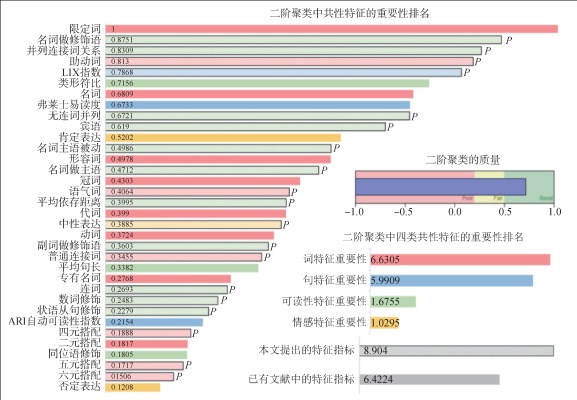
[Objective] This study examines the common features of fake news in different languages to provide a reference for cross-language fake news detection. [Methods] Using English and Russian as examples, we established datasets to extract common quantitative features of fake news across different languages at word, sentence, readability, and sentiment levels. Then, we used these features in principal component analysis, K-means clustering, hierarchical clustering, and second-order clustering experiments. [Results] The 34 common quantitative features demonstrated good performance in cross-language clustering of real and fake news. The proposed 19 quantitative features played a more significant role. The study found a tendency for fake news to exhibit language simplification and economization. It favors short sentences and simple collocations to convey information, making the text easier to understand and containing fewer negative expressions. [Limitations] The current dataset’s limitations made parallel testing with true and false news on the same topic impossible. [Conclusions] Fake news in different languages shares common language-independent features to be used for automatic clustering, providing insights for cross-language fake news detection research.
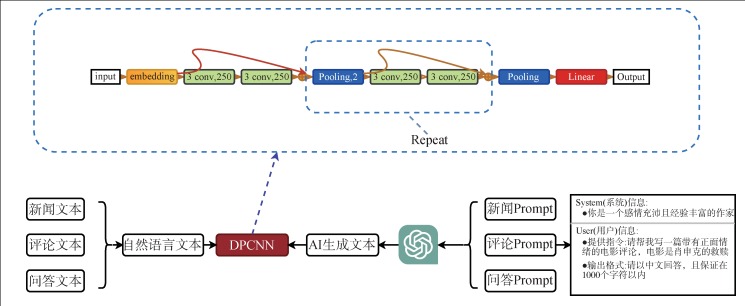
[Objective] This paper develops a method detecting ChatGPT (AI) generated Chinese texts to prevent the misuse of ChatGPT. [Methods] We constructed three Chinese datasets using the prompt-based approach. We then conducted model training and testing on these three datasets and identified an optimal AI-generated text detection method based on dimensions like model type, text type, and text length. [Results] Through various comparative approaches, the text classification method based on the Deep Pyramid Convolutional Neural Network (DPCNN) achieved an accuracy of 0.9655 on the test set, outperforming other methods. Furthermore, the DPCNN model demonstrated strong cross-category capability. The length of the texts affects the model’s accuracy. [Limitations] The Chinese dataset generated by the prompt-based approach has limitations in category diversity, as only three types of datasets were constructed and used for model training. [Conclusions] This paper proposes a method for detecting AI-generated text in the Chinese context, where accuracy is influenced by text type and text length.
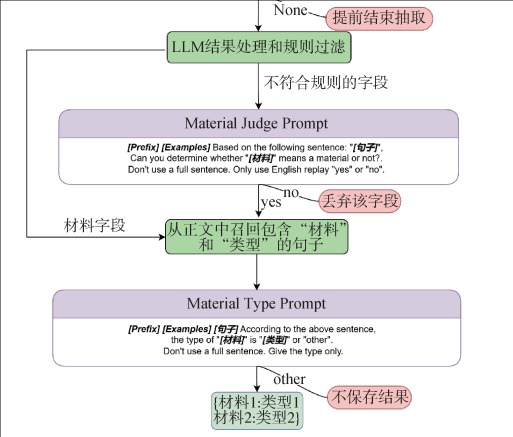
[Objective] This paper extracts entities and type instances of battery materials. It identifies experimental information needed to develop related materials from given research. [Methods] We utilized a locally deployed Large Language Model (LLM) and prompt engineering to transform the information extraction task into dialog-based extraction tasks without fine-tuning. We identified the relevant instance information by adding a few examples to the prompt template and allowing the LLM to provide negative answers. [Results] Without using a dataset for fine-tuning, we extracted materials entities and types with an entity recognition accuracy of 0.98, surpassing fine-tuned methods, and the material type recognition accuracy reached 0.94. [Limitations] Due to the constraints of local computational resources, the LLM’s precision results in lower performance in recognizing long entities. [Conclusions] The proposed method could effectively and flexibly extract experimental information from research papers.
