李保珍 , 王亚
, 王亚
Li Baozhen, Wang Ya
中图分类号: G2
通讯作者:
收稿日期: 2017-02-22
修回日期: 2017-05-1
网络出版日期: 2017-06-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】构建网络信息内容可信度的定量测度模型, 以提高虚假信息的筛除效率。【方法】基于贝叶斯推理理论, 构建网络信息内容可信度的测度模型; 基于贝叶斯决策理论, 构建可信度测度有效性的最小错误率评估模型。【结果】基于实际数据集的实验结果表明, 随着社会化媒体参与者规模增加, 可信度测度的最小错误率呈下降趋势, 且贝叶斯可信度测度模型总体优于传统的模糊可信度测度模型。【局限】可信度测度错误率的影响因素只关注参与者规模因素, 而其他影响因素, 如条件属性或可参照对象等, 将需要进一步研究。【结论】基于集体智慧理论, 揭示网络信息内容可信度测度的最小错误率会随着参与者规模增加而降低。
关键词:
Abstract
[Objective] This paper builds a model to quantitatively measure the credibility of Web contents, aiming to improve the efficiency of removing dis-information. [Methods] We first constructed a credibility measurement model based on Bayesian inference theory, and then established a minimum error rate evaluation model for credibility measurement with Bayesian decision theory. [Results] With the increasing of social media users, the minimum error rate of credibility degree went down, and the proposed model had better performance than those based on traditional fuzzy theory. [Limitations] The influencing factors of the reliability measurement model only include the number of participants. More research is needed to examine other factors, such as the conditional attributes and the reference objects. [Conclusions] This paper reveals that the minimum error rate is decreased by increasing the number of participants.
Keywords:
以用户生成内容(User-Generated Content, UGC)为主的新型媒体, 如社交网络(SNS)、微博、微信、博客(Blog)等, 虽然为参与者发表意见开辟了一个无拘无束、不受限制的空间, 但同时使大众对网络信息的真实性产生某种程度的怀疑。信息可信度是指对于信息内容本身以及信息源的可信任程度, 其判断者是信息接收人[1]。因此, 网络信息内容的可信度测度(Credibility Measure), 是用户对信息内容是否值得信任的判断和评价[2-3]。本文侧重于社会化媒体网络信息内容的定量测度。
目前, 针对社会化媒体网络信息可信度评估及测度的相关文献主要是侧重于对影响因素进行实证分析的探索性研究, 研究视角大体可分为来源可信度[4]、渠道可信度和信息内容可信度。已有研究虽然推动了信息内容可信度评估的研究与发展, 但其不足主要体现在如下方面:
(1) 基于数理模型构建的规范性可信度测度研究较少;
(2) 传统评价模型多侧重于当前信息内容状态的可信程度, 尚缺乏对已有经验及证据性数据的有效利用;
(3) 在社交媒体环境下, 相关研究尚未充分利用用户通过主动参与对网络信息内容进行标注或评价所生成的客观性行为数据, 尚未充分体现用户对相关信息内容的认知性判断。
针对上述不足, 本文基于贝叶斯决策理论, 构建能够利用已有经验及证据性数据的网络信息内容可信测度模型。基于用户生成内容的社交媒体, 信息用户既能够主动参与对信息内容进行体验性判断评价, 又能够对特定信息内容进行交互性判断评价。因此, 新型网络环境下, 如何利用体验性判断评价及交互性判断评价, 对海量网络信息内容的可信度进行测度, 具有重要的理论和现实意义。
传统的可信度评估方法主要是针对信息用户的调查法和实验法。调查法和实验法主要侧重于探索网络信息内容可信度影响因素及内在机理的实证分析。为研究网民如何看待网络商业信息, 特别是电子商务信息内容的可信度评估问题, Flanagin等[4]针对美国使用互联网的成年人进行了一项具有全国代表性的调查, 其样本来自基于随机数字拨号和地址抽样方法的组合。实验法是最初研究可信度的方法[5]。Castillo等[6]基于社会媒体环境本身的特征能够使用户主动参与评估信息的可信度的假设, 构建实验模型, 探讨可自动分析社会化媒体信息, 尤其是针对有新闻价值的信息的可信性评估的方法, 并进一步提出预测信息可信性的模型。以上途径主要依据领域专家的定性判断, 构建相应的可信评估指标体系, 或是在定性评估的基础上, 探测网络信息可信度的关键影响因素及内在机理, 并构建相关的网络信息可信度测度模型。
不少学者结合网络信息内容的海量及高维等特征, 构建相应的数据挖掘分类及排序算法, 以提高网络环境下网络信息内容可信度测度的效率。Pasternack等[7]分别利用来自真实世界的两个无监督数据集和两个半监督数据集, 提出具有较强原则性的概率模型——潜在可信度分析(Latent Credibility Analysis, LCA), 其性能显著超过“事实的发现者”(Fact-Finders)的性能。用于识别可信语句的算法有TextRank算法[8], 它经过100个单独的语料库和一个组合的语料库两种方法的实证检验。上述数据挖掘分类及排序方法主要是基于网络信息内容当前状态数据的挖掘及评估, 尚缺乏网络信息用户对其体验性及交互性经验等先验知识的利用。
此外, 传统的可信度测度主要是模糊测度[9], 其中模糊隶属度的确定是测度的关键。隶属度函数是模糊控制的应用基础, 正确地构造隶属度函数是用好模糊控制的关键之一。隶属度函数的确定过程, 本质上应该是客观的, 但每个人对于同一个模糊概念的认识理解又有差异, 因此, 隶属度函数的确定又带有主观性。隶属度函数的确立目前还没有一套成熟有效的方法, 大多数系统的确立方法还停留在经验和实验的基础上。
