崔家旺 , 李春旺
, 李春旺
Cui Jiawang, Li Chunwang
中图分类号: G25
通讯作者:
收稿日期: 2017-02-16
修回日期: 2017-04-11
网络出版日期: 2017-04-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
展开
摘要
【目的】调研基于关联数据揭示类簇内主题词间语义关系的模型和技术方法。【方法】利用Google Scholar、Springer、CNKI等检索与研究主题相关的文献, 调研分析并梳理当前类簇分析和语义关系揭示相关研究, 构建基于关联数据的类簇语义关系揭示模型, 通过实验验证模型的有效性。【结果】实验结果表明, 利用关联数据可以有效揭示主题词间语义关系, 弥补传统共词聚类分析在语义方面的不足。【局限】受实验数据限制, 目前揭示出的语义关系局限于上下位类关系、类与实例关系和相关关系等类型, 未考虑关联数据质量问题对语义揭示结果造成的影响。【结论】提出的基于关联数据的类簇语义关系揭示模型可以有效揭示主题词间语义关系, 为共词聚类结果的理解和分析提供一种新的方式。
关键词:
Abstract
[Objective] This paper introduces a model to identify the semantic relations for the co-word analysis results based on linked data. [Methods] First, we used Google Scholar, Springer and CNKI to retrieve the literature of the related research. Then, we analyzed the clusters relations of them. Finally, we constructed and examined the semantic relation model for clusters based on the linked data graph structure. [Results] The linked data helped us effectively explore the potential semantic relations among keywords. [Limitations] Due to the limits of the collected linked data, we only identified some sematic relationship, such as hierarchical, simple relavent, as well as classes-instance ones. More research is needed to improve the quality of linked data. [Conclusions] The proposed model could successfully discover the semantic relations among keywords, which help us get more insights from the cluster analysis.
Keywords:
共词聚类分析根据物以类聚的原理将本身没有类别的主题词聚集成代表不同研究子领域的类簇, 通过分析这些类簇可以清晰直观地揭示学科的主题结构与变化[1]。根据聚类原理, 类簇将距离最短的主题词聚集在一起而未考虑词间的逻辑关系, 这样造成的后果是类簇因缺少主题词间的语义关系而难以理解。关联数据的发布与应用为共词聚类研究的发展提供了新契机, 特别是关联数据预先建立了大量权威、准确的属性关系, 每个数据对象包括多种属性和特征, 从而为实现跨学科领域、跨数据源的精准语义关系揭示提供有效支撑。
类簇分析从分析层次上可分为紧密度分析和语义关系揭示两种。类簇的紧密度分析主要衡量聚类的紧密程度, 相关研究主要包括粘合力、密度等类簇分析指标以及共词聚类与其他辅助方法的结合。类簇的语义关系揭示主要从知识发现的角度探索类簇内部语义关系, 相关研究主要包括: 学科专家参与、共词关联分析、文本挖掘、基于本体和词表、基于关联数据的方法等。
(1) 学科专家参与, 张树良等[2]提出共词聚类的过程应有学科专家的介入, 学科专家通过人工梳理的方式帮助人们理解类簇内和类簇间的语义关系, 弥补了共词聚类对数学统计的依赖。
(2) 共词关联分析, 关联规则是描述一个事物中物品之间同时出现的规律的知识模式, 共词关联分析以此为原理, 通过关联统计方法揭示主题词间的依存关系。张晗等[3]利用关联规则算法对4种抗肿瘤药物主题词和副主题词组配模式进行分析, 抽取出与这4类药物有关的、有效的语义关系搭配模式。张晗等[4]根据书目文献数据库中主题词/副主题词之间的语义关联规则抽取知识, 获得具体的药物与疾病之间的知识。Cimino等[5]对主题词和副主题词的组配规则进行研究, 通过使用简单的模式匹配规则来自动生成医学概念之间的语义关系。
(3) 文本挖掘, 面向语义关系发现的文本挖掘主要通过对NLP进行扫描和自动化处理, 发现概念术语及概念术语间存在的语义关系。刘明岩[6]结合文本挖掘和本体自动构建的方法探索了军用飞机领域概念间的语义关系。
(4) 基于本体和词表的语义关系发现主要从已知的概念间的语义关系出发。张小刚[7]结合概率论在中医药语言系统的应用基础上, 利用关联关系分布推断中医药领域未知的语义关系类型。魏来[8]以词表为语义基础, 引入关联词典机制, 通过识别标签集中的标签同在线词表概念体系之间的关系, 进而识别出标签之间的语义关系。
