马红
Ma Hong
中图分类号: G254 TP391
通讯作者:
收稿日期: 2016-08-1
修回日期: 2016-11-2
网络出版日期: 2016-12-25
版权声明: 2016 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】通过结合传统LDA模型的概率主题抽取方法和共词网络分析发现文献词汇间的联系结构的两者优势, 降低由少量文献产生的高频词汇的干扰, 提高主题凝聚性。【方法】在交通法学文献摘要文本主题分析中, 加入文献的关键词作为分词复合词典, 提高语义识别度; 提出CA-LDA模型(Latent Dirichlet Allocation Model with Co-word Analysis), 在传统LDA模型的基础上加入共词网络分析, 以共词网络拓扑结构参数作为权重控制词汇主题分配(采用介数中心度), 优先提取同时具有高共现性(中介性)和高频率的词汇。【结果】CA-LDA模型可以得到多篇文献同时共现的高频词汇, 这样产生的重点词汇表对主题分析更有意义。该算法的结果不仅仅反映词频概率, 同时也能从词汇关联上发现枢纽词汇, 更深入理解该领域的研究热点。【局限】CA-LDA模型主题数目K的取值采用混淆度标准交叉验证获得, 如果在实际分析中K值太大, 不利于文献主题的分类整理, 未来研究需要对该结果进一步处理来凝聚主题。【结论】本文将该模型应用于交通法学研究领域热点主题分析, 在处理大规模文献数据中取得较好效果。相关研究可以拓展应用于各种领域的大规模文献数据自动化处理中。
关键词:
Abstract
[Objective]This paper aims to improve the effectiveness of extracting Chinese literature topics with the help of LDA model and co-word network analysis. [Methods] First, we added keywords to the word segmentation dictionary for the abstracts, which improved the semantic recognition of topic analysis. Second, we proposed a Latent Dirichlet Allocation Model with Co-word Analysis (CA-LDA) to control the topic distribution generated by the weight of co-word network topology parameters (i.e. Betweenness Centrality). Finally, we extracted the words with high connectivity (Betweenness Centrality) and frequency. [Results] The CA-LDA model retrieved high frequency and high connectivity words simultaneously, which were important for subject analysis. The proposed algorithm could also identify key node technical vocabularies with the help of co-word analysis. [Limitations] The K value (number of topics) was obtained by cross validation with perplexity. Thus, it was difficult to classify the document topics with larger K value. More research is needed to deal with this issue. [Conclusions] The proposed model effectively analyzes the topics of Chinese literature on transportation laws, which could also process literature data from other fields automatically.
Keywords:
信息的不断堆积导致文本的数据量日益庞大。这些文本远远超出一个人的正常阅读能力, 同时, 越来越多的信息以电子文本的形式存储, 为计算机分析文本提供了便利。主题模型(Topic Modeling)能够发现“文档-词语”之间所蕴含的潜在语义关系(即主题)。主题由一个核心事件或活动以及所有与之直接相关的事件和活动组成[1]。利用相关自然语言处理技术, 可以对文献内容进行特征分析、提取主题概念、追踪感兴趣的主题, 快速、准确获得领域热点知识和发展趋势。主题分析技术已经成为舆情分析、科研选题等方面的有效工具。
