贾君枝 , 李晓
, 李晓
山西大学经济与管理学院 太原 030006
Jia Junzhi, Li Xiao
中图分类号: G254
通讯作者:
收稿日期: 2017-05-5
修回日期: 2017-07-12
网络出版日期: 2017-10-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】调研owl:sameAs连接在真实数据网络中的配置和应用情况。【方法】从BTC 2014数据集中抽取部分数据, 应用统计学方法对样本数据构成的sameAs网络进行结构分析、域名分析和实例类型分析。【结果】数据分析结果表明, 真实数据网络中sameAs连接较稀疏, 等同实体网络中大多数实体只建立了单个连接。【局限】样本数据数量有限, 未能更全面地深入分析。【结论】该研究分析可以为关联数据中基于实例水平的数据集成、本体对齐、知识发现以及跨数据集查询等提供参考。
关键词:
Abstract
[Objective] This paper examines the application of the owl:sameAs link in the Web of Data. [Methods] First, we extracted owl:sameAs links from the BTC 2014 dataset. Then, we analyzed the structure of the sample data, as well as their domain names and instance types. [Results] The retrieved links of owl:sameAs were sparse, and most entities only had single connection between each other. [Limitations] The size of our sample data was small, and more comprehensive analysis was needed. [Conclusions] Our study lays some foundations for data integration, ontology alignment, knowledge discovery of the Web of Data.
Keywords:
关联数据(Linked Data)建立在网络标准技术如HTTP、RDF和URIs的基础上[1], 通过发布结构化数据, 建立数据相互连接而实现数据的增值。数据网络(Web of Data)是关联数据集的集合, 也称为关联开放数据(Linked Open Data)。2017年2月20日, W3C关联开放数据项目发布最新的关联开放数据云图(Linked Open Data Cloud, LOD Cloud), LOD云图中包含的关联数据集已经由2007年5月的12个数据集增长到1 139个, 内容涵盖地理、政府、生命科学、语言、媒体、出版物、社交网络、用户生成内容9个领域[2]。在过去的几年中, 越来越多的社区将其数据以关联数据的形式发布到LOD中, 这种快速增长使得LOD云图成为知识发现和自动问答等应用的实验平台。数据发布者根据自身需要采用不同词表术语或自定义术语表示数据, 对于现实世界中的同一实体对象, 不同的数据发布者从自身角度出发从不同维度赋予其标识并进行描述, 从而增加了数据共享的难度。从不同数据集发现同一实体, 可以提高数据的互操作性。因此, 识别不同数据集的相同实体已成为数据的关联问题之一, 被人们关注并研究。拥有不同标识或URIs两个实体对象, 通过实例级关系owl: sameAs彼此连接。有研究表明, 数据集资源之间最重要的连接谓词之一是owl:sameAs[3]。找出不同数据集中基于owl:sameAs语义的实例也被定义为“实例对齐” [4]。
近几年, 本体对齐被认为是LOD中最重要的研究问题之一, 它是数据集成、跨数据集查询及知识获取的前提条件。在LOD环境中, 本体对齐主要包括三个部分: 概念(类)对齐, 属性对齐和实例对齐[4]。本体对齐中的很多研究基于实例之间的owl:sameAs连接展开。Parundekar等[5]提出, 识别属于概念的等同(基于owl:sameAs连接)实例会导致这些概念之间的对齐。Correndo等[6]在对齐概念中采用一种利用实例之间的owl: sameAs连接以及Jaccard系数测量实例重叠的统计学方法。Nikolov等[7]利用owl: sameAs连接推断LOD中的本体概念之间的映射。Gunaratna等[8]提出一种可以在LOD环境中使用的属性对齐的方法, 利用数据实例之间的现有实体共现链接(如使用owl:sameAs和skos:closeMatch形式的链接)匹配属性扩展。
