孟园 , 王洪伟
, 王洪伟
同济大学经济与管理学院 上海 210000
Meng Yuan, Wang Hongwei
中图分类号: G350
通讯作者:
收稿日期: 2015-12-9
修回日期: 2016-02-7
网络出版日期: 2016-04-25
版权声明: 2016 《现代图书情报技术》编辑部 《现代图书情报技术》编辑部
基金资助:
展开
摘要
【目的】在有效提取多维特征基础上, 考察评论内容特征对评论质量检测的影响。【方法】基于评论文本的信息特征度量和情感倾向的混合性, 量化并抽取评论内容特征, 采用GBDT模型评估特征集合分类效果, 结合贪婪式特征选择算法识别有效内容特征, 分析其对评论质量检测的影响。【结果】将评论内容特征应用于评论质量检测任务中能取得较好的效果, 明显提升了实验准确率和召回率。【局限】实验对象主要是搜索型产品的评论数据, 未对其他享受型产品(如电影、音乐)等进行验证和比较。【结论】评论内容的信息增益、产品特征词的信息增益、评论客观情感倾向度、内容差异性对评论质量检测有明显作用。
关键词:
Abstract
[Objective] This paper aims to effectively extract multi-dimensional characteristics of online reviews and then examine the impact of text content to the review quality evaluation. [Methods] First, we quantified and extracted content features based on the textual and sentimental message from the reviews. Then, adopted the GBDT model to evaluate the influence of feature sets to classification results, along with greedy feature selection procedure to identify the most effective content features. Finally, we examined the influences of these features. [Results] The proposed method could improve the performance of review quality evaluation tasks, especially the recall and precision of the new system. [Limitations] Our research focused on review data from search services, and did not investigate products like movies and music. [Conclusions] The information gained from reviews and product feature words, degree of sentimental objectiveness, and differences among review contents all posed important effects to review quality evaluation.
Keywords:
随着互联网技术的日益成熟, 消费者网络点评积极性逐渐增强, 网络上产生了数量庞大的评论数据。用户利用这些评论信息辅助购买决策的同时, 也饱受评论质量参差不齐、信息过载等问题的困扰, 仅依靠人工方法难以从海量的评论中识别出真正对用户有价值的信息, 迫切需要自动化方法辅助人们进行甄别, 因而对在线评论的质量进行检测具有重要的研究价值。
一些购物网站通过设置“有用性投票”对评论质量进行排序, 基于此, 学者普遍认为消费者对评论的感知有用性度量了评论的质量或效用, 有用性程度越高, 代表评论质量或效用越高, 因而评论质量、评论效用与评论有用性一般视为同等概念[1-2]。现有文献对评论质量的检测方法主要分为两种: 计量回归方法和监督学习方法。前者一般以元数据特征(如评论评分、评论者身份)或语言特征(如评论字数、词语数等)作为自变量, 评论有用性投票比例作为因变量, 考察哪些元数据特征或语言特征对评论质量影响显著。而后者则将评论质量的检测视为分类问题, 采取设置有用性投票比例阈值或人工标注方法生成有用评论训练模型, 利用最优模型自动识别高质量评论, 效果相对较好。由于评论质量受多种特征因素影响, 如何选择有效特征是评论质量检测的关键。目前, 国内研究对有用评论的特征选择集中在元数据特征、语言特征的等方面[2-6], 对文本内容特征的挖掘还不够深入, 较少涉及特征的贡献度和选择机制分析。