[Objective] By improving the generative loss with CycleGAN and Wasserstein distance, this paper enhances the stability and accuracy of the rumor detection model in cases of unbalanced and unpaired data samples. [Methods] We developed the enhanced rumor discriminative model through adversarial training between the generator and discriminator. During the generative training process, we introduced cyclic consistency loss and recognition loss to achieve controllability of the generated target. We improved the model generative loss using Wasserstein distance, avoiding the problem of gradient explosion that may occur during adversarial network training. [Results] Our method’s accuracy reached 0.8698, and the F1 score was 0.8550 on the unbalanced rumor dataset PHEME. Compared with the baseline method, it has increased by 0.0068 and 0.0180, respectively. [Limitations] The new rumor detection model only has two generators and can only achieve the conversion of two categories of samples. It is suitable for binary classification rumor detection models and cannot be applied to multi-classification rumor detection tasks. [Conclusions] The proposed model can effectively enhance the ability to detect rumors from imbalanced data.
[Objective] To explore methods for integrating different corpora to improve the overall performance of vocabulary complexity assessment. [Methods] This study proposes a multi-domain vocabulary complexity assessment model. The feature generalization module is designed to adapt to different domains. In subsequent fine-tuning tasks, the model learns to predict vocabulary complexity. The feature fusion module is employed to explore the combined significance of hand-crafted features and deep features extracted by neural networks. [Results] On the LCP-2021 dataset, compared to the existing public optimal results, our model improved the Pearson correlation coefficient, MAE, and MSE by 0.0148, 0.0017, and 0.0004 respectively. However, the Spearman correlation coefficient and R2 coefficient decreased by 0.0038 and 0.0255 respectively. There was no significant change after integrating hand-crafted features. When transferred to the CWI-2018 dataset, our model improved the MAE metrics in three new corpus domains by 0.0086, 0.0209, and 0.0174 compared to the public baseline results. [Limitations] The method of vector concatenation could not effectively integrate the hand-crafted features and deep features effectively. The choice of algorithm for the design of the feature generalization module has certain limitations. Further attempts can be made to construct a comprehensive dataset. [Conclusions] Integrating different corpora helps to improve the overall evaluation performance of the model in new domains.
[Objective] This paper proposes a multi-task deep learning model tailored for ancient texts to overcome the limitations of current NER models, enhancing the identification of complex etiquette entity with improved accuracy and efficiency. [Methods] We built a named entity annotated corpus with six categories and employed a combined model, MJL-SikuRoBERTa-BiGRU-CRF. SikuRoBERTa and BiGRU extract contextual semantic information, while CRF imposes label constraints on both tasks, generating globally optimal named entity and punctuation label sequences. [Results] The proposed model has an F1 value of 84.34% on the etiquette recognition task and an F1 value of 75.30% on the automatic punctuation task. Among them, the palace, utensils, and costume moniker categories are effective with an F1 value of more than 85%, while the food, vehicle, and products categories are slightly underperformed with an F1 value of 76%~81%. [Limitations] The model did not validate finer-grained named entity classification, and the paper attempted to augment named entity recognition for cultural entities, but not for all categories. [Conclusions] The model constructed in this paper is more suitable for named entity recognition tasks in classical Chinese ritual texts and can effectively support information extraction and knowledge graph construction related to ancient rituals.
[Objective] To address the issues of insufficient modality fusion and interaction and incomplete multimodal feature extraction in current multimodal sentiment analysis, this paper proposes a multi-modal sentiment analysis method based on cross-modal attention and gated unit fusion networks. [Methods] In terms of multi-modal feature extraction, we added features of smile degree and head posture of characters in the video modality to enrich the underlying features of multi-modal data. We used the cross-modal attention mechanism in modality fusion to enable more sufficient interactions within and between modalities. We also used the gated unit fusion networks to remove redundant information and the self-attention mechanism to allocate attention weights. Finally, the sentiment classification results are output through the fully connected layer. [Results] Compared with the advanced Self-MM model on the public dataset CH-SIMS, the experimental results show that the proposed method improves the binary classification accuracy, ternary classification accuracy, and F1 score by 2.22%, 2.04%, and 1.49%, respectively. [Limitations] The characters’ body movements in the video constantly change, and different body movements contain different emotional information. The model does not consider the body movement of characters in the video. [Conclusions] This paper enriches the underlying features of multimodal data, effectively achieves modal fusion, and enhances the performance of sentiment analysis.