贝叶斯推理方法可通过对已有经验及证据性数据的利用, 达到修正先验知识的目的[10]。以计算概率的方式获得网络信息内容的可信度值。与模糊测度相比较, 概率测度具有如下优势[11]: 论域可列可加; 基于用户参与的经验性标注行为数据, 确定特征关键词的存在可能性程度; 基于信息用户的客观行为数据, 以及可列可加性的特征, 概率测度结果会较为客观。此外, 基于社会化媒体, 信息用户相互之间能够对网络信息用户进行共享及交互评价, 进而形成集体智慧(Collective Intelligence)[12]。基于网络信息用户交互性评价所形成的集体智慧, 也将有助于提高网络信息内容可信度测度的效率。
因此, 本文基于信息用户的先验性知识及交互评价, 将贝叶斯推理应用于网络信息内容的可信测度, 构建基于已有经验及证据性数据的网络信息内容可信度的定量测度模型。此外, 本文还尝试构造最小错误率计算公式, 观察错误率随着参与者规模的增大而发生的变化规律, 探索网络信息用户集体智慧形成过程中, 用户规模对网络信息内容可信度测度的影响。
贝叶斯推理是经典的统计归纳推理, 其推理过程不仅依据当前的样本信息, 还要根据已有的经验和知识[13]。贝叶斯推理由概率论中的贝叶斯定理扩充而来, 将其引入网络信息内容的可信测度模型中, 在使模型具备概率背景的同时, 也可将网络信息用户的体验性评价作为先验知识融入模型, 从而可定量测度网络信息内容的可信度。
本文以案例“苹果具有红的前提下是否甜”的条件性推理问题为例说明信息内容可信度测度的贝叶斯推理思路。为方便计算, 在全部是苹果的大前提下, 选择苹果“红”与“甜”这两个属性, 分别用X, Y表示, 并且采取二值0、1赋值的方法, 数字“1”代表苹果红或甜, 数字“0”即为不红或不甜。可计算在苹果红的条件下苹果为甜的概率, 公式如下:
$\begin{align} & P(Y=1/X=1)= \\ & \frac{P(X=1/Y=1)P(Y=1)}{P(X=1/Y=1)P(Y=1)+P(X=1/Y=0)P(Y=0)} \\ \end{align}$ (1)
其中, $P(Y=1)$是属性甜的先验概率, $P(Y=0)$则表示属性不甜的概率; 而$P(X=1/Y=1)$和$P(X=1/Y=0)$分别表示在收集苹果甜与不甜的样本信息的条件下, 苹果红的抽样分布概率。上述先验分布概率及条件分布概率均可基于实际数据统计得到。
此外, 尚需考虑信息用户规模对网络信息内容可信度测度的影响。因为苹果“红”与“甜”的属性值为0或1, 故对于特定对象“苹果”而言, 属性“红”与“甜”相应的属性值均服从二项分布, 事件“苹果甜且红”、“苹果甜但不红”、“苹果不甜但红”、“苹果不甜也不红”也服从二项分布, 且它们构成一个完备事件组, 将事件“苹果红且甜”表示为事件A。所以, $P(A)=p=1/4$, $P(\bar{A})=1-p=3/4$。于是, n重伯努利试验中, 事件A出现的概率为p, 则A出现M(M为随机变量)次的概率为:
$A(k;n,p)=P(M=k)=C_{n}^{k}{{p}^{k}}{{(1-p)}^{n-k}},k=0,1,2,\cdots ,n$
于是, 公式(1)可表示为公式(2)所示。
$\begin{align} & P(Y=1/X=1)= \\ & \frac{C_{n}^{{{k}_{1}}}{{p}^{{{k}_{1}}}}{{(1-p)}^{n-{{k}_{1}}}}P(Y=1)}{C_{n}^{{{k}_{1}}}{{p}^{{{k}_{1}}}}{{(1-p)}^{n-{{k}_{1}}}}P(Y=1)+C_{n}^{{{k}_{2}}}{{p}^{{{k}_{2}}}}{{(1-p)}^{n-{{k}_{2}}}}P(Y=0)} \\ \end{align}$ (2)
由训练集可得公式(2)的初始先验概率为$P(Y=1)=p=1/4$, 似然概率为$C_{n}^{{{k}_{i}}}{{p}^{{{k}_{i}}}}{{(1-p)}^{n-{{k}_{i}}}}$, 其中ki=1, 2, 3, …, n, $i\in \{1,2\}$, n为样本矩阵的行数。${{k}_{1}}$为苹果红且甜的数量(X=1, Y=1), ${{k}_{2}}$为苹果红但不甜的数量(X=1, Y=0), 由此便可直接代入公式(2)计算得出事件A的后验概率$P(Y=1/X=1)$。
贝叶斯推理不仅利用当前信息, 还要在新的证据性数据的基础上修正先验信息。因此, 本文基于参与对信息内容进行体验性评价及交互性评价的信息用户规模的不同, 根据用户规模分组计算事件A的概率值。
基于贝叶斯推理的可信度测度中先验概率的获取, 需要说明的是, 计算第一组事件A的后验概率时, 贝叶斯公式中的先验分布概率及条件分布概率均由实际数据统计得到, 而从第二组数据开始, 其先验概率$P({{Y}_{i}}=1)$为上一组数据的后验概率, 即:
$P({{Y}_{i+1}}=1)=P({{Y}_{i}}=1/{{X}_{i}}=1)$, i=1, 2, …, n
这样可求得事件A的概率, 并且经过按比例的规模增加进行多次迭代计算, 得到与按比例增加的规模相对应的多个概率值。
对于社交媒体网络信息而言, 其信息内容是否可信, 主要体现为信息内容所包含的关键词是否可信。如果将信息内容对象类比为“苹果”, 则信息内容所包含的关键词可类比为“苹果”所包含的“红或甜”等属性。信息内容所包含的关键词是否可信, 可借鉴“苹果”在可观察的属性“红”的条件下, 基于贝叶斯推理所揭示的其隐含属性“甜”的存在可能性。因而, 本文基于直观例子“苹果具有红的前提下是否甜”所构建的贝叶斯推理模型公式(2), 可类比运用于社交媒体网络信息内容具有可观察确信关键词的前提下, 计算隐含关键词是否存在的可能性。
更一般地, 为定量测度信息内容对象C具有目标关键词K1的可信程度, 本文所构建的可信度测度模型涉及该对象的另一条件关键词K2, 以及基于观察者体验性经验, 能够揭示该信息内容对象C是否具有目标关键词K1及条件关键词K2的记录规模N, 如公式(3)所示。
$\begin{align} & P({{K}_{1}}=1/{{K}_{2}}=1)= \\ & \frac{C_{n}^{{{k}_{1}}}{{p}^{{{k}_{1}}}}{{(1-p)}^{n-{{k}_{1}}}}P({{K}_{1}}=1)}{C_{n}^{{{k}_{1}}}{{p}^{{{k}_{1}}}}{{(1-p)}^{n-{{k}_{1}}}}P({{K}_{1}}=1)+C_{n}^{{{k}_{2}}}{{p}^{{{k}_{2}}}}{{(1-p)}^{n-{{k}_{2}}}}P({{K}_{1}}=0)} \\ \end{align}$ (3)
为简化计算使其更为一般化, 公式(3)中的目标关键词K1及条件关键词K2可取值为更一般化的1(具有该关键词)或0(不具有该关键词)。
为衡量上述基于贝叶斯推理的可信度测度模型的有效性, 尝试基于贝叶斯决策理论, 引入错误率的概念, 计算其最小错误率[14], 并进一步探测在特定场景下信息的可信度随着参与者规模的增加, 可信度测度模型最小错误率变化的趋势。
(1) 贝叶斯决策
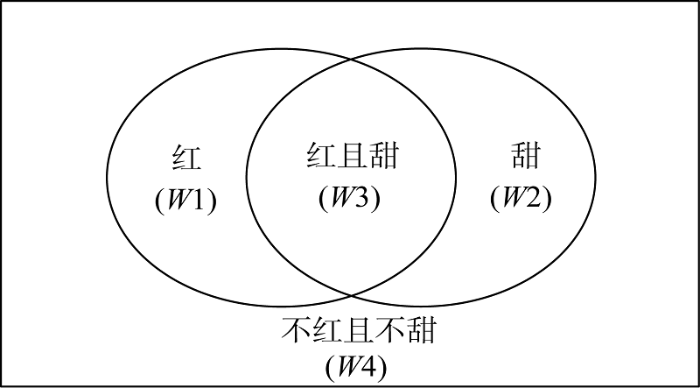
在运用贝叶斯决策理论的时候必须满足如下的基本条件: 各类别总体的概率分布是已知的; 被决策的分类数是一定的[15]。因此, 以上述特定事物苹果为例, 基于其是否具有两种属性(红或甜), 可将其划分为4种状态, 用W表示状态, W={W1, W2, W3, W4}。具体表示如图1所示。
