邓三鸿, 傅余洋子 , 王昊
, 王昊
Deng Sanhong, Fu Yuyangzi, Wang Hao
中图分类号: TP391
通讯作者:
收稿日期: 2017-05-27
修回日期: 2017-07-3
网络出版日期: 2017-07-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】利用LSTM模型和字嵌入的方法构建分类系统, 提出一种中文图书分类中多标签分类的解决方案。【方法】引入深度学习算法, 利用字嵌入方法和LSTM模型构建分类系统, 对题名、主题词等字段组成的字符串进行学习以训练模型, 并采用构建多个二元分类器的方法解决多标签分类问题, 选择3所高校5个类别的书目数据进行实验。【结果】从整体准确率、各类别精度、召回率、F1值多个指标进行分析, 本文提出的模型均有良好表现, 有较强的实际应用价值。【局限】数据仅涉及中图分类法5个类别, 考虑的分类粒度较粗等。【结论】基于LSTM模型的中文图书分类系统具有预处理简单、增量学习、可迁移性高等优点, 具备可行性和实用性。
关键词:
Abstract
[Objective] This paper proposes a new method to automatically cataloguing Chinese books based on LSTM model, aiming to solve the issues facing single or multi-label classification. [Methods] First, we introduced deep learning algorithms to construct a new classification system with character embedding technique. Then, we trained the LSTM model with strings consisting of titles and keywords. Finally, we constructed multiple binary classifiers, which were examined with bibliographic data from three universities. [Results] The proposed model performed well and had practical value. [Limitations] We only analyzed five categories of Chinese bibliographies, and the granularity of classification was coarse. [Conclusions] The proposed Chinese book classification system based on LSTM model could preprocess data and learn incrementally, which could be transferred to other fields.
Keywords:
近年来, 信息技术飞速发展, 人类已经进入了大数据时代。而这一变化也蔓延到图书情报领域, 其典型现象之一就是数字图书馆的发展。数字图书馆利用现代化的数字信息技术,特别是互联网技术, 延伸传统图书馆的职能, 从而更好地组织和传递文献信息。简而言之, 数字图书馆以现实资源的共享为目标[1]。数字图书馆的建设是当前图书馆建设的主要发展方向, 对人们的学习和生活有重要的现实意义。
实现图书自动分类是数字图书馆建设的重要一环。当前, 图书数量激增, 图书涉及到的领域知识越来越宽泛, 人工完成图书分类显得力不从心。因此, 将计算机自动化技术引入到图书分类领域, 实现图书自动分类, 已成为图书情报领域的研究热点, 能在很大程度上克服人力不足、相关人员专业知识薄弱等问题, 从而更高效准确地管理图书。
