岳子静, 章成志 , 周清清
, 周清清
南京理工大学经济管理学院 南京 210094
Yue Zijing, Zhang Chengzhi, Zhou Qingqing
中图分类号: G203
通讯作者:
收稿日期: 2017-08-5
修回日期: 2017-09-3
网络出版日期: 2017-11-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】挖掘不同地区的用户饮食偏好, 从而揭示不同群体的饮食文化差异, 并为餐饮业提供建议。【应用背景】传统饮食偏好研究具有数据收集时间长、样本量少、成本高等不足, 而社交媒体的迅猛发展, 为获取大规模的用户饮食信息、挖掘用户饮食偏好提供了可能。【方法】以“大众点评网”的用户生成内容作为实验数据, 挖掘不同地区的用户饮食偏好, 揭示不同地区的饮食文化差异。【结果】来自经济相对发达地区的用户饮食偏好较为丰富, 同时, 地理距离与用户饮食偏好相似性之间存在显著负相关关系。此外, 味道、服务、环境受到各地区用户较高的关注。【结论】基于用户生成内容的饮食偏好挖掘能在一定程度上反映用户的饮食偏好, 揭示不同地区的饮食文化差异, 为相关研究提供参考。
关键词:
Abstract
[Objective] This study investigates the dietary preferences of Chinese users from different regions to reveal the differences of dietary culture among them, and then provides suggestion to the catering industry. [Context] It took researchers long period of time to collect small amount of data of dietary preferences. With the development of social media, we could retrieve large-scale dietary information more effectively. [Methods] We collected user-generated content (UGC) from Dianping.com to explore their dietary preferences. [Results] Users’ dietary preferences were very different in the developed regions. Meanwhile, there was significant negative correlation between geographic distances and the similarities of users’ dietary preferences. Finally, users paid more attention to the taste, service and environment of the restaurants. [Conclusions] Research based on the user-generated content can reflect their dietary preferences and reveal the differences of dietary cultures.
Keywords:
饮食作为世界各国文化的重要组成部分, 是人类生存和发展的基本保障, 也是影响着人类生命和健康的重要行为。围绕饮食的话题, 已有许多学科展开了一系列的研究[1-3]。饮食偏好是饮食研究的重要话题之一。通过揭示不同群体用户的饮食习惯, 不仅能够反映不同群体的饮食文化差异, 而且能为餐饮业提供相关建议。
当前饮食偏好的研究主要基于传统的调研方法, 如问卷调查、访谈和观察等[4-6]。此类方法虽有成熟的理论支撑且可行性高, 但具有成本高、研究对象规模小、数据收集时间长等局限性。Web2.0时代的到来, 促进了Twitter、新浪微博、Yelp、大众点评等在线社交平台的兴起。截至2017年第一季度, 新浪微博月活跃用户数为3.40亿(http://tech.sina.com.cn/i/2017-05-16/ doc-ifyfeius8004650.shtml); 大众点评APP月活跃用户数超过2.5亿, 用户点评数量超过2亿(http://travel. sina.com.cn/domestic/news/2017-05-12/detail-ifyfeivp5633138.shtml)。伴随着智能终端的普及, 越来越多的用户倾向于通过网络传递自己在衣食住行等方面的信息。海量用户生成内容(User Generated Content, UGC)的产生, 不仅为获取用户饮食偏好信息提供了机会, 而且能在一定程度上弥补传统调研方法的不足。
为此, 本文采用基于数据驱动的方法, 结合评论挖掘技术分析各地区用户的饮食偏好。具体而言, 利用“大众点评网”的UGC作为数据源, 结合“美食杰网”提供的中国菜肴信息, 挖掘中国各地区的用户饮食偏好, 以揭示不同地区的饮食文化差异。同时, 试图分析不同地区的用户在饮食消费过程中的属性偏好差异, 以反映不同地区的用户在饮食消费过程中关注点的偏好差异, 为餐馆提供相关建议, 从而促进餐饮业的发展。
本文的研究目的在于利用UGC分析中国不同地区的用户饮食偏好, 主要涉及的相关研究包括基于用户生成内容的用户研究、用户饮食偏好研究。
海量UGC为开展在线用户研究提供了前所未有的机会。学者们利用UGC, 在网络舆情[7-8]、信息推荐[9-10]、情感分析[11-13]等领域开展了相关研究, 充分证明了基于UGC的用户研究的可行性。此外, 由于UGC文本结构的特殊性, 促进了文本信息处理技术的发展, 从而为后续的用户研究提供了技术支撑。
在用户偏好研究方面, UGC无疑为其提供了充足的数据资源, 因此, 如何挖掘此类数据才是关键。Barreda等利用内容分析技术研究抓取的评论内容, 以分析旅行者是如何在社交网络上交流有关他们在特定旅馆的正面或负面体验信息, 研究表明旅行者更偏好于在方便的环境下发表旅馆的正面评论[14]。杨志墨利用向量空间模型的表示方法, 通过对用户生成内容进行文本聚类来描述用户的兴趣偏好, 并基于个体用户的兴趣偏好构建用户社区兴趣模型[15]。赵华等结合作者主题模型对在线社交网络上图书馆用户的生成内容进行分析, 以了解图书馆机构的关注话题, 结果表明图书馆机构偏好于关注新书推荐、讲座信息、图书馆服务等主题[16]。张晓勇等基于文本聚类技术对不同季节的饮食微博内容进行话题检测, 从而揭示不同季节的饮食话题分布情况, 帮助消费者和商家提供决策依据[17]。Li等尝试基于社交网络从主题视角推断用户的消费偏好, 研究表明从用户生成内容和粉丝关系中能挖掘出用户的在线消费偏好[18]。
通过上述研究可以看出, 当前基于UGC的偏好研究, 主要是基于UGC进行关键词提取、文本聚类等处理以表示用户偏好, 然而此类方法受偏好提取方法的影响较大。为避免该问题的出现, 本文利用菜肴词表匹配的方法, 将用户的饮食偏好映射到菜肴上。此外, 上述用户偏好研究中的用户偏好表示及偏好相似性度量的方法都十分值得借鉴。
