李真, 丁晟春 , 王楠
, 王楠
南京理工大学信息管理系 南京 210094
Li Zhen, Ding Shengchun, Wang Nan
中图分类号: TP391 G350
通讯作者:
收稿日期: 2017-05-31
修回日期: 2017-07-16
网络出版日期: 2017-08-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】识别网络舆情中的观点主题。【方法】通过舆情信息内容、用户关系、用户行为三个方面的4个维度(时间维、用户维、内容维、观点维)的关联, 构建微博舆情观点主题识别模型。【结果】提出包括舆情网络构建、观点主题抽取及聚类、“用户-所属观点主题” 2-模网络构建、观点主题演化分析4部分的网络舆情观点主题识别方法体系, 实验结果证明该方法体系可有效识别网络舆情中的观点主题。【局限】用户属性对观点主题识别的影响有待进一步考虑。【结论】基于社会网络视角, 利用LDA主题模型, 可多方面、多维度地识别网络舆情观点主题。
关键词:
Abstract
[Objective] This paper aims to identify the topics of online public opinion. [Methods] We constructed a model to extract public opinion based on the information content of the Weibo posts, the relationship among the users, and user behaviors. [Results] We built a public opinion network, extracted and clustered relevant topics, constructed a two-mode network of “user-topic” and evolution of the opinion topics. The proposed method could identify topics of online public opinion effectively. [Limitations] The influence of users’ attributes on topic identification needed to be investigated. [Conclusions] We could identify the topics of online public opinion based on the social network analysis with the help of LDA model.
