李飞, 张健 , 王宗水
, 王宗水
Li Fei, Zhang Jian, Wang Zongshui
中图分类号: TP393
通讯作者:
收稿日期: 2017-03-22
修回日期: 2017-05-14
网络出版日期: 2017-06-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】从文献计量和社会网络分析的角度对社会化推荐进行内容特征及网络演化的研究, 归纳领域研究热点和发展趋势。【方法】以WoS数据库为数据源, 采用人工判读法、关键词共现、文献计量、社会网络分析及数据可视化等方法对样本数据进行数据挖掘和关联分析。【结果】检索到社会化推荐类文献3 701篇, 论文数量整体呈上升趋势, 以发文量阈值为阶段划分标准, 将社会化推荐的发展演化趋势划分为三个阶段, 各阶段研究特征明显。【局限】仅以关键词为探究文献内容特征的依据, 内容深度挖掘相对不足, 其中阶段划分是为了分析研究内容及演化趋势的变化, 并不存在统一的划分标准。【结论】我国学者在该领域的国际影响力逐年上升, 领域研究内容方面阶段性变化特征明显, 社会化媒介、协同过滤等传统研究方向一直保持较高关注度。
关键词:
Abstract
[Objective] This paper summarizes the content characteristics and network evolution of social recommendation research based on the of bibliometrics and social network analysis. [Methods] First, we collected the data of social recommendation research from the Web of Science database. Then we analyzed the data with manual interpretation, keywords co-occurrence analysis, bibliometrics, social network analysis and data visualization. [Results] A total of 3701 articles on social recommendation were retrieved, which have been increasing recently. Based on the threshold of papers published each year, we divided the development of social recommendation research into three distinct stages. [Limitations] We only used keywords to explore the characteristics of the relevant document contents, which could be improved with in-depth text mining. There is lack of uniform criterion to classify the evolution stages of the related research. Our study only shows the changing of contents and development trends. [Conclusions] The international impacts of Chinese scholars have been rising in social recommendation studies, which highly focus on the topics of social media and collaborative filtering.
Keywords:
“互联网+”、人工智能、4G/LTE、云计算等新兴技术产业的迅猛发展, 使得快速低廉的网络通信设备得到了极大的应用普及。Web2.0、社会媒体、社交平台等网络应用的逐步推广, 致使用户原创信息内容突增, 频繁的用户交互, 让更多带有社会关系属性的信息呈现出爆炸增长的态势[1]。面对海量异构信息过载问题, 使用线上推荐系统可以为用户有效地过滤冗余信息, 提高服务质量、减少成本投入和噪声影响[2-4]。开放自由的网络环境和社交媒介极大提高了用户的参与程度[5], 为了缓解数据稀疏冷启动等问题, 学者们将社会属性融入到传统的推荐框架中, 构建以社会关系网络为主的轻量级知识体系, 通过挖掘用户间协作及信任关系, 提高整体系统的推荐质量及用户体验。
新技术领域已表现出较好的发展前景和应用潜力, Facebook、LinkedIn、豆瓣网、微博、Last.fm等社交媒体中好友推荐服务展现出较为广阔的商业用途, 文献[6-11]关于社会化推荐的研究也体现出学术界关注度的上升。近些年, 伴随社交信息的不断增多, 更深层次的社会关系网络被挖掘利用, 学者们对社会化推荐类的研究呈现出全面、多元化等特点, Wang等、Quijano-Sanchez等通过引入新的参数类型将用户社会化属性融入到传统的推荐框架, 构建出数据紧密、扩展性较好的用户推荐框架[12-13]; Hotho等受网页排序思想的启发提出大众分类搜索和FolkRank排序相融合的推荐算法[14]; Rendle等借鉴物理学概念提出RTF算法, 利用张量分解进行高维数据降维排序[15]; Song等基于图聚类将用户资源关系用二分图表示, 较好地提高了推荐算法的效率[16]; Abbasi等通过将高层次标签特征和低层次图像特征进行组合训练, 得到的混合特征向量分类器较好地提升了分类器的性能[17]; Eck等提出直接预测音频内容的方法, 缓解了系统冷启动问题[18]; 此外与传统推荐算法模型的结合仍旧保持着较高的关注度, 矩阵分解[11]、协同过滤[19]等算法融合类的研究, 针对阶段领域关键技术的评述性研究[20]以及改进算法框架、调整模型参数、优化预测结果等研究[21-22]。但少有学者从文献计量和社会网络分析的角度对领域相关文献进行统计分析, 更缺乏对本领域发展历程和研究内容的比较分析。
鉴于此, 本文首先通过分析现阶段社会化推荐领域的研究现状, 简述此领域所涉及的相关技术和应用场景, 分析领域所面临的热点问题和主要挑战。为了进一步探究比较领域演化过程和发展趋势, 本文以国际权威文献数据库Web of Science为基础样本数据源, 借助BICOMB2①(①http: //www.cmu.edu.cn/bc/.)、Pajek②(②http: //vlado.fmf.uni-lj.si/pub/networks/pajek/.)、Excel③(③https: //www.microsoft.com/zh-cn.)、CorelDRAW④(④http: //www.corel.com/cn/.)等工具, 采用人工判读[23]、文献计量[24]、社会网络分析[25]、关键词共现[26]等方法, 对样本数据进行文本挖掘和网络演化分析, 并以论文量阈值为整体阶段演化的划分标准[27], 将社会化推荐划分成三个阶段, 通过梳理关联阶段数据找出各阶段的发展状况, 并根据整体趋势特征预测领域的研究前景和发展方向。
社会化推荐所涉及的社会网络分析技术源自复杂网络领域, 是描述自然科学、管理科学、社会科学等复杂互联模型的有力工具。其中网络建模、社会影响力分析、社区检测、安全隐私等内容都在该领域占有较大的研究比重。
从社会学角度研究发现, 相同社会群体中的用户可以形成相对安全的交互平台, 用户间的决策会互相影响, 相互联系的群体会受其周边环境等社会因素影响, 而其群体内部用户行为兴趣表现出较高的相似性[28-29]。由于用户社会特性的突显, 使得考虑关系链接属性的推荐系统, 具有较高的预测精准度和个性化效果。并且社会关系属性的加入, 可以更为真实地模拟现实生活中的推荐流程。社会化推荐类的研究本身基于社会网络分析理论, Siersdorfer等从方法特性角度提出概念定义“一种基于多维社会网络环境的用户推荐预测过程”[30], Guy等根据应用平台定义为“一种借助社会媒介解决信息过载问题的方法技术”[31], Arazy等、Kazienko等从多领域规则角度出发进行定义[32-33], 也有学者从构建系统框架角度进行定义[34], 其中文献[35]从广义和狭义两个层面进行定义。笔者通过归纳总结现阶段研究成果和相关文献, 遵循文献[35]和第19届国际万维网大会(WWW2010)“社会推荐导论”中[36]的界定方法从狭义层面给出本文定义: 社会化推荐是一种结合社会网络与推荐系统的交叉学科, 是以社会媒介为平台, 在传统的推荐算法框架中融入用户社会属性信息, 用以缓解数据稀疏冷启动、提高推荐效果性能的智能化信息过滤技术。
社会化推荐的主要生成技术是由传统推荐算法与社会化网络分析技术融合产生的。有学者通过量化社交关系、调整模型参数, 提高新框架模型的可扩展性与适应性, 如STE[37]、SocialMF[38]、TrustWalker Model[39]等, 也有通过结合网络结构分析将用户关系信息填充至属性列表改进推荐过程的, 如SoNARS[40]、GLOSS[41]、社会网络协同过滤[42]等, 还有从用户角度出发进行社会化推荐建模的[9-10]。商业模式的应用成熟也为社会化推荐提供了较为广阔的开发环境和基础数据来源, 社会书签网站[43]、Twitter[44]、社交推荐电视[45]、Last.fm⑤(⑤http: //www.last.fm/.)等都为用户提供了个性化推荐服务。总结现阶段技术发现多算法融合是研究趋势, 协同过滤、矩阵分解以及概率模型等传统算法依旧是较常用的方法, 张量分解是最近关注度较高的应用技术, 其主要思想是通过将高维空间预测问题分解到低维度空间矩阵进行优化处理[15]。