本文以梯度提升决策树模型(Gradient Boosting Decision Tree, GBDT)作为分类模型, 在提取多维特征基础上, 重点考察评论内容的信息特征和语义情感特征在分类模型上的表现, 进一步利用贪婪式特征选择算法识别有效的内容特征集合, 深入揭示多维评论特征的影响效果。
现有研究中影响评论质量的特征大致可以分为三大类: 元数据特征、语言特征和评论内容特征。杨铭等[2]指出元数据特征与文本内容信息和文本语言特征无关, 评论评分、评论有用投票数、评论总投票数等是重要的元数据特征。Kim等[7]研究表明评论发表距今的时间是显著影响评论质量的元数据特征。Ghose等[8]认为, 评论者相关信息是有效的元数据特征, 例如评论者以往发表的评论数及有用率、评论者身份等。语言特征则主要是指从词频统计的角度发现评论的特征。如Ghose等[8]、Li等[9]、Liu等[10]指出主要的语言特征应包括评论字数、句子数、不同词性(名词、动词、形容词等)的词语数等。Chen等[11]强调在评论所包含的名词中, 产品属性名词的频次是重要的语言特征, 高质量的评论中应包含一定数量的产品属性名词。从这些研究中, 可以发现元数据特征和语言特征属于外在层面的评论特征, 与此相对应的, 内在层面的特征基于评论文本内容, 消费者阅读评论后, 能了解其他用户对产品的正面或负面的观点评价, 从而对产品认知获取到一定程度的信息量, 以消除对产品认知的不确定性。王伟等[12]指出正是这些从评论内容中获取的信息真正影响了消费者的购买意愿, 聂卉等[1]重点验证了评论情感特征对评估评论效用具有较好效果, 可见, 评论内在特征是消费者判断评论质量的重要依据。
已有研究主要采取计量方法和监督学习方法检测评论质量。计量方法研究一般以有用性投票比例作为评论质量的代理变量, 比例越高, 评论质量越高。如Ghose等[8]采用多元线性回归方法, 对DVD产品的评论数据进行验证, 得出评论者特征和评论语言特征对评论质量有显著正向影响。同样采用计量方法的还有文献[5-6], 分别得出评论字数、评论评分、评论长度等特征能影响评论质量。另一方面, 监督方法将评论质量检测视为一个分类问题, 通过人工标注或设置有用性投票比例阈值标注有用评论训练集, 利用提取的特征集来测试和评估分类器效果, 从而发现有效的评论特征, 以自动识别高质量评论。如聂卉等[1]利用有用性投票比例作为评论质量代理指标, 设置合理阈值生成有用性评论训练集, 采用随机森林方法检测评论质量。另外, 以人工标注获得训练集, Liu等[10]采用支持向量回归、决策树等机器学习方法进行比较, 以得到性能最优的分类模型。Chen等[11]构造了多层支持向量机对评论质量进行分类。
由以上文献综述分析得出, 特征选取对于评论质量的检测十分关键。现有研究大多关注语言特征和元数据特征等外在特征, 虽有少数学者专门验证了文本内容情感特征的作用, 但鲜有全面考察外在特征和内在特征对评论质量的影响。评论内容特征对评论质量的影响是否明显?特征选择顺序是否影响分类效果?这些问题仍然需要得到解答。针对现有研究的不足, 本文的目标是采用GBDT监督学习方法, 深入、全面挖掘影响评论质量的有效特征集合, 考察评论内容特征对评论质量的影响。因而, 研究过程从以下三个方面展开:
(1) 提取评论内容的内在特征, 包括信息特征和语义情感特征。
(2) 采取GBDT分类方法和贪婪式特征选择算法, 识别有效特征集合和最佳分类模型。
(3) 分类模型的性能评测和比较。
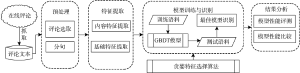
本文将评论质量检测任务建模为二元分类问题, 在对文本多维特征有效提取的基础上, 采用梯度提升决策树模型(GBDT)和贪婪式特征选择算法进行最佳模型识别。对评论质量进行分类学习。GBDT模型组合“基学习器(Base Learner)”, 经多次迭代, 每次迭代过程根据损失函数在梯度下降方向上建立决策树模型, 使得相加的损失函数(Loss Function)最小, 通过迭代改进能获得比基学习器更为良好的分类性能, 在分类、回归等研究问题上表现优异[13-14]。本文研究的主要任务包括实验评论选取、分句、特征提取、特征选择、模型训练与模型识别、实验结果分析等过程, 研究框架如图1所示。
本文的重点是考察评论内容特征的效果, 因此重点阐述评论内容相关特征的提取方法, 着重从文本内容蕴含的信息特征和语义特征两方面, 提取8个特征, 如表1所示。
表1 各种内容特征概述
| 内容特征集合 | 特征定义 | 特征描述 |
|---|---|---|
| 信息 特征(I) | I1: IGain(r) | 评论r的信息量 |
