关鹏
Guan Peng
中图分类号: G202
通讯作者:
收稿日期: 2016-02-22
修回日期: 2016-03-20
网络出版日期: 2016-09-25
版权声明: 2016 《现代图书情报技术》编辑部 《现代图书情报技术》编辑部
基金资助:
展开
摘要
【目的】有效确定科技情报分析中LDA主题模型的最优主题数目。【方法】利用主题相似度度量潜在主题之间的差异, 同时结合困惑度提出一种确定LDA最优主题数目的方法, 该方法既考虑主题抽取效果同时也考虑模型对新文档的泛化能力。【结果】获取国内新能源领域的科技文献作为数据集, 实证结果表明本文提出的最优LDA主题数确定方法与单纯使用困惑度相比, 具有更高的主题抽取查准率(91.67%)、F值(86.27%)及科技文献推荐精度(71.25%)。【局限】未针对其他类型的数据集进行新方法的验证, 如微博短文本、XML文档等。【结论】本文方法能够有效地从科技文献数据集中抽取辨识度较高的主题, 并能够提高科技文献推荐效果。
关键词:
Abstract
[Objective] This paper tries to identify the optimal number of topics for the Latent Dirichlet Allocation (LDA) model to analyze scientific and technical information. [Methods] First, we used the topic similarity to measure the differences among the latent topics. Second, we proposed a method determining the optimal topic numbers and tried to utilize this model to documents from Chinese literature in the field of new energy. [Results] The proposed method achieved higher precision ratio and higher F-score in topic extration, which improved the performance of literature recommendation systems. [Limitations] We did not examine the new mothod with other datasets, such as microblog posts and XML documents. [Conclusions] The proposed method could identify more recognizable topics and improve the performance of scientific and technical literature recommendation systems.
Keywords:
LDA(Latent Dirichlet Allocation)[1]主题模型是统计语言模型中的典型代表, 近几年在情报分析、知识服务、知识发现等领域得到了广泛的应用, 主要集中在科学文献知识挖掘[2-4]、科学研究热点发现与新兴主题探测[5-7]、科学研究主题演化[8-10]、学术评价[11]等研究方向。LDA之所以在情报学领域获得了广泛的应用, 主要原因在于LDA适合海量异构文本数据的建模, 其优势是可以将文本表示的维度大大降低, 从而避免维数灾难[12]。科技情报分析中大量实证研究证明了LDA的可靠性和有效性, 但仍存在一些问题没有解决。与一般的文本挖掘任务相比, 科技情报分析对LDA提出了更高的要求, 主要表现在以下两点:
(1) 在一般的文本挖掘任务中(如文本聚类、文本分类、文本自动摘要[13-16]等), LDA往往在中间的降维环节发挥重要作用, 不需要展示主题的具体形式, 只需要实现文本降维即可。但在科技情报分析任务中(如科学研究主题发现与主题演化), LDA必须将主题抽取的结果展示并分析, 主题抽取的质量直接影响主题抽取和主题演化的效果。
(2) LDA在情报分析中的应用更注重主题数目的确定。目前普遍认为应用LDA的最大问题是无法确定最优主题数目[17]。而主题数目的确定对于科技文献主题抽取至关重要。从目前国内外情报学领域应用LDA进行科技情报分析的情况看, 以上的两个问题还没有引起足够的重视。
大量实证研究证实LDA主题抽取效果与潜在主题数目K值有直接关系, 主题抽取的结果对K值非常敏感。基于此, 国内外不少学者展开了相关研究, 通过各种方法确定最优主题数目, 比较常用方法有以下三种:
(1) Blei等采用困惑度(Perplexity)作为评价模型好坏的标准, 通过选取困惑度最小的模型确定主题的最优数目[1]。困惑度指标可以确定最优的模型预测能力, 但是根据困惑度选取的主题数目往往偏大, 从而导致抽取的主题之间相似度较大, 主题辨识度不高的问题, 影响科技情报分析工作的效率。
(2) 将主题数目进行非参数化处理, 典型代表是层次狄利克雷过程(Hierarchical Dirichlet Processes, HDP)[18]。HDP与LDA主题模型不同的是: HDP是一种非参数贝叶斯模型, 能够从文档集中自动训练最合适的主题数目K。HDP通过狄利克雷过程的非参数特性解决了LDA中主题数目选择问题, 实验证实HDP所选的最优主题数目与基于困惑度选取的最优主题数目一致。但这种方法需要为同一个集合分别建立一个HDP模型和一个LDA模型, 且算法时间复杂性较高, 应用在科技情报分析中存在效率不高的问题。
(3) Griffiths等提出应用贝叶斯模型确定最优主题数目的方法[19]。该方法依赖于Gibbs抽样的过程, 计算复杂度较高, 且只能用来确定主题数目, 无法刻画模型的泛化能力。
另外, 一些学者探讨了主题相似度和最优主题数目之间的关联。Arun等将LDA看作矩阵分解过程, 主题抽取的效果取决于K值的选取, 并通过实验发现利用KL散度度量主题之间的相似度, 当主题数接近最优值时, KL散度较小, 而主题数远离最优值时, KL散度较大[20]。曹娟等通过理论证明和实验分析, 得到最优主题数与主题相似度之间的关系。以此为约束条件, 将最优K值选择与LDA模型参数估计统一在一个框架里, 通过实验证明最优K值不仅与文档集中文本的数量有关, 也与文本之间的相关程度有关[21]。综合分析发现, 以上确定LDA最优主题数的方法, 主要存在模型复杂度较高或者分析所得主题的辨识度不高等问题, 基于此, 本文从主题相似度入手构建新的确定LDA主题数的方法。
如前所述, 当使用LDA对科技文献集进行主题抽取时, 困惑度选取的主题数目往往较大、从而导致抽取的主题之间相似度较大、主题辨识度不高的问题。而主题辨识度与主题之间的相似度密切关联, 当主题相似度越小时, 主题之间的辨识度越大。基于此, 本文权衡模型的泛化能力以及主题抽取的效果, 提出基于困惑度和主题相似度相结合的指标Perplexity-Var来确定主题的最优数目。
在概率语言模型中, 困惑度是用来评估语言模型优劣的指标, 其基本思想是给测试集赋予较高概率值的语言模型较好[22], 且较小的困惑度意味着模型对新文本有较好的预测作用, 所以困惑度一般随着潜在主题数量的增加呈现递减的规律。
在LDA主题模型中, 困惑度计算公式[1]如下:
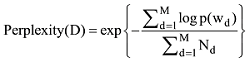
其中, D表示语料库中的测试集, 共M篇文档, Nd表示每篇文档d中的单词数, wd表示文档d中的词, p(wd)即文档中词wd产生的概率。
计算主题相似度常用的方法是Kullback-Leibler散度(KL散度)[23]或Jensen-Shannon散度(JS散度)[24], 由于KL散度不满足对称性和三角不等式, 所以本文选取JS散度作为度量主题之间相似度的计算方法。