目前多数用户饮食偏好的研究主要采用问卷调查、访谈、观察等方法[4-6]。Cantarero等利用焦点小组、访谈、观察和问卷调查的方法分析社会文化价值与人类饮食偏好之间的关系, 研究表明人们倾向于消费具有文化象征性的食物, 从而增强自我归属感, 该研究对于分析社会文化因素对饮食行为的激励作用具有重要意义[4]。杨君等选取中国5个代表性城市的用户作为调查对象, 利用问卷调查的方法研究吸烟人群饮食偏好与卷烟感官偏好的关系[5]。寿小婧等基于问卷调查的方法研究孤独症儿童的饮食偏好特点, 结果表明孤独症儿童拒绝的食物种类显著多于正常儿童, 同时对辣椒和方便面的接受度较高[6]。Vollmer等研究有关食物的育儿行为和儿童饮食偏好之间的关系, 研究表明父母正确的引导行为有利于儿童形成健康的饮食偏好[19]。
为减少数据收集的成本和时间, 已有学者尝试通过其他方法获取用户的饮食偏好信息。任彬等利用依存句法分析的方法基于微博文本分析不同维度的用户饮食习惯特色[20], 并在此基础上绘制了微博饮食地图①(①http://ys.8wss.com/.), 此外, 还对不同地区、不同性别的用户饮食表达行为进行分析[21]。与本文研究不同, 文献[21]更侧重于研究用户语言表达的行为差异, 强调基于依存句法分析的文本挖掘方法优于基于词表的方法, 但未针对不同群体的饮食特色习惯进行深入研究。Zhu等利用在线食谱提供的原料信息研究中国各菜系间的相似度, 研究表明地理位置的邻近性与菜系的原料使用相似度之间存在相关关系[22]。该研究通过分析各菜系在原料使用上的相似性, 能在一定程度上反映出不同地区用户的饮食相似性, 并未从用户角度出发研究用户真实的饮食偏好, 但在一定程度上为本文的研究提供了启发。Vidal等利用“breakfast”、“lunch”、“dinner”以及“snack”4个词在Twitter上返回的检索结果作为研究数据, 利用自动化的词频统计和人工内容统计方法研究用户在不同饮食情况下讨论的主题差异[23]。Abbar等将Twitter用户的饮食选择、人口统计信息和社交网络联系起来, 研究表明用户提及食物的热量与该地区的肥胖率之间存在相关性, 并利用用户的人口统计信息和其在社交网络中提及的食物名称建立模型, 以预测肥胖率和糖尿病率[24]。岳子静等从文本情感分析的角度, 基于“美团网”点评内容挖掘北京地区的用户对各菜系的关注度与满意度, 以揭示各菜系在北京地区的发展与传播情况[25]。
基于传统调研方法的饮食偏好研究主要围绕特定群体展开, 在一定程度上具有用户信息收集时间长、成本高等不足。海量UGC的产生为饮食偏好的研究提供了新的数据来源, 弥补了传统调研方法的不足之处。为此, 本文基于UGC进行饮食偏好分析, 不同于传统的研究方法, 而是从数据驱动的角度出发挖掘中国用户的饮食偏好, 揭示不同地区的饮食文化差异, 从而为餐饮业提供相关建议, 并对相关研究提供参考。
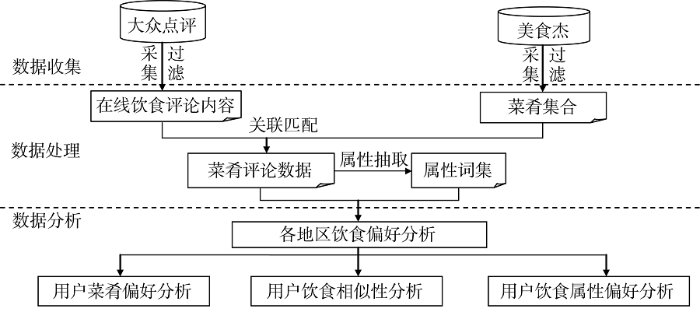
本文旨在通过挖掘在线用户评论, 分析不同地区的用户饮食偏好情况, 研究框架如图1所示。实验数据包括两个部分: “大众点评网”的在线饮食评论数据、“美食杰网”的菜肴数据。基于菜肴集合和在线评论内容的关联匹配得到包含菜肴名称的评论数据, 具体而言, 利用菜肴集合中的菜肴名称对在线评论内容进行检索, 获取至少包含一条菜肴名称的在线评论内容, 作为菜肴评论数据。并在此基础上进行属性抽取以获取属性词集。最后基于上述数据从三个方面开展各地区用户的饮食偏好研究, 包括各地区用户的菜肴偏好分析、饮食相似性分析和饮食属性偏好分析。
(1) 饮食偏好的度量
量化用户饮食偏好的目的是为了分析同一地区用户的饮食偏好情况并能够对比不同地区用户的饮食偏好差异。由于不同地区的用户评论数量不一样, 因此利用用户提及菜肴(或属性)的绝对频率并不能满足上述分析要求。为此, 本文利用用户提及菜肴(或属性)的相对频率[26]来表示用户对菜肴(或属性)的偏好程度, 地区j的用户对菜肴(或属性) i的偏好程度表示为:
${{p}_{ij}}=\frac{{{n}_{ij}}}{\sum{{{n}_{ij}}}}$ (1)
其中, ${{n}_{ij}}$表示地区j的用户提及菜肴(或属性) i的绝对频率, $\sum{{{n}_{ij}}}$表示地区j的用户提及所有菜肴(或属性)的总频率, ${{p}_{ij}}$值越大, 说明地区j的用户对菜肴(或属性) i的偏好越大。在分析用户对菜肴偏好的基础上, 本文试图分析各地区用户对所有菜肴的偏好分布情况, 即度量各地区用户对所有菜肴的偏好差异。信息熵是衡量一个随机变量取值的不确定性程度, 已有研究[27]利用信息熵度量用户对不同主题的偏好分布情况。同理, 信息熵也可用于度量地区j的用户对所有菜肴的偏好分布情况, 其计算公式[28]如下:
${{H}_{j}}=-\sum\nolimits_{j}{{{p}_{ij}}lo{{g}_{2}}{{p}_{ij}}}$ (2)
其中, ${{H}_{j}}$值越大, 说明地区j的用户对所有菜肴的偏好分布越均匀, 偏好差异越小, 用户的菜肴偏好越丰富; 反之, 偏好分布越不均匀, 偏好差异越大, 菜肴偏好越单调。
本文在分析各地区用户饮食偏好的基础上, 试图分析不同地区用户的饮食相似性。具体来说, 是度量不同地区的用户对菜肴偏好的相似性。首先, 利用向量空间模型[29]将地区j的用户饮食偏好表示为提及菜肴i组成的特征向量Vj, 仅利用菜肴提及的次数不足以衡量菜肴的重要程度, 而TF-IDF[30]作为当前计算特征项权重常用的方法之一, 可用来评估一个菜肴对于某地区用户饮食偏好的重要程度。因此, 将地区j的用户饮食偏好表示为:
${{V}_{j}}=({{w}_{1}}{{p}_{1j}},{{w}_{2}}{{p}_{2j}},\cdots ,{{w}_{i}}{{p}_{ij}},\cdots ,{{w}_{n}}{{p}_{nj}})$ (3)
其中, ${{w}_{i}}$表示菜肴i的特征权重, 计算公式如下:
${{w}_{i}}={{\log }_{2}}\frac{M}{{{m}_{i}}}$ (4)
其中, M为地区总数, ${{m}_{i}}$为提及到菜肴i的地区数量。在度量不同地区用户间的饮食相似性时, 本文采用常用于度量用户兴趣相似性的夹角余弦法[31-32]。对于地区a和地区b用户之间的饮食偏好相似度的计算公式[33]如下:
$sim({{V}_{a}},{{V}_{b}})=\frac{\sum\nolimits_{i}{{{w}_{i}}{{p}_{ia}}\cdot {{w}_{i}}{{p}_{ib}}}}{\sqrt{\sum{_{i}{{({{w}_{i}}{{p}_{ia}})}^{2}}}}\cdot \sqrt{\sum{_{i}{{({{w}_{i}}{{p}_{ib}})}^{2}}}}}$ (5)
$sim({{V}_{a}},{{V}_{b}})$值越大, 说明地区a和地区b用户之间的饮食相似性越高, 反之相似性越低。
(2) 饮食属性抽取方法
