翟东升, 胡等金 , 张杰, 何喜军, 刘鹤
, 张杰, 何喜军, 刘鹤
北京工业大学经济与管理学院 北京 100124
Zhai Dongsheng, Hu Dengjin, Zhang Jie, He Xijun, Liu He
中图分类号: G350 TP311
通讯作者:
收稿日期: 2017-08-15
修回日期: 2017-09-8
网络出版日期: 2017-12-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】针对如何确定专利发明等级, 提出一种基于机器学习分类算法的专利发明等级分类模型。【方法】从专利文本中提取技术特征词, 利用Word2Vec训练的词向量模型构建专利技术特征向量, 计算专利文本指标和后向引用指标, 构造模型训练数据集, 采用机器学习分类算法构建分类模型。【结果】获取语音识别技术领域相关专利, 对领域专利数据分类, 高等级与低等级发明专利占比约为1︰4, 符合实际情况, 证明了该模型可行性。【局限】由于使用了WordNet 词典, 对于技术特征词汇的抽取会受到词典收录局限的影响。【结论】该模型可以对专利进行发明等级分类, 从而为企业推荐高发明等级的专利。
关键词:
Abstract
[Objective] This paper proposes a new model to process patent information based on machine learning classification algorithm, aiming to determine the level of invention. [Methods] First, we extracted the technology feature words from the patent texts. Then, we constructed the patent technology feature vector with an algorithm trained by Word2Vec. Third, we calculated patent text indicators and backward references to build the training set. Finally, we constructed the new model with machine learning classification algorithm. [Results] We retrieved patents in the field of speech recognition technology with the proposed model. We found that the proportion of advanced level to entry level patents was around 1:4, which was in line with the actual situation. [Limitations] The WordNet dictionary will limit the results of extraction. [Conclusions] The proposed model could effectively identify the advanced patents and recommend them to the business owners.
Keywords:
专利是技术发展创新的源泉, 通过专利分析可以看出一个国家、企业的技术发展水平, 预测技术发展趋势[1]。随着人们对知识产权保护意识的提升和技术自身快速的发展, 其信息数量呈指数增长, 专利信息已成为获取竞争情报的主要信息源。面对海量的专利数据, 如何确定专利发明等级、获取高质量的专利是一个亟待解决的问题。
传统而言, 领域专家在专利分析, 特别是专利文本的解读研究中扮演着极为重要的角色, 基于领域专家经验的分析、评估、预测方法一度成为主流并在目前仍然占据相当重要的地位。基于经验的方法优势是, 能够以获取专家意见的方式, 有针对性并相对准确地对整个行业或具体技术的历史发展、现实状态及未来趋势进行专业的概括和分析, 但同时其缺点也十分明显, 基于经验的方法所使用的数据大多来自专家访谈或各种问卷调查, 不可避免地会受到出卷人及答卷人主观意识的影响, 尽管很多改进工作已经落实在从科学合理的角度尽力规避这些主观因素带来的偏差, 但在实际中采用基于经验的方法仍然是一个相对耗时费力的选择。随着专利数据量的爆炸式增长, 有学者提出一种基于专利前向引用数据的专利发明等级自动分类方法, 但由于前向引用数据需要一定的时间积累, 所以无法对近期的专利进行正确的分类, 因此在面对较新的数据时会出现分类不准的情况。
综上, 基于专家经验和基于专利前向引用数据自动分类方法在海量专利数据环境下存在低效及判断不准的弊端。本研究从专利的文本数据和后向引用数据出发, 利用词向量技术处理专利文本数据, 构建专利技术特征向量, 计算文本指标和后向引用指标, 并提出一种基于机器学习分类算法的专利发明等级分类模型, 提高了专利发明等级自动分类模型的准确率。
词向量作为深度学习模型中一种词的分布式表达(Distributed Representation), 能够解决数据稀疏对统计建模的影响, 克服维数灾难[2], 采用词的分布式表达来表示词向量最早由Hinton提出[3], 也称之为Word Representation或Word Embedding。词向量主要依靠近几年应用比较普遍的Word2Vec 技术实现[4-5]。
Word2Vec[6]是Google公司的Mikolov等在2013年开源的一个将词汇表示为实数向量的工具。其核心理念是通过训练将词汇对应到N维的实数向量, 而两个词向量之间的距离(余弦距离或欧式距离)表示它们对应词汇在语义上的相似程度。Word2Vec采用连续词袋模型(Continuous Bag-Of-Words, CBOW)和Skip- Gram 两种计算模型。
