【目的】对2019~2023年间融合知识的视觉问答的主流模型与数据集进行综述。【文献范围】 以“融合知识的视觉问答”、“知识型视觉问答”、“基于外部知识的视觉问答”、“Knowledge-Based VQA”、“Knowledge-Based Visual Question Answering”、“Visual Question Answering Reasoning with External Knowledge”等关键词构建检索式,在中国知网、Web of Science等数据库中进行检索,最终确定102篇文献进行综述。【方法】根据融合知识的内容、方法对视觉问答模型进行分类,并比较优缺点;归纳相关数据集,比较分析主流模型的性能。【结果】当前研究聚焦于将多模态数据映射到文本模态进行推理,主要关注融合显式或隐式知识的视觉问答方法,但在衡量知识有效性、细粒度场景理解能力、数据集规模等方面存在不足。【局限】仅对已有研究的主流模型及训练结果进行结构化分析,缺少对算法原理的深入探讨。【结论】未来研究应继续探索集成显式知识与隐式知识的视觉问答方法,提高跨模态知识融合的语义挖掘能力与对齐能力,开发新的评估指标量化知识对模型性能的具体影响。

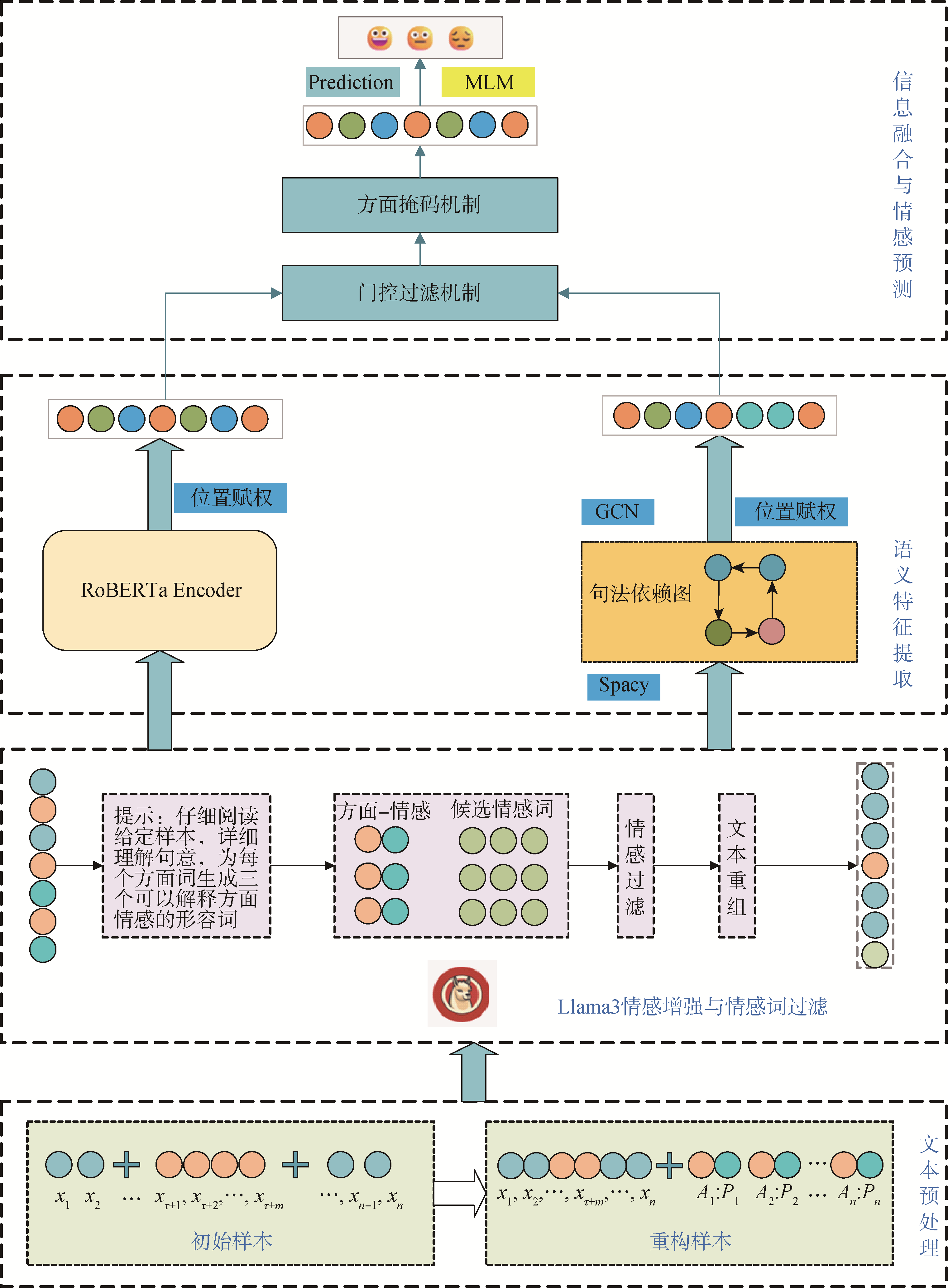
【目的】 为解决方面级情感分析中多方面语句中的语义偏移问题和隐性情感分析问题,提出一种基于大语言模型情感增强和图卷积神经网络的方面级情感分析模型。【方法】 利用提示学习引导大语言模型生成方面语义的情感知识增强表示,然后构建方面语义的情感知识增强图。此外,提出情感-目标位置赋权算法,过滤句法依赖图中无关信息,同时引入方面掩码与门控过滤机制以充分融合语义间信息,精确识别每个方面的情感倾向。