属性抽取的目的是为了帮助理解用户对饮食属性偏好的差异, 因此在属性抽取方法的选择上更注重方法的效率, 本文采用基于高频名词抽取属性词的方法[34], 该方法简单高效。首先利用FudanNLP①(①http://code.google.com/p/fudannlp/.)对菜肴评论数据进行分词与词性标注, 然后抽取词性为名词的词语, 根据词语的频次(Term Frequency, TF)值从高到低进行排序, 结合人工判断的方法从前50个高频名词中抽取热点属性词。汉语的博大精深, 使得在表达同一含义时, 通常有多种表达方式, 因此, 需要对热点属性进行语义扩展。已有研究[35-36]基于Word2Vec进行词语语义的扩展, 且取得了不错的效果。因此, 本文基于Word2Vec②(②https://code.google.com/archive/p/word2vec/.)抽取与候选属性词语义相似的前30个名词, 最终经过人工过滤形成属性词集。由于属性抽取的目的是为了分析不同地区用户的饮食关注点的差异, 因此加入人工判断和过滤的方法以确保抽取属性的准确性。Word2Vec的基本思想是通过对在线饮食评论语料的训练, 将每个词映射到K维实数向量, 通过计算词与词之间的距离来判断它们之间相似性。本文采用Distributed Representation[37]的词向量表示方法, 基于夹角余弦法计算词语的相似度, 具体计算公式如下:
$\cos (x,y)=\frac{\sum\nolimits_{t}{({{x}_{t}}\cdot {{y}_{t}})}}{\sqrt{\sum\nolimits_{t}{{{({{x}_{t}})}^{2}}}}\cdot \sqrt{\sum\nolimits_{t}{{{({{y}_{t}})}^{2}}}}}$ (6)
其中, $\cos (x,y)$表示词语x和y之间的相似度, ${{x}_{t}}$和${{y}_{t}}$表示词语x和词语y在词向量中的第t维(t=1,2,3,…k)。$\cos (x,y)$值越大说明词语间的相似性越高, 反之相似性越小。
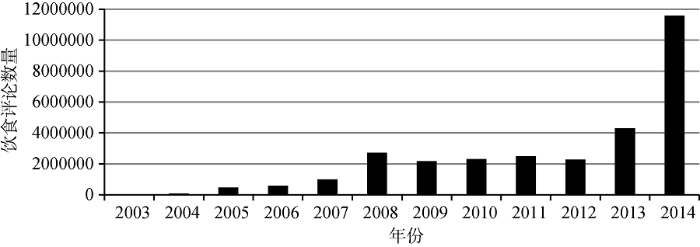
实验数据来自复旦大学自然语言处理实验室采集的2003年4月至2014年9月大众点评饮食评论内容③(③http://sma.fudan.edu.cn/dataset.html.), 于2016年11月7日获取数据集, 共包含30 010 078条评论信息, 根据评论信息中的时间信息统计各年份的饮食点评数量, 结果如图2所示。
可以看出, 自2003年大众点评成立, 饮食点评数据有着逐年不断增长的趋势, 由此反映出近年餐饮市场的迅猛发展。正是由于餐饮业的发展, 使得越来越多的用户通过社交媒体平台发布和寻找美食信息, 从而为在线饮食偏好挖掘提供了机遇。
除饮食评论内容外, 本文利用由Zhu等[22]于2012 年4月从“美食杰网”采集的19 647个菜肴名称作为菜肴集合, 经过关联匹配, 获得8 331 050条至少包含一道菜肴名称的饮食评论数据, 仅有9 085道菜肴名称在评论中得到匹配。最终将8 331 050条评论内容作为实验数据, 每条数据包含商户ID、用户ID、用户所在地、点评时间、点评内容, 数据示例如表1所示。
表1 实验数据示例
| 商户ID | 用户ID | 用户注册地 | 评论时间 | 评论内容 |
|---|---|---|---|---|
| 50**2 | 2**2 | 上海 | 2003/7/10 | 牛肉拉面还是蛮好吃的, 现在又增加了凉粉也不错。 |
| 57**7 | 2**8 | 山东 | 2005/12/20 | 过桥米线比较正宗的一家店。店面不大, 服务差点。 |
| 18**0 | 5**0 | 上海 | 2014/9/21 | 大众消费, 拉条子挺好, 烤肉正宗, 吃羊肉串这儿放心。 |
(1) 各地区用户菜肴偏好分析
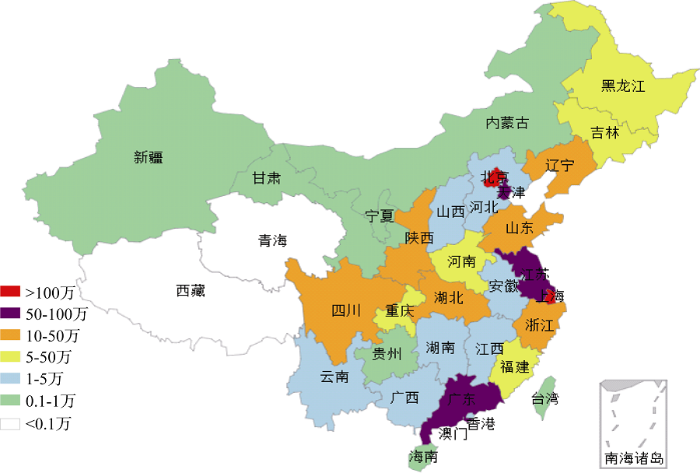
根据用户注册时提供的省份信息, 统计各地区用户提及菜肴的总次数, 结果如图3所示。可以看出, 上海、北京、广东、江苏、天津地区在评论时提及菜肴的次数最多, 说明这些地区的用户较多使用大众点评平台来寻找美食, 且更倾向于分享自己对饮食的看法。
结合菜肴集合, 统计了各地区用户对各菜肴的提及频次, 得出各地区用户对这些菜肴的偏好情况, 取各地区偏好前50的菜肴来体现各地区的菜肴偏好情况, 部分地区的菜肴偏好情况如图4所示。可以看出, 不同地区的用户饮食偏好存在一定差异, 上海和北京地区的用户饮食偏好相对于另外两个地区来说较为相似, 都偏好于烤肉、烤鱼、冰淇淋等菜肴, 澳门地区的用户更偏好于蛋挞、云吞、米粉, 而西藏地区的用户则表现出对酸奶、烤鱼、烤肉的强烈偏好。上海、北京这类经济发达的地区用户的偏好较为相似, 都表现出对当下流行美食的偏好, 而对于澳门、西藏等具有明显地域性特征的地区用户来说, 则表现出对当地特色美食的偏好。
除此之外, 可以发现同样是对烤鱼、烤肉表现出偏好, 上海、北京、西藏地区的用户对其偏好程度不同。为此, 本文试图利用熵值法分析各地区用户对菜肴偏好的分布情况。结果如表2所示。
表2 各地区用户的菜肴偏好分布熵
| 序号 | 地区 | 菜肴偏好分布熵 | 序号 | 地区 | 菜肴偏好分布熵 |
|---|---|---|---|---|---|
| 1 | 香港 | 8.540 | 18 | 重庆 | 7.939 |
| 2 | 上海 | 8.413 | 19 | 河南 | 7.916 |
| 3 | 广东 | 8.388 | 20 | 安徽 | 7.887 |
| 4 | 北京 | 8.259 | 21 | 陕西 | 7.790 |
| 5 | 福建 | 8.221 | 22 | 贵州 | 7.761 |
| 6 | 浙江 | 8.176 | 23 | 广西 | 7.743 |
| 7 | 澳门 | 8.110 | 24 | 辽宁 | 7.668 |
| 8 | 四川 | 8.110 | 25 | 河北 | 7.635 |
| 9 | 江苏 | 8.080 | 26 | 山西 | 7.563 |
| 10 | 江西 | 8.075 | 27 | 黑龙江 | 7.495 |
| 11 | 海南 | 8.062 | 28 | 内蒙古 | 7.454 |
| 12 | 山东 | 8.052 | 29 | 甘肃 | 7.388 |
| 13 | 云南 | 8.049 | 30 | 吉林 | 7.342 |
| 14 | 天津 | 8.048 | 31 | 新疆 | 7.143 |
| 15 | 湖北 | 8.032 | 32 | 宁夏 | 7.048 |
| 16 | 湖南 | 7.995 | 33 | 西藏 | 6.940 |
| 17 | 台湾 | 7.967 | 34 | 青海 | 6.689 |
来自香港、上海、广东、北京等经济较为发达地区的用户的菜肴偏好分布熵值较大。根据熵值的定义, 可以理解为这些地区的用户对所有菜肴的偏好差异较小, 菜肴偏好较为丰富。而对于宁夏、西藏、青海地区的用户来说, 他们对各类菜肴的偏好差异较大, 菜肴偏好较为单调。结合先验知识, 可以发现香港、上海、北京等地区经济发达, 外来人口的比例相对西藏、宁夏等地区来说较多。根据部分地区统计局①(①http://www.stats.gov.cn/.)提供的数据显示, 熵值较高的上海、北京地区的外来人口占常住人口的比例分别为41.0%、38.1%; 熵值较低的河南、广西地区的外来人口占比为11.5%、13.1%。由于外来人口比重的增加, 势必会导致当地餐饮业的多栖发展, 以适应不同地区用户的饮食需求。因此, 来自经济发达且外来人口比重较高的地区用户的饮食偏好较为丰富。上述分析结果可以为各地区餐饮商家在制定菜单时提供参考, 例如商家所在地区外来人口比重较高, 则应丰富菜肴种类, 以适应用户的不同需求。