通过计算Word2Vec向量, 可以将文本中的词汇映射到一个N维的空间中, 从而很多自然语言处理任务可以由之前对文本的处理, 转换成为对N维向量的运算, 这种对非结构数据转换成为统一长度的数值的方法为自然语言处理带来了更多的可能性。向量空间中词汇的位置代表了其语义在空间中的位置, 在空间中距离相近的词汇之间可以认为词义相近。已经有很多研究将Word2Vec词向量应用到自然语言处理任务中, 包括文本的分类、聚类, 同义词寻找, 词性分析等。而Word2Vec最被人们称赞的特性是其向量具备的加法组合运算(Additive Compositionality), 这种特性使得词汇的从语义层面具备可计算性, 加法组合运算的例子为:
vector('Berlin')-vector('Germany')+vector('England')≈vector('London')
在TRIZ理论中, 阿奇舒勒[7]根据发明专利对科学的贡献程度、技术的应用范围和对人类社会的贡献情况将发明划分为5个等级, 具体如表1所示。
表1 TRIZ 发明5级分类表
| 等级 | 描述 | 实验次数 | 专利百分比 |
|---|---|---|---|
| 1 | 1级发明不会消除冲突, 是最小的发明。1级意味着其方法驻留与一个单一的行业的边界, 并且是通过一个相关工程学科掌握的禁言来处理。 | 1-10 | 32.0% |
| 2 | 所解决的问题涉及技术, 该问题通过相关系统的工程学科已知方法可以很容易解决。 | 10-100 | 45.0% |
| 3 | 一个冲突驻留于同一学科的边界(或者说通过同一科学知识就能解决它)。 | 100-1000 | 19.0% |
| 4 | 一个新的技术系统被合成。由于新的系统没有提及解决技术冲突, 或许这个新的发明没有克服该冲突。事实上, 冲突是存在的, 但是他们和旧的技术系统是相关的。在4级发明中, 冲突通过原理问题所属的科学边界来被消除。 | 1000-10000 | ≤4.0% |
| 5 | 发明就是一个困难问题的复杂网络。而实验次数的无限增长导致了一种全新的系统。这种发明推出一种新的系统, 随着时间的推移其伴随着各种等级的发明。一种新的技术被创造出来。 | 10000+ | ≤0.3% |
虽然阿奇舒勒[7]提出的5个发明等级是符合逻辑的, 但其并没有给出用于实际操作的判断条件, 而发明等级的判断对于技术发展趋势尤其是技术成熟度的判断十分重要。人工地分析判断TRIZ发明等级是耗费人力和时间的, 还需要内容齐全的文档和熟悉TRIZ理论又熟悉相关领域技术的人员完成[8]。但有少量研究尝试自动地对专利发明等级进行分类。
王艳领[9]通过分析专利技术, 提出一种专利指标体系, 应用层次分析方法对专利指标进行具体的分析, 获得每个指标的权重, 通过指标与权重相乘获得专利最终的发明等级, 并使用该方法对美国的电冰箱专利进行等级划分。
Regazzoni等[10]通过每年各IPC小类(即IPC前4位)专利的增长数量, 定义“知识产权密度”(Intellectual Property Density, IPD), IPD指标可以表征具体IPC分类技术下的专利聚集程度, 绘制IPD的逐年累计曲线图可以定义“突破事件年份”(Break Year Event, BYE), 并根据这个年份判断专利的TRIZ发明等级, 时间在其之前的认为是高等级专利, 在其之后的则认为是低等级专利。但作者也表示BYE的判定不能够通过一个通用的算法确定, 一个有一定专利分析经验的技术人员也可以通过观察专利引用关系图发现BYE。Verbitsky[11]利用文献计量学方法, 将具体技术的专利按时间排列, 以专利序列中具体专利的位置计算其预期引用次数, 如果一个专利的实际被引次数和预期引用次数的比例值r高于一个阈值C, 则认为该专利是一个高等级的专利, 作者也指出比例r和该专利的发明等级不具有线性关系, 这种方法的缺点在于不能判断新兴技术专利的发明等级, 因为新兴技术专利可用的引用数据比较少。
虽然这两种自动评价方法采用不同的指标, 但它们都将专利分成两类: 低等级发明和高等级发明。本研究将使用这种思想, 并且利用专利文本数据判别专利的发明等级。
基于上述研究, 考虑到新兴专利引用数据不足的缺陷和人工标注的困难, 本文使用专利文本数据和后向引用数据作为模型分类特征指标体系, 构建专利发明等级分类模型; 在使用文本数据时需要先抽取技术特征, 然后利用词向量技术将其转化为技术特征向量, 进而计算文本指标。因此, 本文的主要研究内容为专利技术特征向量构建和专利发明等级分类模型两部分。
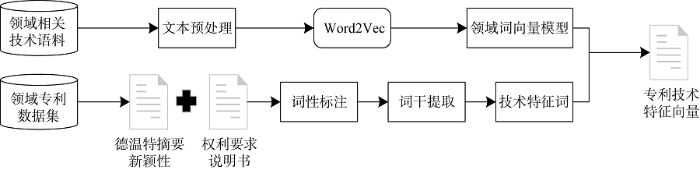
技术特征向量构建思路如图1所示。
(1) 技术特征抽取
根据张惠等[12]对专利组成部分与产品设计知识之间的对应关系的说明以及对主要专利库专利信息分析, 发现技术特征词主要分布在专利的权利要求说明书和德温特专利摘要新颖性部分, 因此从上述两处抽取技术特征词, 技术特征词抽取步骤如下:
①分词/词性标注。首先对专利文本进行英文分词, 然后进行词性标注。本研究使用基于HMM(隐马尔可夫)模型的统计词性标注方法, 该方法在复杂的语义和句法环境下应用广泛, 效果较好[13]。
②词干提取。本研究中将基于规则的Porter词干提取算法[14]和基于词典的词干提取算法[15]相结合, 提出混合词干提取算法, 词典使用的是WordNet, 经验证此方法的准确率得到一定的提升。
③技术特征抽取。根据TRIZ理论的物-场模型以及对专利进行SAO(Subject-Action-Object)结构抽取, 获取技术特征[16-18], 研究发现表征技术特征词汇的词性一般为名词; 这样结合词性标注和词干抽取的结果, 将其中词性为名词(NN)、名词复数(NNS)、专有名词(NNP)的词汇进行抽取并进行词频统计, 形成技术特征词集。
(2) 专利词向量模型训练
用于Word2Vec词向量训练的语料需要满足两个基本要求: 一是大量的文本数量, 二是文本语序正确。为此要对语料进行处理。
①专利文本的预处理: 去除符号; 小写转化; 英文分词; 去除停用词; 词干提取。