目前社会化推荐应用受到了越来越多的关注, 但传统推荐固有问题如数据稀疏冷启动现象等仍是当下研究所面临的主要难题。在数据表示层面, 传统推荐系统大多为用户-项目双向二维数据结构表示, 而社会化推荐则更多通过三元数组或超三角图(用户、资源、标签)三维数据结构来表示, 如何提高算法模型可扩展性是未来一个有趣的研究方向。现阶段文献大多基于用户的评级预估, 通过评分数值大小反映用户的喜好, 如何更好地将非结构化数据和社会关系属性融入传统的推荐框架, 某种程度上仍需进一步研究。大数据环境下新兴应用的推广成熟, 进一步加剧了用户异构数据的井喷现象, 像社会关系属性的确定及量化处理, 跨社会媒体异构数据的分析, 社会网络跨平台模型的建立, 用户兴趣偏好的迁移捕捉等[46-48]一系列新问题的出现, 还有待探索。
随着人工智能和深度学习研究的不断深入, 社会化推荐在算法层面与新兴技术领域的融合, 表现出较高的预测准确度和较好的推荐效果, 如将协同过滤、timeSVD++模型与SDAE框架结合解决冷启动问题[49]; 通过混合推荐使用深度神经网络进行项目内容特征学习, 缓解电影评分预测中的数据稀疏问题[50], 在Twitter应用平台上融入前馈神经网络进行标签字符学习, 从而在深层次范围分析非结构化数据[51]; 还有将社交网络纳入用户间的隐含层单元, 借助RBM模型获取用户偏好提高兴趣学习的精准度[52], 以及借助并行递归神经网络结构p-RNN进行绘画建模扩充[53]。
通过对文献研究进行归纳总结, 不难发现社会化推荐隶属于推荐系统与社会网络分析研究的交叉领域, 通过引入用户社会关系可以有效缓解传统推荐系统所面临的数据稀疏冷启动等问题。但新网络环境下数据结构的变换、服务模式的部署、时变网络信息及其负面关系的处理等一系列技术问题, 仍亟需深入探究解决。近些年, 随着社交化推荐的快速发展, 业内涌现出大量高水平的理论研究成果及应用系统, 因此有必要对已现有文献进行知识梳理, 通过统计计量和文本挖掘深入剖析此领域的发展历程和研究现状, 为未来的研究提供理论依据。
在现阶段社会化推荐研究发展的基础上, 为了更进一步探究领域研究内容层面的特征关系和演化趋势, 通过文本挖掘获取论文内容特征, 使用文献计量[24]、关键词共现[26]和数据可视化的方法, 对现阶段国际主流期刊的文献进行系统的定量和定性分析, 科学直观地表示此领域研究现状。
选取Web of Science为样本数据来源, 检索式为: 主题= (“social recommend*”); 研究方向= (“COMPUTER SCIENCE”); 时间跨度=(“1997-2016”), 数据库= “SCI-EXPANDED, SSCI, CPCI-S, CPCI-SSH, ESCI, CCR-EXPANDED, A&HCI, IC”; 检索日期: “2017年1月21日”, 检索结果为3 701篇文献, 经人工判读和数据预处理, 删除无法获取及其与研究内容不相关的论文, 最后筛选得到2 899篇。
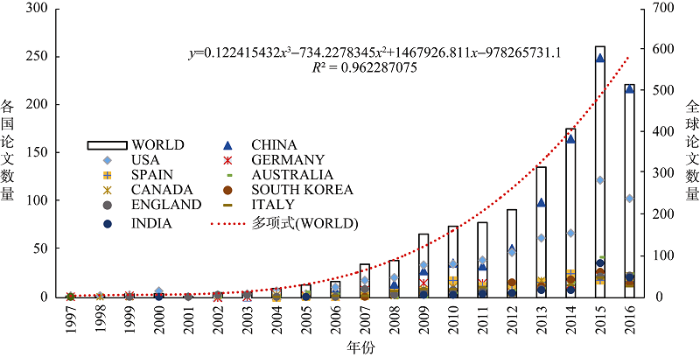
图1为全球整体论文数量的年度分布和发展趋势, 这些文献由85个国家和区域的2 929位学者完成, 其中论文量前10位的国家年度发文分布情况一并予以标注, 统计结果是全球大部分论文来自少数几个高产国家, 论文分布基本符合巴莱多定律。
根据发文量年度数据分布表绘制论文增长变化曲线, 从图1可以发现, 全球整体研究呈现出类指数级上升趋势, 趋势线回归公式为$y=0.122415432{{x}^{3}}$ $-734.2278345{{x}^{2}}+1467926.811x-978265731.1$, 根据公式计算出判定系数R2=0.962287075, 接近1, 表示回归方程拟合性较好, 趋势线可信性较高。通过初步分析发文量发现: 1997年-2008年的年论文量均小于100, 合计占文献总量的比重也较少, 仅为11.07%; 2009年-2013年论文量分布在(100, 350)区间内, 总量占有比重为36.05%; 2014年-2016年论文量均大于350, 合计发文量占整体的52.88%, 因此采用文献[27]的方法, 按照论文量阈值将社会化推荐研究阶段分成: 1997-2008、2009-2013、2014- 2016三个阶段。通过进一步对比分析发现社会化推荐研究初期, 由于相关理论缺乏、学科应用场景单一, 导致相关科技文献发文量较少, 但随着社交媒体的发展成熟、理论研究的不断深入及其相关学者和机构的关注度上升, 发文量增长较快, 特别是在2008年和2014年前后都有明显的文献扩增趋势①(①此处采集数据的时间节点可能会有部分2016年的文献数据未被WoS收录的情况存在, 但按照阈值区分阶段2016年度发文量较符合第三阶段的特性, 故将其划分入第三阶段且对整体的阶段演化趋势分析产生的影响较小。)。自1997年代表性文献[54]发表以来, 社会化推荐以其良好的发展前景和应用潜力引起了大量学者的关注, 2009年国际顶级会议RecSys开始设立社会化推荐的专题研讨会, 其中报告分会场论文4篇(共28篇年度会议论文), 成为该领域中最为热点的应用研究之一②(②http://dblp.uni-trier.de/db/conf/recsys/recsys2009.html.)。
(1) 各国论文量统计
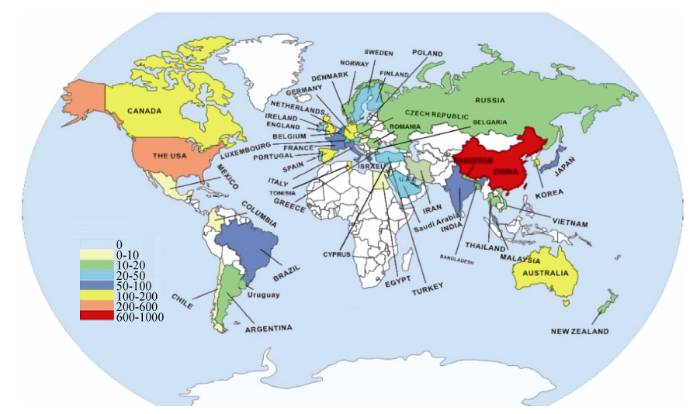
从图1可以看出, 论文量前10位的国家对社会化推荐的关注度整体随时间推移不断上升, 此处统计以作者最新发表文章所列的第一单位所属国家为准, 通过统计分析发现这些论文高产国家的发文量占全球的84.94%。根据各国论文量得到的全球论文地理分布如图2所示, 由于涉及国家较多, 此处仅对论文量前50名的国家进行标注, 以不同的灰度标记来体现不同国家的论文量差异。
由图2可知, 除几个高产国家外, 欧洲发达国家文献量明显较多, 从论文引证的视角判断学术价值, 发现早期的高水平论文几乎全部产生自欧美国家。我国此领域研究虽然起步较晚, 但随着关注度的提高, 论文量呈现逐年上升趋势, 2010年论文量首超美国, 总量占到整体的31.70%; 2017年国际人工智能协会首次考虑中国春节因素而决定改期①(①http://www.weibo.com/3121700831/Du2bssdl8?type=repost.), 体现出华人学者影响力的提高, 但就论文整体的引用量相比欧美发达国家依旧较弱, 业内主流核心期刊依旧较少, 究其原因不难发现互联网起步较早是欧美发达国家的优势, 然而随着国内政策、技术及其社交平台的快速发展②(②http://www.chyxx.com/industry/201605/412976.html.), 我国学者在全球的影响力和学术地位呈现出赶超之势。
(2) 主要期刊分布
从期刊分布角度统计论文量, 发文量最高的前15个期刊如表1所示, 通过InCites数据库获取期刊的影响因子和立即指数, 合计论文量约占到整体的10.15%, 而且这些期刊全部来自欧美等发达国家, 其中EXPERT SYSTEMS WITH APPLICATIONS、INFORMATION SCIENCES和KNOWLEDGE-BASED SYSTEMS等期刊的发文量、质量及其影响力也呈现出一定的领先优势。进一步分析发现社会化推荐领域的高产期刊大多来自计算机科学、人工智能、信息系统、软件工程和管理科学等领域的专业期刊, 此外, 检索发现国际顶级学术会议和学协会, 例如SIGIR、SIGKDD、IEEE和AAAI等每年也都会有大量此领域的论文发表, 并对领域研究发展产生比较重要的影响。
表1 全球发文量前15的期刊
| 序号 | 期刊 | 出现频次 | 发文百分比 | 影响因子 | 立即指数 | 国家 |
|---|---|---|---|---|---|---|
| 1 | EXPERT SYSTEMS WITH APPLICATIONS | 52 | 1.393 | 2.981 | 0.938 | USA |
| 2 | INFORMATION SCIENCES | 38 | 1.018 | 1.832 | 0.500 | USA |
| 3 | KNOWLEDGE-BASED SYSTEMS | 31 | 0.83 | 1.702 | 0.291 | NETHERLANDS |
| 4 | NEUROCOMPUTING | 29 | 0.777 | 2.392 | 0.563 | NETHERLANDS |
| 5 | MULTIMEDIA TOOLS AND APPLICATIONS | 29 | 0.777 | 1.331 | 0.125 | NETHERLANDS |
| 6 | IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING | 27 | 0.723 | 2.476 | 0.257 | USA |
| 7 | ONLINE INFORMATION REVIEW | 25 | 0.67 | 1.152 | 0.077 | ENGLAND |
| 8 | DECISION SUPPORT SYSTEMS | 25 | 0.67 | 2.604 | 0.246 | NETHERLANDS |
| 9 | IEEE TRANSACTIONS ON MULTIMEDIA | 21 | 0.562 | 1.152 | 0.077 | USA |
| 10 | JOURNAL OF UNIVERSAL COMPUTER SCIENCE | 20 | 0.536 | 0.546 | 0.048 | AUSTRIA |
| 11 | MULTIMEDIA SYSTEMS | 19 | 0.509 | 1.410 | 0.349 | GERMANY |
| 12 | JOURNAL OF INFORMATION SCIENCE | 17 | 0.455 | 2.604 | 0.246 | ENGLAND |
| 13 | KNOWLEDGE AND INFORMATION SYSTEMS | 16 | 0.428 | 1.702 | 0.291 | ENGLAND |
| 14 | JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION SCIENCE AND TECHNOLOGY | 15 | 0.402 | 2.452 | - | USA |
