毕强
Bi Qiang
中图分类号: G250.7
通讯作者:
收稿日期: 2016-09-12
修回日期: 2016-10-24
网络出版日期: 2016-12-25
版权声明: 2016 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】为解决传统的文本聚类无法充分挖掘文本资源语义信息以及相似度矩阵高维性、稀疏性等问题, 并进一步改善文本聚类质量, 提出基于语义相似度的文本聚类方法。【方法】通过《同义词词林扩展版》计算词语的语义相似度并得到文本语义相似度矩阵, 根据文本语义相似度矩阵进行谱聚类, 将文本聚集为文本簇。【结果】利用复旦大学文本语料库与搜狗文本语料库中的文本资源作为数据来源分别对传统聚类算法与本文提出的算法进行实验, 结果表明, 当聚类个数为10时, 本文算法的准确率最高, 并且Purity值高于传统聚类算法的Purity值。【局限】《同义词词林扩展版》中包含的领域术语不完整, 部分相似度计算结果需要手工进行调整。【结论】该方法考虑了词语间语义关系, 充分挖掘文本主体潜在信息, 并且改善了聚类质量, 为文本聚类和推荐提供了一条新途径。
关键词:
Abstract
[Objective]This paper proposes an algorithm based on semantic similarity to extract more information from the textual resources. [Methods] First, we calculated the semantic similarity of words with the Extended Dictionary of Synonyms, and then created a semantic similarity matrix. Second, we clustered the texts based on the new semantic similarity matrix. [Results] The proposed algorithm was examined with text corpus from Fudan University and the search engine Sogou. Compared to the traditional methods, the proposed algorithm achieved the highest precision rates and purity values (cluster number=10). [Limitations] Some partial similarity calculation results were manually adjusted due to the incomplete coverage of the Tongyici Cilin Extened Edition. [Conclusions] The proposed algorithm could extract more latent information from the texts, which is an effective method to cluster and recommend textual documents.
Keywords:
Web2.0时代, 文本数据呈现爆炸式增长[1]。文本聚类作为一种无监督的机器学习方法, 可以对文本信息进行有效的组织、分类和导航[2], 从而保证用户对知识进行有效、便捷的获取。然而, 文本聚类过程中, 采用向量空间模型计算文本间相似度的方法受共现特征词影响较大[3], 易造成描述概念信号弱、噪音数据多及特征矩阵稀疏等问题[4]; 基于领域本体计算概念相似度的方法需要人工或半人工构建本体, 构建过程复杂, 借助领域专家和知识工作人员协作完成, 并且本体结构中包含信息较为复杂, 不能充分体现和揭示概念之间的语义关系, 相似度计算结果精度不高[5]。另外, 在文本聚类中也存在着对初始聚类中心选值的敏感性问题、容易陷入局部最优值等问题[6], 影响了文本聚类效果。
《同义词词林扩展版》编码简单, 层次结构清晰, 具有丰富的语义知识并且可以解决中文文本多义词分歧的问题[7], 因此本文利用同义词词林扩展的语义相似度计算方法改进谱聚类算法: 通过同义词词林计算语义相似度并形成语义相似度矩阵, 对语义相似度矩阵进行拉普拉斯变换以降低矩阵维度, 将变换后的向量矩阵进行聚类, 从而完成对语义相近文本簇的划分, 以此提高文本聚类效果。