Keywords:
自媒体平台在给人们提供共享、交流新方式的同时, 也使得由网络引起、放大或主导的社会舆情事件频发。由于互联网具有信息发布及时、传播速度快、影响范围广等特性, 导致舆情事件一旦在互联网上爆发将呈不可逆转的趋势。此外, 网络的开放性和隐蔽性为网民提供了观点表达的场所, 观点是人们对某个事物或事件所产生的带有情感倾向性的看法或态度。面对海量的网络舆情观点信息, 政府和企业要想及时做好网络舆情引导工作, 就必须快速把握网络舆情参与主体当下所持有的主要观点。本文将网民主体在舆情事件中所处立场, 或者所形成的对舆情事件/问题的主要看法称为网络舆情观点主题, 而从大规模网络舆情信息中获取观点主题, 并进行展示的一系列技术方法就称作观点主题识别。
现有研究多是根据网络舆情发展结果进行滞后性的动因分析、回溯分析、演化分析, 处理方式处于被动的问题解决状态, 不能满足政府和企业应急管理中实时监测舆情动态的现实要求。此外, 用户在微博、贴吧等自媒体网络平台上发布的信息具有数据类型多样化、文本内容碎片化与不完备等特性, 使得传统的舆情事件研究方法不能满足现有网络舆情分析的需要。因此网络舆情的研究方法需要得到进一步的创新, 在文本内容处理的基础上, 重视用户行为、用户关系等社会化特征数据, 多维度地挖掘网络舆情中的主题。
基于此, 本文基于社会网络视角, 利用LDA主题模型, 引入时间变量, 提出一种动态识别网络舆情参与主体所持观点主题变化情况的模型, 以期为政府和企业的网络舆情监测和引导提供理论支持, 满足关键舆情事前跟踪和事中实时发现的需求。
目前有关网络舆情主题识别的研究呈现出较为迅速的递增趋势, 由于网络舆情传播途径的多样性, 研究者除针对不同类型的网络舆情信息开展主题识别研究外, 还基于主题特征的差异性, 针对不同类型的主题展开研究。
