张策 , 都云程
, 都云程
Zhang Ce, Du Yuncheng
中图分类号: TP391.1 G35
通讯作者:
收稿日期: 2015-06-25
修回日期: 2015-08-13
网络出版日期: 2016-01-25
版权声明: 2016 《现代图书情报技术》编辑部 《现代图书情报技术》编辑部
基金资助:
展开
摘要
关键词:
Abstract
[Objective] By building a simple data sample, the low efficiency as the problem of traditional recognition method is solved. [Methods] This method uses URL features as the basis of recognition, and uses Support Vector Machine (SVM) to recognize page type. [Results] The precision of this method is 91.2%, also in terms of efficiency performance, the method is increased by nearly 60%. [Limitations] When the URL feature is not obvious or even completely contrary, the recognition accuracy will be greatly reduced. [Conclusions] The experimental results show that the method has a great advantage in efficiency, and it will increase the efficiency of the collection system.
Keywords:
随着网络的发展, Web上的网页数量增长迅猛, 即使采用大规模的分布式网页采集系统, 采集整个网络中的绝大多数重要网页也要花费很长时间。研究结果表明, 中国的网页一个月内大约只有8.52%发生变化[1], 所以采用全采集的方式, 存在很大的资源浪费。另外由于两次采集的周期过长, 在此周期内网页变化频率大的网页发生了多次变化, 而采集系统不能及时抓取变化后的网页, 就会导致搜索引擎系统不能对这些网页提供检索服务。为了解决这个问题, 产生了网页增量采集系统。
网页增量采集系统不是采集所有得到的URL, 只是通过估计网页的变化规律采集新出现的网页、变化的网页和消失的网页, 不关心没有变化的网页。这样极大减少了采集量, 能快速同步Web上的网页与搜索引擎中的网页, 从而给用户提供更实时的检索服务。
在增量式采集研究中, 网页通常被分为目录型网页(Hub网页)与主题型网页(Topic网页)[2], Hub网页在网站中的作用是引导用户找到相关的主题网页, 相当于目录索引, 没有具体表达的内容, 为主题型网页提供入口[3]。主题型网页是具体讲述某一主题。经实验证明, 很多新网页都是从Hub网页链接过去的[4]。因此, 增量式采集系统只要找出Hub网页进行采集就能发现新出现的URL。如上所述, 识别哪些网页是Hub网页就成为首先要解决的问题。
针对此问题, 本文提出一种基于URL特征的Hub网页识别方法, 首次将URL特征作为Hub网页识别的全部依据, 这将会弥补传统Hub网页识别所带来的巨额开销, 最后通过对比实验验证该方法的有效性。
目前主要的Hub网页识别方法有基于简单规则的识别方法[4]、基于多特征启发式规则的分类方法[5-6]和基于网页内容的机器学习方法[7-9]。
基于简单规则的识别方法是分析Hub网页URL的特点, 总结出其规律, 制定简单规则, 符合条件的就是Hub网页。Meng等提出选择网站首页, 以及网站中网页文件名包含index、class和default等单词的网页作为Hub网页[4], 采集Hub网页中链接所对应的网页。该方法能采集到一大部分新网页, 但是对新网页采集的召回率不是很高。存在以下问题:
(1) Hub网页选择不准确。由于网页的文件名是由人命名的, 没有固定模式, 因此不可能寻找到一个规则可以正确找出所有Hub网页;
(2) 不能自动识别Hub网页。由于在采集过程中不能及时发现新的Hub网页, 所以就不能发现新Hub网页中的链接信息。