(2) 各地区用户饮食相似度分析
通过上述分析, 能够发现不同地区的用户饮食偏好存在差异。然而, 仅根据菜肴提及频次的统计, 不能直观地体现出各地区用户间的饮食偏好差异, 为此, 本文基于各地区用户对所有菜肴的偏好程度, 度量不同地区用户间的饮食偏好相似性, 以体现这种差异的大小。表3列举了饮食偏好相似度排名前10的地区, 可以发现江苏、浙江以及上海(简称江浙沪)三个地区间的用户饮食偏好相似度值最高。结合先验知识发现饮食偏好相似性较高的地区之间的地理距离相对较近, 正如地理学第一定律[38]中提到的“事物是普遍联系的, 相近的事物关联更紧密。” 为此, 本文利用各地区省会城市间的平均球面距离②(②http://mathworld.wolfram.com/GreatCircle.html.)度量地区间地理位置的远近, 以此分析地理位置的邻近性与用户的饮食偏好之间是否存在相关关系。
表3 饮食偏好相似度排名前10的地区分布
| 序号 | 地区名 | 地区名 | 饮食偏好 相似度 | 序号 | 地区名 | 地区名 | 饮食偏好 相似度 |
|---|---|---|---|---|---|---|---|
| 1 | 江苏 | 上海 | 0.579 | 6 | 广东 | 澳门 | 0.500 |
| 2 | 江苏 | 浙江 | 0.569 | 7 | 北京 | 河北 | 0.493 |
| 3 | 浙江 | 上海 | 0.518 | 8 | 江苏 | 安徽 | 0.482 |
| 4 | 香港 | 上海 | 0.515 | 9 | 四川 | 重庆 | 0.477 |
| 5 | 贵州 | 云南 | 0.505 | 10 | 广东 | 香港 | 0.464 |
对各地区间的地理距离和饮食偏好相似度进行皮尔逊相关性分析, 结果如表4所示, 各地区间的地理距离与饮食偏好相似度之间存在显著的负相关关系, 相关系数为-0.508。由此说明两个地区之间的地理距离越近, 它们的饮食偏好相似性可能越大。不难理解, 地理距离越近的地区之间, 人口迁徙和文化交融的机会越大, 会在一定程度上造成这种相关性的出现。
表4 地区饮食偏好相关性分析结果
| 各地区间的 地理距离 | 各地区间的 饮食相似度 | |
|---|---|---|
| 各地区间的地理距离 | 1 | -.508** |
| 各地区间的饮食相似度 | -.508** | 1 |
(3) 各地区用户饮食属性偏好分析
在分析各地区用户的菜肴偏好的基础上, 研究不同地区的用户对饮食属性的偏好情况。基于属性抽取结果, 选取5类热点属性用以分析不同地区用户的饮食属性偏好情况, 根据这5类热点属性获取到的属性词集, 结果如表5所示。
表5 饮食属性词集
| 饮食属性 | 属性词集 |
|---|---|
| 味道 | 味道、味道儿、口味、口味儿、口感 |
| 环境 | 环境、氛围、装潢、气氛 |
| 服务 | 服务、服务态度、态度、服务员、服务生、店员 |
| 价格 | 价格、价钱、菜价、价位、价额、单价、定价 |
| 份量 | 份量、量、分量、菜量、菜份量 |
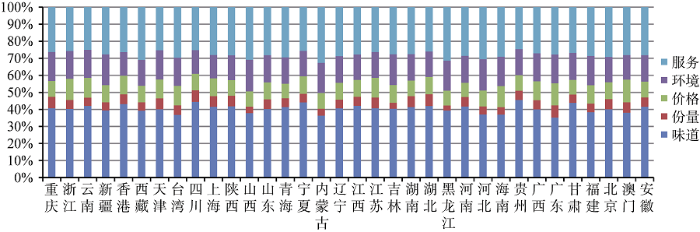
基于用户饮食评论内容和属性词集之间的提及关系, 统计各地区的用户对这5类饮食属性的偏好情况, 结果如图5所示。可以看出, 所有地区的用户偏好程度最高的饮食属性是味道, 其次是服务、环境、价格和份量。这一结果体现出大众在饮食消费的过程中, 除了关注菜肴本身的味道, 对就餐过程中享受到的服务和餐厅环境的关注也越来越高。外出就餐的目的不再是为了果腹, 而是追求味蕾和精神上的享受。在餐饮业商家相互竞争的局势下, 若想提高消费者的满意度, 最简单的方法则是在价格和分量上尽可能满足消费者的需求, 因此相对于其他属性来说, 用户对价格和份量的关注度较低。
根据图5, 可以了解不同地区的用户对这5类饮食属性的偏好差异。其中对饮食味道最为偏好的是贵州地区用户, 内蒙古地区的用户最偏好于服务, 山西地区的用户最偏好于就餐的环境, 澳门地区的用户更偏好于菜肴的价格, 而广东地区的用户更偏好于关注菜肴份量的大小。不同地区的用户对饮食属性的偏好差异, 还能在一定程度上体现出不同地区饮食特点的差异, 如广东地区的饮食讲究精致, 因而菜的份量相对北方地区而言较小, 因此广东地区的用户对菜的份量关注度就远大于黑龙江、吉林等地区。根据不同地区的饮食属性偏好分析, 可以发现虽然各地区对5类属性的偏好大体相同, 但对于同一属性而言, 不同地区用户的偏好程度不同。对于餐饮商家而言, 如一段时间内用户对“服务”的关注度较高, 则应探究该段时间内用户对“服务”是较为满意还是不满意, 以此调整经营策略, 不断提高用户满意度, 从而提升其在行业内的竞争力。
本文利用大众点评的用户评论数据进行饮食偏好分析, 不同于传统的研究方法, 而是基于数据驱动的方法, 结合评论挖掘技术探究各地区用户的饮食偏好, 不仅能帮助餐饮商家调整经营策略, 而且对于计算文化学、社会计算等相关研究具有一定的参考价值。实验结果表明, 不同地区的用户对菜肴偏好的分布不同, 来自经济发达且外来人口比重较高地区的用户, 他们的饮食偏好较为丰富且均衡, 而对于地域性特征显著的地区用户来说, 其饮食偏好相对单调, 且偏好于当地特色美食。同时, 地理距离与用户间的饮食偏好相似性之间存在显著的负相关关系, 地理位置越近的两个地区用户之间的饮食偏好的相似性就可能越大。此外, 所有地区的用户都表现出对饮食本身的味道、享受到的服务和就餐环境的高度关注, 而对菜肴价格的高低和份量的大小的关注度较低; 然而对于同一属性, 不同地区用户的偏好程度存在差异, 这一差异不仅能体现出不同地区用户的饮食属性关注差异, 还能帮助各地餐饮商家针对性地调整经营策略。本文一方面证实了基于用户生成内容挖掘用户饮食偏好的可行性, 且具有规模大、成本低等优势; 另一方面表明利用用户生成内容挖掘用户饮食偏好, 不仅丰富了饮食偏好挖掘的研究方法和研究内容, 而且利用本文的研究方法获取用户的饮食偏好信息(偏好的菜肴和属性), 能为各地区的餐饮商家调整经营策略提供指导性建议, 促进餐饮业的发展, 从而实现饮食挖掘研究的应用价值。
未来研究可从两方面开展: 一是从文本情感分析的角度, 分析不同地区的用户对菜肴及其属性的满意度, 从语义层面更加深入地了解用户的饮食偏好以及对当前餐饮商家提供的饮食产品或服务的满意度; 二是引入点评时间和点评用户的性别信息, 以探究不同时间段、不同性别的用户饮食偏好是否存在差异, 从而更好地了解不同群体在不同时间维度下的饮食偏好。
岳子静: 文献调研与整理, 数据获取与分析, 论文起草;
章成志: 提出研究思路, 设计研究方案, 论文最终版本修订;
周清清: 论文修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: 1347660200@qq.com。
[1] 岳子静, 章成志, 周清清. dpreviewdata.txt. 大众点评用户饮食评论数据.