国外关于网络舆情主题识别的研究起步较早, 采用的主题识别研究方法也更为多样。Wu等利用TF-IDF算法、Text-Rank算法, 提取微博关键词, 标注用户兴趣爱好, 以挖掘用户兴趣及关注热点[1]。Narang等则是将TF-IDF算法与文本聚类以及WordNet局部相似性检测相结合, 发现围绕主题的社交对话[2]。Kim等使用Twitter数据进行实验, 发现词频比率能够恰当地检测社交热点话题或突发新闻[3]。Nguyen等提出一个社交软件平台, 用于从Twitter等类似的社交网络服务的信息扩散模式中检测出有意义的事件, 实现热门话题的发现[4]。Guo等利用FrequentPattern流挖掘算法实现Twitter热点主题的检测[5]。
国内对舆情主题识别的研究主要基于聚类思想, 或通过改进LDA模型, 利用单一维度的文本信息实现对网络舆情主题的挖掘。如叶川等利用LDA主题模型进行热点评论的分类推断及主题特征挖掘, 实现对微博热门评论的主题标签推断[6]。唐晓波等针对文本聚类和LDA主题模型的互补特征, 提出一种两者结合的微博主题检索模型[7]。伍万坤等对标准LDA模型进行改进, 提出一种挖掘电商微博热点话题的EM-LDA综合模型[8]。部分文本聚类方法虽然兼顾了文本内容的结构信息和语义信息, 但很难充分表达语义信息。而利用LDA主题模型实现网络舆情主题识别的研究多侧重于对LDA主题模型的改进, 仍是单一维度的主题识别。此外, 还有研究者将本体论和语义计算的相关技术引入到网络舆情事件的主题识别中[9], 同时还融入影响力计算、句法依存、社会网络分析等改进方法[10-14], 进一步完善网络舆情主题识别研究。
微博具有信息发布便捷、快速、实时等特点, 逐渐成为网络舆情爆发的主阵地, 以微博为主要研究对象的舆情主题识别研究占据了半壁江山。从微博主题识别的类型上看, 已有研究多是对微博社区主题、微博热点主题的挖掘, 少量涉及到对观点主题、潜在主题的研究。其研究方法从初始的简单聚类逐步演化到通过LDA主题模型结合词汇、句子、时间、情感等特征辅助实现对微博主题的检测, 这些研究方法多是从主题词途径来识别舆情主题, 没有综合考虑网络舆情中用户的社会信息, 以及用户行为对于舆情传播演化的影响。
观点主题识别是指从大规模的观点性评论信息中获取主题, 并进行展示的一系列技术方法的总称, 旨在从海量的评论信息中迅速获得用户对某一舆情事件或问题的主要看法和态度。对舆情观点信息的挖掘研究多倾向于观点的抽取与识别。从观点抽取的结果来看, 可将现有研究大致分为三类。
(1) 抽取舆情观点所指对象, 如周杰等提出一种领域无关的由内到外的观点主题识别算法[15], 其中观点主题是指观点所指对象, 仅能指明网民大众所评论的焦点, 并不能直观表示出网民大众对该讨论焦点所持的主要看法或态度。