为了解决基于简单规则方法的局限性, Ail等提出基于多特征启发式规则的网页分类方法, 依据非链接字符数、标点符号数和文字链接比三个特征构建启发式规则[5]。研究发现Hub网页与主题网页在这些特征值上存在广泛差异, 这种差异证明了网页通过这些特征值进行分类的可行性。该方法通过统计网页中各个特征的具体值, 根据贝叶斯公式计算各个特征值对Hub网页的概率支持度, 根据每个特征值的概率支持求出综合支持度, 通过与设定的阈值进行比较, 判断网页属于哪一类。该方法的不足之处在于过度依赖阈值的设定, 阈值的设定会直接影响分类的准确率, 然而对于不同类型网站, 阈值设定也不同, 这样就增加了算法的复杂度。
为了解决阈值的依赖问题, 文献[9]提出基于网页内容的机器学习方法, 通过HTML解析分析出网页特征, 建立训练集与测试集, 从而得到机器学习模型, 用于识别Hub网页。该方法准确率高, 但是效率不高, 增加了系统的额外开销。因为该方法是建立在网页内容的基础上, 需要解析所有的HTML网页, 并提取其中的特征进行保存, 这样就在一定程度上占用了系统资源, 给采集系统带来额外负担, 影响采集系统的性能。
上述方法从不同层面对识别Hub网页进行分析, 在前人研究的基础上, 本文提出的基于URL特征的识别方法, 将会很大程度地解决上述问题。该方法采用URL特征作为样本, 选用SVM作为机器学习方法进行识别。与基于规则和基于网页内容的方法相比, 提供了一种更具使用价值的方法。一方面, 特征提取简单高效, 易于实现, 同时兼顾了识别的准确率。另一方面, 在采集系统中, 从网页中提取URL是必不可少的部分, 因此选用URL作为识别依据, 可以减小对系统效率的影响, 不会给采集系统增加太大的额外开销。
支持向量机(Support Vector Machines, SVM)是由Vapnik等开发的一种机器学习方法。支持向量机是建立在统计学理论——VC维理论和结构风险最小原理基础上的, 特别是在样本数目较少的情况下, SVM的性能明显优于其他算法[10-12]。
其基本思想为: 定义最优线性超平面, 将寻找最优超平面的算法归结为求解一个最优(凸规划)问题。进而基于Mercer核展开定理, 通过非线性映射, 将样本空间映射到一个高维乃至于无穷维的特征空间, 使在特征空间可以应用线性学习机的方法解决样本空间中高度非线性分类和回归等问题。其还包括以下优点:
(1) 基于结构风险最小化原则, 这样可以避免过拟合问题, 泛化能力强。
(2) SVM有坚实理论基础的小样本学习方法。它基本上不涉及概率测度及大数定律。从本质上看, 避开了从归纳到演绎的传统过程, 实现了高效的从训练样本到预测样本的“转导推理”, 大大简化了通常的分类和回归等问题。
(3) SVM 的最终决策函数只由少数的支持向量所确定, 计算的复杂性取决于支持向量的数目, 而不是样本空间的维数, 这在某种意义上避免了“维数灾难”。
(4) 少数支持向量决定了最终结果, 这有助于抓住关键样本、“剔除”大量冗余样本, 而且注定了该方法算法简单, 同时具有较好的“鲁棒”性。
Hub网页识别可以理解为一个二分类问题, 其中正类为Hub网页, 负类为主题网页, Hub网页识别的关键是如何正确划分Hub网页与主题网页。
基于URL特征的Hub网页识别方法主要依据URL中与Hub网页有关系的特征划分网页。具体过程如下: 分析已经得到的URL, 提取其中包含的特征信息, 找出与Hub网页有关的特征; 将得到的特征整合成训练集与测试集, 用训练集去训练SVM机器学习模型, 同时评测其效果; 根据效果调整SVM模型参数, 从而确定最优参数, 得到最终SVM学习模型。
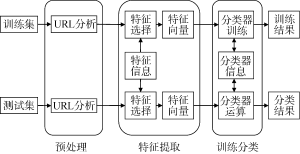
图1展示了基于URL特征的Hub网页识别方法的架构, 从整体角度出发, 该方法主要包含三大模块: 预处理、特征提取、训练分类。
(1) 预处理
预处理主要包括URL分析。URL中包含很多信息, 其中一些信息可以作为网页分类的依据, URL分析的目的在于找出对分类有用的特征信息。URL中存在的信息包括URL长度以及URL之中是否包含某些字符串等。URL所对应的锚文本也能在一定程度上反映网页类型, 因此, 需要在预处理阶段提取URL所对应的锚文本。