②词向量训练: 采用基于Python实现Word2Vec工具的gensim模块来训练词向量(http://radimrehurek.com/gensim/ tut1.html)。在词向量的训练过程中, 本文选择的训练模型是CBOW。具体参数如表2所示。
表2 词向量训练参数设置
| 参数名称 | 含义 | 取值 |
|---|---|---|
| -train | 训练数据 | Patent.txt |
| -output | 词向量输出文件 | Word2vec_model.bin |
| -cbow | 是否使用cbow模型 (1:是, 0:不是) | 1 |
| -size | 词向量维数 | 400 |
| -window | 上下文窗口 | 5-10 |
| -threads | 线程数 | 8 |
| -alpha | 学习速率 | 默认值 |
| -min_count | 单词最小频数 | 5 |
| -Algo | 使用Negative sampling | 是 |
(3) 技术特征向量构建
结合从专利文本中抽取出的技术特征词, 可以构造出技术特征向量, 即专利的技术特征向量是技术特征词的Word2Vec词向量, 每篇专利的技术特征由一个技术向量的集合构成。
专利发明等级分类模型思路如图2所示。
(1) 训练数据集的构建
本研究中训练数据集使用的都是美国专利和商标局(USPTO)的授权专利。专利发明等级分类模型训练时需要对专利进行标注, 采用文献[10-11]的思想将专利划分为高等级发明专利和低等级发明专利, 其中高等级发明专利对应TRIZ发明等级中的3, 4, 5等级, 低等级发明专利对应TRIZ中的1, 2等级。训练数据集构建流程如图3所示。
①实际前向引用与标准前向引用数量比值计算。
文献[11]认为实际的专利前向引用数量如果比其标准前向引用数量大, 则认为该专利为高等级发明专利, 小则为低等级发明专利。由于在本研究中计算标准前向引用专利是为了简化人工标注的过程, 所以根据实际采用前向引用数量和标准前向引用数量的比值, 即:
$r=\frac{A}{C}${Invalid MML} (1)
其中, A为实际前向引用数量, C为标准前向引用数量(具体计算方法此处不赘述, 详见文献[11])。
②自动标注。
按照r值对专利文献排序, r最高的一部分专利为高等级发明专利候选集, r最低的一部分专利为低等级发明专利候选集。
③人工标注。
为了训练集的准确性, 需要领域专家根据自动标注的结果进行人工标注, 从高等级发明专利候选集中筛选出高等级发明专利样本, 从低等级发明专利候选集中筛选出低等级发明样本。根据TRIZ理论中各发明等级的占比情况, 抽取的训练数据中低等级(1级、2级)专利应占训练数据集约77%, 高等级(3级、4级、5级)专利占23%。
(2) 分类特征指标选择
文献[11]使用一种基于前向引用数据判别专利发明等级的方法, 在使用前向引用数据时, 不可避免的缺点在于专利前向引用数据是不全面的, 存在一定的延迟性。所以基于引用数据的专利等级判别方法是无法准确判断新出现的专利发明等级的, 因此本文使用专利文本数据和后向引用数据作为判断专利发明等级的特征来源。
①文本指标
根据TRIZ理论对发明等级的描述, 本文提出一套用专利文本中的技术特征表示知识流动度量专利发明等级的文本指标, 如图4所示。
1)已有技术特征数量, 专利与该技术领域内2年前专利文本相同的特征数量。
$N=|{{F}_{i}}\ \bigcap {{D}_{i}}|$ (2)
其中, i是指当前专利, Fi为当前专利的特征集合, Di为当前专利授权日期前2年的所有同领域专利的特征集合。之所以使用2年前的同技术领域专利是因为考虑到专利申请的延后性。该指标较大的时候说明发明是对已有技术的简单升级或修改, 偏向于低等级发明。
2)引用同小类相同技术特征数量, 专利引用的全部同IPC小类专利(但不包括同技术领域的专利)与该专利共同拥有的特征数量。
${{C}_{small}}=|{{F}_{i}}\ \bigcap {{M}_{i}}|$ (3)
其中, Mi为当前专利引用的具有相同IPC小类的专利特征集合, 该指标较大时, 说明专利使用了十分相关的技术解决了新问题, 但仍属于相关技术领域范畴内, 偏向于低等级发明。
3)引用同大类相同技术特征数量, 专利引用的全部同IPC大类专利(但不包括同技术领域的专利和相同IPC小类的引用专利)与该专利共同拥有的特征数量。
${{C}_{big}}=|{{F}_{i}}\ \bigcap {{B}_{i}}|$ (4)
其中, Bi为当前专利引用有相同IPC大类专利的技术特征集合, 该指标较大时, 说明专利使用了较为相关的技术解决了新问题, 从一定程度上融合了不同领域内的技术, 偏向于高等级发明。
4)引用其他IPC专利的技术特征, 专利引用的其他IPC专利与该专利共同拥有的技术特征数量。
${{C}_{other}}=|{{F}_{i}}\ \bigcap {{B}_{o}}|$ (5)
其中, Bo为当前专利引用不同IPC专利的技术特征集合, 该指标较大时, 说明专利使用不十分相关的技术解决了新问题, 融合了不同领域内的技术, 偏向于高等级发明。
5)新特征数量, 未在引用专利和同领域内2年前专利中出现的特征数量。
$H=|\{f|f\in {{F}_{i}},f\notin ({{D}_{i}}\bigcup {{M}_{i}}\bigcup {{B}_{i}})\}|$ (6)
该指标较大的时候说明发明具有极强的创新性, 偏向于高等级发明。
虽然上述文本指标反映了知识的来源, 但在专利文本中有些词汇被作者多次强调, 可认为这些词汇相对于其他词汇有更高的重要程度。为了量化这一重要程度, 需要对技术特征词汇进行再次筛选, 本文借鉴文本关键词计算过程中TF-IDF值的思想, 使用技术词汇重要性指标。
与文本关键词计算过程相比, 技术词汇重要性指标与其区别在于: 技术词汇重要性指标仅关注专利文档中的技术特征词汇; 技术词汇重要性计算过程中, 具体专利有不同的计算语料, 其语料应当为已有技术专利和引用的专利中的技术词汇, 这是因为考虑到在一个高等级发明专利中, 其高词频的技术词汇新颖性高, 之后的专利也会出现该词, 在计算时影响其重要性, 所以之后的专利文本不应考虑在内。