【结果】 在所有实验数据集上,所提模型仅在Restaurant数据集上的准确率表现略低于其他两个基线模型,但其F1值仍高达81.60%。具体来说,所提模型在Laptop、Twitter和MAMS数据集上F1值均表现出显著提升,分别比最优基线模型提升了1.79、1.17和3.02个百分点。【局限】 未考虑视觉信息对方面级情感分析的作用,且仅针对英文数据集进行实验。【结论】 利用提示学习引导大语言模型生成情感表示词与图神经网络结合,提供一种有效且高效的方面级情感分析解决方案,显著提高文本方面级情感分析的准确性。
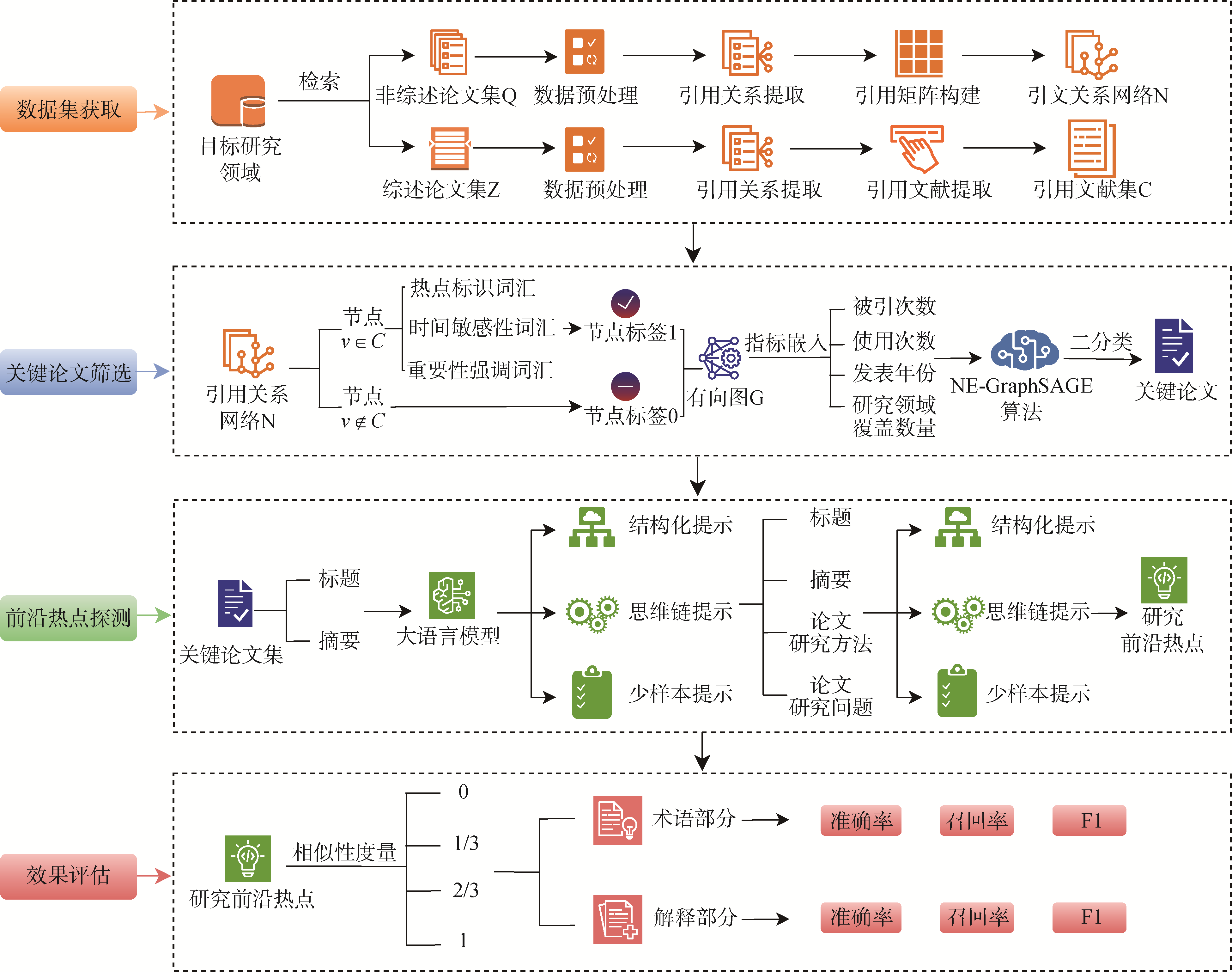
【目的】 为解决前沿研究热点的自动探测问题,提出一种利用图神经网络和大语言模型实现关键信息筛选与总结归纳的方法。【方法】 利用节点和边同时聚合的NE-GraphSAGE模型筛选出更可能揭示领域前沿热点的关键论文,以此为输入,综合采用结构化提示、思维链提示、少样本提示三种提示技术引导大语言模型探测领域前沿研究热点,并采用相似度度量评估其探测效果。【结果】 相比于基于节点聚合的N-GraphSAGE模型和基于边聚合的E-GraphSAGE模型,NE-GraphSAGE模型表现最优,测试准确率达到0.839 8。三种提示技术提升了大语言模型的探测效果,ChatGPT-4o探测结果中“术语”和“解释”部分的F1值分别达到0.73和0.77,同时可以看到长文本、多数量的学习样例不利于大模型探测推理。【局限】 仅以论文数据为单一探测源,数据分析维度不足。【结论】 本文提出的自动探测框架在一定程度上减轻了人为的主观影响,细化了探测颗粒度,为实现“人智协同”提供了参考视角。
