张群 , 王红军, 王伦文
, 王红军, 王伦文
中国人民解放军电子工程学院 合肥 230037
Zhang Qun, Wang Hongjun, Wang Lunwen
中图分类号: G350
通讯作者:
收稿日期: 2016-08-1
修回日期: 2016-10-14
网络出版日期: 2016-12-25
版权声明: 2016 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】针对短文本主题聚焦性差以及严重的特征稀疏问题, 设计一种基于词向量与LDA主题模型相融合的短文本分类方法。【方法】从“词”粒度及“文本”粒度层面同时对短文本进行精细语义建模, 首先基于Word2Vec训练词向量并通过相加平均法合成“词”粒度层面的短文本向量, 基于吉布斯采样法训练LDA主题模型并根据主题概率最大原则对短文本进行特征扩展, 然后基于词向量相似度计算扩展特征权重得到“文本”粒度层面的短文本向量, 最后通过向量拼接构建词向量与LDA相融合的短文本表示模型, 在此基础上通过最近邻分类算法完成短文本分类。【结果】相比传统的基于向量空间模型、基于词向量、基于LDA主题模型这三种基于单一模型的分类方法, 词向量与LDA相融合的分类方法准确率、召回率、F1值均有提升, 分别至少提升3.7%, 4.1%和3.9%。【局限】仅应用于最近邻分类器, 尚未推广应用到朴素贝叶斯和支持向量机等多种不同的分类器。【结论】基于词向量与LDA相融合的短文本表示模型进行分类, 能有效克服短文本的主题聚焦性差及特征稀疏性问题, 提高短文本分类性能。
关键词:
Abstract
[Objective]This paper proposes a short text classification method with the help of word embedding and LDA model, aiming to address the topic-focus and feature sparsity issues. [Methods] First, we built short text semantic models at the “word” and “text” levels. Second, we trained the word embedding with Word2Vec and created a short text vector at the “word” level. Third, we trained the LDA model with Gibbs sampling, and then expanded the feature of short texts in accordance with the maximum LDA topic probability. Fourth, we calculated the weight of expanded features based on word embedding similarity to obtain short text vector at the “text” level. Finally, we merged the “word” and “text” vectors to establish an integral short text vector and then generated their classification scheme with the k-Nearest Neighbors classifier. [Results] Compared to the traditional singleton-based methods, the precision, recall, F1 of the new method were increased by 3.7%, 4.1% and 3.9%, respectively. [Limitations] Our method was only examined with the k-Nearest Neighbors classifier. More research is needed to study its performance with other classifiers. [Conclusions] The proposed method could effectively improve the performance of short text classification systems.