具体的技术词汇重要性指标计算如下:
$t{{f}_{i,j}}=\frac{{{n}_{i,j}}}{\sum{_{k}{{n}_{k,j}}}}$ (7)
$id{{f}_{i}}=\log \frac{|D|}{1+|\{j:{{t}_{i}}\in {{d}_{j}}\}|}$ {Invalid MML}(8)
$TCM=t{{f}_{i,j}}\times id{{f}_{i}}$ {Invalid MML}(9)
当技术词汇重要性值高于某一阈值时, 即可认为该词汇为关键词。具体的指标计算时, 考虑到不同的专利抽取的技术特征词汇数量不同, 需要对数据进行归一化, 即用各文本特征的数量除以技术特征词汇的数量。
对技术特征词汇再次筛选之后, 就可以使用第3节中技术特征向量的构造方法, 将专利转化为技术特征向量集, 利用技术特征向量集进行上述文本指标的计算。
②后向引用指标
1)同IPC引用比例
${{B}_{ipc}}=\frac{\sum{{{b}_{ipc}}}}{B}$ (10)
其中, B代表专利的后引数量, 下同。该指标较大时, 说明专利引用了较多十分相关的专利内容, 偏向于低等级发明专利。
2)同IPC小类引用比例(不包括IPC完全相同的专利)
${{B}_{subclass}}=\frac{\sum{{{b}_{subclass}}}}{B}$ (11)
该指标较大时, 说明专利引用了较多相关技术的专利的内容, 偏向于低等级发明专利。
3)同IPC大类引用比例(不包括IPC完全相同的专利和同IPC小类的专利)
${{B}_{class}}=\frac{\sum{{{b}_{class}}}}{B}$ (12)
该指标较大时, 说明专利引用了较多相关的专利, 一定程度上对其他技术进行了融合, 偏向于中高等级发明专利。
4)其他大类引用比例
${{B}_{other}}=\frac{\sum{{{b}_{other}}}}{B}$ (13)
该指标较大时, 说明专利引用了较多其他技术领域的专利, 将其他领域内的技术应用到新的问题中, 偏向于中高等级发明专利。
5)原创性指标
${{O}_{i}}=1-{{\sum\limits_{k=1}^{{{n}_{i}}}{\left( \frac{{{b}_{ik}}}{{{b}_{i}}} \right)}}^{2}}$ (14)
其中, i为当前专利, b为第i个专利的引用数量, k为引用专利的小类。一般情况下较大的原创性指标说明发明拥有更广泛的技术基础。
6)引用延迟性指标
${{B}_{lag}}=\sum\limits_{j=1}^{B}{\frac{LA{{G}_{j}}}{B}}$ (15)
其中, LAG代表专利与引用专利之间的时间差, 可以用专利授权时间之间相差的天数进行计算。该指标度量了专利与其引用专利之间平均时间差。相对于其他引用指标, 引用延迟性指标在数值上要远远大于其他指标, 所以有必要对其进行归一化, 在这里可以Z-score标准化方法, 其转化函数为:
${{X}_{norm}}=\frac{X-\mu }{\sigma }$ (16)
其中, $\mu $为具体需归一化的指标(在本文中, 即引用延迟性指标)的均值, $\sigma $为该指标数据的标准差。
(3) 模型训练与评估
本研究使用多种分类算法训练模型, 包括贝叶斯、决策树、随机森林、支持向量机、逻辑回归和人工神经网络。为了评估模型的实际效果, 可将样例根据其真实类别与预测类别的组合划分为真正例(TP)、假正例(FP)、真反例(TN)、假反例(FN)等4种情形。分类结果可以使用混淆矩阵(Confusion Matrix)进行表示, 如表3所示。
查准率P与查全率R分别定义为:
$P=\frac{TP}{TP+FP}$ (17)
$R=\frac{TP}{TP+FN}$ (18)
查准率和查全率是一对矛盾的度量。因此, 人们设计了一些综合考虑查准率、查全率的性能度量。最常用的度量方式是F1, 其计算方式为:
$F1=\frac{2\times P\times R}{P+R}$ (19)
本研究专利数据分为三部分: 语音识别技术专利、引用专利、声学相关专利。所有专利数据均来源于Thomson Innovation专利数据库(简称TI数据库)。其中语音识别技术专利数据共15 435条; 引用专利数据76 234条; 声学相关专利(IPC 为G10)共219 873条。
(1) 技术特征词抽取
按照3.1节所述方法进行技术特征抽取, 以某专利的德温特摘要新颖性部分为例, 其文本如图5所示。
对以上文本的技术特征词抽取结果如图6所示。
(2) 词向量训练
本研究的词向量训练语料来自于声学相关专利数据集, 需要分别对权利要求书和德温特摘要新颖性部分构建两套词向量, 但其文本的预处理与训练过程是相同的, 在本文中以德温特摘要的新颖性部分为例, 介绍词向量的训练过程。
根据3.1节所述文本预处理流程, 对训练语料进行预处理, 以某专利的德温特摘要新颖性部分为例, 其文本见图5, 对其进行文本预处理之后, 生成的词汇列表如图7所示。
对语料库预处理完成之后, 可以使用Word2Vec训练工具gensim进行词向量的训练。训练具体参数如3.1节所述。
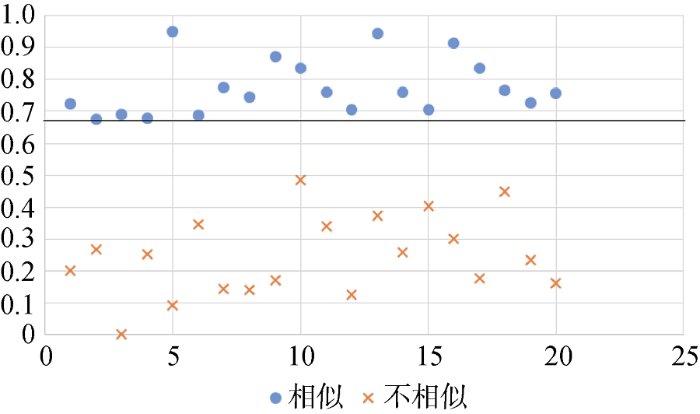
在之后的词向量使用过程中, 需要通过比较两个词向量之间的余弦距离判断两个词在语义上是否相似, 当余弦距离大于阈值时, 有理由相信两个词具有相同的语义。为了判断这个阈值, 本研究使用20组相似语义的词与不相似的词进行比较, 并绘制散点图, 以确定阈值。德温特摘要新颖性部分的散点图如图8所示。
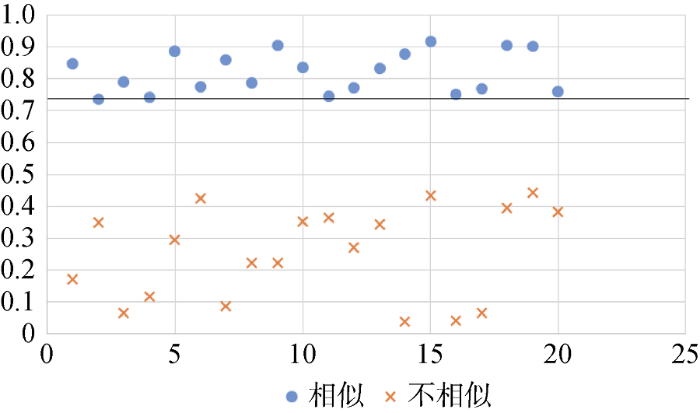
根据图8设定阈值为0.68。权利要求书部分的词向量相似性散点图如图9所示。
根据图9设定阈值为0.74。
(1) 构建训练数据集