此外, 随着跨学科合作研究的不断增多和深入, 越来越多的跨领域成果涌现。与此相应, 越来越多的图书也不再局限于单个领域, 而是适用于分类法中的多个标签。若图书分类仍局限于单标签分类, 将导致图书被检索到的概率降低, 不利于图书的传播与共享。因此, 图书自动分类技术应充分考虑到多标签分类的情况, 更好地组织图书分类信息。
文本分类的研究起源于20世纪50年代末, Luhn提出了词频的概念[2], 被视为是文本分类领域开创性的研究。总体而言, 国外文本分类的研究可以概括为以下4个发展阶段[3]: 第一阶段(1958年-1964年), 研究文本分类的可行性; 第二阶段(1965年-1974年), 对文本分类进行试验性研究; 第三阶段(1975年-1989年), 对文本分类进行实用性研究; 第四阶段(1990年至今), 面向互联网的文本分类研究。
在第四阶段之前, 文本分类主要采用基于知识工程的方法, 即由领域专家根据经验归纳出一系列的逻辑规则, 以此作为计算机对文本进行分类时的依据。然而, 这种方法的缺点很明显: 分类的质量依赖于领域专家的水平, 人力成本极高; 规则不具备扩展能力, 不同领域的规则需要不同领域的专家, 且随着各领域的不断发展, 规则需要实时更新。20世纪90年代以来, 一方面, 随着信息时代的到来, 依赖于人力的、基于知识工程的分类方法难以满足海量的、多样的文本信息; 另一方面, 人工智能技术快速发展, 众多的学者将机器学习技术迁移到文本分类领域, 文本分类开始向基于机器学习的分类系统转移。这类方法通过选择某些特征对文本进行形式化表示, 设计并训练分类器对其进行分类, 大大降低了人力成本, 且具有更高的准确度和稳定性, 因此逐渐成为文本分类领域的主流方法。目前, 已有许多机器学习算法被应用到文本分类领域, 如朴素贝叶斯分类法[4]、k-最近邻分类法[5]、支持向量机分类法[6]、神经网络分类法[7]等。
目前, 文本分类技术取得了大量研究成果, 也得到一定的应用。然而, 其仍然面临着数据偏斜、非线性、多标签、标注瓶颈等问题[8]。其中多标签分类, 指的是一个文本与不止一个类别相关联。在实际任务中, 常常会出现多标签分类的情况。一般而言, 对多标签分类问题的研究主要从以下三个角度出发[9]。
(1) 假设类别相互独立, 在此前提下, 最简单、最常用的方法为将多标签分类问题转换为多个二元分类问题, 综合各二元分类的结果作为最终分类结果。如Joachims利用支持向量机算法实现了这种分类方法[10]。此外, 还有基于排序的方法, 在训练时学习得到一个排序函数, 据此对文本和类别的匹配情况进行打分, 将文本划分到分值高的类别。如Crammer等通过计算出每个类别的权重向量, 进而计算文本特征向量与类别权重向量的内积, 排序决定所属类别[11]。该类方法大多简单易行, 且有大量高效算法可以直接利用, 但对于类别间有关联的情况难以获得很好的性能。
(2) 考虑类别间的关联。一般通过构建主题模型解决多标签分类问题。如Ueda等提出一种产生式体系, 包含任意两个类别间的关系[12]; Zhang等提出双层主题分类模型, 基于实例间的差异构建模型[13]。
(3) 利用半监督学习算法对未标记文本进行学习。这类方法综合考虑了同类别文本间的关系和不同类别文本间的关系。如Liu等通过求解带约束的非负矩阵获得最优的样本标签[14]。这类方法能有效地利用类别间的关系, 但是学习过程较为复杂。总体而言, 多标签分类问题比单标签分类问题更为复杂。
图书分类是文本分类的子领域, 其理论基础与技术方法和文本分类相类似。然而, 专门针对图书分类问题的研究相对较少, 针对中文图书分类问题的研究则更少, 且大多数处于试验阶段, 尚未投入到实际应用之中。本文尝试将近年来发展迅速的深度学习算法引入中文图书自动分类领域, 基于LSTM模型和字嵌入的方法构建分类系统, 克服了手工分类中人力要求高、效率低、主观性强等问题, 以及传统自动分类中预处理复杂、维护困难、可迁移性低等问题。
长短时间记忆神经网络(Long Short Term Memory Neural Network, LSTM)最早是由Hochreiter等提出[15], 是一种基于时间序列的链式结构。Gers等在原始模型的基础上加入了遗忘门[16], 这是LSTM模型的一个重要改进。近年来, Graves对LSTM模型进一步的改良和推广[17], 从而使其进入蓬勃发展时期。本文使用的LSTM模型为当前业界公认的基本LSTM模型[18]。
