周鹏程 , 武川
, 武川
Zhou Pengcheng, Wu Chuan
中图分类号: G353.1
通讯作者:
收稿日期: 2016-01-13
修回日期: 2016-03-20
网络出版日期: 2016-06-25
版权声明: 2016 《现代图书情报技术》编辑部 《现代图书情报技术》编辑部
基金资助:
展开
摘要
【目的】基于多知识库进行实体链接, 解决基于单一知识库的实体链接覆盖度低的问题。【方法】首先生成文本的n-gram并利用词性和多个指称-实体字典获取候选指称, 然后生成指称组合并保留覆盖度最大且不被其他组合包含的指称组合, 接着生成候选实体序列并利用多知识库信息计算实体序列的相关度, 最后选择相关度最大的实体序列为最终结果。【结果】以Wikipedia和Freebase为例的实验结果表明, 基于Wikipedia+Freebase的实体链接准确率、召回率、F值分别达到71.81%、76.86%、74.25%。【局限】基于词性过滤n-gram缺乏理论依据, 数据集FACC1具有高准确率和低召回率的特点。【结论】利用多个知识库的实体信息, 能够提升实体链接效果。
关键词:
Abstract
[Objective] This paper proposes an entity linking method using multi-knowledge bases, aiming at solving the problem of low coverage caused by entity linking with single knowledge base. [Methods] First, we generated n-gram of input text and obtained candidate mentions using part of speech and multi-mention-entity dictionary. Second, we generated and retained mention combinations of highest coverage which are not contained by other mention combinations. Third, we generated entity sequences and calculated their relevence degree using information from multi-knowledge bases. We listed entity sequence with the highest relevence degree as the final result. [Results] This case study showed that the Precision, Recall, and F-value of the entity linking based on Wikipedia+Freebase reaches 71.81%, 76.86%, and 74.25% respectively. [Limitations] Filtering n-gram based on part of speech lacked theoretical foundation, and the FACC1 dataset featured high precision but low recall. [Conclusions] Utilizing entity information from multi-knowledge bases can improve the performance of entity linking.
Keywords:
实体(Entity)是现实世界中客观存在的并可以相互区别的事物, 既包括人名、地名、机构名等具体事物, 又包括概念、关系等抽象事物。实体链接(Entity Linking)是指文档中代表实体的文本片段, 即实体指称(Entity Mention, 简称指称), 与特定知识库(Knowledge Base)中的条目(Entry)相链接的过程, 有时称命名实体链接(Named Entity Linking)[1]。
实体广泛存在于各类文本中, 而面对未知实体时, 需要通过实体链接技术, 利用知识库中相关条目信息为原文本添加丰富的语义信息, 帮助读者加深关于该实体的了解, 从而有助于人或者计算机更好地理解、处理文本。
实体链接研究因其重要的研究意义而备受关注, 多项国际评测会议发布了实体链接相关的任务, 如2007年INEX会议发布的“Link the Wiki”任务(http:// www.inex.otago.ac.nz/tracks/wiki-link/wiki-link.asp)、2009年TAC会议发布的“Knowledge Base Population”任务(http://www.nist.gov/tac/)、2012年TREC会议发布的“Knowledge Base Acceleration”任务(http://trec.nist.gov/)。实体链接在信息检索[2]、知识库构建[3]、问答系统[4]等领域都有较好的应用前景。