[Objective] The paper makes full use of the complementarity of modalities to enhance the correlation between modalities as well as between modalities and labels to achieve highly accurate classification effects. [Methods] We proposed a multi-label classification algorithm for micro-videos based on multimodal semantic enhancement and graph convolutional networks, utilizing multimodal information in micro-videos to support multi- label classification tasks. [Results] We verified the effectiveness of the proposed algorithm through a large number of experimental analyses, and the algorithm’s classification accuracy reached 87.15%, which is 6.82% higher than the optimal benchmark algorithm. [Limitations] The process of modality fusion for information enhancement is hindered by the presence of redundant data, which in turn obscures the correlation between modalities. Furthermore, the domain of modality-based multi-label classification remains relatively unexplored with limited research available. [Conclusions] The algorithm effectively enhances the complementarity among modalities, strengthens the correlation between modalities and categories, and improves the accuracy of classification.
[Objective] This paper proposes a retrieval method for learning the rich semantic representations through associated labels and retaining more discriminative information in hash codes. It considers cross-modal semantic similarity, maintains relevance between different modalities, and better bridges the modal gaps. [Methods] Under the constraint of multi-label association, we explored the common semantic information and the hidden class semantic structure of different modalities. Then, we adopted the asymmetric learning framework for joint similarity measurement of high-level and low-level semantics, thereby quantifying to obtain more discriminative hash codes. [Results] We conducted experiments on three multi-modal benchmark datasets: MIRFlickr-25K, IAPR TC-12, and NUS-WIDE, comparing the proposed method with seven other methods. Under five different code lengths, the average MAP values of the proposed method were 2.1%, 5.8%, and 2.1% higher than the baseline’s maximum value, respectively. [Limitations] The proposed method is more applicable to multi-label datasets and has some deficiencies in mining the semantic relevance of single-label data. [Conclusions] The proposed method maintains the consistency of sample and class semantic structures, fully explores the inherent modal features, and effectively improves retrieval performance.
[Objective] This paper extracts users’ external stimuli and cognitive evaluation indicators to construct a model of influencing factors for Weibo users’ extreme sentiment under corporate negative events. We utilized the SHAP model to explain the impact of each feature variable. [Methods] Based on cognitive-affective theory, social influence theory, emotional appraisal model, LDA model, and grounded theory, this study determined the external stimuli and cognitive evaluation indicators. We used the features contained in these two types of indicators as inputs and extreme emotion variables as outputs to construct the model of influencing factors. By comparing the performance of the four models, the optimal model is integrated with the SHAP model for visual display. [Results] We extracted seven feature variables from the cognitive evaluation dimension. The LGBM model achieved an accuracy, precision, and F1 score of 0.88, 0.90, and 0.93, respectively, outperforming other comparative models. Regarding the impact of feature variables on the extreme emotions of Weibo users, the cognitive evaluation dimension generally had a higher influence than the external stimulus dimension, and the impact of each feature variable varied. [Limitations] We should explore more influencing factors and a wider range of corporate negative event types. The algorithm’s performance needs to be improved. [Conclusions] The proposed model optimizes the grounded coding process and visualizes each feature variable’s influence degree, direction, magnitude, and manner on extreme emotions. This study provides a theoretical basis for enterprises to address negative online reputation issues.
[Objective] This paper uses open-source intelligence to develop a retrieval-based question-answering service system for military knowledge graphs. [Methods] First, we combined the RoBERTa pre-trained model with data augmentation techniques to address the issues of question classification and named entity recognition in low-resource military question-answering. Then, we proposed a three-dimensional feature entity linking method with the characteristics of military domain entities. Third, we utilized the RoBERTa model and dependency parsing analysis to solve the relationship matching issues for simple and partially complex intents. Finally, we applied heuristic rules to extract the answers. [Results] The F1 scores for question classification and entity recognition reached 99.62% and 98.35%, respectively. The accuracy of relation extraction was 99.72%, and the average accuracy of the question-answering system’s application evaluation reached 91.70%. [Limitations] The military knowledge graph in this question-answering system suffers from low efficiency in automatic expansion, which affects the quality of the question-answering service. [Conclusions] This study developed a military Q&A service with high interpretability and accuracy.