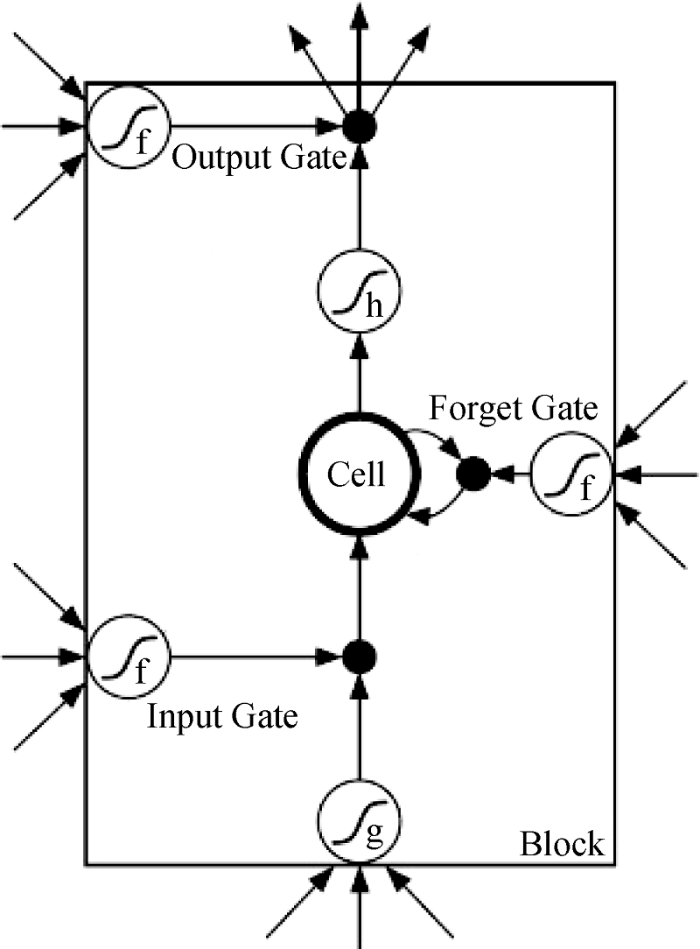
LSTM模型是循环神经网络(Recurrent Neural Network, RNN)的一种, 针对RNN模型存在的梯度消失问题[19-20]而提出改进, 用一个记忆单元替换原来RNN模型中的隐层节点。这个记忆单元的结构如图1所示[17-18], 由记忆细胞、遗忘门、输入门、输出门组成。记忆细胞负责存储历史信息, 通过一个状态参数来记录和更新历史信息; 三个门结构则通过Sigmoid函数决定信息的取舍, 从而作用于记忆细胞。
具体而言, LSTM模型主要涉及到以下计算过程,如公式(1)-公式(6)所示。
${{f}_{t}}=\sigma ({{W}_{f}}\cdot [{{h}_{t-1}},{{x}_{t}}]+{{b}_{f}})$ (1)
${{i}_{t}}=\sigma ({{W}_{i}}\cdot [{{h}_{t-1}},{{x}_{t}}]+{{b}_{i}})$ (2)
${{o}_{t}}=\sigma ({{W}_{o}}\cdot [{{h}_{t-1}},{{x}_{t}}]+{{b}_{o}})$ (3)
${{\tilde{C}}_{t}}=\tanh ({{W}_{C}}\cdot [{{h}_{t-1}},{{x}_{t}}]+{{b}_{C}})$ (4)
${{C}_{t}}={{f}_{t}}\times {{C}_{t-1}}+{{i}_{t}}\times {{\tilde{C}}_{t}}$ (5)
${{h}_{t}}={{O}_{t}}\times \tanh ({{C}_{t}})$ (6)
公式(1)-公式(3)分别是遗忘门、输入门、输出门的计算公式。在t时刻, 门结构接受上一时刻记忆单元的输出${{h}_{t-1}}$和当前时刻记忆单元的输入xt, 与各自的权重矩阵相乘, 然后加上偏置向量, 通过Sigmoid函数产生一个0到1之间的值, 对信息进行筛选。公式(4)-公式(5)是对Cell状态进行更新。公式(4)通过tanh函数对上一时刻记忆单元的输出${{h}_{t-1}}$和当前时刻记忆单元的输入xt进行计算, 得出一个候选值, 并由输入门决定将候选值的哪些信息更新到Cell状态中。同时, 由遗忘门决定上一时刻Cell状态信息的保留情况, 与更新的信息相加, 得到当前时刻的Cell状态。公式(6)计算记忆单元最终的输出。通过tanh函数对当前时刻的Cell状态进行计算, 使模型变为非线性的, 并由输出门决定哪些信息将被最终输出。
可以看出, LSTM模型采用累加的线性形式处理序列数据的信息, 从而避免了梯度消失问题, 也能学到长周期的信息[21], 克服了RNN模型的缺点。因此, LSTM模型是处理时间序列数据常用的深度学习模型。
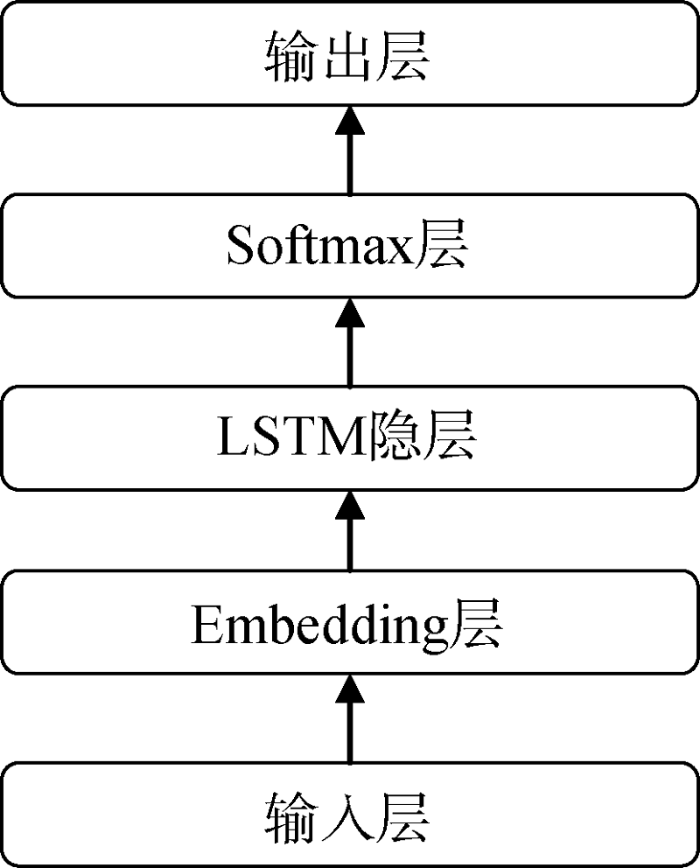
本文以LSTM模型为基础对中文图书分类系统进行设计, 系统的整体架构如图2所示。系统共分为5个部分: 输入层、Embedding层、LSTM隐层、Softmax层、输出层。
整体架构中的第三部分即为本文重点采用的LSTM模型。在该部分, LSTM隐层对之前部分处理得到的序列数据进行学习, 利用LSTM模型的特性结合上下文信息, 学习到的结果将传递给之后的部分, 以进行分类预测。
除LSTM隐层外, 第二部分Embedding层也是系统的重要组成部分。输入层将待分类文本统一为同等长度, 并传递给Embedding层; Embedding层采用字嵌入的方法, 将传递来的文本中的每个字符转换为一个向量, 从而将待分类文本转换为二维向量, 传递给后续部分继续处理。字嵌入方法是在词嵌入方法的基础上提出的, 而词嵌入方法则起源于Hinton提出的分布式表征的思想[22]。词嵌入将词表示为一个低维稠密向量, 从而解决了维度灾难问题; 并且可以通过余弦距离、欧式距离等方法计算词之间的相似度, 从而克服了One-hot表示法这一类词表示方法无法反映词之间关系的问题。然而, 完美的分词算法是不存在的[23], 故字嵌入的方法被提出。字嵌入将字符转换为低维稠密向量, 继承了词嵌入的优点, 同时避免了分词可能出现的问题。本文系统采用字嵌入的方法, 使得整个系统是基于字符的, 而不是基于特征词的, 从而降低了系统的维护难度, 不需要维护特征集合, 也不需要在新特征加入后重新训练模型, 而是可以采用增量学习的方法; 此外, 系统也可以方便地迁移到其他语言, 提高了系统的应用价值。
