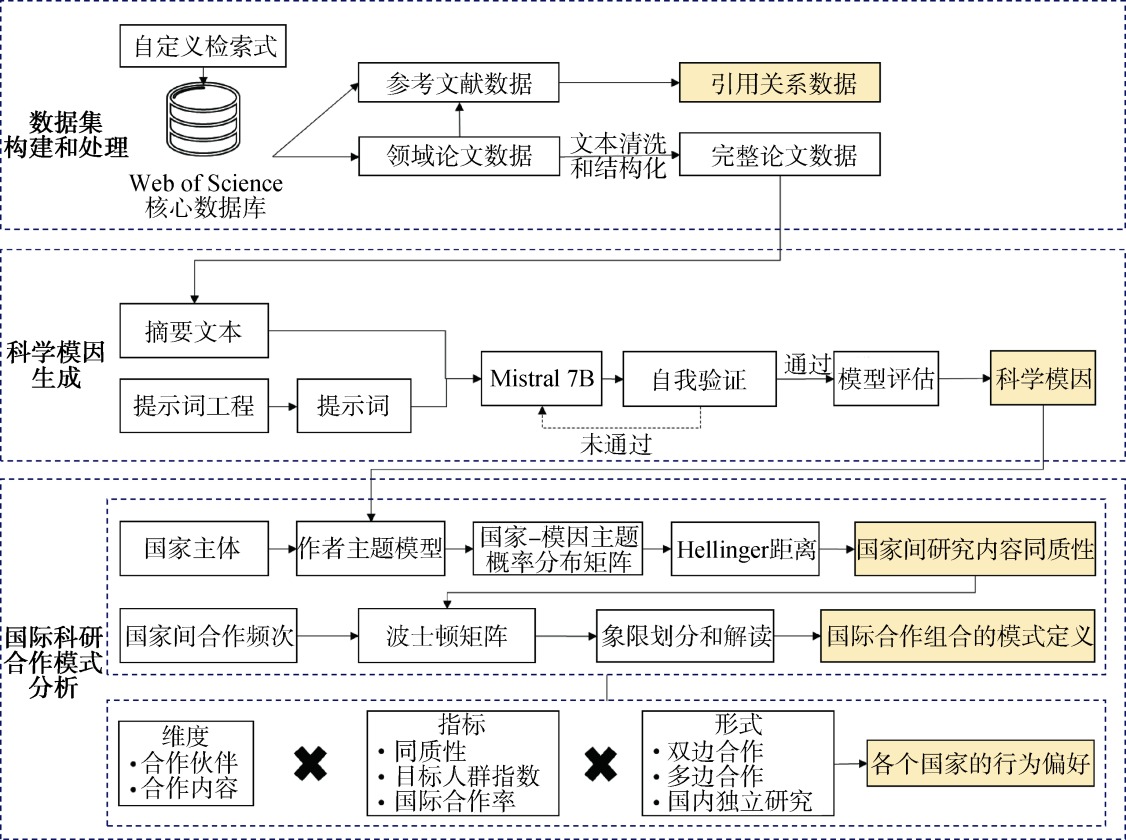
【目的】 从研究内容视角探究国际科研合作的模式和主体行为特征。【方法】 引入大语言模型和科学模因概念衡量研究内容同质性;基于研究内容同质性和合作频次划分合作模式,并从合作伙伴和合作内容的角度量化分析合作主体的特征。【结果】 在脑机接口领域开展实证。在合作模式上,核心国家以同质性和异质性合作模式为主,自由合作主要由新兴领域的探索性合作和依附性小国合作构成;在主体特征上,多数国家倾向于国际合作而非国内独立合作,且合作主导国和依附性小国在多边和单边合作中合作伙伴同质性高;中、英等国倾向于基于本国研究内容的国际合作,而美、德等国则偏好合作研究新内容。【局限】 仅涉及研究内容的同质性,未将更多因素的同质性纳入分析框架,缺乏全面性。【结论】 本研究丰富了国际科研合作模式分析的方法工具,为理解国际科研合作提供了新视角。
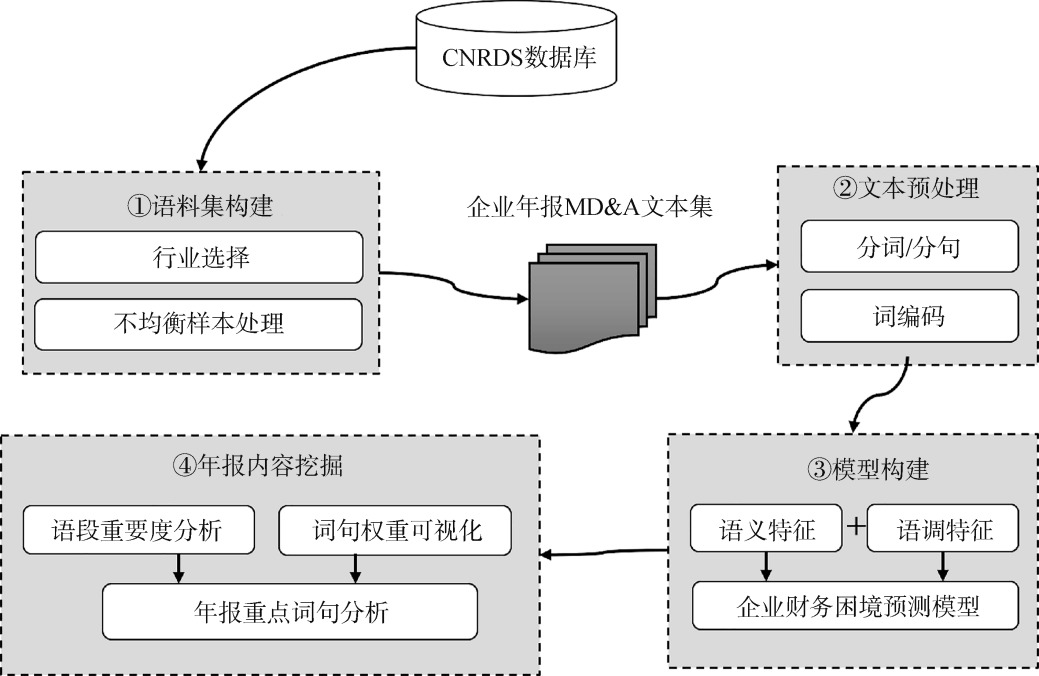
【目的】 研究上市公司年报中的管理层讨论与分析(MD&A)部分,挖掘其对企业财务困境预测的信息价值,以提升财务风险评估的准确性和实用性。