实体链接的难点在于两方面, 即多词一义和一词多义。多词一义是指实体可能有多个指称, 实体的标准名、别名、名称缩写等都可以用来指代该实体, 例如Michael Jordan、MJ和Jordan都可以指代实体Michael Jeffrey Jordan。一词多义是指一个指称可以指代多个实体, 例如MJ可能指代实体Michael Jeffrey Jordan, 也可以指代实体Michael I. Jackson。解决一词多义问题要利用知识库中的实体信息进行实体消歧, 单一知识库中的实体信息相对较少, 笔者认为如果能利用多个知识库中的实体信息进行实体消歧, 一词多义问题将会得到更好的解决。
知识库是实体链接研究的基础, 常见的知识库包括Wikipedia①(①https://www.wikipedia.org/.)、Freebase[5]、YAGO[6]、DBpedia[7]等, 其中Wikipedia是实体链接研究中最常见的知识库, 它包含丰富的文本语义信息, 其中的每个实体页面都是某个实体的描述。Freebase也比较常见, 与Wikipedia相比, Freebase中的实体信息更加结构化。谷歌于2013年发布了Freebase实体标注数据集FACC1[8], 并且该数据集已经在信息检索领域[9]得到了应用。FACC1是对ClueWeb09②(②http://www.lemurproject.org/clueweb09.php/.)和ClueWeb12③(③http://www.lemurproject.org/clueweb12.php/.)的实体标注, 利用该数据集可以统计实体的流行度等信息。
本文提出了一种基于多知识库的实体链接方法, 该方法利用多个指称-实体字典进行指称识别, 利用多个知识库的实体信息进行实体消歧, 以期解决基于单一知识库的实体链接覆盖度低的问题。
实体链接包括两个步骤, 即指称识别和实体消歧[10]。虽然有的研究[11]划分方式略有不同, 但本质上是一样的。传统的实体链接大多关注长文档, 近年来有研究者[9,12-14]开始关注短文本实体链接, 如微博、查询词等, 并已经在信息检索领域得到了应用[9]。二者的主要区别是短文本上下文信息少, 实体消歧相对困难。另外短文本存在书写不规范问题, 如丢失大小写信息和标点信息[9]、拼写错误[14], 这也给指称识别带来一定困难。因此笔者认为短文本实体链接研究更具挑战性, 应给予更多的关注。
实体链接的第一步是进行指称识别, 首先要构建一个指称-实体字典, 大多数研究者抽取Wikipedia的实体页面、消歧页面、重定向页面的标题作为实体指称, 建立指称-实体字典, 还有其他的建立方式, 如Sil等[15]抽取了Freebase中实体的标准名和别名。然后按一定的规则识别实体指称, 如Cucerzan[11]利用大小写规则、先验统计信息进行指称识别, 并选择实体上下文与实体Wikipedia主页、候选实体之间的一致性最高的实体序列。Mihalcea等[16]利用链接概率识别指称, 然后综合利用知识工程方法和朴素贝叶斯分类方法确定最终的实体序列。
由于一个指称可能指向多个实体, 因此需要用一定的方法确定指称所指向的实体, 即实体消歧。目前实体消歧方法主要包括机器学习[17-18]、排序学习[19-21]、图模型[22-25]、无监督方法[11,26]和集成方法[27-28]等。Zhang等[17]采用文献[11]的方法构建指称字典进行指称识别, 如果候选指称集为空, 则利用Wikipedia的“Did You Mean”和“Wikipedia Search Engine”特征补充候选指称集, 并将实体消歧看作二类分类问题, 即指称及其所指向的实体构成的指称-实体对为正例, 与其他候选实体构成的指称-实体对为负例, 选取词法特征、词-类别特征、实体类型等特征, 采用SVM分类器分类, 如果多个候选实体标记为正例, 那么利用词袋、实体共现等特征计算指称-实体相似度, 选择相似度最高的候选实体。Ratinov等[20]假设指称已经给定, 并提出两类特征: 局部特征(即指称上下文与实体主页文本、指称所在文档与实体主页文本、指称上下文与实体上下文、指称所在文档与实体上下文等的余弦相似度)和全局特征(包括标准化谷歌距离、点互信息测度的实体类别相似度、入链相似度、出链相似度), 训练得到Rank SVM模型, 选取排序最高的实体为该指称在上下文中所指的实体。Han等[22]同样只关注实体消歧问题, 以指称及其候选实体为节点, 构建指称-实体、实体-实体关系图, 利用类似PageRank的机制识别实体。