Softmax层用到了Softmax回归模型, 对LSTM隐层传递来的信息进行学习, 计算出待分类数据归属各类别的概率, 传递给输出层, 最终给出待分类文本的预测类别。Softmax回归模型是Logistic回归模型的一般化形式, 是常用的多分类算法。Softmax回归模型拥有很好的数学性质[24]; 并且, 其不仅能预测出对应的类别, 还能计算出归属各类别的概率, 方便更进一步的处理。该层也是损失函数的构建依据, 系统整体采用Adam算法[25]进行优化。
实验数据为南京大学、同济大学、中国科学技术大学这三所高校的图书馆馆藏书目。这三所高校的图书馆书目检索系统均由江苏汇文软件有限公司[26]构建, 具有基本一致的体系和格式, 便于数据的获取和整理。使用Python语言[27]编写网络爬虫, 分别从三所高校的图书馆书目检索系统爬取书目信息, 并根据每条书目的机读格式(Machine Readable Catalog, MARC)获取特定字段的信息。主要抓取的字段及其含义如表1所示。
针对《中国图书馆分类法》中的第一层分类进行实验。考虑到书目数量、实验规模等因素, 没有将全部22个大类都纳入到实验中, 而是选择A(马克思列宁主义、毛泽东思想、邓小平理论)、C(社会科学总论)、F(经济)、N(自然科学总论)、X(环境科学、安全科学)这5个大类的书目为实验数据, 涵盖了社会科学、自然科学等多个方面, 具有一定的代表性。
本文从单标签分类、多标签分类两个角度进行实验。单标签分类指每个样本只属于一个特定的类别; 而多标签分类指每个样本更倾向于属于多个类别[28]。利用单标签分类实验验证系统的可行性, 再探索系统在多标签分类上的实用性。
实验环境为: CPU Intel Core i7-6700HQ, 四核; 内存16GB; GPU NVIDIA GeForce GTX950M; 显存4GB; 操作系统为64位Ubuntu 16.04 LTS。
对单标签图书分类进行实验探索, 即针对数据集中所有单标签条目进行分类实验。对数据进行合并、去重、去除多标签条目等操作, 最终获得如表2所示的数据分布。根据类型抽样法将数据按80%、10%、10%的比例划分为训练集、验证集、测试集, 本节实验即在此数据集上进行。
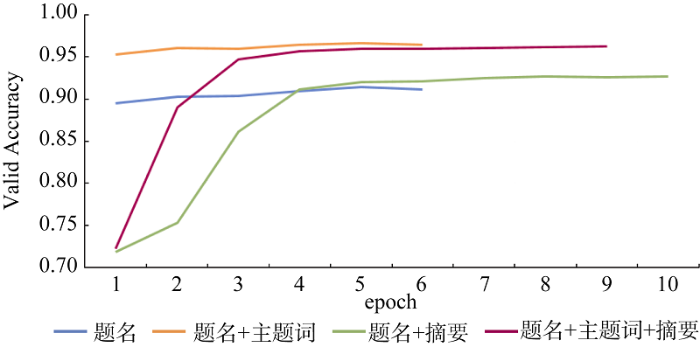
考虑到不同的字段对书目内容的表达能力和涵盖情况不同, 将探讨只选择题名字段、选择题名和主题词字段、选择题名和摘要字段、选择题名和主题词以及摘要字段这4种情况下的模型分类效果。选择基本单向LSTM模型; 1层LSTM隐层, 每层隐层包含128个节点; 每批处理的数据量为128; 训练过程采用早停原则, 当模型在验证集上的损失值增大时则停止训练, 且对整个训练集至多训练1 000轮, 训练情况如图3所示。
图3反映了每训练完一遍整个训练集后的模型在验证集上的准确率变化趋势。观察只选择题名字段的模型与选择题名和主题词字段的模型, 这两者在验证集上的准确率在训练初期便迅速趋于平稳。这是由于题名和主题词字段的字符数相对较少, 模型学习到稳定状态的速度相对较快。从收敛情况来看, 包含主题词字段的两个模型最终的准确率更高且相近, 可见主题词字段对训练更优的模型有较大帮助。
当选择题名和主题词字段时, 浅层的、单向的、基本LSTM模型在测试集上的分类准确率达到97%左右, 在具体类别上的F1值均高于90%, 处于较高水平。因此, 综合实验情况、模型简单性、字段普遍性等因素, 认为选择题名和主题词字段即可达到较好的分类效果, 也具有可行性, 后续的实验将基于这两个字段进行。