本实验的基础数据都是预先由网络采集器采集, 在采集过程中, URL及其对应的标题等采集信息会作为日志文件被记录下来。因此, 实验通过抽取日志文件内容进行分析, 获取其中URL相关信息。其中包括URL标题长度、URL长度、URL是否含有日期、网页文件名、文件类型、参数名称、参数个数、目录名称、目录深度、URL大小、采集深度。
(2) 特征提取
特征提取主要包括特征选择与特征量化。特征选择的任务是要将信息量小、不重要的特征从特征项空间中删除, 从而降低特征项空间的维数。特征量化是将选择的特征进行数值化, 从而代表该特征和Hub页的关联程度。
经URL分析, 可以得到URL中包含的信息, 通过查阅相关文献并观察统计可以发现Hub网页具有以下区别于主题网页的特征:
①URL标题长度: 即锚文本长度, Hub网页由于不讲述某一具体内容, 锚文本长度一般较短。
②URL长度: 由于Hub网页基本都位于主题网页上层, 因此Hub网页的URL相比主题网页较短。
③URL是否含有日期: 主题网页主要讲述某一内容, 在URL中大多包含发布日期, Hub网页基本没有。
④网页文件名: Hub网页URL一般有两种可能: 只是一个目录, 不存在文件名; 文件名中大都包含“index”、“class”等词语。
⑤文件类型: 文件类型与网页文件名是一体的, 存在网页文件名的Hub网页大多数是ASP、JSP、ASPX和PHP类型。
⑥参数名称: 存在参数的URL中, 主题网页URL大都包含ID参数, 而Hub网页的URL一般没有。
⑦参数个数: Hub网页URL大多没有参数。
⑧目录深度: Hub网页基本上都是位于网站的上层。
⑨URL大小: 即URL对应网页的大小。Hub网页存在大量链接, 对应网页也相对较大。
⑩采集深度: 采集到该URL的层次。Hub网页为主题网页提供链接入口, 因此, Hub网页采集一般都先于主题网页。
机器学习模型只能将数值类型进行分类, 因此需要将文本类型进行数值化, 数值化的依据为归纳不同类型URL的文本值, 找出代表性的文本值进行赋值, 赋值是通过统计求出各个文本值的出现频率, 然后计算其出现概率并进行归一化处理。在统计中, 选取500个Hub网页, 对各个文本值数量进行统计并计算概率, 将概率乘以100进行赋值(只是为了让最后得到的特征值在一个合理的范围), 具体过程如下:
①网页文件名为“空”的数量为302, 其概率为0.604, 赋值为60.4; 含有“class”、“index”、“default”和“list”的数量为153, 其概率为0.306, 赋值为30.6; 含有“article”和“content”的数量为0, 其概率为0, 赋值为0; 其他情况数量为45, 其概率为0.09, 赋值为9。
②文件类型为“空”的数量为302, 其概率为0.604, 赋值为60.4; 含有“asp”、“jsp”、“aspx”和“php”的数量为123, 其概率为0.246, 赋值为24.6; 含有“shtml”、“html”和“htm”的数量为75, 其概率为0.15, 赋值为15; 其他情况数量为0, 其概率为0, 赋值为0。
③参数名称为“空”的数量为412, 其概率为0.824, 赋值为82.4; 含有“id”的数量为52, 其概率为0.104, 赋值为10.4; 其他情况的数量为36, 其概率为0.072, 赋值为7.2。
(3) 训练分类
①http://www.csie.ntu.edu.tw/~cjlin/libsvm/.
通过以上步骤, 将URL表示成向量空间, 使用LibSVM[13]对URL进行分类。LibSVM是一个快速有效的SVM模式识别与回归的集成包, 还提供了源码, 可以根据需求对源码进行修改。本实验使用的是LibSVM-3.20版本①中的Java源代码, 在参数设置和训练模型两个方面对源码进行修改, 增加参数自动寻优以及模型文件返回保存功能。
①按照LibSVM所要求的格式准备数据集。
该算法使用的训练数据和测试数据文件格式如下:
[label] [index1]:[value1] [index2]:[value2]…
[label] [index1]:[value1] [index2]:[value2]…
其中, label(或称class)是本条数据所属种类, 通常是一些整数; index表示特征的序号, 通常是以1开始的整数; value是特征值, 通常是一些实数。当特征值为0时, 特征序号和特征值都可以省略, 所以index可以是不连续的自然数。
②对数据进行简单的缩放操作。