概念语义相似度是指两个概念间的相似程度[8], 已经被应用于词义消歧[9]、自动检索[10]、图像分类及标注[11]、信息抽取[12]、信息检索[13]等领域。目前, 语义相似度计算方法主要包括基于本体的概念语义相似度计算与基于语义词典的概念相似度计算。基于本体的语义相似度计算按照计算方法的不同可分为: 基于距离的方法、基于内容的方法和基于属性的方法等。基于距离的计算方法是在层次网络中使用路径长度来量化两个概念之间的语义距离[14]。基于属性的方法[15]是利用事物之间不同的属性特征区别事物。两个事物的公共属性越多, 相似度越高。基于内容的方法[16]认为两个概念共享的信息会影响二者的语义相似度。然而由于本体结构中包含信息较为复杂, 不能充分体现和揭示概念之间的语义关系, 导致相似度计算的精度不高。另一方面, 利用语义词典WordNet FrameNet、MindNet等来计算英文词语相似度, 以及利用《知网》(HowNet)、同义词词林等计算中文相似度[17], 也是较为常用的方法。基于语义词典的方法通常依赖于比较完备的大型语义词典。词典中的关系和层次结构, 如概念之间的上下位关系和同位关系可以用来计算词语的相似度。由于基于同义词词林比基于《知网》的词汇语义相似度计算方法更符合人们的理解[18], 因此本文利用其作为计算语义相似度的方法。
文本聚类分析是利用文本之间的相似性对无结构或半结构化的文本对象进行自动分组的过程[19]。同组内文本相似性较高, 不同组的文本相似性较低。通常将文本表示成向量的模式, 利用特征词来计算各文本之间的相似度。常用的文本聚类分析的方法包括K-means聚类[20]、层次聚类[21]、基于密度的聚类[22]以及基于网格的聚类[23]等。文本聚类的过程包括提取文本特征词、计算文本相似度以及文本聚类算法等方面。文本聚类技术在文档整理、组织以及信息检索中得到广泛应用, 例如对网页自动归类、新闻报道自动分类、电子邮件分组等, 还可以对搜索引擎返回的结果进行聚类, 使用户迅速查询到所需要的信息。
传统的聚类算法都是建立在凸球形的样本空间上。当样本空间不为凸时, 算法会陷入“局部”最优。另外, 许多文档之间没有公共词语存在, 导致文档矩阵具有高维性和稀疏性, 而且聚簇中心也没有提供可以理解的聚簇描述。为了能在任意形状的样本空间上聚类, 收敛于全局最优解, 克服文档矩阵的高维性和稀疏性等缺点, 相关学者开始利用谱方法来聚类。谱聚类方法建立在谱图理论的基础上, 通过计算数据相似关系建立相似度矩阵, 以该矩阵的前k个特征向量来对不同的数据点聚类。与其他聚类方法不同, 谱聚类不容易陷入局部最优解, 而且可以有效识别非凸分布的聚类, 已经成功应用于在线学习分类[24]、图像分割[25]、词义消歧[26]、网页划分[27]和文本挖掘[28]等领域。因此, 本文选用谱聚类作为文档聚类的分析方法。
文本聚类过程中首先要对文本文档数据进行预处理, 完成从文本形式到数学表示的转换。常见的文本表示方法采用向量空间模型, 利用单词或词语共现次数表征文档内容, 忽略了文档资源之间存在的语义关联。基于距离的相异度可以用来度量文档对象之间相似度, 例如余弦距离、欧几里德距离、曼哈坦距离等。但由于文档之间的特征词交集过少导致文档向量矩阵的高维性和稀疏性, 距离度量往往不能准确有效地表达文档之间潜在的语义关联信息。因此, 在文本聚类过程中应充分挖掘隐藏在文档中的语义信息, 寻找文本对象之间特有的语义关联。本文利用改进的语义相似度矩阵代替空间向量模型, 并利用谱聚类方法对相似度矩阵进行分解, 从而降低矩阵的高维度, 提高聚类结果的准确性。
文献[18]根据同义词词林结构及其编排的特点, 利用词语在词林树状结构中的编号, 提出基于同义词词林的概念语义相似度计算方法。本文参考文献[18]的计算方法计算概念的语义相似度。具体描述如下: 首先判断两个概念在同义词林中不同编号的起始位置, 例如: Aa01A01与 Aa01B01, 在第四层不同。对于不同的层, 分别乘以不同的系数。同义词词林的结构深度共五层, 从第二层开始, 对于不同层的词语分别乘以不同的参数a、b、c、d。然后再乘以调节参数 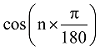
概念所在词林位置的密度会影响概念语义的相似度计算: 密度越大, 概念语义相似度的值越精确; 相反, 密度越小, 概念语义相似度值误差越大。一般的计算方式是统计两个概念在词典间隔单词的数量, 即计算词林中公共祖先的数量来计算概念语义相似度, 这种方法并没有考虑概念所在分支的密度信息。通过统计两个概念c1, c2在同义词词林中分支间的距离, 即统计这两个概念所在分支包含的概念数量来计算密度信息[29], 密度信息公式如下。