主题模型主要采用相似度计算来判断新主题是否属于已知主题, 基于统计知识, 对文本进行信息过滤, 然后利用分类策略跟踪相关主题。目前常用的模型主要有: 凝聚层次聚类算法(Hierarchical Clustering Algorithm, HCA)[2-3], 语言模型(Language Model, LM)[4-5]、向量空间模型(Vector Space Model, VSM)[6-7]和概率主题模型(Probabilistic Topic Models, PTM)。其中, 潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)模型属于概率主题模型, 被公认为是最成功的主题模型。对LDA模型的改进主要有快速折叠吉布斯采样LDA模型[8]、分布式学习LDA模型[9-10]; 打破原有可交换的假设的关联LDA模型[11]; 以及非参数贝叶斯HDP模型 (Hierarchical Dirichlet Processes)[12-13]。这些改进极大地提高了主题分析效率, 丰富了LDA方法的应用范围。
LDA模型可以从文本中抽取主题, 但没有考虑多个文本中词汇共现现象。很显然, 词汇在多篇文献中共同出现, 形成的共词网络对于主题凝聚具有指导意义。共词网络分析(Co-word Analysis)是由Callon等提出的另一种主题分析技术, 主要分析词汇的共现频率, 通过共词矩阵将距离较近的主题词聚集成簇, 凝聚文献主题[14]。如: Callon等分析了高分子化学的主题共现情况[15]、Coulter等研究软件工程主题共现情况[16]、张晓冬等研究计算机集成制造主题共现情况[17], 等等。共词网络分析是一种基于已有主题词的频率及共现的文献关联分析, 并不能产生主题。
因此, 本文结合两者的优势, 提出一种共词网络LDA主题模型(CA-LDA), 在传统LDA模型中加入共词网络特征参数, 调节主题生成过程。同时, 为了解决新参数带来的计算复杂度, 引入随机梯度下降(Stochastic Gradient Descent, SGD)优化提高了算法执行效率, 在处理大规模文本中取得较好效果。
潜在狄利克雷分配模型(Latent Dirichlet Allocation, LDA)是由Blei等在2003年提出的一种概率主题的语言模型[18], 该模型认为任何文本都可以表示成若干潜在主题的混合Dirichlet分布, 并可以用词频分布来刻画主题, 以主题混合权重视为K维参数的隐含随机变量, 其生成主题的过程如图1所示[18-19]。
LDA的参数估计主要有贝叶斯变分推断(Bayesian Variational Inference, VBI)[20]和Hoffman等提出的具有代表性的随机变分方法(Stochastic Variational Inference, SVI)[21]两种方法。传统LDA算法中吉布斯采样过程耗时严重, 有时会产生随机梯度噪音, 影响收敛速度。传统LDA模型算法过程如下:
(1) 从参数为α的Dirichlet分布第一取样获得文档主题内容向量θ, 确定每个主题被选择的概率;
(2) 从主题内容向量θ中选择一个主题z;
(3) 基于一个主题z的单词概率分布, 生成单个词汇。
重复此过程, 遍历文档所有词汇, 直到生成所有文档的主题。
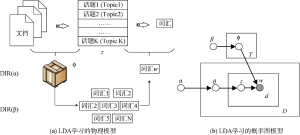
主题模型包含语料库D={W1,W2,L,WM}, 文档d 中的词汇集合W={W1,W2,L,WN}, 所有词汇属于K个主题。zdj代表d篇文档的第j个单词被划分给主题z; LDA的联合概率密度函数[18]为:
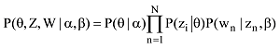
参数α代表文本集上主题的Dirichlet分布的先验, 描述了文本集中潜在隐含主题间的相对强弱; β是一个K×V的矩阵,βij表示第i个主题条件下生成第j个单词的概率, 描述了第j个特征词归属于第i个隐含主题的概率。θd表示文本d在T个主题上的多项分布, θ是一个文档级别的主题向量, 每个值对应主题z在文档中出现的概率, z和w都是单词级别的变量, z由θ生成, w由z和β共同生成, 所有单词w分别属于K个主题z。
每一篇文档的潜在主题分布θ都服从Dirichlet分布, 参数αk>0的情况下(公式(2)) 全部文档集的词频概率[11,18]为公式(3)。
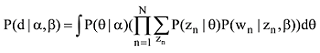
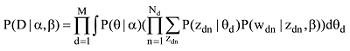
其中, Nd代表文档d的词汇的总数, 对文档中的每一个词wn (1≤n≤N), 生成一个主题zn服从参数为θ的多项式分布。