【方法】 研究采用层次注意力网络(HAN)构建年报语义模型,通过HAN提取年报MD&A部分的语义向量,结合年报语调预测企业财务困境,并利用热力图直观呈现年报中预示企业财务风险的关键内容。【结果】 利用年报语义模型预测企业财务状况效果显著(AUC达0.895),MD&A首尾语句及语调特征对财务困境预测至关重要,关键风险信息聚焦政策、业务、业绩、治理和风险五大维度。【局限】 研究聚焦年报文本,未引入企业的财务指标和其他有价值信息。未来可探究年报与各类有价值信息的融合,进一步提升预测的准确性和全面性。【结论】 本研究通过HAN模型验证了年报中MD&A文本的语义特征对企业财务预测的重要价值,为投资者决策和企业信息披露优化提供了科学依据。
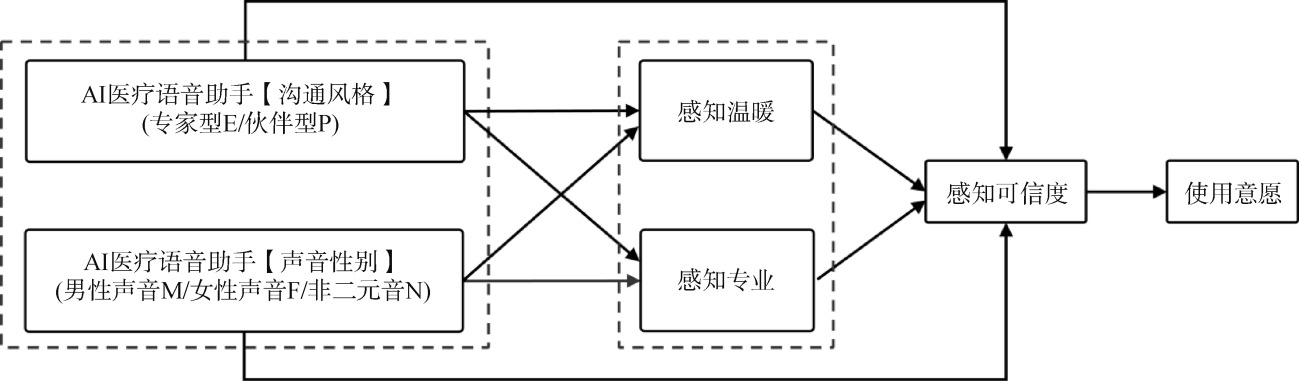
【目的】 本研究基于CASA范式及刻板印象模型,探索AI医疗语音助手的声音特征对老年人感知可信度的影响机制。【方法】 开展3(声音性别:女性/男性/非二元音)×2(沟通风格:专家型/伙伴型)的被试间实验,考察AI医疗语音助手的声音性别和沟通风格对老年人感知可信度和使用意愿的影响,以及在感知温暖和感知专业的刻板印象维度上的作用机制。【结果】 老年人对男性专家型和女性伙伴型的AI医疗语音助手的感知可信度较高,沟通风格通过感知专业影响老年人对声音性别的感知可信度,感知可信度能够正向影响和预测老年人对AI医疗语音助手的使用意图。