| I2: IGainf(r) | 评论r包含的特征词信息量 | |
| I3: Entropy(r) | 评论r的信息熵 | |
| I4: Perplexity(r) | 评论r的困惑值 | |
| 语义情感 特征(S) | S1: ObjDegree(r) | 评论r的客观情感倾向度 |
| S2: DevObj(r) | 评论r的客观情感倾向度偏差 | |
| S3: PosDegree(r) | 评论r的正向情感倾向度 | |
| S4: DevPos(r) | 评论r的正向情感倾向度偏差 |
(1) 信息特征提取
①评论内容的信息量
从信息论的角度来看, 评论r蕴含的信息量越大, 这条评论对用户越有用。评论中不同的词语为评论有用性贡献不同的信息量, 因而本文利用词语的信息增益量化评论r 的信息量。
对于给定的在线评论集合R, 以C=(c1, c2)表示评论空间有用性类别, 其中c1表示有用类别, c2表示无用类别, 则判断二分类系统所需的信息熵总量H(C)为:
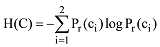
其中, Pr(ci)为系统中类别ci的出现概率。
评论r由多个不同的词组成, 考虑评论中的某个词语t, 其可能的取值为两种, 出现或不出现, 分别用w和 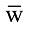
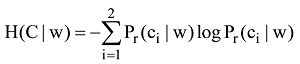
其中, Pr(ci|w)为t出现的评论中, 类别ci出现的概率。
同理, 可以得到t不出现(即t取值为 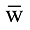
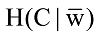
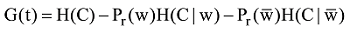
其中, Pr(w)表示t的出现概率, 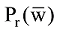
由于G(t)考虑的是词t在两个类别(c1和c2)整体上的贡献度之和, 考虑到有用评论能帮助用户消除对产品不确定性的认知, 而无用评论不仅无法给用户购买决策提供支持, 可能还会影响用户对产品的正确判断, 因而词t在有用类别不同评论中, 其信息增益方向是不同的。为了更好地体现t在两个类别中信息增益的差异, 借鉴文献[15]对词t的信息增益进行改进, 在t出现的所有评论中, 比较有用类别和无用类别的出现概率, 即Pr(c1|w)和Pr(c2|w), 如果前者大于后者, 则词语t代表正向信息增益, 反之则代表负向信息增益。改进后的词t的信息增益IG(t)表示为:

由此, 评论r的信息量IGain(r)表示为r中所有词语的信息增益之和, 公式如下所示:
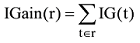
文献[12]表明评论中产品特征词相比其他词语, 其信息增益对于用户判断评论质量作用更大, 为此, 考察每个产品特征词f提供的信息增益IG(f), 并提取每条评论中所有特征词的贡献的信息量 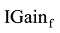
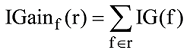
②评论内容的差异性
文献[16]指出, 内容越相似的评论越有可能是虚假评论, 这反映出评论内容与其他评论内容的差异性影响用户对评论质量的感知。贾里尼克在文本信息熵基础上, 定义了困惑值的概念, 两者同时使用, 可以度量一条评论与其他评论在内容上的差异性[17]。对于评论集合R, 如果评论r和其他评论内容差异越大, 则评论r的信息熵和困惑值就越大。假设评论r由一连串特定顺序排列的词w1,w2…wn组成, p(wi)为r中词语wi出现的概率, 则该条评论的信息熵Entropy(r)和困惑值Perplexity(r)的表示如下:
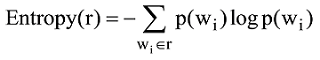
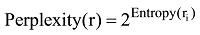
本文以每个产品型号对应的评论子集分别作为训练语料, 构建unigram统计语言模型, 再使用训练模型计算对应子集内每条评论的信息熵和困惑值。
(2) 语义情感特征提取
评论中经常呈现出混合观点形式, 既包含正面或负面情感, 也有主观或客观情感。通常, 评论观点的正负面情感倾向由评论中的观点词极性来决定, 而评论的主客观情感倾向则由评论者对商品属性点评与商家描述的一致性程度度量[18], 即评论文本与商家描述内容越相似, 说明评论的用语比较正式, 评论文本趋向于客观。例如评论句:
“这款产品性能挺优越的, 外观上也非常小巧漂亮。性价比一般吧, 因为价格有点高。总体来说, 我还是非常喜欢的!”
