翟东升, 刘鹤 , 张杰, 蔡力伟
, 张杰, 蔡力伟
北京工业大学经济与管理学院 北京 100124
Zhai Dongsheng, Liu He, Zhang Jie, Cai Liwei
中图分类号: TP393 G353
通讯作者:
收稿日期: 2016-08-9
修回日期: 2016-09-27
网络出版日期: 2016-12-25
版权声明: 2016 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
展开
摘要
【目的】针对德温特专利数据设计并实现语义完整、性能良好的专利语义知识库。【应用背景】专利语义知识库用于存储专利数据以及各项数据之间存在的语义关系, 使得人们可以通过语义关系对专利进行检索。【方法】通过分析德温特专利数据所含及其之间的语义关系, 改进基于本体的专利语义表示方法, 提出基于属性图模型的德温特专利图数据模型, 并使用Neo4j图形数据库存储实例化的专利数据。【结果】以云计算技术为例, 构建专利语义知识库, 该知识库保证了语义信息完整, 在较大数据量的情况下, 查询速度可达到传统关系型数据库的5.35倍。【结论】基于图形数据库的专利语义知识库有着信息完整、语义清晰、性能良好等特点, 是一种稳定且高效的专利数据组织与存储方式。
关键词:
Abstract
[Objective]Design and implement a semantic knowledge management system for the Derwent patent data. [Context] The proposed system collects the patent data as well as the semantic relations among them. It could retrieve patent information with semantic relation. [Methods] First, we analyzed the Derwent patent data and the semantic relations among the data. Second, we modified the method of patent semantic representation based on Ontology. Third, we proposed a Derwent patent graph data model based on property graph model. Finally, we used the Neo4j graphic database to store the instantiated patent data. [Results] We built a semantic knowledge management system using cloud computing technology patents. The new system showed stronger semantic integrity and faster retrieval speed than traditional ones. [Conclusions] The proposed patent semantic knowledge management system offers stable and efficient solutions for organizing and storing patent data.
Keywords:
传统的专利数据信息存储采用关系型数据库, 其设计复杂、冗余度大且查询效率低, 无法直接获取专利信息中需要推理、挖掘的隐性语义信息。如果要从关系型数据库中获取结构较为复杂的专利信息, 需要将多个表进行连接查询, 使用者需要对表关系十分了解且查询效率较低。
图形数据库是一种特殊的NoSQL数据库。与其他类型的NoSQL数据库和传统的关系型数据库相比, 图形数据库更关注实体之间的联系, 它使用图的概念描述数据模型, 将数据保存为图中的节点以及节点之间的关系, 使得数据存储在一个面向对象的、灵活的网络结构中, 而不是关系复杂、静态的表格中。图形数据库是处理复杂的、半结构化的、紧密关联的数据的有效工具。
Neo4j作为基于原生图存储的开源图数据库, 支持ACID事务处理, 是当前最流行的图数据库之一[1]。Neo4j基于属性图模型将数据保存为图中的节点以及节点之间的关系。本研究基于对海量数据处理具有较高稳定性和效率的Neo4j图形数据库, 结合德温特专利索引数据库(Derwent Innovations Index, DII)的专利信息, 构建专利语义知识库。将专利中结构与半结构的信息, 根据其内容与语义关系, 设计图数据模型, 并存储在基于图形数据库的专利语义知识库中, 便于在未来研究中进一步对专利信息进行检索和利用。
专利知识表示是利用语义或文本表示技术, 从非结构化的专利文本中抽取出能体现专利信息的结构化知识, 构建结构化语义模型。使用本体表示的专利语义知识是当下较为主流的专利信息组织方式。