如图1所示, W1表示状态“苹果红且甜”, W2表示状态“苹果红但不甜”, W3表示状态“苹果不红但甜”, W4则表示状态“苹果不红也不甜”。
当状态W1发生时$P({{W}_{1}})=P(Y=1/X=1)$; 当状态W2发生时$P({{W}_{2}})=P(Y=0/X=1)$; 当状态W3发生时$P({{W}_{3}})=P(Y=1/X=0)$; 当状态W4发生时$P({{W}_{4}})=P(Y=0/X=0)$。其中, $P({{W}_{1}})+P({{W}_{2}})=1;$ $P({{W}_{3}})+P({{W}_{4}})=1$。这4种状态出现的概率均可计算得出, 以P(W3)为例其计算如公式(4)。
$\begin{align} & P({{W}_{3}})= \\ & \frac{C_{n}^{{{k}_{3}}}{{p}^{{{k}_{3}}}}{{(1-p)}^{n-{{k}_{3}}}}P(Y=1)}{C_{n}^{{{k}_{3}}}{{p}^{{{k}_{3}}}}{{(1-p)}^{n-{{k}_{3}}}}P(Y=1)+C_{n}^{{{k}_{4}}}{{p}^{{{k}_{4}}}}{{(1-p)}^{n-{{k}_{4}}}}P(Y=0)} \\ \end{align}$ (4)
其中, ${{k}_{3}}$为苹果不红且甜的数量(X=0, Y=1), ${{k}_{4}}$为苹果不红也不甜的数量(X=0, Y=0)。
(2) 类条件概率密度函数
除用作训练参数计算概率值的数据组外, 根据样本特征组成二维特征向量$z=[{{x}_{i}},{{y}_{i}}]$, 其中i=1, 2。该二维特征向量用于计算上述4类状态的类条件概率密度, x和y的可能取值均为0和1。即有$z=[{{x}_{1}}=1,{{y}_{1}}=1]$, $z=[{{x}_{2}}=1,{{y}_{2}}=0]$, $z=[{{x}_{3}}=0,$ ${{y}_{3}}=1]$, $z=[{{x}_{4}}=0,{{y}_{4}}=0]$。属性x=1表示始终选择苹果属性为红的数据, $p(z/{{w}_{1}})$是红苹果的属性为甜的类条件概率密度, 且$p(z/{{w}_{1}})=p({{x}_{1}}=1,$ ${{y}_{1}}=1)$;$p(z/{{w}_{2}})$是红苹果的属性不甜的类条件概率密度, 且$p(z/{{w}_{2}})=p({{x}_{2}}=1,{{y}_{2}}=0)$, 以此类推可分别求得W3与W4的类条件概率密度。由于状态1和状态2发生的概率构成完备事件组, $P({{W}_{1}})+P({{W}_{2}})=1$, 同理有$P({{W}_{1}})+P({{W}_{3}})=1$。基于初始的训练集, 类条件概率均可计算确定, 即有$p(z/{{w}_{i}})={{(1/4)}^{ki}}$, i=1, 2, 3, 4。其中, ki表示4类状态的统计数量。
当i取值为1或2时, 分别计算出状态W1和W2的后验概率, 表示如下:
$p({{w}_{i}}/z)=\frac{p(z/{{w}_{i}})p({{w}_{i}})}{p(z/{{w}_{1}})p({{w}_{1}})+p(z/{{w}_{2}})p({{w}_{2}})}$ (5)
同理, 当i取值为3或4时, 计算状态W3和W4的后验概率, 表示如下:
$p({{w}_{i}}/z)=\frac{p(z/{{w}_{i}})p({{w}_{i}})}{p(z/{{w}_{3}})p({{w}_{3}})+p(z/{{w}_{4}})p({{w}_{4}})}$ (6)
(3) 最小错误率公式
为保证错误率最小, 要使对于每个证据因子的$P(e/z)$取最小值, 所以每次均取$P({{w}_{1}}/z)$和$P({{w}_{2}}/z)$、$P({{w}_{3}}/z)$和$P({{w}_{4}}/z)$中的最小值[16]。表示如下:
当i取值为1或2时, ${{P}_{1}}(e/z)=\min \{P({{w}_{1}}/z),$ $P({{w}_{2}}/z)\}$
当j取值为3或4时, ${{P}_{2}}(e/z)=\min \{P({{w}_{3}}/z),$ $P({{w}_{4}}/z)\}$
所以, 错误率$P(e)={{P}_{1}}(e/z)P({{w}_{i}})+{{P}_{2}}(e/z)$ $P({{w}_{j}})$, 其中i=1或2; j=3或4。例如, 当${{P}_{1}}(e/z)=P({{w}_{1}}/z)$时, i=1;当${{P}_{2}}(e/z)=P({{w}_{3}}/z)$时, j=3, 以此类推。
为进一步明确上述步骤, 本文以样本数据为例说明上述模型的思路, 样本数据集中训练集为100条记录的前50条记录; 测试集为后50条记录。
首先, 观察数据可得, ${{k}_{1}}$为苹果红且甜的数量, ${{k}_{1}}=11$, ${{k}_{2}}$为苹果红但不甜的数量, ${{k}_{2}}=15$, 由此便可直接代入公式(2)和公式(4)计算得出苹果在红的条件下甜的后验概率$P(Y=1/X=1)$以及苹果在不红的条件下甜的后验概率$P(Y=1/X=0)$如下:
$\begin{align} & P(Y=1/X=1) \\ & =\frac{C_{n}^{{{k}_{1}}}{{p}^{{{k}_{1}}}}{{(1-p)}^{n-{{k}_{1}}}}P(Y=1)}{C_{n}^{{{k}_{1}}}{{p}^{{{k}_{1}}}}{{(1-p)}^{n-{{k}_{1}}}}P(Y=1)+C_{n}^{{{k}_{2}}}{{p}^{{{k}_{2}}}}{{(1-p)}^{n-{{k}_{2}}}}P(Y=0)} \\& =\frac{C_{50}^{11}\frac{1}{4}{{}^{11}}\frac{3}{4}{{}^{50\text{-}11}}\times \frac{11}{50}}{C_{50}^{11}\frac{1}{4}{{}^{11}}\frac{3}{4}{{}^{50\text{-}11}}\times \frac{11}{50}+C_{50}^{15}\frac{1}{4}{{}^{15}}\frac{3}{4}{{}^{50\text{-}15}}\times \frac{11}{50}} \\ & \approx \frac{0.026}{0.026+0.089}\approx 0.23 \\ \end{align}$
另外, ${{k}_{3}}$为苹果不红但甜的数量, ${{k}_{3}}=10$, ${{k}_{4}}$为苹果不红也不甜的数量, ${{k}_{4}}=14$。