为了建立更多的外部关联, 数据发布者通过一些自动和半自动的方法发现网络中的等同实体, 并建立owl:sameAs连接。因此, 伴随着数据网络的急速增长, 跨数据集实例之间的owl:sameAs连接数量也在增长。虽然单个owl:sameAs谓词仅连接两个资源, 但当数据网络中所有的owl:sameAs谓词及其连接的RDF资源汇聚在一起时, 就形成一张巨大的有向图, 称为sameAs网络。本文对真实数据网络中的sameAs网络作统计学分析, 以期得到跨数据集之间实例的owl:sameAs配置和使用情况, 为关联数据中基于实例水平的数据集成、本体对齐、跨数据集查询以及知识发现等研究提供参考。
owl:sameAs是万维网本体语言(OWL)的一个内建属性, 用于将两个个体连接在一起。事实上要求每个人都使用相同的名字指称同一个个体是不现实的。当两个不同URI参引实际指的是同一个事物时, 可以通过属性owl:sameAs将它们相连, 表明被连接的两个个体有相同的“身份”[9]。比如, 可以通过以下陈述表示两个URI参引实际指的是同一个人:
<rdf:Descriptionrdf:about="#William_Jefferson_Clinton">
<owl:sameAs rdf:resource="#BillClinton"/>
</rdf:Description>
假设拥有不同URL的两个个体是相同的实体, 或者单个个体拥有多个名字, 可以通过owl:sameAs属性声明它们的同一性关系。owl:sameAs广泛应用于关联数据集中, 通过可参引的HTTP URL提供了可以指向外部“等价”资源的可选方式, URL自身可以唯一识别远程文档中的匹配资源。owl:sameAs陈述经常用来定义本体之间的映射[9]。在关联数据社区中, 由于owl:sameAs可以连接分布式数据集中的相同资源, 因此它经常被用来支持关联数据聚合。
sameAs陈述: 是指由owl:sameAs谓词连接两个RDF资源构成的三元组。其中, 两个资源及谓词都由可参引的HTTP URL作为标识符。如下所示为一个sameAs陈述:
<http://data.linkedmdb.org/resource/film/13508>
<http://www.w3.org/2002/07/owl#sameAs>
<http://dbpedia.org/resource/The_Temptress>.
sameAs网络: 网络从图论意义上理解是指由节点和连线构成的图, 可以用带箭头的连线表示从一个节点到另一个节点存在的某种顺序关系[10]。把数据网络中所有sameAs陈述中的RDF资源表示成节点, 用有方向的连线表示owl:sameAs关系, 由此形成的网络称之为sameAs网络。
为获得真实数据网络中owl:sameAs的使用情况, 本文选择的数据来源于Billion Triple Challenge (BTC) 2014 数据集[11]。BTC 2014数据集对网络数据的覆盖比率很高, 其使用包括VOID描述和数据管理系统CKAN所有示例URIs在内的众多数据源作为种子集合, 在网络中爬行了近5个月, 截止到2014年6月, 共采集4 090 758 596个RDF三元组, 其中包含大量的sameAs陈述。本文从该数据集中抽取了4个数据包, 共计2 096 904个三元组, 进行处理和分析, 使用的数据处理工具主要是SQL Server。通常假设顶级域名相同的数据来自同一个数据集。为了获得真实数据网络中不同数据集之间的互联方式, 对数据进一步处理, 首先去掉无效和重复记录, 然后提取主体和客体资源的顶级域名, 从而得到主体和客体资源分别来自不同数据集的三元组共有190 549个。基于实例的数据集之间通过不同的谓词实现互联。对谓词进行统计, 筛选出URI有效链接并且为多个数据集之间通用的谓词, 如表1所示, 可以看出owl:sameAs连接为数据集互联做出了巨大的贡献。
表1 数据集间互联统计
| 谓词缩写 | 谓词URI及备注 | 数量 |
|---|---|---|
| rdf:type | <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> 定义实例和类之间的联系 | 64 449 |
| owl:sameAs | <http://www.w3.org/2002/07/owl#sameAs> 表示由不同URI标识的两个RDF资源指的是同一个对象 | 44 746 |