Ferragina等[13]最早开始关注短文本实体链接, 采用文献[11]的方法构建指称字典, 并用人工规则过滤指称字典, 利用该字典识别候选指称, 然后利用指称指向实体的先验概率和候选实体与其他候选实体的相关性等特征, 采用机器学习和人工规则两种方法进行实体消歧。Meij等[14]则尽可能多地获得候选指称, 提出n-gram特征、概念特征、n-gram-概念特征、Tweet特征等4类特征, 同样采用机器学习的方法识别概念并链向相应的Wikipedia页面。Liu等[29]在Meij等的基础上又融合指称-指称特征, 选择相似度得分最高的实体序列。
笔者发现目前实体链接研究都是基于单一知识库, 但是由于某些实体只存在于特定的知识库库中, 单一知识库可能无法完全覆盖文档中的实体。另外单一知识库可利用的实体信息相对较少, 这将影响实体消歧的效果。针对以上问题, 本文提出了一种基于多知识库的实体链接方法, 该方法能够有效地利用多个知识库的实体信息, 并同时对多个知识库进行实体链接。
实体链接是指给定一段文本, 识别其中包含的指称, 利用实体消歧方法确定指称指代的实体, 并链向特定知识库中的相应条目。
实体链接问题的形式化定义如下: 输入是由n个单词组成的文本t=(w1,w2…wn), 输出是指称组合 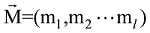
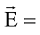
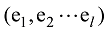
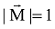
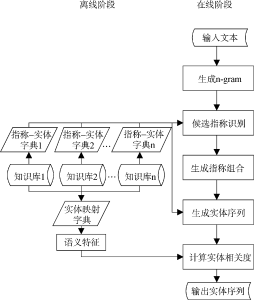
图1为基于多知识库的实体链接步骤, 分为离线阶段和在线阶段, 离线阶段构建指称-实体字典和实体映射字典; 在线阶段为实体链接方法的主要步骤, 包括生成n-gram、候选指称识别、生成指称组合、生成实体序列、计算实体相关度等。
(1) 字典构建
为了进行指称识别, 笔者从知识库中收集实体的标准名、别名等信息作为实体指称, 进行相应的预处理, 构建指称-实体字典。指称-实体字典包含两个域, 即指称域和实体域, 存储格式为“m e1e2…en”, 其中m表示实体指称, e1e2…en 表示指称m可能指向的实体。
为了能同时利用多知识库信息进行实体链接, 本文按照一定方法构建实体映射字典。实体映射字典包含n个域, 存储格式为“e1e2…en ”, 其中ei表示知识库i的实体, 且e1e2…en 为不同知识库中的同一实体。
(2) 方法步骤
①生成n-gram
生成输入短文本的n-gram,例如对于短文本“obama family tree”, 共生成6个n-gram, 即{obama, family, tree, obama family, family tree, obama family tree }。
②候选指称识别
对于生成的每个n-gram, 直接搜索多个指称-实体字典的指称域, 如果任一指称-实体字典中存在相应的记录, 则该n-gram可能是实体指称。如果n-gram所包含单词的词性都不是名词, 那么将被过滤掉, 因为根据笔者的观察, 实体一般作为名词出现。例如对于obama, 指称-实体字典的指称域中存在相应的记录并且其词性为名词, 因此obama是实体指称, 同样, family、tree、obama family、family tree也是实体指称。但是对于obama family tree, 指称-实体字典的指称域中不存在相应的记录, 因此被过滤掉。从而“obama family tree”共保留5个可能的实体指称, 即{obama, family, tree, obama family, family tree}。
③生成指称组合
候选指称识别阶段产生的实体指称可能存在重叠问题, 有研究者[30]采用从左至右最长匹配的策略解决指称重叠问题, 但是笔者认为这可能造成指称识别错误。本研究经过以下三个步骤生成候选指称组合:
1) 选择至少一个相互不重叠候选指称组成指称组合;
2) 保留覆盖度最大的指称组合;
3) 保留至少有一个指称不被其他组合包含的指称组合。这里的包含是指要么一个指称是另一个指称的一部分, 要么两个指称相同。
例如“obama family tree”共保留两个指称组合, 即{obama+family tree, obama family+tree}。
④生成实体序列及实体相关度计算
如果生成指称组合阶段共保留n个指称组合, 且第i个指称组合包含ni个指称, 对于每一个指称, 笔者合并各知识库中的候选实体记录, 并取先验概率最大的k个实体为候选实体, 则共生成 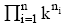
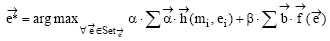
其中, 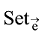