$\begin{align} & P(Y=1/X=0) \\ & =\frac{C_{n}^{{{k}_{3}}}{{p}^{{{k}_{3}}}}{{(1-p)}^{n-{{k}_{3}}}}P(Y=1)}{C_{n}^{{{k}_{3}}}{{p}^{{{k}_{3}}}}{{(1-p)}^{n-{{k}_{3}}}}P(Y=1)+C_{n}^{{{k}_{4}}}{{p}^{{{k}_{4}}}}{{(1-p)}^{n-{{k}_{4}}}}P(Y=0)} \\ & =\frac{C_{50}^{10}\frac{1}{4}{{}^{10}}\frac{3}{4}{{}^{50\text{-}10}}\times \frac{11}{50}}{C_{50}^{10}\frac{1}{4}{{}^{10}}\frac{3}{4}{{}^{50\text{-}10}}\times \frac{11}{50}+C_{50}^{14}\frac{1}{4}{{}^{14}}\frac{3}{4}{{}^{50\text{-}14}}\times \frac{11}{50}} \\ & \approx \frac{0.099}{0.099+0.111}\approx 0.21 \\ \end{align}$
于是, 状态“红苹果甜”的概率为P(W1)=0.23; 状态“红苹果不甜”的概率为P(W2)=1-0.23=0.77; 状态“苹果不红但甜”的概率为P(W3)=0.21; 状态“苹果不红也不甜”的概率为P(W4)=1-0.21=0.79。然后, 利用测试集$z=[{{x}_{i}},{{y}_{i}}]$得出状态的后验概率, 其中i=1, 2, 3, 4。测试集中, ${{k}_{1}}$为苹果红且甜的数量, ${{k}_{1}}=12$, ${{k}_{2}}$为苹果红但不甜的数量, ${{k}_{2}}=14$, ${{k}_{3}}$为苹果不红但甜的数量, ${{k}_{3}}=6$, ${{k}_{4}}$为苹果不红也不甜的数量, ${{k}_{4}}=18$。基于公式(5)和公式(6)计算可得到:
$\begin{align} & p({{w}_{1}}/z)=\frac{p(z/{{w}_{1}})p({{w}_{1}})}{p(z/{{w}_{1}})p({{w}_{1}})+p(z/{{w}_{2}})p({{w}_{2}})} \\ & \ \ \ \ \ \ \ \ \ \ \ =\frac{{{(\frac{1}{4})}^{12}}\times 0.23}{{{(\frac{1}{4})}^{12}}\times 0.23+{{(\frac{1}{4})}^{14}}\times 0.77}\approx 0.827 \\ \end{align}$
$p({{w}_{2}}/z)=1-0.827=0.173$
$\begin{align} & p({{w}_{3}}/z)=\frac{p(z/{{w}_{3}})p({{w}_{3}})}{p(z/{{w}_{3}})p({{w}_{3}})+p(z/{{w}_{4}})p({{w}_{4}})} \\ & \ \ \ \ \ \ \ \ \ \ \ \ =\frac{{{(\frac{1}{4})}^{6}}\times 0.21}{{{(\frac{1}{4})}^{6}}\times 0.21+{{(\frac{1}{4})}^{18}}\times 0.79}\approx 0.999 \\ \end{align}$
$p({{w}_{4}}/z)=1-0.999=0.001$
显然, $p({{w}_{2}}/z)<p({{w}_{1}}/z);p({{w}_{4}}/z)<p({{w}_{3}}/z)$, 则${{P}_{1}}(e/z)=0.173;{{P}_{2}}(e/z)=0.001$。
所以, 第一组数据最终的错误率为: $\begin{align}& P(e)={{P}_{1}}(e/z)P({{w}_{2}})+{{P}_{2}}(e/z)P({{w}_{4}})=0.173\times 0.77+ \\ & 0.001\times 0.79=0.134 \\ \end{align}$
基于三类真实数据集, 以及衡量可信度测度效率的最小错误率公式, 将本文所构建的贝叶斯推理可信度测度模型, 与目前具有代表性的模糊可信度测度模型相比较, 以验证上述基于贝叶斯推理的网络信息内容可信度测度模型, 并探索贝叶斯可信度测度模型和模糊可信度测度模型的最小错误率随着参与者规模的增加而变化的趋势。
为探索错误率随记录规模增加而变化的规律, 本文尝试按一定比例逐渐增加样本的数量(如每次抽样在原来记录规模基础上增加100条记录), 依次抽取累积的记录作为样本数据。在每次实验中, 取样本数据的50%作为可信度测度计算的输入, 基于贝叶斯可信度测度公式计算对象是否具有目标属性的可信值; 取样本数据的50%作为最小错误率计算的输入, 基于最小错误率公式计算可信度测度的错误率。
基于典型的UCI数据库①(①Bache K, Lichman M.UCI Machine Learning Repository[OL]. vol. 19, 2013. http://archive.ics. uci.edu/ml.), 分别选取计算机、社交、网络新闻三个不同领域的社交媒体数据集。对于每个数据集, 分别确定可观察的条件属性关键词以及隐含的目标属性关键词。基于社交媒体参与者的评价或标注, 如果参与者认为信息内容对象具有相应属性关键词, 则相应目标属性及条件属性取值为1(具有该属性), 否则为0(不具有该属性), 因而每个数据集是取值为0或1的矩阵${{M}_{n\times 2}}$, 其中, n为参与者的规模, 两列属性关键词为别为目标属性关键词和条件属性关键词。
数据集1: 数据集1来自于2012年YouTube的喜剧大满贯实验, 属于计算机类主题, 共包含1 138 562条记录, 3个属性, 抽取该对象的目标属性“左或右”(左表示视频有趣, 右则相反)及条件属性“YouTube视频ID”, 可构成1593行、2列的0-1矩阵。
数据集2: 数据集2来自于博客帖子在24小时之内的评论数量, 属于社交类主题, 共包含60 021条记录, 281种属性, 抽取该对象的目标属性“博客的评论数”及条件属性“博客文章的长度”, 可构成21 276行、2列的0-1矩阵。
数据集3: 数据集3来自于互联网信息服务器MSNBC.com和MSN.com新闻相关的部分记录, 属于网络新闻类主题, 相关记录共有981 818条记录、17个属性, 抽取该对象的目标属性“首页与新闻”的点击顺序及条件属性“首页与其它”的点击顺序, 可构成435050行、2列的0-1矩阵。
本文所构建的可信度测度模型及衡量可信度测度模型的最小错误率公式, 对三个不同领域的相关数据集进行实验, 分别得到随着用户规模而变化的错误率。
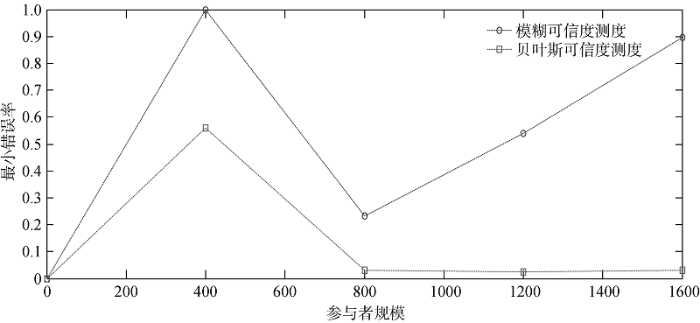
实验一: 计算机类主题的可信度测度, 基于实验结果如图2所示。
由图2可知, 参与者规模从200增加到1 593的过程中, 模糊可信度测度模型的最小错误率始终高于贝叶斯可信度测度模型的最小错误率。因此, 对于计算机领域对象可信度测度而言, 贝叶斯可信度测度模型具有较高的可行性和有效性。
就贝叶斯可信度测度的错误率而言, 当用户规模小于400时, 错误率随着用户规模的增加而显著提高; 当用户规模大于400时, 错误率随着用户规模的增加而显著降低; 当用户规模达到800时, 错误率趋于稳定。该领域的对象是否具有目标属性的可信度测度模型的错误率随着用户规模的增加具有波动的特征。结合错误率随用户规模变化的趋势, 对于该领域的对象而言, 在对其具有目标属性的可信度进行测度时, 应选择用户规模大于800为宜。
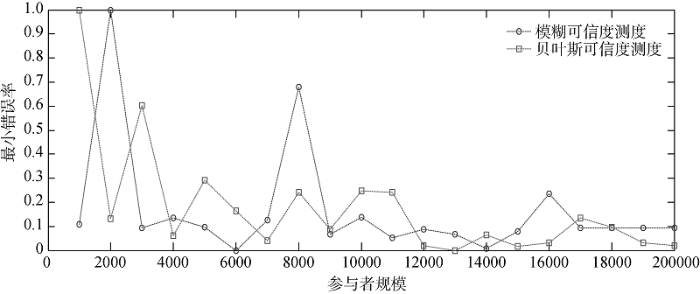
实验二: 社交主题的可信度测度, 实验结果如图3所示。
