詹春霞 , 王荣波, 黄孝喜, 谌志群
, 王荣波, 黄孝喜, 谌志群
杭州电子科技大学计算机学院 杭州 310018
Zhan Chunxia, Wang Rongbo, Huang Xiaoxi, Chen Zhiqun
中图分类号: TP391
通讯作者:
收稿日期: 2016-12-30
修回日期: 2017-03-15
网络出版日期: 2017-04-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】针对CFSFDP(Clustering by Fast Search and Find of Density Peaks)算法利用局部密度和距离的乘积选择聚类中心而导致聚类结果不理想的问题进行改进。【方法】提出一种基于粒子群算法的CFSFDP算法, 通过粒子群算法寻找CFSFDP算法中的最佳局部密度和距离阈值, 得到相对较高的局部密度和距离的聚类中心, 减少离散点对数据中心选取的影响, 并在某高考咨询平台提供的考生问题库中随机选取数据集进行试验。【结果】实验结果表明, 在不同的数据集中, 本文算法相对于基本的CFSFDP算法在准确率、召回率、F值上均有明显提高。【局限】文本处理时没有考虑语义关系。【结论】本文方法有很好的聚类效果, 应用在高考咨询库中能够有效地减轻被咨询方的工作量并且帮助快速回答考生的问题。
关键词:
Abstract
[Objective] This paper aims to improve the un-satisfactory performance of CFSFDP (clustering by fast search and find of density peaks) algorithm with the help of based on particle swarm optimization. [Methods] First, we determined the cluster centers by searching optimal local density and distance thresholds to increase the accuracy of results. These clustering centers have relatively high local density and distance, which reduced the influence of discrete points. Then, we examined the proposed method on a randomly selected dataset from the question-answer database of a college entrance exam consulting platform. [Results] The modified CFSFDP algorithm had better performance than the original one. [Limitations] We did not include the semantic relations to process the texts. [Conclusions] The proposed algorithm could achieve good clustering results, and improve the efficiency of the consulting personnel .
Keywords:
随着信息时代的到来, 互联网中的数据以爆炸式增长, 如何从这些海量的数据中获取有用的信息并对数据进行有效的处理分析是当前研究的热点。数据挖掘[1]中的一个热门分支就是聚类[2], 它是一种无监督学习方法, 无需任何先验知识, 按照某种相似性度量方式, 找到数据之间的共性, 将数据集划分成若干个不同的类。划分到同一个类中的数据相似度高、差异小, 而不同类之间的数据相似性较低。迄今为止, 对聚类方法的研究已经长达几十年, 它在医学、模式识别、图像处理、用户兴趣推荐等方面具有广泛的应用, 推动了社会的发展, 改善了人们的生活。