[2] 岳子静, 章成志, 周清清. dishdata.txt. 美食杰菜肴数据.
| [1] |
The Anthropology of Food and Eating [J].https://doi.org/10.2307/4132873 URL [本文引用: 1] 摘要
The study of food and eating has a long history in anthropology, beginning in the nineteenth century with Garrick Mallery and William Robertson Smith. This review notes landmark studies prior to the 1980s, sketching the history of the subfield. We concentrate primarily, however, on works published after 1984. We contend that the study of food and eating is important both for its own sake since food is utterly essential to human existence (and often insufficiently available) and because the subfield has proved valuable for debating and advancing anthropological theory and research methods. Food studies have illuminated broad societal processes such as political-economic value-creation, symbolic value-creation, and the social construction of memory. Such studies have also proved an important arena for debating the relative merits of cultural and historical materialism vs. structuralist or symbolic explanations for human behavior, and for refining our understanding of variation in informants' responses to ethnographic questions. Seven subsections examine classic food ethnographies: single commodities and substances; food and social change; food insecurity; eating and ritual; eating and identities; and instructional materials. The richest, most extensive anthropological work among these subtopics has focused on food insecurity, eating and ritual, and eating and identities. For topics whose anthropological coverage has not been extensive (e.g., book-length studies of single commodities, or works on the industrialization of food systems), useful publications from sister disciplines-primarily sociology and history-are discussed.
|
| [2] |
Cuisine and Culture: A History of Food and People [M].
|
| [3] |
Food & Philosophy: Eat, Think, and Be Merry [M]. |
| [4] |
Human Food Preferences and Cultural Identity: The Case of Aragón (Spain) [J].https://doi.org/10.1080/00207594.2012.692792 URL PMID: 22916705 [本文引用: 3] 摘要
Abstract This research aims to analyze the relationship between sociocultural values and human food preferences. The latter, as shown in this paper, are greatly influenced by cultural identity. This work stems from a theoretical context that originated in Europe and the United States towards the mid-twentieth century, within the field of the anthropology of food. A qualitative and quantitative analysis has been performed in the Comunidad Aut0106noma de Arag0106n (Spain). Research methods include focus groups, in-depth interviews, participant observation, and a questionnaire that was handed out to a representative sample of the Aragonese population (816 people over 21 years of age; confidence level of 95.5% and error margin of 00±3.5). Regarding the research outcome, a highly significant qualitative and quantitative connection has been found between food selection and cultural identity. In other words, people prefer to consume foods that are symbolically associated with their own culture, in order to reinforce their sense of belonging. Although this study has been carried out in Arag0106n, it is our belief that the results can be generalized to other areas. The originality and interest of our findings are notable considering that, to date, few works have analyzed the sociocultural factors motivating food behavior. Moreover, these results could be used by public and private organizations to meet objectives such as health promotion and product marketing.
|
| [5] |
吸烟人群饮食习惯引起的吸烟(烟气)偏好分析 [J].Smoking (Mainstream Smoke) Preference Caused by Dietary Habit in Chinese Cigarette Smokers [J]. |
| [6] |
孤独症儿童饮食谱及食物偏好研究 [J].https://doi.org/10.3760/cma.j.issn.1674-6554.2014.05.009 URL [本文引用: 3] 摘要
目的 探究孤独症儿童食物偏好的特点,通过对其异常饮食行为原因的分析,为其异常饮食行为的改善途径提供参考.方法 采用自编家长问卷的形式,对162例正常发育儿童以及162例孤独症儿童在中国常见的六大类共113种食物进行食物偏好调查.结果 1.研究发现对于谷薯类[正常儿童拒绝0.0(1.0)种,孤独症儿童拒绝1.0(2.0)种,P<0.001]、豆类[正常儿童拒绝0.0(1.0)种,孤独症儿童拒绝0.0(2.0)种,P<0.05]、肉类[正常儿童拒绝0.0(0.0)种,孤独症儿童拒绝0.0(2.0)种,P<0.05]、蔬菜类[正常儿童拒绝3.0(5.0)种,孤独症儿童拒绝6.0(10.0)种,P<0.001]和水果类[正常儿童拒绝0.0(1.0)种,孤独症儿童拒绝2.0(5.0)种,P<0.001]的食物,孤独症儿童拒绝的食物种类都显著多于正常儿童,差异有统计学意义;2.在正常儿童中性别并不影响其食物偏好,而孤独症儿童中男孩在谷薯类[孤独症女孩拒绝0.0(1.0)种,孤独症男孩拒绝1.0(2.0)种,P<0.05]和蔬菜类[孤独症女孩拒绝3.5(5.0)种,孤独症男孩拒绝7.0(11.0)种,P<0.05]选择中比女孩更加挑剔;3.对于绝大多数的食物,孤独症儿童的接受度都显著低于正常儿童,而却对方便面(正常儿童接受度71.01%,孤独症儿童接受度81.02%,P<0.001)和辣椒(正常儿童接受度20.71%,孤独症儿童接受度28.47%,P<0.05)有着特殊的偏好.结论 与正常儿童相比,孤独症儿童的饮食谱狭窄;对辣椒和方便面这两种刺激性食物则有着更高的接受度.
The Food Repertoire and Food Preference in Children with Autism Spectrum Disorder [J].https://doi.org/10.3760/cma.j.issn.1674-6554.2014.05.009 URL [本文引用: 3] 摘要
目的 探究孤独症儿童食物偏好的特点,通过对其异常饮食行为原因的分析,为其异常饮食行为的改善途径提供参考.方法 采用自编家长问卷的形式,对162例正常发育儿童以及162例孤独症儿童在中国常见的六大类共113种食物进行食物偏好调查.结果 1.研究发现对于谷薯类[正常儿童拒绝0.0(1.0)种,孤独症儿童拒绝1.0(2.0)种,P<0.001]、豆类[正常儿童拒绝0.0(1.0)种,孤独症儿童拒绝0.0(2.0)种,P<0.05]、肉类[正常儿童拒绝0.0(0.0)种,孤独症儿童拒绝0.0(2.0)种,P<0.05]、蔬菜类[正常儿童拒绝3.0(5.0)种,孤独症儿童拒绝6.0(10.0)种,P<0.001]和水果类[正常儿童拒绝0.0(1.0)种,孤独症儿童拒绝2.0(5.0)种,P<0.001]的食物,孤独症儿童拒绝的食物种类都显著多于正常儿童,差异有统计学意义;2.在正常儿童中性别并不影响其食物偏好,而孤独症儿童中男孩在谷薯类[孤独症女孩拒绝0.0(1.0)种,孤独症男孩拒绝1.0(2.0)种,P<0.05]和蔬菜类[孤独症女孩拒绝3.5(5.0)种,孤独症男孩拒绝7.0(11.0)种,P<0.05]选择中比女孩更加挑剔;3.对于绝大多数的食物,孤独症儿童的接受度都显著低于正常儿童,而却对方便面(正常儿童接受度71.01%,孤独症儿童接受度81.02%,P<0.001)和辣椒(正常儿童接受度20.71%,孤独症儿童接受度28.47%,P<0.05)有着特殊的偏好.结论 与正常儿童相比,孤独症儿童的饮食谱狭窄;对辣椒和方便面这两种刺激性食物则有着更高的接受度.