【目的】 针对多模态情感分析中存在不同模态之间情感表达不一致的现象,影响多模态协同决策效果的问题,提出一种大模型特征增强与多层次交叉融合的多模态情感分析方法。【方法】 为缓解各模态之间的冲突情感信息,提高共性情感特征的表达,借助多模态大语言模型提取模态内部辅助性情感信息。利用层次化交叉注意力机制学习模态间的共性情感特征并挖掘模态内的辅助性情感特征,提高共性情感语义的表达。在融合阶段,提出一种模态注意力的加权融合方法,平衡共性情感特征与辅助性情感特征的贡献,并引入融合多模态与单模态的损失函数解决情感语义不一致问题。【结果】 本文提出的模型在公开数据集CH-SIMS和CMU-MOSI上的效果均优于对比模型。在CH-SIMS上,二分类准确率和F1值分别提升1.77和0.63个百分点;在CMU-MOSI上,二分类准确率和F1值分别提升0.43和0.41个百分点;在CH-SIMS情感不一致数据上,二分类准确率和F1值分别提升1.80和1.72个百分点,可以有效解决不同模态间的情感语义不一致问题。【局限】 未考虑到视频中人物的个性化信息带来的影响。【结论】 本文利用层次化交叉注意力机制有效融合各模态特征,可以提高共性语义的表达,有效解决不同模态间的情感语义不一致问题。
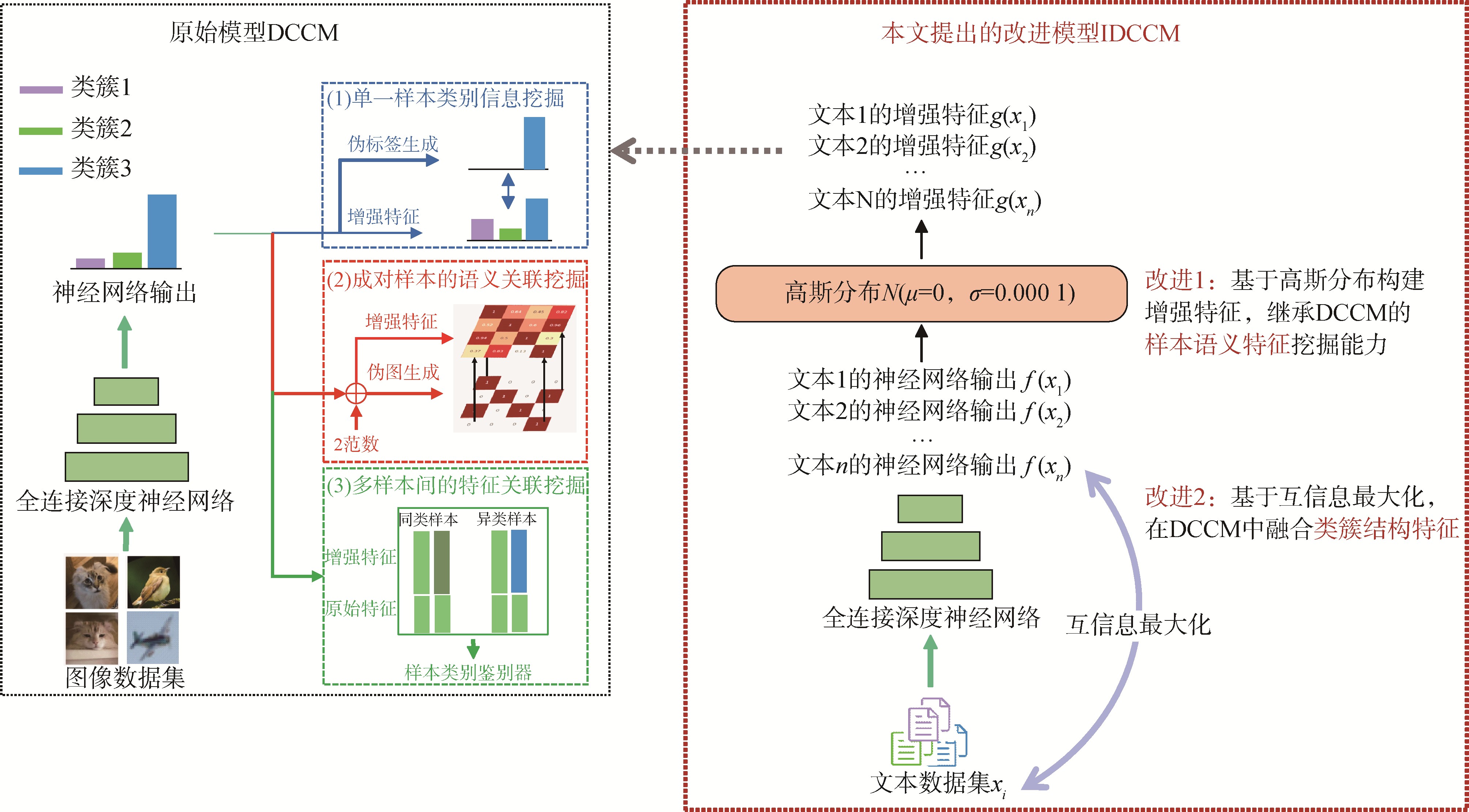
【目的】 针对深度综合关联挖掘图像聚类模型仅基于样本语义特征,无法充分利用类簇结构特征中蕴含的具有高判别性的类间结构关系的局限,进一步提升DCCM模型聚类性能。【方法】 提出融合类簇结构特征的改进模型IDCCM。首先,以DCCM作为基础聚类模型,引入基于高斯分布的文本数据增强策略,继承DCCM模型的样本语义特征挖掘能力。