本体是共享的概念模型的形式化规范说明[2]。基于本体的专利知识表示优点在于拥有很强的语义表现能力, 可从多角度展现专利语义信息。Ghoula等[3]借助本体对专利进行标注, 提高标注的效率。Giereth等[4]构造了一个模块化的架构, 使用专利结构本体、专利分类本体、语言本体(WordNets)等多个本体表达专利信息。Taduri等[5]设计本体用以整合与专利信息相关的文档, 包括专利文档、诉讼案例和文档夹信息等, 克服不同领域文档之间的异构性, 提高信息检索效率。翟东升等[6]基于德温特专利数据库中的专利信息和其中所包涵的语义关系设计德温特专利本体, 并实现使用OWL语言描述的本体模型。基于本体的专利知识表示方法的优点是可以多角度地揭示专利语义信息, 语义完整, 缺点在于专利本体的构建过程较为复杂, 可能需要领域专家协助构建模型。
当前有多种本体知识库存储方式。基于纯文本进行存储, 采用OWL/XML等语言形式将本体信息写入本体文件中, 这种存储方式可以完整保存语义信息并拥有较好的可扩展性, 但当本体文件较大时, 会引发内存占用过多和访问效率低下等问题。基于内存进行存储, 将本体信息以一定结构直接存储在内存中, 这种方法优点是运行速度快、检索效率高, 但受限于计算机内存的大小, 不能存储较大的本体。基于关系型数据库的存储[7], 将本体按照一定的策略组织在数据库中, 该方法有较好的查询效率, 常在存储的数据量较大时使用, 这种存储方式的缺点在于存储时需将本体的网状模型转化为传统关系模型, 会造成本体语义信息的缺失。
也有研究开始使用图形数据库对本体进行存储。图形数据库适用于规模庞大、数据对象间的关系复杂的数据, 且有着非常良好的可扩展性[8], 这些特点使得图形数据库适用于存储本体信息。Elbattah等[9]论述了使用图形数据库存储和检索大规模本体信息的优越性, 并利用Neo4j进行测试。Lampoltshammer等[10]使用图形数据库替换传统的Protégé本体开发环境处理本体信息的分类任务, 并实验证明了在同等准确率下, 使用图形数据库可以节省大量时间成本。李佳南等[11]探索性地提出基于图形数据库的网状标注结果存储方案, 以降低知识库中的语义损失。王颖等[12]将Neo4j数据库作为RDF数据仓储, 构建本体知识库。张慧等[13]提出一种从本体到图形数据库存储的映射规则。专利是知识的重要载体, 但很少有研究涉及使用图形数据库存储专利语义信息。
本研究通过分析德温特专利信息, 改进基于本体的专利知识表示方法, 设计出专利属性图模型, 保证了专利语义信息的完整性, 并使用图形数据库Neo4j构建专利语义知识库, 提升专利信息的检索效率。
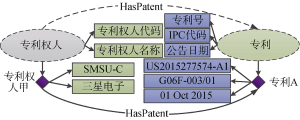
使用本体存储专利文本中的信息及其中所蕴含的语义关系是当下主流的专利信息组织方式。OWL(Web Ontology Language)[14-15]作为一种本体描述语言, 采用面向对象的方式描述领域知识, 即通过类和属性描述对象, 并通过公理描述类和属性的关系, 从而有效支持知识推理。图1为基于OWL的本体描述示例。
其中, 椭圆代表类, 本示例中包括“专利权人”和“专利”两个类; 类之间的虚箭头线表示对象属性, 例中为由专利权人类指向专利类的对象属性“HasPatent”; 矩形表示各类的数据属性, 例如专利类有“公告日期”、“专利号”和“IPC代码”等数据属性; 菱形代表各类的实例, 本示例中包含“专利权人甲”实例, 数据属性专利权人代码为“SMSU-C”; 对象属性的源域为专利权人类, 目标域为专利类, “专利权人甲”具有对象属性“HasPatent”指向实例“专利A”。
属性图是图形数据库中最流行的图数据模型[16]。属性图由节点、联系及属性构成。其中节点和联系含有属性, 用于存储对应节点或属性的信息, 属性以键值对的形式存在。联系用来连接节点, 需要有一个开始节点和一个结束节点。同时节点和联系可以使用标签标记, 用以缩小搜索范围。
因为属性图模型与本体知识库结构高度契合, 所以可将基于本体的专利知识表达方法改进为基于属性图的专利知识表示方法。具体地, 将本体知识库中“类”抽象为图数据库中“节点”, 将“类属性”抽象为“节点属性”, 将“类之间的语义关系”抽象为节点之间的“联系”, 并将部分类属性抽象为“联系属性”。例如图1中本体实例可以用如图2所示的图形数据存储。
其中, “专利权人”节点用于记录专利权人基本信息, 有“专利权人代码”、“专利权人名称”两个节点属性; “专利”节点用于记录专利的基本信息, 有“专利号”、“IPC”两个节点属性; “HasPatent”是一个“联系”, 它将“专利权人”节点和“专利”节点有向地连接起来, 并且该“联系”有“年”、“月”、“日”三个“联系属性”, 用来记录专利的公告日期。其数据结构变化较小, 在一定程度上避免了语义信息的缺失, 并且可以看出属性图模型有着直观、容易理解的特点。