(5) 基于关联数据的语义关系发现研究还处于探索阶段。Tiddi等[9]提出的Dedalo启发式关联数据遍历挖掘系统具有一定代表性, Dedalo通过启发式的迭代检索关联数据寻找簇内实体间共同路径, 进而形成簇内实体共有的语义关系。Taheriyan等[10]通过语义标注和构建语义关联的方式利用关联数据推断结构化资源的语义关系。此外, 还有一些关联数据挖掘相关技术对本研究有重要借鉴意义。在国内, 李楠等[11]、李俊等[12]分别总结了基于关联数据的数据挖掘相关研究, 提出基于关联数据的知识发现模型。高劲松等[13]在关联数据的知识发现过程金字塔的基础上提出基于关联数据的知识发现模型。宋丽娜[14]提出关联数据环境下基于知识地图的隐性知识发现模型。刘龙[15]提出基于关联数据的知识发现过程模型。与国内相比, 国外研究较为丰富。Narasimha等[16]提出的LiDDM关联数据挖掘系统及Paulheim等[17]提出的FeGeLOD特征提取器通过格式转化或特征提取将关联数据转化为适合传统数据挖掘算法的格式。Ramezani等[18]提出的SWApriori和Personeni等[19]提出的ILP学习方法通过改进传统数据挖掘算法将其应用于RDF格式数据进行关联数据的挖掘。Jiang等[20]提出的频繁子图挖掘方法及Li等[21]提出的深度学习方法针对关联数据的属性链和节点等结构信息进行挖掘。
每种方法都有一定的缺陷, 专家参与方法的缺陷在于成本高、难以推广; 基于关联分析的语义关系发现的缺陷在于只能发现某些特定类型的语义关系; 基于文本挖掘的方法缺陷在于文本语料库通常缺乏足够的结构化信息, 本体和词表的结构严谨但覆盖程度和语义关联程度交叉不足, 许多本体和词表相关往往在大小和规模上有所限制, 难以覆盖到足够丰富的概念以及概念之间的关系。关联数据作为一个可供语义挖掘的重要资源, 在规模和结构上体现出双重优势, 因此基于关联数据揭示类簇语义关系虽然属于一种新的尝试, 但伴随着LOD数据资源和相关技术的快速发展, 这种新的语义关系揭示方法可能会成为未来研究发展的一个趋势。
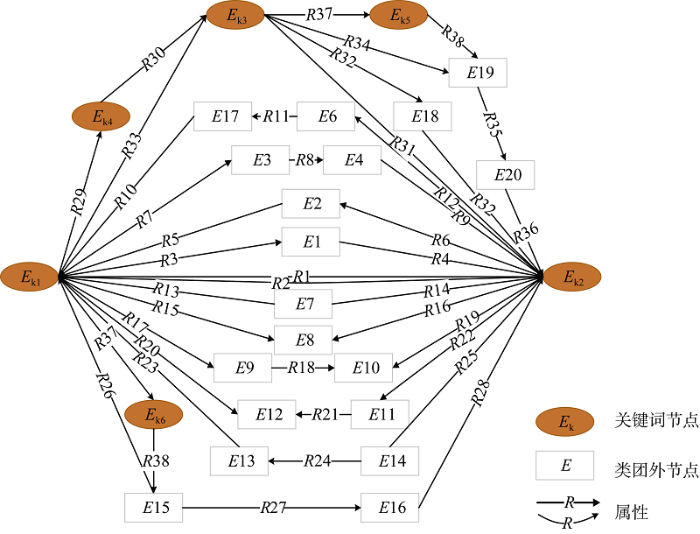
类簇内的主题词对应关联数据中的节点, 根据关联数据的网状结构特征, 主题词节点间最大距离为3可能存在的关联关系如图1所示。
其中棕色椭圆框(Ek)表示类簇内主题词对应关联数据中的节点, 即主题词节点; 白色方框代表的类簇外节点(E)是指通过关联数据挖掘发现的新节点, 节点间的直线/曲线代表属性关系(R)。本文将研究范围限定在主题词距离不超过3的关联关系, 原因如下:
(1) 最大距离为3保证了充足的关联关系。LOD是典型的小世界图, 这种图的特点就是无论网络规模多大, 一般搜索路径的最大步数是一个比较稳定的值, 研究表明LOD中节点间平均最短路径长度为2.4[22];
(2) 根据路径综合重要性评价方法, 距离较远的关联关系重要性较低, 缺乏语义揭示的价值;
(3) 关联数据图挖掘的检索空间呈指数上升, 更长的路径会导致更大的时间开销。
为准确描述类簇内关联关系, 本文提出以下定义:
(1) 关联数据图: 关联数据图是由RDF数据构成的有向图, 图中节点是由URI标注的主语或对象, 边是一组具有URI标注的属性。
(2) 关联路径: 本文将从主题词节点${{E}_{k1}}$出发到主题词节点${{E}_{k2}}$之间所经过的属性R和节点E的集合定义为关联路径, 从${{E}_{k1}}$经过节点E1到${{E}_{k2}}$的一条关联路径可以表示为: ${{E}_{k1}}\xrightarrow{R1}E1\xrightarrow{R2}{{E}_{k2}}$, 其中${{E}_{k1}}$、${{E}_{k2}}$表示主题词节点, E1为关联数据挖掘发现的类簇外节点, R1和R2表示节点间属性关系。关联路径的长度指路径拥有的属性数量, 例如: ${{E}_{k1}}\xrightarrow{R1}$ $E1\xrightarrow{R2}{{E}_{k2}}$就是一条长度等于2的关联路径;
(3) 路径和属性方向: 从主题词${{E}_{k1}}$到主题词${{E}_{k2}}$的关联路径的方向表示为${{E}_{k1}}\xrightarrow[{}]{{}}{{E}_{k2}}$, 关联路径中的属性关系方向与${{E}_{k1}}\xrightarrow[{}]{{}}{{E}_{k2}}$相同的为正向属性, 属性关系与关联路径方向相反则为逆向属性。例如, 在关联路径${{E}_{k1}}\xleftarrow{R1}E1\xrightarrow{R2}{{E}_{k2}}$中, $\xleftarrow{R1}$为逆向属性, $\xrightarrow{R2}$为正向属性。
由于多个主题词节点之间的关联路径错综复杂难以理解, 本文从两两主题词节点间的语义关系出发, 逐步探索整个类簇内主题词之间的语义关系。以图1中主题词节点${{E}_{k1}}$和${{E}_{k2}}$为例, 根据关联路径长度和属性方向的不同, ${{E}_{k1}}$和${{E}_{k2}}$间的关联路径可分为: 直接关联、间接关联、最近公共祖先节点关联、最近公共子孙节点关联等4类, 不同类型的关联路径对应不同类型语义关系。
(1) 直接关联(Direct Relation, DR); 直接关联指的是主题词节点间长度为1的关联路径, 主题词节点${{E}_{k1}}$和${{E}_{k2}}$间存在${{E}_{k1}}\xrightarrow{R1}{{E}_{k2}}$、${{E}_{k1}}\xleftarrow{R2}{{E}_{k2}}$两种直接关联。
(2) 间接关联(Indirect Relation, IR); 间接关联指主题词间长度大于等于2且不存在逆向属性的关联路径。如图2所示, 主题词${{E}_{k1}}$和${{E}_{k2}}$之间长度为2的间接关联有${{E}_{k1}}\xrightarrow{R3}E1\xrightarrow{R4}{{E}_{k2}}$和${{E}_{k2}}\xrightarrow{R6}$ $E2\xrightarrow{R7}{{E}_{k1}}$等两种, 关联路径长度为3时存在${{E}_{k1}}\xrightarrow{R7}E3\xrightarrow{R8}E4\xrightarrow{R9}{{E}_{k2}}$和${{E}_{k2}}\xrightarrow{R12}$ $E6\xrightarrow{R11}E17\xrightarrow{R10}{{E}_{k1}}$等两种间接关联。
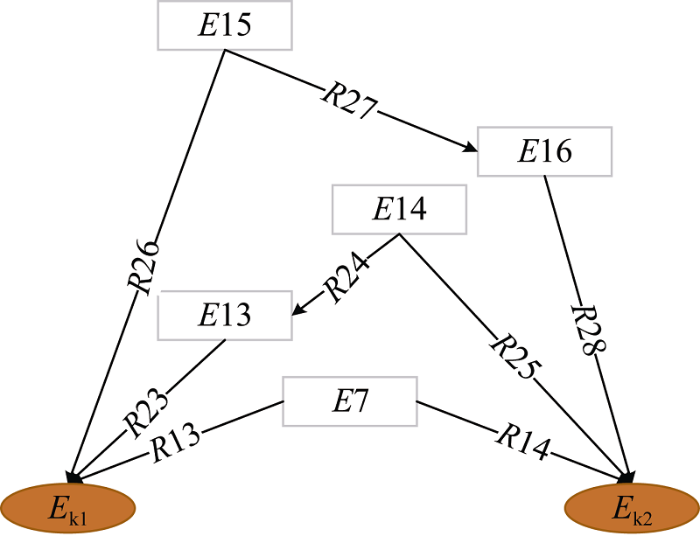