【局限】 研究基于中国医疗体系智慧化建设状况展开,研究结论的普适性有待探讨。【结论】 声音特征与刻板印象的匹配对老年人感知可信度产生积极影响,在AI医疗语音助手的设计中,应考虑声音多种因素间的相互作用及场景适用性。
【目的】 通过知识蒸馏将来源于无监督数据的额外知识以训练数据的形式注入学生实体抽取模型,缓解古籍实体抽取任务有监督数据稀缺的问题。【方法】 使用大语言模型作为生成式知识教师模型,在无监督语料上进行知识蒸馏;基于《左传》和GuNer的有监督数据构造词典知识教师模型蒸馏词典知识,共同构建半监督古籍实体抽取数据集,将古籍实体抽取任务转换为序列到序列任务,再微调mT5、UIE等预训练模型。【结果】 在《左传》和GuNer数据集上抽取4类实体的F1值分别达到89.15%和95.47%,与使用古籍语料增量微调的基线模型SikuBERT和SikuRoBERTa相比,分别提升8.15和9.27个百分点。【局限】 未加入实体额外信息,受限于大模型生成的数据质量。【结论】 本文方法在低资源情境下,利用预训练大语言模型和词典资源的知识优势,将知识有效蒸馏到学生实体抽取模型,能显著提升古籍实体抽取的效果。