(2) 按舆情观点的情感倾向进行观点的分类。丁晟春等结合心理学与自然语言处理技术, 将微博情绪分为喜、怒、哀、恶、惧5大类, 利用情感特征、句式特征及句间特征对微博情绪进行表示, 借助SVM模型形成微博情绪5类分类模型, 实现微博情绪的多类分类[16]。这种观点挖掘仅从宏观上把握网民主体的情感极性, 并不能体现观点的具体描述。
(3) 舆情观点词或观点句的识别及描述。陈晓美等运用多文档文摘技术和以句子为单位的LDA主题模型方法, 获得每个主题具有代表性的观点言论, 揭示网络舆情主要观点[17]。姚兆旭等利用LDA模型和改进的TF-IDF算法构建主题特征词向量, 基于相似度计算自动抽取主题词汇链, 在此基础上, 引入情感词典, 实现主题观点词的抽取[18]。无论是将语法语义相结合的观点识别方法, 还是将情感极性与主题信息相结合的方法, 实质上都是基于内容的观点识别, 其忽略了社交网络平台中用户行为、用户属性等社会化特征数据, 不能满足现有微博舆情观点主题识别的需要。
基于以上研究现状, 本文将在文本内容处理的基础上, 引入社会化网络分析途径, 将主题模型与社会网络分析相结合, 实现从海量评论信息中获取微博舆情参与主体的主流观点, 为政府与企业的微博舆情引导工作提供有力的理论支撑。
本文选取新浪微博为研究平台, 通过舆情信息内容、用户关系、用户行为三个方面的4个维度(时间维、用户维、内容维、观点维)的关联, 构建网络舆情观点主题识别模型。
(1) 时间维。已有研究往往选取舆情事件生命周期作为时间粒度, 即对舆情事件的潜伏期、成长期、爆发期和衰退期等各个阶段进行分析, 以实现对舆情传播过程的动态监测。本文所研究的观点主题——网民对某一事件所持观点的变化往往发生在更短的时间粒度内, 即在舆情生命周期的某一阶段内观点已发生多次变化。因此本文以“天”为时间粒度, 研究每天观点主题的变化情况。
(2) 用户维。用户是网络舆情产生的主体, 网络舆情事件正是由于用户在互联网上表达对该事件的认知、态度和意见, 并进行传播而形成的。本文对用户维度的研究侧重于用户的行为及用户间评论、点赞等关系, 具体包括三类:
①发布行为。当微博用户想要及时分享所见所闻、发表个人观点时会产生发布行为, 用户的发布行为促使个人观点的产生。
②评论行为。当微博用户对原始微博所述内容感兴趣或持有个人看法时, 会发生评论行为, 评论行为也会促使观点的产生。