在此基础上,通过样本变量与类簇变量之间的互信息损失和DCCM模型原始损失的加权和,联合学习样本语义特征和类簇结构特征。【结果】 在公开标准数据集和科技论文摘要数据集上的实验验证了IDCCM模型的优越性。在公开数据集20NewsGroups和Reuters-60k数据集上改进模型的聚类准确率相较基准模型分别提升了9.80和6.60个百分点。【局限】 在实际应用中往往很难确定原始数据的最优类簇数量,需根据具体情况适当调整。【结论】 IDCCM模型能够挖掘利用类簇结构特征,提升了DCCM模型的聚类效果。
【目的】 鉴于司法裁判文书摘要需要与原文在基于案件事实、法律适用等要素方面保持一致,提出嵌入司法要素事实一致性评测的中文司法裁判文书摘要生成方法。【方法】 定义司法裁判文书摘要事实一致性判定的原则和方法;确定数据增加、事实一致性纠错和测评等预处理流程;分别构建分段抽取模型和引入司法要素知识图的生成式摘要模型,并在CAIL2020数据集上进行实验。【结果】 本文提出的FC-JDSM模型生成的摘要在指标ROUGE-N(N=1、2、L)、SRO、EM-FCJS上分别为67.98%、55.40%、64.14%、78.54%、90.01%,均优于比较模型。消融实验证实了分块抽取和事实信息引入的有效性。【局限】 事实一致性评测模型中的数据增强方案得到的数据与真实数据存在偏差。【结论】 将司法要素融入一致性评测和摘要生成过程中,能提高中文司法裁判文书摘要一致性,有利于司法工作的公正性。
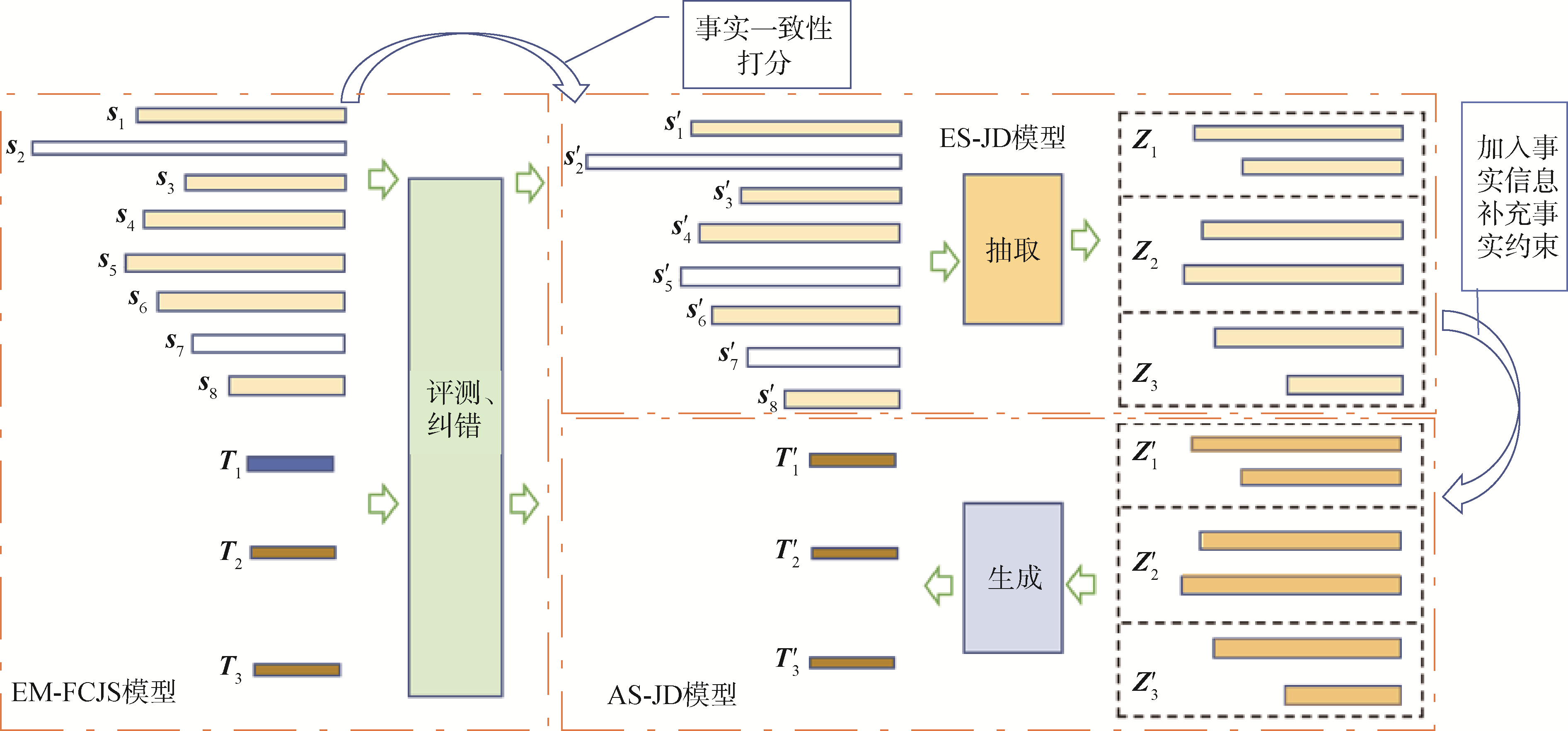