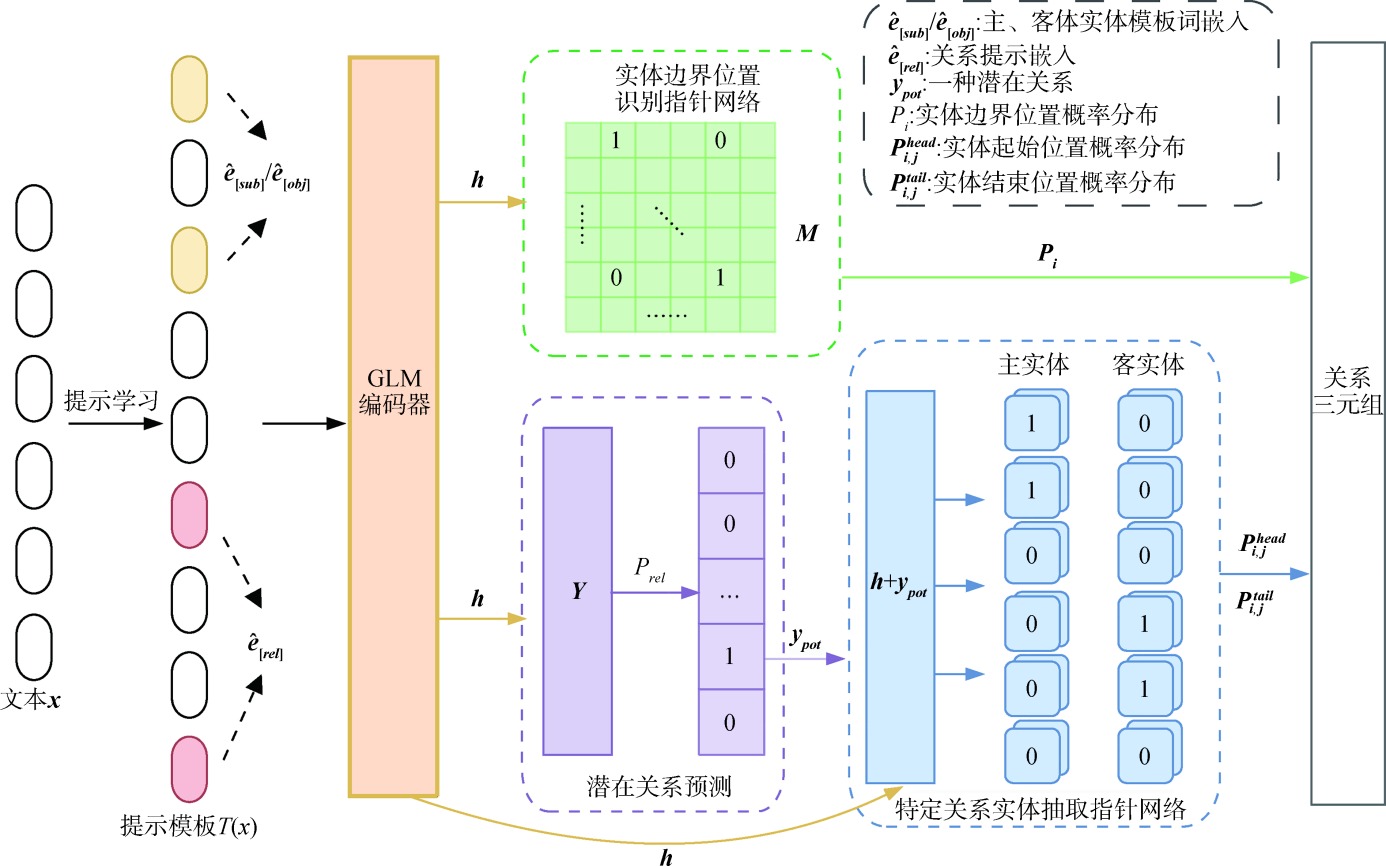
【目的】 针对旅游领域知识分散、标注数据有限导致的微调效率低、抽取性能不佳等问题,进行小样本场景下实体关系抽取方法的研究。【方法】 基于大模型GLM进行旅游领域的提示学习后,对输入文本进行编码表示,结合全局指针网络完成潜在关系预测和特定关系下的实体识别,抽取关系三元组。【结果】 在自建旅游数据集和百度DuIE数据集上进行实验,本文模型的F1值分别为90.51%和89.45%,较传统关系抽取模型分别提升2.37和0.16个百分点。【局限】 提示学习仅应用于旅游领域和特定编码器,在应用场景方面还有拓展空间。【结论】 本文方法能够更好地对旅游文本进行实体关系联合抽取,提示学习和大语言模型编码器可以缓解小样本场景下模型训练效果不佳的问题,有效提高实体关系抽取的准确率。
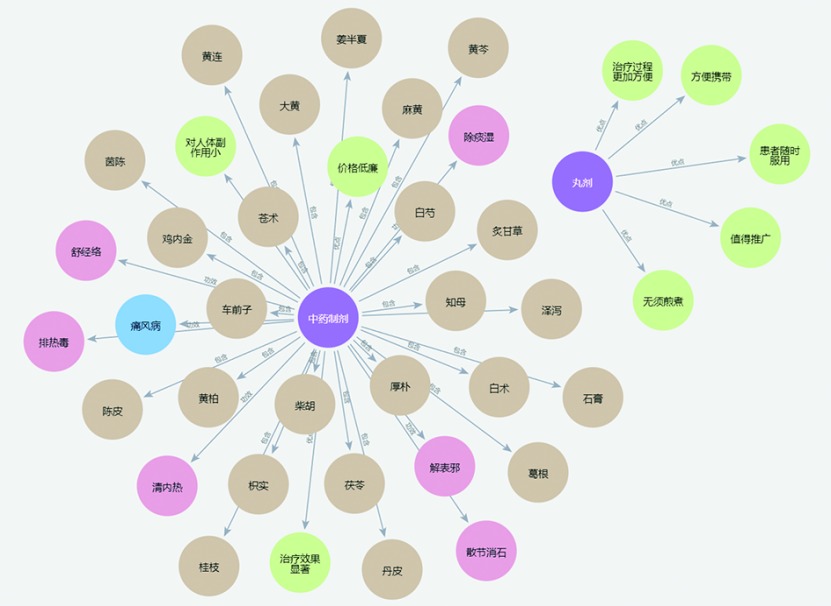
【目的】 解决中药专利文本中实体重叠和关系复杂的问题,提升中药成分、药理疗效、优点等实体关系的抽取精度。【方法】 提出一种中药专利文本实体关系联合抽取模型TPSCRE:结合词性标注网络和CDIL-CNN增强模型对中药专利文本的语义理解,利用双重Cross-Attention机制生成多样化词表示以增强实体和关系的信息交互和互补,通过对抗学习策略提高模型对潜在错误标注数据的鲁棒性和泛化能力;构建主客体对应矩阵过滤出正确的中药专利实体关系三元组。