从情感极性上来看, 这条评论表达了正向和负向两种情感倾向, 但整体而言情感表达是正向的, 而从内容的主客观性上分析, 前两句评论相比后一句评论, 则更接近于客观的评论。为全面度量评论中情感的混合性对评论质量的影响, 以下定义客观情感倾向度ObjDegree及其偏差DevObj、正向情感倾向度PosDegree及其偏差DevPos等4个特征项。
①客观情感倾向度及其偏差
以评论子句为单位, 考察评论内容与产品描述文本的余弦相似性, 判断其客观性。利用文本词语的tf-idf权值对评论子句s和商品描述d分别进行向量表示, 计算两者的余弦相似度sim(s,d), 设定阈值λ判断评论子句的客观性。以s+表示r中客观的评论子句, total(r)为评论r中的评论子句总数, 则评论r客观情感倾向度计算公式为:
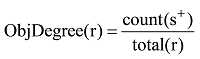
对于同一产品p的所有评论平均客观情感倾向度, 均匀地反映整体主客观观点句比例的稳定值, 将评论r的客观情感倾向度与整体均值进行比较, 偏差越大, 说明评论r中越有可能呈现一致性观点(都是客观或都是主观观点), 偏差越小, 说明评论r越有可能呈现主客观混合观点(既有客观观点也有主观观点)。
因此, 基于产品p所有评论的平均客观情感倾向度, 定义评论r的客观情感倾向偏差, 表示评论主客观情感混合程度, 其计算公式为:
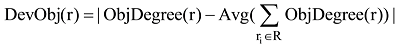
②正向情感倾向度及其偏差
评论一般由多个观点子句构成, 以正向观点子句的占比代表评论的正向情感倾向度, 占比越大, 说明整条评论偏向于正向情感, 反之则偏向于负向情感, 因而, 正向情感倾向度表达了评论的情感极性特征。以评论r中的子句为单位, 判断其情感极性。本文采取机器学习方法对评论子句进行情感极性分类。从实验语料中选取5星评分和1星评分评论各1 000条构建情感分类器。根据卡方统计值选择前1 500个单词(unigram)和双词(bigram)作为文本情感极性分类特征项[1], 在Python环境下选择分类效果最好的BernoulliNB作为分类器对评论子句正负情感极性进行判别。以r+表示r中正向的评论子句, total(r)为评论r中的子句总数, 则评论r的正向情感倾向度计算如下:
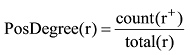
同理, 正向情感倾向偏差度量了评论r的正负情感混合程度特征, 其计算如下所示:
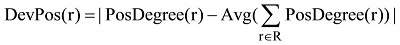
(1) 基础特征模板
由于评论质量与评论元数据特征(Meta)和语言特征(Lan)密切相关, 为此将元数据特征和语言特征作为基本特征集合, 构建分类模型的特征模板。根据文献[3,5,7-8,10-11]中研究结论, 提取6个有效元数据特征(M1-M6)和3个语言特征(L1-L3), 如表2所示:
表2 基础特征集合
| 特征 | 描述 |
|---|---|
| M1 | 评论r的有用投票率, 评论r获得的有用投票 数除以总投票数 |
| M2 | 评论r获得的有用投票数 |
| M3 | 评论r对应的用户评分 |
| M4 | 评论r发表至今的时间 |
| M5 | 评论r对应的评论者排名 |
| M6 | 评论r对应的评论者以往评论的平均有用率 |
| L1 | 评论r包含的字数 |
| L2 | 评论r包含的词语数 |
| L3 | 评论r的产品特征词数 |
(2) 贪婪式特征选择算法
为了能够从提取的文本内容相关特征集中分别选择有利于评论质量检测的特征集, 以元数据特征和语言学特征为基本特征集合, 以提取的内容特征为候选特征集合, 采用贪婪式特征选择算法[19]和GBDT分类模型进行特征选择。主要思路为: 根据每个候选内容特征在开发集DevData上对分类任务的贡献度大小, 每次选取贡献度最大的特征加入基本特征集合, 当从剩余候选特征集中添加任意特征时, 导致开发集的分类评价指标下降或剩余候选特征集为空时, 算法终止。算法的执行流程如下:
输入: 读入所有特征集合Fall={M1~M6,L1~L3,I1~I4,S1~S4}
输出: 有效特征集合Fselect={set of selected features}, Mselect= {selected model}
