杨如意 , 刘东苏, 李慧
, 刘东苏, 李慧
西安电子科技大学经济与管理学院 西安 710126
Yang Ruyi, Liu Dongsu, Li Hui
中图分类号: G202
通讯作者:
收稿日期: 2015-07-17
修回日期: 2015-08-30
网络出版日期: 2016-01-25
版权声明: 2016 《现代图书情报技术》编辑部 《现代图书情报技术》编辑部
基金资助:
展开
摘要
关键词:
Abstract
[Objective] In order to reveal the relationships between contents, topics and authors of documents, this paper presents the Dynamic Author Topic (DAT) model which extends LDA model. [Context] Extracting features from large-scale texts is an important job for informatics researchers. [Methods] Firstly, collect the NIPS conference papers as data set and make preprocessing with them. Then divide data set into parts by published time, which forms a first-order Markov-chain. Then use perplexity to ensure the number of topics. At last, use Gibbs sampling to estimate the author-topic and topic-words distributions in each time slice. [Results] The results of experiments show that the document is represented as probability distributions of topics-words and authors-topics. On the dimension of time, the revolution of authors and topics can be observed. [Conclusions] DAT model can integrate contents and extra-features efficiently and accomplish text mining.
Keywords:
在当前信息环境下, 文本是最为主要的信息表达方式, 从海量文本中实现特征抽取和语义挖掘已经成为情报研究人员的重要工作。主题模型凭借其在挖掘文本隐含信息的有效性而赢得广泛关注。主题模型从文档生成过程的角度进行建模, 通过统计文档层面的词项共现信息, 抽取出语义上相近的主题, 将文档表示成一组主题, 大幅降低了文档的特征空间维度[1]。2003年, Blei等[2]提出LDA(Latent Dirichlet Allocation)模型, 它是一个三层贝叶斯模型, 将文档看成不同的主题以一定概率分布组成, 每一个主题看成不同的词项以一定概率分布组成。Griffiths等[3]认为LDA模型提取的主题能捕捉到数据中有意义的结构, 从而阐明语义内容, 并对LDA模型中的β参数施加Dirichlet先验, 使之更加完整。
以LDA为代表的主题模型关注文本内容的语义挖掘, 而没有考虑外部特征, 为此本文提出一种基于LDA的改进主题模型, 融合了作者和时间两个外部特征, 旨在揭示文档内容、主题和作者之间的动态关系。