【结果】 在自建中药专利数据集上进行对比实验和消融实验,结果表明本文提出的TPSCRE模型表现最优,在中药实体识别和关系抽取上F1值分别为94.71%和87.56%。【局限】 模型复杂度和计算成本较高,评估标准受限于现有数据集的规模。【结论】 TPSCRE模型能更好地捕捉中药文本中实体间的复杂关系,在中药专利文本实体关系的联合抽取任务中有显著性能优势。
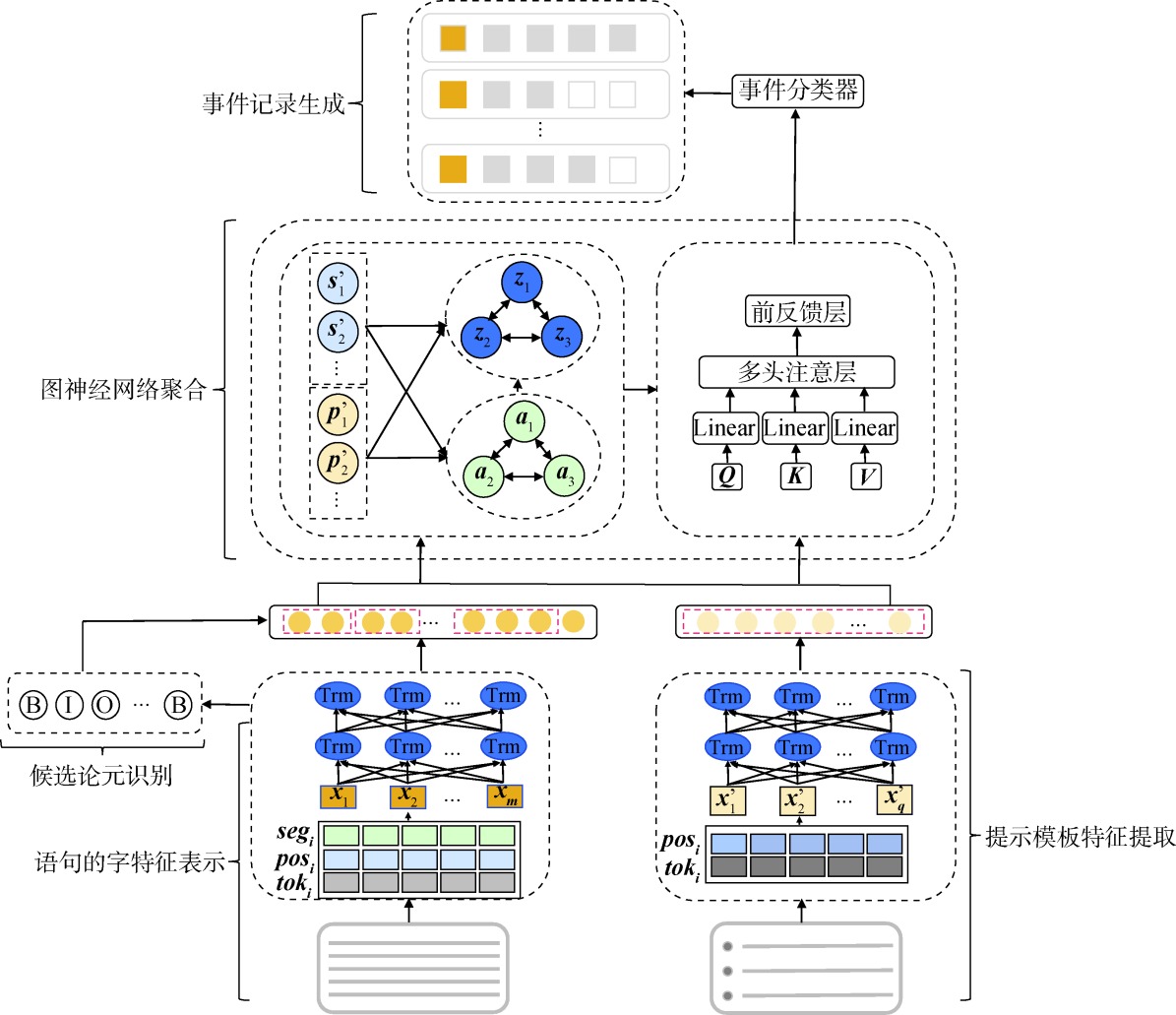
【目的】 针对文档级金融事件抽取中存在的论元分散和多事件问题,构建提示模板引导的文档级事件抽取模型DEEM-PT。【方法】 DEEM-PT设计了基于金融事件类型的提示模板,使用图神经网络和伪事件代理节点增强论元、句子和事件之间的关联,强化多事件之间的信息交互,并使用多头注意力机制对提示模板、论元和事件等特征进行融合。【结果】 在ChFinAnn数据集上的实验结果表明,DEEM-PT模型在各类金融事件上都有优异表现,准确率、召回率和F1值总体上分别达到85.2%、81.5%和83.3%。