1: 初始化基础特征集合、候选内容特征集合, Fselect={ M1~M6, L1~L3},Fcan=Fall-Fselect
2: 训练模型, 得到初步分类性能Mselect=GBDT_Train(Fselect), Eselect=Evaluate(Mselect, DevData)
3: 对文本内容特征进行选择
4: loop
5: for each feature fi in Fcan do
6: Fi= FselectU fi
7: Mi= GBDT_Train(Fi)
8: Ei= Evaluate(Mi, DevData)
9: end for
10: Emax=Max(Ei)
11: If Emax> Eselect then
12: Fselect= FselectUfmax
13: Mselect=Mmax
14: Eselect= Emax
15: Fcan= Fcan-fmax
16: end if
17: if Fcan= = or Emax<= Eselect then
18: return Fselect, Mselect
19: end if
20: end loop
其中, 算法第5-9行为每次从候选特征集合Fcan中选择一个特征fi加入有效特征集合Fselect, 执行分类模型并记录其对应分类指标Ei; 算法第10-16行为比较当前每个特征fi对应的分类指标, 确定最大贡献度的fi和其加入有效特征集合的顺序。
利用爬虫程序抓取中文亚马逊网站的数码相机的相关评论信息和产品信息, 采集评论文本、评论元数据信息和产品描述文本, 数据采集截止时间为2013年9月2日, 评论发表时间跨度为2009年1月7日到2013年9月1日, 共采集了15 327条评论。选择其中评论总数大于50条的产品作为实验对象, 去除重复、广告评论等预处理操作后, 得到10 568条有效评论数据, 涵盖10个相机品牌、67个型号的产品。具体统计信息如表3所示:
表3 评论数据特征统计
| 评论相关属性 | 最小值 | 最大值 | 平均值 |
|---|---|---|---|
| 评论字数 | 1 | 3 296 | 62.93 |
| 评论词语数 | 1 | 1 961 | 38.13 |
| 评论产品特征词数 | 0 | 192 | 3.33 |
| 评论有用性投票数 | 0 | 1 122 | 2.01 |
| 评论有用率 | 0 | 1 | 0.20 |
| 评论评分 | 1 | 5 | 4.38 |
| 评论发表时间(log) | 0.47 | 3.23 | 2.51 |
| 评论者排名(log) | 1.77 | 6.64 | 5.90 |
| 评论r对应的评论者以往评论的平均有用率 | 0 | 1 | 0.38 |
鉴于有用性投票率有较大偏差, 借鉴文献[20], 对评论质量进行人工标注。邀请两名数码产品资深用户对实验数据进行独立标注。标注者逐条阅读所有评论, 并回答问题“该评论内容对您了解产品或购买产品有用吗?”。除了评论文本外, 还提供标注者评论对应的产品简要描述。经过对标注结果的Cohen-Kappa检验, 两名标注者的标注结果Kappa值达83.45%, 可见标注者对于实验数据的质量评价标准达到了较高的一致性。以标注者1的标注结果训练和测试模型。最终获得5 307条高质量评论和5 261条低质量评论。
采用GBDT模型对评论质量进行分类, 经过测试, 分类中建立25棵树模型能达到最优分类效果。将实验数据按4:1分成训练集和测试集进行特征选择, 采用平均准确率、平均召回率和平均F1值作为评价标准, 分别记为P、R、F1。
实验机器是Win7 32bit操作系统, 内存4GB。使用Python语言编写程序, 在Python2.7.3下完成所有程序编写及测试。以下为部分文本内容特征抽取结果。
(1) 词语信息增益
利用实验数据的评论质量标注结果, 对评论进行分词、去停用词操作后, 计算评论集合词语(仅计算词性为n、v、a、d、vn)的信息增益。有效词语共计11 729个, 部分词语的信息增益计算结果如表4所示:
表4 部分词语信息增益计算结果
| WordID | 词语 | 正向信息增益 | WordID | 词语 | 负向信息增益 |
|---|---|---|---|---|---|
| 1 | 镜头 | 0.026199 | 11 | 签单 | -0.000201 |
| 2 | 电池 | 0.019720 | 12 | 时机 | -0.000204 |