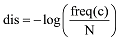
其中, freq(c)= ∑count(c), c为从概念c1所在分支到概念c2所在分支之间所包含的概念, ∑count(c)为这些概念数量的总合, N为c1和c2所在分支的所有概念的总和。利用公式(1)对计算的语义相似度结果进行细化, 以此保证计算结果更加精确。由以上得出概念的语义相似度公式, 用Sim表示。
若两个概念不在同一棵树上:
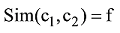
若两个概念在同一棵树上, 并且位于在第二层分支, 则系数为a, 计算公式如下:
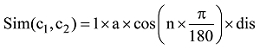
若两个概念在同一棵树上, 并且位于第三层分支, 则系数为b, 计算公式如下:
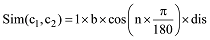
若两个概念在同一棵树上, 并且位于第四层分支, 则系数为c, 计算公式如下:
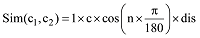
若两个概念在同一棵树上, 并且位于第五层分支, 则系数为d, 计算公式如下:
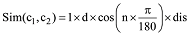
当编号相同且末尾号为“=”时, 相似度为 1; 当编号相同而只有末尾号为“#”时, 直接将定义的系数e赋给结果。即: Sim(c1,c2)=e。通过对概念相似度测试及根据文献[18]的参考, 本文将层数初始值设置为a = 0.532, b = 0.78, c = 0.84, d = 0.88, e = 0.42, f = 0.001。
文本相似度是指文本间主题或内容的相似程度, 与Quillian的联合概念相似, 可以通过计算文本特征词或概念的相似度计算文本相似度[30]。当计算文本的语义相似度时, 首先要计算文本的语义距离, 如公式(7)[30]所示。
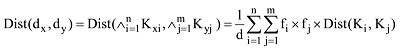
其中, dx, dy为两个不同文本, xi, yj分别为文本dx, dy所包含的特征词或概念; fi为概念xi在文本dx中出现的次数; fj为概念yj在文本dy中出现的次数; n, m分别为两个文本所包含的概念个数。为了避免语义距离的计算结果过大, 利用d进行归一化, 公式如下[30]。
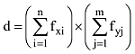
d所代表的意义为两个文本中概念或者特征词语义距离的数量, 同时也考虑到特征词或概念在文本中出现的次数, 对语义距离进行归一化可以避免文本包含的特征词或概念过多, 导致文本语义距离过大。综上, 本文将文本语义相似度定义如下[30]。
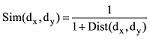
可以看出, 语义距离越大, 文本的相似度越小。
基于NJW算法[31], 本文提出基于语义相似度矩阵的谱聚类算法(SCBSS)。SCBSS算法采用概念列表表示文本, 以文本间的语义相似度作为文本间相关程度的度量。相似度矩阵是一个对称矩阵, 而且相似度值是非零的。在进行文本预处理的基础上, 以中文词语为单位, 利用《同义词词林扩展版》计算词语之间的语义相似度, 将其作为衡量概念距离的指标。其次, 将文本表示成概念的集合, 两个文本的相似度可以通过它们包含概念的语义相似度计算。最后, 构建文本间相似度矩阵, 并应用文本谱聚类方法进行分析。改进 SCBSS算法的描述如下:
输入: n个数据点, 聚类的个数K
输出: K个聚类
方法:
Begin
①构造相似性矩阵W∈Rn×n;
②构造矩阵P=D-1/2WD1/2;
③求P的k个最大特征值所对应的特征向量v1, v2, …, vn,构造
矩阵V=[v1v2L vn]∈Rn×k, 其中vi为列向量, i=1, …, n;
④规范化V的行向量, 得到矩阵Y, 其中 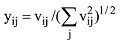
⑤将Y的每一行看成是Rk空间中的一点, 使用K-means聚类。
End
如上所示, 谱聚类将文档的相似度放到一个带权无向图中, 采用“图划分”的方法进行聚类。谱聚类算法分为三步:
(1) 构造一个n×n的权值矩阵W, 利用同义词词林计算词语的相似度wij。wij表示词语i和词语j的相似度, 显然W是对称矩阵。