【局限】 DEEM-PT模型的训练基于金融领域事件数据集,因此提示模板设计依赖于领域知识和专家。【结论】 引入事件提示模板和在图神经网络中增加信息交互可以有效提升模型在事件类型和论元上的分类性能。
【目的】 构建基于检索增强的中医药标准知识问答系统,提供高效的标准知识服务,推动中医药标准化研究与应用。【方法】 对比BaiChuan、Gemma、通义千问等大语言模型的性能,选择GPT-3.5模型作为基础模型,结合数据优化和检索增强生成等技术,开发出具有语义分析、上下文关联和生成能力的中医药标准知识问答系统。【结果】 系统在中医文献问题生成数据集上的答案相关性精确率、召回率和F1值分别为0.879、0.839和0.857,上下文相关性分别为0.838、0.869和0.853,在中医药标准问答数据集上答案相关性分别为0.871、0.836和0.853,各项指标均优于对比模型。【局限】 当前系统在意图识别的准确性仍需进一步优化,中医药标准知识库规模和粒度有待进一步扩充和完善。【结论】 针对中医药知识服务的现实需求,构建了基于检索增强的中医药标准知识问答系统,该系统能够回答用户关于中医药诊疗指南、中药标准、信息标准等各类问题,包括治疗原则、病证分类、治疗方法、中医药标准内容技术要求等,展示出较高的实用性和可行性。