本研究中, 使用Neo4j存储专利知识库。对于基于海量数据的本体知识库, 基于文本文件或关系型数据库的存储存在无可逾越的瓶颈, Neo4j图数据库因其内含高效图形算法, 在执行数据增删改查的遍历操作时, 性能远高于关系型数据库, 尤其是在进行大量数据处理时, Neo4j具有较高的稳定性和效能。Neo4j提供类似SQL Server企业管理器的HTTP端点, 可进行简单事务性Cypher语言查询, 并以可视化的方式输出结果, 如图3所示。同时Neo4j也提供了多种编程语言下的API接口, 如Java、Python、.Net等, 可进行嵌入式开发。
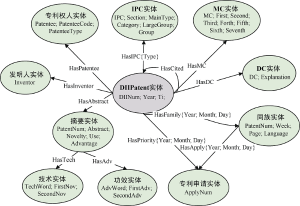
为了尽可能保存专利语义信息, 并且使得专利数据符合图形数据库对数据的要求, 需要对专利数据进行图建模。根据属性图模型的要求, 专利知识库中用于描述专利的数据, 分为用于记录专利中实体的节点和记录实体之间语义关系的联系。通过对德温特专利信息进行观察, 并结合本地德温特专利数据库所涉及专利信息, 总结出表1中的节点及其属性。
表1 节点及其属性设计
| 节点名 | 释义 | 节点属性 |
|---|---|---|
| DII Patent | 德温特专利标识 | TI(标题); Year(公开年份); DIINum(德温特入藏号) |
| Abstract | 摘要 | Nov(新颖性); Use(应用); Adv(功效) |
| Patent Family | 同族专利 | PatentNum(同族专利号); Week(周次); Page(页数); Language(语言) |
| Patent Apply | 专利申请 | ApplyNum(专利申请号) |
| Priority Detail | 专利优先权 | ApplyNum(专利申请号) |
| IPC | 专利IPC | Section(部); MainType(大类); Category(小类); LargeGroup(大组); Group(小组) |
| MC | 专利MC | First(一级部); Second(二级部); Third(三级部); Forth(四级部); Fifth(五级部); Sixth(六级部); Seventh(七级部) |
| DC | 专利MC | Explanation(解释) |
| Patentee | 专利权人 | PatenteeCode(专利权人代码); PatenteeType(类型) |
| Inventor | 发明人 | Inventor(发明人) |
| Nov | 技术 | FirstTech(一级技术); SecondTech(二级技术); TechWord(技术词) |
| Adv | 功效 | FirstAdv(一级功效); SecondAdv(二级功效); AdvWord(功效词) |
通过对专利信息的分析、理解, 总结出以下联系及其属性, 在属性图模型中的联系是有向的, 所以还需要标明该联系的开始节点和结束节点, 如表2所示。
表2 对象属性设计
| 联系名 | 开始节点 | 结束节点 | 联系属性 |
|---|---|---|---|
| HasFamily | 德温特专利标识 | 同族专利 | PublicDate(公开日期) |
| HasAbstract | 德温特专利标识 | 摘要 | 无 |
| HasTech | 摘要 | 专利技术特征 | 无 |
| HasAdv | 摘要 | 专利功效特征 | 无 |
| HasDC | 德温特专利标识 | 德温特分类代码 | 无 |
| HasIPC | 德温特专利标识 | 专利IPC | IPCType(IPC类型) |
| HasMC | 德温特专利标识 | 德温特手工代码 | 无 |
| HasCited | 德温特专利标识 | 德温特专利标识 | 无 |
| HasInventor | 德温特专利标识 | 发明人 | 无 |
| HasPatentee | 德温特专利标识 | 专利权人 | 无 |
| HasApply | 德温特专利标识 | 专利申请详情 | ApplyDate(申请日期) |
| HasPriority | 专利申请号 | 专利优先权 | PriorityDate(优先权日期) |
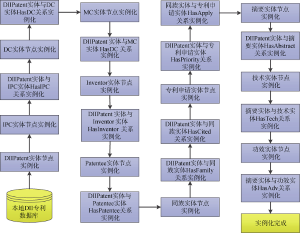
将上述节点及其之间的联系和属性结合起来, 设计出表示德温特专利语义的图数据模型, 如图4所示, 其中椭圆代表节点, 节点中拥有节点名及其属性, 黑色箭头代表联系, 联系名后的大括号中是联系的属性。通过该图数据模型, 专利的语义信息将很大程度上得以保留, 并且使专利中非结构化信息及半结构化信息在图形数据库中实现结构化及易用。同时, 该模型强调了节点之间的联系, 结合Neo4j图形数据库本身具有高效的存取效能以及其“节点-联系”的逻辑存储结构, 可以良好支持专利语义知识库在遍历、查询以及推理中的实际应用。
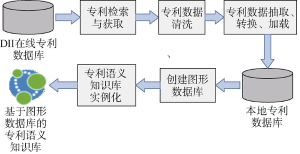
专利语义知识库构建的整体流程如图5所示:
关于专利数据的预处理及信息抽取的过程已有较多且成熟的研究[17-18]。创建图形数据库的方式有利用Http端点创建和使用代码创建, 使用Java创建图形数据库实例的关键语句如下, DB_PATH为数据库文件的路径。
GraphDatabaseService db = new GraphDatabaseFactory().