Keywords:
移动终端的智能化催生了移动互联网的飞速发展。为适应移动用户阅读习惯, 移动互联网内容更多以短文本形式呈现, 例如微博和即时推送新闻等, 如何对海量短文本内容进行自动分类已成为研究者关注的热点问题。
在过去几十年里, 国内外学者提出及改进了一系列经典的机器学习算法, 如k近邻分类(k-Nearest Neighbors, k-NN) [1]、朴素贝叶斯分类(Naive Bayes, NB) [2]和支持向量机(Support Vector Machine, SVM)[3]等, 并将其成功应用于文本分类领域, 取得了比较满意的效果。然而相比普通长文本, 新兴的移动互联网短文本具有内容长度短小、信息描述能力弱、主题分散等特点, 使得以上经典文本分类方法应用于该领域时将面临严重的特征稀疏问题[4], 导致短文本分类效果并不理想。
文本数据表示对于文本分类至关重要, 数据表示的好坏直接影响分类效果。传统文本分类算法通常基于向量空间模型(Vector Space Model, VSM), 通过特征词及权值构成的向量表示文本数据[5]。该方法忽略了词语间的语义关系, 无法体现文本深层次的主题信息, 存在数据高维稀疏问题, 尤其是在表示短文本时, 语义缺失及高维稀疏问题变得更为严重。近年来针对这一问题的研究主要有三个方向。一些学者引入外部知识库(如搜索引擎、维基百科和知网等)对文本进行语义特征扩展以丰富词语间语义关系[6-7]。这些方法能一定程度上缓解稀疏性, 其局限性在于严重依赖外部知识库的质量, 对于知识库中未收录的主题概念无能为力, 且计算量大, 耗时长, 因此应用于主题分散的短文本效果一般。另有部分学者通过将原始高维特征词空间映射到低维的潜在语义空间或主题空间, 挖掘文本潜在的语义结构。如潜在语义分析方法(Latent Semantic Analysis, LSA)将文本表示为低维潜在语义空间的语义向量[8], 降维去噪的同时改善稀疏性, 但是降维过程可能带来分类受损问题且该语义空间每个维度的语义含义并不明确。相比LSA方法, LDA主题模型 (Latent Dirichlet Allocation, LDA)将文本表示为其隐含主题的概率分布[9], 能极大改善文本高维稀疏性, 克服LSA方法分类受损问题的同时每个主题维度也具有可解释性, 因此受到广泛应用。文献[10-11]直接在LDA主题维上进行文本分类, 但由于短文本主题聚焦性差, 该方法对于改善短文本的稀疏性效果有限; 文献[12-14]基于LDA主题模型对短文本进行特征扩展, 相比于单纯直接应用LDA的方法有一定的效果提升。以上的VSM、LSA和LDA模型均为直接导出短文本向量以表示短文本, 属于“文本”粒度层面的模型。最新研究考虑从“词”粒度层面进行文本建模从而更精细地表达语义, 首先导出词的向量表示, 然后将词向量(Word Embedding)合成短文本向量[15]。这种方法有效解决了短文本主题分散和聚焦性差的问题, 其局限性在于简单有效的词向量合成方法还有待研究, 如文献[16-17]通过神经网络构建词向量的短文本合成模型, 具有较高的复杂度。
在以上分析的基础上, 本文将词向量与LDA有机融合, 提出一种新的短文本分类方法, 从“词”粒度及“文本”粒度层面同时进行短文本建模, 以解决短文本特征稀疏问题及主题聚焦性差的问题。通过简单直接的相加平均法合成“词”粒度层面的短文本向量, 避免了复杂的词向量合成过程; 同时在进行“文本”粒度层面建模时, 并非直接应用LDA模型将短文本映射到主题维, 而是基于LDA主题概率最大原则对短文本进行特征扩展, 并基于词向量相似度计算扩展特征权重, 从而构建词向量与LDA相融合的短文本表示模型; 另外在训练词向量及LDA模型时并不依赖已标注数据, 仅在训练分类器时需要小规模的已标注数据, 属于一种半监督学习方法[18]。
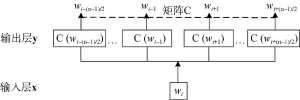