在JS散度的基础上, 将随机变量方差的概念引入到潜在主题空间中, 即可衡量主题空间的整体差异性。主题方差是各个主题分别与其均值之间的距离平方和的平均数, 用Var(T)表示。主题方差用来度量主题和其均值之间的偏离程度, 可以衡量潜在主题空间的整体差异性和稳定性。主题方差的计算方法如下:
①计算主题-词概率分布φ均值 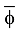
②利用JS散度计算主题方差, 公式如下:
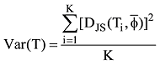
其中, T表示LDA抽取的主题, K表示主题数目, DJS表示JS散度。Var(T)衡量了主题之间的稳定性和差异性, 当Var(T)越大时, 主题之间的差异性越大, 主题之间的区分性就越好, 这样的主题结构就越稳定。困惑度反映了模型的预测能力, 但一味追求模型的预测能力则必然导致抽取的主题数过大的问题, 所以二者相结合可以有效解决主题辨识度不高的问题。
Perplexity-Var指标计算公式如下:
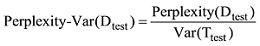
其中, Dtest为实验文本集中的测试数据集, Perplexity(Dtest)为测试数据集的困惑度, Var(Ttest)是测试数据集的主题方差。
Perplexity-Var指标含义: 首先, 考虑到模型的泛化能力, 当Perplexity越小时, LDA的泛化能力越好。其次, 考虑到LDA的主题抽取效果, 当主题结构的平均相似度最小时, 对应的LDA主题模型最优[21], 而主题结构的平均相似度越小, 则主题之间的差异就越大, 此时主题结构的方差越大。所以当主题方差越大时, LDA主题抽取的效果越佳, 同时Perplexity-Var指标就越小。综合以上分析, 当Perplexity-Var指标最小时, 对应的LDA主题模型最优。
(1) 数据检索
实验数据检索自CNKI, 通过去重、删除不完整数据, 共获得国内新能源领域1994年-2000年1 018篇文献, 字段包括标题、作者、机构、摘要和关键词, 不包括全文。将语料库中10%的文献用作测试集评估模型, 剩下的文献用来训练LDA模型。
通过对1 018篇科技文献的标题、关键词、摘要等元数据的分析, 笔者统计了文本集的主题及相关统计数据, 经过课题组成员打标签和专家鉴定, 共获得有效主题27个, 包含文献955篇, 另外还有主题不明确的文献63篇, 具体数据如表1所示。
表1 实验文本集主题及文献量
| 主题 | 文献量 | 主题 | 文献量 |
|---|---|---|---|
| 太阳能资源 | 89 | 风能资源 | 60 |
| 光伏发电 | 36 | 风力发电 | 55 |
| 太阳池 | 11 | 风力机 | 48 |
| 太阳能空调 | 10 | 沼气池 | 50 |
| 太阳灶 | 18 | 沼气发酵 | 30 |
| 太阳能电池 | 15 | 生物质能 | 62 |
| 太阳能热水器 | 69 | 地热资源 | 63 |
| 太阳能集热器 | 64 | 地热井、地热田 | 22 |
| 空气取水 | 8 | 地热发电 | 20 |
| 氢能 | 31 | 热流 | 14 |
| 海洋石油 | 20 | 波力发电 | 12 |
| 天然气水合物 | 62 | 潮汐能 | 13 |
| 优化设计 | 15 | 核能 | 9 |
| 建模、仿真 | 59 | 其他 | 63 |
(2) 数据预处理
①抽取领域词典、分词
通过Python编程获取1 018篇原始文献的关键词, 计算词频并获取领域词典。利用Python的jieba[25]分词软件包对原始文献的摘要进行分词, 并将上一步获取的领域词典作为分词组件的用户词典, 以提高分词的效果。
②LDA主题模型及工具包选择
LDA主题抽取由基于Python语言的机器学习包gensim[26]实现, Perplexity-Var指标的计算以及文档相似度的计算也通过Python编程实现。
实验环境是一台Windows 7旗舰版操作系统、Intel(R) Core(TM) i5-4570 CPU、3.2GHz、4GB内存的计算机。