【目的】 针对现有社会化序列推荐研究容易引入与用户兴趣不相似的好友信息,且未能考虑不同用户受社交影响的程度,致使推荐性能受限的问题。为提升社会化序列推荐性能,提出一种基于图注意力网络的自适应社会化序列推荐模型。【方法】 首先,利用自注意力机制对用户行为序列建模,获取用户动态兴趣表示。其次,设计一种正则化限制的图注意力网络聚合好友特征,以准确建模用户社交兴趣表示。最后,提出一种基于注意力的自适应融合方法,准确融合动态兴趣与社交兴趣,生成推荐结果。【结果】 与主流基线模型相比,所提模型在HR@10上最高提升10.80%,在NDCG@10上最高提升5.29%。【局限】 所提模型对于社交网络结构的依赖性较高,当社交关系数据稀疏时,性能提升不明显。【结论】 所提模型可以更充分地利用社交信息,有效预测用户行为,提高推荐性能。
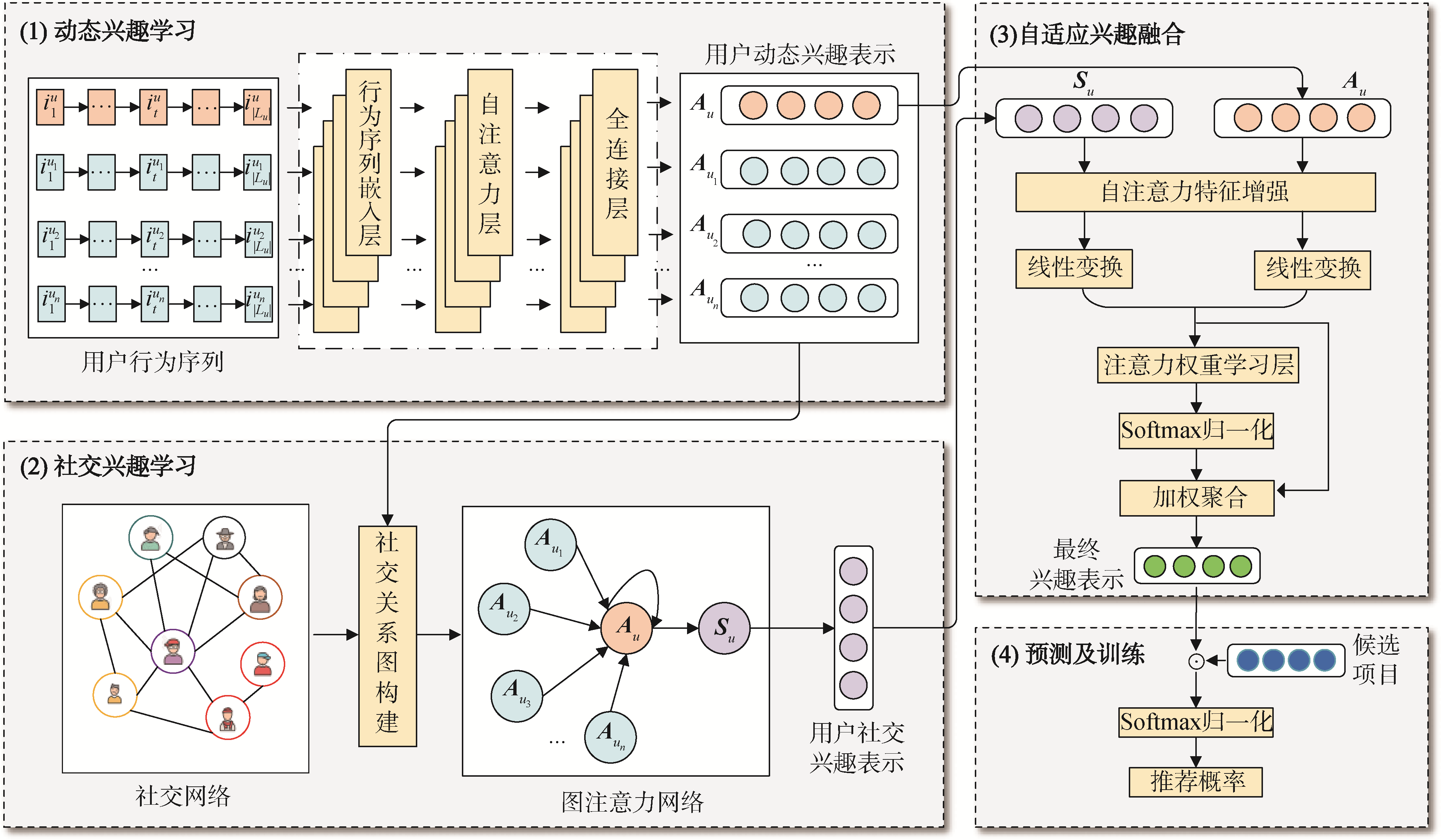
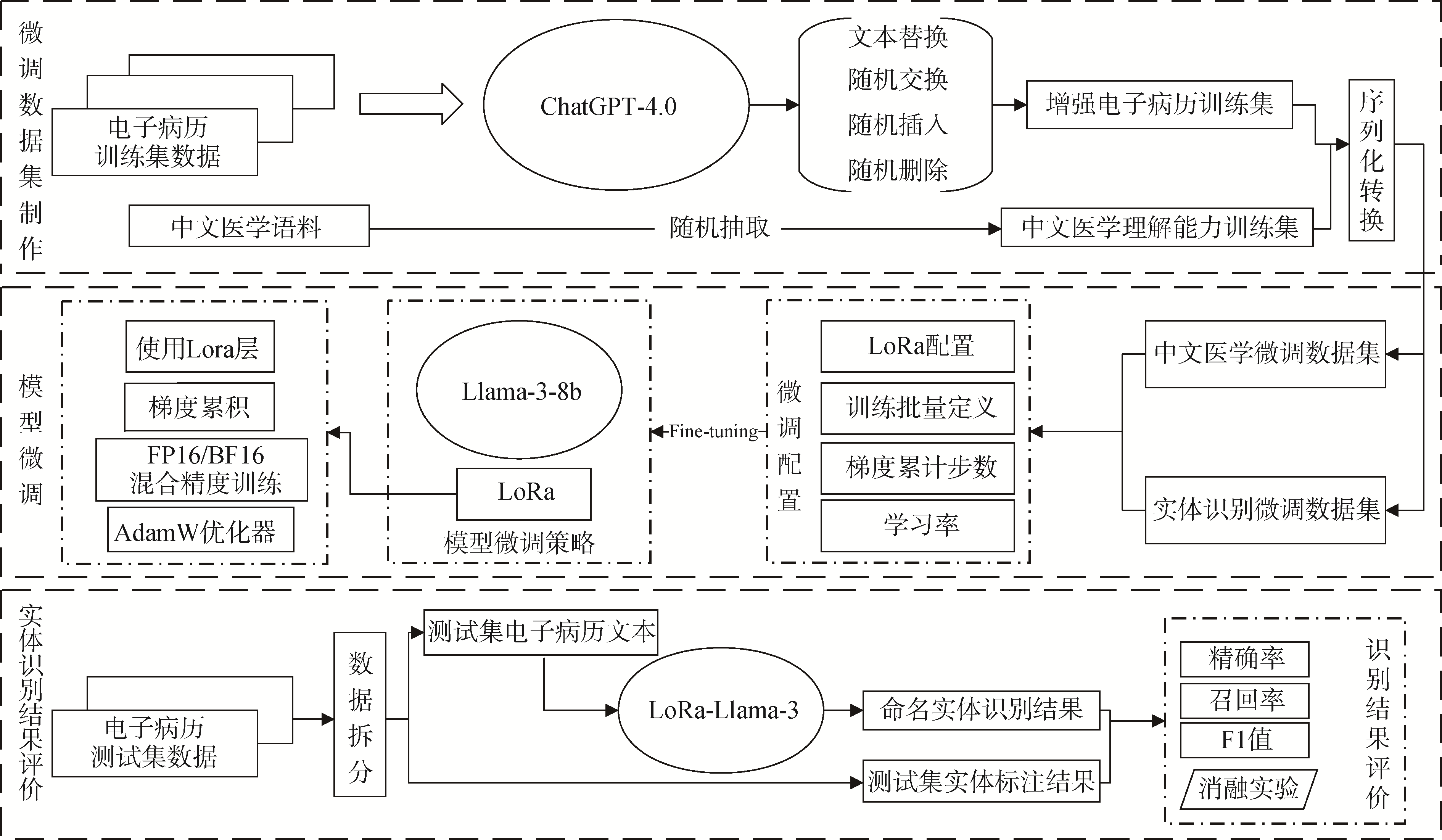
【目的】 将大模型技术应用于中文电子病历命名实体识别任务,以提高识别效果,促进中文医疗领域的智能化应用。【方法】 首先利用huatuo226K中文医学问答语料集,增强模型在医学领域的知识理解能力。随后采用Easy Data Augmentation (EDA)方法对CCKS2019电子病历数据集进行数据增强,并通过LoRa方法对Llama3-8b模型进行微调,最终形成专门用于中文电子病历命名实体识别的模型。【结果】 微调后的Llama3模型在CCKS2019中文电子病历数据集上表现显著提升,总体精确率达到0.888 9,召回率为0.866 0,F1值为0.877 3,较原始模型的F1值提高了0.161 1。【局限】 对实体重叠现象的研究不够深入,且不同实体类别的识别精确度存在一定差距。【结论】 提出基于大模型的中文电子病历命名实体识别模型,验证了大模型技术在中文医疗领域的应用潜力,为中文电子病历命名实体识别通用性模型的建立提供了基础。