目前, 聚类算法主要分为5大类[2-3]: 基于层次的方法、基于划分的方法、基于密度的方法、基于模型的方法和基于网络的方法。每一类聚类方法都有一些经典算法[3], 在文本处理方面有着广泛的应用。但是鉴于数据的多样性和复杂性, 没有任何一种聚类算法可以普遍适用于各种数据集, 每一类方法都有各自的优点和缺陷, 不同的聚类算法会得到不同的聚类结果。本文对比实验中, Agglomerative Clustering算法和DBSCAN算法分别是基于层次和基于密度的方法, 基本的CFSFDP算法是由Rodriguez和Laio提出的一种新的密度聚类算法[4], 该算法具有能够发现任意形状的数据集且快速简单的优点。张文开进行了基于密度的层次聚类算法研究[5], Mehmood等进行了基于CFSFDP算法的模糊聚类研究[6], 马春来等提出一种基于簇中心点自动选择策略的密度峰值聚类算法[7]。由于CFSFDP算法聚类中心的选取取决于数据点密度和距离乘积的大小, 乘积越大越有可能是聚类中心, 而数据集中密度大距离小或距离大密度小的数据点之间的乘积也可能很大而被误认为是聚类中心。因此本文通过引入粒子群算法找到一对密度距离阈值, 数据集中密度和距离均大于这对阈值的数据点为数据中心, 减少了离散点对聚类中心选取的影响, 实现了聚类中心的自动选择, 减少了人工干预的过程。
本文的实验数据来自于某高考咨询平台自动问答APP, 其中的数据都是学生对于所报考大学的录取情况、学校基本信息等方面的问题, 对其中文本的聚类有利于完善机器人知识库, 提高对学生问答的准确率。将该算法应用于从中抽取的数据集中, 证明了本文聚类算法的有效性。
CFSFDP[4]聚类算法的基本思想是: 首先计算数据点的密度及距离, 其次选取聚类中心, 最后对非聚类中心点进行归类操作。其中, 对聚类中心的选取是该算法的关键。聚类中心点具有两个重要的特征: 聚类中心本身密度比较大, 它是由一些密度比它小的数据点包围; 与其他比其密度高的数据点之间的距离都比较大。基本的CFSFDP算法选取聚类中心的方法具有很大的缺点: 数据集中密度大距离小或密度小距离大的数据点乘积也可能很大而被误认为是聚类中心; 聚类中心的个数无法自动确定, 需要一个人工干预的过程。
(1) 局部密度和距离
设有数据集$s=\{{{x}_{i}}\}_{i=1}^{N}$, ${{I}_{s}}=\{1,2,\cdots ,N\}$, di,j表示数据点xi和数据点xj之间的距离。对于数据集s中的每一个数据点xi, 可以用两个变量进行刻画: 局部密度和距离。计算局部密度${{\rho }_{i}}$, 如公式(1)所示[4]。
${{\rho }_{i}}=\sum\limits_{j\in {{I}_{s}}\{i\}}{\varphi ({{d}_{i,j}}-{{d}_{c}})}$ (1)
其中, $\varphi (x)=\left\{ \begin{align} & 1,x\ \ 0 \\ & 0,x\ge 0 \\ \end{align} \right.$, 参数${{d}_{c}}0$为截断距离。由公式(1)可知, 每个数据点的密度是在数据集s中与该数据点的距离小于dc的数据点个数(不包括本身)。
当数据点xi具有最大的局部密度时, 其距离为s与xi距离最大的数据点与xi之间的距离。除此之外, 对于其他不具有最大密度的数据点, 距离表示在所有局部密度大于xi的数据点当中, 与xi的距离最小的数据点与xi之间的距离。其计算如公式(2)所示[4]。
${{\delta }_{qi}}=\left\{ \begin{align} & \underset{ji}{\mathop{\min }}\,\{{{d}_{qi,qj}}\}\ \ \ \ \ i\ge 2 \\ & \underset{j\ge 2}{\mathop{\max }}\,\{{{d}_{q1,qj}}\}\ \ \ \ i=1 \\ \end{align} \right.$ (2)
其中, ${{\rho }_{q1}}\ge {{\rho }_{q2}}\ge \cdots \ge {{\rho }_{qN}}$。
(2) 决策图
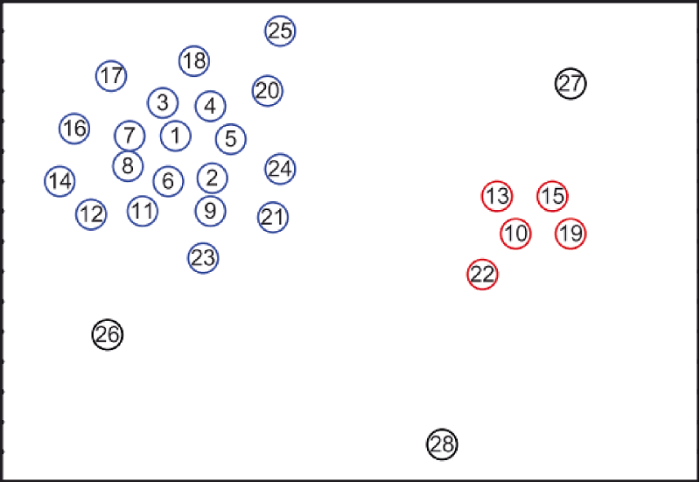
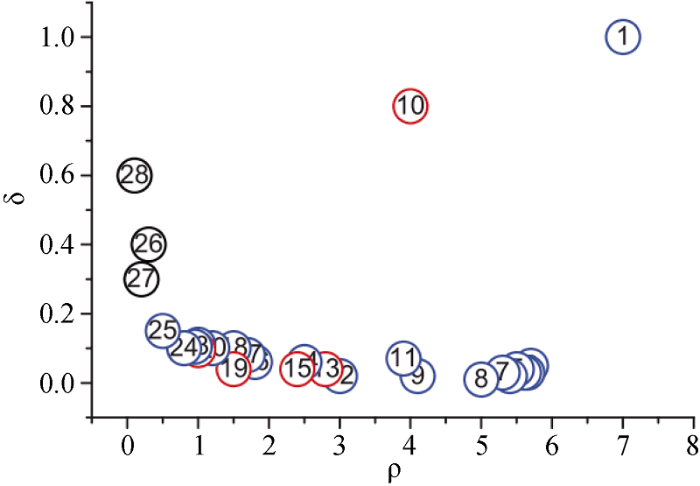
以局部密度ρ为横轴, 距离δ为纵轴, 对数据点的局部密度和距离刻画出相应的决策图。图1是由28个数据点包含的散点图, 相应的决策图如图2[4]所示。