本研究将专利的发明等级分为高等级与低等级两种, 使用3.2节专利发明等级标注预处理方法, 对语音识别技术专利进行预处理。通过专家从高质量候选集中筛选出高等级专利351件, 从低质量候选集中筛选出低等级专利1 176件。
(2) 特征计算
专利发明等级分类模型中的指标分为文本指标和引用指标。首先计算其技术词汇重要性, 某专利计算结果如表4所示。
表4 技术词汇重要性结果
| 技术特征词 | 技术词汇重要性 |
|---|---|
| ‘lattice’ | 1.012178089 |
| ‘module’ | 0.40855953 |
| ‘concatenate’ | 0.253707282 |
| ‘multiple’ | 0.209988341 |
| ‘applies’ | 0.165597509 |
| ‘field’ | 0.148309666 |
| …… | …… |
| ‘score’ | 0.095205173 |
| ‘data’ | 0.039488217 |
| ‘speech’ | 0.02694872 |
| ‘recognition’ | 0.018010984 |
根据技术词汇重要性设置一个阈值, 大于该阈值的词汇认为其为关键词, 在本研究中针对德温特摘要新颖性的关键词阈值设置为0.15, 针对权利要求书的关键词阈值设置为0.05, 这是由于权利要求书的篇幅一般较长。
在文本特征计算过程中, 可能会出现同义词的情况, 为了处理这种情况, 使用词向量计算词汇之间的相似度, 在德温特摘要新颖性部分, 两个词汇的余弦相似度大于0.68即视为同义词; 在权利要求书部分, 两个词汇的余弦相似度大于0.74即视为同义词。
本文专利的技术特征来源有4个, 又将特征分为关键技术特征词和普通技术特征词, 加上原创特征, 因此对于每篇专利的权利要求书和德温特摘要新颖性部分都有9个文本特征。表5至表8展示了部分文本特征。后向引用指标表示专利所引用的其他专利的特征, 部分结果如表9所示。
表5 权利要求书关键词的来源分布
| 专利号 | 权利要求书_已有 技术_关键词 | 权利要求书_ 同小类_关键词 | 权利要求书_ 同大类_关键词 | 权利要求书_ 其他_关键词 |
|---|---|---|---|---|
| US20020184373A1 | 0.202702703 | 0.027027 | 0 | 0 |
| US20020161579A1 | 0.239130435 | 0 | 0 | 0.021739 |
| US20010041980A1 | 0.246153846 | 0.015385 | 0 | 0 |
| US20040049388A1 | 0.042857143 | 0.007143 | 0 | 0 |
| US20050143989A1 | 0.141176471 | 0 | 0 | 0 |
| US20060200348A1 | 0.193548387 | 0 | 0 | 0 |
| US20060265225A1 | 0.41025641 | 0 | 0 | 0 |
| US20060293899A1 | 0.212121212 | 0.015152 | 0 | 0 |
| US6205425B1 | 0.257142857 | 0.028571 | 0 | 0 |
| US20030055642A1 | 0.347826087 | 0 | 0 | 0 |
表6 权利要求书普通词的来源分布
| 专利号 | 权利要求书_已有 技术_非关键词 | 权利要求书_同 小类_非关键词 | 权利要求书_同 大类_非关键词 | 权利要求书_ 其他_非关键词 | 权利要求书_ 新词汇 |
|---|---|---|---|---|---|
| US20020184373A1 | 0.581081 | 0.054054 | 0 | 0 | 0.135135 |
| US20020161579A1 | 0.695652 | 0.021739 | 0 | 0 | 0.021739 |
| US20010041980A1 | 0.723077 | 0 | 0 | 0 | 0.015385 |
| US20040049388A1 | 0.935714 | 0.014286 | 0 | 0 | 0 |
| US20050143989A1 | 0.811765 | 0.011765 | 0 | 0 | 0.035294 |
| US20060200348A1 | 0.806452 | 0 | 0 | 0 | 0 |
| US20060265225A1 | 0.589744 | 0 | 0 | 0 | 0 |
| US20060293899A1 | 0.772727 | 0 | 0 | 0 | 0 |
| US6205425B1 | 0.685714 | 0 | 0 | 0 | 0.028571 |
| US20030055642A1 | 0.652174 | 0 | 0 | 0 | 0 |
表7 德温特摘要新颖性部分关键词的来源分布
| 专利号 | 新颖性部分_已有 技术_关键词 | 新颖性部分_同小类_关键词 | 新颖性部分_同大类_ 关键词 | 新颖性部分_其他_关键词 |
|---|---|---|---|---|
| US20020184373A1 | 0.304347826 | 0.043478 | 0 | 0 |
| US20020161579A1 | 0.666666667 | 0 | 0 | 0 |
| US20010041980A1 | 0.545454545 | 0 | 0 | 0 |
| US20040049388A1 | 0.571428571 | 0 | 0 | 0 |
| US20050143989A1 | 0.75 | 0 | 0 | 0 |
| US20060200348A1 | 0.818181818 | 0 | 0 | 0 |
| US20060265225A1 | 0.4375 | 0 | 0 | 0 |
| US20060293899A1 | 0.444444444 | 0 | 0.055556 | 0 |