(3) 最近公共祖先节点关联; 最近公共祖先 (Lowest Common Ancestor, LCA)的定义为: 对于有根树T的两个节点u、v, 最近公共祖先LCA(T, u, v)表示一个节点x, 满足x是节点u和节点v的祖先且x的深度尽可能大。在关联数据中也存在类似的结构, 存在最近公共祖先节点的关联路径被定义为最近公共祖先节点关联(Lowest Common Ancestor Relation, LCAR)。最近公共关联祖先关联的定义如下: 通过最短的属性链向两个主题词节点的节点被称作主题词的最近公共祖先节点。如图3所示, 当关联路径长度为2时, 存在${{E}_{k1}}\xleftarrow{R13}E7(LCA)\xrightarrow{R14}{{E}_{k2}}$一种LCAR。当关联路径长度为3时, 存在${{E}_{k1}}\xleftarrow{R23}E13\xleftarrow{R24}$ $E14(LCA)\xrightarrow{R25}{{E}_{k2}}$和${{E}_{k1}}\xleftarrow{R26}E15(LCA)$ $\xrightarrow{R27}E16\xrightarrow{R28}{{E}_{k2}}$两种LCAR。
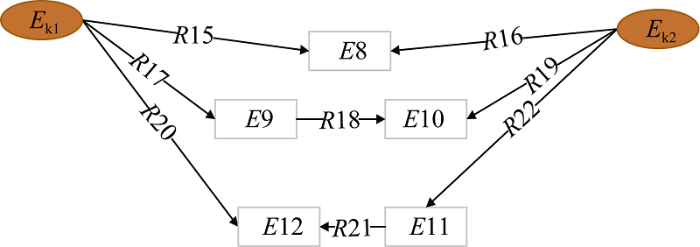
(4) 最近公共子孙节点关联; 在关联数据中节点间不仅存在最近公共祖先节点, 也存在最近公共子孙节点。关联数据中, 两个主题词节点通过最短的属性关系链向同一个节点, 那么这个节点就被称作最近公共子孙节点(Lowest Common Descendant, LCD), 存在最近公共子孙节点的关联路径被定义为最近公共子孙节点关联(Lowest Common Descendant Relation, LCDR)。如图4所示, 当关联路径长度为2时存在${{E}_{k1}}\xrightarrow{R15}E8(LCD)\xleftarrow{R16}{{E}_{k2}}$一种LCDR。当关联路径长度为3时, 存在${{E}_{k1}}\xrightarrow{R17}E9$ $\xrightarrow{R18}E10(LCD)\xleftarrow{R19}{{E}_{k2}}$和${{E}_{k1}}\xrightarrow{R20}E12(LCD)$ $\xleftarrow{R21}E11\xleftarrow{R22}{{E}_{k2}}$等两种LCDR。
主题词节点间关联路径数量庞大, 无法一一分析, 且并非所有关联路径都具有揭示的价值。因此, 对关联路径的重要性进行评价是实现类簇实体间语义关系揭示的重要工作, 具体包括: 实体属性重要性评价、实体节点重要性评价以及实体间路径综合重要性评价。
(1) 实体属性重要性评价
目前, 常见的基于关联数据的属性重要性评价指标方法主要包括: 基于信息熵的属性重要性评价、基于属性频率的属性重要性评价、基于关联节点的属性重要性评价以及基于TF-IDF的属性重要性评价。
①基于信息论
Meymandpour等[23]提出基于信息论的关联数据信息量衡量方法。信息论利用不确定性度量信息的大小, 因此单个关联属性P的信息量可以表示为其出现概率的负对数, 计算公式为: $I(R)=-\log Pr(P)$, 其中Pr(P)表示属性P在整个数据集中的出现概率, 计算方式为属性P出现频次除以关联数据集中属性总频次, 公式中对数一般取2为底, 单位为比特。
②基于属性频率
Kasneci等[24]基于属性频率构建了信息量计算方法MING, MING给出了节点i到节点j的关联关系r的权重计算方法, 计算公式为: Wij=$\frac{N(i,r,j)}{N(*,r,j)}$, 其中N(i, r, j)为实例(i, r, j)的数量, N(*, r, j)为所有经由关联关系r到达节点j的实例数量。Balmin等[25]将基于属性频率的方法与人工分配权重的方式相结合, 在计算属性权重时先根据经验预先给定每种属性分配一定的权重, 然后根据关联关系实例数量等比例均分给定权重。Nie等[26]提出对象排序算法PopRank中对关联属性的权重计算也是基于同样的思路。
③基于关联节点
Ng 等[27]提出基于属性所关联的节点计算属性权重的MultiRank算法。在MultiRank算法中, 属性关系的重要性由该属性关系所关联的两个节点(即关联数据中的主语和对象)的重要性得分乘积计算。
④基于TF-IDF
关联数据集中属性关系的分布往往是偏斜的, 不同的属性关系的频率数量级差异十分悬殊。为解决基于属性频次的重要性评价方法的不足, 本文提出基于TF-IDF的属性权重计算方法。在关联数据中, 一个属性在关联数据图挖掘出的子图(如图1)中出现的频率越高说明它在区分该子图内属性方面的能力越强(TF), 一个属性在整个关联数据集中出现的频率越高说明它的区分性越低(IDF)。基于TF-IDF的关联数据属性权重计算公式可表示为: ${{W}_{R}}=t{{f}_{iR}}\times id{{f}_{R}}=t{{f}_{iR}}\times $ $\log (N/{{n}_{R}})$, 其中tfiR指属性R在关联挖掘结果子图出现的次数, idfj指属性R频次的倒数, N表示关联数据集中的总关联数, nj指tj在整个关联数据集中出现的总次数。
(2) 实体节点重要性评价
基于关联数据的节点评价方法主要包括: 信息论法、网络图分析法、张量分解法[28]。
①信息论法
信息论中如果一个事件是由若干个独立的小事件构成, 则信息量是这些独立小事件的信息量之和。在关联数据中, 节点由若干个关联属性组成, 节点自身信息量为其关联属性的信息量之和。
②网络图分析法
关联数据网络中的节点和属性类似于Web中的网页和超链接, 因此传统的网络图分析算法PageRank、HITS经过一定的调整也可以应用到LOD中。在关联数据中, 以某个节点为核心时, 可以通过综合考虑核心节点的每个相邻节点通过关联关系对核心节点贡献重要性, 形成核心节点的总体的重要性, 以此评价核心节点的影响力。以待计算权重的节点为核心, 其权重的计算公式可表示为: $R(j)=\alpha \sum\limits_{i\in B(j)}{R(i)\times Wij+\frac{(1-\alpha )}{|E|}}$, 其中B(j)是所有指向节点j的节点集合, 其中Wij为节点i指向节点j的关联关系权重; E为整个关联数据网络中的所有节点; α为阻尼系数, 一般取0.85。在开始计算时, 每个节点的初始重要性值默认是相同的。与之类似, 拓展网络图分析算法HITS方法也可用于关联数据中节点重要性的评价, Bamba等[29]基于HITS算法通过预定义每个关联关系的权威度权重和中心度权重来计算节点的主观性得分和客观性得分以进行节点重要性排名。