在LDA模型之后, 越来越多的研究人员通过扩展主题模型完成文本语义挖掘任务。Blei等[4]提出CTM(Correlated Topic Model)模型, 克服了LDA模型中不同主题之间弱相关性的缺点, 将主题之间的相关性用一个协方差矩阵表示, 有效地改进了主题抽取的效果。Li等[5]针对CTM只考虑两个主题间关系的不足, 提出了PAM模型。其核心思想是用有向无环图(DAG)描述文档中隐含主题之间的结构, 叶子节点是单词, 非叶子节点(主题)可以看成是由所包含的子节点(主题或词项)构成, 那么主题可能是词项概率分布, 也可能是(子)主题概率分布[1]。PAM模型的缺陷在于, 对主题概率分布进行采样的过程过于复杂, 不易于实现。Rosen-Zvi等[6]基于LDA提出Author-Topic 模型, 引入文档作者信息, 用于对文档内容和作者的建模, 作者可表示为一组主题的概率分布, 从而发现每个主题下的知名作者。Wang等[7]向LDA模型中添加一个作为观测值的时间随机变量后得到主题随时间变化的主题模型(Topic Over Time, TOT), 认为主题概率分布受到时间的影响, 而时间变量服从Beta分布。李文波等[8]在LDA模型基础上引入文本的类别信息, 提出Labeled-LDA模型, 在各个类别上协同计算隐含主题的分配量, 克服了传统LDA模型用于分类时强制分配隐含主题的缺陷, 有效改进文本分类的性能。王萍[9]验证了使用LDA主题模型进行文献知识挖掘的可行性, 对文献的文本信息和作者信息进行联合建模, 提出多维度文献知识挖掘方法。胡吉明等[10]基于动态LDA模型进行主题演化与挖掘, 在每个时间片内采用LDA模型进行主题挖掘, 其不足之处在于本质上还是对文本内容进行挖掘, 缺少外部特征。
针对主题模型仅限于分析文档的内部特征而不考虑外部特征的缺陷, 本文改进思路是在LDA模型的基础上融合文本内外部特征。借鉴胡吉明等[10]将文本按时间划分的思想, 但时间片之间的状态依赖关系不同, 创新点是在主题采样的过程中加入先验参数——作者主题概率分布, 通过作者主题概率分布发现作者研究兴趣变化。
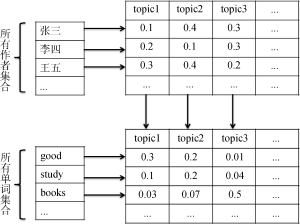
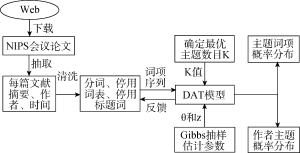
动态主题模型[11](Dynamic Topic Model)考虑了时间和文本主题的连续性, 作者主题模型[6](Author Topic Model)考虑了作者和文本主题之间的关系, 两者都是基于LDA模型引入了一种外部特征。本文结合上述两个模型的优势, 提出动态作者主题模型(Dynamic Author Topic, DAT), 首先将文档集划分到不同的时间片内, 在每个时间片内对子文档集进行建模分析, 文档中可观测变量是作者和词项, 每个作者都对应一个在主题上的多项分布, 每个主题都对应一个在词项上的多项分布, 如图1所示:
基于这个思想, 文档可表示为作者主题概率分布和主题词项概率分布, 在时间维度上进行观测, 还可发现作者研究兴趣变化、主题内容和强度变化。下面从模型输入、基本假设、模型表示和参数估计这4个方面对DAT模型进行论述。
主题模型的主要输入是文档集合, Griffiths等[3]将文本中的词分为两大功能: 一个是语义功能, 用于表示文档主题, 也就是特征词; 另一个是语法功能, 这些词的存在是为了让整个句子的生成过程看起来更像一个整体或者说更符合语言规范, 比如虚词、代词和量词等。这些高重复性的非特征词和文档主题无关, 需要在预处理中进行停用词(Stop Words)去除。经过预处理后的文档集, 实质上就是文档集的特征词序列。
另外一个重要的输入是主题个数T, 通常T的大小需要在模型训练前指定, 而且存在一定的经验性, 确定最优T的简单方法是用不同的T值进行重复实验, 也可采用困惑度(Perplexity)[12]指标确定最优主题数。
DAT模型包含的基本假设主要有: 文档的词顺序是可交换的; 文章各个主题之间不相关或者弱相关; 作者顺序是可交换的, 即文档中每个词均匀地随机地由某个作者产生; 不同时间片的模型参数满足一阶马尔科夫假设, 即仅与前一时间片的模型参数有关。
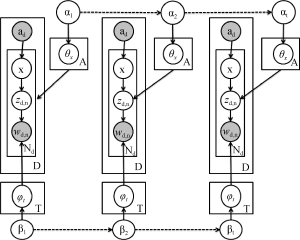
为了清晰地阐述DAT模型, 对本文所使用的符号进行说明, 如表1所示:
表1 符号说明
| 符号 | 描述 |
|---|---|
| D T V A Nd Ad ad θx ϕt x zd,n wd,n α β | 文档的数量 文档集所有主题的数量 文档集所有词项的数量 文档集所有作者的数量 文档d中特征词的数量 撰写文档d的作者数量 撰写文档d的作者向量 作者x的主题概率分布 主题t的词项概率分布 文档d中采样的某个作者 文档d中第n个单词的主题分配 文档d中第n个词项 θ的Dirichlet先验参数 ϕ的Dirichlet先验参数 |
