姜霖
Jiang Lin
中图分类号: TP18 G35
通讯作者:
收稿日期: 2015-09-6
修回日期: 2015-11-3
网络出版日期: 2016-02-25
版权声明: 2016 《现代图书情报技术》编辑部 《现代图书情报技术》编辑部
基金资助:
展开
摘要
【目的】更准确便捷地完成术语词汇的自动抽取。【方法】利用CBOW模型计算构成术语的各个词部件的向量空间模型。通过词向量之间的余弦相似度衡量术语词汇内部各个词部件的关联度。利用PageRank算法计算候选词汇的领域代表性并排序, 通过阈值的设定, 抽取出更为具有领域代表性的术语词汇。【结果】在以自然语言处理领域内的论文摘要作为数据集的实验中取得较高的准确率和召回率。【局限】测试的数据训练集偏小, 而数据集的训练效果直接影响实验的效果。【结论】实验结果表明利用CBOW模型完成术语的抽取工作是一个较为合理、可行的方法。
关键词:
Abstract
[Objective] This study tries to extract domain terms more accurately and conveniently. [Methods] First, proposed a method using the CBOW model to build word vectors for each component of the terms. Then, applied the cosine similarity to calculate the internal correlation degree among each term’s individual components. To get more representative terms, we used the PageRank algorithm to rank the candidates. [Results] We obtained high recall and precision rates using the paper abstacts in the field of natural language processing as the training pool. [Limitations] The training pool was relatively small, which might influence the results. [Conclusions] This study shows that CBOW model is a more appropriate method to extract terminologies.
Keywords:
术语被定义为“特定专业领域中一般概念的词语指称”。许多专业领域的术语, 会伴随着学科的发展而产生动态的更新。新技术、新信息、新知识的产生会推动潜在的新术语词汇的出现。新术语被不停地引入到各个不同的学科领域中, 而旧术语则有可能逐渐消亡亦或是被赋予新的含义。术语和术语学这种动态变化的本质更加推动了术语处理技术的不断发展。
在术语的自动抽取中使用了很多自然语言处理技术, 如: 统计分析、词性标注、语义分析等。但同时, 自然语言处理应用中也需要与术语相关的信息来协助处理专业文档。比如: 机器翻译、自然语言生成、词典编纂、句法分析和自动文摘等。基于此, 实现高效、快速的术语自动抽取对于自然语言处理技术的发展有重要的意义。为了提高当前术语抽取的准确度, 本文提出一种基于词部件扩展算法和神经网络算法相结合的术语抽取方法, 利用神经网络的词向量计算方法构造词扩展部件的向量空间模型, 利用余弦相似度判断各个词扩展部件间的内部关联强度, 实现对术语候选词集的初步过滤, 最后结合PageRank算法, 统计候选集中各个词汇的领域代表性, 借此完成对领域术语词汇的精确抽取。
术语的构成一般分为单词型术语和多词型术语。在冯志伟主持建设的“数据处理术语数据库”GLOT-C中, 词组型术语就占了75.17%。吴云芳等[1]研究发现词组型术语的比例是74%, 而单词型术语仅为26%。张榕[2]则分析了一个包含8 150条术语的数据库, 并通过分词工具统计了这些术语的词长分布特征, 其中包含2、3、4个单词的术语最多, 一共占总数的71.723%, 而长度大于6的术语仅为0.572%。李芸[3]对56 609条网络技术术语进行统计分析, 发现单词型术语的比例为7.7938%, 而包含2到6个单词不等的词组型术语占据的比例为89.7101%。因此本文将主要的研究对象设定为多词型术语。
单语的术语抽取方法主要分为三类:
(1) 基于语言规则的方法, 即通过专家编写的术语词典和规则模板完成对术语的抽取[4-6]。该方法虽然精度较高, 但编写规则依赖于语言环境和领域主题, 难以实现移植。
(2) 基于统计特征的方法, 即基于术语内部词之间黏着度较高的假设, 利用统计特征实现术语抽取。目前在术语抽取中被成功使用的统计特征包括卡方检验、对数似然检验、互信息[7]和C-Value/NC- Value[8]等。但是仅仅依靠术语内部黏着度效果却并不理想, 为了能够大大提高准确率, 加斯特森和卡茨在1995年利用一个词性过滤器过滤候选短语, 这个过滤器只允许可能的“短语”的模式通过[9]。此外基于统计特征的方法还存在一些缺点, 例如互信息算法很难排除语料中超低频词和超高频词的干扰, 用来判断字词间的关联强度也存在缺陷, 并且难以扩展到多词术语中。
(3) 基于机器学习的方法, 即将术语抽取任务转化为分类问题或标注问题, 借助决策树(DT)、支持向量机(SVM)[10]、隐Markov模型(HMM)、条件随机场(CRF)模型[11]等, 但此类方法一般需要借助大量的人工标注语料。例如, 章成志[12]提出一种多层术语度的一体化术语抽取方法, 并采用句子术语度的概念, 将术语所在句子的所有词语均作为训练特征, 使用条件随机场识别术语, 但该方法依赖大量训练数据。Lee等[13]提出一种不依赖词典、以规则作为特征, 通过SVM分类抽取术语的方法, 但该方法的召回率偏低。
上述研究充分地利用了语法规则、统计方法两者的优点, 大大提高了术语抽取的准确率。但是传统的监督学习算法, 如利用CRF进行术语抽取, 需要大量的人工标注以提高抽取的准确性, 而使用SVM等无监督的抽取算法, 又会带来超低频词的平滑, 算法扩展性差等问题。基于此, 本文采用基于CBOW模型(Continuous Bag-of-Words Model)的神经网络算法有效解决这些问题。
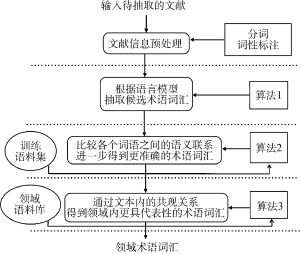
图1为术语抽取实验的算法框架。算法输入为待抽取的文本文献, 算法主要分为4个子函数层次, 分别为: 文献信息预处理层、语言模型抽取层、语义模型抽取层和领域代表性挖掘层。
(1) 文献信息的预处理层
对于待抽取术语的文献资料, 首先对其进行中文分词和词性标注处理, 本文采用中国科学院计算技术研究所开发的ICTCLAS分词软件[14]对采集的汉语语料完成分词和词性标注工作。由于术语是一种能够表述具体概念的语言单元, 隶属于实词的范畴。词性构成一般为名词、动词和形容词。针对术语词汇的这一特点, 利用分词软件抽取出待抽取术语语料中的所有词性为名词、动词和形容词的词汇。
(2) 语言模型抽取层
算法1主要是利用预处理过的已经分过词、进行过词性标注的语料, 利用语言模型提取出其中可能的候选术语语料集。为术语的抽取工作进行第一次初步的术语抽取和过滤。在实际操作过程中, 人为添加了停用词表, 例如“是”、“有”在文本语料中经常以动词的形式出现, 但很少含有实际意义, 也几乎不在术语词汇中出现, 所以在抽取时利用词表将其去除, 可以很好地提高抽取的效果。
(3) 语义模型抽取层
算法2主要是对初步筛选的候选术语进行进一步过滤, 利用神经网络算法计算出每个词分量的语义向量, 通过比较语义向量间的余弦相似度判断术语候选词中各个词扩展部件间的语义结合强度, 以此得到更为准确的候选术语词汇结果。
若向量 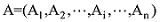
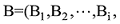
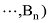
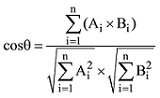
(4) 领域代表性挖掘层
算法3主要是为了评估得到的术语所具有的领域代表性, 为此本文借鉴PageRank算法计算各个词部件在领域中的重要程度, 并通过加和排序得到候选术语词集中最具有领域代表特征的术语词汇, 从而使术语的抽取工作达到更好的效果。
(1) 词部件扩展的使用原理
根据自然语言处理领域内术语的构成特点, 将研究重点设置为多词型术语。假设某一特定领域, 设T为该领域中一个多词型术语, 构成它的词或者词缀设为C, 其构成的术语集合为SETT={T|T=C1…Cm-1,C, Cm+1…Cn}, 集合SETT中的元素个数为n(n>1), 构成术语词汇的每个词或者词缀称之为词扩展部件, 由于大部分多词术语由两到三个词或者词缀组成, 所以将研究的词部件的个数上限设置为3, 即4>n>1。
(2) 术语语言模型运用原理
①术语是一种能够具体表述领域特征概念的语言单元, 隶属于实词的范畴。所以词性构成一般为名词、动词和形容词。