| 15 | JOURNAL OF MANAGEMENT INFORMATION SYSTEMS | 15 | 0.402 | 3.025 | 0.098 | USA |
(3) 关键词统计
关键词是文献研究内容特征的高度概括和总结, 通过文献中关键词共现往往可以较为有效地获取该领域的研究热点[55]。为避免不同阶段因样本量不同而引起的误差, 此处采用定量分析选取各阶段引用量最高的500篇文献作为样本, 高引用量在某种程度上不仅可以反映此领域研究的热点和趋势, 还能体现此文献的领域研究重要性。采用BICOMB2对样本数据进行关键词提取, 通过人工判读手动修改关键词列表, 将大小写、单复数、同义词、缩写等具有相同含义的词汇进行合并处理以保持检索词汇一致性, 通过Excel进行词频汇总统计排序。表2为三个阶段排在前10位的高频词汇, 其中阶段一共有1 405个关键词, 词频≥2的有573个, 占阶段总词量的40.78%; 阶段二有2 065个关键词, 词频≥2的有263个, 占整体的12.73%; 阶段三有1 390个关键词, 词频≥2的有176个, 占整体的12.66%。
表2 三个阶段关键词词频统计
| 序号 | 阶段一 | 阶段二 | 阶段三 | |||
|---|---|---|---|---|---|---|
| 关键词 | 词频 | 关键词 | 词频 | 关键词 | 词频 | |
| 1 | recommender system | 120 | recommender system | 134 | recommender system | 131 |
| 2 | social network | 65 | social network | 89 | social network | 76 |
| 3 | collaborative filtering | 37 | social media/collaborative filtering | 37 | collaborative filtering | 49 |
| 4 | personalization | 29 | algorithms | 36 | social media | 33 |
| 5 | trust | 26 | social network analysis | 26 | location based social network | 29 |
| 6 | social network analysis | 19 | social tagging | 22 | algorithms | 18 |
| 7 | information retrieval/ experimentation | 18 | data mining | 21 | topic modeling | 16 |
| 8 | social tagging/data mining/ algorithms/ontology | 17 | trust | 18 | social recommendation/ matrix factorization | 15 |
| 9 | NLP | 16 | Personalization/Twitter | 16 | Twitter/Personalization/data mining/location recommendations | 13 |
| 10 | evaluation | 15 | experimentation | 15 | online social networks | 12 |
| 频次累计百分比 | 15.88% | 13.27% | 20.14% | |||
(1) 共词分析法
表述学科领域研究主题的关键词出现在同一文献中的现象称为关键词共现, 以关键词在同一文献出现的频率为基础进行聚类分析常被用于探索潜在主题和学科间的发展联系及学术趋势演化[28, 56]。相比其他文本分析方法, 关键词共现使用定量分析法概述研究领域的热点, 以客观数据呈现学科研究的现有水平[57-58], 通过横向比较纵向分析形成的共现网络得到领域学科特点和关键词间亲疏关系[59-60]。本文使用共现指数来表示不同关键词间的关联程度, 此处借鉴Ochiia系数法进行关键词共现的研究[61-62], 如公式(1)所示。
${{O}_{mn}}=\frac{{{C}_{mn}}}{C_{m}^{1/2}\times C_{n}^{1/2}}$ (1)
其中, Omn为关键词m和n之间的Ochiia系数, Cmn为关键词i和j共现数, Cm为关键词m出现总次数, Cn为关键词n出现总次数。
(2) 社会网络分析
作为社会化推荐的主要研究领域, 社会网络分析源自复杂网络, 是一种综合图论和数学模型的定量分析方法, 主要针对网络成员间的社会关系, 进行量化分析研究[25]。目前的社会网络分析软件较多, 如Ucinet、Pajek、NetMiner和StOCNET等, 本文借助BICOMB2生成关键词共现矩阵, 使用Pajek辅助分析矩阵数据, 构建关键词间的特征关系网络。依据链接网络结构的统计特性, 分析归纳出社会化推荐的主题演化过程和结构变化规律。
网络结构特性可以从中心性、度分布、聚集度系数和网络平均度刻画描述[63-65]。本研究更关心各节点距离中心的程度, 故选用接近度中心(Closeness Centrality)描述节点中心性, 在构建的无向连通图中, 节点vi到节点vj的距离为dij, 则接近度中心性计算如公式(2)所示。
$Cc({{v}_{i}})=\frac{N-1}{\sum\limits_{j=1,j\ne i}^{N}{{{d}_{ij}}}}$ (2)
在构建的关键词网络图中, M为网络边数, N为网络节点数, 则网络平均密度如公式(3)所示。
$L=\frac{2M}{N(N-1)}$ (3)
通过聚类系数来体现临近节点的集团性质, CC1表示具有一个邻接节点的聚集度系数, 节点v直接连接且包含1个邻居节点的节点用$\left| E({{G}_{1}}(v)) \right|$表示, $deg(v)$表示关键词v的邻接节点数, 如公式(4)所示。
$C{{C}_{1}}=\frac{2\left| E({{G}_{1}}(v)) \right|}{deg(v)\times (deg(v)-1)}$ (4)
整体网络节点间亲密程度使用平均距离描述, 网络中所有节点vi的度ki的平均度如公式(5)所示。
$\left\langle k \right\rangle =\frac{1}{N}\sum\limits_{i=1}^{N}{{{k}_{i}}}$ (5)
以词频统计结果为基础建构关键词共现系数矩阵, 根据本文对社会化推荐的定义, 此处主要研究推荐系统和社会网络两个方面, 所以仅列出各阶段部分较具代表性的高频词汇在这两个方面的Ochiia系数, 如表3所示。
表3 三个阶段推荐系统和社会网络共现系数统计
| 阶段一 | 推荐系统 | 社会网络 | 阶段二 | 推荐系统 | 社会网络 | 阶段三 | 推荐系统 | 社会网络 | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 关键词 | 词频 | 共现系数 | 关键词 | 词频 | 共现系数 | 关键词 | 词频 | 共现系数 | |||
| 协同过滤 | 37 | 0.41 | 0.06 | 社会化媒介 | 37 | 0.04 | 0.07 | 协同过滤 | 49 | 0.42 | 0.16 |
| 个性化 | 29 | 0.34 | 0.09 | 协同过滤 | 37 | 0.38 | 0.30 | 社会化媒介 | 33 | 0.12 | 0.04 |
| 信誉 | 26 | 0.18 | 0.26 | 算法 | 26 | 0.22 | 0.14 | 基于位置的 社会网络 | 29 | 0.08 | 0.06 |
| 社会网络分析 | 19 | 0.13 | 0 | 社会网络 分析 | 22 | 0.13 | 0 | 算法 | 18 | 0.04 | 0.08 |
| 信息检索 | 18 | 0.04 | 0.06 | 社会标签 | 21 | 0.15 | 0.02 | 主题建模 | 16 | 0.09 | 0.06 |
| 实验法 | 18 | 0.17 | 0.12 | 数据挖掘 | 19 | 0.10 | 0.04 | 社会化推荐 | 15 | 0.11 | 0.09 |
| 社会标签 | 17 | 0.38 | 0 | 信誉 | 18 | 0.08 | 0.22 | 矩阵分解 | 15 | 0.25 | 0.06 |
| 数据挖掘 | 17 | 0 | 0.03 | 个性化 | 16 | 0.13 | 0.16 | 13 | 0.07 | 0.03 | |
| 算法 | 17 | 0.15 | 0.21 | 16 | 0.13 | 0.05 | 个性化 | 13 | 0.17 | 0 | |
| 本体 | 17 | 0.07 | 0.06 | 实验法 | 15 | 0.11 | 0.05 | 位置推荐 | 13 | 0.07 | 0.03 |
| 自然语言处理 | 16 | 0.04 | 0.04 | 性能 | 14 | 0.14 | 0.11 | 数据挖掘 | 13 | 0.12 | 0.1 |
| 评估 | 15 | 0.05 | 0 | 聚类 | 14 | 0.07 | 0 | 在线社交 网络 | 12 | 0.1 | 0 |
| 标签 | 14 | 0.15 | 0.10 | 自然语言 处理 | 13 | 0.02 | 0 | 实验法 | 11 | 0.05 | 0.07 |
| 社会化 媒介 | 13 | 0.15 | 0.07 | 社会化推荐 | 12 | 0 | 0.03 | 社会影响 | 10 | 0.08 | 0.07 |
| 互联网 | 12 | 0.05 | 0.07 | 信息检索 | 12 | 0.02 | 0 | 好友推荐 | 9 | 0.03 | 0.11 |
| 机器学习 | 12 | 0.07 | 0.05 | 本体 | 12 | 0.12 | 0 | 链路预测 | 9 | 0.06 | 0.08 |