③张量分解法
张量是一种高维数据的组织方法, 张量分解指的是张量等高维数据通过Tucker和Parafac模型等方法将其直接降维成几个更小更简单的子矩阵相乘来表示的过程, 其中分解后的小矩阵描述的是分解前原矩阵的重要特性。关联数据网络中包含大量丰富的语义关系使其可以表示为一个三维张量T, 同样, 关联数据中的节点、相邻及连接相邻节点的关系也能表示为三维张量。以待计算节点作核心, 可以通过综合考虑核心节点对各主题的权威度形成核心节点的总体权威度, 以此评价核心节点的影响力[30]。
(3) 关联路径综合重要性评价
基于节点间路径越短语义越相关的一般假设, 可利用社会网络分析中的拓展卡茨中心度指标(Katz’s Centrality Measure)对一条路径P的重要性进行综合计算, 其基本原理[31]是: 假设两个节点间的路径的有效性由已知的常量概率α决定, 那么在一个由k个节点组成的路径的概率为αk。本文在卡茨中心度指标的基础上引入属性的概率, 长度为N的关联路径综合的重要性Pr(P)可通过以下公式计算: $Pr(P)=W({{R}_{1}})\times $ $W({{E}_{1}})\times W({{R}_{2}})\times \cdots W({{R}_{N}})$。由于属性和节点的重要性评价结果数量级存在差异, 计算关联路径综合重要性前须对属性和节点的重要性评价结果进行归一化处理。常见的归一化算法包括: 线性函数转换、对数函数转换、反正切函数转换和线性与对数函数结合等方法。
本文以Java语言和Eclipse为开发环境, 借助Jena和Virtuoso等开源工具和DBpedia(2016-4)关联数据集实现基于关联数据的类簇语义揭示。
调研发现, 相对于其他数据集, DBpedia数据更为全面和丰富。DBpedia是基于 Wikipedia、语义 Web和关联数据技术的创新型知识库, 是文档网向数据网过渡的标志性成果之一。最新的DBpedia(2016-4)拥有超过90亿个RDF三元组, 包含754个类, 涉及127种语言, 仅英文版的DBpedia 知识库中就描述了超过600万个事物(其中520万个资源都归类于统一的本体), 包含150万人、81万个地点、13.5万份音乐作品、10.6万部电影、27.5万个组织机构、30.1万个生物物种及5 000多种疾病, 是目前最大的跨领域语义知识库之一。鉴于DBpedia丰富的语义关系和资源规模, 本文采用DBpedia数据集作为类簇语义发现的基础。同时, 为保证实验的合理和客观, 选择论文《基于共词分析的兽医分子生物学领域研究热点分析及初步展望》[32]中类簇主题词“Cloning”和“PCR”作为语义揭示的对象。
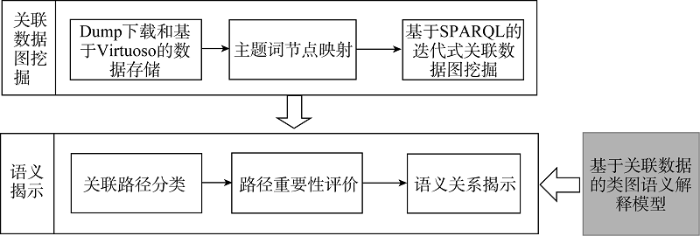
为实现基于关联数据的类簇语义揭示, 笔者设计了如图 5 所示的语义揭示系统框架, 该框架分为关联数据图挖掘和语义揭示两部分。
关联数据图挖掘指从关联数据集中发现图1所示的主题词节点中关联路径的过程, 分为数据准备和关联数据挖掘两个部分。
(1) 数据准备
以Dump下载的方式获取DBpedia(2016-4)英文版数据集, 并基于Virtuoso7.2.4搭建本地SPARQL查询。完成关联数据集的获取后, 通过语义浏览器LodLive提供的关键词检索服务完成主题词节点的映射, 发现类簇内主题词“Cloning”和“PCR”在DBpedia中对应的节点URI分别是“http://dbpedia.org/ resource/Cloning”和“http://dbpedia.org/resource/Polymerase_ chain_reaction”。
(2) 关联数据图挖掘
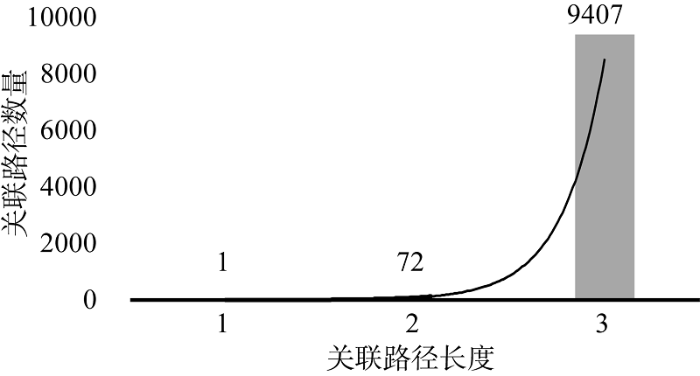
本文在借鉴相关挖掘技术基础上提出基于迭代式SPARQL查询的关联数据图挖掘方法, 基本原理是通过SPARQL检索迭代查找的方法实现节点间最短关联路径的发现, 查找策略是从长度为1的路径开始逐渐增加。以主题词节点“http://dbpedia.org/resource/ Cloning”和“http://dbpedia.org/resource/Polymerase_ chain_reaction”为初始节点, 设定最大挖掘路径长度为3在DBpedia(2016-4)关联数据集中进行挖掘, 共计发现9 480条关联路径, 其中长度为1的关联路径1条、长度为2的关联路径为72条、长度为3的关联路径9 407条, 如图6所示。
语义揭示模块指将基于关联数据的类簇语义揭示模型应用于关联数据图挖掘的结果, 分为关联路径分类、重要性指标计算和语义关系揭示等三个部分。
(1) 关联路径分类
挖掘关联路径后, 根据模型对4种关联路径类型的定义, 对发现的9 480条关联路径进行分类。其中, 属于直接关联的有1条(0.01%), 属于间接关联的有1 076条(11.35%), 属于最近公共祖先节点关联的有3 847条(40.58%), 属于公共祖先节点关联的关联路径有4 556条(48.05%)。
(2) 路径重要性指标计算
基于现有数据的情况和可行性, 笔者基于信息论计算属性和节点重要性指标, 并据此评价关联路径的综合重要性。计算过程如下: 首先, 基于SPARQL动态获取属性频次、节点频次等评价所需数据, 然后利用第3节的方法对属性重要性和节点重要性分别进行计算, 最后根据调整Min-Max归一化处理后的属性和节点重要性指标计算结果评价关联路径的综合重要性, 调整Min-Max归一化方法函数表示为${{\text{x}}^{*}}=0.001+\frac{\text{x}-\text{Max}}{\text{Max}-\text{Min}}\times 0.999$。路径的综合重要性指标的计算结果如表1所示, 其中“<*>”表示节点, “$\xrightarrow{*}$”表示属性。
表1 部分关联路径综合重要性指标计算结果
| 关联路径 | 重要性指标 | 类型 |