②根据周浪[15]的统计分析, 在两个词和三个词构成的术语中Top5的词法模式如表1所示, 其中N代表名词, V代表动词, A代表形容词。
表1 两词和三词术语Top5词法模式表
| 两词术语 | 三词术语 | ||||
|---|---|---|---|---|---|
| 序号 | 词性序列 | 示例 | 序号 | 词性序列 | 示例 |
| 1 | N+N | “自然/n语言/n” | 1 | N+N+N | “句法/n标注/n语料库/n” |
| 2 | V+N | “测度/v空间/n” | 2 | N+V+N | “电路/n交换/v网络/n” |
| 3 | N+V | “机器/n学习/v” | 3 | V+V+N | “并行/v虚拟/v机/n” |
| 4 | V+V | “编译/v优化/v” | 4 | N+N+V | “自然/n语言/n处理/v” |
| 5 | A+N | “单调/a函数/n” | 5 | V+N+N | “插/v值/n算法/n” |
根据术语词汇中的词性构成特点, 将本文重点研究的语言模型设定为表1中的10种。在实际术语词扩展部件的选取过程中, 主要采用ICTCLAS分词软件对采集的汉语语料完成分词和词性标注工作。利用术语词汇的语言模型对候选术语完成初步提取工作。
(3) 术语词扩展部件的向量构建原理
本文中单词词向量的构建主要依据神经网络技术, 采用CBOW模型[16-17]为词扩展部件构建词向量空间模型。
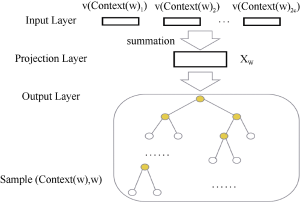
该模型的主要思想是在已知当前词Wt的上下文Wt-2,Wt-1,Wt+1,Wt+2的前提下预测Wt。CBOW模型的网络结构主要包括三层: 输入层、投影层和输出层, 如图2所示。
①输入层: 包含Context(w)中2c个词的词向量v(Context(w)1), v(Context(w)2)… v(Context(w)2c)∈Rm, m表示词向量的长度。c表示在词w的前后各取c个词。
②投影层: 将2c个向量做求和累加, 如下所示:

③输出层: 输出层对应一棵二叉树, 以语料库中出现的词作为叶子节点, 以各词在语料中出现的次数作为权值构造出霍夫曼树, 树中叶子节点共N(N=|D|)个, 分别对应词典D中的词, 非叶子节点N-1个(在图2中用深色标注的节点)。
实验主要采用基于Hieratchical Softmax的CBOW模型。目标函数通常为如下所示的对数似然函数:
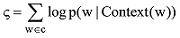
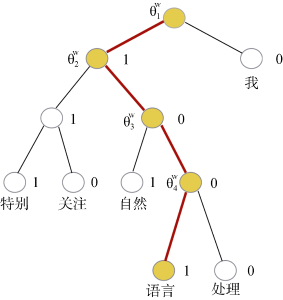
如图3中的霍夫曼树所示, 对于词典中的任意词w, 霍夫曼树中必存有一条从根节点到词w对应节点的路径pw(且这条路径是唯一的), 路径pw上存在Yw-1个分支, 将每个分支看成一个二分类, 每次分类就产生一个概率, 将这些概率乘起来就是所需的p(w|Context(w))。使用随机梯度上升法, 使目标函数最大化。这个神经网络中输出层的霍夫曼树的叶子节点上的向量为实验中使用的词向量。
(4) 基于语义的领域术语过滤原理
由于术语不同于一般的普通短语, 是领域内具有表征概念的词语。所以术语词汇需要在所代表的领域内具有代表性。在领域文本集中, 候选术语之间通过共同的上下文建立关联关系。在领域语料中的某个候选术语被其他候选术语关联越多, 说明它越具有领域代表性, 越有可能成为术语。为了能够体现出术语间的这种领域代表性, 借鉴PageRank算法[18], 求出组成术语的各个词扩展部件在领域内的重要程度, 以此进行排序, 得到更具有领域代表性的术语词汇。
术语领域代表性的计算方法如下所示:
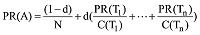
其中, N表示词总数, PR(A)表示词A的PageRank值, PR(Ti)表示和词A共现的Ti的PageRank值, C(Ti)表示词Ti和其他词共现的数量, d为阻尼系数, 取值范围为: 0<d<1。在实际计算中每个词的初始PageRank值设为1, 阻尼系数设为0.85。
实验利用网络爬虫从中国知网(CNKI)中以“自然语言处理”为检索主题, 抽取1 500篇文献的中文摘要作为训练样本, 并对其中的500篇完成人工标注作为对比实验样本, 共得到7 642个术语词汇(主要为两词和三词词汇), 平均每篇摘要约15个术语词汇。人工标注提取的术语词汇如图4所示:
准确率和召回率是广泛用于信息检索和统计学分类领域的两个度量值, 用来评价结果的质量。笔者在术语的抽取实验中也采用准确率、召回率和F1值作为评价参考, 考量方法的实际使用效果。