| skos:exactMatch | <http://www.w3.org/2004/02/skos/core#exactMatch> 连接两个有足够的可信度并在信息检索应用程序较大范围可以交替使用的概念, 是skos:closeMatch的子属性 | 13 102 |
| rdfs:seeAlso | <http://www.w3.org/2000/01/rdf-schema#seeAlso> 将一个资源关联到另一个解释它的资源 | 5 570 |
| skos:closeMatch | <http://www.w3.org/2004/02/skos/core#closeMatch> 连接两个足够相似以致在一些信息检索应用程序可以交替使用的概念 | 1 490 |
| dcterms:type | <http://purl.org/dc/terms/type> 描述文件格式、物理媒介或资源的维度 | 1 170 |
190 549个三元组中有45 846个sameAs陈述。统计这些sameAs陈述中用于表示owl:sameAs属性的谓词形式及数量, 如表2所示。可知, 在数据网络中绝大多数sameAs陈述都使用了<http://www.w3.org/ 2002/07/owl#sameAs>这一规范的表达形式表示sameAs属性。
表2 owl:sameAs谓词表达形式
| sameAs谓词 | 数量 | 占比 |
|---|---|---|
| <http://www.w3.org/2002/07/owl#sameAs> | 44 746 | 97.60% |
| <http://www.w3.org/2000/01/rdf-schema#sameAs> | 631 | 1.38% |
| <owl:sameAs> | 445 | 0.97% |
| <htpp://www.abes.fr/owlsameAs> | 16 | 0.03% |
| <http://lexvo.org/ontology#nearlySameAs> | 4 | 0.009% |
| <http://linkedgeodata.org/ontology/gadmSameAs> | 4 | 0.009% |
另外, 由于Wikipedia有多个语言版本, 基于Wikipedia的DBpedia数据集也具备多语言知识库特性, 目前可支持多达92种语言。DBpedia中的资源与它的各个语言版本下对应资源也建立了大量的sameAs连接, 类似这样的陈述总共有3 505条。这部分数据对研究意义不大, 因此从45 846个sameAs陈述中把上述3 505条移除, 最终得到42 341条sameAs陈述, 其主、客体资源来自不同的数据集。笔者将这42 341个sameAs陈述形成的集合称为样本数据集, 由之形成的sameAs网络称为样本sameAs网络。
sameAs网络具有一定的网络拓扑结构, 通过对其结构的分析可以研究owl:sameAs在真实数据网络中的配置情况。
(1) 连接组件规模
样本数据集包含80 521个无重复的URI资源和42 341个唯一性sameAs陈述, 把RDF资源表示成节点, 用有向线表示owl:sameAs关系, 因此形成的sameAs网络中共有80 521个节点和42 341条有向边。
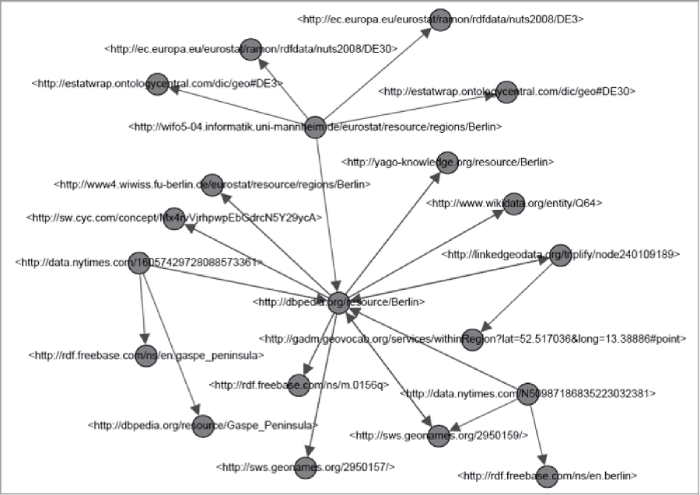
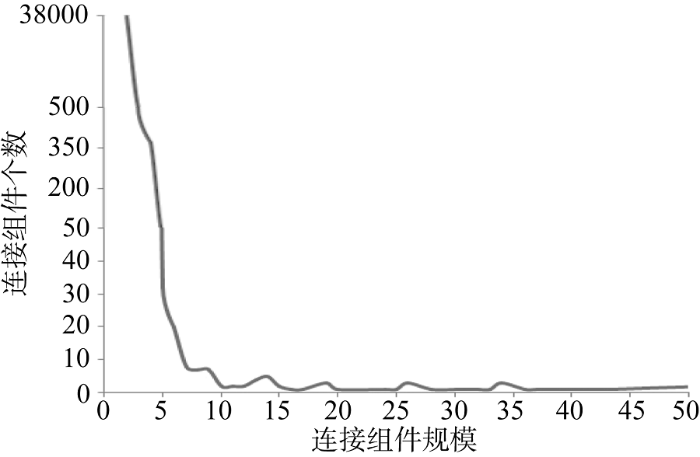
在网络G=(V,E)中(其中V称为节点集, E称为边集), 如果有一部分图G’=(V’, E’), V’是V的子集, E’是E的子集, 且E’中的任意一条边e’ij必定与E中的边eij对应, 则称G’是G全部的子图。若一个图G中的每对不同节点vi, vj之间都至少存在一条简单路径, 则称该图G是连通的。连通子图指网络G中的一个子图, 在这个子图中任意两个节点之间都至少存在一条简单路径[10]。如果把一个有向图的所有有向边用无向边替换掉后生成一个连通(无向)图, 这个有向图就被称为是弱连接。一个无向图G的最大连通子图被称为一个连接组件。一个网络可能存在多个连接组件。图1为样本sameAs网络中的一个连接组件, 其规模(用节点个数表示)为20。样本sameAs网络的所有连接组件规模分布如图2所示, 横坐标为连接组件规模(用节点个数表示), 纵坐标为对应规模的连接组件个数。该网络中共有38 558个连接组件, 每个连接组件平均覆盖了2.1个URI资源。97%的连接组件规模为2, 即只在两个RDF资源间建立了owl:sameAs连接。大型连接组件较少, 有个别连接组件包含上百个RDF资源。大规模连接组件呈现星型拓扑结构, 由较少节点作为中心节点, 将来自其他数据集的“等同”资源聚集在一起。因此, 样本sameAs网络的典型尺寸是一个比较小的常数, 并且规模增长也是比较缓慢的。