newEmbeddedDatabase(DB_PATH)
本文主要介绍专利语义知识库实例化的过程, 其具体流程如图6所示。
数据准备→DIIPatent实体节点实例化→IPC实体节点实例化→HasIPC关系实例化→DC实体节点实例化→HasDC关系实例化→MC实体节点实例化→HasMC关系实例化→Inventor 实体节点实例化→HasInventor关系实例化→Patentee实体节点实例化→HasPatentee关系实例化→同族实体节点实例化→HasFamily关系实例化→HasCited关系实例化→专利申请实体实例化→HasPriority关系实例化→HasApply关系实例化→摘要实体实例化→HasAbstract关系实例化→技术实体实例化→HasTech关系实例化→功效实体实例化→HasAdv关系实例化。
上述步骤需顺序进行, 尤其在实例化两节点之间的联系之前, 需要确保完成两节点的实例化。以专利权人为例, 介绍Patentee节点实例化, Patentee节点与DIIPatent节点之间HasPatentee联系实例化的具体实现算法。
(1) 专利权人实例化
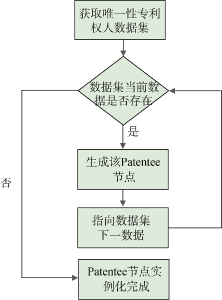
从本地德温特专利数据库(DII), 读取预处理完成后的专利权人数据, 将其写入Neo4j图形数据库, 主要分为两个步骤: 创建与该图形数据库的连接; 从本地DII专利数据库读取唯一性专利权人数据, 通过Java中的ResultSet.HasNext循环, 将专利权人数据写入图形数据库, 创建专利权人节点, 并进行保存。具体算法流程如图7所示。
该流程的关键步骤为生成Patentee节点, 其核心代码如下:
① Transaction tx = db.beginTx();
② String queryString = "MERGE (n:DIIPatentee {Patentee: {Patentee},
③ PatenteeCode: {PatenteeCode}, Type:{Type}}) RETURN n";
④ Map<String, Object> parameters = new HashMap<String, Object>();
⑤ parameters.put( "Patentee", Patentee );
⑥ parameters.put( "PatenteeCode", PatenteeCode );
⑦ parameters.put( "Type", Type );
⑧ db.execute(queryString, parameters);
⑨ tx.success();
⑩ tx.close();
第①行代码创建了一个图形数据库事务, db为创建的数据库实例; 第②-③行为将要执行的Cypher语句; 第④行创建了一个哈希表parameters, 用以保存专利权人节点的节点名和属性数据; 第⑤-⑦行分别将专利权人名、专利权人代码、专利权人类型加入到parameters中; 第⑧行为执行结合parameters的Cypher语句; 第⑨-⑩行是提交事务和关闭事务。
(2) HasPatentee联系实例化
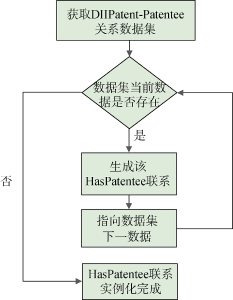
与节点的实例化类似, 联系的实例化同样是从本地DII专利数据库, 通过表连接查询获取联系数据, 插入到图形数据库中, 完成实例化。与节点的实例化不同的是需要确保联系所涉及的节点已经存在于图形数据库中, 否则该联系的实例化会发生错误, 这可以在数据预处理部分完成。在HasPatentee联系的实例化过程中, 首先查询出DIIPatent实体与Patentee实体之间关系的数据, 然后通过Java中的ResultSet.next()循环, 将数据写入图形数据库, 创建HasPatentee联系, 并进行保存。具体算法流程如图8所示。
该流程的关键步骤为生成Patentee节点, 其核心代码如下:
① Transaction tx = db.beginTx();
② String queryString = "MATCH (a:DIIPatent{DIINum:
{DIINum}}),
③ (b:DIIPatentee {Patentee: {Patentee}}) MERGE
(a)-[:HasPatentee]->(b)";