粒子群算法[8-9]中, 种群中的粒子都有决定自身方向和位置的速度和由适应度函数决定的适应度值, 每个粒子通过向自身和群体曾达到的最优位置靠拢来动态调节自身位置, 通过迭代得到最优解。
假设粒子群的种群规模为N, 种群中个体维度为D, 每一个粒子都有两个属性: 当前的位置xi和飞行的速度vi,可表示为${{x}_{i}}=({{x}_{i,1}},{{x}_{i,2}},\cdots ,{{x}_{i,D}})$, ${{v}_{i}}=$ $({{v}_{i,1}},{{v}_{i,2}},\cdots ,{{v}_{i,D}})$, 其中i=1,2,…N。Pi为粒子xi在搜索解的过程中适应度值最高的位置; Pg为整个粒子群中粒子所达到的最优位置, 即Pg是所有Pi当中的适应度最大的值。在每一次迭代的过程中, 每个粒子通过这两个极值来调整自身的位置和飞行速度。位置和速度的更新如公式(3)和公式(4)所示[9]。
${{x}_{i}}={{x}_{i}}+{{v}_{i}}$ (3)
${{v}_{i}}=w\times {{v}_{i}}+{{c}_{1}}\times {{r}_{1}}\times ({{P}_{i}}-{{x}_{i}})+{{c}_{2}}\times {{r}_{2}}({{P}_{g}}-{{x}_{i}})$ (4)
其中, c1、c2为正数, 称之为加速因子; r1、r2为[0,1]中均匀分布的随机数; w是惯性权重因子。vmax是粒子的最大速率, ${{v}_{i}}\in [-{{v}_{\max }},{{v}_{\max }}]$, 当粒子的飞行速度超过vmax时, 粒子的飞行速度即为vmax。
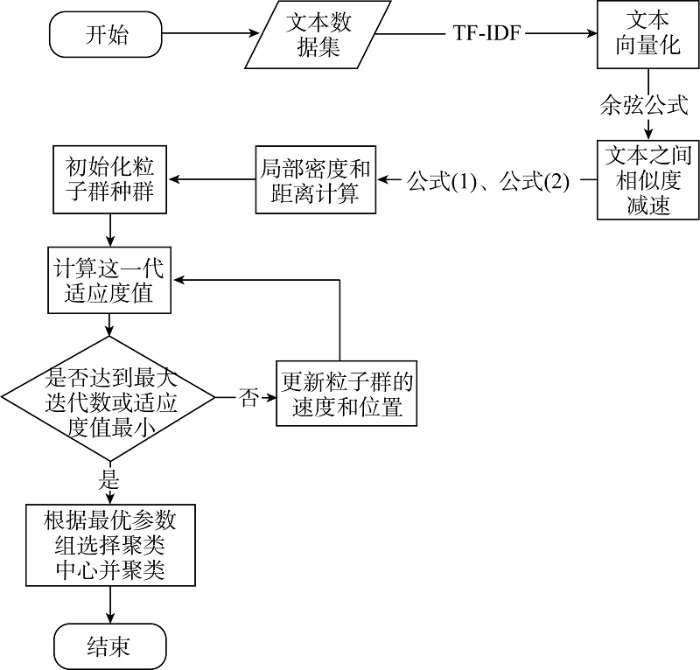
由于基本的CFSFDP算法存在上述缺陷, 本文引入了粒子群算法。改进CFSFDP算法的主要思想为: 利用粒子群算法调节CFSFDP算法中聚类中心的选取。即通过粒子群算法得到一个密度和距离的阈值, 在CFSFDP算法中密度值和距离均大于这个阈值的数据点为聚类中心, 根据选取出来的聚类中心进行聚类, 根据聚类结果计算适应度值, 将其作为粒子群算法更新的判断依据。将其运用到文本聚类中, 通过计算文本之间的相似性, 计算出每条文本的密度和局部距离, 实现文本聚类。算法的流程如图3所示。
对于全部的文本数据集, 采用目前最广泛的文本处理方法, 基于TF-IDF(Term Frequency-Inverse Document Frequency)[10-12]的向量空间模型VSM (Vector Space Model)[12]来表示文本, 向量的每一维为对应的特征词在该文本中的权重。文本相似度的度量方式是依据余弦距离[13-14], 值越大, 两条文本之间越相似, 距离越近。
粒子群算法在迭代过程中以适应度函数为依据, 适应度值越高说明该粒子的适应能力越好, 则会对下一代粒子的进化产生影响, 从而产生最优解。本文采用Rand系数[15]的倒数作为粒子群算法的适应度函数, 以此来评价聚类结果的好坏。
算法的具体过程如下:
①对文本集S进行预处理, 计算每条文本特征词的权重, 得到每条文本的向量化表示并且计算文本之间的相似度。
②将①中得到的每个向量作为一个数据点, 根据公式(1)和公式(2)计算每个数据点的局部密度和距离。
③初始化粒子群算法的参数, 主要包括种群规模m、惯性权重w、学习因子c1和c2{Invalid MML}{Invalid MML}、最大迭代次数t等。随机生成种群的初始速度和初始位置, 将粒子的初始位置赋值给粒子的初始最优位置Pi{Invalid MML}{Invalid MML}, 根据各个粒子的最优位置找到全局最优位置Pg{Invalid MML}{Invalid MML}, 位置由密度和距离确定。
④计算每个粒子对应的聚类结果。将每个粒子的位置传递给CFSFDP算法, 数据集中局部密度和距离均大于此粒子位置的数据点记为聚类中心, 并使用数据点归属方法对非聚类中心点进行归属, 完成聚类操作。
⑤对于每个粒子对应的聚类结果计算适应度值, 更新当前每个粒子的最优位置。并且根据每个粒子的最优位置更新种群全局最优位置, 更新每个粒子的位置和速度。