文献[29]同样对A、C、F、N、X等5大类进行实验, 准确率为95.94%, 处于当前研究中的较高水平。本文则取得96.97%的准确率, 优于前人研究, 证明本文系统确实具有可行性和应用价值。
对多标签图书分类进行实验探索, 即针对数据集中所有条目进行分类实验, 包括单标签条目和多标签条目。选择题名和主题词字段, 对数据进行合并、去重的操作, 最终获得如表3所示的数据分布。采用类型抽样法按80%、20%的比例将数据集划分为训练集和测试集, 本节实验即在此数据集上进行。
表3 多标签图书分类实验的数据分布
| 类标号 | 书目数 | 类标号 | 书目数 |
|---|---|---|---|
| A | 8 101 | A、X | 5 |
| C | 25 595 | C、F | 1 217 |
| F | 133 401 | C、N | 69 |
| N | 6 461 | C、X | 50 |
| X | 15 642 | F、N | 49 |
| A、C | 38 | F、X | 684 |
| A、F | 111 | N、X | 21 |
| A、N | 4 | C、F、X | 3 |
| 总计 | 191 451 |
从表3可以看到, 数据集中多标签的书目较少, 只占数据总量的1.18%。如果将多标签组合作为一个单独类别, 采用单标签分类的方法进行分析。一方面, 其对应的书目数量太少, 难以学习到有效信息, 或者存在过拟合风险; 另一方面, 只选择5个大类, 若将全部类别都纳入考虑, 则组合的数量将非常庞大, 会给模型的训练带来难度。因此, 将多标签组合作为一个单独类别是不具备可行性的, 而因采取多标签分类的分析方法。对于《中国图书馆分类法》中同层次的类别而言, 各类别之间是相对独立的, 类别间没有什么关联。因此, 本文将多标签分类问题转换为多个二元分类问题, 即针对每个类别分别构建一个二元分类器, 用于判断书目是否属于该类别。将训练集中所有属于该类别的数据标记为正类别, 包括多标签的情况, 而不属于该类别的数据标记为负类别, 以此构建模型。
在单标签图书分类实验中, 所有类的地位是一样的, 即所有类的权重相同, 在损失函数里的系数相同。而在本节实验中, 一方面, 大多数分类器的训练集存在类别不平衡的情况, 正类别数据远远少于负类别; 另一方面, 实验目标在于尽量预测出所属的所有类别, 故正类别的重要程度高于负类别, 即正类别的误差成本应高于负类别。因此, 笔者对类的权重进行调整, 正类别与负类别的权重比为15:1, 损失函数中的对应系数据此进行调整。
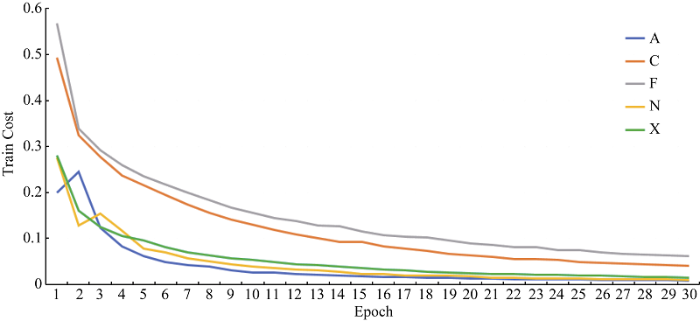
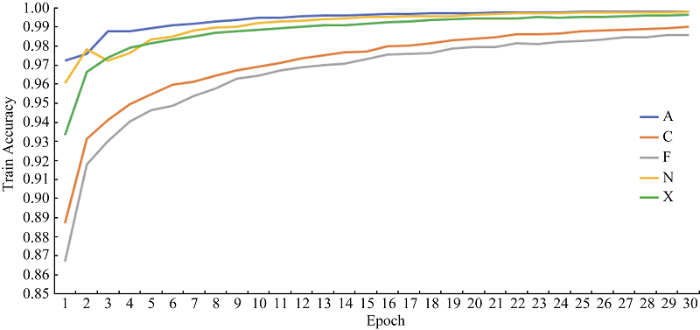
笔者采用基本单向LSTM模型; 2层LSTM隐层, 每层隐层包含128个节点; 每批处理的数据量为128; 模型分别对各自的训练数据迭代学习30轮。训练情况如图4和图5所示。
可以发现两图反映出的信息是相符的, 当训练到15轮左右时, 各二元分类器在训练集上的损失和准确率都开始趋于平稳。结合各二元分类器对应的训练集来看, 训练集包含的条目越少, 其对应的二元分类器越快趋向于收敛, 且停止训练时的损失值越低、准确率越高。由此可知, 当训练集较大时, 应适当增加训练的轮数以提升分类器的性能。
训练结束后, 各二元分类器分别对测试集进行分类测试, 并统计各类别的精度、召回率和F1值。统计过程中, 包含所有属于某一类别的数据, 包含单标签和多标签的情况, 统计结果如表4所示。可以看到, 15个指标数据基本都在85%以上, 其中三分之二的指标数据在90%以上。由此可见, 各二元分类器的表现尚可, 有一定的实际应用价值。
表4 各类别的二元分类器在测试集上的测试情况表
| 类标号 | 精度 | 召回率 | F1值 |
|---|---|---|---|
| A | 91.23% | 94.32% | 92.75% |
| C | 85.47% | 93.61% | 89.35% |
| F | 95.85% | 98.56% | 97.19% |
| N | 83.43% | 90.17% | 86.67% |
| X | 88.88% | 96.13% | 92.36% |