| US6205425B1 | 0.307692308 | 0.076923 | 0 | 0 |
| US20030055642A1 | 1 | 0 | 0 | 0 |
表8 德温特摘要新颖性部分普通词的来源分布
| 专利号 | 新颖性部分_已有 技术_非关键词 | 新颖性部分_ 同小类_非关键词 | 新颖性部分_同 大类_非关键词 | 新颖性部分_ 其他_非关键词 | 新颖性部分_ 新词汇 |
|---|---|---|---|---|---|
| US20020184373A1 | 0.391304 | 0 | 0 | 0 | 0.26087 |
| US20020161579A1 | 0.333333 | 0 | 0 | 0 | 0 |
| US20010041980A1 | 0.363636 | 0 | 0 | 0 | 0.090909 |
| US20040049388A1 | 0.428571 | 0 | 0 | 0 | 0 |
| US20050143989A1 | 0.25 | 0 | 0 | 0 | 0 |
| US20060200348A1 | 0.181818 | 0 | 0 | 0 | 0 |
| US20060265225A1 | 0.5625 | 0 | 0 | 0 | 0 |
| US20060293899A1 | 0.5 | 0 | 0 | 0 | 0 |
| US6205425B1 | 0.615385 | 0 | 0 | 0 | 0 |
| US20030055642A1 | 0 | 0 | 0 | 0 | 0 |
表9 后向引用指标数据
| 专利号 | 相同IPC比例 | 相同小类比例 | 相同大类比例 | 其他IPC比例 | 原创性指标 | 引用延迟指标 |
|---|---|---|---|---|---|---|
| US20020184373A1 | 0.222222222 | 0.666667 | 0.111111 | 0 | 0.839111 | 1.256112 |
| US20020161579A1 | 0.130434783 | 0.217391 | 0.086957 | 0.565217 | 0.93077 | 0.362692 |
| US20010041980A1 | 0.888888889 | 0.111111 | 0 | 0 | 0.865133 | 0.964108 |
| US20040049388A1 | 0.846153846 | 0.128205 | 0 | 0.025641 | 0.945875 | 0.76467 |
| US20050143989A1 | 0.733333333 | 0.233333 | 0.033333 | 0 | 0.8492 | 0.618055 |
| US20060200348A1 | 0.545454545 | 0.363636 | 0 | 0.090909 | 0.799255 | 0.280562 |
| US20060265225A1 | 0.333333333 | 0.333333 | 0 | 0.333333 | 0.48 | 0.727931 |
| US20060293899A1 | 0.285714286 | 0.285714 | 0.214286 | 0.214286 | 0.925187 | 0.15219 |
| US6205425B1 | 0.333333333 | 0.666667 | 0 | 0 | 0.328125 | 0.646833 |
| US20030055642A1 | 0.444444444 | 0.333333 | 0 | 0.222222 | 0.577402 | 0.361963 |
(3) 模型训练与评价
本研究对比了多种机器学习分类模型算法, 发现人工神经网络更适用于专利发明等级分类模型。各种训练算法的效果如表10所示。
表1 0 各算法性能比较
| 训练算法 | 准确率 | 召回率 | F1值 |
|---|---|---|---|
| 贝叶斯 | 70.40% | 73.20% | 0.7177 |
| 决策树 | 68.30% | 60.20% | 0.6399 |
| 随机森林 | 81.20% | 75.10% | 0.7803 |
| 支持向量机 | 73.90% | 72.70% | 0.7329 |
| 逻辑回归 | 69.40% | 70.50% | 0.6994 |
| 人工神经网络 | 83.50% | 80.10% | 0.8176 |
(4) 专利发明等级分类应用
计算出语音识别技术专利的文本指标和引用指标, 再利用训练好的人工神经网络分类器进行分类, 结果如图10所示。获得高等级专利2 983件, 占全部语音识别技术专利的19.33%, 低等级专利11 538件, 占全部语音识别技术专利的74.75%, 另外有914件专利由于缺失必要数据, 并没有进行分类, 但该部分仅占全部的5.92%, 并不影响整体分析。
本研究针对专利发明等级分类问题, 在基于专利前向引用数据自动分类方法的基础上, 针对新专利前向引用数据不足的问题, 考虑专利文本语义, 通过抽取技术特征词汇, 构建专利技术特征向量, 计算专利的文本指标和后向引用指标, 并采用人工神经网络分类算法进行训练, 提出了专利发明等级分类模型。并在语音识别技术领域进行验证, 证明了该模型的可行性。
本文提出的专利发明等级分类模型虽然能够自动对专利进行标注, 但是只能将专利分成高、低两个等级, 还不够精细, 而且该模型具有领域局限性。未来希望获取大量标注精细的多领域样本数据, 对模型进行训练, 使模型具有更高的精度和普适性。
翟东升: 提出选题及思路, 论文最终版本修订;
翟东升, 胡等金, 张杰, 何喜军: 设计研究方案;
胡等金, 刘鹤: 处理数据, 实现分类模型, 完成实验, 论文起草。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: hudengjin@emails.bjut.edu.cn。
[1] 胡等金, 刘鹤. TrainData.csv. 专利发明等级分类模型训练数据.