(2) 构造一个对角矩阵D, dii为W第i列元素之和。对矩阵P进行规范化, 即P=D-1/2WD1/2。可以证明P是个半正定和对称矩阵, 求得P的前n大特征值所对应的特征向量。
(3) 将n个特征向量放在一起构造一个n×k的矩阵V, 将V的每一行当成一个新的样本点, 对新的样本点进行K-means聚类。传统的聚类方法要求数据必须是N维欧氏空间中的向量, 而利用谱方法聚类只需要计算文本的相似度矩阵, 这降低了数据矩阵的维度, 并且缓解了数据矩阵的稀疏性。
选取10组概念进行语义相似度计算, 为了对比实验效果, 采用咨询的方式获得人工对于语义相似度的判断。咨询对象包括计算机专业、情报专业、经济专业的硕士生和博士生, 共有20人。通过对该组概念语义评价问题进行语义相似度判定。语义相似度的评判范围是[0, 1], 0表示两个概念完全不同, 1表示两个概念语义相同。对受测者各进行两次实验, 并对同一概念语义相似度的评测结果取平均值。计算结果如表1所示。
表1 概念语义相似度部分计算结果
| 词语 | 语义相似度 | 相似度范围 | |
|---|---|---|---|
| 经济 | 产业 | 0.693 | 0.7-0.8 |
| 货币 | 银行 | 0.540 | 0.6-0.7 |
| 企业 | 公司 | 1.000 | 0.9-1.0 |
| 资源 | 工业 | 0.362 | 0.3-0.4 |
| 软件 | 计算机 | 0.717 | 0.7-0.8 |
| 服务器 | 路由器 | 0.500 | 0.5-0.6 |
| 历史 | 二战 | 0.431 | 0.4-0.5 |
| 地理 | 地理学 | 1.000 | 0.9-1.0 |
| 电路 | 电子 | 0.832 | 0.8-0.9 |
| 设备 | 产品 | 0.727 | 0.7-0.8 |
该方法根据概念在同义词词林的位置进行编码, 计算得出概念相似度。从表1可以看出, 利用同义词词林进行语义相似度计算结果具有较高的准确性, 并且符合目标用户对于语义相似度的主观判断, 说明该算法可以客观准确地反映概念之间的语义关系, 并为有效度量概念的语义相似度提供一种新的方法和途径。
搜狗文本挖掘数据集是比较全面的语料库, 该数据集包含汽车、财经、IT、健康、体育、旅游、教育、招聘、文化、军事等10个类别, 每个类别大约有2 000篇文档。本文从这10个类别中各选择100篇文档共计1 000篇, 利用 NLPIR大数据搜索与挖掘共享平台①(①http://ictclas.nlpir.org/nlpir/.)对其进行分词处理和词频统计。从中选出10个词频较高并能代表文档内容的关键词, 将其作为表征文档特征的关键词, 并记录其词频, 如图1所示。
利用Java语言对公式(7)-公式(9)进行编程计算语义相似度及文本相似度。部分计算结果如图2所示。
得到文本相似度矩阵后, 利用谱聚类方法对文档矩阵进行聚类划分。本文聚类结果的衡量指标选用聚类结果的纯度(Purity)进行分析, 此方法是一种简单有效的聚类结果的评价指标, 计算公式如下。
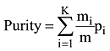
其中, 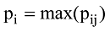
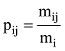
表2 K=4时聚类结果
| 类别 | C1 | C2 | C3 | C4 |
|---|---|---|---|---|
| 汽车 | 82 | 4 | 5 | 9 |
| 财经 | 10 | 64 | 12 | 14 |
| IT | 40 | 17 | 24 | 19 |
| 健康 | 19 | 17 | 33 | 31 |
| 体育 | 37 | 15 | 10 | 38 |
| 旅游 | 23 | 35 | 18 | 24 |
| 教育 | 8 | 3 | 84 | 5 |
| 招聘 | 46 | 39 | 9 | 7 |
| 文化 | 2 | 13 | 8 | 77 |
| 军事 | 28 | 24 | 30 | 28 |
由表2所示, 通过算法聚类后, 得到Purity=0.307。当 K=10 时, 聚类的结果如表3 所示。
表3 K=10时聚类结果
| 类别 | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 汽车 | 67 | 8 | 4 | 3 | 0 | 2 | 2 | 6 | 1 | 7 |