DAT模型的概率图表示如图2所示, 实线箭头表示变量之间的条件依赖关系, 虚线箭头表示不同时间片内的参数渐变, 通过参数α和β的渐变构建不同时间片的文档子集之间的状态依赖, 矩形表示重复采样(生成), 其右下角字母表示采样次数, 可观察变量是文档的作者和词项, 表示为填充阴影的圆。该模型中, 在每个时间片内文档子集D的产生过程如下:
(1) 对于每个主题t 
(2) 对于每个作者x 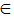
(3) 对于每篇文档中的每个词项wd,n:
① a采样一个作者xd,n~Uniform(ad);
② b采样一个主题zd,n~Multinomial(θxd,n);
③ c采样一个词项wd,n~Multinomial(ϕzd,n);
(4) 重复步骤(3)的采样过程Nd次, 生成文档d的全部特征词;
(5) 重复步骤(4)的采样过程D次, 生成整个文档子集。
对LDA模型进行参数估计的方法有很多, 常用的有VB (Variational Bayesian Inference)算法[2], EP (Expectation-Propagation)算法[13], Collapsed Gibbs Sampling[14]等。本文选择Gibbs抽样方法, 它是一种快速高效的MCMC (Markov Chain Monte Carlo)抽样方法, 利用每个变量的条件概率分布实现从联合分布中抽样, 通过反复抽样迭代, 得到参数估计值。
在LDA模型中有两组待估计参数: 文档主题概率分布和主题词项概率分布, 在DAT模型中, 需要估计的也是两组参数: 作者主题概率分布θ和主题词项概率分布ϕ。
对于每个时间片内的文档子集, 通过Gibbs采样为每个词项分配了主题z和作者x, 利用Dirichlet分布的期望, 推导如下计算公式:
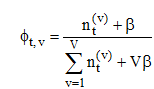
其中, 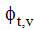
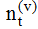
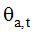
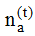
在典型的语言建模应用中, Dirichlet分布经常被用来刻画词项分布的不确定性[3], 本文中ϕt服从参数为β的Dirichlet分布, θx服从参数为α的Dirichlet分布。图2中虚线箭头表示相邻时间片的超参数渐变, 依据3.1节中的模型假设, 本文用u, v分别刻画α和β的渐变权重, 定义如下:
βt=ut×βt-1 (3)
ut=(Token)t/(Token)t-1 (4)
αt=vt×αt-1 (5)
vt= (Author)t/(Author)t-1 (6)
Token是当前时间片内文档子集的词项总数, Author是当前时间片内文档子集的作者总数, 因此当第一个时间片内的超参数取值确定时, 其后的取值均可确定。
从推断方法、时间、作者三个方面, 对比4个扩展主题模型的区别, 如表2所示:
表2 模型对比
| 比较项 | 作者 主题模型 | 动态 主题模型 | 作者主题 演化模型 | 动态作者 主题模型 |
|---|---|---|---|---|
| 推断方法 | Gibbs 采样 | 变分期望 最大化 | Gibbs 采样 | Gibbs 采样 |
| 如何处理时间 | / | 离散, 一阶 马尔科夫 | 连续, Beta 分布 | 离散, 一阶 马尔科夫 |
| 是否包含作者 | 是 | / | 是 | 是 |
实验过程设计如图3所示。实验的机器是HP ProDesk 600台式电脑, CPU是Intel i5-4590处理器, 内存4GB, 系统是Windows7 64bit版本。使用Eclipse开发工具, 用Java语言编写程序完成数据抽取、分词等预处理工作并实现DAT模型, 最终得到文档集的主题词项概率分布和作者主题概率分布。
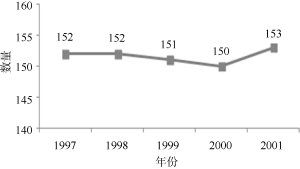
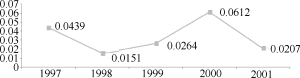
选取NIPS(Neural Information Processing Systems)会议论文作为实验数据。在Web of Science核心集数据库中, 以“NIPS”为会议关键词进行检索, 时间范围是1997-2001年, 得到758条记录, 检索结果的出版年份分布如图4所示, 将每个年度的检索结果集导出为纯文本格式, 得到原始实验数据集。