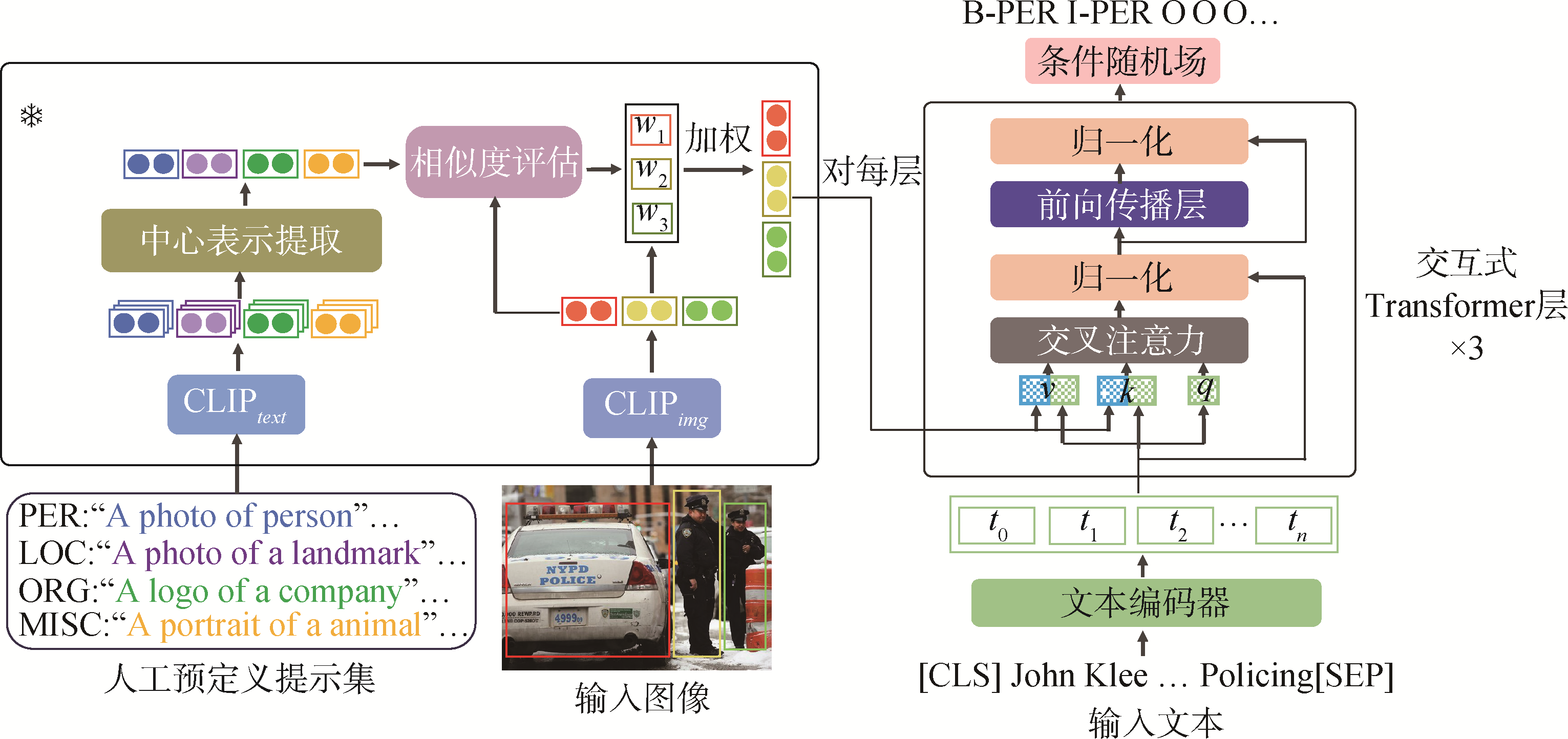
【目的】 为提高多模态命名实体识别的效果,通过计算实体锚文本与图像区域的语义相关性过滤不相关视觉区域,达到消除视觉噪声的目的。【方法】 使用提示词代替类别词作为实体锚文本对视觉区域进行语义相关性评估,通过降低无关视觉区域的权重消除无关视觉区域对实体识别的影响,采用多层交互式Transformer进行文本-视觉的模态融合,并通过CRF层实现实体识别。【结果】 在公开数据基准上的实验结果表明,所提方法在Twitter15和Twitter17数据集上的F1值分别达到76.97%和88.88%,相较于主流方法分别提升了0.48和1.17个百分点。【局限】 所提方法基于有监督学习范式,效果受标注数据的质量和数量的影响,研究仅基于公开基准数据的实体识别任务,下一步将对方法的可迁移性开展研究。【结论】 通过消除视觉噪声,可以有效提高多模态命名实体识别的效果;可以通过计算实体锚文本与图像区域的语义相关性实现对不相关视觉区域的过滤。
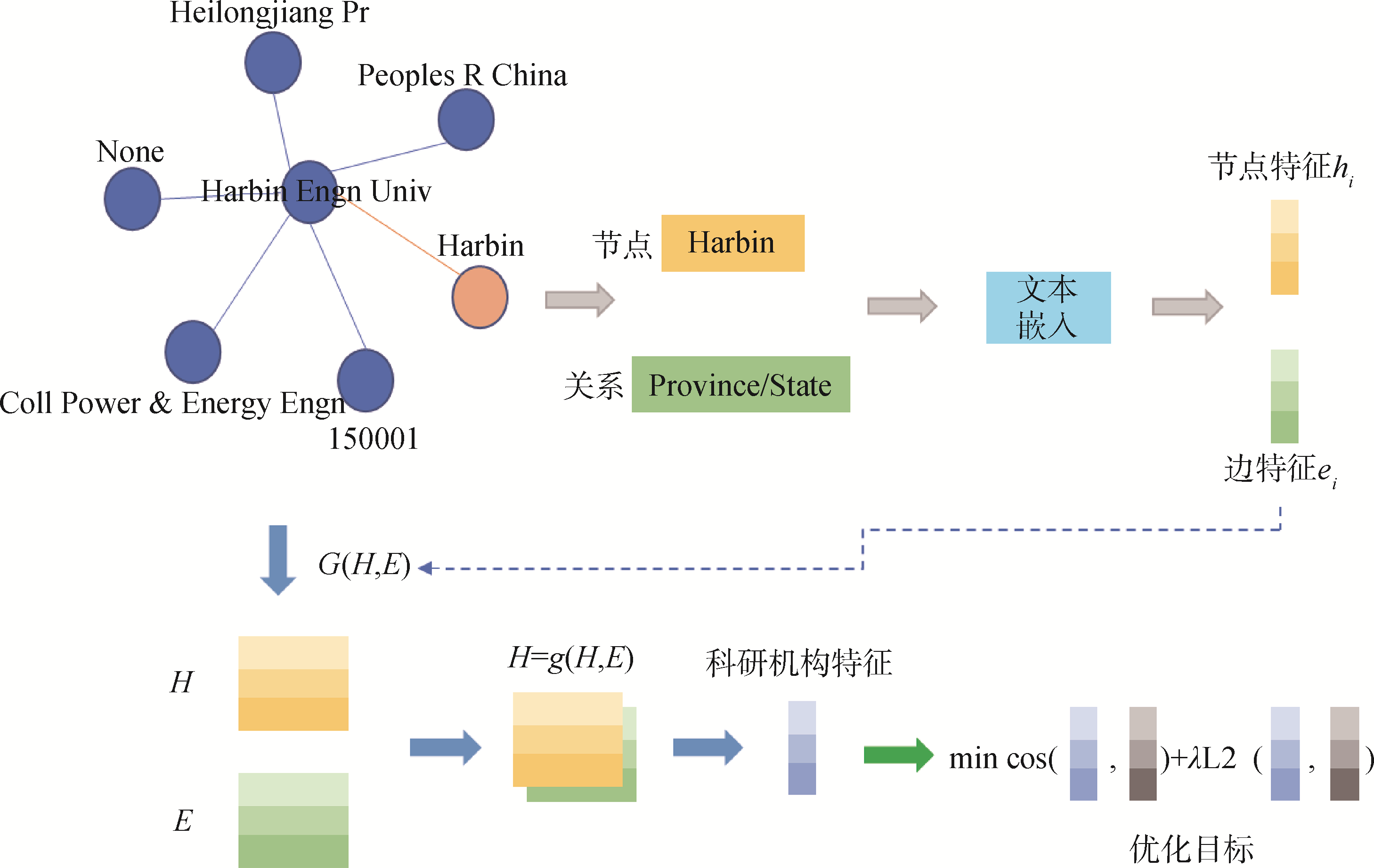
【目的】 研究适用于科技文献的机构名称对齐方法。【方法】 利用大语言模型并结合提示工程,从科技文献著录信息中识别机构及其关联实体,构建机构知识图谱,通过文本嵌入和图卷积网络,基于所构建的知识图谱实现同一机构不同表述形式的名称对齐。【结果】 与直接采用文本对齐的方法相比,论文提出的方法在无需要额外训练的情况下,机构名称对齐性能指标Hit@1、Hit@10和MRR分别提升约24%、7%和11%。【局限】 处理复杂信息结构文本中的跨语种、多模态的实体对齐效果有待提升。【结论】 融合提示工程与图卷积网络的机构名称对齐方法,可有效提升科研机构名称规范库建设的质量与效率。