⑥判断是否满足收敛条件或是否达到最大迭代次数, 若是, 返回⑦; 否则, 迭代次数加1后执行④。
⑦根据种群的全局最优位置选取聚类中心, 通过数据点的归属方法完成聚类, 得到最终文本集的聚类结果, 算法结束。
实验中的数据来自于从高考咨询平台APP中考生向学校招生办提出的问题, 从问题库中随机选取7个类别: 询问学校代码和专业代码类、军训有关事项、高考加分情况、分数极差情况、询问招生办电话、省控线有关信息、是否有退档情况。从每一类中随机选取构造包含7类数据的数据集, 共构造出data1050、data3100、data5000三个数据集, 分别包含1 050、3 100、5 000条数据, 其中每个数据集中包含的各个类数如表1所示。利用“结巴分词”、停用词处理等对数据集进行预处理, 并且对不同的数据集进行实验分析比较。本文通过纯度(Accuracy)、精度(Precision)、召回率(Recall)和F度量值(F-Measure)[16-17] 4个评价指标衡量聚类效果。
表1 文本数据集
| 类 数据集 | 代码 | 军训 | 加分 | 极差 | 电话 | 省控线 | 退档 |
|---|---|---|---|---|---|---|---|
| data1050 | 200 | 100 | 200 | 100 | 150 | 200 | 100 |
| data3100 | 600 | 300 | 600 | 300 | 500 | 500 | 300 |
| data5000 | 1 000 | 400 | 1000 | 400 | 900 | 900 | 400 |
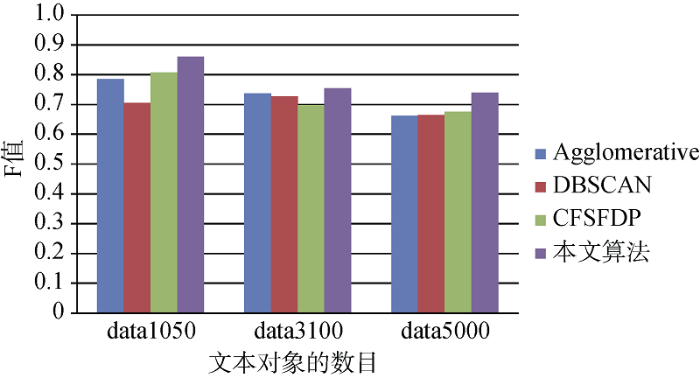
分别用层次聚类算法(Agglomerative Cluster)[18-19]、DBSCAN算法[20] 、基本的CFSFDP算法、以及本文算法对抽取的三个数据集进行聚类比较。其中Agglomerative Clustering算法因其可以适用于任意形状和任意属性的数据集在文本聚类方面也有广泛的应用。Agglomerative Clustering算法采用在三个数据集中设定的类别数目实验效果最佳的7。粒子群算法中种群数量设定为50, 最大迭代次数为30, 加速因子为2, 惯性权重因子为0.5。DBSCAN算法是基于密度的聚类算法中的一种经典算法, 具有较强的代表性。针对DBSCAN算法进行多次实验, 在数据集data1050中选取参数eps=0.8、minPts=30, 数据集data3100中参数eps=0.8、minPts=70, 数据集data5000 中选取参数eps=0.8、minPts=110效果相对最佳的实验结果。层次聚类算法、DBSCAN算法、基本的CFSFDP算法、本文算法总体F值比较如图4所示。
可见本文算法相对于其他三个算法在不同的数据集中聚类效果都较好。实验结果如表2所示, 可以看出本文算法在高考问询文本库中相比其他三个算法都有较好的效果。其中基本的CFSFDP 算法由于噪声点的影响造成同一个类中两个及以上的数据点成为数据中心导致聚类算法的不准确性。DBSCAN算法由于对参数eps(被认为是同一个类的文本之间的最大距离)和minPts(一条文本与其他文本的距离小于eps的个数大于等于minPts视为聚类中心)特别敏感, 在类中的数据发布密度不均匀的时候, eps较小时, 密度小的类会被划分成多个相似的类, eps较大时, 会使得距离较近且密度较大的类被合并成一个较大的类, 导致聚类效果不理想。层次算法比DBSCAN算法具有更好的效果, 但是Agglomerative Clustering算法的计算复杂度太高。
表2 4种算法的Accuracy、Precision、Recall、F-Measure值比较
| 算法 | 数据集 | Accuracy | Precision | Recall | F-Measure |
|---|---|---|---|---|---|
| Agglomerative | data1050 | 0.7305 | 0.7743 | 0.7969 | 0.7854 |
| data3100 | 0.7077 | 0.6976 | 0.7811 | 0.7370 | |
| data5000 | 0.6808 | 0.6598 | 0.6627 | 0.6612 | |