(2) 节点的度数、入度和出度
度是描述节点属性的重要概念。在网络中, 节点vi的邻边数目ki称为该节点的度。一个节点的度越大, 该节点越重要。对网络中所有节点的度求平均, 可得到网络的平均度。有向网络中与某个节点相连的线既有指向节点的, 也有从节点发出的, 因此也有必要分开统计两个方向的连线数, 前者称为节点的入度, 后者称为出度。在社交网络中, 通常将入度视为声望, 将出度视为合群性[10]。
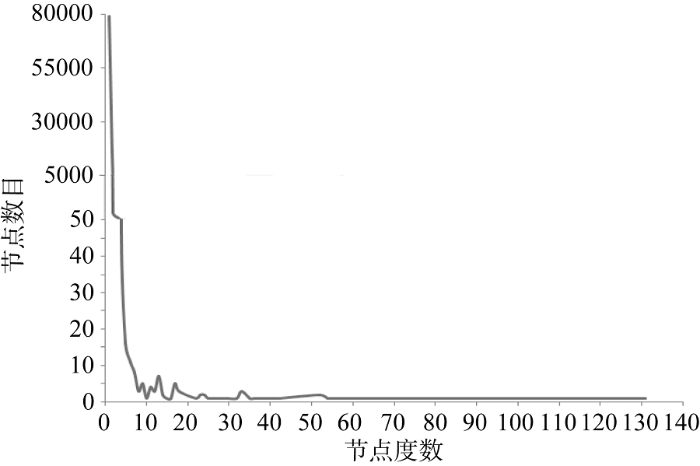
样本sameAs网络中, 节点度数分布如图3所示。98%的节点的度数为1, 即只与一个节点进行sameAs关联, 分布尾部稀少, 少量的节点与较多的RDF资源进行了sameAs关联。节点度数分布图在头部呈现出指数行为, 尾部呈现长尾特征。样本sameAs网络的结构特征表明即使个别节点失效, 不至于影响整体的稳定性, 但高度数节点失效, 会对关联数据网络造成一定的影响。
节点的入度范围在0-7之间, 48.6%的节点入度为0, 50.7%的节点入度为1。节点的出度范围在0-131之间, 51.3%的节点出度为0, 47.6%的节点出度为1。两个RDF资源间大多数为单向连接, 只有极少数RDF资源间建立了双向连接。RDF资源更容易与其他数据集中的资源主动建立owl:sameAs连接。正如Vatant指出, 当owl:sameAs用于数据融合时未必是对称属性。假设A拥有资源a, B拥有资源b, “a owl:sameAs b”并不意味着“b owl:sameAs a”。只有A声明了“a owl:sameAs b”, B也声明了“b owl:sameAs a”, a和b这两个RDF资源才被认为有强等同关系[12]。在样本sameAs网络中, RDF资源间建立了双向连接的情况非常少, 基于sameAs进行语义聚合时要适当考虑此类情况。
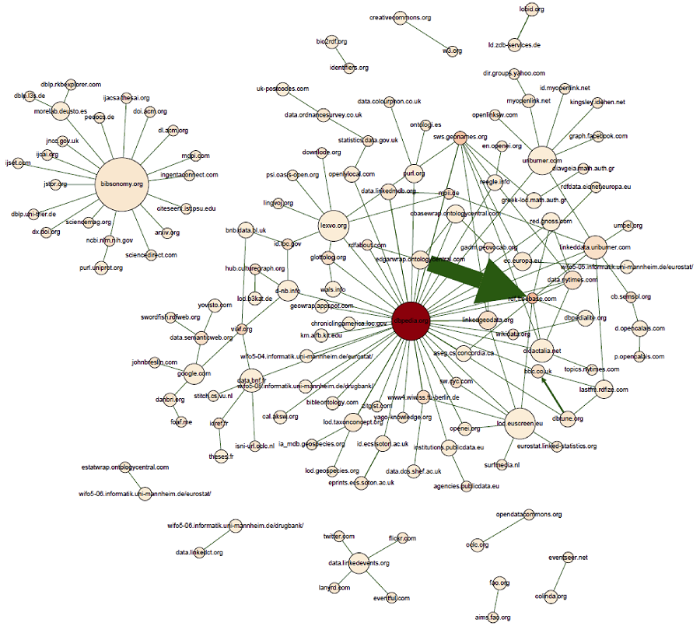
顶级域名通常可以用来识别关联数据的发布者, 即资源的拥有者(即拥有URIs命名空间并且对相关URIs作出官方描述的责任人)。通常假设顶级域名相同的数据属于一个数据集[3]。对于单个域名下包含多个数据集的情况, 单独处理这部分数据。研究顶级域名之间的连接情况可以发现数据集之间的关联情况。从这些sameAs陈述中提取所有RDF资源的域名, 进而统计分析不同数据集之间的owl:sameAs连接情况。经过对80 521个资源URIs的提取, 得到136个不同顶级域名。利用Gephi 绘制基于实例sameAs连接的域名网络结构图, 并通过特定的布局工具对节点进行类聚和排列, 最终效果如图4所示。在该图中, 不同节点代表不同的数据集, 节点颜色的深浅代表入度的大小, 节点的大小代表出度的大小, 有向连线代表数据集之间的sameAs连接, 连线的粗细代表连接的权重。发出有向连线的节点一方称为源数据集, 有向连线指向的节点一方称为目标数据集。
从图4中可以看到不同数据发布者之间的联系: SEC Edgar (edgarwrap.ontologycentral.com)同Freebase (rdf.freebase.com)建立了密集的sameAs连接, DBTune (dbtune.org, 提供音乐相关的结构化数据)和BBC (bbc.co.uk)次之, DrugBank (wifo5-04.informatik.uni- mannheim.de/drugbank/, 药物库)和LinkedCT (data. linkedct.org, 临床试验关联项目)之间也建立了数量可观的sameAs连接。笔者认为彼此之间建立了大量sameAs连接的域名, 从不同角度描述了相似的话题。利用Gephi中的布局工具, 把性质相同的节点聚在一起并从整体上作有序排列, 有利于进一步发现享有共同知识和兴趣的数据发布者。在图4中可以看到一些比较大的簇, 如以DBpedia为中心、以BibSonomy为中心的簇。DBpedia与许多大规模的数据集和本体实现关联和互操作, 而由于DBpedia广泛的主题覆盖, 因此它也被各种数据集首选作关联目标。在样本sameAs网络中, 进一步验证了DBpedia被称为“关联中转站”这一事实[13]。BibSonomy是由Kassel大学中 知识和数据工程组研究的用于共享标签和文献列表的推荐系统, 旨在整合书签系统和团队出版物管理的特征,使用户能够储存和组织标签及发布的条目[14]。