|---|---|---|
| $\{<\text{Cloning}>\xrightarrow{\text{http://dbpedia}\text{.org/ontology/wikiPageWikiLink}}\text{PCR }\!\!\}\!\!\text{ }$ | 0.001 | DR |
| $\{<\text{Cloning}>\xrightarrow{\text{wikiPageWikiLink}}$<Cloning_vector >$\xrightarrow{\text{wikiPageWikiLink}}$<PCR>} | 0.00000072 | IR |
| $\{<\text{Cloning}>\xrightarrow{\text{wikiPageWikiLink}}$<Bisulfite_sequencing >$\xrightarrow{\text{wikiPageWikiLink}}$<PCR>} $\{<\text{Cloning}>\xrightarrow{\text{http://www}\text{.w3}\text{.org/2004/02/skos/core }\!\!\#\!\!\text{ broader}}<\text{Category:Cloning}>$ $\xrightarrow{\text{http://www}\text{.w3}\text{.org/2004/02/skos/core }\!\!\#\!\!\text{ broader}}<\text{Category:Biotechnology}>$ | 0.00000072 | IR |
| $\xleftarrow{\text{http://purlorg/dc/terms/subject}}<\text{PCR}>\}$ | 0.00118999 | LCAR |
| $\{<\text{Cloning}>\xrightarrow{\text{wikiPageWikiLink}}$< Molecular_cloning>$\xrightarrow{\text{http://purlorg/dc/terms/subject}}$ <Category:Molecular_biology>$\xleftarrow{\text{http://purlorg/dc/terms/subject}}$<PCR>} | 0.000260651 | LCAR |
| $\{<\text{Cloning}>\xleftarrow{\text{http://purlorg/dc/terms/subject}}<\text{Category:}\ \text{Molecular }\!\!\_\!\!\text{ biology}>$ $\xrightarrow{\text{http://purlorg/dc/terms/subject}}$<PCR>} | 0.00720822 | LCDR |
| $\{<\text{Cloning}>\xleftarrow{\text{rdf:type}}<\text{http://dbpedia}\text{.org/dbtax/Technique}>\xrightarrow{\text{rdf:type}}$<PCR>} | 0.00139680 | LCDR |
(3) 语义关系揭示
在揭示关联路径所表达的语义关系前, 需分析关联数据中属性关系的语义含义。如表2所示, 通过SPARQL检索获取并分析DBpedia中的高频属性, 将关联数据的语义关系界定为: 等同关系(包含同义和近义)、上下位类关系(属种关系)、整部关系、类与实例的关系以及相关关系(除上述4种关系的其他所有关系)等5种基本语义关系, 并基于这5种基本语义关系分析关联路径所蕴含的语义关系。
表2 DBpedia高频属性(部分)
| 序号 | 属性 | 出现频次 | 含义 | 语义关系 |
|---|---|---|---|---|
| 1 | http://dbpedia.org/ontology/wikiPageWikiLink | 172 300 574 | 对应Wikipedia的链接信息 | 相关关系 |
| 2 | http://www.w3.org/1999/02/22-rdf-syntax-ns#type | 66 418 990 | 资源的标签信息 | 类和实例关系 |
| 3 | http://www.w3.org/2002/07/owl#sameAs | 40 637 907 | 指向同义资源 | 等同关系 |
| 4 | http://dbpedia.org/property/wikiPageUsesTemplate | 36 772 939 | RDF抽取所用模版信息 | 相关关系 |
| 5 | http://dbpedia.org/ontology/wikiPageWikiLinkText | 23 809 294 | Wikipedia超链接的文本信息 | 相关关系 |
| 6 | http://purl.org/dc/terms/subject | 22 673 220 | 资源的主题信息 | 类和实例关系 |
①直接关联的语义关系揭示
主题词节点“Cloning”和“PCR”间存在1条直接关联: $\{<\text{Cloning}>\xrightarrow{\text{wikiPageWikiLink}}<\text{PCR}>\}$($\xrightarrow{\text{wikiPageWikiLink}}$代表属性“http://dbpedia.org/ontology/wikiPageWikiLink”), 它所表示的语义关系为: 主题词“Cloning”和“PCR”具有相关关系。
②间接关联的语义关系揭示
主题词节点“Cloning”和“PCR”间存在1 076条间接关联,其中综合重要性最高的关联路径为: $\{<\text{Cloning}>$ $\xrightarrow{\text{wikiPageWikiLink}}\text{Cloning }\!\!\_\!\!\text{ vector}\xrightarrow{\text{wikiPageWikiLink}}<\text{PCR}>\},$它表示节点“Cloning_vector”与主题词“Cloning”和“PCR”同时具有相关关系。除此之外, 实验还发现“DNA” “DNA_ sequencing” “DNA_profiling”和“Molecular_cloning”等多个资源也与主题词“Cloning”和“PCR”同时具有相关关系。