| DBSCAN | data1050 | 0.6486 | 0.6795 | 0.7332 | 0.7052 |
| data3100 | 0.6797 | 0.6761 | 0.7880 | 0.7278 | |
| data5000 | 0.6006 | 0.6270 | 0.6500 | 0.6643 | |
| CFSFDP | data1050 | 0.8171 | 0.8050 | 0.8090 | 0.8070 |
| data3100 | 0.750 | 0.7375 | 0.6617 | 0.6975 | |
| data5000 | 0.7425 | 0.7438 | 0.6189 | 0.6756 | |
| 本文算法 | data1050 | 0.8333 | 0.7171 | 0.9098 | 0.8609 |
| data3100 | 0.7574 | 0.7421 | 0.7676 | 0.7546 | |
| data5000 | 0.7712 | 0.7340 | 0.7450 | 0.7395 |
本文针对CFSFDP算法聚类中心选取的武断性的问题, 提出一种基于粒子群算法的CFSFDP算法。引入粒子群算法找到一对阈值, 将大于这对阈值的数据点作为聚类中心, 减少离散点对聚类结果的影响, 提高了聚类准确性。将此算法应用在从某高考咨询平台问题库中随机提取的问题中, 验证了本文算法的有效性和准确性, 能够帮助考生更准确高效地获得答案并且减轻了被咨询方的咨询量, 大大节省了双方的时间。但是该算法也存在局限性, 由于粒子群本身算法的特性, 在计算高纬度的问题时, 粒子群优化算法需要的粒子数较多, 导致计算复杂度通常很高。
詹春霞: 提出研究思路, 采集分析数据;
詹春霞, 王荣波: 进行实验, 起草并修改论文;
王荣波, 黄孝喜, 谌志群: 修改论文。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, http://pan.baidu.com/s/1bpL0WcJ。
[1] 王荣波. data1050.rar. 数据集data1050中包含的数据.
[2] 王荣波. data3100.rar. 数据集data3100中包含的数据.
[3] 王荣波. data5000.rar. 数据集data5000中包含的数据.
| [1] |
Introduce to Data Mining [M]. |
| [2] |
聚类算法研究 [J].Clustering Algorithms Research [J]. |
| [3] |
文本聚类算法综述 [J].Summary of Text Clustering Algorithms [J]. |
| [4] |
Clustering by Fast Search and Find of Density Peaks [J].https://doi.org/10.1126/science.1242072 Magsci [本文引用: 7] 摘要
a Cluster analysis is aimed at classifying elements into categories on the basis of their similarity. Its applications range from astronomy to bioinformatics, bibliometrics, and pattern recognition. We propose an approach based on the idea that cluster centers are characterized by a higher density than their neighbors and by a relatively large distance from points with higher densities. This idea forms the basis of a clustering procedure in which the number of clusters arises intuitively, outliers are automatically spotted and excluded fromthe analysis, and clusters are recognized regardless of their shape and of the dimensionality of the space inwhich they are embedded. We demonstrate the power of the algorithm on several test cases.