|
| [7] |
基于社会网络分析的移动环境下网络舆情信息传播研究——以新浪微博“雾霾”话题为例 [J].https://doi.org/10.13266/j.issn.0252-3116.2015.07.002 URL [本文引用: 1] 摘要
[目的/意义]研究移动互联网络环境下舆情信息传播路径和传播规律,为相关部门加强社会舆情信息监管提供参考。[方法/过程]在理论研究层面,基于社会网络分析法,从点度中心性、中间中心性和接近中心性3个属性出发,对移动端和非移动端雾霾网络舆情信息传播进行对比分析;在应用研究层面,以新浪微博中雾霾话题信息为例,采用Java编程方式接入新浪网API开放平台获取新浪微博数据,使用Gephi软件及数理统计分析工具绘制有关图表。[结果/结论]揭示了移动环境下网络舆情信息传播特点,验证了社会网络分析法在移动环境下网络舆情信息传播研究中的有效性,并为移动环境下网络舆情信息传播的研究提供了新的研究视角,为实践层面移动环境下网络舆情信息监管提供了分析工具。
The Study of Network Public Opinion Dissemination with Social Network Analysis Under the Mobile Environment: A Case of “Haze” in Sina Micro-blog [J].https://doi.org/10.13266/j.issn.0252-3116.2015.07.002 URL [本文引用: 1] 摘要
[目的/意义]研究移动互联网络环境下舆情信息传播路径和传播规律,为相关部门加强社会舆情信息监管提供参考。[方法/过程]在理论研究层面,基于社会网络分析法,从点度中心性、中间中心性和接近中心性3个属性出发,对移动端和非移动端雾霾网络舆情信息传播进行对比分析;在应用研究层面,以新浪微博中雾霾话题信息为例,采用Java编程方式接入新浪网API开放平台获取新浪微博数据,使用Gephi软件及数理统计分析工具绘制有关图表。[结果/结论]揭示了移动环境下网络舆情信息传播特点,验证了社会网络分析法在移动环境下网络舆情信息传播研究中的有效性,并为移动环境下网络舆情信息传播的研究提供了新的研究视角,为实践层面移动环境下网络舆情信息监管提供了分析工具。
|
| [8] |
面向主题的微博热门话题舆情监测研究——以“北京单双号限行常态化”舆情分析为例 [J].https://doi.org/10.3969/j.issn.1003-0077.2015.05.019 URL Magsci [本文引用: 1] 摘要
社交媒体舆情监测是社交媒体分析的热点研究问题,学界和工业界取得了很多研究成果。但目前针对热门话题舆情监测研究中,往往只在整体上关注事件舆情趋势,而没有对事件内部不同的讨论主题进行分析。鉴于此,该研究将主题分类模型引入到舆情监测中来,并在此基础上,以时间为脉络进行面向主题的情感分析。并以“北京市单双号限行常态化”这一微博话题为例进行实证研究,通过各个时段 “北京市单双号限行常态化”这一微博话题群体情感倾向变化的分析,为舆情的监测提供对象和时点选择的参考建议。<br/>
Research on Topic-oriented Supervision of Public Sentiment Towards Heated Weibo Events ——A Case Study of “Implementing 'Odd-Even' Vehicle Restriction on a Regular Basis” [J].https://doi.org/10.3969/j.issn.1003-0077.2015.05.019 URL Magsci [本文引用: 1] 摘要
社交媒体舆情监测是社交媒体分析的热点研究问题,学界和工业界取得了很多研究成果。但目前针对热门话题舆情监测研究中,往往只在整体上关注事件舆情趋势,而没有对事件内部不同的讨论主题进行分析。鉴于此,该研究将主题分类模型引入到舆情监测中来,并在此基础上,以时间为脉络进行面向主题的情感分析。并以“北京市单双号限行常态化”这一微博话题为例进行实证研究,通过各个时段 “北京市单双号限行常态化”这一微博话题群体情感倾向变化的分析,为舆情的监测提供对象和时点选择的参考建议。<br/>
|
| [9] |
基于在线评论的个性化推荐系统 [D].Personalized Recommendation System Based on Online Reviews [D]. |
| [10] |
一种融合个性化与多样性的人物标签推荐方法 [J].
针对人物标签推荐中多样性及推荐标签质量问题,该文提出了一种融合个性化与多样性的人物标签推荐方法。该方法使用主题模型对用户关注对象建模,通过聚类分析把具有相似言论的对象划分到同一类簇;然后对每个类簇的标签进行冗余处理,并选取代表性标签;最后对不同类簇中的标签融合排序,以获取Top-K个标签推荐给用户。实验结果表明,与已有推荐方法相比,该方法在反映用户兴趣爱好的同时,能显著提高标签推荐质量和推荐结果的多样性。
User Tag Recommendation with Personalization and Diversity [J].
针对人物标签推荐中多样性及推荐标签质量问题,该文提出了一种融合个性化与多样性的人物标签推荐方法。该方法使用主题模型对用户关注对象建模,通过聚类分析把具有相似言论的对象划分到同一类簇;然后对每个类簇的标签进行冗余处理,并选取代表性标签;最后对不同类簇中的标签融合排序,以获取Top-K个标签推荐给用户。实验结果表明,与已有推荐方法相比,该方法在反映用户兴趣爱好的同时,能显著提高标签推荐质量和推荐结果的多样性。
|
| [11] |
中文博客多方面话题情感分析研究 [J].https://doi.org/10.3969/j.issn.1003-0077.2013.01.007 URL Magsci [本文引用: 1] 摘要
博客是Web环境中个人表达观点和情感的一种重要载体,一般涉及较宽泛的话题,蕴含丰富的舆情信息。现有针对有关社会事件的用户产生内容进行情感分析的研究多数以篇章级为处理粒度,尚不能满足博客文本深度情感分析的需求。该文提出一种基于LDA话题模型与Hownet词典的中文博客多方面话题情感分析方法。该方法首先利用数据语料训练LDA话题模型,然后以滑动窗口为基本处理单位,利用训练好的LDA模型对博客文本进行话题识别与划分;在此基础上,基于Hownet词典对划分后的话题段落进行情感倾向计算。该方法有助于同时识别博客文本所涉及的多方面子话题及每个子话题上的情感倾向。实验结果表明,该方法不仅能获得较好的话题划分结果,也有助于改善情感分析的准确率。
Multi-aspect Topic Sentiment Analysis of Chinese Blog [J].https://doi.org/10.3969/j.issn.1003-0077.2013.01.007 URL Magsci [本文引用: 1] 摘要
博客是Web环境中个人表达观点和情感的一种重要载体,一般涉及较宽泛的话题,蕴含丰富的舆情信息。现有针对有关社会事件的用户产生内容进行情感分析的研究多数以篇章级为处理粒度,尚不能满足博客文本深度情感分析的需求。该文提出一种基于LDA话题模型与Hownet词典的中文博客多方面话题情感分析方法。该方法首先利用数据语料训练LDA话题模型,然后以滑动窗口为基本处理单位,利用训练好的LDA模型对博客文本进行话题识别与划分;在此基础上,基于Hownet词典对划分后的话题段落进行情感倾向计算。该方法有助于同时识别博客文本所涉及的多方面子话题及每个子话题上的情感倾向。实验结果表明,该方法不仅能获得较好的话题划分结果,也有助于改善情感分析的准确率。
|
| [12] |
Sharing Feelings Online: Studying Emotional Well-being via Automated Text Analysis of Facebook Posts [J].
Digital traces of activity on social network sites represent a vast source of ecological data with potential connections with individual behavioral and psychological characteristics. The present study investigates the relationship between user-generated textual content shared on Facebook and emotional well-being. Self-report measures of depression, anxiety, and stress were collected from 201 adult Facebook users from North Italy. Emotion-related textual indicators, including emoticon use, were extracted form users' Facebook posts via automated text analysis. Correlation analyses revealed that individuals with higher levels of depression, anxiety expressed negative emotions on Facebook more frequently. In addition, use of emoticons expressing positive emotions correlated negatively with stress level. When comparing age groups, younger users reported higher frequency of both emotion-related words and emoticon use in their posts. Also, the relationship between online emotional expression and self-report emotional well-being was generally stronger in the younger group. Overall, findings support the feasibility and validity of studying individual emotional well-being by means of examination of Facebook profiles. Implications for online screening purposes and future research directions are discussed.
|
| [13] |
Social-Media-based Public Policy Informatics: Sentiment and Network Analyses of U.S. Immigration and Border Security [J].https://doi.org/10.1002/asi.23449 URL [本文引用: 1] 摘要
Social media provide opportunities for policy makers to gauge pubic opinion. However, the large volumes and variety of expressions on social media have challenged traditional policy analysis and public sentiment assessment. In this article, we describe a framework for social-media-based public policy informatics and a system called iMood that addresses the needs for sentiment and network analyses of U.S. immigration and border security. iMood collects related messages on Twitter, extracts user sentiment and emotion, and constructs networks of the Twitter users, helping policy makers to identify opinion leaders, influential users, and community activists. We evaluated the sentiment, emotion, and network characteristics found in 909,035 tweets posted by over 300,000 users during three phases between May and November 2013. Statistical analyses reveal significant differences in emotion and sentiment among the 3 phases. The Twitter networks of the 3 phases also had significantly different relationship counts, network densities, and total influence scores from those of other phases. This research should contribute to developing a new framework and a new system for social-media-based public policy informatics, providing new empirical findings and data sets of sentiment and network analyses of U.S. immigration and border security, and demonstrating a general applicability to different domains.