③LCAR的语义关系揭示
主题词“Cloning”和“PCR”对应节点间存在最近公共祖先节点关联3 847条, 其中综合重要性最高为: $\{<\text{Cloning}>$ $\xrightarrow{\text{http://www}\text{.w3}\text{.org/2004/02/skos/core }\!\!\#\!\!\text{ broader}}\text{Category:}\ \text{Cloning}$$\xrightarrow{\text{http://www}\text{.w3}\text{.org/2004/02/skos/core }\!\!\#\!\!\text{ broader}}<\text{Category:}\ $$\text{Biotechnology}>\xleftarrow{\text{http://purl}\text{.org/dc/terms/subject}}<\text{PCR}>\}$, 它所表示的语义关系为: 主题词“Cloning”和“PCR”与类“Biotechnology(生物技术)”都具有上下位类的语义关系, 即主题词 “Cloning”和“PCR”都是隶属于生物技术类的概念。
④LCDR的语义关系揭示
主题词节点“Cloning”和“PCR”间存在最近公共祖先节点关联4 556条, 其中综合重要性最高的为关联路径{$<\text{Cloning}>\xleftarrow{\text{http://purl}\text{.org/dc/terms/subject}}$<Category:Molecular_biology>$\xrightarrow{\text{http://purl}\text{.org/dc/terms/subject}}$<PCR>}, 它所表达的语义关系为: 主题词“Cloning”和“PCR”都与类“Molecular_ biology(分子生物学)”具有类和实例关系, 即主题词“Cloning”和“PCR”都是隶属于分子生物学类的概念。除此之外, 关联路径$\{<\text{Cloning}>\xleftarrow{\text{rdf:type}}<\text{http://dbpedia}\text{.org/}$ $\text{dbtax/Technique}>\xrightarrow{\text{rdf:type}}<\text{PCR}>\}$表示实主题词“Cloning”和“PCR”同时与类“<http://dbpedia.org/ dbtax/Technique>”具有类和实例的语义关系, 即“Cloning”和“PCR”都是同种技术。
笔者对重要性指标排名前300的关联路径进行分析, 结果显示由于关联数据不完整等质量问题导致的无价值关联路径有136条, 其余164条有语义价值的关联路径中, LCDR有106条(64.6%), LCAR有54条(32.9%), IR有3条(1.8%), DR有1条(0.6%), 可以发现LCAR和LCDR对类簇的语义揭示最为重要。对164条关联路径所揭示的语义关系类型进行分析发现, 相关关系以92.7%(152条)占据绝对优势, 其次是类与实例关系占比4.8%(8条), 最后是上下位类关系占比2.4%(4条)。相关关系占比最高的主要原因是实验所用数据集DBpedia抽取自维基百科, 存在大量涉及维基百科网页信息的属性, 例如属性“http://dbpedia.org/ ontology/wikiPageWikiLink”出现1.7亿次, 占数据集属性总数(6.8亿)约四分之一, 这些对应相关关系的属性大量存在, 造成语义揭示结果中相关关系占比最高。
本实验利用关联数据有效揭示了主题词间的相关关系、类和实例关系以及类和属性关系等多种语义关系, 例如: 主题词“Cloning”和“PCR”都是隶属于生物技术类的概念、主题词“Cloning”和“PCR”都隶属于分子生物学类的概念、主题词“Cloning”和“PCR”都属于一种技术等。在论文《基于共词分析的兽医分子生物学领域研究热点分析及初步展望》中, 专家通过对类簇的人工分析将主题词“Cloning”和“PCR”所属的类簇命名为“克隆技术研究”, 与本实验语义结果揭示相一致, 证明了基于关联数据的类簇语义关系揭示模型具有可行性和有效性。
实验也存在一些不足, 首先仅基于单一的DBpedia英文版关联数据集对模型进行实验验证, 揭示出的语义关系类型局限为相关关系、类与实例关系以及上下位类关系等三种。另外, 关联数据资源存在数据不完整、数据重复和数据不一致等质量问题也对语义揭示的精确度造成一定影响。
本文提出利用关联数据揭示类簇内主题词间的语义关系并通过实证验证了模型和方法的有效性, 弥补了传统类簇分析在语义关系揭示方面的不足, 为类簇语义关系的揭示提供了一种新的思路。相较于其他语料库, 关联数据具有语义资源覆盖广和结构化程度高的双重优势, 快速发展的LOD资源保证了绝大多数领域的类簇可以得到有效语义揭示。本研究主要存在以下两个方面的不足: 局限于单一数据集的语义揭示以及关联数据质量对语义揭示结果造成的影响。后续研究中, 将对基于更多关联数据资源的类簇语义揭示进行研究, 同时改进关联路径的重要性评价指标, 克服关联数据质量对语义揭示结果的影响。
崔家旺: 文献搜集, 程序设计, 论文撰写;
李春旺: 提出研究思路, 审阅、修改论文。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: cuijiawang@mail.las.ac.cn。
[1] 崔家旺. 关联数据挖掘_9480.xls. 实验数据集.
| [1] |
共词分析法研究(一)——共词分析的过程与方式 [J].The Research of Co-word Analysis (1) ———The Process and Methods of Co-word Analysis [J]. |
| [2] |