| 财经 | 2 | 73 | 5 | 3 | 3 | 4 | 1 | 2 | 5 | 2 |
| IT | 5 | 4 | 69 | 2 | 3 | 8 | 1 | 3 | 2 | 3 |
| 健康 | 7 | 4 | 3 | 57 | 10 | 4 | 2 | 5 | 3 | 5 |
| 体育 | 0 | 2 | 2 | 0 | 92 | 1 | 1 | 0 | 2 | 0 |
| 旅游 | 1 | 4 | 2 | 1 | 6 | 78 | 3 | 1 | 2 | 2 |
| 教育 | 2 | 6 | 1 | 9 | 2 | 1 | 62 | 5 | 6 | 4 |
| 招聘 | 3 | 3 | 3 | 1 | 2 | 1 | 1 | 84 | 1 | 1 |
| 文化 | 2 | 4 | 5 | 5 | 8 | 7 | 11 | 4 | 55 | 9 |
| 军事 | 1 | 2 | 1 | 1 | 2 | 2 | 1 | 1 | 1 | 88 |
可以看出, 聚类个数K=10时Purity= 0.725。这说明随着聚类个数的增多, 聚类的结果越来越准确。
选取K-means、TCUSS[16]以及本文提出的SCBSS三种方法进行实验, 并将聚类个数设置为4、5、6、7、8、10, 对于不同的聚类数量各重复实验10次, 然后取Purity值的平均数集C(P)= ∑f/10, 计算结果如表4所示。
表4 三种聚类算法的 Purity 值对比
| 聚类数量 | K-means | TCUSS | SCBSS |
|---|---|---|---|
| 4 | 0.296 | 0.303 | 0.307 |
| 5 | 0.272 | 0.411 | 0.439 |
| 6 | 0.371 | 0.506 | 0.565 |
| 7 | 0.433 | 0.517 | 0.688 |
| 8 | 0.466 | 0.513 | 0.706 |
| 10 | 0.483 | 0.504 | 0.725 |
如表4所示, SCBSS算法为本文的算法, TCUSS、K-means为人工方式构建。结果表明, SCBSS算法的纯度有明显提高。并且当聚类数量较少时, 算法的Purity值并不高, 但是随着聚类数量的增多, Purity值有显著提升。由于 SCBSS算法采用概念列表示文本, 并基于《同义词词林》语义相似度计算方法对文本进行相似度计算, 解决了基于向量空间模型的文本聚类算法中数据维数过高和相似度矩阵稀疏等问题, 也解决了文本中包含的近义词和多义词问题, 从而提高了聚类的效果和质量。但是, 在对表征本文关键词的选取过程中由于个人主观因素的差异导致关键词选取不准确, 聚类结果的精确度计算出现偏差; 另外, 《同义词词林扩展版》作为一种语义资源, 存在未登录词的问题, 互联网语料库中很多新词需要人工标示其相似度, 由此也会影响聚类结果。以上问题也是今后研究的重点。
本文提出基于语义相似度的文本聚类方法SCBSS。首先, 对文本进行预处理, 提取出文本的特征词, 利用《同义词词林扩展版》进行词语间的语义相似度计算, 以此作为计算文本间相似度的依据, 并构造文本相似度矩阵。其次, 对相似度矩阵进行规范化, 求得最大特征值以及对应的特征向量, 并构造特征向量矩阵。最后, 使用谱聚类方法对新的特征向量构成的矩阵进行聚类, 完成文本的划分。相对于基于本体的方法计算语义相似度, 本文提出的基于《同义词词林扩展版》的语义相似度计算方法的计算结果更加准确。利用本文提出的谱聚类方法, 解决了传统聚类算法数据维数过高和矩阵稀疏等问题。实验结果表明, SCBSS可以充分挖掘聚类中文本之间的语义相似度, 同时提高了聚类结果的质量。
毕强: 提出研究命题及研究思路;
刘健: 论文撰写及最终版本修订, 数据处理及实证研究;
鲍玉来: 论文修改。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: tomosliu9999@126.com。
[1] 刘健, 毕强. Resoures.csv. 文章分词统计表.
[2] 刘健, 毕强. Similarity.csv. 文章相似度计算结果.
[3] 刘健, 毕强. Similarity Questionnaire.doc. 相似度调查表.
[4] 刘健, 毕强. Result.csv. 文章聚类结果统计表.
[5] 刘健, 毕强. PurityResult.csv. 文章聚类Purity值统计表.

/
| 〈 |
|
〉 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}