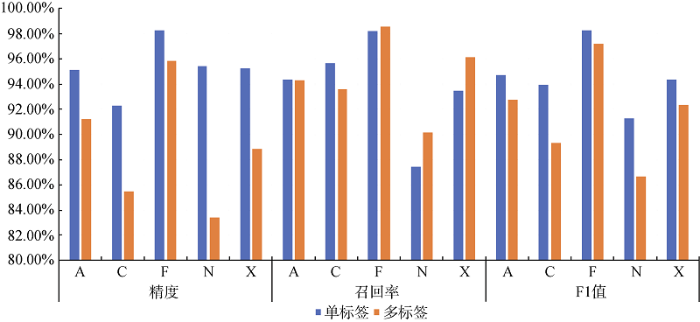
将各二元分类器在测试集上的指标数据与单标签分类实验进行对比, 对比结果如图6所示。由于对类别权重进行调整, 正类别的权重高于负类别, 故对召回率的提升有促进作用。由图6可以发现, 与单标签分类实验相比, 召回率大多保持稳定或有所提升。但是, 由于精度与召回率这两个指标相对矛盾, 故精度显著下降。从F1值这一综合评价指标来看, 分类表现在整体上略逊于单标签分类实验, 但相差不大, 仍处于较高水平。
针对测试集的分类结果, 统计其中多标签条目的实际预测情况, 统计结果如表5所示。
表5 测试集中多标签条目的实际预测情况统计表
| 多标 签项 | 实际 存在数 | 预测情况 | ||
|---|---|---|---|---|
| 包含至少一 个实际类别 | 包含全部 实际类别 | 恰好等于 实际类别 | ||
| A、C | 8 | 7 | 4 | 4 |
| A、F | 23 | 23 | 16 | 16 |
| A、N | 1 | 1 | 0 | 0 |
| A、X | 1 | 1 | 1 | 1 |
| C、F | 244 | 242 | 140 | 140 |
| C、N | 14 | 14 | 7 | 7 |
| C、X | 10 | 10 | 5 | 3 |
| F、N | 10 | 10 | 2 | 2 |
| F、X | 137 | 136 | 100 | 100 |
| N、X | 5 | 5 | 2 | 2 |
| C、F、X | 1 | 1 | 1 | 1 |
| 总计 | 454 | 450 | 278 | 276 |
可以发现, 99.12%的多标签数据都至少预测出其中一个实际类别, 61.23%的多标签数据预测出全部实际类别, 60.79%的多标签数据恰好预测出了实际分类。同时, 多标签项对应的实际数据越多, 其被系统学习的情况越好, 越有可能被全部预测出, 反之则会导致偶尔性。由此可知, 当增加更多多标签条目时, 系统能获得更好的表现。此外, 对整个测试集的预测情况进行统计分析, 有97.62%的数据至少被预测出一个实际分类, 97.17%的数据的预测分类包含了全部实际分类, 而91.92%的数据被恰好完全预测正确。整体而言, 系统在测试集上表现较好。
综上可知, 对于多标签分类的中文图书分类任务, 针对每个类别构建一个二元分类器, 然后每个分类器采用浅层的、单向的、基于题名与主题词字段的、基本LSTM模型, 这样的方法可以取得较好的分类表现, 对单标签和多标签分类均有一定的实践意义。
本文将LSTM模型引入到中文图书分类问题中, 与以往研究中的基于知识工程或基于传统机器学习的中文图书分类方法相比, 本文系统具有如下优势。
(1) 预处理工作和后期维护工作简单。本文采用字嵌入方法, 整个系统是基于字符序列构建的, 故不需要分词、特征选择等过程。当出现新知识、新研究时, 可以实现增量学习, 无需重新训练模型。
(2) 充分利用LSTM模型的特点, 递归神经网络适合处理序列数据。本文系统是对各字段直接连接而成的字符序列进行学习, 一方面, 避免了特征选择等过程中可能会误删重要信息等情况, 对所有信息都进行学习; 另一方面, 相比于词袋模型未考虑词序等问题, LSTM模型在处理序列数据时考虑了上下文信息, 能更好地理解文本。
(3) 实验证明, 无论是单标签图书分类, 还是多标签图书分类, 本文系统均有较好的表现。无论是整体的分类准确率, 还是各类别的分类精度、召回率、F1值, 都达到了较高水平, 有实际应用价值。
当然, 本文研究也存在一些不足和改进空间, 如测试环节未将全部类别纳入系统、分类粒度较粗等, 这些将是笔者进一步的研究方向, 以不断完善中文图书分类系统。
邓三鸿, 傅余洋子, 王昊: 提出研究思路, 设计研究方案;
傅余洋子: 设计模型, 进行实验, 分析数据, 起草论文;
邓三鸿: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: mg1414011@smail.nju.edu.cn。
[1] 傅余洋子. 单标签分类实验数据.zip. 单标签图书分类实验数据集.