|
| [5] |
基于密度的层次聚类算法研究 [D].Research on Density- based Hierarchical Clustering Algorithm[D]. |
| [6] |
Fuzzy Clustering by Fast Search and Find of Density Peaks [C]// |
| [7] |
一种基于簇中心点自动选择策略的密度峰值聚类算法 [J].https://doi.org/10.11896/j.issn.1002-137X.2016.7.046 URL [本文引用: 1] 摘要
针对基于密度峰值的聚类算法(CFSFDP)无法自行选择簇中心点的问题,提出了CFSFDP改进算法。该算法采用簇中心点自动选择策略,根据簇中心权值的变化趋势搜索"拐点",并以"拐点"之前的一组点作为各簇中心,这一策略有效避免了通过决策图判决簇中心的方法所带来的误差。仿真实验采用5类数据集,并与DBSCAN及CFSFDP算法进行了对比,结果表明,CFSFDP改进算法具有较高的准确度及较强的鲁棒性,适用于较低维度的数据的聚类分析。
Improved Density Peaks Based Clustering Algorithm with Strategy Choosing Cluster Center Automatically [J].https://doi.org/10.11896/j.issn.1002-137X.2016.7.046 URL [本文引用: 1] 摘要
针对基于密度峰值的聚类算法(CFSFDP)无法自行选择簇中心点的问题,提出了CFSFDP改进算法。该算法采用簇中心点自动选择策略,根据簇中心权值的变化趋势搜索"拐点",并以"拐点"之前的一组点作为各簇中心,这一策略有效避免了通过决策图判决簇中心的方法所带来的误差。仿真实验采用5类数据集,并与DBSCAN及CFSFDP算法进行了对比,结果表明,CFSFDP改进算法具有较高的准确度及较强的鲁棒性,适用于较低维度的数据的聚类分析。
|
| [8] |
Partical Swarm Optimization [C]// |
| [9] |
粒子群算法的基本理论及其改进研究 [D].The Basic Theory of Partical Swarm Optimization and Its Improvement[D]. |
| [10] |
一种结合词项语义信息和TF-IDF方法的文本相似度量方法 [J].https://doi.org/10.3724/SP.J.1016.2011.00856 URL [本文引用: 1] 摘要
传统的文本相似度量方法大多采用TF-IDF方法把文本建模为词频向量,利用余弦相似度量等方法计算文本之间的相似度.这些方法忽略了文本中词项的语义信息.改进的基于语义的文本相似度量方法在传统词频向量中扩充了语义相似的词项,进一步增加了文本表示向量的维度,但不能很好地反映两篇文本之间的相似程度.文中在TF-IDF模型基础上分析文本中重要词汇的语义信息,提出了一种新的文本相似度量方法.该方法首先应用自然语言处理技术对文本进行预处理,然后利用TF-IDF方法寻找文本中具有较高TF-IDF值的重要词项.借助外部词典分析词项之间的语义相似度,结合该文提出的词项相似度加权树以及文本语义相似度定义计算两篇文本之间的相似度.最后利用文本相似度在基准文本数据集合上进行聚类实验.实验结果表明文中提出的方法在基于F-度量值标准上优于TF-IDF以及另一种基于词项语义相似性的方法.
A Text Similarity Measurement Combining Word Semantic Information with TF-IDF Method [J].https://doi.org/10.3724/SP.J.1016.2011.00856 URL [本文引用: 1] 摘要