| 人为因素 | 11 | 0.06 | 0.11 | 群推荐 | 11 | 0.03 | 0.06 | 微博 | 9 | 0.09 | 0.04 |
| P2P | 11 | 0.08 | 0.19 | 评估 | 11 | 0.05 | 0.03 | 社会网络 分析 | 9 | 0.09 | 0 |
| 信息提取 | 11 | 0.06 | 0.07 | 主题建模 | 10 | 0 | 0.03 | 性能 | 9 | 0.06 | 0 |
| 信誉 | 10 | 0.06 | 0.31 | 大众分类 | 10 | 0.11 | 0 | 随机游走 | 9 | 0.03 | 0.11 |
| 合计 | 340 | 2.64 | 1.90 | 合计 | 313 | 2.03 | 1.31 | 合计 | 314 | 2.13 | 1.22 |
进一步归纳总结发现三个阶段呈现以下特点:
阶段一: 各关键词与推荐系统的共现系数高于社会网络, 协同过滤和社会化标签与推荐系统的共现系数分别为0.41和0.38, 算法类关键词如矩阵因子分解、概率模型等保持较高的共现系数, 信誉和信托机制与社会网络的共现系数达0.26和0.31, 这表明此阶段揭示领域特性的关键词共现系数比较高, 其中体现领域属性词汇如信息检索、自然语言处理、机器学习、信息抽取、本体、互联网等较多。本阶段社会化推荐研究呈现出多领域融合特点, 发展趋势较为分散, 研究内容偏向于文本处理, 社会化推荐研究处于初步探索阶段, 交叉学科特性表现明显。
阶段二: 各关键词共现系数相比阶段一有所下降, 社会网络与协同过滤共现系数高达0.30, 说明学者们对社会网络和协同过滤间关系比较关注, 社会化媒介、聚类、主题模型等算法应用类词频上升, 方法属性词如数据挖掘与推荐系统的共现系数也有所上升, 领域类的关键词较上一阶段明显减少, 社会化推荐特性词汇关注度普遍提高, 如群推荐、社会化推荐、大众分类法(Folksonomy)都具有较高的关注度。本阶段工具应用、算法技术类词汇较多, 领域名称类词汇关注度下降, 研究内容偏向于算法改进优化, 社会化推荐研究处于算法优化模型扩展阶段。
阶段三: 此阶段各个关键词与社会网络的Ochiia系数累计最低, 推荐系统累计系数较上阶段有所上升, 关键词与社会化网络共现系数为0的比例下降, 随着GPS、无线通信网络发展成熟与位置相关的新兴技术应用获得较高的关注度, 如基于位置的社会网络、位置推荐等, 基于网络图的算法模型较为热门如链路预测、随机游走等, 传统技术类关注度依旧较高如协同过滤、矩阵因子分解等, 社交网络类研究较为集中如Twitter、微博等, 个性化推荐历经三个阶段演化词频不断下降但关注度依旧较高, 更能体现用户群体特性和社会关系的推荐类词汇关注度不断上升, 如好友推荐和位置推荐等。
通过三个阶段的共现系数比较, 推荐系统的共现系数一直高于社会网络, 协同过滤、个性化、社会网络分析、实验法、数据挖掘、算法和社会化媒介在社会化推荐系统研究领域一直保持较高的词频, 根据三阶段的共现系数累计统计发现推荐系统研究发展处于较为平稳的状态, 社会网络经历三阶段演化累计系数不断下降, 但其他同类关键词如社会关系网络等属于社会网络子类的关键词不断增多。而且关键词中体现用户社会化和群体化特性的应用也在不断增加, 如朋友推荐、社区发现、群推荐等。
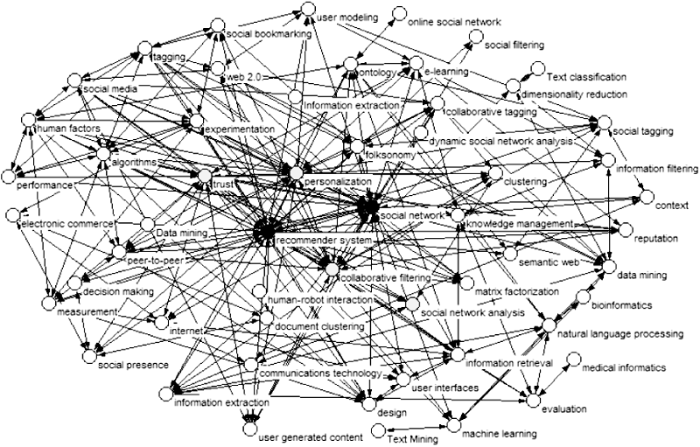
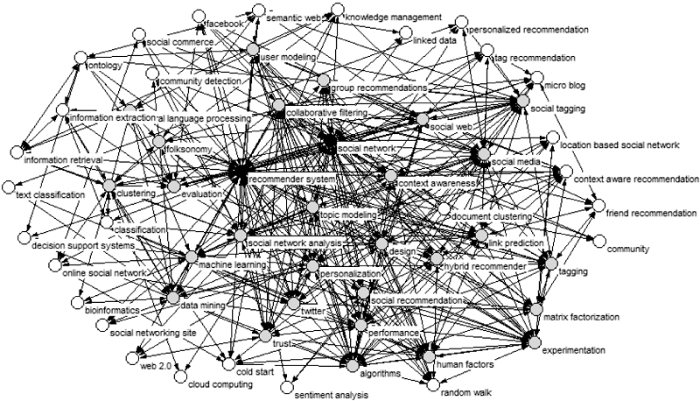
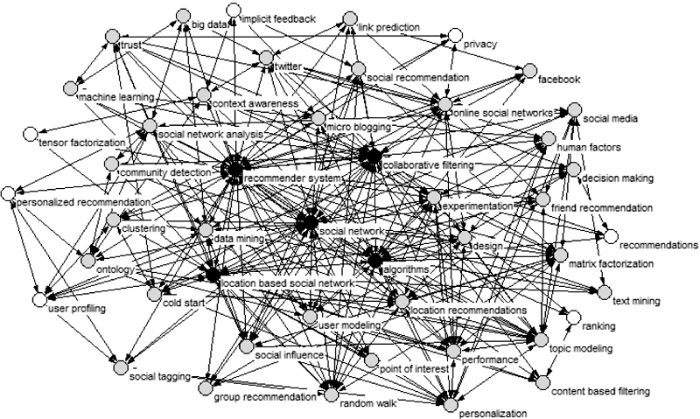
选取词频≥5的关键词, 根据公式(2)计算各个阶段关键词的中心性, 借鉴文献[63]的方法将中心性划分为三个阶段, 并分别在图3、图4和图5中展现出三个阶段的关键词中心性层次分布网络, 其中: 核心节点是$Cc({{v}_{n}})\ge 0.61$的●节点, 中心节点为$0.61>Cc({{v}_{n}})$ $\ge 0.51$的●节点, 边缘节点为$Cc({{v}_{n}})<0.51$的○节点。
阶段一(1997-2008): 经统计词频$\ge 5$关键词有54个, 其中2个核心节点分别是推荐系统和社会网络, 中心性是0.70和0.63, 处于中间层的有协同过滤、个性化和信誉, 分别是0.58、0.54和0.52, 有49个边缘节点占90.74%, 边缘节点占绝对多数。进一步研究分析发现, 文本挖掘、本体论、文本分类等体现文本特性的节点都保持较高的度, 且与其他节点连接较为密切, 领域类节点电子商务、社会化书签、自然语言处理、知识管理等虽然为边缘节点但有较高的度。总结此阶段社会化推荐研究关系网络涉及领域较为广泛, 研究内容呈现出多样性、分散性和多领域性等特点。
阶段二(2009-2013): 此阶段词频词频≥5的关键词有60个, 其中核心节点保持不变依旧是推荐系统和社会网络, 中心性为0.79和0.73。此阶段中心节点28个, 边缘节点30个, 占总体的46.67%和50.00%。中心节点数较上一阶段明显上升。用户属性节点(如用户建模、个性化、个性化推荐等)与社会网络属性节点(如社会网络分析、社会媒介、社会标签、社会商务等)都具有较高的度, 边缘节点如文档过滤、信息传播、普适计算等处于隔离位置(中心性为0), 新兴领域节点云计算、决策支持系统、Web2.0等虽然处于边缘节点但和其他节点连接较为密切, 具有一定的研究热度。此阶段技术算法类节点如协同过滤、主题模型、聚类、矩阵因子分解等, 在中心层占比较大, 与其他节点联系较为紧密。
阶段三(2014-2016): 此阶段词频词频≥5的关键词有47个, 其中核心节点是推荐系统、社会网络、协同过滤、基于位置网络和算法, 中心性分别为0.90、0.75、0.73、0.65、0.65, 推荐系统处于绝对核心位置。中心节点为35个, 占总体的74.47%, 达到三个阶段最高比例; 边缘层仅7个, 占总体的14.89%。较前两个阶段边缘节点数不断下降, 核心节点和中间节点数不断上升。体现社会属性和物理位置的节点具有较高的关注度, 如社会影响、信誉、链路预测、随机游走等, Facebook、Twitter、微博等应用类节点也具有较高的度。此阶段推荐应用类与其他节点联系较为紧密, 也有一些新的研究点被学者们关注, 如基于位置的推荐、位置社会网络。
通过公式(3)-公式(5)计算出三个阶段关键词网络的网络密度、集聚系数和网络平均度, 结果如表4所示。三个阶段网络密度不断增加说明三个阶段关键词连接紧密程度不断上升, 阶段二集聚系数为0.4141, 体现出此阶段关键词节点联系程度较高; 而阶段三为0.3865, 说明此阶段联系程度较低; 阶段一的网络平均度最低18.1429, 体现出此阶段研究较为分散, 而阶段二相比其他两个阶段研究内容较为集中。
表4 三个阶段关键词网络结构特性指标统计
| 网络特性指标 | 阶段一 | 阶段二 | 阶段三 |
|---|---|---|---|
| 网络密度 | 0.162 | 0.2122 | 0.2476 |
| 集聚系数 | 0.4039 | 0.4141 | 0.3865 |
| 网络平均度 | 18.1429 | 25.4667 | 23.2766 |
通过对比三个阶段的中心性、网络结构和网络特性, 主要得出以下结论:
(1) 三个阶段的中心性整体趋于稳定状态, 其中体现社会属性和推荐应用的关键词越来越多, 体现领域特性的关键词逐渐变少;
(2) 三个阶段关键词间链路网络紧密度不断提高;
(3) 随着阶段变化, 中间层的节点数量逐步增加, 边缘层节点数量相对减少, 表明研究的关注点逐渐集中;
(4) 传统算法和主要研究领域一直保持较高的关注度, 如协同过滤、个性化、社会网络分析、实验法、数据挖掘、算法、社会媒体等;
(5) 各阶段研究特性明显, 与社交网络应用相关的研究不断增加, 各个阶段都会出现新的研究热点, 如张量分解、大众分类法等。
社会化推荐发展至今依旧是一个较新的研究领域, 随着理论研究的不断深入, 越来越多的复杂数学模型被引入到社会化推荐中, 强调信息社会化属性的应用模型不断演化扩展, 研究内容日趋丰富, 系统可信性和安全隐私重视度不断提升, 评价指标不断完善, 但异构数据处理、跨平台用户画像构建、大数据处理等一些还处于探索阶段的问题, 仍需进一步研究解决。
本文首先从学术研究角度归纳总结社会推荐领域论文的前沿方法和科研成果, 通过挖掘分析WoS数据库中的2 899篇科学文献, 深入探究比较了此领域的阶段研究特性和演化发展过程。结果表明全球发文量呈现类指数级上升趋势, 我国这方面的研究虽然起步较晚但发展较快。各领域交叉学科联系紧密, 模型构建多元化特性明显, 研究内容经历多领域融合、算法优化、发展成熟等阶段, 研究趋势表现为稳定集聚的状态。在未来几年随着云计算、人工智能和深度学习的发展深入, 社会化推荐将会面临更多的机遇和挑战。
王宗水: 提出研究思路及命题, 文字校对;
李飞: 设计研究方案, 进行实验, 资料收集, 撰写论文;
张健, 王宗水: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: leefly072@126.com。
[1] 李飞, 张健, 王宗水.支撑数据.xlsx. 期刊年份分布数据, 出版物统计数据, 三个阶段词频统计结果、共现网络及节点中心性分布.
| [1] |
用户生成内容(UGC)概念解析及研究进展 [J].https://doi.org/10.3969/j.issn.1001-8867.2012.05.007 URL [本文引用: 1] 摘要
用户生成内容(UGC)是Web2.0环境下一种新兴的网络信息资源创作与组织模式。本文对国内外相关研究文献进行了检索和梳理.在类型理论基础上提出了UGC的概念分析框架。从用户的类型与角色(Who)、内容的类型与属性(What)、用户生成内容的动因(Why)以及用户生成内容的模式(How)四个维度及相互之间的联系深入解析UGC概念中最为本质的一系列问题。同时通过关键词分析方法,提炼出UGC研究的焦点和重心,归纳出UGC研究的五个分析单元(用户、内容、技术、组织、社会)、四大视角(资源观、行为观、技术观、应用观)和三个层面(微观层面、中观层面、宏观层面)。试图从理论上规范并完善了UGC研究的思路,帮助信息管理领域的研究者在今后的UGC研究中寻找并挖掘相关研究主题,清晰定位研究层次,并选择科学的研究方法和路径。图4。表2。参考文献64。