|
| [14] |
An Analysis of User-Generated Content for Hotel Experiences [J].https://doi.org/10.1108/JHTT-01-2013-0001 URL [本文引用: 1] 摘要
ABSTRACT Purpose ‐ The broad goal of the study is to determine how travelers communicate in the cyberspace in relation to their positive and negative experiences they had when staying in a particular hotel. Further goals of this study include identifying the main themes that motivate consumers to evaluate hotel experiences in online environments and categorize the most frequently mentioned areas in the online hotel reviews. Design/methodology/approach ‐ Content analysis techniques were applied by using the software tool NVivo 8 in order to analyze comments extracted using an automated web spider. The spider extracted qualitative data in the form of reviews and comments and quantitative data in the form of demographic information and ratings. The reviews were considered as a primary data for analysis, these reviews portrayed both positive and negative experiences. During this process, the spider collected data on 3,124 hotels and 17,357 traveler reviews from the TripAdvisor site. Findings ‐ By reviewing and understanding traveler comments of their hotel experiences, managers could gain knowledge concerning which element influence to form a positive brand image. Cleanliness of the hotel generally is a common concern in traveler's expectations. Words about deficiency of cleanliness (dirty) appeared more regularly when travelers write negative reviews about the hotel. Travelers showed to be more likely to write positive reviews of hotels with convenient location to good areas such as attractions, shopping, airports, and restaurants. The data in this research shows that travelers can be positively influenced by quality of service received a friendly and well trained staff. When travelers are pleased with the quality of human contact offerings of a well-trained employee, they tend to feel more satisfied and to form a positive brand image that it is translated into a positive review. Research limitations/implications ‐ Limitations could be listed using a relatively small sample size, and a relatively limited geographical capacity. Future studies are advised to include bigger sample sizes and also advised to explore a diverse pool of geographical. Originality/value ‐ The study identifies the possible areas that hoteliers need to pay close attention to improve service. Further, it is one of the first studies in hospitality that highlights strategies to create and reinforce brand image by using online reviews.
|
| [15] |
基于社区发现的移动自媒体用户兴趣建模 [D].User Interest Modeling for Mobile We Media Based on Community Discovery [D]. |
| [16] |
利用作者主题模型进行图书馆UGC的主题发现与演化研究 [J].Topic Detection and Evolution of Library User Generated Content Based on Author-Topic Model [J]. |
| [17] |
面向在线社交网络用户生成内容的饮食话题发现研究 [J].Identifying Food Topics from User-Generated Contents in Microblogs [J]. |
| [18] |
Inferring User Consumption Preferences from Social Media [J].https://doi.org/10.1587/transinf.2016EDP7265 URL [本文引用: 1] 摘要
Social Media has already become a new arena of our lives and involved different aspects of our social presence. Users' personal information and activities on social media presumably reveal their personal interests, which offer great opportunities for many e-commerce applications. In this paper, we propose a principled latent variable model to infer user consumption preferences at the category level (e.g. inferring what categories of products a user would like to buy). Our model naturally links users' published content and following relations on microblogs with their consumption behaviors on e-commerce websites. Experimental results show our model outperforms the state-of-the-art methods significantly in inferring a new user's consumption preference. Our model can also learn meaningful consumption-specific topics automatically.
|
| [19] |
Practices and Preferences: Exploring the Relationships Between Food-related Parenting Practices and Child Food Preferences for High Fat and/or Sugar Foods, Fruits, and Vegetables [J].https://doi.org/10.1016/j.appet.2017.02.019 URL PMID: 28235620 [本文引用: 1] 摘要
Abstract The purpose of this study was to determine the relationship between food-related parenting practices and child fruit, vegetable, and high fat/sugar food preferences. Parents (n0002=0002148) of children (3-7 years old) completed the Comprehensive Feeding Practices Questionnaire (CFPQ), the Preschool Adapted Food Liking Scale (PALS), and answered demographic questions. Separate linear regressions were conducted to test relationships between the different food categories on PALS (fruits, vegetables, and high fat/sugar foods) and each food-related parenting practice using race, ethnicity, and income level, and child age and gender as covariates. It was found that when a parent allows a child to control eating, it was negatively associated with a child's preference for fruit (02050002=0002-0.15, p0002=00020.032) and parent encouragement of child involvement in meal preparation was positively related to child preference for vegetables (02050002=00020.14, p0002=00020.048). Children preferred high fat and sugar foods more if parents used food to regulate child emotions (02050002=00020.24, p0002=00020.007), used food as a reward (02050002=00020.32, p0002<00020.001), pressured the child to eat more food (02050002=00020.16, p0002=00020.045), and restricted unhealthy food (02050002=00020.20, p0002=00020.024). Conversely, children preferred high fat and sugar foods less if parents made healthy food available in the home (02050002=0002-0.13, p0002=00020.05), modeled healthy eating in front of the child (02050002=0002-0.21, p0002=00020.021), and if parents explained why healthy foods should be consumed (02050002=0002-0.24, p0002=00020.011). Although it cannot be determined if the parent is influencing the child or vice versa, this study provides some evidence that coercive feeding practices are detrimental to a child's food preferences. Copyright 0008 2017 Elsevier Ltd. All rights reserved.
|
| [20] |
基于依存句法分析的社会媒体文本挖掘方法——以饮食习惯特色分析为例 [J].
在进行社会媒体文本挖掘时,传统的基于词表的方法,存在准确率较低、词表难获得等问题。该文提出一种基于依存句法分析的文本挖掘方法,通过规则匹配的方式从社会媒体文本中提取信息。该方法不依赖词表,且实验证明了相比基于词表的方法在准确率上有大幅提高。应用基于依存句法分析的文本挖掘方法,我们在微博文本上进行了饮食习惯特色分析,实现了性别、地区、时间等维度的饮食习惯特色分析并可进行交叉分析,最终用词云的方式展示了结果。
Dependency Parsing-Based Social Media Text Mining ——A Case Study in Analysis of Weibo Users’ Eating Habits [J].
在进行社会媒体文本挖掘时,传统的基于词表的方法,存在准确率较低、词表难获得等问题。该文提出一种基于依存句法分析的文本挖掘方法,通过规则匹配的方式从社会媒体文本中提取信息。该方法不依赖词表,且实验证明了相比基于词表的方法在准确率上有大幅提高。应用基于依存句法分析的文本挖掘方法,我们在微博文本上进行了饮食习惯特色分析,实现了性别、地区、时间等维度的饮食习惯特色分析并可进行交叉分析,最终用词云的方式展示了结果。
|
| [21] |
基于微博的用户饮食特色及表达习惯分析 [D].Analysis of Diet Habits and Diet Expression Habits Based on Microblog [D]. |
| [22] |
Geography and Similarity of Regional Cuisines in China [J].https://doi.org/10.1371/journal.pone.0079161 URL PMID: 3832477 [本文引用: 2] 摘要
Food occupies a central position in every culture and it is therefore of great interest to understand the evolution of food culture. The advent of the World Wide Web and online recipe repositories have begun to provide unprecedented opportunities for data-driven, quantitative study of food culture. Here we harness an online database documenting recipes from various Chinese regional cuisines and investigate the similarity of regional cuisines in terms of geography and climate. We find that geographical proximity, rather than climate proximity, is a crucial factor that determines the similarity of regional cuisines. We develop a model of regional cuisine evolution that provides helpful clues for understanding the evolution of cuisines and cultures.
|
| [23] |
Using Twitter Data for Food-related Consumer Research: A Case Study on “What People Say When Tweeting about Different Eating Situations” [J].https://doi.org/10.1016/j.foodqual.2015.05.006 URL [本文引用: 1] 摘要
Twitter data is emerging as a source of insight regarding food-related consumer behaviour, and as such merit consideration regarding inclusion in the set of methodologies used by sensory and consumer researchers. Contributing to the evaluation of the pros/cons of Twitter as a research tool, we present a case study on the topic: “what people say when they tweet about different eating situations”. Rather than focusing on specific food/beverage products, we consider eating/drinking more widely, and hereby adopt a broader lens through which to evaluate this data gathering platform. Using the search words breakfast , lunch , dinner and snack , a total of 69,961 tweets were retrieved, of which 48,746 corresponded to original tweets and were subject to automated word analysis. However, manual content analysis of a subset of 16,000 tweets randomly selected provided more detailed insight. Mirroring results from past food choice research, information about what was consumed, when, where, with whom, and why was contained within the tweets, hereby confirming the potential of Twitter data as a source of information about food choice decisions. Despite access to free data, labour costs associated with data analysis were high and other limitations were also identified. While the content of tweets was largely free of written emotional expressions, emoticons were used with greater frequency. Some tweets also contained references to the (un)healthiness of foods/beverages being consumed and may be useful for exploring consumer perceptions of health/wellbeing, a topic which, like emotions, is currently attracting considerable attention. Overall, we find that Twitter data merit inclusion in the researcher’s toolbox, but that it is no panacea.