扫描数据, 由于原始数据可能范围过大或过小, svmscale可以先将数据重新缩放到适当的范围, 默认范围是[-1,1], 可以用参数lower和upper分别调整缩放的上界与下界。这样也避免在训练时为了计算核函数而计算内积的时候引起数值计算的困难。
③选用RBF核函数。
SVM的类型选择C-SVC, 即C类支持向量分类机, 允许用异常值惩罚因子c进行不完全分类。c越大, 错分样本越少, 分类间距变小, 泛化能力减弱; c越小, 错分样本越大, 分类间距变大, 泛化能力增强。
核函数的类型选择RBF, 原因有三点: RBF核函数可以将一个样本映射到一个更高维的空间, 而且线性核函数是RBF的一个特例, 也就是说如果考虑使用RBF, 那么就没有必要考虑线性核函数; 需要确定的参数较少, 核函数参数的多少直接影响函数的复杂程度; 对于某些参数, RBF和其他核函数具有相似的性能。在RBF核函数中自带一个gamma参数, 表示核函数的半径, 隐含地决定了数据映射到新的特征空间后的分布。
SVMtrain对训练数据集进行训练, 获得SVM模型。模型内容如下:
svm_type c_svc %训练所采用的SVM类型, 此处为C-SVC
kernel_type rbf %训练采用的核函数类型, 此处为RBF核
gamma 0.0769231 %设置核函数中的gamma参数, 默认值为1/k
nr_class 2 %分类时的类别数, 此处为两分类问题
total_sv 132 %支持向量的总个数
rho 0.424462 %决策函数中的常数项
label 1 0 %类别标签
nr_sv 64 68 %各类别标签对应的支持向量个数
SV %以下为支持向量
1 1:0.166667 2:1 3:-0.333333 4:-0.433962 5:-0.383562 6:-1 7:-1
8:0.0687023 9:-1 10:-0.903226 11:-1 12:-1 13:1
0.5104832128985164 1:0.125 2:1 3:0.333333 4:-0.320755
5:-0.406393 6:1 7:1 8:0.0839695 9:1 10:-0.806452 12:-0.333333 13:0.5
④采用十折交叉验证选择最佳参数c与g(c为惩罚系数, g为核函数中gamma参数)。
交叉验证是把训练样本平均分成10份, 每次拿出9份当作训练集, 剩下的一份当作测试集, 这样重复10次, 获得10次的平均交叉验证准确率, 以此寻找最佳的参数, 使得准确率最高。在LibSVM源码中每次只能验证一组参数的效果, 要寻求最优参数, 只能多次手动设置参数。
本实验对源码进行修改, 采用网格搜索方法自动寻求最优参数并返回。具体操作为自动获取一组参数, 进行十折交叉验证, 得到平均准确率, 以此重复, 最终找到对应最高准确率的那组参数。为了确定训练集的合适大小, 选取三个训练集分别进行训练。实验结果表明, 训练集为1 000时, 平均分类精度为80%; 训练集为2 000和3 000时, 平均分类精度都在91%左右。因此, 为了保证训练集的精简, 训练集大小选择2 000, 平均分类精度达到最高(91%)时, c为32, g为0.0625。
⑤采用最佳参数c与g对训练集进行训练获取SVM模型。
使用SVMtrain函数训练模型, LibSVM中不会保存训练模型, 每次预测都需要重新训练。本实验改进了源码, 将训练好的模型进行本地保存, 以方便下次使用。
⑥利用获取的模型进行预测。
使用训练好的模型进行测试。输入新的X值, 给出SVM预测出的Y值。
分别与两种方法进行对比实验, 验证基于URL特征的Hub网页识别方法的可行性: 与传统的基于多特征启发式规则的网页分类方法对比; 与传统的基于内容特征的机器学习方法对比。该阶段没有选用与传统基于URL的简单规则识别方法进行对比, 是因为在曹桂峰[6]的研究中已经明确证明基于URL简单规则的效果明显差于基于多特征启发式规则的分类方法。
可行性主要从效率和效果两方面进行验证, 已有研究在提出传统方法时, 只给出了其效果数据, 没有效率方面的数据, 因此本文将两种验证方法根据原有步骤再次实现, 在达到原有实验效果的同时得到其效率数据。
(1) 基于多特征启发式规则的网页分类方法
①预处理操作。通过一组正则表达式去除注释信息、Script脚本和CSS样式信息。