Conceptualization and Research Progress on User-Generated Content [J].https://doi.org/10.3969/j.issn.1001-8867.2012.05.007 URL [本文引用: 1] 摘要
用户生成内容(UGC)是Web2.0环境下一种新兴的网络信息资源创作与组织模式。本文对国内外相关研究文献进行了检索和梳理.在类型理论基础上提出了UGC的概念分析框架。从用户的类型与角色(Who)、内容的类型与属性(What)、用户生成内容的动因(Why)以及用户生成内容的模式(How)四个维度及相互之间的联系深入解析UGC概念中最为本质的一系列问题。同时通过关键词分析方法,提炼出UGC研究的焦点和重心,归纳出UGC研究的五个分析单元(用户、内容、技术、组织、社会)、四大视角(资源观、行为观、技术观、应用观)和三个层面(微观层面、中观层面、宏观层面)。试图从理论上规范并完善了UGC研究的思路,帮助信息管理领域的研究者在今后的UGC研究中寻找并挖掘相关研究主题,清晰定位研究层次,并选择科学的研究方法和路径。图4。表2。参考文献64。
|
| [2] |
VarianH R. Recommender Systems [J]. |
| [3] |
Future Shock [M].
|
| [4] |
Recommender Systems [J]. |
| [5] |
基于社会化标签系统的个性化信息推荐探讨 [J].
<html dir="ltr"><head><title></title></head><body><font style="BACKGROUND-COLOR: #cce8cf"> 针对用户个人特征并向其提供准确恰当信息的个性化信息推荐研究,一直是学术界和产业界所关注的热点。结合后控词表,对用户分散的、个性化的标注进行处理,并将用户兴趣用向量表示,然后借鉴协同过滤算法的思想,寻找出相似用户集及其内部的资源集。在此基础上,采用相对匹配策略,提出一种基于社会化标签系统的个性化推荐方法。</font></body></html>
On Personalized Information Recommendation Based on Social Tagging System [J].
<html dir="ltr"><head><title></title></head><body><font style="BACKGROUND-COLOR: #cce8cf"> 针对用户个人特征并向其提供准确恰当信息的个性化信息推荐研究,一直是学术界和产业界所关注的热点。结合后控词表,对用户分散的、个性化的标注进行处理,并将用户兴趣用向量表示,然后借鉴协同过滤算法的思想,寻找出相似用户集及其内部的资源集。在此基础上,采用相对匹配策略,提出一种基于社会化标签系统的个性化推荐方法。</font></body></html>
|
| [6] |
Tag Recommendations in Social Bookmarking Systems [J].https://doi.org/10.3233/AIC-2008-0438 URL 摘要
Summary: Collaborative tagging systems allow users to assign keywords 63 so called “tags” 63 to resources. Tags are used for navigation, finding resources and serendipitous browsing and thus provide an immediate benefit for users. These systems usually include tag recommendation mechanisms easing the process of finding good tags for a resource, but also consolidating the tag vocabulary across users. In practice, however, only very basic recommendation strategies are applied. In this paper we evaluate and compare several recommendation algorithms on large-scale real life datasets: an adaptation of user-based collaborative filtering, a graph-based recommender built on top of the FolkRank algorithm, and simple methods based on counting tag occurrences. We show that both FolkRank and collaborative filtering provide better results than non-personalized baseline methods. Moreover, since methods based on counting tag occurrences are computationally cheap, and thus usually preferable for real time scenarios, we discuss simple approaches for improving the performance of such methods. We show, how a simple recommender based on counting tags from users and resources can perform almost as good as the best recommender.
|
| [7] |
Graph-based Personalized Recommendation in Social Tagging Systems [
|
| [8] |
Friend Recommendation by User Similarity Graph Based on Interest in Social Tagging Systems [C]//
|
| [9] |
Collaborative Topic Regression with Social Trust Ensemble for Recommendation in Social Media Systems [J].https://doi.org/10.1016/j.knosys.2016.01.011 URL [本文引用: 1] 摘要
Social media systems provide ever-growing huge volumes of information for dissemination and communication among communities of users, while recommender systems aim to mitigate information overload by filtering and providing users the most attractive and relevant items from information-sea. This paper aims at providing compound recommendation engine for social media systems, and focuses on exploiting multi-sourced information (e.g. social networks, item contents and user feedbacks) to predict the ratings of users to items and make recommendations. For this, we suppose the users decisions on adopting item are affected both by their tastes and the favors of trusted friends, and extend Collaborative Topic Regression to jointly incorporates social trust ensemble, topic modeling and probabilistic matrix factorization. We propose corresponding approaches to learning the latent factors both of users and items, as well as additional parameters to be estimated. Empirical experiments on Lastfm and Delicious datasets show that our model is better and more robust than the state-of-the-art methods on making recommendations in term of accuracy. Experiments results also reveal some useful findings to enlighten the development of recommender systems in social media.