确定LDA最优主题数目的三种方法中, 基于HDP确定LDA最优主题数目的方法算法复杂度较高, 而基于Gibbs抽样过程中的贝叶斯模型方法无法刻画模型的新文档预测能力。所以, 本文选取最流行的基于困惑度计算的方法作为本文方法的比较对象。实验设计从科技文献主题抽取效果和科技文献相似度推荐效果两个评价指标进行模型评价。
(1) 科技文献主题抽取效果
采用查准率P (Precision)、查全率R (Recall)和F值(F-Score)进行定量评价。查准率用以评估LDA主题抽取的有效主题中正确主题所占的比例, 查全率用以评估LDA抽取的正确主题占专家评判的领域研究主题的比例, 而F值为二者的调和平均值, 公式如下:

其中, Textract为LDA抽取的有效主题的数目; Tcorrect为有效主题中正确抽取的主题数目, 所谓正确抽取的主题指LDA所抽取的主题包含在专家评判的领域研究主题之中; Tstandard为通过文献调研和专家评判的领域主题数目。
(2) 科技文献相似度推荐
高质量的科技情报服务应立足于用户需求, 当用户在海量科技文献中寻找与自己阅读文献相似度较高的文献时, 科技文献相似度推荐就显得尤为迫切, 而文献推荐的质量与所抽取主题的质量是直接相关联的。所以, 特别选取科技文献相似度推荐效果作为评价最优主题数目选择方法的依据之一。
对训练集语料库实行LDA主题抽取之后, 文档可以表示为主题向量空间, 其维度比词向量空间的维度小很多。对于测试集的新文档, 可以使用训练好的LDA模型进行主题抽取, 并将文档映射到主题空间, 在此基础上使用JS散度度量新文档与训练集中文档的相似度, 完成新文档的相似度推荐工作。
基于文档相似度的文档推荐方法如下:
①在主题数目为K时用训练语料库对LDA模型进行参数学习;
②对测试集中的文档用训练好的LDA进行主题抽取;
③对测试集中的文档根据JS散度与训练集中的所有文档进行相似度计算, JS散度越小则文档越相似, 对所有文档进行相似度排名, 排名靠前的文档为相似度高的文档。
实验通过打标签的形式, 对测试集中的102篇文献进行人工标注, 标注出训练数据集中与之最相关的前10个文献。对每篇测试集文献取其相似度推荐结果中的前10篇文献, 通过推荐准确率(Recommend Precision)对相似度推荐效果进行对比分析。
假设对于M篇测试集中的文献di, 在训练数据集中, 人工标注的最相关的前10篇文献集为Ti, 通过相似度推荐算法得到的推荐结果前10篇文献集为Ri。则该测试集的推荐精度如公式(5)所示, 其中#(Ti)表示文献集Ti所含文献数量。
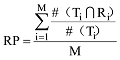
(1) 最优主题数目的确定
实验设定主题数目K的取值范围为[10, 200], 取步长为10进行LDA主题抽取, 分别在测试集上计算Perplexity指标和Perplexity-Var指标, 从而确定最优主题数目。
①Perplexity指标的计算
从图1中困惑度的取值来看, 当主题数目K=70时, LDA的困惑度指标达到最小, 此时最优主题数目为70。
②Perplexity-Var指标的计算
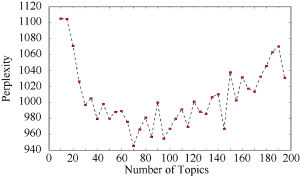
利用JS散度在测试集中计算不同主题数目K情况下, LDA抽取的潜在主题的方差如图2所示。
图2中显示方差随着主题数目的增加而减小, 即当主题数量越多时, 主题之间的方差越小。这是因为当抽取的主题越多时, 出现了一些干扰主题和语义重复的主题, 导致主题之间的相似度增大, 主题结构的方差变小, 造成主题结构不稳定。
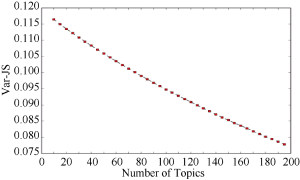
使用Perplexity-Var指标计算最优主题数目, 如图3所示。可以得出当主题数目选择为30个时, Perplexity-Var指标达到最小值, 此时选择的LDA最优主题数目为30。