②计算网页的特征值。该过程是进行网页分类的关键, 主要是计算经过归一化后的非链接字符数、标点符号数、文字链接比。
③计算支持度。通过求得的各项特征值计算该网页为主题型网页的综合支持度。
④将计算得到的支持度同阈值进行比较。如果支持度小于该阈值, 则输出网页的类型为Hub网页, 否则输出网页类型为主题型。
在该验证方法实现过程中, 阈值是通过实验的方法获取, 实验中选取500个Hub网页, 计算每个网页为主题型网页的综合支持度, 发现其值都集中在0.6以下, 其中大部分集中在-0.2以下, 因此确定了阈值大致范围, 最终在该范围内进行逐一测试实验, 找出最优阈值, 使得实验准确率最高。
(2) 基于内容特征的机器学习方法
①HTML解析。通过建立DOM树去掉与网页分类无关的HTML源码。HTML解析步骤如下:
1)规范化HTML标签
由于有些网页中的 HTML 标签是错误的、丢失的, 为了后续处理的方便, 需要将错误的标签改正回来, 将丢失的标签补全。
2)建立 DOM树
由 HTML 中的标签建立一棵DOM树。
3)网页去噪
除去<style>、<script>、<applet>等标签所嵌的HTML源码, 因为这些代码只与网页表现形式有关, 而与网页内容无关。
4)信息提取
从网页中抽取信息, 包括: 网页深度、更新周期、锚文本文字数量、文本文字数量、含有URL个数、含有新URL个数。
②特征提取。通过观察与实验, 找出在两种网页类型上存在差异的特征项, 因此提取8个网页内容特征, 分别为: 网页深度、更新周期、锚文本文字数量、文本文字数量、锚文本文字与文本文字数量之比、URL个数、新URL个数、新URL所占比率。
③训练分类。根据提取的特征值建立训练集与测试集, 训练SVM分类模型。
对识别效果主要从两个方面进行评价: 识别效率与识别效果。其中, 效率就是系统开销, 包括耗费时间、内存使用率和CPU使用率; 效果主要包括准确率和召回率。
准确率(Precision), 表示在分类过程中得到的网页测试集中, 网页类别被正确标注的网页所占的比率, 反映分类器分类的准确程度。召回率(Recall), 表示在分类过程中得到的网页测试集中, 真正网页类别被正确标注在所有符合该类别的网页测试集中所占的比率, 反映分类器查到相关网页的完备性。
准确率与召回率反映分类效果的两个方面是互补的, 单纯的提高某一个, 另外一个就会受到其影响。在实际应用中, 需要综合考虑准确率与召回率, 目前主要用F1值作为评价标准, 反映准确率和召回率综合效果。
实验采用Precision, Recall和F1评价网页分类的效果, Precision, Recall和F1计算方法如下所示。参数含义如表1所示。
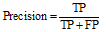
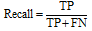

在实验中, 从50个中文网站采集网页, 这50个网站大致分为: 政府网站(10个)、教育网站(10个)、事业单位网站(10个)、公司网站(10个)和新闻网站(10个)。其中, 由于新闻网站网页数量较大, 因此每个新闻网站采集500个网页, 而其他4种类型网站相对较小, 因此采集300个网页。为了保证数据的多样性, 同时保证实验数据的简单高效, 需要对采集的网页进行筛选精简, 减少数据冗余。从采集的网页中分别选取1 000个、2 000个和3 000个作为训练集, 每个训练集从每种类型网站中平均选取, 其中Hub网页与主题网页数量各占一半。构造三个训练集是为了确定训练集大小的合适取值。
在训练机器学习模型时, 是在随机切分的测试数据上得到的交叉验证平均准确率, 因此对已有算法就不能使用同样的测试数据, 造成缺乏可比性。因此在实验中又标注了另外30个网站中的1 000个网页作为测试数据, 其中包括600个Hub网页和400个主题网页。保证了与已有算法的可比性, 同时也在一定程度上证明本文提出算法的稳定性。
实验环境使用Win7系统, CPU为Intel双核, 内存为2GB。
本实验分别选用基于URL特征的Hub网页识别方法、基于多特征启发式规则的网页分类方法和基于内容特征的机器学习方法进行三次实验。
表2为采用基于URL特征的Hub网页识别方法得到的实验结果, 经计算得到Precision为91.20%, Recall为86.33%, F1为88.70%。在训练样本上对模型进行十折交叉验证得到平均准确率为91%。