④ Map<String, Object> parameters = new HashMap<String,
Object>();
⑤ parameters.put( "DIINum", DIIPatentNum );
⑥ parameters.put( "Patentee", Patentee);
⑦ db.execute( queryString, parameters );
⑧ tx.success();
⑨ tx.close();
实现过程与节点的实例化相似, 不再具体解释, 不过需要注意到第②-③行的Cypher语句中需要光找到该联系所连接的两个节点, 再执行联系的实例化。
以上专利权人数据预处理、专利权人实体实例化以及专利实体与专利权人实体之间HasPatentee关系实例化算法, 是基于Neo4j图形数据库的本体语义知识库实例化中的一个简单子程序。其他字段实例化算法与该处举例算法类似, 只需根据各字段实际情况进行相关调整。
构建专利语义知识库的目的, 是以一种基于图的信息组织形式, 存储专利信息及其中所蕴含的语义关系, 便于研究人员快捷地对专利中语义信息进行挖掘和应用, 获取专利情报信息。将本体存入Neo4j图形数据库, 是以属性图的方式存储本体中的信息及其语义关系。图形数据库侧重于全局查询, 其对大规模信息的快速扫描及批处理特性, 使得可以方便快捷地挖掘专利信息中语义信息进行应用。
Cypher图数据库查询语言, 以程序化描述图的方式, 实现在图形数据中对专利的语义查询。Cypher查询语言中, 节点使用小括号表示, 例如“(CitingMC: DIIMC)”, 其中“:”前是节点名, “:”后是节点的属性; 联系使用中括号表示, 例如“[:HasMC]”, “:”后面是联系名, 使用“-[]->”的方式表明联系的方向。MATCH为实例化需求, 用字符画表示节点和联系, 寻找匹配模式; WHERE添加过滤模式匹配结果的条件; RETURN用来指明在匹配查询的数据中, 返回哪些节点、联系或属性。例如, 实现基于图形数据库的专利语义知识库中专利族之间引用关系对应的MC引用, 可以通过如下的Cypher语言进行图形数据库查询:
MATCH (CitingMC:DIIMC) <-[:HasMC]- (CitingPatent:
DIIPatent) -[:HasCited] -> (:PatentFamily) <-[:HasFamily]-
(CitedPatent:DIIPatent) -[:HasMC]-> (CitedMC:DIIMC)
WHERE CitedPatent.DIINum <> CitingPatent.DIINum
RETURN DISTINCT CitingMC.MC, CitedMC.MC
该Cypher语句中, 使用MATCH语句确定同一专利族中的施引专利的MC和被引专利MC之间应该具有的模式关系, WHERE语句限定了施引专利与被引专利拥有不同的DII入藏号, RETURN语句表明返回的是施引专利的MC和被引专利的MC, 即CitingMC. MC和CitingMC.MC, 且使用了DISTINCT确保返回的结果没有重复。
专利信息数据源采用DII专利创新数据库, 检索表达式基于文献[19], 采用“TS=((cloud comput*) OR (cloud storage*) OR (cloud infrastructure*) OR (private cloud) OR (public cloud) OR Iaas OR PaaS OR SaaS) NOT (IP=A*) NOT (IP = F*) NOT (IP = G01*)”检索表达式, 共检索到15 684条德温特专利, 时间跨度为1967年1月1日-2015年10月21日。
本实例中硬件及软件配置如表3所示。
表3 硬件、软件配置信息
| 硬件 | 配置 | 软件 | 配置 | |
|---|---|---|---|---|
| CPU | Intel i7-2640M | 操作系统 | Windows7 64位 | |
| 内存 | 8GB | Neo4j | Neo4j 2.2.3社区版 | |
| 硬盘 | 320GB 7200转 | MySQL | MySQL 5.7 | |
| JDK | JDK 1.8.0_65 |
