钮亮
中国计量大学经济与管理学院 杭州 310018
Niu Liang
中图分类号: G250
通讯作者:
收稿日期: 2016-03-9
修回日期: 2016-05-9
网络出版日期: 2016-08-25
版权声明: 2016 《现代图书情报技术》编辑部 《现代图书情报技术》编辑部
基金资助:
展开
摘要
【目的】通过构建共主题网络, 对主题之间的关系进行分析, 优化主题包含的词项。【方法】将“文档-主题”二分图依照加权投影规则生成共主题网络, 使用介数中心性和主题概率结合的方法测度共主题网络中重点主题, 通过GN算法对主题网络进行社区分割, 使用相关度方法优化主题词项。【结果】将共主题网络与基于JSD的K-means方法进行比较发现, 两者在三种主题数(最优主题数28和随机主观主题数20, 30)测试下产生的聚类数目都相同, 聚类内容的一致程度分别达到100%、95%、87%。【局限】其他社区分割方法共主题网络未能全面涉及。【结论】共主题网络照顾到了高维数据的需要, 能够探查出文档中哪些主题是重要主题, 哪些主题联系紧密。
关键词:
Abstract
[Objective] This paper builds a co-topics network to analyze the relationship among the topics of research articles and then optimize terms representing these topics. [Methods] First, we transformed the “document-topics” bipartite Graph to co-topics networks in accordance with weighted projection rules. Second, we identified the key topics with the combination of betweenness centrality and topic probability. Third, we divided the co-topics network community with the GN algorithm. Finally we optimized topic terms with relevance method. [Results] We compared the co-topics networks and the K-means based on JSD by testing optimal topic number (28) and random subjective topic numbers(20, 30). Their clustering numbers were the same and the consistent degree of clustering content reached 100%, 95% and 87%. [Limitations] We did not include other community partition methods with the proposed co-topics networks. [Conclusions] The co-topics network meets the demands of high-dimensional data and identifies the key topics and the closely linked topics of the target documents.
Keywords:
科技文献资源的利用一直以来都受到学术界的重视, 以往的研究一般是利用共词分析方法对科技文献进行计量分析, 集中在分析对象的改进、指标改进、可视化方法调整等方面[1]。但共词分析方法由于难以发现文档中潜在的语义联系, 无法满足用户对科技信息深层次的需求。在自然语言处理领域提出了LDA主题模型[2], 由于其围绕语义问题进行词项分配, 很快被引入到科技文献的计量分析之中[3-4]。并在其基础上形成一些比较经典的扩展, 如AT模型[5]、TOT模型[6]、CTM模型[7]等。