词向量是词语的一种数学表示方法, 向量的每个维度代表一个语义特征, 向量间的距离或相似度能够反映词语间的语义相似性。分布假说理论(Distributional Hypothesis)表明词语语义由其上下文决定。依据分布假说理论, 一种基于神经网络的词向量获取方法受到广泛研究, 该方法通过对目标词的上下文及目标词与其上下文的关系进行建模, 能够获取包含丰富语义的低维稠密的词向量。Bengio等提出神经网络语言模型(Neural Network Language Model, NNLM), 词向量作为一种副产品, 是在训练该语言模型的同时得到的[19]。NNLM为一个三层前馈神经网络结构, 如图1所示[19]。
NNLM结构图中, wi为目标词, 目标词的上下文为一个词序列, 即context={wi-n+1,L,wi-2,wi-1}。NNLM的输入层通过一个矩阵C将上下文序列中的词映射为词向量, 然后将词向量顺序拼接作为整个模型的输入, 如下所示[19]。
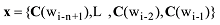
隐藏层与输出层分别如下[19]。
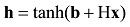
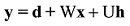
其中, tanh为隐藏层激活函数, H为输入层到隐藏层的权重矩阵, U为隐藏层到输出层的权重矩阵, W为输入层到输出层的直连边权重矩阵(通常忽略), b、d为模型偏置项。模型最终需通过Softmax函数将输出层y归一化为目标词的概率分布, 如下所示[19]。
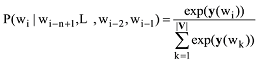
最后, 模型通过迭代优化, 在使公式(4)最大化的过程中训练出模型参数, 其中包括词向量参数矩阵C, 从而获得词向量。
NNLM的计算量集中在公式(3)中的隐藏层到输出层的矩阵乘法Uh中; 另外, 公式(4)中, |V|为词汇表大小, 因此当词汇表很大时Softmax函数计算非常耗时。
在NNLM的基础上, 本文基于Word2Vec进行词向量训练。Word2Vec是基于Mikolov等提出的CBOW (Continuous Bag-of-Words)和Skip-gram 模型开放的一款词向量训练工具[20]。CBOW及Skip-gram这两种模型类似于NNLM, 区别在于NNLM是以训练语言模型为目标而间接获得了词向量, 而CBOW和Skip-gram模型的直接目的即为获取词向量。因此Word2Vec在NNLM的基础上做了以下简化与改进:
(1) 去掉隐藏层, 避免了公式(3)中复杂的矩阵乘法运算Uh。
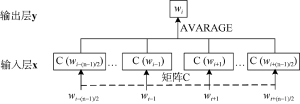
(2) NNLM在输入层采用如公式(1)所示的词向量拼接法, 而Word2Vec的CBOW模型采用向量相加求平均法降低了运算复杂度, 如下所示[20]。
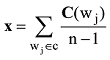
其中, c={wi-(n-1)/2,L,wi-1,wi+1,L wi+(n-1)/2}, 指CBOW中目标词wi前后各(n-1)/2个词, 即wi的上下文。相比NNLM仅采用前(n-1)个词作wi的上下文, Word2Vec更具有上下文完备性。
CBOW与Skip-gram不同之处在于, CBOW是通过上下文预测目标词而Skip-gram是通过目标词预测上下文。CBOW与Skip-gram结构图分别如图2、图3所示[20]。
另外, 针对NNLM输出层Softmax函数计算复杂度大的问题, Word2Vec采用两种算法进行优化: 结合霍夫曼编码的层次Softmax算法[21]及负采样(Negative Sampling)技术[15]。
本文基于Word2Vec训练词向量用于短文本分类任务, 发现语料数据集规模及模型的选择会影响词向量质量进而影响短文本分类效果。针对这两个方面, 总结以下经验用于指导训练词向量:
(1) 语料集规模在200MB以上时, CBOW模型优于Skip-gram模型, 在100MB以下则相反, 在100MB- 200MB之间两模型表现差别不明显。