| 3 | 拍 | 0.019718 | 13 | 拍下 | -0.000207 |
| 4 | 机身 | 0.018958 | 14 | 正品 | -0.000212 |
| 5 | 快门 | 0.017846 | 15 | 涨价 | -0.000270 |
| 6 | 照片 | 0.017434 | 16 | 骗 | -0.000274 |
| 7 | 清晰 | 0.016422 | 17 | 看上 | -0.000286 |
| 8 | 功能 | 0.016267 | 18 | 不贵 | -0.000349 |
| 9 | 屏幕 | 0.015868 | 19 | 自毁 | -0.000381 |
| 10 | 对焦 | 0.015324 | 20 | 帮别人 | -0.000467 |
(2) 部分特征抽取结果
对实验语料进行分词、分句等操作后, 按3.1节所述特征提取方法提取特征, 部分评论内容特征提取结果如表5所示。
表5 部分内容特征提取结果
| ReviewID | IGain | IGainf | Entropy | Perplexity | ObjDegree | DevObj | PosDegree | DevPos |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.024422 | 0.002269 | 8.849878 | 461.401121 | 0.400000 | 0.020892 | 0.200000 | 0.355263 |
| 2 | 0.031540 | 0.008544 | 8.301512 | 315.503415 | 0.222222 | 0.156886 | 0.000000 | 0.555263 |
| 3 | 0.093255 | 0.036050 | 8.495248 | 360.848181 | 0.466667 | 0.087559 | 0.066667 | 0.488597 |
| 4 | 0.026955 | 0.008158 | 8.554623 | 376.008819 | 0.800000 | 0.420892 | 0.200000 | 0.355263 |
| 5 | 0.199504 | 0.022060 | 8.115530 | 277.343496 | 0.350000 | 0.029108 | 0.400000 | 0.155263 |
| 6 | 0.043566 | 0.002513 | 8.069165 | 268.572038 | 0.375000 | 0.004108 | 0.625000 | 0.069737 |
| 7 | 0.054861 | 0.000000 | 9.680146 | 820.378626 | 0.500000 | 0.120892 | 0.000000 | 0.555263 |
| 8 | 0.014244 | 0.000000 | 8.913717 | 482.276570 | 0.200000 | 0.179108 | 0.000000 | 0.555263 |
| 9 | 0.137508 | 0.076782 | 7.904827 | 239.656882 | 0.666667 | 0.287559 | 0.750000 | 0.194737 |
| 10 | 0.017129 | 0.000000 | 8.130206 | 280.179206 | 0.250000 | 0.129108 | 0.500000 | 0.055263 |
(1) 文本内容特征的效果
以元数据特征和语言特征作为基础特征, 然后依次加入文本内容特征。表6显示了分别加入单个文本内容特征的效果。
表6 加入单个文本内容特征的效果
| 特征 | P(%) | R(%) | F1(%) |
|---|---|---|---|
| Meta+Lan | 72.92 | 74.20 | 73.56 |
| +I1 | 77.15 | 74.56 | 75.83 |
| +I2 | 76.56 | 75.88 | 76.22 |
| +I3 | 76.60 | 76.06 | 76.33 |
| +I4 | 76.60 | 76.06 | 76.33 |
| +S1 | 76.60 | 76.06 | 76.33 |
| +S2 | 76.51 | 75.97 | 76.24 |