尽管LDA在科技文献挖掘方面取得了一定的成绩, 但是传统LDA模型仍然存在两个明显的问题:
(1) LDA模型训练语料后形成的主题之间缺乏联系。传统LDA模型在解释文档时常常选择一个概率分布最高的主题来说明文档, 然而一个文档有时候不仅仅只体现一个主题内容, 它可能由若干个主题构成, 因此传统LDA模型对于这些共同出现在文档中的主题的关系如何, 在表达文档意义时哪些主题是更重要的, 并未给以解释。为了表达主题之间的关系, 也有一些文献引入了主成分分析方法和聚类方法, 将多个维度的主题压缩成两维来计算, 并通过多维标度来展示[8-9]。其中聚类的距离测度采用KL距离(Kullback-Leibler Divergence)[5,10]、JSD(Jensen-Shannon Divergence)[11-13]、余弦相似度[14]方法来实现。这些文献存在的问题是主成分分析方法将高维数据压缩成两维数据来处理, 忽略了高维数据的复杂性。聚类中距离测度到底要选择哪种方法存在困扰。复杂网络很好地照顾到了高维数据的需要, 也能够利用社区分割方法完成数据的聚类问题。因此在探测主题关系时, 根据主题在文档中的共现情况, 构建文档-主题二分图网络, 并通过投影形成主题网络, 实现对主题关系的探测。主题模型和复杂网络结合的文献较少, 文献[10]和文献[15]把合作网络中的每个用户看作文档, 每个用户的所有合作者看作该文档的词项, 使用主题模型的方法处理合作网络用户的聚类问题, 这些网络数据属于LDA模型的语料准备。文献[16]将复杂网络社区分割的模块度作为隐形变量以增强LDA模型的性能, 与AT模型、TOT模型的性质类似, 对生成的主题关系并未进一步讨论。
(2) 传统LDA模型的主题词项构成中经常会存在一些不重要的, 甚至是不太有关联的词项。模型输出结果需要领域专家来确定和修改哪些词项是有意义的[17-18], 无法自动完成词项的选择[19-20], 后来有一些模型通过引入一些外在的隐性变量来增强构成主题的词项的精度, 例如AT模型引入作者这个隐形变量以增强LDA模型的精度。TOT模型引入时间因素, 将时间看作连续的可观测变量来增强词项精度。但由于这些扩展模型与LDA的生成机制是一样的, 产生的主题词项中依旧无法避免存在不太关联的词项。
针对传统LDA存在的问题, 本文将完成两项内容:
(1) 通过文档-主题二分图投影构建共主题网络, 通过社区分割和中心性测度探测主题关系和重要主题;
(2) 优化主题词项选择, 并遴选出与主题相关的词项。
LDA 主题模型是一种非监督的机器学习方法, 采用词袋(Bag of Words)表示的方法, 这种方法将每一篇文档视为一个词频向量, 从而将文本信息转化为易于建模的数字信息。LDA的建模方式认为每一篇文档代表了一些主题所构成的一个概率分布, 而每一个主题又代表了很多词项所构成的一个概率分布。如果有T个主题, 则给定文档中wi词项的概率如下:
其中, zi是潜在变量, 表明第i个词汇wi是从该主题得出的。P(wi|zi=j)是词汇wi属于主题j的概率, P(zi=j)给出主题j 属于当前文本的概率。直观上, P(w|z)揭示的是哪些词对一个主题是重要的, 而P(z)是在一个文档中的主题分布。主题的内容反映在P(w|z)中, 一篇文章的构成依赖于主题分布P(z)。例如一个期刊在“统计学习”和“机器学习”栏目中发布了若干论文, 那么就认为词项的概率分布是围绕“统计学习”和“机器学习”的, 它的主题内容反映在P(w|z)中。在“统计学习”主题中, “方差”、“偏差”、“回归”这些词项就有很高的概率, 而“统计学习”和“机器学习”主题就反映在P(z)中。事实上, 这种文章由若干主题构成, 若干主题又由词项构成的情况是一个标准的贝叶斯分类问题。给定D个文档, 这些文档包含T(通过反复试验等方法事先给定)个主题且这些主题又由词汇表中W个独立的词项构成。其中, P(w|z)表示每个主题与词汇表中的 W个词项的一个多项分布相对应, 将这个多项分布记为Φ, 即 
(1) 文档-主题二分图及其投影