由图3可知, 两个模型的可信度测度的最小错误率均总体呈现降低的趋势。参与者规模从2 000增加到6 000的过程中, 也即参与者规模较小时, 模糊可信度测度模型的最小错误率低于贝叶斯可信度测度模型的最小错误率。而随着参与者规模的增加, 模糊可信度测度模型的最小错误率也开始高于贝叶斯可信度测度模型的最小错误率。因此, 对于社交领域对象可信度测度而言, 随着参与者越来越多, 贝叶斯可信度测度模型具有较高的可行性和有效性。
就可信度测度的错误率而言, 当用户规模小于2 000时, 错误率随着用户规模的增加而显著提高; 当用户规模大于2 000且小于12 000时, 错误率随着用户规模的增加而总体呈下降趋势, 尽管这期间有上下波动; 当用户规模大于12 000时, 错误率逐渐降低并且渐渐趋于稳定。该领域的对象是否具有目标属性的可信度测度模型的错误率随着用户规模的增加具有波动的特征。结合可信度及错误率随用户规模变化的趋势, 对于该领域的对象而言, 在对其具有目标属性的可信度进行测度时, 应选择用户规模大于12 000为宜。
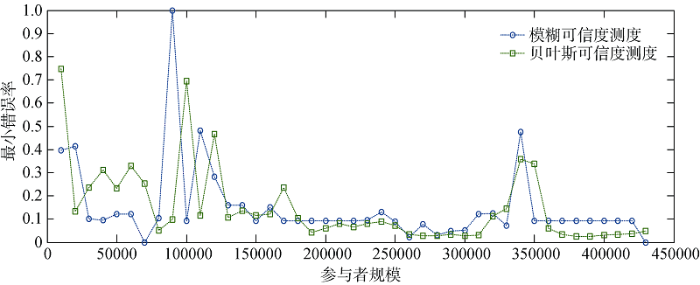
实验三: 网络新闻信息主题的可信度测度, 实验结果如图4所示。
由图4可知, 两个模型的可信度测度的最小错误率均总体呈现降低的趋势。参与者规模从50 000增加到200 000的过程中, 模糊可信度测度模型的最小错误率低于贝叶斯可信度测度模型的最小错误率。而随着参与者规模的增加, 模糊可信度测度模型的最小错误率开始高于贝叶斯可信度测度模型的最小错误率。因此, 对于网络新闻领域对象可信度测度而言, 随着参与者越来越多, 贝叶斯可信度测度模型具有较高的可行性和有效性。
就可信度测度的错误率而言, 当用户规模小于100 000时, 错误率的波动较大, 随着用户规模的增加而总体呈下降趋势; 当用户规模大于150 000时, 错误率随着用户规模的增加而显著降低; 当用户规模达到350 000时, 错误率趋于稳定。由上述结果可知, 贝叶斯可信度测度模型结果的错误率随着用户规模的增加具有波动的特征。结合可信度及错误率随用户规模变化的趋势, 对于该领域的对象而言, 在对其具有目标属性的可信度进行测度时, 应选择参与者规模介于200 000和300 000之间以及大于350 000为宜。
上述实验结果表明: 在参与者规模越来越多的情况下, 贝叶斯可信度测度模型相较于模糊可信度测度模型而言, 具有较高的可行性; 贝叶斯可信度测度模型的最小错误率会随着用户规模的增加, 总体呈现降低且始终大于0的趋势, 但对于不同领域的对象及目标属性而言, 该变化趋势也具有不同的波动特征。
在构建可信度测度模型过程中, 本文基于贝叶斯推理理论, 首先针对一定用户规模的特定事件所具有目标属性的数据集, 计算出其先验概率; 然后按一定比例逐渐增加用户规模, 对该特定事件具有目标属性的可信度进行迭代计算; 最后获得随着用户规模不断扩大所不断增加的新信息, 计算该特定事件具有目标属性可信度的后验概率逐渐被修正的结果。本文模型利用参与用户对事件是否具有目标属性的体验性经验, 提出了网络信息内容可信度的定量测度指标。
对于可信度测度模型结果的评价, 本文基于贝叶斯决策理论, 构建最小错误率模型, 该模型在一定程度上揭示了特定事件具有目标属性可信度的可靠性或可接受程度, 为可信度测度模型的实际运用提供了更多的参照标准。即, 对于一定的用户规模, 当其可信度测度的最小错误率较高时, 相应的可信度测度值的可靠性或可接受程度较低。并揭示了随着用户规模的增加, 最小错误率总体降低的趋势, 这其中体现了集体智慧的规律。
此外, 本文选择目前具有代表性的模糊测度法, 基于贝叶斯决策的最小错误率公式, 分别探索模糊可信度测度模型和贝叶斯可信度测度模型的最小错误率随着参与者规模的增加而变化的趋势。虽然随着参与者规模的增加, 两个模型的最小错误率总体都呈现降低的趋势, 但是模糊可信度测度模型的最小错误率总体而言高于贝叶斯可信度测度模型的最小错误率, 由此证明本文构建的贝叶斯可信度测度模型的有效性和可行性。
基于贝叶斯推理理论, 构建了网络信息内容可信度测度模型, 基于贝叶斯决策理论, 构建了衡量可信度测度模型的最小错误率模型, 并基于集体智慧的思想, 揭示了随着参与用户规模的增大, 最小错误率识别错误率的变化规律。利用三个不同领域的真实数据集, 验证了相关模型的有效性。具体而言, 本文所构建的网络信息内容可信度测度模型及最小错误率模型具备以下优势:
(1) 不同于传统的基于调查或实验、基于领域专家知识的定性判断、以及基于用户主观感知[17]的侧重于定性的信息可信度评估途径, 本文基于贝叶斯推理及决策模型, 构建了基于参与用户客观行为数据的信息可信度定量测度模型。
(2) 基于贝叶斯推理的网络信息可信度测度模型, 实现了对已有经验和证据性数据的有效利用, 也即, 随着用户规模按比例扩大, 较小用户规模时的后验概率会作为先验概率, 增加的用户经验会不断修正该先验概率, 进而形成更符合实际可信度的后验概率。该途径不再单纯依据当前信息内容, 从而弥补了传统数据挖掘中分类及排序方法缺乏对先验知识及新信息进行利用的不足。
(3) 基于贝叶斯决策理论的最小错误率模型, 实现了对可信度测度可靠性及可接受程度的评价。对于特定用户规模前提下, 可信度测度值是否可靠, 应参考相关的最小错误率是否满足实际应用的可接受标准。该模型为可信度测度模型的实际应用提供了参照标准, 并可更加直观地体现测度模型的可行性。相关实验结果也揭示了集体智慧理论所体现的规律。随着参与用户规模的增加, 可信度测度的错误率总体趋于下降。
对于不同领域的实验数据, 基于本文所构建的最小错误率模型, 随着参与者规模的增加, 最小错误率总体呈现下降趋势。并且模糊可信度测度模型的最小错误率高于贝叶斯可信度测度模型的最小错误率由此证明了本文构建的贝叶斯可信度测度模型的有效性和可行性。但对于不同领域的数据而言, 其波动趋势会有差异, 因而, 本文所构建的可信度测度模型虽然适用领域范围较广, 但在具体应用时, 应分析相关的应用领域场景前提。
鉴于网络信息内容可信度测度所涉及的影响因素较复杂, 本文所构建的可信度测度模型仍存在一些在未来的研究中需要进一步改进的工作: 网络信息内容可信度的影响因素较多, 除条件属性及用户规模之外, 其他因素对可信度测度的影响程度需要进一步探索, 此外, 不同影响因素之间的相关性也需要在构建可信度测度模型时进一步探讨; 本文实验主要涉及三个不同领域的数据集, 相关模型是否适用于其他更为广泛的应用领域, 需要在今后的研究中进一步验证。
李保珍: 提出研究命题、研究思路, 论文最终版本修订;
王亚: 数据处理及实验验证, 论文撰写及修改。
周可: 数据分析及实验。
所有作者声明不存在利益冲突关系。
支撑数据[1]见http://archive.ics.uci.edu/ml; 支撑数据[2-4]由作者自存储, E-mail: baozhenli@126.com。
[1] Bache K, Lichman M. category_url. “UCI machine learning repository,” 推荐文章栏目包含的网页链接.
[2] 李保珍. 数据集1: 2012年YouTube的喜剧大满贯实验.
[3] 李保珍. 数据集2: 博客帖子在24小时之内的评论数量.