共词网络是由文本的主题词在多篇文章或多个段落共同出现(Co-exit)关系构成的一类特殊的科学知识网络。本文研究的摘要文本分析中, 共词网络为不同文章摘要中的词汇共现。定义共词网络图G(Vertex,Edge), 其中Vertex代表词汇网络节点集合, 也即文本集D上的全部词汇集Vertex={w1,w2,L,wNd}; Edge为词汇共现网络连接的边, Edge={eij|∃(wi,wj),wi, wj∈Vertex}, 也即词汇wi,wj在某一文本(或段落)内共现。这样的网络为无向网络, 其邻接矩阵 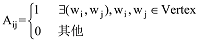
复杂网络的拓扑结构特征参数包括: 节点连通度指标(如: 度Degree); 中心度指标(如: 点度中心度Degree Centrality、介数中心度Betweenness Centrality、接近中心度Closeness Centrality); 节点间紧密度指标(如: 簇系数Clustering Coefficient、派系Cliques、社区Community)等。这些参数也表明了一个词汇在共词网络中的重要程度、以及与其他词汇关系的密切程度, 可以作为主题生成时计算词汇重要性的参考依据。本文提出的CA-LDA主题模型使用介数中心度作为词汇归类的调节变量, 修正LDA模型词汇生成概率, 并建立共词网络, 提高主题分析的凝聚性(也可以采用点度中心度或接近中心度作为调节变量, 其实验结果与介数中心度调节变量的效果基本一致)。
介数中心度, 简称中介度, 源于社会网络分析中个体的重要性。一个节点的介数中心度表示所有的节点对之间通过该节点的最短路径条数。介数中心度在共词网络中很好地描述了词汇之间的联系的中介关系, 以这个词汇为中心的主题归类, 可以提高主题内部凝聚性。如果记图中任意两个词汇wi,wj之间的最短路径条数为σij, 而这些最短路径中经过节点l的条数为σij(wl), 那么节点wi,wj间经过节点l的最短路径条数占wi,wj间总的最短路径条数的比例为 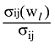
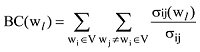
传统LDA模型给某个文档先选择一个主题z, 再根据该主题生成文档, 该文档中的所有词都来自一个主题。主题z1,z2,L zK, 生成文档W的概率[18]为:
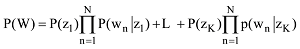
CA-LDA算法的核心是在判断词汇归类时候, 考虑词汇在共词网络中的介数中心度。在复杂网络理论中, 一个节点的介数中心度越大, 该节点在整个网络中就越重要[23]。同理, 词汇共现网络G(Vertex,Edge)的节点词汇的介数中心度越大, 在主题划分中该词汇也越重要。基于这个思想, CA-LDA模型给生成词汇的概率增加一个权重 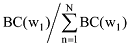
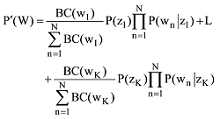
根据吉布斯采样算法[8,18], 对于后验估计 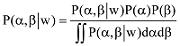
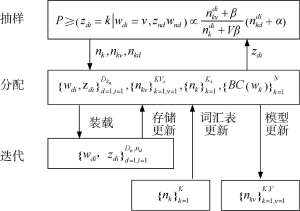
为了解决这个问题, 根据随机梯度下降算法, 笔者改进传统吉布斯采样的样本分割与抽样过程, 从而降低迭代次数。设计一个随机梯度函数, 存储CA-LDA模型的参数: 主题词汇表 
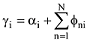
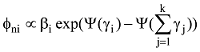
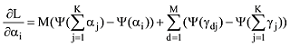
针对每一篇文档的初始γ和φ参数, 迭代更新主题词汇表 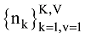
CA-LDA算法以及随机梯度下降优化的迭代过程, 如图2所示。
具体执行过程可以用伪代码表示:
Initialize 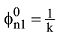
Initialize 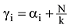
repeat
for n=1 to N
for i=1 to K
update 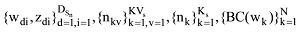
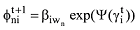
sample topic: 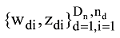
end for
normalize 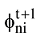