综上, 从两种指标所确定的LDA主题数目来看, 单纯使用困惑度确定的主题数目70与人工判定的主题数目27相差太大, 而本文所提出的Perplexity-Var指标得到的最优主题数目30与人工判定的结果比较吻合。
(2) 实验结果对比分析
①科技文献主题抽取效果评价
根据实验结果可知, 通过Perplexity指标计算的最优主题数目70, 通过Perplexity-Var指标计算的最优主题数目为30, 利用LDA对新能源领域科技文献数据集进行主题抽取, 并分析结果, 部分主题抽取结果如表2和表3所示(只展示了前10个主题并省略了主题词的概率值):
表2 K=30时LDA主题抽取结果(部分结果, 阴影为干扰主题)
| 主题 | 主题词 | ||||
|---|---|---|---|---|---|
| Topic1 | 太阳能热水器 | 太阳能发电 | 农村能源 | 燃气热水器 | 蓄热 |
| Topic2 | 太阳能 | 太阳能集热器 | 管簇结构腔体式吸收器 | 集热效率 | 仿真 |
| Topic3 | 太阳能集热器 | 太阳能热水器 | 保温材料 | 循环管 | 聚苯乙烯泡沫板 |
| Topic4 | 太阳能 | 设计 | 发展 | 热水器 | 海洋能 |
| Topic5 | 沼气池 | 产气量 | 发酵液 | 农村 | 活动盖 |
| Topic6 | 地温梯度 | 地热资源 | 温度 | 热流 | 地热场 |
| Topic7 | 潮汐发电 | 风力发电机组 | 间断性发电 | 温泉水 | 风机 |
| Topic8 | 天然气水合物 | 温室气体 | 气体水合物 | 海洋 | 甲烷 |
| Topic9 | 太阳灶 | 反射率 | 太阳房 | 太阳能利用 | 太阳能资源 |
| Topic10 | 太阳能利用 | 集热器 | 太阳能热水器 | 真空管太阳能热水器 | 新能源 |
表3 K=70时LDA主题抽取结果(部分结果, 阴影为干扰主题)
| 主题 | 主题词 | ||||
|---|---|---|---|---|---|
| Topic1 | 潮汐电站 | 潮汐能资源 | 潮汐能源 | 灯泡贯流式机组 | 开发前景 |
| Topic2 | 太阳能热水器 | 集热器 | 热效率 | 太阳热水器 | 太阳能干燥器 |
| Topic3 | 太阳能 | 热效率 | 供热与制冷 | 热损 | 管簇结构腔体式吸收器 |
| Topic4 | 地热 | 厌氧发酵 | 地热热泵 | 供暖 | 太阳能集热器 |
| Topic5 | 真空集热管 | 太阳集热器 | 全玻璃 | 选择性吸收涂层 | 真空太阳集热管 |
| Topic6 | 沼气 | 综合利用 | 太阳能资源 | 天然气 | 自动绘图 |
| Topic7 | 地温梯度 | 大地热流 | 使用方法 | 地热电站 | 瞬时效率 |
| Topic8 | 风电场 | 风能 | 风能资源 | 风力发电机组 | 风力机 |
| Topic9 | 地温场 | 金属陶瓷 | 地热 | 共溅射 | 太阳能制氢 |
| Topic10 | 风力机 | 风力发电机 | 控制系统 | 模型 | 风轮 |
主题的含义是通过其主题词项的综合语义反映出来的, 通过与人工判定的主题进行比较(见表1), 得出Perplexity-Var指标确定的LDA主题模型可以准确抽取22个主题, 所抽取的30个主题中含有6个干扰主题; Perplexity指标确定的LDA主题模型可以准确抽取23个主题, 所抽取的70个主题中含有29个干扰主题。两种指标下的主题抽取效果对比如表4所示:
表4 不同最优主题数选择方法下LDA主题抽取效果对比
| 最优主题数 选择方法 | Textract | Tcorrect | Tstandard | 查准率(P) | 查全率(R) | F值 |
|---|---|---|---|---|---|---|
| Perplexity | 41 | 23 | 27 | 56.10% | 85.19% | 67.65% |
| Perplexity-Var | 24 | 22 | 27 | 91.67% | 81.48% | 86.27% |