[4] 李保珍. 数据集3: 互联网信息服务器MSNBC.com和MSN.com新闻相关的部分记录.
| [1] |
Making Sense of Credibility on the Web: Models for Evaluating Online Information and Recommendations for Future Research. [J]https://doi.org/10.1002/asi.20672 URL [本文引用: 1] 摘要
This article summarizes much of what is known from the communication and information literacy fields about the skills that Internet users need to assess the credibility of online information. The article reviews current recommendations for credibility assessment, empirical research on how users determine the credibility of Internet information, and describes several cognitive models of online information evaluation. Based on the literature review and critique of existing models of credibility assessment, recommendations for future online credibility education and practice are provided to assist users in locating reliable information online. The article concludes by offering ideas for research and theory development on this topic in an effort to advance knowledge in the area of credibility assessment of Internet-based information.
|
| [2] |
Web Credibility Research: A Method for Online Experiments and Early Study Results [C]// |
| [3] |
Credibility Microscope: Relating Web Page Credibility Evaluations to Their Textual Content [C]// |
| [4] |
Mitigating Risk in Ecommerce Transactions: Perceptions of Information Credibility and the Role of User-Generated Ratings in Product Quality and Purchase Intention [J].https://doi.org/10.1007/s10660-014-9139-2 URL Magsci [本文引用: 2] 摘要
Although extremely popular, electronic commerce environments often lack information that has traditionally served to ensure trust among exchange partners. Digital technologies, however, have created new forms of "electronic word-of-mouth," which offer new potential for gathering credible information that guides consumer behaviors. We conducted a nationally representative survey and a focused experiment to assess how individuals perceive the credibility of online commercial information, particularly as compared to information available through more traditional channels, and to evaluate the specific aspects of ratings information that affect people's attitudes toward ecommerce. Survey results show that consumers rely heavily on web-based information as compared to other channels, and that ratings information is critical in the evaluation of the credibility of online commercial information. Experimental results indicate that ratings are positively associated with perceptions of product quality and purchase intention, but that people attend to average product ratings, but not to the number of ratings or to the combination of the average and the number of ratings together. Thus suggests that in spite of valuing the web and ratings as sources of commercial information, people use ratings information suboptimally by potentially privileging small numbers of ratings that could be idiosyncratic. In addition, product quality is shown to mediate the relationship between user ratings and purchase intention. The practical and theoretical implications of these findings are considered for ecommerce scholars, consumers, and vendors.