使用原型系统中本体语义知识库构建系统, 完成云计算专利语义知识库的构建, 即完成云计算领域原始数据的数据清洗、专利特征抽取结果导入、实体节点实例化、实体关系实例化以及基于图形数据库Neo4j的专利知识库存储。在构建的基于图形数据库的专利知识库中, 包含各概念类实体共计12万余个, 各实体间语义联系31余万组, 专利知识库实例化准确率接近100%, 整体构建时间为97分钟45秒。其中各实体详细数量如表4所示。
表4 各实体数量
| 实体名 | 数量 |
|---|---|
| DIIPatent实体 | 15 684 |
| IPC实体 | 2 891 |
| MC实体 | 2 089 |
| DC实体 | 200 |
| 同族实体 | 27 935 |
| 专利申请实体 | 27 796 |
| 专利权人实体 | 5 852 |
| 发明人实体 | 21 212 |
| 摘要实体 | 15 684 |
| 技术实体 | 543 |
| 功效实体 | 623 |
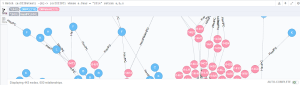
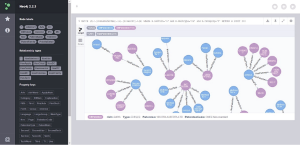
在完成云计算专利语义知识库后, 可以使用Neo4j提供的基于Web的执行界面对数据进行探索。如图9所示, 在该界面左侧, 显示了云计算专利语义知识库中全部的节点类型、联系类型和全部的属性; 该界面的右侧是主界面, 可以编写Cypher查询语言, 并且结果会以可视化的方式显示出来。图8中查询显示的是拥有IPC小类为“G06F”的专利及其对应的专利权人。
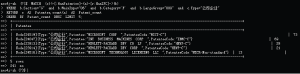
在数据量较大的时候, 可视化的显示方式会花费较多计算资源, 影响查询效率, 可以使用Neo4j提供的命令行进行查询。如图10所示, Neo4j提供的命令行界面同样基于Web, 输入正确的查询语句后, 便会返回结果及结果数量、查询时间, 图中查询的是专利IPC大组是“G06F009”的, 专利数量前5的专利权人。
为了明确基于图形数据库的专利语义知识库的性能情况, 利用基于关系型数据库的专利知识库进行比较, 该专利知识库使用的是MySQL数据库, 且在各关键字上都建立了B-Tree索引以提高查询效率。比较的过程是通过以下4个查询:
(1) 查询拥有特定IPC专利的专利权人;
(2) 查询各专利权人的专利涉及的IPC数量;
(3) 查询IPC间的引用关系;
(4) 查询2015年的所有专利的标题。
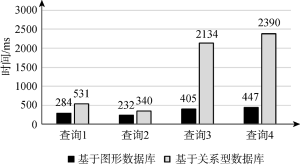
比较过程中, 使用两种数据库分别提供的命令行工具进行查询, 并且以命令行工具返回的查询耗时作为评价专利知识库的主要性能指标, 最终的对比查询结果如图11所示。
根据实验结果, 基于图形数据库的专利语义知识库在查询速度上有着明显的优势, 4个查询的所用时间均小于基于关系型数据库的专利语义知识库。尤其是查询3和查询4, 基于图形数据库的专利语义知识库的查询速度分别是传统关系型数据库的5.27倍和5.35倍。
本文介绍了在图形数据库上构建专利语义知识库的方法。在数据模型的设计上, 改进了基于本体的专利语义表示方法, 结合德温特专利数据, 利用属性图表示专利语义知识, 该数据模型保证了专利语义信息的完整性, 同时还有直观、易理解的优点。在知识库的实现上, 使用Neo4j图形数据库, 设计专利语义知识库的实例化流程, 并以专利权人节点和HasPatentee联系为例, 具体地描述了节点与联系的实例化算法。在专利语义知识库的使用上, 简要介绍了图形数据库查询语言Cypher, 并以云计算专利语义知识库为例, 证明了相对于传统关系型数据库, 基于图形数据库的专利语义知识库在查询性能上的优势。
翟东升, 刘鹤: 提出研究思路, 设计研究方案;
刘鹤, 蔡力伟: 进行实验, 构建知识库, 采集、处理和分析数据;
翟东升, 刘鹤, 张杰: 论文起草;
刘鹤: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据见期刊网络版http://www.infotech.ac.cn。
[1] 刘鹤, 蔡力伟. 云计算专利数据.csv. 从德温特数据库上获取的云计算技术专利.
[2] 刘鹤. 性能测试记录.xlsx. 记录两种专利语义知识库运行查询任务的时间.

/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}