BibSonomy通过提供文献交流的社会平台, 支持不同社区和用户合作。以BibSonomy为中心的簇代表一个社区, 其成员ACM数字图书馆(http://dl.acm.org/)等发布关于学术期刊及文献的信息, DBLP (http://dblp.uni- trier.de/)等提供关于计算机科学期刊和论文集的开放书目信息, NCBI(https://www.ncbi.nlm.nih.gov/)作为国家生物技术信息中心发布相关科学研究数据。由于本文数据是真实数据网络中的一部分, 在样本数据中, BibSonomy作为中心点, 与之关联的数据集较多, 但其与每个关联数据集之间的sameAs陈述并不多。也正是由于这个原因, 虽然在LOD云图中, DBLP、NCBI等数据集与DBpedia都是有连接的, 但由于样本数据中恰好没有这部分sameAs陈述, 因此在图4中没有看到上述数据源与DBpedia的连接。另外, 还有一些比较小但有意思的簇, 如以EUscreen (http://lod. euscreen.eu/)为中心的簇。EUscreen旨在创造欧洲电视节目、二次资源及文章的收集, 以便学生、学者和普通大众获取使用[15], 因此其以关联数据的形式发布相关内容, 使用户不仅能通过标准网络技术获取和检索相关元数据, 而且能发现更多相关的可用数据, 进而通过应用程序集成EUscreen收集的数据。
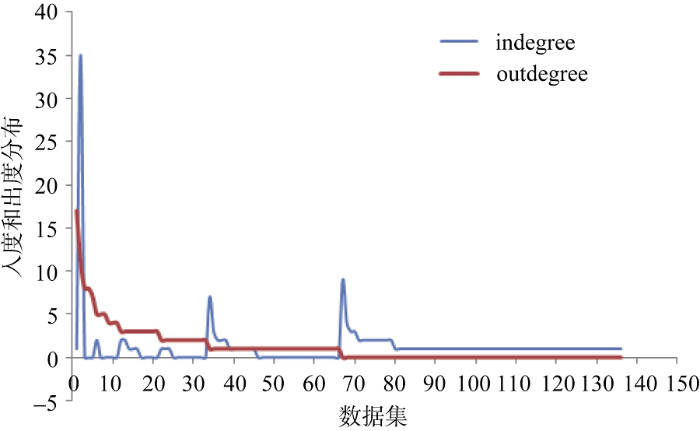
为深入了解数据集之间的连接情况, 对每个数据集的入度和出度进行统计并比对。如图5所示, 蓝色的线代表数据集的入度, 红色的线代表数据集的出度。发现高度链接的数据集较少且其入度和出度相差较大, 大部分数据集度数较低、owl:sameAs连接稀疏, 部分数据集只有入度或出度(即要么被动关联要么主动关联)。
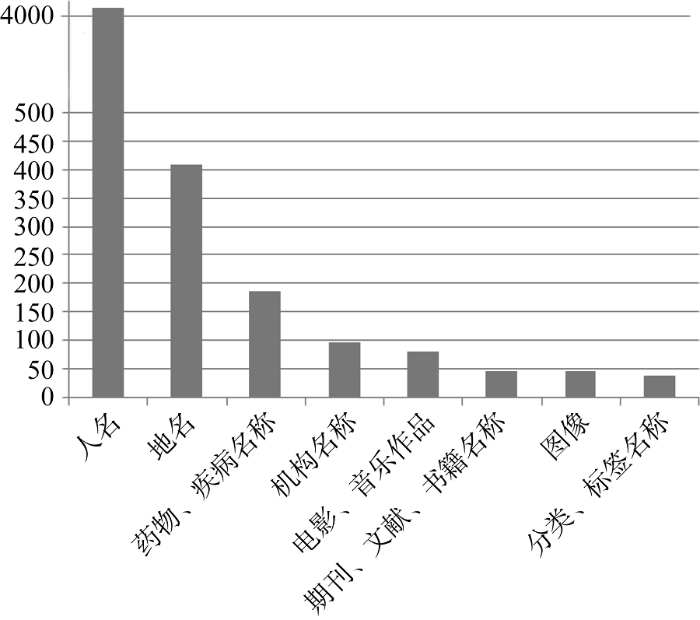
了解真实数据网络中建立了owl:sameAs连接的实体对象类型有助于探寻关联数据的分布和应用领域, 从而开拓不同领域的关联发现和应用。因此, 基于owl:sameAs连接, 对源数据集中实例的rdf:type信息进行提取并统计分析。由于数据发布者可以从不同维度描述同一实体对象, 因此同一实体常对应多个类型。在源数据集中, 总共获得5 155个RDF资源的9 056个类型信息。其中有340个实体对象对应的类型数目大于1, DBpedia中的足球运动员艾度斯恩(Connally Edozien)所属的类型更是多达65个, 其所属类型从不同角度描述了同一个人。为避免多次重复统计同一个实体对象, 对于类型数目大于1的实体只取其中一个类型(并不影响其最终归并后的类型), 经过分组汇总最终获得181个有效的以HTTP形式表示的不同类型信息及其对应的实体个数。基于类型查看建立了owl:sameAs连接的实体对象类型并再次归并及统计其数目, 结果如图6所示(对于拥有实例数目小于20的类型在此处不作讨论)。可以看到关联数据网络中, 建立了最多owl:sameAs连接的实体对象类型为人名, 其次分别是地名、医药类名称、机构名称、电影等。
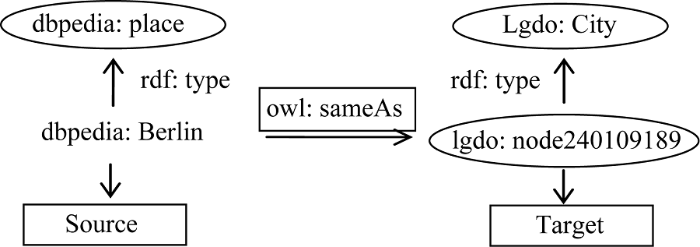
近几年, 利用实例数据进行概念对齐显示出其有效性。Parundekar等[5]提出识别包含于概念的等同实例将会导致这些概念之间的对齐。同时对源数据集和目标数据集中由owl:sameAs连接的实例的rdf:type信息进行统计, 有利于发现不同数据集中可对齐的概念, 同时可以帮助了解不同数据集之间建立owl:sameAs连接的深层次原因。图7是对样本数据集中的一个owl:sameAs连接同时获取其RDF资源的类型信息。
从图7可以看到在DBpedia数据集中, 柏林(dbpedia: Berlin)是dbpedia:place类的一个实例, 在linkedgeodata数据集中lgdo: node240109189是lgdo:City类的一个实例, 因而可知dbpedia:place和lgdo:City这两个概念至少是有交集的。在样本数据集中, 基于owl:sameAs连接同时获取源数据集和目标数据集中实例的rdf:type信息, 共计得到625条记录。基于这625条记录统计源数据集和目标数据集使用最多的type类型对, 如表3所示。
表3 基于owl:sameAs连接的源数据集和目标数据集常用type
| 源数据集 | 目标数据集 | 基于owl:sameAs连接的最常用的type对 | |