③点赞行为。当微博用户对正在浏览的原始微博或评论表示赞同时会产生点赞行为, 是行为成本最低的观点表达行为。
(3) 内容维。本文所指“内容”表示的是用户发表的以微博或微博评论为载体的带有情感倾向性的文字内容, 其中, 将用户直接发布的微博内容称为“原始微博”, 将评论内容称为“评论微博”。这些带有用户情感倾向性的内容里隐含了用户的观点, 是观点的具体阐释, 即内容一定包含了用户的某一种或某几种观点。本文允许用户发表多条内容, 但假设每条内容仅包含一种观点。
(4) 观点维。观点通常是指用户对某一事件或事物所持有的看法或情感倾向, 并不是舆情事件的基本要素, 而是基于内容总结、提取得到的, 即观点是从用户发表的内容中高度概括、总结出来的。
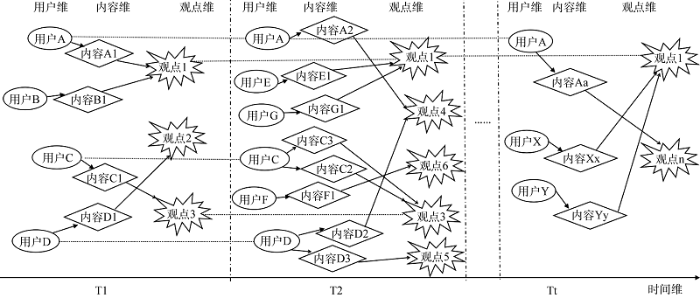
图1展示了时间、用户、内容及观点4个维度间的关系。随着时间维度的变化, 舆情事件参与主体、发表内容、所持观点及网民大众整体观点倾向都会不断发生变化。有的用户会出于兴趣等原因参与舆情事件整个生命周期过程(如用户A), 也有用户只在某一阶段参与了对该事件的讨论(如用户B)。用户在参与事件讨论的不同阶段会发表一条或几条不同的内容, 可能是发表了不同内容但表达了同一观点(如用户C发表的内容C2、C3), 也有可能是发表了不同内容且表达了多种观点(如用户D发表的内容D2、D3)。有的用户虽发表了多条内容, 但内容所含观点始终不变(如用户C始终持有观点3, 直至用户C退出此事件的讨论), 也有用户发表内容的所属观点会随时间的推移而发生变化(如用户A在T1时期发表的内容A1属于观点1, 在T2时期发表的内容A2属于观点4)。
本文不研究具体某一用户的观点变化情况, 而是研究参与事件讨论的网民整体所持观点主题的变化情况。
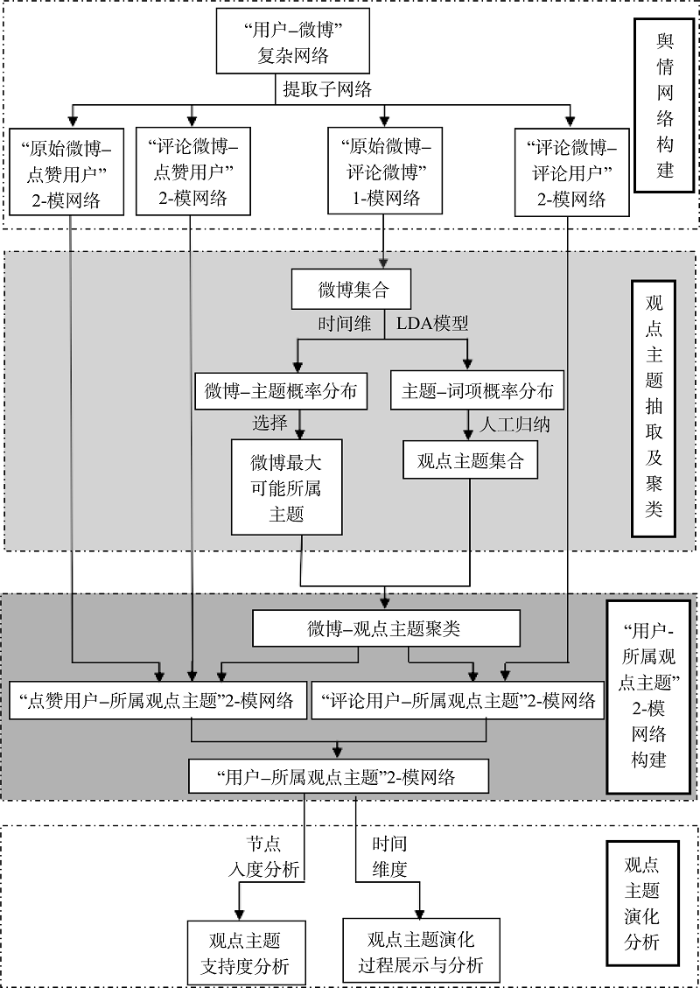
本文网络舆情观点主题识别框架包括舆情网络构建、观点主题抽取及聚类、“用户-所属观点主题”2-模网络构建、观点主题演化分析4部分, 如图2所示。
(1) 基于用户维和内容维构建“用户-微博”复杂网络, 并从该复杂网络中提取4个子网络, 其中“原始微博-评论微博”1-模网络节点构成了微博集合, 即该模型要处理的文本集合。根据3.1节中对时间维度的分析, 以“天”为时间粒度, 将待处理的文本集合离散到相应的时间窗口, 依次处理各时间窗口的文本, 并进行下一步的主题抽取。