传统的文本相似度量方法大多采用TF-IDF方法把文本建模为词频向量,利用余弦相似度量等方法计算文本之间的相似度.这些方法忽略了文本中词项的语义信息.改进的基于语义的文本相似度量方法在传统词频向量中扩充了语义相似的词项,进一步增加了文本表示向量的维度,但不能很好地反映两篇文本之间的相似程度.文中在TF-IDF模型基础上分析文本中重要词汇的语义信息,提出了一种新的文本相似度量方法.该方法首先应用自然语言处理技术对文本进行预处理,然后利用TF-IDF方法寻找文本中具有较高TF-IDF值的重要词项.借助外部词典分析词项之间的语义相似度,结合该文提出的词项相似度加权树以及文本语义相似度定义计算两篇文本之间的相似度.最后利用文本相似度在基准文本数据集合上进行聚类实验.实验结果表明文中提出的方法在基于F-度量值标准上优于TF-IDF以及另一种基于词项语义相似性的方法.
|
| [11] |
An Information-treoretic Perspective of TF-IDF Measures [J].https://doi.org/10.1016/S0306-4573(02)00021-3 URL Magsci 摘要
<h2 class="secHeading" id="section_abstract">Abstract</h2><p id="">This paper presents a mathematical definition of the “probability-weighted amount of information” (PWI), a measure of specificity of terms in documents that is based on an information-theoretic view of retrieval events. The proposed PWI is expressed as a product of the occurrence probabilities of terms and their amounts of information, and corresponds well with the conventional term frequency–inverse document frequency measures that are commonly used in today’s information retrieval systems. The mathematical definition of the PWI is shown, together with some illustrative examples of the calculation.</p>
|
| [12] |
Term Weight Approaches in Automatic Text Retrieval [J].https://doi.org/10.1016/0306-4573(88)90021-0 URL [本文引用: 2] 摘要
The experimental evidence accumulated over the past 20 years indicates that text indexing systems based on the assignment of appropriately weighted single terms produce retrieval results that are superior to those obtainable with other more elaborate text representations. These results depend crucially on the choice of effective termweighting systems. This article summarizes the insights gained in automatic term weighting, and provides baseline single-term-indexing models with which other more elaborate content analysis procedures can be compared.