|
| [24] |
You Tweet What You Eat: Studying Food Consumption Through Twitter [C]// |
| [25] |
利用在线评论挖掘用户饮食偏好——以北京地区为例 [J].Mining User Diet Preference with Online Reviews——A Case Study of Beijing City [J]. |
| [26] |
Introduction to the Theory of Statistics [M]. |
| [27] |
融合结构与内容特征的微博沉默用户兴趣模型构建研究 [J].https://doi.org/10.3772/j.issn.1000-0135.2015.011.010 URL [本文引用: 1] 摘要
用户的参与度与活跃度是微博平台影响力与价值的决定性因素。然而微博中“沉默用户”群体日益庞大,为了有效地激发该类用户的参与热情,提高其活跃度,就需要以其兴趣偏好为基础,进行个性化推荐。本文试图通过构建沉默用户兴趣模型,来充分挖掘其兴趣分布状况,以沉默用户的好友之间的关注关系形成的社会网络为基础,提出融合微博结构特征和内容特征的兴趣模型构建方法,分别运用基于聚类的社群分析方法Concor算法以及LDA主题模型,来实现该用户群体不同粒度层次的兴趣主题发现,并引入信息熵的概念,对同一层次上的兴趣偏好进行量化和排序,最终实现沉默用户兴趣模型的构建。通过在新浪微博真实数据上进行实验,验证了本模型的有效性及准确性。
Research of Silent User Interest Modeling in Microblog Based on the Features of Structure and Content [J].https://doi.org/10.3772/j.issn.1000-0135.2015.011.010 URL [本文引用: 1] 摘要
用户的参与度与活跃度是微博平台影响力与价值的决定性因素。然而微博中“沉默用户”群体日益庞大,为了有效地激发该类用户的参与热情,提高其活跃度,就需要以其兴趣偏好为基础,进行个性化推荐。本文试图通过构建沉默用户兴趣模型,来充分挖掘其兴趣分布状况,以沉默用户的好友之间的关注关系形成的社会网络为基础,提出融合微博结构特征和内容特征的兴趣模型构建方法,分别运用基于聚类的社群分析方法Concor算法以及LDA主题模型,来实现该用户群体不同粒度层次的兴趣主题发现,并引入信息熵的概念,对同一层次上的兴趣偏好进行量化和排序,最终实现沉默用户兴趣模型的构建。通过在新浪微博真实数据上进行实验,验证了本模型的有效性及准确性。
|
| [28] |
Domain Specific Word Extraction from Hierarchical Web Documents: A First Step Toward Building Lexicon Trees from Web Corpora [C]// |
| [29] |
A Vector Space Model for Automatic Indexing [J].https://doi.org/10.1145/361219.361220 URL [本文引用: 1] |
| [30] |
Term-weighting Approaches in Automatic Text Retrieval [J].https://doi.org/10.1016/0306-4573(88)90021-0 URL [本文引用: 1] 摘要
The experimental evidence accumulated over the past 20 years indicates that text indexing systems based on the assignment of appropriately weighted single terms produce retrieval results that are superior to those obtainable with other more elaborate text representations. These results depend crucially on the choice of effective termweighting systems. This article summarizes the insights gained in automatic term weighting, and provides baseline single-term-indexing models with which other more elaborate content analysis procedures can be compared.
|
| [31] |
作者合著网络中研究兴趣相似性实证研究 [J].https://doi.org/10.13266/j.issn.0252-3116.2015.02.012 URL [本文引用: 1] 摘要
[目的/意义]从作者微观个体研究兴趣角度出发,通过对作者合著网络中作者关联关键词集的研究,定量地验证研究兴趣相似是作者合作的一个动机。[方法/过程]收集WOS中检索领域相关文献题录信息,构建作者舍著网络,并利用Louvain算法划分社区,实现了Jaccard系数及余弦相似性系数的计算指标,统计与对比分析整体网络及社区内部作者研究兴趣的相似性。[结果/结论]在网络整体层次,作者合著网络中作者的研究兴趣相似性较高,但也存在一定比例的差异性即互补性;在科研牡区内部,合著作者平均研究兴趣相似性及互补性均高于网络整体层次,科研社区的形成受到作者研究兴趣的影响。两个层次的兴趣相似性反映了研究兴趣相似是作者合作的一个重要动机。
Empircal Research on Similarity of Research Interests in Co-authorship Network [J].https://doi.org/10.13266/j.issn.0252-3116.2015.02.012 URL [本文引用: 1] 摘要
[目的/意义]从作者微观个体研究兴趣角度出发,通过对作者合著网络中作者关联关键词集的研究,定量地验证研究兴趣相似是作者合作的一个动机。[方法/过程]收集WOS中检索领域相关文献题录信息,构建作者舍著网络,并利用Louvain算法划分社区,实现了Jaccard系数及余弦相似性系数的计算指标,统计与对比分析整体网络及社区内部作者研究兴趣的相似性。[结果/结论]在网络整体层次,作者合著网络中作者的研究兴趣相似性较高,但也存在一定比例的差异性即互补性;在科研牡区内部,合著作者平均研究兴趣相似性及互补性均高于网络整体层次,科研社区的形成受到作者研究兴趣的影响。两个层次的兴趣相似性反映了研究兴趣相似是作者合作的一个重要动机。
|
| [32] |
用户兴趣相似性度量的关系预测算法 [J].https://doi.org/10.3778/j.issn.1673-9418.1606038 URL [本文引用: 1] 摘要
针对目前研究微博用户兴趣变化时,只考虑用户兴趣的易变性而忽略了用户兴趣持久性的问题,提出了基于用户兴趣相似性的用户关系预测算法。将用户兴趣分为短期兴趣和长期兴趣,用户的文本信息表征为短期兴趣,用户的标签表征为长期兴趣。根据长短期兴趣的特征,采用频率统计和多阶量化的方法度量用户兴趣度并更新用户兴趣状态。最后通过余弦相似性指标计算用户间的兴趣相似度来预测用户关系。实验结果表明,该算法能够准确描述用户兴趣,提高用户关系预测的准确性。
User Relationships Prediction Algorithm with Interest Similarity Measurement [J].https://doi.org/10.3778/j.issn.1673-9418.1606038 URL [本文引用: 1] 摘要
针对目前研究微博用户兴趣变化时,只考虑用户兴趣的易变性而忽略了用户兴趣持久性的问题,提出了基于用户兴趣相似性的用户关系预测算法。将用户兴趣分为短期兴趣和长期兴趣,用户的文本信息表征为短期兴趣,用户的标签表征为长期兴趣。根据长短期兴趣的特征,采用频率统计和多阶量化的方法度量用户兴趣度并更新用户兴趣状态。最后通过余弦相似性指标计算用户间的兴趣相似度来预测用户关系。实验结果表明,该算法能够准确描述用户兴趣,提高用户关系预测的准确性。
|
| [33] |
Introduction to Data Mining [M]. |
| [34] |
Mining and Summarizing Customer Reviews [C]// |
| [35] |
领域依赖的Web信息抽取系统设计与实现 [D].The Design and Implementation of Domain Dependent Web Information Extraction System [D]. |
| [36] |
领域关键词抽取:结合LDA与Word2Vec [D].Keyword Extraction Based on LDA and Word2Vec [D]. |
| [37] |
Learning Distributed Representations of Concepts [C]// |
| [38] |
A Computer Movie Simulating Urban Growth in the Detroit Region [J].https://doi.org/10.2307/143141 URL [本文引用: 1] |

/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}