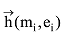
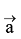
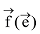
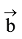
由于在实体链接研究中Wikipedia、Freebase使用比较广泛, 具有较强的代表性, 因此笔者分别基于Wikipedia、Freebase、Wikipedia+Freebase进行实体链接。
(1) 指称-实体字典构建
本文采用Bunescu等[31]的方法, 抽取Wikipedia的实体页面、消歧页面、重定向页面的页面标题以及实体主页的锚文本, 进行小写化等预处理, 构建指称-实体字典。同时, 利用锚文本统计指称指向其候选实体的次数, 并将其存入指称-实体字典中。
由于本文的输入不包含特殊符号并且都是小写化的, 为了与输入进行匹配, 笔者移除了实体指称中的特殊符号, 并进行小写化处理, 同时移除指称中的消歧信息, 例如对于指称The Last Supper (Leonardo da Vinci), 括号及其内部的信息被移除, 这是因为文档提及实体时, 通常不会附带实体的消歧信息。如果经过上述的处理后, 两个指称变成了相同指称, 那么合并指称记录, 例如:
bilos Daniel_Ruben_Bilos_(2) Daniel_Rubén_Bilos_(1) Daniel_Bilos_(3)
其中bilos是指实体指称, 存储于指称域; Daniel_ Ruben_Bilos、Daniel_Rubén_Bilos、Daniel_Bilos是bilos可能指向的实体(这里用实体的Wikipedia主页标题表示), 且在Wikipedia的主页文本中bilos指向三个实体的次数分别是2次、1次、3次, 实体及次数信息存储于实体域, 利用次数信息可计算候选实体的先验概率, 例如bilos指向Daniel_Bilos的先验概率为:
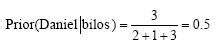
(2) Wikipedia实体特征
①指称-实体特征
1) 先验概率
候选实体的先验概率是重要的消歧信息, 很多研究[23,29,31]都有使用, 笔者利用公式(2)计算候选实体的先验概率。注意, 本文取各候选实体先验概率的算术平均数为实体序列的先验概率, 字符串相似度的计算类似。
2) 字符串相似度
如果指称与其候选实体的标准名的相似度越高, 那么指称指向该候选实体的概率越大。编辑距离(Edit Distance)是一种度量字符串相似度的方法, 它是指一个字符串转变成另一个字符串所需要的最小编辑操作次数。对于两个给定的字符串, 编辑距离越小表示两个字符串相似度越高。本文用公式(3)计算指称与其候选实体标准名的相似度。
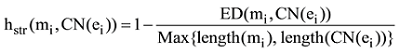
其中CN(ei)表示实体ei的标准名, 即Wikipedia实体主页标题; hstr(mi,CN(ei)) 表示指称与其候选实体标准名的字符串相似度, 该值越高表示二者相似度越大; ED(mi,CN(ei))表示指称与其候选实体标准名的编辑距离, Max{length(mi),(CN(ei))} 表示指称与其候选实体标准名字符串长度较大者。
②实体-实体特征
1) 文本相关度
如果两个实体相关, 那么它们的实体描述文本可能会讨论相同的内容, 因此文本相关度可以用来表征实体相关度。笔者对Wikipedia实体主页文本做了小写化、移除特殊字符、去除停用词等处理, 用公式(4)计算两个实体之间的文本相关度。
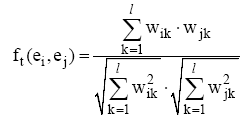
其中ft(ei,ej)表示实体ei与ej的文本相关度, l表示两段文本单词总数, wik表示第k个单词在第i篇文档中的权重, 本文将单词的频率作为其权重。注意, 这里对实体文本相关度的定义只考虑两个实体的情况, 如果实体序列包含的实体数大于2, 那么取两两实体的文本相关度的算术平均数为实体序列的文本相关度, 其他相关度计算与之类似。
2) 相关实体相关度
如果两个实体相关, 那么它们可能会存在相同的相关实体, 因此相关实体相关度可以用来表征实体相关度。Wikipedia的实体主页中存在指向其他实体页面的链接, 可以利用这些链接搜集候选实体的相关实体集。
Wikipedia实体ei存在三种类型的相关实体:
λ 入链相关实体, 即实体ei在实体ej的主页中出现, 而实体ej在实体ei的主页中未出现, 则实体ej是实体ei的入链相关实体。
λ 出链相关实体, 即实体ej在实体ei的主页中出现, 而实体ei在实体ej的主页中未出现, 则实体ej是实体ei的出链相关实体。