[2] 胡等金, 刘鹤. Index.csv. 语音识别技术专利相关指标数据.
[3] 胡等金, 刘鹤. Word2Vec_train.py. 词向量训练源代码.
| [1] |
Better Technology Forecasting Using Systematic Innovation Methods [J].https://doi.org/10.1016/S0040-1625(02)00357-8 URL [本文引用: 1] 摘要
An evolved version of the Soviet-originated Theory of Inventive Problem Solving, TRIZ, contains a series of generically predictable technology and business evolution trends uncovered from the systematic analysis of over 2 million patents, academic journals and business texts. The current state of the art—recorded for the first time together in this paper—now bring the total number of generic technical trends to over 30, and the number of business trends to over 20. The paper describes some of the newly discovered trends, and their incorporation into a design method that allows individuals and businesses to first establish the relative maturity of their current systems, and then, more importantly, to identify areas where ‘evolutionary potential’ exists. The paper introduces this concept of evolutionary potential—defined as the difference between the relative maturity of the current system, and the point where it has reached the limits of each of the evolution trends—through a number of case study examples focused on the design and evolution of complex systems.
|
| [2] |
基于词向量特征的循环神经网络语言模型 [J].https://doi.org/10.16451/j.cnki.issn1003-6059.201504002 URL Magsci [本文引用: 1] 摘要
循环神经网络语言模型能解决传统N-gram模型中存在的数据稀疏和维数灾难问题,但仍缺乏对长距离信息的描述能力.为此文中提出一种基于词向量特征的循环神经网络语言模型改进方法.该方法在输入层中增加特征层,改进模型结构.在模型训练时,通过特征层加入上下文词向量,增强网络对长距离信息约束的学习能力.实验表明,文中方法能有效提高语言模型的性能.
Recurrent Neural Network Language Model Based on Word Vector Features [J].https://doi.org/10.16451/j.cnki.issn1003-6059.201504002 URL Magsci [本文引用: 1] 摘要
循环神经网络语言模型能解决传统N-gram模型中存在的数据稀疏和维数灾难问题,但仍缺乏对长距离信息的描述能力.为此文中提出一种基于词向量特征的循环神经网络语言模型改进方法.该方法在输入层中增加特征层,改进模型结构.在模型训练时,通过特征层加入上下文词向量,增强网络对长距离信息约束的学习能力.实验表明,文中方法能有效提高语言模型的性能.
|
| [3] |
Deep Learning of Representations: Looking Forward [C]// |
| [4] |
Joint Word2Vec Networks for Bilingual Semantic Representations [J].
Abstract. We extend the word2vec framework to capture meaning across languages. The input consists of a source text and a word-aligned parallel text in a second language. The joint word2vec tool then repre- sents words in both languages within a common "semantic" vector space. The result can be used to enrich lexicons of under-resourced languages, to identify ambiguities, and to perform clustering and classification.Experiments were conducted on a parallel English-Arabic corpus, as well as on English and Hebrew Biblical texts.
|
| [5] |
Chinese Sentiment Classification Using a Neural Network Tool—Word2Vec [C]// |
| [6] |
Efficient Estimation of Word Representations in Vector Space [OL].
Abstract: We propose two novel model architectures for computing continuous vector representations of words from very large data sets. The quality of these representations is measured in a word similarity task, and the results are compared to the previously best performing techniques based on different types of neural networks. We observe large improvements in accuracy at much lower computational cost, i.e. it takes less than a day to learn high quality word vectors from a 1.6 billion words data set. Furthermore, we show that these vectors provide state-of-the-art performance on our test set for measuring syntactic and semantic word similarities.
|
| [7] |
|
| [8] |
A Framework for Automatic TRIZ Level of Invention Estimation of Patents Using Natural Language Processing, Knowledge-transfer and Patent Citation Metrics [J].https://doi.org/10.1016/j.cad.2011.12.006 URL Magsci [本文引用: 1] 摘要
Patents provide a wealth of information about design concepts, their physical realization, and their relationship to prior designs in the form of citations. Patents can provide useful input for several goals of next-generation computer-aided design (CAD) systems, yet more efficient tools are needed to facilitate patent search and ranking. In this paper, a novel framework is presented and implemented for classifying patents according to level of invention (LOI) as defined in the theory of inventive problem solving (TRIZ). Level of invention characterizes the creativity of a design concept based on the resolution of a design conflict and the disciplines used in resolving the conflict. The assessment of LOI for a series of patents provides a useful input for screening and ranking patents in databases to identify high-impact patents. However, the manual effort required for assigning LOI to each patent is laborious and time-consuming. In this paper, a novel method that combines text mining, natural language processing, creation of knowledge-transfer metrics, and application of machine learning approaches is presented and implemented for classifying patents according to LOI. Two case studies are presented in which LOI data is compiled for patents: dynamic magnetic information storage or retrieval using Giant Magnetoresistive (GMR) or Colossal Magnetoresistive (CMR) sensors formed of multiple thin films (USPC 360/324) and arbitration for access to a channel (USPC 370/462). The peak performance in 5-fold stratified cross-validation was found to be 73.38% in the first case study and 77.12% for the second.
|
| [9] |
专利等级划分方法的研究与实现 [D].Research and Implementation of the Mean of the Patent Classification [D]. |
| [10] |
TRIZ-Based Patent Investigation by Evaluating Inventiveness[A]// Computer-Aided Innovation (CAI) [M]. |
| [11] |
Semantic TRIZ [R]. |
| [12] |
产品专利设计知识获取方法研究 [J].https://doi.org/10.3969/j.issn.1006-7043.2009.07.012 URL [本文引用: 1] 摘要
为了获得专利文献中的产品功能与结构的相关知识,提出一种基于关 联规则的知识获取方法.通过提取专利文献的权利要求书中特征零部件,分析标题或摘要中的目的功能和手段功能,建立手段功能一特征零部件和目的功能一手段功 能的训练集,并采用作者提出的修剪分类算法提取它们之间的关联规则,获得特征零部件-手段功能-目的功能之间关系的知识,以辅助产品的持续创新.并以冲击 钻为例验证了该方法的有效性.