对以上文本数据进行预处理, 本文只对论文中的摘要、出版年份、作者进行分析, 不保留其他特征。利用正则表达式去除虚词、代词、量词等词项, 并去除词频低于3的词项, 按照年份进行分类汇总, 得到DAT模型的输入数据集。
主题模型中两个超参数的经验值取值一般为α=50/T, β=0.01[15], 对第一个时间片内的超参数取值也做上述处理。主题数目通常由用户输入, 其取值对于模型中的主题抽取和拟合性能影响较大, 其最佳值的确定主要通过两种方式: 词汇被选概率和困惑度[2]。困惑度是从模型泛化能力衡量主题模型对于新文本的预测能力, 困惑度越小表示模型的泛化能力越强, 产生文档的性能越高, 能够较为全面地评价模型效果。本文选取困惑度作为评测指标, Blei等[2]定义一个数据集的主题模型的困惑度为:
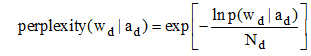
其中, wd是文档d的特征词向量, 表示所有词项, ad是文档d的作者向量, 表示所有作者。P(wdlad)表示在给定一组作者的情况下生成特征词向量的概率, Rosen-Zvi等[6]在作者主题模型中给出了其推导算式如下:
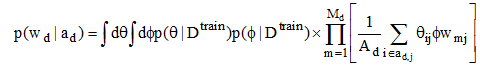
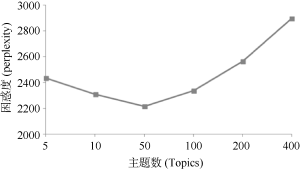
对于不同的K取值, 分别进行Gibbs抽样, 迭代次数500, 困惑度取值的变化情况如图5所示。因此, 选取的最优主题数目是T=50。
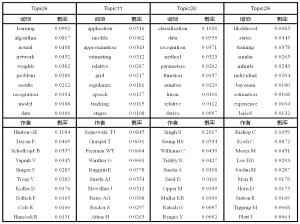
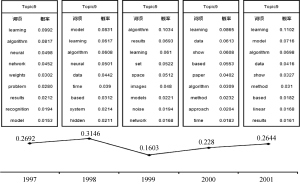
利用DAT模型, 对实验数据进行处理后得到作者主题分布和主题词项分布, 图6给出了1997年文档集的部分主题的表示, 每个主题表示为概率最大的前10个词项和前10个作者。
实验结果显示, 主题9关注“神经学习算法”方面的内容, 相关的研究人员有Hinton GE, Dayan P等人; 主题11关注“模型应用”, 相关研究人员有Sejnowski TJ, Graepel T等人; 主题20关注“数据分类和识别”, 相关研究人员有Singh S, Seung HS等人; 主题29关注“似然估计”, 相关研究人员有Bishop C, Koch C等人。通过DAT主题模型对文档集的隐含主题进行抽取, 将隐含主题表示为作者和词项的概率分布。观测同一个主题在不同时间片内的词项概率变化, 可实现主题演化分析。图7揭示了主题9在每个时间片内文档子集的词项分布变化, 下方的曲线表示主题的概率强度变化。从作者主题分布中, 可发现作者在各个时间片对同一主题的兴趣强弱变化。图8揭示了作者Willams C对Topic20的研究兴趣变化。
从海量科技文献中自动挖掘隐含主题、作者研究兴趣及其变化, 是情报研究的重要内容之一。目前以LDA为代表的主题模型对文本内容的特征抽取得到了广泛应用, 但是缺少对多个外部特征的融合分析。本文在研究动态主题模型和作者主题模型的优势后, 引入时间和作者两个外部特征进行扩展, 构造动态作者主题模型, 将文档表示为作者主题概率分布和主题词项概率分布, 并以NIPS会议的论文作为实验数据集, 通过吉布斯采样估算参数, 验证了模型的有效性。本文的不足之处在于, 模型的隐含假设是文档作者服从均匀分布, 与作者的排序无关, 文档主题服从多项分布, 不同主题之间具备弱相关性, 这与实际语料不符。
本文在以下两个方面值得进一步研究。
(1) 通过研究不同时间片内的主题词项概率分布, 发现主题内容变化和强度变化。主题内容变化可表示为主题的词项概率分布随着时间变化增大或减小, 带来主题语义上的变迁; 主题强度变化可表示为文档集中同一个主题在不同时间片上的概率大小, 带来文档主题的变迁, 从而实现主题演化分析。
(2) 研究作者主题概率分布, 研究人员在不同时间片内对同一个主题的关注度有强弱之分, 表现为研究兴趣的变迁, 从而发现作者的研究兴趣变化。
杨如意, 刘东苏: 提出研究思路改进模型, 设计研究方案; 杨如意: 采集、清洗、分析数据, 进行实验; 杨如意, 李慧: 分析结果, 起草论文; 杨如意, 刘东苏: 论文最终版本修订。

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}