λ 互指相关实体, 即实体ej在实体ei的主页中出现, 且实体ei在实体ej的主页中也出现, 则实体ej是实体ei的互指相关实体。
本文利用Jaccard系数表示两个实体的相关实体相关度, 公式如下:
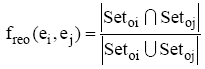
其中freo(ei,ej)表示实体ei和实体ej的出链相关实体相关度, Setoi和Setoj分别表示实体ei和实体ej的出链相关实体集合。公式(5)以出链相关实体为列, 入链相关实体相关度、互指相关实体相关度的计算公式与之类似, 实体ei和实体ej的相关实体相关度由三种类型相关实体相关度加权平均得到。
3) 类别相关度
如果两个实体相关, 那么它们可能属于同一类别, 因此类别相关度可以用来表征实体相关度。Wikipedia的编辑者为每个实体标注了若干类别, 类别信息可以从实体主页中获取。
仍利用Jaccard系数表示两个实体的类别相关度, 公式如下。
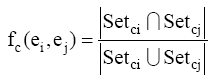
其中fc(ei,ej) 表示实体ei和实体ej的类别相关度, Setci和Setcj分别表示实体ei实体ej的类别集合。
(1) 指称-实体字典构建
本文抽取Freebase实体的标准名和别名构建指称-实体字典。Freebase的实体信息结构化程度高, 有专门存储实体属性的字段, 可以直接从名称字段和别名字段抽取实体标准名和别名。同样, 笔者对Freebase实体指称做了小写化和去除特殊符号的处理, 并利用ClueWeb09的Freebase实体标注数据集FACC1[8]计算指称指向其候选实体的次数, 例如:
balwin_vi /m/0129jf_(3) /m/01_dt9_(6)
其中baldwin_vi是指实体指称, 存储于指称域; /m/0129jf、/m/01_dt9是指baldwin_vi可能指向的实体(这里用Freebase唯一标识符表示), 且在ClueWeb09中baldwin_vi指向两个实体的次数分别是3次、6次, 实体及次数信息存储于实体域, 实体先验概率可用公式(2)计算。
(2) Freebase实体特征
①指称-实体特征
这里仍采用先验概率和字符串相似度两个特征, 定义及含义均同Wikipedia实体。注意, Freebase实体标准名是从名称字段中抽取。
②实体-实体特征
1) 文本相关度
Freebase实体文本相关度的文本取自实体描述(Description)字段, 其含义、预处理、计算公式均同Wikipedia实体。
2)类型相关度
类似于Wikipedia实体的类别, 如果两个实体相关, 那么它们可能属于同一类型, 因此类型相关度可以用来表征实体之间的相关度。Freebase的编辑者为每个实体标注了若干类型, 类型信息存储在类型字段中。例如实体Barack Obama (Freebase唯一标识符是/m/02mjmr)被标注了/people/ person、/government/politician、/award/award_winner等97种类型。可以看出, Freebase实体可能有多种类型, 并且每种类型是分层次的。笔者对实体的各层次类型名做了简单的词频统计, 词频作为权重, 仍用公式(4)计算两个实体的类型相关度。
基于Wikipedia+Freebase的实体链接同时利用4.1节和4.2节中的指称-实体字典进行候选指称识别。由于Wikipedia与Freebase包含了实体不同方面的信息, 因此本文从两个知识库中抽取了不同的实体特征, 且二者可形成互补关系。为了能够同时利用Wikipedia和Freebase实体特征, 本文构建了Wikipedia实体与Freebase实体映射字典。
(1) Wikipedia实体与Freebase实体映射字典
Freebase的实体页面中存在等价页面(Equivalent Webpage)域, 其中包含了与之等价的其他知识库链接。笔者抽取与之等价的Wikipedia实体页面的标题, 从而建立了Wikipedia实体与Freebase实体一一对应的关系, 例如:
/m/03kkbz 873558 Ivan_Bella
其中/m/03kkbz是Freebase实体唯一标识符, 可通过该标识符获取Freebase实体的语义信息, 如别名、类型、描述等; Ivan_Bella是与/m/03kkbz等价的Wikipedia实体页面标题, 利用该标题可获取Wikipedia实体的语义信息, 如类别、出/入链、主页文本等; 873558是Wikipedia实体的编号。
(2) Wikipedia+Freebase实体特征
对于指称-实体特征, 仍采用先验概率和字符串相似度, 这里对Wikipedia和Freebase相应的特征做算术平均; 对于实体-实体特征, 利用Wikipedia实体与Freebase实体映射字典, 基于Wikipedia+Freebase的实体链接融合Wikipedia的文本、相关实体、类别等相关度和Freebase的类型相关度进行实体消歧, 具体定义见4.1节和4.2节。