[2] 傅余洋子. 多标签分类实验数据.zip. 多标签图书分类实验数据集.
| [1] |
也谈数字图书馆的建设目标 [J].https://doi.org/10.3969/j.issn.1008-0821.2002.12.072 URL [本文引用: 1] 摘要
近年来,我国兴起了数字图书馆建设的热潮,对数字图书馆的研究也不断深入,然而对于数字图书馆的内涵,为什么要建数字图书馆等问题,还存在不少分歧。本文试从全国的角度探讨中国数字图书馆的建设目标,并提出几点建议。
Talking About the Construction Target of Digital Library [J].https://doi.org/10.3969/j.issn.1008-0821.2002.12.072 URL [本文引用: 1] 摘要
近年来,我国兴起了数字图书馆建设的热潮,对数字图书馆的研究也不断深入,然而对于数字图书馆的内涵,为什么要建数字图书馆等问题,还存在不少分歧。本文试从全国的角度探讨中国数字图书馆的建设目标,并提出几点建议。
|
| [2] |
Auto-encoding of Documents for Information Retrieval Systems [M]. |
| [3] |
WWW科技信息资源自动标引的理论与实践研究 [D].Study on the Theory and Practice of Automatic Indexing of WWW Science and Technology Information Resources [D]. |
| [4] |
A Comparison of Two Learning Algorithms for Text Categorization [C]// |
| [5] |
An Example-based Mapping Method for Text Categorization and Retrieval [J].https://doi.org/10.1145/183422.183424 URL [本文引用: 1] 摘要
A unified model for text categorization and text retrieval is introduced. We use a training set of manually categorized documents to learn word-category associations, and use these associations to predict the categories of arbitrary documents. Similarly, we use a training set of queries and their related documents to obtain empirical associations between query words and indexing terms of documents, and use these associations to predict the related documents of arbitrary queries. A Linear Least Squares Fit (LLSF) technique is employed to estimate the likelihood of these associations. Document collections from the MEDLINE database and Mayo patient records are used for studies on the effectiveness of our approach, and on how much the effectiveness depends on the choices of training data, indexing language, word-weighting scheme, and morphological canonicalization. Alternative methods are also tested on these data collections for comparison. It is evident that the LLSF approach uses the relevance information effectively within human decisions of categorization and retrieval, and achieves a semantic mapping of free texts to their representations in an indexing language. Such a semantic mapping lead to a significant improvement in categorization and retrieval, compared to alternative approaches.
|
| [6] |
基于机器学习的自动文本分类模型研究 [J].https://doi.org/10.3969/j.issn.1003-3513.2005.10.006 URL [本文引用: 1] 摘要
基于机器学习的方法是自动文本分类中非常重要的一大类方法.本文先给出了形式化的定义,提出 了自动文本分类的流程模型,然后选取了支持向量机(Support Vector Machine,SVM)算法作为一个典型例子进行分析,最后作者通过一个中文文本分类实验评价了该算法的效果.
Study on Machine Learning Based Automatic Text Categorization Model [J].https://doi.org/10.3969/j.issn.1003-3513.2005.10.006 URL [本文引用: 1] 摘要
基于机器学习的方法是自动文本分类中非常重要的一大类方法.本文先给出了形式化的定义,提出 了自动文本分类的流程模型,然后选取了支持向量机(Support Vector Machine,SVM)算法作为一个典型例子进行分析,最后作者通过一个中文文本分类实验评价了该算法的效果.
|
| [7] |
Exploiting Hierarchy in Text Categorization [J].https://doi.org/10.1023/A:1009983522080 URL [本文引用: 1] 摘要
With the recent dramatic increase in electronic access to documents, text categorization—the task of assigning topics to a given document—has moved to the center of the information sciences and knowledge management. This article uses the structure that is present in the semantic space of topics in order to improve performance in text categorization: according to their meaning, topics can be grouped together into “meta-topics”, e.g., gold, silver, and copper are all metals. The proposed architecture matches the hierarchical structure of the topic space, as opposed to a flat model that ignores the structure. It accommodates both single and multiple topic assignments for each document. Its probabilistic interpretation allows its predictions to be combined in a principled way with information from other sources. The first level of the architecture predicts the probabilities of the meta-topic groups. This allows the individual models for each topic on the second level to focus on finer discriminations within the group. Evaluating the performance of a two-level implementation on the Reuters-22173 testbed of newswire articles shows the most significant improvement for rare classes.
|
| [8] |
基于机器学习的文本分类技术研究进展 [J].
文本自动分类是信息检索与数据挖掘领域的研究热点与核心技术,近年来得到了广泛的关注和快速的发展.提出了基于机器学习的文本分类技术所面临的互联网内容信息处理等复杂应用的挑战,从模型、算法和评测等方面对其研究进展进行综述评论.认为非线性、数据集偏斜、标注瓶颈、多层分类、算法的扩展性及Web页分类等问题是目前文本分类研究的关键问题,并讨论了这些问题可能采取的方法.最后对研究的方向进行了展望.