表4展示了两种最优主题数选择方法下, LDA主题抽取的查准率、查全率和F值。可以看出, 基于困惑度(Perplexity)的方法, 抽取的有效主题数较多, 但是这些主题大多是重复的且干扰主题也很多, 所以查准率和F值较低。而基于主题相似度和困惑度(Perplexity-Var)的选择方法, 抽取的主题中干扰主题较少, 各项指标较高, 效果较好。科技文献主题挖掘的目标, 既要保证主题抽取的准确性也要保证主题抽取有较高的效率。否则, 抽取的干扰主题过多, 会严重影响主题挖掘效率。
②科技文献相似度推荐
先将训练文本集通过LDA进行主题抽取, 获取主题空间。然后将测试文本集中的每篇文献表示为主题空间中的向量, 利用本文提出的相似度推荐方法推荐相似文献, 并取前10篇推荐文献。表5展示了两种指标下, 测试文本集的相似度推荐精度。
从表5看出, Perplexity-Var指标确定的LDA主题模型其文献相似度推荐精度比单纯使用困惑度指标要高, 主要原因是Perplexity-Var指标不仅依赖于模型的预测能力, 还兼顾了主题之间的相似度, 使主题之间的差异性更加明显, 增加了主题的辨识度。当文档映射到主题空间上时, 主题可以很好地表达文档的语义信息。为了更加清晰地展示文献相似度推荐效果, 笔者从测试集中随机选取了两篇测试文档进行相似度推荐结果的展示, 分别属于潮汐发电主题和风力发电主题, 如表6和表7所示:
表6 文档相似度推荐结果对比1
| 推荐文档 (测试集) | K=30时的推荐结果排序(取前5) | K=70时的推荐结果排序(取前5) | ||||
|---|---|---|---|---|---|---|
| 文档关键词 | 文档 编号 (训练集) | JS散度 | 文档关键词 | 文档 编号 (训练集) | JS散度 | 文档关键词 |
| 潮汐电站; 潮 汐能源; 潮汐 能资源; 利用 问题; 经济效 益; 电站建设; 灯泡贯流式机 组; 离退休科 技工作者; 发 展前景; 开发 前景 | 215 | 0.00436 | 潮汐电站; 规划设计; 浙江省; 潮汐能资源; 灯泡贯流式机组; 潮汐发电站; 年发电量; 电力负荷; 潮汐资源; 开发利用 | 346 | 0.01760 | 海洋能资源; 开发前景; 资源开发利用; 波浪能; 盐差能; 海洋热能; 潮汐能资源; 潮汐发电站; 年发电量; 琼州海峡 |
| 299 | 0.00436 | 海洋能; 可再生能源; 潮汐电站; 波浪能; 开发利用; 波浪发电; 波力电站; 发电装置; 装机容量; 化石燃料 | 671 | 0.01760 | 地热井; 贴砾管; 钻机提升系统; 过滤器; 牙轮钻头; 钻井参数; 成井工艺; 存在问题; 测井资料; 石油钻井 | |
| 346 | 0.00436 | 海洋能资源; 开发前景; 资源开发利用; 波浪能; 盐差能; 海洋热能; 潮汐能资源; 潮汐发电站; 年发电量; 琼州海峡 | 311 | 0.01760 | 潮汐能; 潮汐电站; 综合开发 | |
| 444 | 0.00853 | 海洋波浪能; 波浪能发电站; 装机容量; 理论蕴藏量; 波浪发电; 开发利用; 年发电量; 波能发电站; 振荡水柱式; 波力电站 | 406 | 0.01760 | 对数正态模型; 参数估算方法; 拟合误差 | |
| 576 | 0.00853 | 发电设备; 开发利用; 波浪能量; 发电机; 波浪发电; 水下波; 缩小比; 蘑菇形; 浮体; 样机 | 459 | 0.03164 | 潮汐电站; 运行方式; 分析 | |
表7 文档相似度推荐结果对比2
| 推荐文档 (测试集) | K=30时的推荐结果排序(取前5) | K=70时的推荐结果排序(取前5) | ||||
|---|---|---|---|---|---|---|
| 文档关键词 | 文档 编号 (训练集) | JS散度 | 文档关键词 | 文档 编号 (训练集) | JS散度 | 文档关键词 |