基于文献的知识发现的应用进展研究 [J].Study on the Applicational Development of Literature-based Knowledge Discovery [J]. |
| [3] |
基于主题词关联规则的医学文本数据库数据挖掘的尝试 [J].Study on the Data Mining in Medical Text Database Based on Keywords Association Rules [J]. |
| [4] |
生物信息学的共词分析研究 [J].https://doi.org/10.3969/j.issn.1000-0135.2003.05.018 URL [本文引用: 1] 摘要
本文应用共词分析的方法对生物信息学的主题词进行聚类,得到其研究的热点内容,然后利用战略坐标进一步定量地分析了各热点的发展阶段.
Study of Bioinformatics through Co-word Analysis [J].https://doi.org/10.3969/j.issn.1000-0135.2003.05.018 URL [本文引用: 1] 摘要
本文应用共词分析的方法对生物信息学的主题词进行聚类,得到其研究的热点内容,然后利用战略坐标进一步定量地分析了各热点的发展阶段.
|
| [5] |
Automatic Knowledge Acquisition from Medline [J].https://doi.org/10.1007/BF01581301 URL PMID: 8321130 [本文引用: 1] 摘要
Abstract Construction of medical knowledge bases for use in expert systems is an arduous task. We propose a procedure for obtaining medical knowledge via automated analysis of citations found in the National Library of Medicine's MEDLINE database. In this method, simple pattern of keywords and subheading co-occurrences are detected in the keyword descriptor portion of the citations. Each pattern corresponds to a fact, expressed as a semantic relationship between medical concepts. We have constructed a set of 504 pattern-matching rules and applied it to a set of 673 MEDLINE citations to produce 2,795 such facts. The results are presented of an analysis of the syntactic and semantic features of these facts to understand the kinds of knowledge than can be obtained through our method and speculate on the potential uses and pitfalls for knowledge of this type.
|
| [6] |
面向语义关系发现的文本挖掘研究 [D].Research of Text Mining About Semantic Relation Recognition[D]. |
| [7] |
基于中医药本体的语义关系发现及验证方法 [D].Traditional Chinese Medical Ontology Based Semantic Relation Discovering and Verification [D]. |
| [8] |
基于在线词表的Folksonomy语义关联识别方法研究 [J].
<html dir="ltr"><head><title></title></head><body><font style="BACKGROUND-COLOR: #cce8cf">在研究现有folksonomy语义关系发现与识别的基础上,提出基于在线词表的folksonomy语义关联识别的总体思路和方法步骤,重点研究folksonomy语义关联识别的具体规则,制定基于在线词表的直接关联关系识别规则和非直接包含/同源关系识别规则,并利用开放教育领域的在线词表ERIC作为语义基础进行实证研究。</font></body></html>
Research of Folksonomy Semantic Association Method Based on Online Thesaurus [J].
<html dir="ltr"><head><title></title></head><body><font style="BACKGROUND-COLOR: #cce8cf">在研究现有folksonomy语义关系发现与识别的基础上,提出基于在线词表的folksonomy语义关联识别的总体思路和方法步骤,重点研究folksonomy语义关联识别的具体规则,制定基于在线词表的直接关联关系识别规则和非直接包含/同源关系识别规则,并利用开放教育领域的在线词表ERIC作为语义基础进行实证研究。</font></body></html>
|
| [9] |
Dedalo: Looking for Clusters Explanations in a Labyrinth of Linked Data [M]. |
| [10] |
|
| [11] |
基于关联数据的知识发现模型研究 [J].Research on Knowledge Discovery Based on Linked Data [J]. |
| [12] |
关联数据的知识发现研究 [J].Knowledge Discovery in Linked Data [J]. |
| [13] |
基于关联数据的知识发现模型构建研究 [J].