|
| [5] |
基于网络用户体验与感知的信息质量影响因素模型实证研究 [J]https://doi.org/10.3772/j.issn.1000-0135.2013.06.011 URL [本文引用: 1] 摘要
随着网络环境的变化与发展,信息用户的地位也随之发生了变化,用 户在与网站交互过程中的体验与感知直接影响其对信息质量的评价与满意度.文章运用了问卷调查研究方法对所提出的网络用户体验与感知视角的信息质量影响因素 模型进行验证与修正.结果表明,其模型由信息特征、帮助支持、感观心理、过程服务、基本功能、用户个性素养六个维度所构成,其指标要素涵盖了用户在信息获 取与信息交互过程的全方位、多视角体验与感知到的信息质量影响因素,体现与反映了基本网络用户的特征与切实需求.研究结果将为通过优化用户体验与感知提升 信息质量提供可兹借鉴的路径.
Empirical Study on Information Quality Influencing Factors Based on Network User Experience and Perception [J].https://doi.org/10.3772/j.issn.1000-0135.2013.06.011 URL [本文引用: 1] 摘要
随着网络环境的变化与发展,信息用户的地位也随之发生了变化,用 户在与网站交互过程中的体验与感知直接影响其对信息质量的评价与满意度.文章运用了问卷调查研究方法对所提出的网络用户体验与感知视角的信息质量影响因素 模型进行验证与修正.结果表明,其模型由信息特征、帮助支持、感观心理、过程服务、基本功能、用户个性素养六个维度所构成,其指标要素涵盖了用户在信息获 取与信息交互过程的全方位、多视角体验与感知到的信息质量影响因素,体现与反映了基本网络用户的特征与切实需求.研究结果将为通过优化用户体验与感知提升 信息质量提供可兹借鉴的路径.
|
| [6] |
Predicting Information Credibility in Time-Sensitive Social Media [J]https://doi.org/10.1108/IntR-05-2012-0095 URL Magsci [本文引用: 1] 摘要
Purpose - Twitter is a popular microblogging service which has proven, in recent years, its potential for propagating news and information about developing events. The purpose of this paper is to focus on the analysis of information credibility on Twitter. The purpose of our research is to establish if an automatic discovery process of relevant and credible news events can be achieved.<br/>Design/methodology/approach - The paper follows a supervised learning approach for the task of automatic classification of credible news events. A first classifier decides if an information cascade corresponds to a newsworthy event. Then a second classifier decides if this cascade can be considered credible or not. The paper undertakes this effort training over a significant amount of labeled data, obtained using crowdsourcing tools. The paper validates these classifiers under two settings: the first, a sample of automatically detected Twitter "trends" in English, and second, the paper tests how well this model transfers to Twitter topics in Spanish, automatically detected during a natural disaster.<br/>Findings - There are measurable differences in the way microblog messages propagate. The paper shows that these differences are related to the newsworthiness and credibility of the information conveyed, and describes features that are effective for classifying information automatically as credible or not credible.<br/>Originality/value - The paper first tests the approach under normal conditions, and then the paper extends the findings to a disaster management situation, where many news and rumors arise. Additionally, by analyzing the transfer of our classifiers across languages, the paper is able to look more deeply into which topic-features are more relevant for credibility assessment. To the best of our knowledge, this is the first paper that studies the power of prediction of social media for information credibility; considering model transfer into time-sensitive and language-sensitive contexts.
|
| [7] |
Latent Credibility Analysis [C]// |
| [8] |
Application of TextRank Algorithm for Credibility Assessment [C]// |
| [9] |
Multi-item Supplier Selection Model with Fuzzy Risk Analysis Studied by Possibility and Necessity Constraints [J]https://doi.org/10.1016/j.fiae.2015.11.004 URL [本文引用: 1] 摘要
Three different supplier selection models have been developed in crisp and fuzzy environments. Here two objective functions have been considered, profit and risk. In this paper, profit has been maximized and risk has been minimized with some constraints. Each supplier has an limited capacity. The purchasing cost of each item from different supplier as well as associative risk is known. The total space and budget of a retailer are constant. In Model I, all the parameters are considered as crisp. In Model II, the demand has been considered as fuzzy. In Model III, the risk values and demand have been considered as fuzzy. To defuzzyfy the fuzzy constraints, necessity and possibility have been introduced. To defuzzyfy the fuzzy objective, two different methods, credibility measure and -cut method have been introduced. All the models have been illustrated numerically using multi-objective genetic algorithm (MOGA). Also a sensitivity analysis has been done taking different sets of risk values and a comparison result has been shown for credibility measure and -cut method for Model III.
|
| [10] |
基于贝叶斯推理的决策树模型 [J]https://doi.org/10.3321/j.issn:0253-987X.2006.08.005 URL [本文引用: 1] 摘要
针对决策树(DT)模型缺乏概率背景这一问题,将贝叶斯推理引入DT模型,提出了一种基于贝叶斯推理的决策树(BDT)模型.在假定所含待定参量的先验与似然的前提下,借助贝叶斯推理获得参量的后验,然后运用逆跳马尔科夫链蒙特卡洛算法对后验抽样,最终求出样本属于某一类别的置信度,从而避免了武断判决.BDT模型以抽样代替拆分与剪枝操作,既直观又灵活,同时在抽样时考虑了不同的树结构与递归分割方案,使得分类准确率得以提高.仿真实验结果表明,BDT模型的平均分类准确率与DT模型相比提高了1.7%~3.5%.