| 风力发电场; 风力发电机 组; 风力机; 年发电量; 雷州半岛; 有效风速; 总装机容量; 风电场; 发 电装机容量; 常规火电 | 142 | 0.00073 | 内蒙古草原; 内蒙古锡林浩特; 风力发电机; 牧民; 财政补贴; 分离牛奶; 小型风机; 风能开发; 粉碎饲料; 风能资源 | 693 | 0.10211 | 风能; 风力发电; 风电场; 现状前景 |
| 196 | 0.00073 | 风能资源; 有效风能; 开发利用前景; 风能密度; 嵊泗县; 有效风速; 风力发电; 设计风速; 相对变率; 年平均风速 | 381 | 0.10286 | 风能; 风力机; 风能利用; 风能研究 | |
| 214 | 0.00073 | 浙江省海岛; 有效风速; 有效风能密度; 风力资源; 年平均风速; 风能资源; 日变化; 计算公式; 电力紧缺; 风资料 | 607 | 0.10286 | 风资源评价; 风电场; 年平均风速; 风能功率密度 | |
| 267 | 0.00191 | 风力机组; 内蒙古锡林浩特; 安家落户; 风力发电机; 锡盟; 内蒙古锡林郭勒盟; 拖拉机制造厂; 西德; 电建二公司; 年平均风速 | 752 | 0.10286 | 风能; 风力发电; 装机容量; 风电场 | |
| 269 | 0.00209 | 风电机; 内蒙古锡林浩; 特大型风力发电机组; 风电场; 锡林浩特市; 风能功率密度; 商业化运营; 计算机控制; 风电机组; 拖拉机制造 | 859 | 0.10531 | 可持续发展; 风能; 风电场; 租赁 | |
从表6可知, 第一篇属于潮汐发电主题的被推荐文档在主题数目K=30时与训练集中文档215之间具有最小的JS散度, 因而最相似; 而当K=70时, 与文档346最相似。从文档的关键词可以看出, 文档215在关键词上与被推荐文档极为相似, 都包含“潮汐电站; 潮汐能源; 潮汐能资源; 灯泡贯流式机组; 开发; 利用”等词, 特别是核心词汇“灯泡贯流式机组”, 而文档346没有。另外, 文档671是“地热”主题, 与“潮汐发电”无关, 可见K=30时文档推荐效果要优于K=70。同样的对比方法, 从表7中也可以得出类似的结论。可见, 基于Perplexity-Var指标选择的LDA模型, 由于保证了所抽取的主题结构的稳定性, 当文档表示为主题的混合分布时, 能够较准确地刻画文档的语义信息, 从而在文档相似度推荐方面有更好的表现。
在大数据背景下, 对于智能情报分析需求的日益增强, 对于能够处理海量文本数据的智能算法的需求日益增强。本文从LDA的特点入手, 分析了情报分析与一般的文本挖掘中应用LDA的主要区别。提出了在情报分析工作中应用LDA必须要重视主题抽取的效果和主题数目这两个问题。结合主题相似度以及困惑度, 本文提出确定最优主题数目的方法, 实证证实了在科技文献的知识挖掘中, 利用此方法可以有效确定主题数目获得较好的主题抽取结果, 帮助情报分析工作者从海量科技文献中抽取显著主题, 并能够提高基于相似度的科技文献推荐效果。
本文在实证分析时针对科技文献数据进行了方法有效性验证, 没有针对其他类型的数据集进行方法的验证, 如微博短文本、XML文档等。另外, 只针对科技情报分析任务, 从主题抽取效果和科技文献相似度推荐效果这两个方面进行新方法的验证, 其他方面的验证还需要进一步的拓展, 以证明方法的有效性。所以, 扩展验证范围和评价指标是下一步的工作重点。
关鹏: 提出研究方案和思路, 进行实验, 起草并修改论文;
王曰芬: 扩展研究思路, 审阅论文, 提出论文修改建议。
所有作者声明不存在利益冲突关系。
支撑数据见期刊网络版http://www.infotech.ac.cn。
[1] 关鹏. new_energy_corpus (training set).xlsx. 分词、去重、去停用词后的LDA训练语料库.
[2] 关鹏. new_energy_corpus (test set).xlsx. 分词、去重、去停用词后的LDA测试语料库.

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}