[Objective] This paper aims to enhance the accuracy of the recommendation system, considering the accuracy of the original rating information and the reliability of its prediction results. [Methods] First, we designed three schemes to provide the reliability probabilities for the prediction results of existing methods from the perspectives of information input and output. For information input, we proposed a fuzzy natural noise detection mechanism based on intuitionistic fuzzy set theory to identify and correct erroneous ratings. For information output, we adopted quadratic fuzzy noise detection, matrix factorization, and deep neural networks to obtain the reliability probabilities of predicted positions. Finally, we identified and corrected the unreliable prediction ratings based on the set reliability discrimination criteria. [Results] We examined the new method with experiments on two public datasets. Compared with the original recommendation methods, the new model achieved the highest improvements of 6.4% and 7.2% in F1 value and NDCG evaluation metrics. [Limitations] Our strategy does not apply to datasets containing only implicit feedback. [Conclusions] This paper provides a new solution for improving the performance of recommendation algorithms by measuring information reliability.
[Objective] Starting from the technology integration perspective, this paper uses link prediction and indicator evaluation methods to identify technological opportunities for enterprises, providing references for strategic research and development. [Methods] Based on the patent data of the target enterprise, we constructed a co-occurrence network of knowledge elements. We also used the link prediction method to identify potential knowledge combinations. From the perspectives of internal technology endowment and external innovation environment, we created a multi-dimensional index to evaluate the feasibility of potential knowledge combinations. Finally, we created a distribution map of potential knowledge combinations to identify technological opportunities for enterprises. [Results] We constructed the link prediction model using six machine learning algorithms, with the highest accuracy reaching 0.810. We accurately identified ten technological opportunities for the target enterprise and presented the corresponding relationship between the technology description and functional modules. [Limitations] This study only included knowledge combinations presented in the form of IPC pairs. Further exploration is needed for knowledge combinations in multiple IPC forms. [Conclusions] Combining the link prediction methods and multi-dimensional indicator evaluation methods can more accurately identify technological opportunities for enterprises.
[Objective] This paper scientifically quantifies and evaluates the strategic policies of carbon neutrality in major developed countries/regions. It aims to promote the deployment of carbon peaking and neutrality policies in China. [Methods] First, we explored the strategic actions and policies of major developed countries/regions regarding carbon neutrality. Then, we optimized the Policy Quantification PMC index model. Third, we investigated the evolution path of carbon neutrality-related technologies using the Web of Science core database. Finally, we discussed the characteristics of global carbon neutrality strategic actions and development trends. [Results] Japan’s “2050 Carbon Neutrality and Green Growth Strategy”, updated and issued in 2021, is the most comprehensive. The development trends of disciplines and technologies in carbon neutrality exhibit interdisciplinary and multilateral cooperation. The Chinese Academy of Sciences and Tsinghua University in China occupy the key hubs in the global institutional cooperation network. [Limitations] Our research method involves optimizing traditional technical means and is limited to major countries/regions. [Conclusions] When formulating carbon neutrality strategic action policies, we need to start from the national level and involve as many interdisciplinary institutions as possible in the discussion. We also need to fully use emerging research technologies and strengthen global exchanges and cooperation. It will effectively support our clean energy transition and accelerate the achievement of the “double carbon” goals.
[Objective] This paper proposes a new approach to comprehensively evaluating the quality of doctoral dissertations. [Methods] We applied the data envelopment analysis (DEA) to the comprehensive quality evaluation of dissertations. We compared the outcomes with the conventional total-score grading method. It aims to explore whether more accurate, reasonable, and comprehensive evaluation results. [Results] The grade division based on DEA is an effective method for comprehensively evaluating the quality of doctoral dissertations. It can identify comprehensive quality differences of samples with similar scores. Compared to the total-score rating, data envelopment analysis can better accommodate the diversity of dissertation quality performance rather than judging the quality of dissertations based on the score. Our study effectively used the “unqualified dissertations” and “excellent doctoral dissertations” as bench-marker samples. [Limitations] The DEA grading method must be based on standardized expert review scores. The “passing line” must be determined by experts’ evaluation of the subject area. [Conclusions] Unlike random sampling methods, data envelopment analysis has speed, accuracy, and sensitivity characteristics. It has practical application value in evaluating doctoral education.