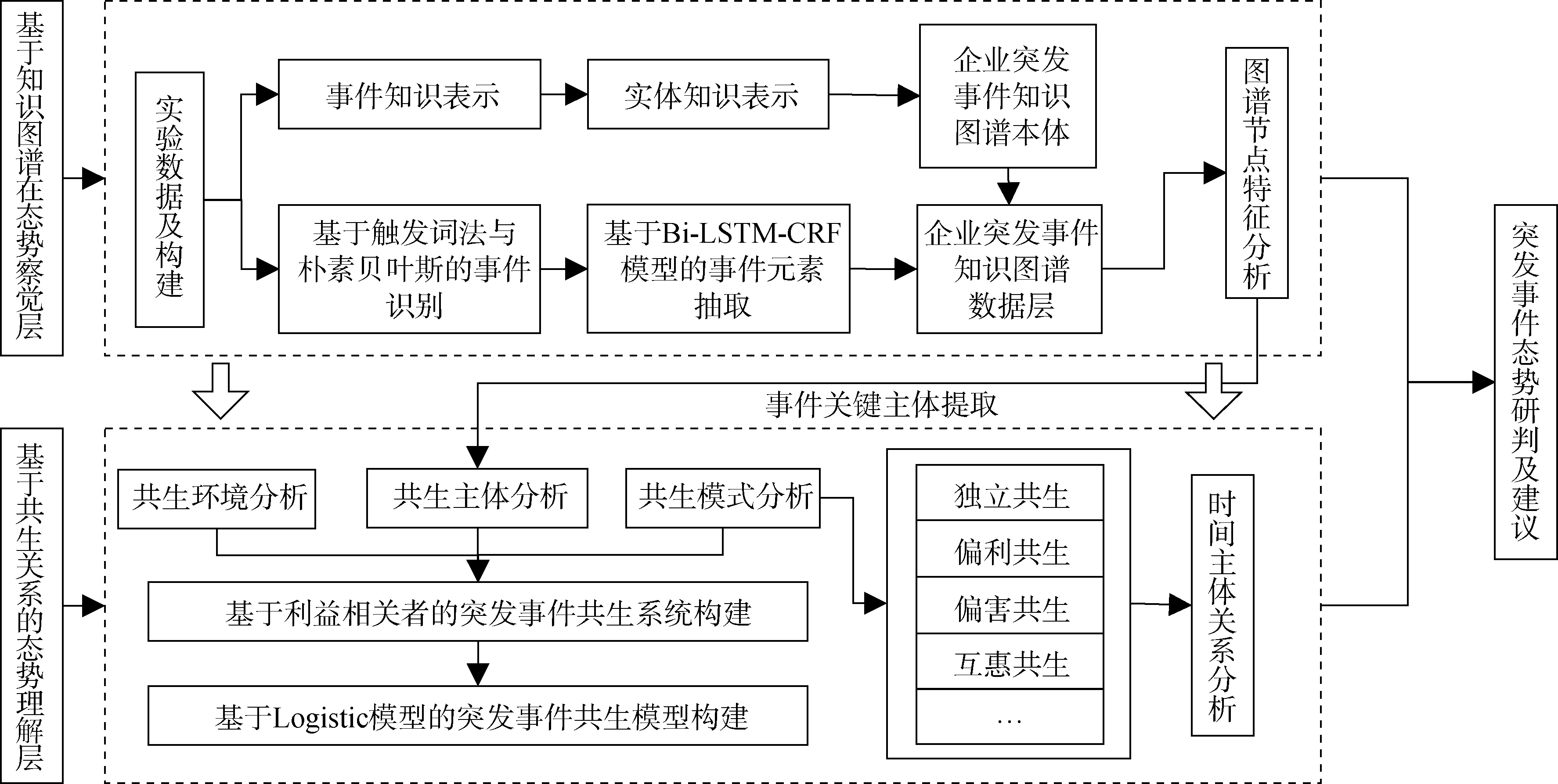
【目的】 为感知突发事件中不同态势阶段下各利益相关主体间的关系状态,提高企业面对突发事件的态势感知能力和应急决策能力。【方法】 本文从察觉与理解两个层面出发,构建面向企业应急决策的企业突发事件态势感知模型。利用知识图谱和深度学习技术完成突发事件知识抽取,并基于共生理论和Logistic种群生长模型构建企业突发事件共生系统。【结果】 在突发事件知识抽取当中,事件分类的F1值达到88.9%,事件元素抽取的宏平均F1值为91.4%。针对“土坑酸菜”事件进行态势要素识别,基于共生关系的分析表明,康师傅与插旗菜业呈现非平等互惠共生模式,康师傅与白象呈现寄生共生模式,插旗菜业与白象呈现偏害共生模式。【局限】 实验数据质量需进一步提高,图谱本体结构需进一步扩展。【结论】 本文所提模型可精准识别态势发展阶段与关键要素,并解析多主体共生关系以辅助应急决策布局。
【目的】 为完善电信诈骗领域知识图谱,提升领域知识图谱补全任务的效果,改进当前模型的局限性,提出一种基于四元数的神经网络补全方法ConvQR模型。【方法】 ConvQR模型由四元数嵌入模块、神经网络模块和优化预测模块组成。将三元组数据由四元数嵌入模块得到特征向量,将特征向量作为神经网络模块的输入,经过卷积和全连接层处理,最后通过点积操作进行评分并依据评分判定三元组的正确性,以此进行电信诈骗领域知识图谱补全。