(2) CBOW模型在输入层采用词向量相加平均法代替NNLM中的词向量拼接法, 降低了计算复杂度, 但忽略了词序信息; 本文尝试在CBOW模型的基础上仍采用词向量拼接法引入词序信息, 但结果表明修改后的模型与原CBOW模型相比性能表现无明显差别。
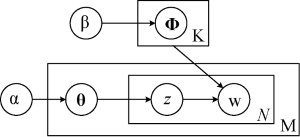
LDA主题模型是一个“文档-主题-词”的三层贝叶斯概率生成模型, 其通过模拟文本的生成过程, 将文本建模为混合主题上的概率分布, 将主题建模为混合词上的概率分布, 模型如图4所示[9]。
图4中符号含义如下: M表示总文本数,N表示一篇文本中的总词数, K表示文本集隐含主题数; θ为文本-主题分布矩阵, Φ为主题-词分布矩阵, θ与Φ均服从狄利克雷分布(Dirichlet Distribution), α为θ的超参数, β为Φ的超参数;w表示词,z为w所属的主题。
令dm=(wm1,wm2,L wmN)表示第m篇文本, zm=(zm1,zm2,L zmn)中分量表示dm中每个词对应所属的主题, D=(d1,d2,L ,dM)表示整个文本集, Z=(z1,z2,L ,zM)中分量表示D中每个文本对应的主题向量。基于图4, LDA模型生成过程描述如下:
(1) 对于第m篇文本dm, 根据θ服从参数为α的Dirichlet分布(θm~Dir(α)), 确定一个主题分布θm;
(2) 对于第n个词wmn, 根据z服从θ的多项分布(zmn~Mult(θm)), 为wmn确定一个主题编号zmn;
(3)根据Φ服从参数为β的Dirichlet分布(Φm~Dir(β)), 确定一个主题-词分布矩阵Φm, 同时根据步骤(2)确定的zmn, 为wmn确定一个词分布 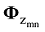
(4)根据词wmn服从 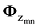
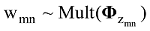
(5) 遍历文本中N个词, 重复步骤(2)-步骤(4), 生成dm;
(6) 遍历文本集中M篇文本, 重复步骤(1)-步骤(5), 生成整个文本集D。
LDA模型的目标是为文本集D中的每个词分配一个潜在主题, 从而估计出模型中的文本-主题分布矩阵θ与主题-词分布矩阵Φ, 由此需要计算如公式(6)所示的后验概率[9]。
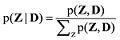
其中分母计算难度非常大, 为避免直接计算公式(6), 一种简单有效的方法是采用吉布斯采样(Gibbs Sampling)算法。
吉布斯采样算法[22]是一种特殊的基于马氏链的蒙特卡洛方法(Markov Chain Monte Carlo, MCMC), 通过对词的主题采样生成马氏链, 用p(zi|z-i,D)仿真近似p(Z|D)。P(zi|z-i,D)表示对于词汇表中V的一个词t, 其当前采样的主题zi依赖于其他时刻采样的主题z-i。p(zi|z-i,D)通过吉布斯采样公式得到[22]。
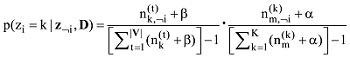
其中, |V|表示词汇表V的大小; 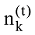
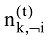
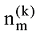
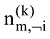
主题采样完成后, 基于采样得到的样本可以估计出模型的文本-主题分布矩阵θ及主题-词分布矩阵Φ, 公式如下[22]。
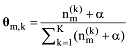
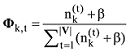
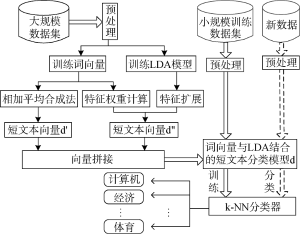
LDA主题模型从“文本”粒度层面对文本建模, 在传统长文本分类任务中取得不错效果, 但应用于短文本分类时效果很差; 词向量属于“词”粒度层面的模型, 在词语的语义相似度计算方面表现优越, 但应用于文本级别的语义表示还有待研究。短文本介于“词”粒度与“文本”粒度之间, 鉴于此, 本文提出一种词向量与LDA相融合的短文本分类方法, 从“词”粒度层面与“文本”粒度层面同时对短文本建模; 另外, 词向量及LDA模型的训练是在大规模无标注数据集上完成的, 仅分类器的训练需要小规模的已标注训练数据, 属于半监督学习方法。方法流程如图5所示。