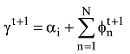
until convergence
传统LDA词汇表来源于概率分布, 也就是较高出现频率的词汇作为重点词汇优先提取, 而CA-LDA模型根据共词网络拓扑结构参数(本文采用中介中心度)调整, 获得的结果是同时具有较高的共现性(中介性)和频率的词汇优先提取。这种调整可以降低由少量文献产生高频词汇的干扰, 得到多篇文献同时共现的高频词汇, 这样产生的重点词汇表对主题分析更有意义。
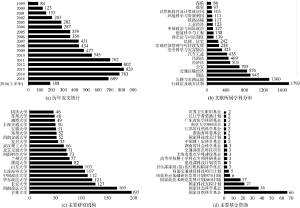
在2016年7月23日检索中国知网的中国学术期刊网络出版总库, 检索式: “条件: 发表时间 between (2006-01-01, 2016-06-30 and 主题=交通 and 主题=法律 or 主题=法规 ) (精确匹配)”, 检索获得6 230条文献记录, 根据“发表年份”、“学科”、“机构”和“基金”这4项做描述性统计分析, 如图3所示。
由图3中可以看出: 交通法学领域研究文献呈现快速增长趋势, 但最近两年略有下降; 行政法及地方法制、公路与水路运输、刑法、交通运输经济领域的相关文献比较集中; 吉林大学、西南政法大学、长安大学、华东政法大学、中国政法大学为主要研究机构; 国家自然科学基金、国家社会科学基金、国家科技支撑计划、国家高技术研究发展计划(863计划)为主要资助来源。
将交通法学6 230篇中文文献的摘要字段提取出来, 经过文本整理和分词获得各文档的词汇。采用停用词字典的方法去除文本中部分代词和语气助词等。但如果仅仅做简单分词, 得出的高频词汇前10位的是: “机制”、“规范”、“建设”、“问题”、“发展”、“管理”、“研究”、“影响”、“社会”、“道路”, 这些词汇的内涵不是十分明确, 对分析文本主题实际意义并不大。
为此, 可以采用增加复合词的方法提高语义识别度, 提取6 230篇文献的关键词字段, 去重后获得11 565条词汇作为复合词词典, 并将所有复合词分词, 一并存储。比对每一篇摘要是否包含该复合词拆分的所有分词, 如果包含则去除这些分词, 增加该复合词。结果与“关键词”+“摘要”的结果不是一一对应。这样分析的结果可以做到依赖摘要的文本分析而不是作者提供的关键词。
如图4所示, 以任意一篇文献: 中南大学王飞跃发表在《政治与法律》2016年第6期的文章《论道路交通事故责任认定中几对关系的区分》的文本预处理过程为例, 简单分词获得189个词汇。去除重复词和停用词、增加复合词并删除复合词包含词汇, 获得80个词汇。其中: “责任推定”、“道路交通事故”、“侵权责任法”、“治安管理”、“刑事责任”、“交通事故”、“交通法律” 7个词汇为新增复合词。实际上, 作者为这篇文章提供的关键词是: “交通事故”、“与交通有关的事故”、“不作为交通违章”、“责任推定” 4个关键词, 两者并不是一一对应。
分析这篇文献新增复合词可以发现: 新增复合词有本文关键词, 如“责任推定”, 该词在其他文献关键词中没有出现过; 也有与本文关键词高度相似的复合词, 如“道路交通事故”(与本文关键词“交通事故”、“与交通有关的事故”高度相似)来源于2014年北京工业大学孙玉荣发表在《法学杂志》2014年第3期《道路交通事故损害赔偿特殊责任主体研究》, 以及湖北警官学院邵祖峰发表在《中国司法鉴定》2012年第3期《论道路交通事故鉴定的现状、问题与对策》等367篇文献的关键词; 还有本文关键词没有涉及, 但摘要中出现的复合词, 如“侵权责任法”, 则是来源于驻马店市委党校李志浩发表在《广东教育学院学报》2010年第6期《道路交通事故责任主体研究——兼评<侵权责任法>相关规定》等24篇文献的关键词。这些复合词的加入与原文摘要内容高度一致, 语义更加明确。
利用CA-LDA模型针对每一篇文章的摘要做主题分析。其中可变量包括超参数α, φ以及主题数目K。α根据主题数目的变化而变化, 由一般经验值可取 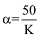
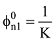
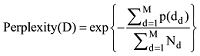
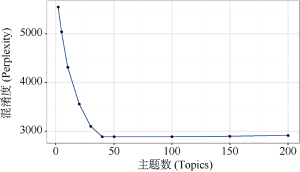
根据混淆度计算公式, 在文本集D上进行10组实验, 获得不同K值下的混淆度数值如图5所示, 其中K值在50的时候模型混淆度取得最小值。
利用CA-LDA模型, 根据共词网络拓扑结构参数(本文采用中介中心度)调整生成主题概率的权重, 生成50个主题。提取各个主题中的前20位词汇1 000个, 生成共词网络矩阵(1000×1000)稀疏矩阵(Sparsity= 98.16%), 权重系数采用TF-IDF(Term Frequency-Inverse Document Frequency)[18], 去掉稀疏矩阵中低频率的词(Sparsity=90%), 获得533个词汇作为领域热点主题词汇。被去除词汇有“安保公司”、“深水航道”等467个词汇, 这些词汇的最高词频为7, 而剩余词汇词频平均值为64, 词频最高的“交通安全”达到353。这种稀疏矩阵降维处理极大减少了计算量, 在大规模文本处理时信息损失较小。