表3为采用基于多特征启发式规则的网页分类方法得到的结果, 实验中阈值在-0.2到0.6之间选取, 经多次实验发现阈值选择-0.1时, 准确率最高, 经计算得到Precision为86.63%, Recall为83.17%, F1为84.86%, 该结果已达到曹桂峰[6]所做实验的效果。
表4为采用基于内容特征的机器学习方法得到的实验结果, 经计算得到Precision为88.73%, Recall为90.50%, F1为89.61%, 该结果已达到文献[9]中实验的效果。
表5是在三种方法具体实现时, 得到的各个方法运行过程中消耗的时间、内存使用情况和CPU使用情况。
表5 三种方法的系统开销数据
| 实验组别 | 方法 | 处理 网页数 | 耗时 /s | 内存使用/MB | CPU 使用率 |
|---|---|---|---|---|---|
| 1 | 基于多特征 启发式规则 | 1 000 | 79.6 | 112 | 51% |
| 2 | 基于内容特征 | 1 000 | 87.5 | 128 | 59% |
| 3 | 基于URL特征 | 1 000 | 21.3 | 36 | 17% |
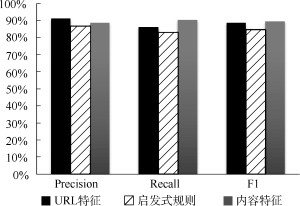
为证明基于URL特征的Hub网页识别方法的稳定性, 在训练阶段对该模型进行了十折交叉验证, 得到平均准确率为91%, 用该模型对测试数据进行测试时, 得到准确率为91.2%, 这两组数据没有明显差异, 由此可以证明该方法具有一般性与稳定性。实验结果对比如图2所示:
基于URL特征的Hub网页识别方法优于基于多特征启发式规则的分类方法, 经分析原因为: 基于多特征启发式规则的分类方法缺乏灵活性, 不可能适用于所有网页; 在基于多特征启发式规则的分类方法中阈值的设定存在盲目性; 基于URL特征的Hub网页识别采用机器学习模型, 能发掘特征之间的内在联系, 具有很强的泛化能力。
基于URL特征的Hub网页识别方法与基于内容特征的机器学习方法在实验效果上没有太大差异, 因为两者采用了相同的识别方法, 只是选择的特征对象不同。基于URL特征的方法在准确率上优于基于内容特征的方法, 而在召回率上低于基于内容特征的方法, 原因是: Hub网页所对应的URL特征明显, 如URL标题和URL长度较短、不包含日期等, 所以依据URL特征识别的准确率会相对较高。但URL存在很大随意性, 没有统一规范, 依据个人设定, 当不符合一般特性的URL出现时, 该方法很难识别, 所以召回率会相对较低; Hub网页的内容存在一般特性, 如链接较多, 普通文本文字较少等, 基本所有Hub网页都满足此特性, 所以依据内容特征识别的召回率会很高。但有些主题网页也存在很多相关链接, 其中内容文本也很短, 所以依据内容特征识别的准确率会降低。综上所述, 这两种方法在识别效果上差别很小, 各有优点, 但是在识别效率上存在明显差别。
如表5所示, 基于URL特征的Hub网页识别方法在运行效率上有很大的优势, 时间消耗少, 大幅度降低了识别时间(70%)。因为URL本身相对较小, URL特征提取就相对简单, 但提取网页内容特征需要进行HTML解析, HTML解析本身就是一项耗时的工作; 内存与CPU占用较少, 大约为传统方法的60%, 对采集系统影响小。因为在采集过程中本就会提取URL, 所以不会带来很大的额外开销, 也不会影响采集系统的采集效率。综合以上原因, 基于URL特征的Hub网页识别方法具有一定理论意义与实际应用价值, 是一种行之有效的方法。
本文提出的基于URL特征的Hub网页识别技术, 通过提取URL特征以训练机器学习模型, 达到自动识别的目的。实验结果表明, 该方法在达到传统方法识别效果的同时, 能降低约60%的系统开销。但该方法存在一定局限性, 因为URL本身具有一定随意性, 当遇到URL特征不明显甚至完全相背的网站时, 识别准确率会大幅度降低, 此时需要结合网页内容特征去识别。因此, 如何将基于内容特征的方法与基于URL特征的方法相结合以适应所有网站, 是下一步研究的重点。
都云程: 确定研究方向, 提出研究思路, 对论文提出修改意见; 张策: 设计研究方案, 进行实验过程设计及实验分析, 起草论文; 梁然: 采集基础数据; 张策, 梁然: 论文修改及最终版本修订。

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}