|---|---|---|---|
| 源数据集type | 目标数据集type | ||
| theses.fr | idref.fr | <http://www.abes.fr/foafPerson> | <http://xmlns.com/foaf/0.1/Person> |
| <http://www.abes.fr/foafAgent> | <http://xmlns.com/foaf/0.1/Person> | ||
| <http://www.abes.fr/foafAgent> | <http://xmlns.com/foaf/0.1/Organization> | ||
| d-nb.info | dbpedia.org | <http://d-nb.info/standards/elementset/gnd# DifferentiatedPerson> | <http://dbpedia.org/class/yago/Traveler109629752> |
| morelab.deusto.es | dblp.l3s.de | <http://swrc.ontoware.org/ontology#Article> | <http://purl.org/dc/dcmitype/Text> |
| wals.info | glottolog.org | <http://purl.org/dc/terms/LinguisticSystem> | <http://purl.org/linguistics/gold/Language> |
| didactalia.net | data.nytimes.com | <http://rdfs.org/sioc/types#Tag> | <http://www.w3.org/2004/02/skos/core#Concept> |
表3中, 通过第1、2、3、4行可以看出: 基于owl:sameAs实例连接, 源数据集和目标数据集可以尝试进行对齐的概念有哪些, 这为将来不同数据集的概念之间的对齐提供了有益的参考。第5行中对于nytimes数据集, 虽然其包含丰富的术语层次, 但只涵盖了很少的概念, 大部分实体归属于skos:Concept这个概念, 因此该数据集与其他数据集进行本体对齐时提供的概念非常有限。
sameAs网络特征表明大部分节点只有一个owl:sameAs连接, 少数节点拥有多个甚至大量的owl:sameAs连接。现实网络具有优先连接的特征, 即新的节点更倾向于与那些具有较高度的“大”节点相连接, sameAs网络同样具有这种特征。对于sameAs网络而言, 大部分节点随机失效基本不会影响其连通性, 但少数重要节点的失效就会对网络的连通性造成一定影响, 进而影响数据的关联。sameAs网络连接组件规模较小(典型尺寸为2), 不利于数据集之间关联关系的扩散。有时数据发布者并不热衷于声明owl:sameAs连接也会影响到连接组件的规模。
对基于owl:sameAs实例连接的部分数据集的入度和出度进行统计, 发现综合类知识库(如DBpedia, Freebase)及同类领域中的知名数据集(如地理领域中的GeoNames)容易被其他数据集信任并作为链接资源, 因此这些数据集往往具有高入度。其中一些数据集的入度和出度相差较大, 如DBpedia。入度高说明其作为知名数据集由于内容跨度大而被后发布的数据集积极关联, 而出度小则说明其发布较早且后期维护滞后, 致使其未能与后发布到LOD中的数据集主动关联, 从而减少了数据集之间的互联。跨领域中的语言资源Lexvo数据集具有高出度而无入度, 这是由于其需要确保所发布的资源即有关语言的实体对象可以与网络中多样化的资源建立密集的关联, 因此它与较多数据集的实体对象主动建立了owl:sameAs关联。BibSonomy数据集与之类似, 出度远远超过入度, 说明其作为分享标签和文学作品的推荐系统基于自身属性从而积极与有着类似话题的数据集建立关联, 而被其关联的数据集大多是出版物领域较知名权威的期刊或科研组织, 由于发布数据集的出发点不同、时间先后不同、发布者的地位不同等原因, 在其之间未能建立对等连接。在整个数据网络中, 对不同数据集中同一实体的关联发现还有很大的开拓空间。