Decision Tree Model Based on Bayesian Inference [J].https://doi.org/10.3321/j.issn:0253-987X.2006.08.005 URL [本文引用: 1] 摘要
针对决策树(DT)模型缺乏概率背景这一问题,将贝叶斯推理引入DT模型,提出了一种基于贝叶斯推理的决策树(BDT)模型.在假定所含待定参量的先验与似然的前提下,借助贝叶斯推理获得参量的后验,然后运用逆跳马尔科夫链蒙特卡洛算法对后验抽样,最终求出样本属于某一类别的置信度,从而避免了武断判决.BDT模型以抽样代替拆分与剪枝操作,既直观又灵活,同时在抽样时考虑了不同的树结构与递归分割方案,使得分类准确率得以提高.仿真实验结果表明,BDT模型的平均分类准确率与DT模型相比提高了1.7%~3.5%.
|
| [11] |
Comparison of Fuzzy Numbers Based on the Probability Measure of Fuzzy Events [J]https://doi.org/10.1016/0898-1221(88)90124-1 URL [本文引用: 1] 摘要
Most approaches for ranking fuzzy numbers proposed in the literature are based on fuzzy sets theory only, and suffer from lack of discrimination and occasionally conflict with intuition. It is true that fuzzy numbers are frequently partial order and cannot be compared. However,this does not alleviate the need for comparison in practical applications. In this paper the order of fuzzy numbers are determined based on the concept of probability measure of fuzzy events due to Zadeh. It considers both the mean and dispersion of alternatives and gives two groups of indices based on the uniform and the proportional probability distributions. The approach is also extended to the comparison of random fuzzy numbers by means of a mean fuzzy number. It is shown that several comparison indices in the literature can be obtained based on the probability present measure approach. Finally some typical examples are used to compare the various different approaches. The different interpretations of the dispersion index under different physical situations are emphasized.
|
| [12] |
集体智慧的内涵及研究综述 [J]
基于对集体智慧的内涵、组成及形成过程的探讨,综述了国内外关于集体智慧的优越性、影响因素及应用研究,构建了集体智慧的理论研究框架。该框架从个体智慧贡献、集体智慧形成及集体智慧平台发展3个方面梳理了集体智慧发展的影响因素,并整合了集体智慧的主要应用领域。
The Collective Wisdom of the Connotation and Research Review [J].
基于对集体智慧的内涵、组成及形成过程的探讨,综述了国内外关于集体智慧的优越性、影响因素及应用研究,构建了集体智慧的理论研究框架。该框架从个体智慧贡献、集体智慧形成及集体智慧平台发展3个方面梳理了集体智慧发展的影响因素,并整合了集体智慧的主要应用领域。
|
| [13] |
谈调查问卷的可信度与有效度问题 [J]https://doi.org/10.3969/j.issn.1002-5863.2008.15.034 URL [本文引用: 1] 摘要
为了保证调查的准确性与科学性,对搜集到的问卷资料进行可信度和有效度分析已成为调查的一个必不可少的步骤,本文对调查问卷的可信度与有效度问题展开研究,并说明如何在SPSS软件上实现可信度与有效度的度量。
The Reliability and Validity of the Questionnaire [J].https://doi.org/10.3969/j.issn.1002-5863.2008.15.034 URL [本文引用: 1] 摘要
为了保证调查的准确性与科学性,对搜集到的问卷资料进行可信度和有效度分析已成为调查的一个必不可少的步骤,本文对调查问卷的可信度与有效度问题展开研究,并说明如何在SPSS软件上实现可信度与有效度的度量。
|
| [14] |
基于最小错误率的贝叶斯决策在手写英文字母分类识别中的应用 [J]https://doi.org/10.3969/j.issn.1674-3261.2009.02.009 URL [本文引用: 1] 摘要
统计决策理论是处理模式识别问题的基本理论之一,而贝叶斯决策理论方法又是统计模式识别中的一个基本方法,它可以有效地对大量数据进行分析,并生成相应的分类器,对于数据的分类识别有着重大的意义.把最小错误率的贝叶斯方法运用到手写英文字母的识别中,提高了分类的准确性和有效性.
Application of Bayesian Decision Making Based on Minimum Error Rate in Handwritten Chinese Character Recognition [J].https://doi.org/10.3969/j.issn.1674-3261.2009.02.009 URL [本文引用: 1] 摘要
统计决策理论是处理模式识别问题的基本理论之一,而贝叶斯决策理论方法又是统计模式识别中的一个基本方法,它可以有效地对大量数据进行分析,并生成相应的分类器,对于数据的分类识别有着重大的意义.把最小错误率的贝叶斯方法运用到手写英文字母的识别中,提高了分类的准确性和有效性.
|
| [15] |
基于最小错误率贝叶斯决策和平滑滤波的图像去噪算法研究 [D]Research on Image Denoising Algorithm Based on Minimum Error Rate Bayes Decision and Smoothing Filter [D]. |
| [16] |
社会化媒体信息源感知可信度及其影响因素研究——一项基于微博用户方便样本调查的实证分析 [J]
随着社会化媒体在世界范围内的广泛流行,越来越多的用户开始使用社会化媒体获取信息。对于传播学研究而言,了解用户如何对社会化媒体上的信息可信度作出判断是一个非常重要的研究问题。本文通过方便抽样的方法对微博用户进行问卷调查,以实证的方式对社会化媒体用户的信息源感知可信度及其影响因素进行了研究。结果表明,用户对机构微博主(信息源)的感知信任度要显著高于个人微博主(信息源),专业型的"意见领袖"相比之社会名人更容易获得用户的青睐。包括用户的人口统计学特征、微博使用习惯和微博谣言/虚假信息感知在内的一系列影响因素会对用户的信息源可信度感知造成影响。这些实证分析结论为进一步对社会化媒体信息源可信度开展研究提供了一个参考。
Perceived Social Media Source Credibility and Its Influence Factors: An Empirical Analysis Based on Weibo Users’ Convenience Sample Survey [J].
随着社会化媒体在世界范围内的广泛流行,越来越多的用户开始使用社会化媒体获取信息。对于传播学研究而言,了解用户如何对社会化媒体上的信息可信度作出判断是一个非常重要的研究问题。本文通过方便抽样的方法对微博用户进行问卷调查,以实证的方式对社会化媒体用户的信息源感知可信度及其影响因素进行了研究。结果表明,用户对机构微博主(信息源)的感知信任度要显著高于个人微博主(信息源),专业型的"意见领袖"相比之社会名人更容易获得用户的青睐。包括用户的人口统计学特征、微博使用习惯和微博谣言/虚假信息感知在内的一系列影响因素会对用户的信息源可信度感知造成影响。这些实证分析结论为进一步对社会化媒体信息源可信度开展研究提供了一个参考。
|
| [17] |
网络文本数据分类技术与实现算法 [J]https://doi.org/10.3969/j.issn.1000-0135.2002.01.005 URL [本文引用: 1] 摘要
本文主要论述网络文本数据挖掘中的文本分类技术原理、方法,同时给出实现文档分类和类型匹配的若干算法,最后介绍文本分类正确率评价指标以及网络文本数据检索系统应用实证测评分析.
Classification Technology and Implementation Method for Web-based Text Data [J].https://doi.org/10.3969/j.issn.1000-0135.2002.01.005 URL [本文引用: 1] 摘要
本文主要论述网络文本数据挖掘中的文本分类技术原理、方法,同时给出实现文档分类和类型匹配的若干算法,最后介绍文本分类正确率评价指标以及网络文本数据检索系统应用实证测评分析.
|

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}