该方法分为4个步骤, 描述如下:
(1) 构建一个大规模无标注数据集及一个小规模已标注数据集, 并进行数据预处理;
(2) 在大规模无标注数据集上训练词向量及LDA主题模型;
(3) 在小规模已标注数据集上融合词向量与LDA对短文本建模;
(4) 构建一个k近邻分类器(k-NN)对新的短文本进行分类, 测试本文方法的分类效果。
数据集的构建对于文本分类至关重要。分类任务属于有监督学习, 需要大量已标注数据保证学习的准确性。本文分类方法属于半监督学习, 仅需要小部分已标注数据, 有效降低了人工数据标注的工作量。需要构建一个大规模无标注数据集D及一个小规模有标注数据集D′, 对两个数据集有以下要求:
(1) 数据集应符合正常的语言表达习惯;
(2) 数据集所包含的领域应与分类任务一致;
(3) 数据集应最大程度地包含并均衡分布于领域的各个潜在主题;
(4) 大规模无标注数据集应包含足够多的领域及主题相关词。
数据集预处理主要包括中文分词、停用词过滤等操作。对于小规模已标注训练数据集还需采用χ2统计进行特征选择。χ2统计值反映了词语t与数据集类别c的主题相关性, 如下所示[2]。
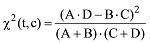
公式(10)中各参数含义如表1所示。
在大规模无标注数据集上训练词向量及LDA主题模型, 然后融合词向量与LDA对短文本建模。
基于Word2Vec训练词向量, 结果记为:
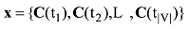
其中, tn表示词汇表V中第n个词, C(tm)为tm的词向量表示。
基于吉布斯采样训练LDA, 输出文件包括文本-主题分布矩阵θ、主题-词分布矩阵Φ及主题词文件。主题词文件显示了每个潜在主题下概率最大(即主题相关性最强)的前n个词, 主题词文件示例如表2所示。
表2 主题词文件示例
| 主题编号 | 主题词及其概率值 | ||
|---|---|---|---|
| Topic 0th: | 教育 0.020447 人 0.013244 | 学校 0.017544 教师 0.012354 | 学生0.015859 …… |
| Topic 1th: | 比赛 0.020663 中国 0.011119 | 中 0.012811 亚运会0.010645 | 选手0.011491 …… |
| Topic 2th: | 中 0.009706 武器 0.006090 | 美国 0.007455 系统 0.006072 | 美军0.006404 …… |
| Topic 3th: | 软件 0.009364 程序0.004344 | 函数 0.006048 过程 0.004271 | 系统0.005572 …… |
词向量与LDA结合的短文本建模方法具体实施步骤描述如下:
输入: ①小规模已标注的短文本训练数据集D°;
②大规模无标注数据集D上训练得到的词向量;
③大规模无标注数据集D上训练得到的LDA模型。
输出: 训练数据集D°的结合词向量与LDA的表示模型。
(1) 词向量合成
采用向量相加平均法得到D'的基于词向量合成的短文本表示模型, 如下所示。
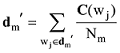
其中, dm'表示D'中第m篇短文本的基于词向量合成的短文本表示, wj为其中的词, Nm为词数, C(wj)为词wj的词向量。
(2) 基于LDA进行特征扩展
将D'中的每个词与LDA模型的主题-词分布矩阵Φ相匹配, 选择该词所属的概率最大的主题zmax; 然后将zmax匹配LDA模型的主题词文件, 选择主题zmax下的前r个词作为该词的扩展特征, 则D'基于LDA的特征扩展模型如下:
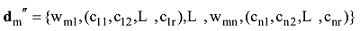
其中, dm''表示D'中第m篇短文本的基于LDA的特征扩展模型, wmn为这篇短文本中的第n个词, (cn1,cn2,L, cnr)为wmn的r个扩展特征。