互连数据集通常具有互补数据, 某一实体的事实可能分布于若干数据集, 将同一实体的不同属性及属性值聚合可以产生基于不同观点的实体的完整呈现。因此, owl:sameAs连接在数据集互联中起着举足轻重的作用。sameAs网络结构具有连接组件规模较小, 高度数节点稀疏, 大部分节点连接单一化, 节点出、入度分布曲线具有在头部呈幂率分布、尾部呈长尾分布的特征。基于owl:sameAs连接的关联数据集大部分连接稀疏, 高度链接的数据集较少且其中部分出入度相差较大。LOD云图中的数据集大部分基于实例对齐技术, 通过实例级关系相互连接, 而基于实例的owl:sameAs连接可以进行概念对齐、属性对齐等, 从而实现本体对齐。本体对齐通过为数据聚合、跨数据集查询、知识获取提供解决方案, 从而使LOD数据集的事实和信息呈现更加有用。在数据网络中, 从不同数据集中找到“等同”实例是有挑战性的, 发现分布于不同数据集的等同实体并为之建立owl:sameAs连接, 需要进一步提高相关技术、完善关联机制。owl:sameAs属性是否具有对称性、传递性、适用条件以及owl:sameAs属性在推理中的应用机制, 这些问题需要在今后进一步研究, 它们的应用势必会改变sameAs网络的结构。
贾君枝: 提出研究思路, 设计研究方案, 修改论文;
李晓: 收集、整理、分析资料, 撰写论文。
所有作者声明不存在利益冲突关系。
支撑数据见期刊网络版http://www.infotech.ac.cn。
[1] 李晓. sample.txt. 样本数据集.
| [1] |
Linked Data: The Story So Far [J].https://doi.org/10.4018/jswis.2009081901 URL [本文引用: 1] 摘要
The term 0904Linked Data09 refers to a set of best practices for publishing and connecting structured data on the Web. These best practices have been adopted by an increasing number of data providers over the last three years, leading to the creation of a global data space containing billions of assertions09” the Web of Data. In this article, the authors present the concept and technical principles of Linked Data, and situate these within the broader context of related technological developments. They describe progress to date in publishing Linked Data on the Web, review applications that have been developed to exploit the Web of Data, and map out a research agenda for the Linked Data community as it moves forward.
|
| [2] |
Linking Open Data Cloud Diagram 2017 [EB/OL]. [ |
| [3] |
Adoption of the Linked Data Best Practices in Different Topical Domains [C]// |
| [4] |
Alignment and Dataset Identification of Linked Data in Semantic Web [J].https://doi.org/10.1002/widm.1121 URL [本文引用: 2] 摘要
The Linked Open Data (LOD) cloud has gained significant attention in the Semantic Web community over the past few years. With rapid expansion in size and diversity, it consists of over 800 interlinked datasets with over 60 billion triples. These datasets encapsulate structured data and knowledge spanning over varied domains such as entertainment, life sciences, publications, geography, and government. Applications