|
| [13] |
基于向量空间模型的文本相似度算法研究 [D].Research on Text Similarity Algorithm Based on Vector Space Modal[D]. |
| [14] |
基于文本分类的文档相似度计算 [J].https://doi.org/10.3969/j.issn.1007-757X.2008.12.016 URL [本文引用: 1] 摘要
如何从成千上万篇文档中找出与指定文档相似的所有文档,首先要做的第一件事就是判断其类别,也就是分类;在判定类别后,再进一步计算,找出同类中所有与指定文档内容相似的文档。由于文档相似度的计算和文本分类过程很相似,所以可以借助指定文档的分类结果,即类别和文档特征向量值,通过进一步计算与同类中其他文档的相似度值,找出超过阂值的文档,即找出与指定目标内容相似的文档。
Simility Calculation Based on Text Classification [J].https://doi.org/10.3969/j.issn.1007-757X.2008.12.016 URL [本文引用: 1] 摘要
如何从成千上万篇文档中找出与指定文档相似的所有文档,首先要做的第一件事就是判断其类别,也就是分类;在判定类别后,再进一步计算,找出同类中所有与指定文档内容相似的文档。由于文档相似度的计算和文本分类过程很相似,所以可以借助指定文档的分类结果,即类别和文档特征向量值,通过进一步计算与同类中其他文档的相似度值,找出超过阂值的文档,即找出与指定目标内容相似的文档。
|
| [15] |
On Clustering Validation Techniques [J]. |
| [16] |
The K-Means-Type Algorithms Versus Imbalanced Data Distributions [J].https://doi.org/10.1109/TFUZZ.2011.2182354 URL Magsci [本文引用: 1] 摘要
K-means is a partitional clustering technique that is well-known and widely used for its low computational cost. The representative algorithms include the hard k-means and the fuzzy k-means. However, the performance of these algorithms tends to be affected by skewed data distributions, i.e., imbalanced data. They often produce clusters of relatively uniform sizes, even if input data have varied cluster sizes, which is called the "uniform effect." In this paper, we analyze the causes of this effect and illustrate that it probably occurs more in the fuzzy k-means clustering process than the hard k-means clustering process. As the fuzzy index m increases, the "uniform effect" becomes evident. To prevent the effect of the "uniform effect," we propose a multicenter clustering algorithm in which multicenters are used to represent each cluster, instead of one single center. The proposed algorithm consists of the three subalgorithms: the fast global fuzzy k-means, Best M-Plot, and grouping multicenter algorithms. They will be, respectively, used to address the three important problems: 1) How are the reliable cluster centers from a dataset obtained? 2) How are the number of clusters which these obtained cluster centers represent determined? 3) How is it judged as to which cluster centers represent the same clusters? The experimental studies on both synthetic and real datasets illustrate the effectiveness of the proposed clustering algorithm in clustering balanced and imbalanced data.
|
| [17] |
符号数据聚类评价指标研究 [D].Study on the Evaluation Index Symbol of Data Clustering[D]. |
| [18] |
Fast Agglomerative Clustering Using a K-nearest Neighbor Graph [J].https://doi.org/10.1109/TPAMI.2006.227 URL PMID: 17063692 [本文引用: 1] 摘要
We propose a fast agglomerative clustering method using an approximate nearest neighbor graph for reducing the number of distance calculations. The time complexity of the algorithm is improved from O(tauN2) to O(tauNlogN) at the cost of a slight increase in distortion; here, tau denotes the number of nearest neighbor updates required at each iteration. According to the experiments, a relatively small neighborhood size is sufficient to maintain the quality close to that of the full search.
|
| [19] |
层次聚类算法的研究及应用 [D].Research and Application of Hierarchical Clustering Algorithm [J]. |
| [20] |
DBSCAN聚类算法的研究与改进 [J].An Improved DBSCAN Clustering Algorithm [J]. |

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}