(3) 基于词向量的扩展特征权重计算
公式(13)中, 采用基于词频及逆向文档频(Term Frequency-Inverse Document Frequency, TFIDF)的方法计算被扩展特征wmn的权重, TFIDF权重反映了特征词表征文本的能力[1], 公式如下。

其中, TF(wmn)表示wmn的归一化词频, IDF(wmn)表示zmax的逆向文档频, 分母部分是对TFIDF权重的归一化操作。
对于公式(13)中的扩展特征cnr, 其权重与两个因素有关: cnr所属的主题在文本中的重要性; cnr与其所属主题的相关度。由于cnr所属主题是由被扩展特征wmn根据概率最大原则匹配LDA的主题-词分布矩阵得到的, 因此认为wmn的TFIDF权重代表cnr所属的主题在文本中的重要性, cnr与wmn的语义相关度代表cnr与其所属主题的相关度。cnr与wmn的语义相关度通过计算cnr与wmn的词向量的余弦值得到, 记为sim(cnr,wmn), 如下:
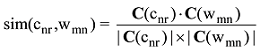
其中, C(cnr)与C(wmn)分别为cnr与wmn的词向量表示。
综上, 基于词向量的扩展特征权重计算方法如下:
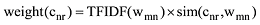
(4) 向量拼接
由于一个词可能含有多重语义, 因此对于步骤(2)中的特征扩展模型dm'', 可能会出现同一扩展特征多次出现的情况, 这时需合并相同的扩展特征, 并将其权重相加作为合并后的扩展特征的权重。最终, 将此特征扩展模型dm''与步骤(1)中的基于词向量合成的模型dm'进行顺序拼接, 得到词向量与LDA结合的短文本表示模型, 如下:
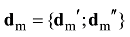
其中, “;”表示向量顺序拼接操作, dm为训练集D'中第m篇短文本的词向量与LDA结合的向量表示。
k近邻分类(k-NN)算法作为一个经典的机器学习算法, 应用于文本分类领域具有较高的稳定性, 其原理简单直接: 将新数据与训练数据集中的样本进行比较, 选择与新数据最相似的前k个样本的类标签作为新数据的候选类标签, 最后统计候选类标签中数量最多的类标签作为新数据的分类结果。
本文方法的最后一步通过构建一个k-NN分类器, 以建模后的短文本训练集与待分类短文本数据作为输入, 使用余弦相似度作为新数据与训练集样本的比较函数, 完成对新数据的分类并测试本文方法的分类效果。
采用复旦大学中文文本分类语料库作为大规模数据集用于训练词向量及LDA主题模型。选取1 000篇少于150字的短文本构建有类别标注的小规模训练数据集用于训练最近邻分类器, 数据集均衡分布于计算机、经济、环境、艺术、体育5个领域, 每个领域各200篇。另外选取670篇短文本作为测试数据集, 其中, 计算机类145篇, 经济类130篇, 环境类135篇, 艺术类120篇, 体育类140篇, 训练集和测试集之间彼此不重叠, 不包括重复文本。中文分词采用中国科学院计算技术研究所的NLPIR汉语分词系统。基于Word2Vec训练词向量, 依据实验经验设置词向量维数为50, 当维数设置超过50时实验结果无明显提升。基于吉布斯采样方法训练LDA主题模型, 依据GibbsLDA++手册设置参数[23], 隐含主题数K设置为100, 超参数取α=0.5、β=0.1, 主题词数设置为20。依据实验经验设置k-NN分类器的近邻数k, 一般不超过训练样本数的平方根, 取k=20。
分类结果用准确率(Precision, Pr)、召回率(Recall, Re)和调和平均值F1三个指标来衡量, 公式如下[1]。
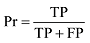
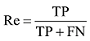
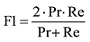
各参数含义如表3所示。
其中, 准确率考察的是分类结果的正确性, 召回率考察分类结果的完备性。
(1) 实验一
对CBOW模型进行修改, 在CBOW模型输入层采用向量拼接法代替向量相加平均法引入词序信息, 然后比较Word2Vec原版的CBOW与Skip-gram以及本文修改后的CBOW这三个模型训练的词向量应用于本文分类方法时所取得的分类效果, 比较结果如表4所示。