can take advantage of this by using the knowledge distributed over the interconnected datasets, which is not realistic to find in a single place elsewhere. However, two of the key obstacles in using the LOD cloud are the limited support for data integration tasks over concepts, instances, and properties, and relevant data source selection for querying over multiple datasets. We review, in brief, some of the important and interesting technical approaches found in the literature that address these two issues. We observe that the general purpose alignment techniques developed outside the LOD context fall short in meeting the heterogeneous data representation of LOD. Therefore, an LOD-specific review of these techniques (especially for alignment) is important to the community. The topics covered and discussed in this article fall under two broad categories, namely alignment techniques for LOD datasets and relevant data source selection in the context of query processing over LOD datasets.Conflict of interest: The authors have declared no conflicts of interest for this article.For further resources related to this article, please visit the WIREs website.
|
| [5] |
Linking and Building Ontologies of Linked Data [C]// |
| [6] |
Statistical Analysis of the owl:sameAs Network for Aligning Concepts in the Linking Open Data Cloud [J].https://doi.org/10.1007/978-3-642-32597-7 URL [本文引用: 1] |
| [7] |
Capturing Emerging Relations Between Schema Ontologies on the Web of Data [C]// |
| [8] |
A Statistical and Schema Independent Approach to Identify Equivalent Properties on Linked Data [C]// |
| [9] |
|
| [10] |
|
| [11] |
Billion Triples Challenge 2014 Dataset [EB/OL]. [ |
| [12] |
Using owl:sameAs in Linked Data [EB/OL]. [ |
| [13] |
DBpedia: A Nucleus for a Web of Open Data [C]// |
| [14] |
BibSonomy: A Social Bookmark and Publication Sharing System [C]// |
| [15] |
EUscreen Linked Open Data Pilot [EB/OL]. [ |

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}