大多数网络是由一种节点类型组成的单模式网络, 事实上还存在一种二分图网络, 这种网络的节点属于不同的节点集, 边是由这些不同类型的节点集合中的节点连接在一起的。针对文档-主题二分图网络, 其中一种节点类别是文档, 一种节点类别是主题。对文档-主题二分图网络进行形式化: 设G=<V, E> 且 
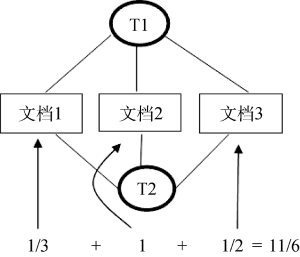
二分图网络如果不做转化很少能够被分析, 是由于大多数网络的测度手段为单模式图设计, 只有很少的一些设计是解决二分图的, 因此需要将二分图投影为单模式图。节点集X的投影规则为: 如果节点集X中的任意两个节点与节点集Y中的某个节点都相连, 那么就让节点集X的这两个节点连边。节点集Y的投影规则反之亦然。二分图及其投影如图1所示 , 其中二分图为(a), X节点投影为(b), Y节点投影为(c)。
单模式图投影方法非常实用并被广泛使用, 但是它的构造方式丢失了很多原始二分网络结构包含的信息。在映射中只是将同类的两个顶点做了连接, 却没有考虑这两个顶点到底属于多少个群组。通过给投影赋予权重, 可以在投影中保留这类信息。通常是将投影网络中的两个顶点间边的权重设置为它们共同属于的另一个群组的数目[21]; Newman在科学家-论文二分图转化为科学家单模式图中认为, 群组数目忽略了作者的贡献程度, 作者的权重应该随着一篇论文合著作者数量的不同而有所不同[22]; Zhou等认为Newman的方法[22]忽略了独著作者在投影中的重要性, 他从资源分配的影响出发设计二分图投影后的权重[23] 。
本文的投影规则是将主题作为一个节点, 两个主题如果出现在同一个文档之中, 则在这两个主题之间建立一个连边, 说明这两个主题存在相关关系, 如果一个文档有n个主题, 那么就产生n(n-1)/2种两两相关关系。当两个特定的主题T1和T2同时出现在多个文档中时, 对T1和T2不再重复连接, 但这样二分图中的文档节点就被忽略了。为了在投影中反映二分图的文档节点, 同时又反映主题之间联系的紧密程度, 设定主题T1和T2之间的权重如下:
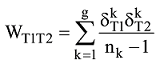
其中, g表示文档数目, 当主题T1在文档k中出现时, 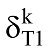
(2) 节点重要性计算
共主题网络节点重要性探测由两方面构成: 基于拓扑结构的共主题网络的节点中心性; 基于LDA模型训练的基于词项分布的主题概率大小。节点中心性的探测有度中心性、介数中心性、接近中心性、特征向量中心性、k-壳与k-核[24]。本文采用介数中心性和主题自身的词项概率分布来探测主题的重要程度。之所以将两种相结合是因为介数中心性解决的是任何一个节点达到其他节点的最短路径必然要经过的节点。介数中心节点起到建立其他节点彼此关系的作用, 显然地位是非常重要的。但是仅仅有介数中心性, 就无法体现其他节点自身的重要性, 因为网络中很多节点本身并不担当连接其他节点桥梁的作用, 因此节点自身的非拓扑性质的重要性需要体现。针对主题网络而言, 这个非拓扑属性就是构成主题内容的词项的概率分布。因此在计算共主题网络中主题节点的重要程度时, 本文将介数中心性和词项的概率分布结合在一起。节点Vi的介数中心性是网络中所有最短路径中经过该点的数量, 公式如下:
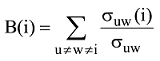
其中, σuw是节点Vu和Vw之间的最短路径数量, σuw(i)是经过节点Vi的Vu和Vw之间的最短路径数量。介数越高, 则节点越处于中心地位。当一个节点不在任何一条最短路径上时, 其中心性为0。
节点Vi的主题词项概率分布公式如下:
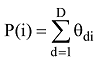
其中, θdi为文档d的话题主题节点Vi的多项式分布, D为文档集合。
最终共主题网络中的主题节点强度由介数中心性、主题节点概率分布共同构成。由于数据之间量纲的不相同, 采用Min-Max标准化将其转化为无量纲的纯数值, 公式如下:
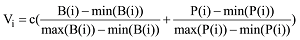