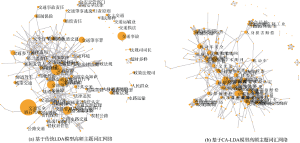
将CA-LDA模型获得的533个高频主题词汇建立共词网络, 共词网络主题个数降至28个, 如图6所示。
这些热点词汇基本涵盖2006年到2016年交通法学研究热点。如果将这些词汇按照出现文献所对应的年份排序, 可以发现热点领域演变。
在同一数据集上(交通法学6 230篇中文文献的摘要文本), 分别采用CA-LDA模型方法与传统LDA模型主题做分析实验, 结果如表1所示。由于CA-LDA和传统LDA模型都采用LDA词袋模式, 得到的词汇表相同, 但词汇重要性排序差异较大。其中CA-LDA模型获得的高频共现词汇“中国学术期刊”与交通法学研究主题无关, 主要原因是网络数据中非主题内容词汇的混入。
两种模型前50位高频词汇基本都是以“交通运输”、“交通管理”、“交通事故”为主, 核心内容一致。比较两种算法结果获得的前50位高频词差异:
(1) 两者有18个词汇不同(见表1中带有底纹词汇);
(2) 各词的词频顺序有较大差异;
(3) 传统LDA模型生成的主题重点词汇意义较为单一(如“城市轨道交通”、“城市交通”、“公共交通”、 “法律责任”、“司法解释”等), CA-LDA模型结果重点词汇中出现了“汽车社会”、“低碳经济”、“蓝色经济”等研究背景词汇; “《道路交通安全法》”、“《解释》”等法律法规; 以及“限额范围”、“自由裁量权”、“结果加重犯”、“交通事故认定书”、“人身损害赔偿”等争议研究热点内容; “电子警察”、“交通安全教育”、“公交优先”等管理方法。
总之, CA-LDA模型获得的研究辅助信息比传统LDA模型结果要丰富, 而且确实为热点研究内容。
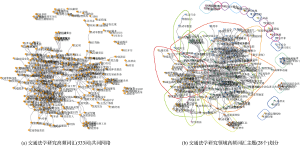
为了显示清晰, 仅对两个模型前50位的高频词汇生成词汇网络, 并以节点大小代表词频(或权重修正后词频), 结果如图7所示。
从图7对比可以看出, 两个模型结果差异较大。传统LDA模型中孤立的高频词汇较多, 说明这些词汇由少量文献产生, 而热点应该是多篇文献共同研究内容; 传统LDA模型生成词频差异较大, 分布不均匀, 可能把绝对频率较低而相对频率高的词汇作为重点。而CA-LDA模型的词频差异较小, 关联更强, 词汇扎堆明显, 主题集聚优势明显。
本文提出一个共词网络分析的CA-LDA模型, 该模型以网络拓扑结构参数作为主题归类的调节变量, 控制词汇主题分配, 并使用随机梯度下降技术提高算法执行效率。共词网络拓扑结构参数从词向量关联角度修改词汇分配, 其结果不仅反映词频概率, 同时, 词汇网络的节点介数中心度也能提供信息, 从词汇关联上发现枢纽词汇, 在纵向上反映领域研究演进的关键技术, 在横向上提供解决不同问题的同一有效手段。该模型应用在交通法学研究领域热点主题分析, 在处理大规模文献数据中取得了较好效果。相关研究可以拓展应用于各种领域的大规模文献数据自动化处理中。
CA-LDA模型以节点中心度指标调节LDA主题生成, 其他复杂网络拓扑结构参数(如节点间紧密度的簇系数、派系、社区)也在不同角度反映共词网络的词汇社交网络关系, 可以进一步研究这些参数对LDA模型主题生成的影响; 再者, 分词是文本分析的重要基础, 但是所得结果往往都是单独词汇, 存在歧义等特殊性, 不利于文本语义分析。本文采用增加合成词的方法来提高语义识别度, 这些词汇来自于文献关键词, 这种方法不适用于其他文本处理(如网络购物评价等), 可以建立一个领域内的专业词汇表, 实现更科学的分词; 最后, 基于LDA主题模型分析需要科学设置主题数K, 虽然该值可以采用混淆度标准交叉验证获得, 但在实际分析中计算出的K值有时会很大, 不利于文献主题的分类整理。未来研究需要找到更为科学的主题数目确定方法, 或者对K值较大的主题划分结果进一步处理来凝聚主题。
马红: 提出研究思路, 设计研究方案, 结论分析;
蔡永明: 数据获取、整理和清洗, 算法设计, 程序开发。
所有作者声明不存在利益冲突关系。
支撑数据见期刊网络版 http://www.infotech.ac.cn。
[1] 马红, 蔡永明. CNKI 检索原始数据.rar. CNKI 检索原始数据.
[2] 马红, 蔡永明. 合成词库和停用词库.rar. 合成词库和停用词库.
[3] 马红, 蔡永明. 描述性统计分析数据.xlsx. 描述性统计分析数据.
[4] 马红, 蔡永明. 预处理后数据.rar. 预处理后数据.

/
| 〈 |
|
〉 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}