|
| [10] |
Integrating Heterogeneous Information via Flexible Regularization Framework for Recommendation [J].https://doi.org/10.1007/s10115-016-0925-0 URL [本文引用: 1] 摘要
Abstract: Recently, there is a surge of social recommendation, which leverages social relations among users to improve recommendation performance. However, in many applications, social relations are absent or very sparse. Meanwhile, the attribute information of users or items may be rich. It is a big challenge to exploit these attribute information for the improvement of recommendation performance. In this paper, we organize objects and relations in recommendation system as a heterogeneous information network, and introduce meta path based similarity measure to evaluate the similarity of users or items. Furthermore, a matrix factorization based dual regularization framework SimMF is proposed to flexibly integrate different types of information through adopting the similarity of users and items as regularization on latent factors of users and items. Extensive experiments not only validate the effectiveness of SimMF but also reveal some interesting findings. We find that attribute information of users and items can significantly improve recommendation accuracy, and their contribution seems more important than that of social relations. The experiments also reveal that different regularization models have obviously different impact on users and items.
|
| [11] |
Recommendation Using DMF-based Fine Tuning Method [J].https://doi.org/10.1007/s10844-016-0407-6 URL [本文引用: 1] 摘要
Recommender Systems (RS) have been comprehensively analyzed in the past decade, Matrix Factorization (MF)-based Collaborative Filtering (CF) method has been proved to be an useful model to improve the performance of recommendation. Factors that inferred from item rating patterns shows the vectors which are useful for MF to characterize both items and users. A recommendation can concluded from good correspondence between item and user factors. A basic MF model starts with an object function, which is consisted of the squared error between original training matrix and predicted matrix as well as the regularization term (regularization parameters). To learn the predicted matrix, recommender systems minimize the squared error which has been regularized. However, two important details have been ignored: (1) the predicted matrix will be more and more accuracy as the iterations carried out, then a fix value of regularization parameters may not be the most suitable choice. (2) the final distribution trend of ratings of predicted matrix is not similar with the original training matrix. Therefore, we propose a Dynamic-MF algorithm and fine tuning method which is quite general to overcome the mentioned detail problems. Some other information, such as social relations, etc, can be easily incorporated into this method (model). The experimental analysis on two large datasets demonstrates that our approaches outperform the basic MF-based method.
|
| [12] |
Joint Social and Content Recommendation for User-generated Videos in Online Social Network [J].https://doi.org/10.1109/TMM.2012.2237022 URL Magsci [本文引用: 1] 摘要
Online social network is emerging as a promising alternative for users to directly access video contents. By allowing users to import videos and re-share them through the social connections, a large number of videos are available to users in the online social network. The rapid growth of the user-generated videos provides enormous potential for users to find the ones that interest them; while the convergence of online social network service and online video sharing service makes it possible to perform recommendation using social factors and content factors jointly. In this paper, we design a joint social-content recommendation framework to suggest users which videos to import or re-share in the online social network. In this framework, we first propose a user-content matrix update approach which updates and fills in cold user-video entries to provide the foundations for the recommendation. Then, based on the updated user-content matrix, we construct a joint social-content space to measure the relevance between users and videos, which can provide a high accuracy for video importing and re-sharing recommendation. We conduct experiments using real traces from Tencent Weibo and Youku to verify our algorithm and evaluate its performance. The results demonstrate the effectiveness of our approach and show that our approach can substantially improve the recommendation accuracy.
|
| [13] |
Social Factors in Group Recommender Systems [J].https://doi.org/10.1145/2414425.2414433 URL [本文引用: 1] 摘要
In this article we review the existing techniques in group recommender systems and we propose some improvement based on the study of the different individual behaviors when carrying out a decision-making process. Our method includes an analysis of group personality composition and trust between each group member to improve the accuracy of group recommenders. This way we simulate the argumentation process followed by groups of people when agreeing on a common activity in a more realistic way. Moreover, we reflect how they expect the system to behave in a long term recommendation process. This is achieved by including a memory of past recommendations that increases the satisfaction of users whose preferences have not been taken into account in previous recommendations.
|
| [14] |
Information Retrieval in Folksonomies: Search and Ranking [C]// |
| [15] |
Learning Optimal Ranking with Tensor Factorization for Tag Recommendation [C]// |
| [16] |
Real-time Automatic Tag Recommendation [C]// |
| [17] |
|
| [18] |
Automatic Generation of Social Tags for Music Recommendation [J].
ABSTRACT Social tags are user-generated keywords associated with some resource on the Web. In the case of music, social tags have become an important component of "Web2.0" recommender systems, allowing users to generate playlists based on use-dependent terms such as chill or jogging that have been applied to particular songs. In this paper, we propose a method for predicting these social tags directly from MP3 files. Using a set of boosted classifiers, we map audio features onto social tags collected from the Web. The resulting automatic tags (or autotags) furnish information about music that is otherwise untagged or poorly tagged, al- lowing for insertion of previously unheard music into a social recommender. This avoids the "cold-start problem" common in such systems. Autotags can also be used to smooth the tag space from which similarities and recommendations are made by providing a set of comparable baseline tags for all tracks in a recom- mender system.
|
| [19] |
Generating Predictive Movie Recommendations from Trust in Social Networks [C]// |
| [20] |
社会化推荐系统研究 [J].Research on Social Recommender Systems [J]. |
| [21] |
Recommender Systems Based on Social Networks [J].https://doi.org/10.1016/j.jss.2014.09.019 URL [本文引用: 1] 摘要
The traditional recommender systems, especially the collaborative filtering recommender systems, have been studied by many researchers in the past decade. However, they ignore the social relationships among users. In fact, these relationships can improve the accuracy of recommendation. In recent years, the study of social-based recommender systems has become an active research topic. In this paper, we propose a social regularization approach that incorporates social network information to benefit recommender systems. Both users friendships and rating records (tags) are employed to predict the missing values (tags) in the user-item matrix. Especially, we use a biclustering algorithm to identify the most suitable group of friends for generating different final recommendations. Empirical analyses on real datasets show that the proposed approach achieves superior performance to existing approaches.
|
| [22] |
Predicting Personality Traits Related to Consumer Behavior Using SNS Analysis [J].https://doi.org/10.1080/13614568.2016.1152313 URL [本文引用: 1] 摘要
Modeling a user profile is one of the important factors for devising a personalized recommendation. The traditional approach for modeling a user profile in computer science is to collect and generalize the user's buying behavior or preference history, generated from the user's interactions with recommender systems. According to consumer behavior research, however, internal factors such as personality traits influence a consumer's buying behavior. Existing studies have tried to adapt the Big 5 personality traits to personalized recommendations. However, although studies have shown that these traits can be useful to some extent for personalized recommendation, the causal relationship between the Big 5 personality traits and the buying behaviors of actual consumers has not been validated. In this paper, we propose a novel method for predicting the four personality traits-Extroversion, Public Self-consciousness, Desire for Uniqueness, and Self-esteem-that correlate with buying behaviors. The proposed method automatically constructs a user-personality-traits prediction model for each user by analyzing the user behavior on a social networking service. The experimental results from an analysis of the collected Facebook data show that the proposed method can predict user-personality traits with greater precision than methods that use the variables proposed in previous studies.
|
| [23] |
国内外共词分析法研究的发展与分析 [J].https://doi.org/10.13266/j.issn.0252-3116.2014.22.022 URL [本文引用: 1] 摘要
采用人工判读法、文献计量法和对比分析法,从定性和定量两个角度对共词分析法在国际上和中国国内的研究现状进行分析。通过人工判读法,将共词分析法的研究分为理论研究和应用研究,其中理论研究分为5类,应用研究分为4个层次;通过文献计量方法,对共词分析法在国际上和中国国内的总体研究发展趋势、文献类型、引用情况和应用领域进行分析;通过对比分析法,比较分析国际上和中国国内共词分析法的理论研究和应用研究之发展趋势的差异、在各类型共词分析法研究中的活跃程度和影响力的差异,以及共词分析法具体应用领域的差异。
Development and Analysis of Co-word Analysis Method at Home and Abroad [J].https://doi.org/10.13266/j.issn.0252-3116.2014.22.022 URL [本文引用: 1] 摘要
采用人工判读法、文献计量法和对比分析法,从定性和定量两个角度对共词分析法在国际上和中国国内的研究现状进行分析。通过人工判读法,将共词分析法的研究分为理论研究和应用研究,其中理论研究分为5类,应用研究分为4个层次;通过文献计量方法,对共词分析法在国际上和中国国内的总体研究发展趋势、文献类型、引用情况和应用领域进行分析;通过对比分析法,比较分析国际上和中国国内共词分析法的理论研究和应用研究之发展趋势的差异、在各类型共词分析法研究中的活跃程度和影响力的差异,以及共词分析法具体应用领域的差异。
|
| [24] |
|
| [25] |
Social Network Analysis: A Handbook [M]. |
| [26] |
Knowledge Discovery Through Co-word Analysis [J].