实验的输入是2009年-2012年国际文本检索会议(TREC)的Web Track任务中的200个查询主题(Topic), 对其中包含的实体进行人工标注。由于部分查询主题本身即为实体指称, 无法根据上下文进行实体消歧, 因此将其移除, 最终共处理179个查询主题, 标注242个实体。
笔者下载2013年12月2日Wikipedia的转储文件①(①https://dumps.wikimedia.org/.), 包含实体页面、消歧页面、重定向页面等共4 450 000余篇, 以及页面链接关系、实体类别信息等。利用Java②(②http://www.oracle.com/technetwork/java/index.html.)语言处理原始文件、抽取实体指称、计算指称指向其候选实体的先验概率, 用Lucene③(③http://lucene.apache.org/.)建立索引, 以方便指称搜索, 从Wikipedia中共抽取14 870 000多条指称。同时下载2014年7月6日Freebase的RDF文件④(④https://developers.google.com/freebase/data.), 包含实体的别名、等价页面、描述等属性, 共包含42 660 000多个实体。利用同样的工具完成指称抽取、索引建立等工作, 从Freebase中共抽取22 130 000多条指称。
由于Freebase中存在其与Wikipedia的映射关系, 笔者抽取该映射关系, 并利用Lucence构建相应的索引。
采用准确率、召回率和F值评价实验效果, 三个指标的定义如下:
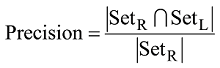
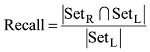

其中SetR表示利用本文的方法识别的实体集合, SetL表示标注实体集合, |SetL|表示集合中元素的个数, 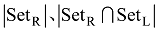
从表1可以看出, 基于Wikipedia的实体链接, 准确率达到62.68%, 召回率达到71.49%, F值达到66.80%; 基于Freebase的实体链接, 准确率、召回率、F值分别达到69.32%、75.62%、72.33%; 基于Wikipedia+Freebase的实体链接, 准确率、召回率、F值分别达到71.81%、76.86%、74.25%。
表1 基于不同知识库以及同时基于两个知识库的实体链接评测结果
| 知识库 | 准确率 | 召回率 | F值 |
|---|---|---|---|
| Wikipedia | 62.68% | 71.49% | 66.80% |
| Freebase | 69.32% | 75.62% | 72.33% |
| Wikipedia+Freebase | 71.81% (+14.57%) (+3.59%) | 76.86% (+7.51%) (+1.64%) | 74.25% (+11.15%) (+2.65%) |
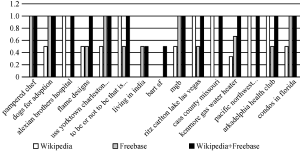
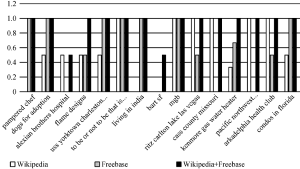
实验结果显示, 基于Wikipedia+Freebase的实体链接效果均高于基于Wikipedia或Freebase的效果, 其中准确率分别提升14.57%和3.59%, 召回率分别提升7.51%和1.64%, F值分别提升11.15%和2.65%, 实验结果证明了基于多知识的实体链接方法的有效性。 图2和图3显示了15个查询主题在三组实验中的召回率和准确率, 可以看出, 在基于Wikipedia的实体链接实验中, 部分查询主题效果较好, 例如pacific northwest laboratory、arkadelphia health club; 在基于Freebase的实体链接实验中, 部分查询主题效果较好, 例如condos in florida、uss yorktown charleston sc; 在基于Wikipedia+Freebase的实体链接实验中, 15个查询主题的效果都较好。
为了分析效果提升的原因, 笔者补充了4组实验, 结果如表2所示:
表2 基于不同知识库以及补充实验评测结果
| 知识库 | 准确率 | 召回率 | F值 |
|---|---|---|---|
| Wikipedia | 62.68% | 71.49% | 66.80% |
| Wikipedia-MF | 63.26% (+0.93%) | 69.01% (-3.5%) | 66.01% (-1.2%) |
| Wikipedia-MD | 71.43% (+13.96%) | 76.45% (+6.94%) | 73.85% (+10.55%) |
