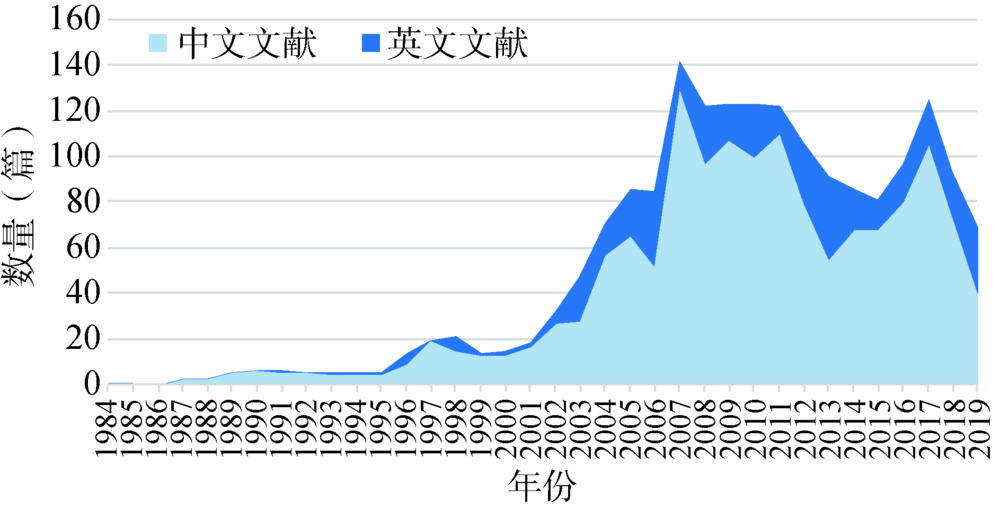
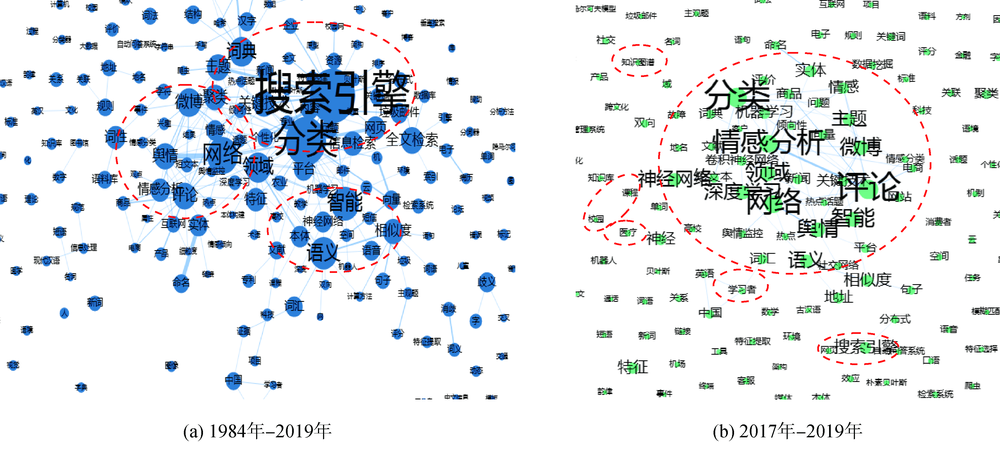
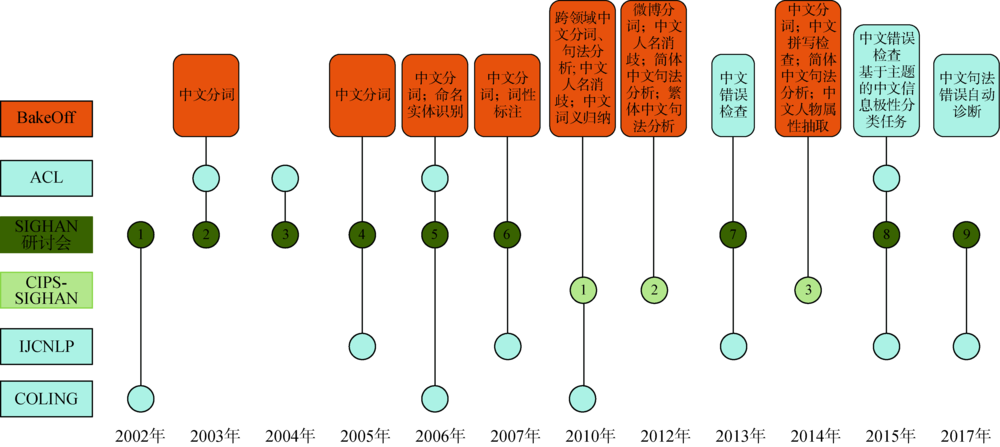
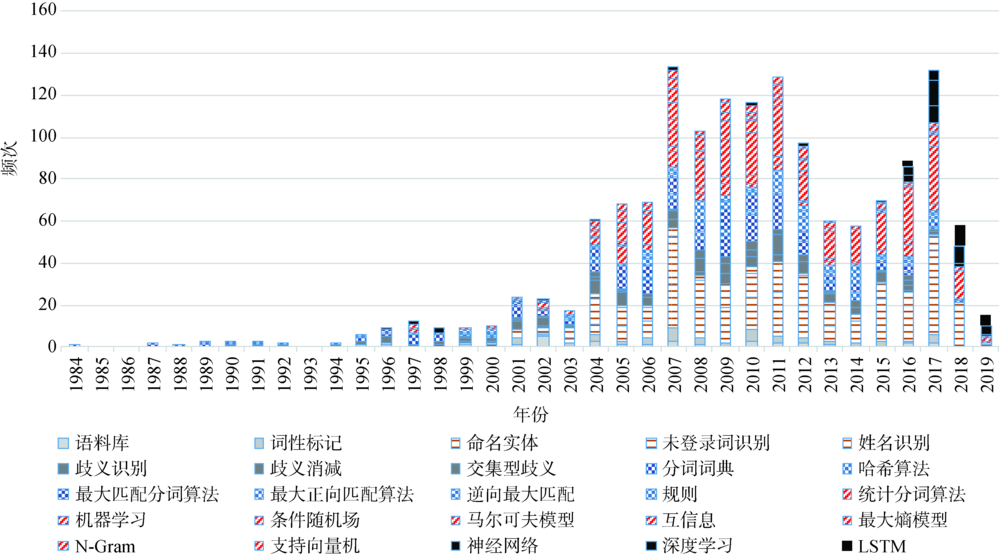
| 年份 | 作者 | 来源 | 研究思路 | 研究方法 | 实验使用的数据集 |
|---|---|---|---|---|---|
| 2019 | Gong等[ | AAAI | 方法改进 | 模型由多个长短时记忆神经网络(LSTM)和一个切换器组成,可以在这些LSTM之间自动切换。 | SIGHAN2005[ SIGHAN2008[ |
| 2019 | Huang等[ | arXiv | 方法改进 | 基于Bidirectional Encoder Representations (BERT),使用模型剪枝、量化和编译器优化。 | CTB6[ SIGHAN2005[ SIGHAN2008[ CoNLL2017[ |
| 2019 | Qiu等[ | arXiv | 方法改进 | 基于Transformer的构架方法采用全连接自注意力机制。 | SIGHAN2005[ SIGHAN2008[ |
| 2019 | He等[ | SCI | 语料改进 | 每一个句子的开头和结尾增加人工标记,以区分多粒度语料。再使用LSTM和CRF实现多粒度分词。 | SIGHAN2005[ SIGHAN2008[ |
| 2019 | 张文静等[ | 中文信息学报 | 语料改进 方法改进 | 模型在网格结构的辅助下,对不同粒度的分词标准都有较强的捕捉能力,且不局限于单一的分词标准。 | MSR[ |
| 2017 | Chen等[ | ACL | 方法改进 | 借鉴多任务学习的思想,融合多个语料的数据提升共享字向量模块。在此基础上应用对抗网络,把私有信息从共享模块中剥离到各个私有模块中去,既有大数据量的优势,又避免了不同语料之间的相互制约。 | SIGHAN2005[ SIGHAN2008[ |
| 2017 | Gong等[ | EMNLP | 语料改进 | 构建多粒度语料库。 | MSR[ |