Advances in Machine Learning Based Text Categorization [J].
文本自动分类是信息检索与数据挖掘领域的研究热点与核心技术,近年来得到了广泛的关注和快速的发展.提出了基于机器学习的文本分类技术所面临的互联网内容信息处理等复杂应用的挑战,从模型、算法和评测等方面对其研究进展进行综述评论.认为非线性、数据集偏斜、标注瓶颈、多层分类、算法的扩展性及Web页分类等问题是目前文本分类研究的关键问题,并讨论了这些问题可能采取的方法.最后对研究的方向进行了展望.
|
| [9] |
基于频繁项集的多标签文本分类算法 [J].
针对多标签文本分类问题,提出基于频繁项集的多标签文本分类算法——MLFI。该算法利用FP-growth算法挖掘类别之间的频繁项集,同时为每个类计算类标准向量和相似度阈值,如果文本与类标准向量的相似度大于相应阈值则归到相应的类别,在分类结束后利用挖掘到的类别之间的关联规则对分类结果进行校验。实验结果表明,该算法有较高的分类性能。
Multi-label Text Classification Algorithm Based on Frequent Item Sets [J].
针对多标签文本分类问题,提出基于频繁项集的多标签文本分类算法——MLFI。该算法利用FP-growth算法挖掘类别之间的频繁项集,同时为每个类计算类标准向量和相似度阈值,如果文本与类标准向量的相似度大于相应阈值则归到相应的类别,在分类结束后利用挖掘到的类别之间的关联规则对分类结果进行校验。实验结果表明,该算法有较高的分类性能。
|
| [10] |
Text Categorization with Support Vector Machines: Learning with Many Relevant Features[A]// Machine Learning: ECML-98 [M]. |
| [11] |
A New Family of Online Algorithms for Category Ranking [C]// |
| [12] |
|
| [13] |
Multi-Label Learning by Instance Differentiation [C]// |
| [14] |
Semi-supervised Multi-label Learning by Constrained Non-negative Matrix Factorization [C]// |
| [15] |
Long Short-term Memory [J].https://doi.org/10.1162/neco.1997.9.8.1735 URL [本文引用: 1] |
| [16] |
Learning to Forget: Continual Prediction with LSTM [J].https://doi.org/10.1162/089976600300015015 URL [本文引用: 1] |
| [17] |
Supervised Sequence Labelling with Recurrent Neural Networks [D]. |
| [18] |
|
| [19] |
Recurrent Neural Net Learning and Vanishing Gradient [J].https://doi.org/10.1142/S0218488598000094 URL [本文引用: 1] 摘要
Recurrent nets are in principle capable to store past inputs to produce the currently desired output. Because of this property recurrent nets are used in time series prediction and process control. Practical applications involve temporal dependencies spanning many time steps, e.g. between relevant inputs and desired outputs. In this case, however, gradient based learning methods take too much time. The extremely increased learning time arises because the error vanishes as it gets propagated back. In this article the de-caying error flow is theoretically analyzed. Then methods trying to overcome vanishing gradients are briefly discussed. Finally, experiments comparing conventional algorithms and alternative methods are presented. With advanced methods long time lag problems can be solved in reasonable time.
|
| [20] |
|
| [21] |
|
| [22] |
Learning Distributed Representations of Concepts [C]// |
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
HUIWEN Software [EB/OL]. [ |
| [27] |
|
| [28] |
多标签数据挖掘技术: 研究综述 [J].https://doi.org/10.3969/j.issn.1002-137X.2013.04.003 URL [本文引用: 1] 摘要
传统的单标签数据挖掘技术研究对象中,每个样本仅属于一个类别标签,但在实际应用中一个样本更倾向于同时具备多个属性,即属于多标签数据类型。多标签数据挖掘技术现已成为数据挖掘技术中的一个研究热点。其研究成果广泛地应用于各种不同的领域,如图像视频的语义标注、功能基因组、音乐情感分类以及营销指导等。从多标签数据挖掘的方法和度量方式两个方面对多标签数据挖掘进行了系统详细的阐述,最后归纳了目前研究中存在的问题和挑战并展望了本领域的发展趋势。
Multi-label Data Mining: A Survey [J].https://doi.org/10.3969/j.issn.1002-137X.2013.04.003 URL [本文引用: 1] 摘要
传统的单标签数据挖掘技术研究对象中,每个样本仅属于一个类别标签,但在实际应用中一个样本更倾向于同时具备多个属性,即属于多标签数据类型。多标签数据挖掘技术现已成为数据挖掘技术中的一个研究热点。其研究成果广泛地应用于各种不同的领域,如图像视频的语义标注、功能基因组、音乐情感分类以及营销指导等。从多标签数据挖掘的方法和度量方式两个方面对多标签数据挖掘进行了系统详细的阐述,最后归纳了目前研究中存在的问题和挑战并展望了本领域的发展趋势。
|
| [29] |
基于机器学习的中文书目自动分类研究 [J].
Research on Automatic Classification for Chinese Bibliography Based on Machine Learning [J].
|

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}