其中, c为调节系数, 调节主题节点的可视化显示大小。主题网络中主题节点的面积大小取决于Vi的值。从公式(5)可以看出Vi越大, 主题重要程度越高, 在主题网络中主题节点显示的面积也就越大。
(3) 共主题网络聚类
尽管共主题网络通过边权关系揭示了主题节点之间的关系, 突出了哪个主题是重要的, 但它们揭示的是两两主题之间的关系。而多个主题是否同属一种类别需要通过聚类进行揭示。针对共主题网络, 本文采取社区分割技术。对社区结构进行划分常用的方法有两类: 图论算法(包括谱平分法、随机游走算法、派系过滤法等)和层次聚类算法(凝聚算法和分裂算法)。前者的代表为基于贪婪算法思想的凝聚算法, 也称CNM算法[25]; 后者的代表为基于边介数的GN算法[26]。CNM算法适用于大规模网络的社区分割, GN算法只适用于中小型规模的网络。由于共主题网络节点边数少, 所以采用GN算法实现社区分割。GN算法是一种分裂型的社区结构发现算法。该算法根据网络中社区内部高内聚、社区之间低内聚的特点, 逐步去除社区之间的边, 取得相对内聚的社区结构。算法用边介数的概念探测边的位置, 计算所有边的介数中心度, 最高介数的边被移除, 反复迭代计算剩下的边介数直到边介数低于某个阈值μ, 算法停止。伪代码如下:
Input: A weighted or unweighted graph G = (V, E) , Threshold µ
Output: A list of clusters
while |E(G)| >0 do
Cu, v - betweenness centrality of edge (u, v)
Calculate Cu, v for all (u, v) ∈ E(G)
maxBetweennessEdge = (x, y) : Cx, y is minimum over all (x, y)
in E(G)
maxBetweennessValue = Cx, y
if maxBetweennessValue ≥ µ then
E(G) = E(G) - {maxBetweennessEdge}
else
Break out of loop
end
end
return Connected components of modified G
由于GN算法是反复迭代寻找边介数最大的值并移除, 因此无法判断算法终止位置, 而且还会重复计算节点的最短路径, 时间复杂度高。理论上无法自动确定最后会分割为多少个社区。社区的确定需要对阈值μ进行调试。因此需要有一种度量的方法, 判断不同阈值μ下面产生的结果是不是最佳的结果。为此Newman引入了模块度Q的概念来评价社区结构划分的质量[27-28]。但模块度只能用来衡量一个社区的划分是不是相对比较好, 之所以说相对是因为准确最优的模块度优化算法在计算上是困难的[29]。因此, 在计算模块度Q值时, Q取值最大的时候就认为是网络较理想的划分。Q值的范围在0-1之间, Q值越大说明网络划分的社区结构准确度越高。模块度Q的计算公式如下:
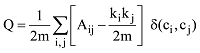
其中, Aij是 i行j列邻接矩阵A的元素。ki是连接到节点i的度, kj是连接到节点j的度。ci,cj表示节点i和j所在的两个社区。如果i和j在同一个社区, 则函数δ(ci,cj) =1, 否则δ(ci,cj)=0, 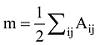
LDA主题模型主要是对两个参数进行推断: “文档-主题”分布θ和“主题-词项”分布Φ。共主题网络解决的是θ的关系问题, 由于共主题网络中的节点主题词项依赖于Φ, 因此Φ的优化直接决定了节点主题的被解释情况。传统主题模型训练后的主题里经常会存在一些不重要的, 甚至是不太相关的词项。因此模型输出结果需要领域专家来确定和修改那些词项是有意义的。当前主题质量评价完全依赖专家对给定主题中词项的甄别。为了提高自动选择主题词项的能力, 排除构成主题中的某些不相干的词项, 文献[30]使用一种称为提升度法(Lift)的内在度量方法来排序主题中的词项, 该提升度法被定义为某个主题中的词概率占据该词项在整个语料中边际概率的比率。文献[31]根据词项在主题中出现的频率和独占性进行排序。文献[9]结合提升度和独占性方法提出一种相关度方法(Relevance), 其中某个词语主题的相关性由λ参数来调节。如果λ接近1, 那么在该主题下频繁出现的词和主题更相关, 正是文献[30]所讨论的; 如果λ越接近0, 那么该主题下特殊、独有(Exclusive)的词和主题更相关, 正是文献[31]所讨论的。考虑到文献[9]在主题词项产生中的精度, 因此构建主题词项网络节点所需要的词项由主题词项相关性构建, 公式如下:
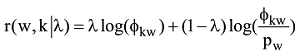
其中, λ决定了词项w在共主题网络节点k中关乎其提升度的权重。如果λ=0, 那么词项完全由其提升度决定, 即由词项在主题中的概率φkw占据词项在整个文档中的概率Pw的比率决定。如果λ=1, 则词项排序完全由主题中词项概率φkw决定, 文献[9]中建议取λ=0.6。
利用中国知网的“中国学术期刊网络出版总库”, 检索期刊名称为“大学图书馆学报”, 时间为1989年-2015年。为了计算的便利, 按照年度对下载的题录文件进行合并, 形成27个年度文档, 每个文档按照年进行编号。每个文档由若干记录构成, 该记录包含题目、作者、单位、关键词、摘要等。为了分析从1989年到2015年期刊关注的核心研究主题, 选取题录文献的标题、关键词、摘要进行研究。步骤如下:
(1) 对27个文件做循环读取;
(2) 通过Rjieba分词包对标题、关键词、摘要做分词处理, 利用正则表达式清理不相干字符(连接符、空值、数字等);
(3) 使用tm包构建文档-词频矩阵, 并通过TF-IDF优化特征词。后续研究是基于这个词频矩阵开展的。
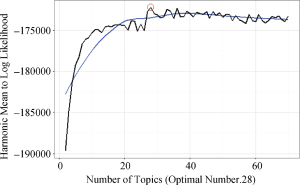
为了构建主题网络, LDA必须给出一个主题的最优数目。一般主题数目都是经验给定的, 经验给定的问题在于设定的主题数目少了则不能全面表示文档, 设定的主题数目多了则主题重复。因此在求证主题数目时大多使用自动发现主题数目的方法。目前有几种自动发现文档中最优主题的方法, 包括贝叶斯统计中的标准方法[3]、KL距离法[32]、余弦相似度法[33]、JSD法[34]。由于贝叶斯标准统计方法的简洁和计算的效率, 已经被大量的研究所使用, 因此本实验采用该方法。计算方法见公式(8)和公式(9), 结果如图3所示。
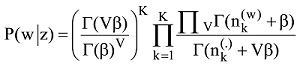
其中, 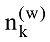
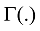
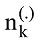
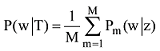
选取k=28为最大主题数量, 建立27行28列的“文档-主题”矩阵(D×T), 这个矩阵在LDA中被命名为 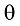
表1 选取的文档主题(部分)
| 文档(D) | 主题(T) |
|---|---|
| 1989 | T4 , T23 , T26, T27 |
| 2000 | T12 , T23 , T26, T27 |
| … | … |
| 2014 | T13, T14 |
| 2015 | T13, T28 |
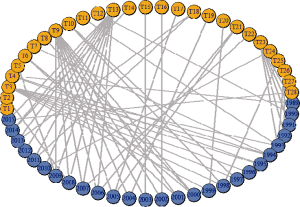
对表1中数据进行二分图构建, 得到文档-主题二分图, 如图4所示:
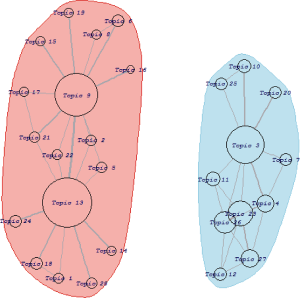
为更好地说明主题网络中节点的聚类情况, 利用GN算法对主题网络进行社区分割, 通过模块度Q判断不同阈值μ下产生的社区分割是不是最优, 在迭代运算的倒数第2次时模块度达到最高的0.4904142, 社区因此被自动切分为两个社区, 如图5所示:
共主题网络中重要节点为T13、T3、T9、T23。共主题网络节点之间的权重越大, 说明它们在揭示文档时共同出现的机会越多, 联系越紧密。节点的面积越大, 说明在文档解释中重要性越大。例如T13和T9的边权较大, 说明它们在文档中共同出现的机会很大, 而且它们在网络中的节点面积也很大, 说明它们是代表文档的重要主题。为了更加清晰地揭示主题重要程度, 对T13、T3、T9、T23中的前30个主题词项云进行观察, 如图6所示:
可以看出, 数字、服务质量、图书馆自动化等逐渐成为《大学图书馆学报》期刊关注的重点。
Kim等比较了余弦相似、Jaccard系数、Kendall τ系数、DCG指标、KL距离、JSD等测度指标, 结果显示JSD 在主题距离测度上表现最好[35]。为了显示共主题网络在主题关系以及主题重要节点探测方面的能力, 将其与表现最好的基于JSD的K均值聚类进行比较, 观察共主题网络的可视化与基于JSD的多维标度展示的聚类可视化情况。JSD是一种基于KL距离的度量方法, 改善了KL距离的不对称问题, 成为概率主题的常用测度方法。任意两个主题Tp与Tq的JSD测度公式如下:
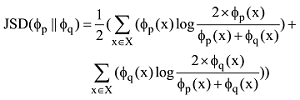
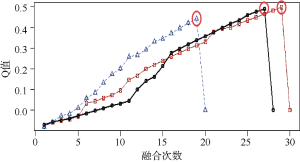
为了观察JSD测度结果和共主题网络测度结果是否一致, 分别选择最优主题数28和主观选择的主题数30、20这三个数目进行测试。对它们进行共主题网络分析, 其中社区分割的Q值融合如图7所示:
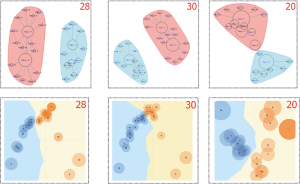
黑色线为最优主题数28的情况, 红色线和蓝色线分别为主题数30和20的情况。它们在Q值融合到倒数第2次时达到最大值, 见红色圆圈处。说明这三个主题数目构成的共主题网络都会聚类成两个社区。最后共主题网络的可视化结果如图8上半部分所示。
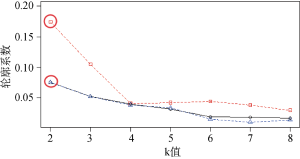
使用基于JSD的K-means聚类同样测度28、30、20三种主题数, 如果JSD测度下的K-means聚类和共主题网络下的聚类结果一致, 那么就可以判断共主题网络的聚类是可行的。判断基于JSD的K-means聚类的数目是否与模块度划分的聚类数目一致。基于JSD的K-means聚类的数目通过轮廓系数(Silhouette Coefficient)方法判断, 其值在-1到+1之间取值, 值越大表示聚类效果越好, 最大值对应的聚类数目就是最佳聚类数目[36]。依据这个原理使用多个聚类数目, 反复计算每个聚类数目条件下的轮廓系数, 当轮廓系数取最大时, 其相应的聚类数目是最好的。通过枚举, 令聚类数目k从2到8, 为了避免局部最优解在每个k值上重复运行25次K-means, 并计算当前k的平均轮廓系数, 最后选取轮廓系数最大的值对应的k作为最终的聚类数目, 计算结果如图9所示:
其中, 红色、黑色、蓝色分别表示30、28、20个主题, 三者的最优k值都是2, 见红色圆圈标注处。轮廓线划分的聚类主题与模块度划分的主题数目完全相同。选择k=2对主题数为30、28、20的主题进行聚类(其中主题节点的面积大小与该主题的概率分布值大小相关), 结果如图8下半部分所示。分别抽取共主题网络社区分割和K-means聚类中内容进行比较, 发现基于JSD的聚类和共主题网络聚类的结果相似度很高, 分别为28(100%)、20(95%)、30(87%)。比较结果如表2所示, 其中的数字为主题编号。
表2 两种方法聚类效果比较
| 主题数 | 共主题网络社区划分 | 基于JSD的K-means聚类 | ||
|---|---|---|---|---|
| 聚类1 | 聚类2 | 聚类1 | 聚类2 | |
| 28个 | 3, 4, 7, 10, 11, 12, 20, 23, 25, 26, 27 | 1, 2, 5, 6, 8, 9, 13, 14, 15, 16, 17, 18, 19, 21, 22, 24, 28 | 3, 4, 7, 10, 11, 12, 20, 23, 25, 26, 27 | 1, 2, 5, 6, 8, 9, 13, 14, 15, 16, 17, 18, 19, 21, 22, 24, 28 |