Based on coexistence frequency of pairs of words or phrases, coword analysis is used to discover linkages among subjects in a research field and thus to trace the development of science. This article reviews the development of coword analysis, summarizes the advantages and disadvantages of this method, and discusses several research issues. Contains 35 references. (Author/MES)
|
| [27] |
Research Trends in Gender Differences in Higher Education and Science: A Co-word Analysis [J].https://doi.org/10.1007/s11192-014-1327-2 URL Magsci [本文引用: 1] 摘要
The aim of this study is to map and analyze the structure and evolution of the scientific literature on gender differences in higher education and science, focusing on factors related to differences between 1991 and 2012. Co-word analysis was applied to identify the main concepts addressed in this research field. Hierarchical cluster analysis was used to cluster the keywords and a strategic diagram was created to analyze trends. The data set comprised a corpus containing 652 articles and reviews published between 1991 and 2012, extracted from the Thomson Reuters Web of Science database. In order to see how the results changed over time, documents were grouped into three different periods: 1991-2001, 2002-2007, and 2008-2012. The results showed that the number of themes has increased significantly over the years and that gender differences in higher education and science have been considered by specific research disciplines, suggesting important research-field-specific variations. Overall, the study helps to identify the major research topics in this domain, as well as highlighting issues to be addressed or strengthened in further work.
|
| [28] |
Social Network Analysis and Mining for Business Applications [J].https://doi.org/10.1145/1961189.1961194 URL [本文引用: 2] 摘要
Social network analysis has gained significant attention in recent years, largely due to the success of online social networking and media-sharing sites, and the consequent availability of a wealth of social network data. In spite of the growing interest, however, there is little understanding of the potential business applications of mining social networks. While there is a large body of research on different problems and methods for social network mining, there is a gap between the techniques developed by the research community and their deployment in real-world applications. Therefore the potential business impact of these techniques is still largely unexplored. In this article we use a business process classiication framework to put the research topics in a business context and provide an overview of what we consider key problems and techniques in social network analysis and mining from the perspective of business applications. In particular, we discuss data acquisition and preparation, trust, expertise, community structure, network dynamics, and information propagation. In each case we present a brief overview of the problem, describe state-of-the art approaches, discuss business application examples, and map each of the topics to a business process classification framework. In addition, we provide insights on prospective business applications, challenges, and future research directions. The main contribution of this article is to provide a state-of-the-art overview of current techniques while providing a critical perspective on business applications of social network analysis and mining. 2011 ACM.
|
| [29] |
Social Network Analysis: A Brief Introduction [EB/OL]. [ |
| [30] |
Social Recommender Systems for Web 2.0 Folksonomies [C]// |
| [31] |
Social Recommender Systems [J]. |
| [32] |
Improving Social Recommender Systems [J]. |
| [33] |
Multidimensional Social Network in the Social Recommender System [J].https://doi.org/10.1109/TSMCA.2011.2132707 URL [本文引用: 1] 摘要
All online sharing systems gather data that reflects users' collective behavior and their shared activities. This data can be used to extract different kinds of relationships which can be grouped into layers and which are basic components of the multidimensional social network (MSN) proposed in the paper. The layers are created on the basis of two types of relations between humans, i.e., direct and object-based ones which, respectively, correspond to either social or semantic links between individuals. For better understanding of the complexity of the social network structure, layers and their profiles were identified and studied on two, spanned in time, snapshots of the `Flickr' population. Additionally, for each layer, a separate strength measure was proposed. The experiments on the `Flickr' photo sharing system revealed that the relationships between users result either from semantic links between objects they operate on or from social connections of these users. Moreover, the density of the social network increases in time. The second part of this paper is devoted to building a social recommender system that supports the creation of new relations between users in a multimedia sharing system. Its main goal is to generate personalized suggestions that are continuously adapted to users' needs depending on the personal weights assigned to each layer in the MSN. The conducted experiments confirmed the usefulness of the proposed model.
|
| [34] |
Recommender Systems with Social Regularization [C]// |
| [35] |
Social Recommendation: A Review [J].
|
| [36] |
Introduction to Social Recommendation [C]// |
| [37] |
Learning to Recommend with Social Trust Ensemble [C]// |
| [38] |
A Matix Factorization Technique with Trust Propagations for Recommendation in Social Networks [C]// |
| [39] |
TrustWalker: A Random Walk Model for Combining Trust-based and Item-based Recommendation [C]// |
| [40] |
SoNARS: A Social Networks-based Algorithm for Social Recommender Systems [C]// |
| [41] |
Gloss: A Social Networks- based Recommender System [C]// |
| [42] |
Collaborative Filtering in Social Networks: A Community-based Approach [C]// |
| [43] |
Can Social Bookmarking iImprove Web Search? [C]// |
| [44] |
Recommending Twitter Users to Follow Using Content and Collaborative Filtering Approaches [C]// |
| [45] |
A Recommender System for the TV on the Web: Integrating Unrated Reviews and Movie Ratings [J].https://doi.org/10.1007/s00530-013-0310-8 URL [本文引用: 1] 摘要
The activity of Social-TV viewers has grown considerably in the last few years—viewers are no longer passive elements. The Web has socially empowered the viewers in many new different ways, for example, viewers can now rate TV programs, comment them, and suggest TV shows to friends through Web sites. Some innovations have been exploring these new activities of viewers but we are still far from realizing the full potential of this new setting. For example, social interactions on the Web, such as comments and ratings in online forums, create valuable feedback about the targeted TV entertainment shows. In this paper, we address this last setting: a media recommendation algorithm that suggests recommendations based on users’ ratings and unrated comments. In contrast to similar approaches that are only ratings-based, we propose the inclusion of sentiment knowledge in recommendations. This approach computes new media recommendations by merging media ratings and comments written by users about specific entertainment shows. This contrasts with existing recommendation methods that explore ratings and metadata but do not analyze what users have to say about particular media programs. In this paper, we argue that text comments are excellent indicators of user satisfaction. Sentiment analysis algorithms offer an analysis of the users’ preferences in which the comments may not be associated with an explicit rating. Thus, this analysis will also have an impact on the popularity of a given media show. Thus, the recommendation algorithm—based on matrix factorization by Singular Value Decomposition—will consider both explicit ratings and the output of sentiment analysis algorithms to compute new recommendations. The implemented recommendation framework can be integrated on a Web TV system where users can view and comment entertainment media from a video-on-demand service. The recommendation framework was evaluated on two datasets from IMDb with 53,112 reviews (5002% unrated) and Amazon entertainment media with 698,210 reviews (2602% unrated). Recommendation results with ratings and the inferred preferences—based on the sentiment analysis algorithms—exhibited an improvement over the ratings only based recommendations. This result illustrates the potential of sentiment analysis of user comments in recommendation systems.
|
| [46] |
In Pursuit of Satisfaction and the Prevention of Embarrassment: Affective State in Group Recommender Systems [J].https://doi.org/10.1007/s11257-006-9008-3 URL [本文引用: 1] 摘要
This paper deals in depth with some of the emotions that play a role in a group recommender system, which recommends sequences of items to a group of users. First, it describes algorithms to model and predict the satisfaction experienced by individuals. Satisfaction is treated as an affective state. In particular, we model the decay of emotion over time and assimilation effects, where the affective state produced by previous items influences the impact on satisfaction of the next item. We compare the algorithms with each other, and investigate the effect of parameter values by comparing the algorithms鈥 predictions with the results of an earlier empirical study. We discuss the difficulty of evaluating affective models, and present an experiment in a learning domain to show how some empirical evaluation can be done. Secondly, this paper proposes modifications to the algorithms to deal with the effect on an individual satisfaction of that of others in the group. In particular, we model emotional contagion and conformity, and consider the impact of different relationship types. Thirdly, this paper explores the issue of privacy (feeling safe, not accidentally disclosing private tastes to others in the group) which is related to the emotion of embarrassment. It investigates the effect on privacy of different group aggregation strategies and proposes to add a virtual member to the group to further improve privacy.
|
| [47] |
User Profiling for Web Page Filtering [J].https://doi.org/10.1109/MIC.2005.90 URL 摘要
To help address pressing problems with information overload, researchers have developed personal agents to provide assistance to users in navigating the Web. To provide suggestions, such agents rely on user profiles representing interests and preferences, which makes acquiring and modeling interest categories a critical component in their design. Existing profiling approaches have only partially tackled the characteristics that distinguish user profiling from related tasks. The authors
|
| [48] |
Personalized Recommender System Based on Social Relations [C]// |
| [49] |
Collaborative Filtering and Deep Learning Based Recommendation System for Cold Start Items [J].https://doi.org/10.1016/j.eswa.2016.09.040 URL [本文引用: 1] 摘要
Recommender system is a specific type of intelligent systems, which exploits historical user ratings on items and/or auxiliary information to make recommendations on items to the users. It plays a critical role in a wide range of online shopping, e-commercial services and social networking applications. Collaborative filtering (CF) is the most popular approaches used for recommender systems, but it suffers from complete cold start (CCS) problem where no rating record are available and incomplete cold start (ICS) problem where only a small number of rating records are available for some new items or users in the system. In this paper, we propose two recommendation models to solve the CCS and ICS problems for new items, which are based on a framework of tightly coupled CF approach and deep learning neural network. A specific deep neural network SADE is used to extract the content features of the items. The state of the art CF model, timeSVD++, which models and utilizes temporal dynamics of user preferences and item features, is modified to take the content features into prediction of ratings for cold start items. Extensive experiments on a large Netflix rating dataset of movies are performed, which show that our proposed recommendation models largely outperform the baseline models for rating prediction of cold start items. The two proposed recommendation models are also evaluated and compared on ICS items, and a flexible scheme of model retraining and switching is proposed to deal with the transition of items from cold start to non-cold start status. The experiment results on Netflix movie recommendation show the tight coupling of CF approach and deep learning neural network is feasible and very effective for cold start item recommendation. The design is general and can be applied to many other recommender systems for online shopping and social networking applications. The solution of cold start item problem can largely improve user experience and trust of recommender systems, and effectively promote cold start items.
|
| [50] |
Collaborative Filtering and Deep Learning Based Hybrid Recommendation for Cold Start Problem [C]// |
| [51] |
Towards Twitter Hashtag Recommendation Using Distributed Word Representations and a Deep Feed Forward Neural Network [C]// |
| [52] |
Representation Learning for Homophilic Preferences [C]// |
| [53] |
Parallel Recurrent Neural Network Architectures for Feature-rich Session-based Recommendations [C]// |
| [54] |
Combining Social Networks and Collaborative Filtering [J]. |
| [55] |
基于文献计量的大数据研究综述 [J].A Review of Big Data Research Based on Bibliometrics [J]. |
| [56] |
|
| [57] |
国外知识管理研究范式——以共词分析为方法 [J].https://doi.org/10.3321/j.issn:1007-9807.2007.06.008 URL [本文引用: 1] 摘要
在确定国外知识管理研究领域58个高频关键词的基础上,运用共词分析法,以SPSS软件为工具分析知识管理的学科结构,发现了国外知识管理领域的三大学派、两大范式,并预测知识管理今后将会在知识资源这一概念下走向范式的融合,从而得出知识管理的资源范式这一论点.