表4 词向量训练模型比较结果
| 词向量训练模型 | 准确率(%) | 召回率(%) | F1值(%) |
|---|---|---|---|
| Skip-gram | 77.0 | 81.5 | 79.2 |
| 原版CBOW(向量相加平均) | 81.1 | 83.7 | 82.4 |
| 修改后CBOW(向量拼接) | 81.8 | 82.6 | 82.2 |
从表4可以看出: 在短文本分类任务上, CBOW模型优于Skip-gram模型; 修改后的CBOW模型相比原CBOW模型仅在分类准确率上略有提升, 而召回率及F1值均略有下降, 因此认为修改后的CBOW模型相比原CBOW模型无明显差别。综上, 考虑到原CBOW模型计算复杂度低, 因此本文方法基于原CBOW模型训练词向量。
(2) 实验二
测试本文方法在短文本分类任务上的分类效果, 并与三种基于单一模型的分类方法(VSM+k-NN、词向量+k-NN、LDA+k-NN)进行比较, 结果如表5、表6所示。
表5 本文方法分类效果
| 类别 | 准确率(%) | 召回率(%) | F1值(%) |
|---|---|---|---|
| 计算机 | 85.3 | 87.1 | 86.2 |
| 经济 | 83.0 | 84.7 | 83.8 |
| 环境 | 79.3 | 84.2 | 81.7 |
| 艺术 | 78.3 | 80.6 | 79.4 |
| 体育 | 79.4 | 82.0 | 80.7 |
| 平均值 | 81.1 | 83.7 | 82.4 |
表6 不同分类方法比较结果
| 分类方法 | 准确率(%) | 召回率(%) | F1值(%) |
|---|---|---|---|
| VSM+k-NN | 74.7 | 77.2 | 75.9 |
| 词向量+k-NN | 77.4 | 79.6 | 78.5 |
| LDA+k-NN | 66.2 | 69.3 | 67.7 |
| 本文方法 (词向量+LDA+k-NN) | 81.1 | 83.7 | 82.4 |
表5显示本文分类方法在短文本数据集各个领域类别均能获得满意的分类效果, 是一种有效的短文本分类方法。表6显示, 前三种基于单一模型的分类方法中, 基于LDA模型的方法分类效果最差, 甚至低于传统的基于词袋模型的分类方法, 表明LDA模型并不适用于短文本分类; 与三种基于单一模型的分类方法相比, 本文方法在三个分类指标上均有提升, 其中分类准确率指标至少提升3.7%, 召回率至少提升4.1%, F1值至少提升3.9%。这是因为方法融合词向量与LDA主题模型对短文本进行建模, 能更精细地表示短文本语义信息, 因此有效克服了单一LDA模型主题聚焦性差的缺陷以及词袋模型的特征稀疏问题, 从而提高短文本分类效果。
本文提出一种同时从“词”粒度及“文本”粒度层面建模短文本的思路, 并由此提出了一个词向量与LDA相融合的短文本分类模型。另外, 该分类方法基于无标注数据集进行短文本建模, 属于一种半监督学习方法。实验部分比较了该方法与三种传统基于单一模型方法的分类效果, 此外还探讨了不同的词向量训练模型应用于本文方法时的优劣。后续将重点研究该分类方法应用于不同分类器的情况。
张群, 王红军: 提出研究思路, 设计研究方案;
张群: 进行实验, 采集、清洗和分析数据, 论文起草;
王红军, 王伦文: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据[1]由作者自存储, E-mail: 1875586718@qq.com; 支撑数据[2-4]见期刊网络版http://www.infotech.ac.cn。
[1] 张群. dataset.zip. 用于训练词向量与LDA主题模型的大规模数据集.
[2] 张群. word2vec.zip. 用于训练词向量的word2vec源码.
[3] 张群. GibbsLDA++.zip. 基于吉布斯采样的LDA主题模型程序包.
[4] 张群. LDA_result.zip. LDA主题模型训练结果文件.

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}