【结果】 在两个公开数据集FB15k-237、WN18RR以及在电信诈骗领域数据集TFG上的实验结果表明,所提模型的评价指标领先现有基线模型。其中,MRR指标得分分别为0.368、0.511和0.311,相较于已有最优基线TransERR模型,提高了2.5%、2.0%和2.6%。【局限】 随着电信诈骗领域知识图谱的不断更新和演化,该模型可能无法及时适应新发案件,因此需要引入外部知识和更新机制,以保持其补全能力的有效性和准确性。【结论】 ConvQR模型具有更好的预测精度,能够有效补全电信诈骗领域知识图谱中的缺失信息,更好地为知识图谱在公安系统的应用提供支持和参考。

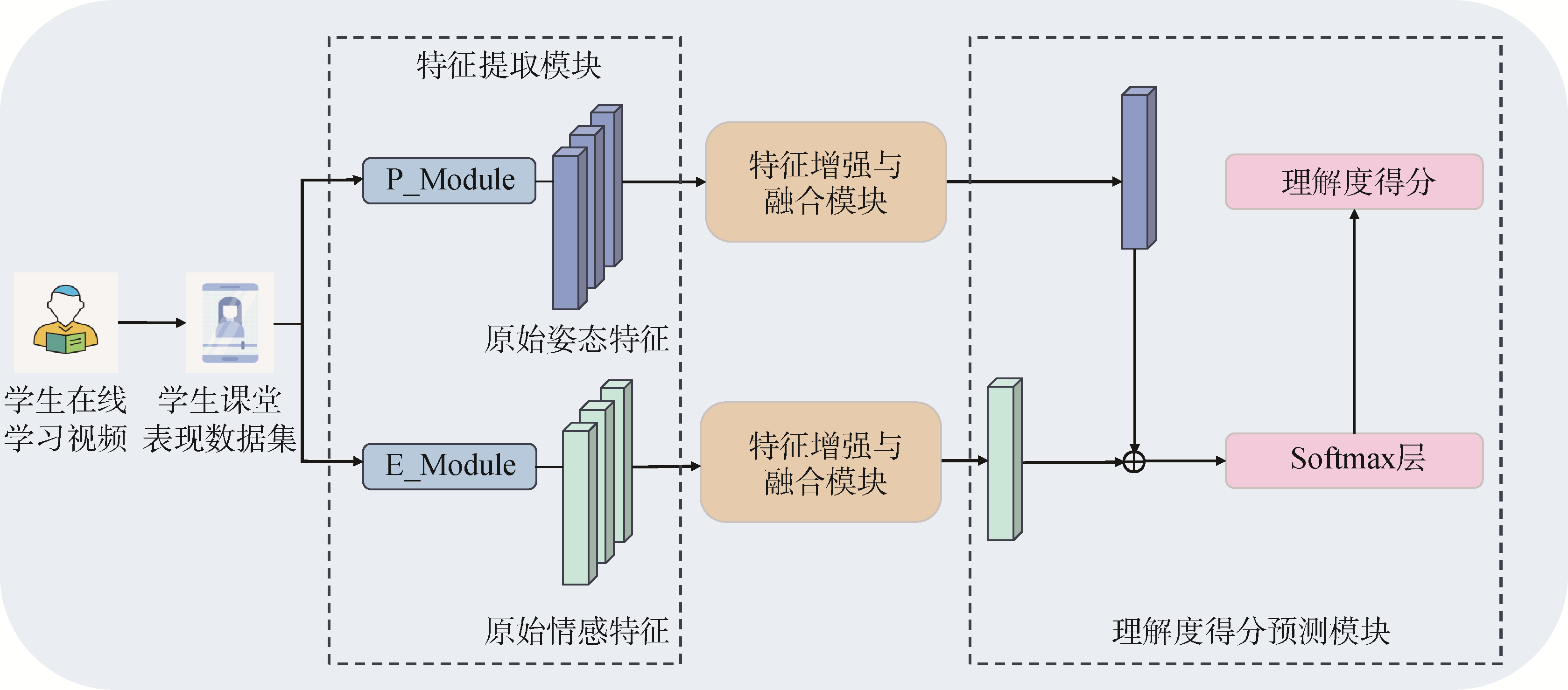
【目的】 通过构建有效的学生理解度图像数据集,设计基于深度学习的学生理解度得分预测模型,克服当前公开人脸数据集与实际课堂状态不匹配及使用专注度测评局限于仅捕捉学生课堂直观表现的问题。【方法】 基于真实的在线教学课堂环境采集学生表情图像数据,建立适应理解度预测需求的学生表情数据集,结合加权知识点得分和自我理解度评价得分提出理解度标签的主客观联合计算公式,并设计融合三种模块的理解度预测模型。【结果】 理解度得分预测模型评测结果表明,所提模型在测试集上多次迭代后,其平均绝对误差达到0.14,在4种对比模型架构中表现最好;理解度水平评价结果表明,与先前对专注度水平的研究结果对比,理解度能够更加全面深入地反映和衡量学生课堂对所讲授知识点的理解程度。【局限】 在研究学生理解度时高度依赖于学生的姿态特征与情绪特征,未深入探究其他影响理解度水平的特征。【结论】 所提模型能够有效预测在线教学环境中学生的理解度水平,且与专注度水平的对比体现了教学效果多维度联合评估的理念。