An Automated Method for Acquiring Design Knowledge from Product Patents [J].https://doi.org/10.3969/j.issn.1006-7043.2009.07.012 URL [本文引用: 1] 摘要
为了获得专利文献中的产品功能与结构的相关知识,提出一种基于关 联规则的知识获取方法.通过提取专利文献的权利要求书中特征零部件,分析标题或摘要中的目的功能和手段功能,建立手段功能一特征零部件和目的功能一手段功 能的训练集,并采用作者提出的修剪分类算法提取它们之间的关联规则,获得特征零部件-手段功能-目的功能之间关系的知识,以辅助产品的持续创新.并以冲击 钻为例验证了该方法的有效性.
|
| [13] |
基于改进的隐马尔科夫模型的词性标注方法 [J].
针对隐马尔可夫(HMM)词性标注模型状态输出独立同分布等与语言实际特性不够协调的假设,对隐马尔可夫模型进行改进,引入马尔可夫族模型。,该模型用条件独立性假设取代HMM模型的独立性假设。将马尔可夫族模型应用于词性标注,并结合句法分析进行词性标注。用改进的隐马尔可夫模型进行词性标注实验。实验结果表明:与条件独立性假设相比,独立性假设是过强假设,因而基于马尔可夫族模型的语言模型更符合语言等实际物理过程;在相同的测试条件下,马尔可夫族模型明显好于隐马尔可夫模型,词性标注准确率从94.642%提高到97.126%。
A Part-of-Speech Tagging Method Based on Improved Hidden Markov Model [J].
针对隐马尔可夫(HMM)词性标注模型状态输出独立同分布等与语言实际特性不够协调的假设,对隐马尔可夫模型进行改进,引入马尔可夫族模型。,该模型用条件独立性假设取代HMM模型的独立性假设。将马尔可夫族模型应用于词性标注,并结合句法分析进行词性标注。用改进的隐马尔可夫模型进行词性标注实验。实验结果表明:与条件独立性假设相比,独立性假设是过强假设,因而基于马尔可夫族模型的语言模型更符合语言等实际物理过程;在相同的测试条件下,马尔可夫族模型明显好于隐马尔可夫模型,词性标注准确率从94.642%提高到97.126%。
|
| [14] |
An Algorithm for Suffix Stripping[A]// Readings in Information Retrieval [M]. |
| [15] |
词形还原方法及实现工具比较分析 [J].
结合理论和实验比较分析用于词形规范的词形还原方法和工具。归纳现有词形还原方法的主要分类,分析各类方法的特点和不足。介绍7种词形还原实现工具,并从其实现原理、使用的词性标注器、词典、开发语言、处理的语种、是否具有拼写检查功能等方面比较分析各工具的特点。选取其中5种工具,利用WordSimith Tools的标准数据进行词形还原实验。结合实验结果分析各工具的优劣,发现Specialist NLP Tools的词形还原工具具有较好的词形还原处理效果,为研究者选择适当的词形还原方法和工具提供参考。
Contrast Analysis of Methods and Tools for Lemmatization [J].
结合理论和实验比较分析用于词形规范的词形还原方法和工具。归纳现有词形还原方法的主要分类,分析各类方法的特点和不足。介绍7种词形还原实现工具,并从其实现原理、使用的词性标注器、词典、开发语言、处理的语种、是否具有拼写检查功能等方面比较分析各工具的特点。选取其中5种工具,利用WordSimith Tools的标准数据进行词形还原实验。结合实验结果分析各工具的优劣,发现Specialist NLP Tools的词形还原工具具有较好的词形还原处理效果,为研究者选择适当的词形还原方法和工具提供参考。
|
| [16] |
面向中文专利SAO结构抽取的文本特征比较研究 [J].https://doi.org/10.13209/j.0479-8023.2015.049 URL [本文引用: 1] 摘要
针对中文专利文本中SAO结构实体关系抽取问题,使用支持向量机的机器学习方法进行关系抽取实验,分别对基本词法信息、实体间距离信息、最短路径闭包树句法信息以及词向量信息等特征的有效性进行验证分析.实验结果表明,基本的词法信息能够明显提高关系抽取性能,而句法信息没有显著提高关系抽取效果.此外,也验证了词向量在SAO结构关系抽取中的可行性.
Text Feature Analysis on SAO Structure Extraction from Chinese Patent Literatures [J].https://doi.org/10.13209/j.0479-8023.2015.049 URL [本文引用: 1] 摘要
针对中文专利文本中SAO结构实体关系抽取问题,使用支持向量机的机器学习方法进行关系抽取实验,分别对基本词法信息、实体间距离信息、最短路径闭包树句法信息以及词向量信息等特征的有效性进行验证分析.实验结果表明,基本的词法信息能够明显提高关系抽取性能,而句法信息没有显著提高关系抽取效果.此外,也验证了词向量在SAO结构关系抽取中的可行性.
|
| [17] |
基于SAO结构语义分析的新兴技术识别研究 [J].
Identifying Emerging Technologies Based on Subject-Action-Object [J].
|
| [18] |
基于SAO结构分析的技术发展路径预测研究 [D].Research on Forecasting Technological Development Paths Based on SAO Structure Analysis [D]. |

/
| 〈 |
|
〉 |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}