| +S3 | 76.53 | 76.06 | 76.30 |
| +S4 | 76.53 | 76.06 | 76.30 |
从表6可以看出, 加入单个内容特征后, 评论质量的分类准确率和召回率都有一定程度的提高, F1可以提高近3个百分点, 验证了内容特征对评论质量检测的有效性。但依次加入内容特征后, 分类指标值呈现先上升后下降的趋势, 说明有些特征项的效果不明显, 因此有必要进行特征选择, 去除没有帮助的特征项。根据3.2节的特征选择算法得出, 依次按照{I1,I2, S1,I3,I4}特征组合顺序, 可以达到最好的分类效果。表7显示了利用贪婪式特征选择算法所选择的特征组合的分类效果, 因此, 将特征组合{I1,I2,S1,I3,I4}及其顺序作为最终有效的评论内容特征集合。
表7 贪婪式特征选择结果
| 特征 | P(%) | R(%) | F1(%) |
|---|---|---|---|
| Meta+Lan | 72.92 | 74.20 | 73.56 |
| +I1 | 77.15 | 74.56 | 75.83 |
| +I2 | 76.56 | 75.88 | 76.22 |
| +S1 | 76.60 | 76.06 | 76.33 |
| +I3 | 76.67 | 76.06 | 76.36 |
| +I4 | 76.67 | 76.06 | 76.36 |
从表7可以看出, 过滤了冗余后的特征项中, 仅有客观情感倾向度(S1)为有效情感特征, 说明正式、客观的评论内容能影响评论质量。而所有信息特征对评论质量都具有明显作用, 其中作用最大的是整体评论的信息量(I1)以及产品特征词的蕴含的信息量(I2), 其次分别是度量评论内容差异性的信息熵(I3)和困惑值(I4)。整条评论提供的信息量(I1)能帮助用户了解产品信息, 产品特征词给用户判别评论质量提供了更有价值的信息, 从而利于判别评论质量。评论内容的差异性对于评估评论质量起着非常关键的作用, 这也间接验证了文献[16]的结论, 即越相似的评论, 越有可能是垃圾评论的论断。
(2) 基于有效特征集的模型比较
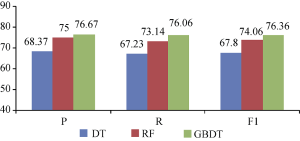
为考察GBDT模型的分类表现, 基于有效特征集, 与Ghose等[8]采用的随机森林模型(Random Forest, RF)进行比较。此外, 与基本决策树模型(Decision Tree, DT)进行比较, 考察梯度提升优化效果, 实验比较结果如图2所示。可以看出, GBDT模型方法与RF模型、DT模型相比, 准确性和召回率都有显著提高。整体来看, 相比DT模型, F1可以提高约9个百分点, 说明GBDT优化效果较好; 同时, 相比RF模型, F1也提高了约2.3个百分点, 说明模型性能表现良好。
本文主要介绍了文本信息特征和语义情感特征在评论质量检测中的应用效果, 研究结果表明, 经过贪婪式特征选择算法按一定顺序选择特征项后, GBDT能在经过选择特征集上取得最佳分类性能, 其分类效果优于决策树模型和随机森林模型, 验证了特征提取和特征选择的有效性, 从而更有效地帮助商家自动识别高质量评论。
未来将继续搜索其他有效的内容特征, 进一步提高和完善文本特征在评论质量监测中的应用。
孟园: 采集、清洗和分析数据, 论文起草及最终版本修订;
王洪伟: 论题拟定, 提出研究思路, 设计研究方案, 修改完善论文。
所有作者声明不存在利益冲突关系。
支撑数据见期刊网络版http://www.infotech.ac.cn。
[1] 孟园, 王洪伟. quality_classify.py. 评论质量贪婪式特征选择和模型比较算法.
[2] 孟园, 王洪伟. exp_data_initial.xlsx. 亚马逊原始抓取数据.
[3] 孟园, 王洪伟. classifier.pkl. 文本情感极性分类器.
[4] 孟园, 王洪伟. segged_pos_words.txt. 评论分词数据.
[5] 孟园, 王洪伟. sub_sentence.txt. 评论分句数据.
[6] 孟园, 王洪伟. Refine_Igain_word.txt. 改进评论词语信息增益数据.
[7] 孟园, 王洪伟. all_feature_value.txt. 评论特征提取数据.

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}