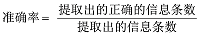


以α、β作为判断词扩展部件间的关联强度和所具有的领域关键性的阈值设定。经过多次的反复对比实验, 得到的结果具体如表2所示。从表2中可以直观地发现当α=0.6, β=0.015时, F1值相对最高, 实验得到比较高的准确率和召回率。
表2 实验结果
| 实验号 | α | β | 准确率 | 召回率 | F1值 |
|---|---|---|---|---|---|
| 1 | 0.5 | 0.0015 | 0.84 | 0.55 | 0.56 |
| 2 | 0.6 | 0.0015 | 0.87 | 0.60 | 0.71 |
| 3 | 0.7 | 0.0015 | 0.82 | 0.62 | 0.70 |
| 4 | 0.6 | 0.0014 | 0.83 | 0.53 | 0.65 |
| 5 | 0.6 | 0.0016 | 0.80 | 0.51 | 0.62 |
为了能够更加清楚地展示实验效果, 示例将文献摘要“统计自然语言处理中, 一个很复杂的问题是数据稀疏问题。主要有两种平滑方法解决: 回退法和线性插值法。本文分析和比较了几种典型的线性插值方法, 着重研究了它们所引发的词性聚类倾向。在此基础上, 给出了2种改进的平滑方法。实验结果表明, 改进的方法比原来的方法有更出色的平滑效果。”作为输入文本语料, 从中抽取的具体术语结果如下:
可以发现, 由于像“方法”这样的词汇在文本语料中的使用比较频繁而且和其他词汇都比较容易搭配, 导致“方法解决”和“方法着重”在抽取过程中很难被过滤。在今后的实验方法上, 应该更关注这样的词汇, 希望通过其他的方法进一步提高术语抽取的准确度和召回率。另外由于设计的语言模型有限, 所以例如“数据稀疏问题”这样的术语词汇未被抽取出来。随着语言模型的扩展添加和训练语料的扩展, 实验的准确率和召回率可以得到进一步提升。
将实验方法与使用N-Gram模型建立向量空间模型作为Baseline对比, 准确率有明显提高。使用神经网络模型较N-Gram模型主要有两个优势:
(1) 词语之间的相似性可以通过词向量体现。举例来说, 如果S1=“计算机 软件”和S2=“电脑 软件”在语料中分别出现1 000次和1次, 按照N-Gram模型, P(S1)一定大于P(S2), 但是“计算机”和“电脑”是同义词并且承担相同的语法作用, 所以P(S1)应该与P(S2)相似才更合理。在基于神经网络的算法中, P(S1)与P(S2)是相近的, 原因在于: 在神经网络概率语言模型中假定“相似”的词对应的词向量也是相似的。并且概率函数关于词向量是光滑的, 及词向量中的一个小变化对概率的影响也只是一个小变化。
(2) 基于词向量的CBOW模型自带平滑功能, 由于p(w| Context(w))∈(0,1), 不为零, 所以不需要额外处理。此外与传统的基于CRF模型的抽取实验比较, 在只进行少量的语料标注的情况下, 基于CBOW模型的抽取实验在准确率和召回率上都明显优于CRF模型。
本文针对术语生成方式和结构特点, 提出一种基于词部件扩展和神经网络相结合的术语抽取方法。与前人的研究相比, 采用基于神经网络的CBOW模型构建基于语义的词部件向量空间模型, 很好地解决传统互信息方法存在的词平滑问题, 此外这种方法还可以避免大量的人工标注。通过利用向量间的余弦相似度衡量各个词扩展部件间的关联强度, 通过关联强度的阈值设定完成术语词汇的抽取, 可以有效地提高方法的可扩展性, 加强对长术语的抽取效果。
综合而言, 基于神经网络的词向量构建, 便于以大量的领域语料库作为支撑, 利用部件的领域聚合性特征完成术语抽取, 并且可以得到较高的术语抽取召回率和准确率。但由于本次实验采集的数据量的限制, 词扩展部件的向量计算和词领域代表性计算可能不精确, 随着训练数据集的加大, 实验得到的准确率和召回率可以进一步提升。
姜霖: 提出研究思路, 进行实验与论文起草;
王东波: 改进研究方案, 采集数据;
姜霖, 王东波: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, 可通过电子邮件向作者索取, E-mail: 18205185622@163.com。
[1] 姜霖, 王东波. TermExtraction.rar. 术语自动抽取实验的程序代码.
[2] 姜霖, 王东波. WordTraining.rar. 训练语料.

/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}