| 30个 | 1, 3, 5, 6, 7, 8, 11, 12, 14, 15, 20, 22, 23, 24, 25, 26, 29 | 2, 9, 16, 19, 4, 10, 13, 28, 30, 17, 18, 21, 27 | 1, 2, 3, 5, 6, 7, 8, 9, 11, 12, 14, 15, 16, 19, 20, 22, 23, 24, 25, 26, 29 | 4, 10, 13, 28, 30, 17, 18, 27, 21 |
| 20个 | 1, 2, 4, 5, 7, 8, 10, 11, 15, 16, 17, 20 | 3, 6, 9, 12, 13, 14, 18, 19 | 1, 4, 5, 7, 8, 10, 11, 15, 16, 17, 20 | 2, 3, 6, 9, 12, 13, 14, 18, 19 |
从聚类结果来看, 最优主题数28产生的共主题网络社区划分的结果与基于JSD的K-means聚类产生的结果完全一样, 原因是最优主题数中的主题不重复, 而主观选定的30个和20个主题两种方法在聚类时略有一点偏差, 但是大部分是一致的。例如主题数20的主题在共主题网络聚类1中主题2是不一致的, 但是通过观察其构成的词项, 发现它与和它聚在一起的其他主题讨论的话题非常相似, 都是讨论图书馆数字化方面的问题。另外共主题网络由于建立了节点之间的边权关系, 能够说明哪些主题节点是共同出现在文档之中来解释文档的, 而基于JSD主题聚类的方法只能测度主题是否相似, 却无法解释主题之间的这种关系。而且因为有介数中心性测度方法, 还能够探测出哪些主题是被大多数文档共同使用的, 这是JSD聚类做不到的。
本文通过共主题网络方法处理科技文献, 实现了以下目标:
(1) 建立主题之间的网络关系, 从而解决了传统LDA生成的主题缺乏联系的问题;
(2) 优化主题词项选择, 并遴选出与主题相关的词项, 并以词云的形式可视化展现。
共主题网络分析与其他基于主成分的主题关系探查的不同在于照顾到了高维数据的需要, 也不存在主题之间距离测度到底选择什么方法的问题, 能够探查到哪些主题之间联系紧密且共同出现在对文档的解释中。
在研究过程中存在的不足有:
(1) 由于一篇期刊文献不仅包含文本信息, 还包括作者信息, 如何结合主题和作者信息分析主题的演变情况?尽管目前AT模型[5]进行了相关研究, 但其考虑的是单个作者研究几个主题的问题。如何考虑科学家合作网络研究的主题情况, 以便于找到这些知识共同体是后续研究需要探讨的;
(2) 目前科技文献内在结构分析常用的手段是共词网络[37], 共主题网络和共词网络的原理有哪些不同, 它们在科技文献分析方面的联系与区别是什么, 这些问题也是后续工作要探讨的。
所有作者声明不存在利益冲突关系。
支撑数据[1-3]由作者自存储, E-mail: niutyut@126.com; 支撑数据[4-7]见期刊网络版 http://www.infotech.ac.cn。
[1] 钮亮. data_preprocessing.R. 《大学图书馆学报》题录文件摘要、标题、关键词的分词处理、文档词频矩阵构建, 最优主题数的确定.
[2] 钮亮. CoTopic_network.R. 三种不同主题数(28, 30, 20)下的文档–主题二分图构建, 加权共主题网络生成, 共主题网络重点主题测度, 模块度计算, 共主题网络社区分割.
[3] 钮亮. JSD_K-means.R. 三种不同主题数(28, 30, 20)下基于JSD的K均值轮廓线系数计算以及主题聚类可视化.
[4] 钮亮. JAL.rar. 知网下载的1989-2015年间《大学图书馆学报》题录文献.
[5] 钮亮. ldamodel.rar. 三种不同主题数(28, 30, 20)下的主题建模数据和文档词频数据, 可供共主题网络和K均值主题聚类使用.
[6] 钮亮. modularity.rar. 三种不同主题数(28, 30, 20)下的模块度数据, 判断最佳社区分割数目.
[7] 钮亮. silhouette-coefficient.rar. 三种不同主题数(28, 30, 20)下的聚类轮廓线数据, 判断最佳聚类数目.

/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}