分析了关联数据应用于知识发现的可行性与优势, 对比关联数据集和知识集的特征, 提出了基于关联数据的知识发现过程金字塔。在此基础上, 构建了基于关联数据的知识发现模型, 并对其进行了深入探讨。最后以关联数据可视化工具gFacet为例进行实例分析, 结果表明, 该模型可以为开放网络环境下的知识发现提供新的研究范式与方案, 能够实现关联数据环境下的知识抽取, 从而构建新环境下的创新性知识, 满足用户的多维知识需求。
Research on Construction of the Knowledge Discovery Model Based on Linked Data [J].
分析了关联数据应用于知识发现的可行性与优势, 对比关联数据集和知识集的特征, 提出了基于关联数据的知识发现过程金字塔。在此基础上, 构建了基于关联数据的知识发现模型, 并对其进行了深入探讨。最后以关联数据可视化工具gFacet为例进行实例分析, 结果表明, 该模型可以为开放网络环境下的知识发现提供新的研究范式与方案, 能够实现关联数据环境下的知识抽取, 从而构建新环境下的创新性知识, 满足用户的多维知识需求。
|
| [14] |
关联数据环境下基于知识地图的隐性知识发现模型研究 [D].Research on Model of Knowledge Discovery Based on Knowledge Map Under the Environment of Linked Data [D]. |
| [15] |
基于关联数据的知识发现过程模型研究 [D].Research on Model of Knowledge Discovery Process Based on Linked Data [D]. |
| [16] |
LiDDM: A Data Mining System for Linked Data [C]// |
| [17] |
Unsupervised Generation of Data Mining Features from Linked Open Data [C]// |
| [18] |
Finding Association Rules in Linked Data, A Centralization Approach [C]// |
| [19] |
Mining Linked Open Data: A Case Study with Genes Responsible for Intellectual Disability [M]. |
| [20] |
Graph Compression Strategies for Instance-Focused Semantic Mining [C]// |
| [21] |
LRBM: A Restricted Boltzmann Machine Based Approach for Representation Learning on Linked Data [C]// |
| [22] |
LOD的网络结构分析与可视化 [J].
【目的】对关联开放数据(LOD)进行结构特征分析,利用分析结果指导关联数据的组织实践。【方法】通过度分布、平均路径长度、聚类系数等指标描述LOD网络结构,对比复杂网络理论中的两个基本性质:无标度特性和小世界效应。【结果】LOD整体网络结构具有近似无标度网络的幂率分布特征,图书馆学、情报学领域子网具有相对均匀的指数分布特征,两网同时具有短平均路径长度和高聚类系数的小世界效应。【局限】缺乏对关键节点的多权重赋值。【结论】LOD的小世界特性能优化检索效率,而无标度特性会降低整个网络的稳定性。
Analysis and Visualization of the LOD Network Structure [J].
【目的】对关联开放数据(LOD)进行结构特征分析,利用分析结果指导关联数据的组织实践。【方法】通过度分布、平均路径长度、聚类系数等指标描述LOD网络结构,对比复杂网络理论中的两个基本性质:无标度特性和小世界效应。【结果】LOD整体网络结构具有近似无标度网络的幂率分布特征,图书馆学、情报学领域子网具有相对均匀的指数分布特征,两网同时具有短平均路径长度和高聚类系数的小世界效应。【局限】缺乏对关键节点的多权重赋值。【结论】LOD的小世界特性能优化检索效率,而无标度特性会降低整个网络的稳定性。
|
| [23] |
Linked Data Informativeness [M]. |
| [24] |
MING: Mining Informative Entity-Relationship Subgraphs [C]// |
| [25] |
Objectrank: Authority-based Keyword Search in Databases [C]// |
| [26] |
Object-level Ranking: Bringing Order to Web Objects [C]// |
| [27] |
MultiRank: Co-ranking for Objects and Relations in Multi-relational Data [C]// |
| [28] |
基于关联数据的科研机构评价研究述评 [J].Review on the Evaluation of Scientific Research Institution Based on Linked Data [J]. |
| [29] |
Utilizing Resource Importance for Ranking Semantic Web Query Results [C]// |
| [30] |
TripleRank: Ranking Semantic Web Data by Tensor Decomposition [C]// |
| [31] |
Path-Based Semantic Relatedness on Linked Data and Its Use to Word and Entity Disambiguation [C]// |
| [32] |
基于共词分析的兽医分子生物学领域研究热点分析及初步展望 [J].https://doi.org/10.3969/j.issn.1005-8567.2015.02.001 URL [本文引用: 1] 摘要
在选择国内近十年兽医分子生物学研究领域的高频关键词基础上,借 助共词分析法,利用pajek软件对CNKI收录的1 242篇论文的关键词进行共词分析和可视化展示,探索兽医分子生物学领域的研究热点和进展,将兽医分子生物学研究领域划分为六大区域:病毒基因与蛋白质体 系研究、克隆技术研究、病毒的序列分析研究、分子生物学与相关基础学科基础理论研究、高传染性病毒疫苗研究及新城疫病毒研究.再根据分析结果和相关研究文 献,对各个区域主要研究内容进行分析和探讨,并针对我国分子生物学领域的研究提出一些展望.
Interpretation and Preliminary Outlook of the Research Focus in Veterinary Molecular Biology Based on the Co-word Analysis [J].https://doi.org/10.3969/j.issn.1005-8567.2015.02.001 URL [本文引用: 1] 摘要
在选择国内近十年兽医分子生物学研究领域的高频关键词基础上,借 助共词分析法,利用pajek软件对CNKI收录的1 242篇论文的关键词进行共词分析和可视化展示,探索兽医分子生物学领域的研究热点和进展,将兽医分子生物学研究领域划分为六大区域:病毒基因与蛋白质体 系研究、克隆技术研究、病毒的序列分析研究、分子生物学与相关基础学科基础理论研究、高传染性病毒疫苗研究及新城疫病毒研究.再根据分析结果和相关研究文 献,对各个区域主要研究内容进行分析和探讨,并针对我国分子生物学领域的研究提出一些展望.
|

/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}