On Paradigm of Research Knowledge Management: A Bibliometric Analysis [J].https://doi.org/10.3321/j.issn:1007-9807.2007.06.008 URL [本文引用: 1] 摘要
在确定国外知识管理研究领域58个高频关键词的基础上,运用共词分析法,以SPSS软件为工具分析知识管理的学科结构,发现了国外知识管理领域的三大学派、两大范式,并预测知识管理今后将会在知识资源这一概念下走向范式的融合,从而得出知识管理的资源范式这一论点.
|
| [58] |
知识图谱分析方法的可靠性检验研究——以共词分析为例 [J].https://doi.org/10.3969/j.issn.1003-2053.2015.05.002 URL [本文引用: 1] 摘要
知识图谱分析虽然已经成为科学计量学的主要研究方法之一,但对于利用该方法发现学科生长点的可靠性检验大多还停留在经典案例的印证阶段。本文使用基于高频关键词的文献耦合网络回归共词网络指向的施引论文网络,通过比较高被引与零被引论文的节点度数、中介中心性以及孤立节点数等网络特征指标,考察了共词分析结果的可靠性。研究结果显示,高频词关键词更多地指向高被引文献,但使用节点的度数和中介中心性指标去判断节点价值具有不确定性。同时,本文也对标准叙词应用与知识图谱数据采集问题进行了讨论。
The Reliability Testing of Knowledge Mapping: Case Study on Co-word Analysis [J].https://doi.org/10.3969/j.issn.1003-2053.2015.05.002 URL [本文引用: 1] 摘要
知识图谱分析虽然已经成为科学计量学的主要研究方法之一,但对于利用该方法发现学科生长点的可靠性检验大多还停留在经典案例的印证阶段。本文使用基于高频关键词的文献耦合网络回归共词网络指向的施引论文网络,通过比较高被引与零被引论文的节点度数、中介中心性以及孤立节点数等网络特征指标,考察了共词分析结果的可靠性。研究结果显示,高频词关键词更多地指向高被引文献,但使用节点的度数和中介中心性指标去判断节点价值具有不确定性。同时,本文也对标准叙词应用与知识图谱数据采集问题进行了讨论。
|
| [59] |
Social Networks in Marketing Research 2001~2014: A Co-word Analysis [J].https://doi.org/10.1007/s11192-015-1672-9 URL [本文引用: 1] 摘要
Abstract This article aims to explore the evolution of social network in marketing research by analyzing the co-occurrence index and network structures of keywords. We find that the number of articles which subjective tittle consist of social networks within 19 marketing journals and 9 UTD (Utdallas list of top journals) management journals increase significantly and the number of keywords whose frequency are no less than two also grow dramatically since 2010, the network structures of keywords 2010–2014 become more dispersed shows as most of keywords’ centralities are between 0.32 and 0.63, and more keywords have strong relationships (Higher Cosine Index) with social networks or networks than 2001–2009. We also conclude that social network analysis has been mainly applied to study relationships, diffusion, influence, customer analysis, and enterprise management five subfields. Since mobile internet, intelligent devices, new media and digital technology are developing rapidly, social networks will be a powerful tool to study the related research fields.
|
| [60] |
Dynamics of the Evolution of the Strategy Concept 1962-2008: A Co-word Analysis [J].https://doi.org/10.1002/smj.948 URL [本文引用: 1] 摘要
Abstract The aim of this paper is to extend recent reflection on the evolution of strategic management by analyzing the field's object of study: strategy. We show how the concept of strategy has formed the backbone of the development of strategic management as an academic field and how consensus regarding it has evolved in the academic community during the stages of its historical development. We also address changes in the structure of the definition as it evolved through the growth of internal consistency, the centrality degree of the key terms that have shaped it, and how this evolution fostered the emergence of new research topics during the development of the discipline. Copyright 2011 John Wiley & Sons, Ltd.
|
| [61] |
On the Normalization and Visualization of Author Co-citation Data: Salton’s Cosine versus the Jaccard Index [J].https://doi.org/10.1002/asi.20732 URL [本文引用: 1] 摘要
Abstract Top of page Abstract Introduction The Jaccard Index Results Conclusions Acknowledgment References The debate about which similarity measure one should use for the normalization in the case of Author Co-citation Analysis (ACA) is further complicated when one distinguishes between the symmetrical co-citation—or, more generally, co-occurrence—matrix and the underlying asymmetrical citation—occurrence—matrix. In the Web environment, the approach of retrieving original citation data is often not feasible. In that case, one should use the Jaccard index, but preferentially after adding the number of total citations (i.e., occurrences) on the main diagonal. Unlike Salton's cosine and the Pearson correlation, the Jaccard index abstracts from the shape of the distributions and focuses only on the intersection and the sum of the two sets. Since the correlations in the co-occurrence matrix may be spurious, this property of the Jaccard index can be considered as an advantage in this case.
|
| [62] |
Introduction to Modern Information Retrieval, 3rd Edition [J].https://doi.org/10.1080/00048623.2010.10721488 URL [本文引用: 1] 摘要
Through a grant received from the Australian Library and Information Association (ALIA), Health Libraries Australia (HLA) is conducting a twelve-month research project with the goal of developing a system-wide approach to education for the future health librarianship workforce. The research has two main aims: to determine the future skills, knowledge, and competencies for the health librarian workforce in Australia; and to develop a structured, modular education framework for specialist post-graduate qualifications together with a structure for ongoing continuing professional development. The paper highlights some of the drivers for change for health librarianship as a profession, and particularly for educating the future workforce. The research methodology is outlined and the main results of the second stage of the project are described together with the findings and their implications for the development of a structured, competency-based education framework.
|
| [63] |
社会网络研究范式的演化、发展与应用——基于1998-2014年中国社会科学引文数据分析 [J].https://doi.org/10.3772/j.issn.1000-0135.2015.012.001 URL [本文引用: 1] 摘要
社会网络广泛应用于社会科学研究中,但少有研究对社会网络的研究范式做出系统、深入的总结与归纳。本文在对现有研究归纳总结的基础上,将社会网络研究概括为产生及初步发展阶段、统计模型快速发展阶段、复杂网络兴起及移动互联繁荣时期三个阶段;将社会网络研究范式概括为社会实体关系研究和社会网络分析研究两种范式。通过中国社会科学引文数据库(CSSCI)高级搜索,得到以社会网络为主题词、关键词、标题或中含社会网络的文章3931篇,根据年发文量阈值的设定,将社会网研究的发展分为三个阶段:阶段一(1998—2007年),阶段二(2008—2011年),阶段三(2012—2014年)。每个阶段选取被引次数最高的500篇文献作为研究样本,运用共词分析和社会网络分析方法对三个阶段社会网络研究内容进行比较分析。研究结果表明:社会网络作为研究方法的应用性增强,研究内容方面社会资本、知识管理等传统的领域始终保持较高的关注度,但是具有时代特性的研究问题在不同阶段也会成为热点问题。
Evolution, Development and Application of Social Network Paradigm: Evidence from CSSCI Database of China [J].https://doi.org/10.3772/j.issn.1000-0135.2015.012.001 URL [本文引用: 1] 摘要
社会网络广泛应用于社会科学研究中,但少有研究对社会网络的研究范式做出系统、深入的总结与归纳。本文在对现有研究归纳总结的基础上,将社会网络研究概括为产生及初步发展阶段、统计模型快速发展阶段、复杂网络兴起及移动互联繁荣时期三个阶段;将社会网络研究范式概括为社会实体关系研究和社会网络分析研究两种范式。通过中国社会科学引文数据库(CSSCI)高级搜索,得到以社会网络为主题词、关键词、标题或中含社会网络的文章3931篇,根据年发文量阈值的设定,将社会网研究的发展分为三个阶段:阶段一(1998—2007年),阶段二(2008—2011年),阶段三(2012—2014年)。每个阶段选取被引次数最高的500篇文献作为研究样本,运用共词分析和社会网络分析方法对三个阶段社会网络研究内容进行比较分析。研究结果表明:社会网络作为研究方法的应用性增强,研究内容方面社会资本、知识管理等传统的领域始终保持较高的关注度,但是具有时代特性的研究问题在不同阶段也会成为热点问题。
|
| [64] |
|
| [65] |
|

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}