| Freebase | 69.32% | 75.62% | 72.33% |
| Freebase-MF | 69.47% (+0.22%) | 75.21% (-0.54%) | 72.22% (-0.15%) |
| Freebase-MD | 69.26% (-0.09%) | 77.27% (+2.2%) | 73.05% (+1%) |
从表2可以看出, 利用多个指称-实体字典进行指称识别是实体链接效果提升的主要原因, 其中召回率分别提升6.94%和2.2%, F值分别提升10.55%和1%; 多特征仅对实体链接的准确率有较小提升(分别提升0.93%和0.22%), 对实体链接效果总体没有提升作用。
笔者分析了在基于Wikipedia+Freebase的实体链接实验中识别错误的查询主题, 发现以下问题:
(1) 识别候选指称时可能过滤掉正确的指称。例如对于查询主题old coins, 其正确的指称是coins, 但是由于“old coins”覆盖度更大, 并且符合最长匹配的原则, 因此被保留。笔者发现“old coins”在Wikipedia中仅有一次作为指称出现, 但是由于缺少相应的策略, 造成指称识别错误。同因, espn sports、diabetes education也发生了指称识别错误。
(2) 获取候选实体时指称所指向的实体可能没被获取。例如对于查询主题website design hosting, 在获取指称hosting的候选实体时, 根据最大先验概率选取Wikipedia中该指称可能指向的前k个实体, 然而这k个实体不包含指称hosting所指向的实体, 因此造成候选实体选取错误, 并且笔者发现Freebase中指称hosting可能指向的前k个实体包含该指称所指向的实体。同因, lymphoma in dogs、fact on uranus也发生候选实体选取错误。
(3) 未能正确地对实体进行消歧。例如对于查询主题obama family tree, 基于Wikipedia+Freebase的实体链接未能正确地对其进行消歧, 造成实体识别错误。笔者认为向消歧框架中加入更多特征或许能解决这类问题。
本文提出一种基于多知识库的实体链接方法, 以Wikipedia和Freebase为例的实验结果表明, 基于Wikipedia+Freebase的实体链接效果高于基于Wikipedia或Freebase的实体链接效果。本文存在两点不足, 即基于词性过滤n-gram缺乏理论依据、数据集FACC1具有高准确率和低召回率的特点[8]。另外, 本文的方法也可适用于其他知识库, 例如对于YAGO, 利用“HasWikipediaURL”关系可以构建YAGO实体与Wikipedia实体的映射字典, 再结合笔者构建的Wikipedia实体与Freebase实体映射字典可构建三个知识库实体的映射字典; 利用“means”关系收集YAGO实体的指称[6]并利用Wikipedia实体主页的锚文本统计指称指向其候选实体的次数[23], 从而构建相同结构的指称-实体字典; 利用文本相关度、类型相关度(根据type关系和subClass关系计算的实体类型距离[23])等进行实体消歧。基于本文的结论, 笔者认为基于Wikipedia+Freebase+YAGO的实体链接效果将会高于基于Wikipedia或Freebase或 YAGO的实体链接效果。未来笔者将会探索更好的信息融合方式, 以期进一步提升基于多知识库的实体链接效果。
周鹏程: 方案设计, 实验实施, 论文起草以及修订;
武川: 方案设计和修订, 论文多次修订;
陆伟: 指导方案设计和论文写作, 论文多版本及最终版修订。
所有作者声明不存在利益冲突关系。
支撑数据见期刊网络版http://www.infotech.ac.cn。
[1] 周鹏程, 武川, 陆伟. 标注数据.xml. 主题的实体标注数据.
[2] 周鹏程, 武川, 陆伟. freebase识别结果.txt. 基于Freebase的实体识别结果.
[3] 周鹏程, 武川, 陆伟. wikipedia识别结果.txt. 基于Wikipedia的实体识别结果.
[4] 周鹏程, 武川, 陆伟. wikipedia_freebase识别结果.txt. 基于Wikipedia+Freebase的实体识别结果.
[5] 周鹏程, 武川, 陆伟. freebase指称-实体字典.txt. 基于Freebase构建的指称-实体字典.
[6] 周鹏程, 武川, 陆伟. wikipedia指称-实体字典.txt. 基于Wikipedia构建的指称-实体字典.
[7] 周鹏程, 武川, 陆伟. freebase实体-wikipedia实体映射字典.txt. Freebase实体与Wikipedia实体映射字典.

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}