(2) 利用LDA模型得到该微博集合的“微博-主题”概率分布和“主题-词项”概率分布。依据“主题-词项”概率分布, 将各主题下的词项进行人工归纳得到各主题所代表的观点, 即本文所研究的观点主题, 形成观点主题集合, 完成对微博舆情观点主题的抽取; 同时, 根据“微博-主题”概率分布矩阵, 利用LDA直接聚类, 实现对微博按主题聚类。
(3) 在上述微博聚类结果的基础上, 结合网络舆情构建中提取出的其他三个子网络中微博与用户的对应关系, 构建“用户-所属观点主题”2-模网络。
(4) 基于“用户-所属观点主题”2-模网络进行舆情观点主题演化分析, 该演化分析包括两部分: 一是通过对“用户-所属观点主题”2-模网络中节点入度的分析得到观点主题支持度排名, 对每天的观点主题支持度变化情况进行分析与说明; 二是对舆情事件观点主题“产生-发展-衰退”的演化过程进行展示与分析。
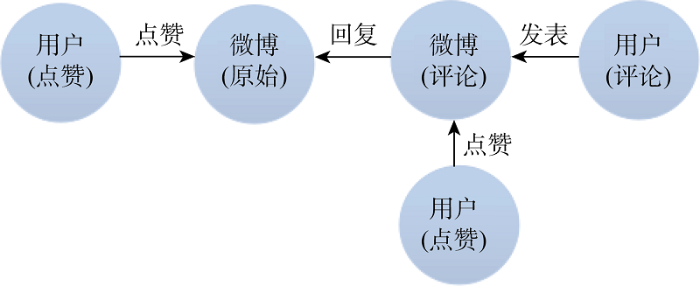
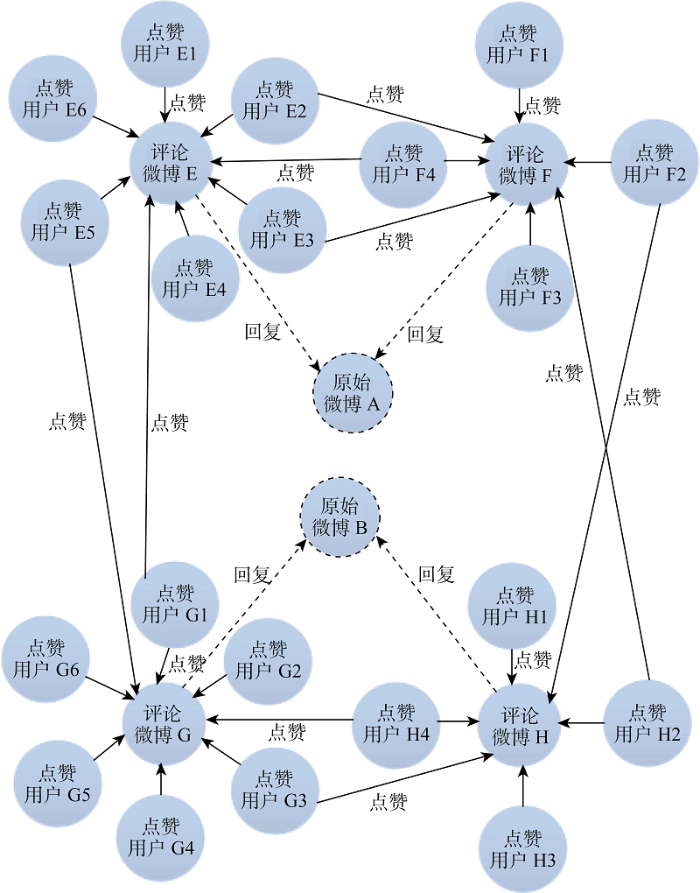
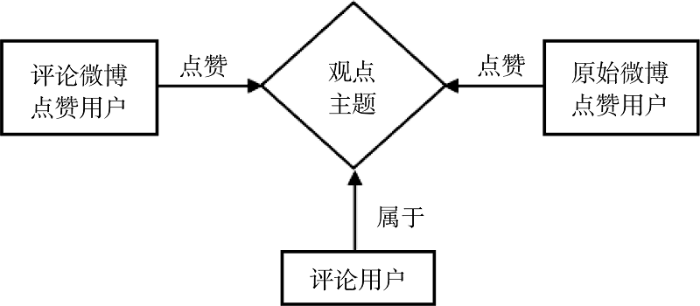
“用户-微博”复杂网络中的节点包括微博、用户两大类, 其中微博节点包括原始微博和评论微博两种; 用户类节点包括评论用户及点赞用户, 其中点赞用户又分为点赞原始微博的用户和点赞评论微博的用户。节点关系主要涉及回复、发表和点赞三种关系。节点与节点间的关系如图3所示。
(1) “原始微博-评论微博”1-模网络
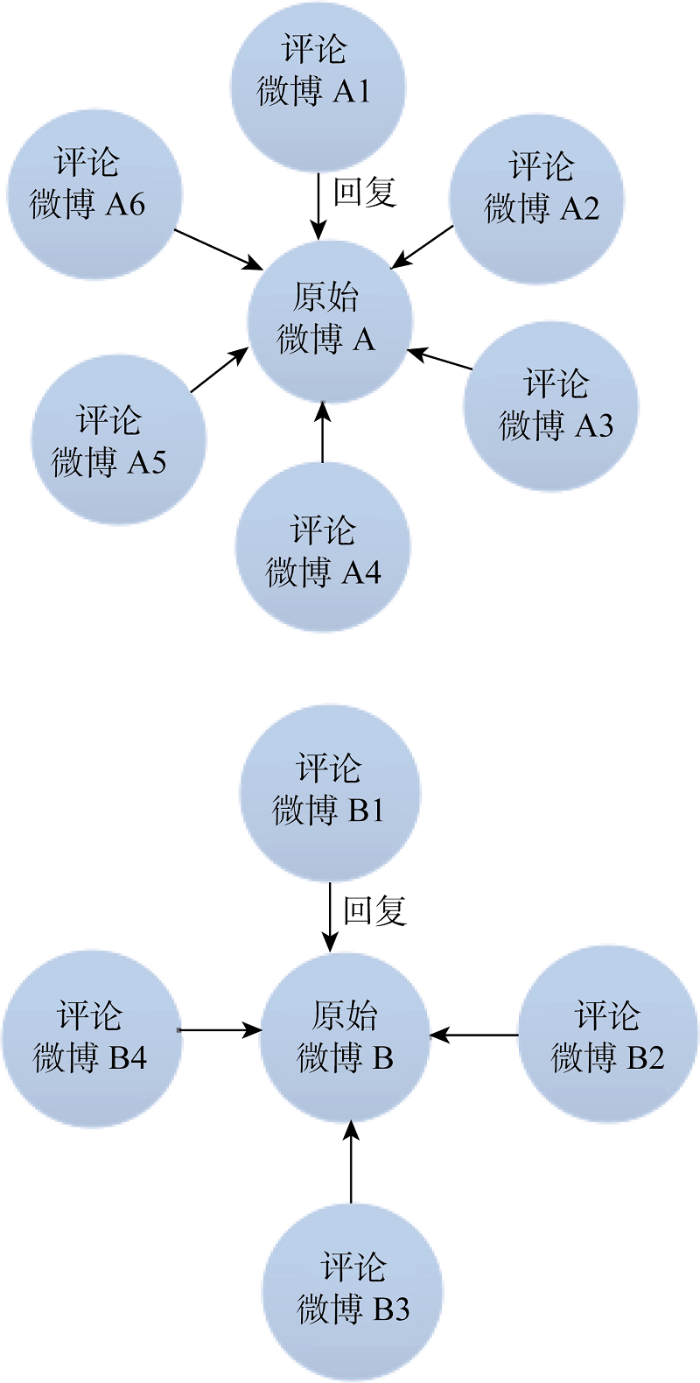
为了分析原始微博的观点和评论微博的观点, 将“用户-微博”复杂网络的用户节点剔除, 提取回复关系, 转换成“原始微博-评论微博”1-模网络, 如图4所示。该网络将原始微博和评论微博视为同一种节点, 即微博节点, 以它们之间的回复关系为连线, 连线的方向代表了回复的方向。同时, 一条评论微博仅代表对原始微博的一条回复, 所以线值为1。该网络由一个个不连通的“星型”子网络构成, 以“原始微博”为子网络的中心节点, 外围的“评论微博”必须通过中心节点才能建立联系, 即评论微博与评论微博之间因共同回复了同一原始微博才建立联系。因此, 该网络的网络密度低, 网络规模取决于外围节点个数, 在一定程度上表征了原始微博的热度。
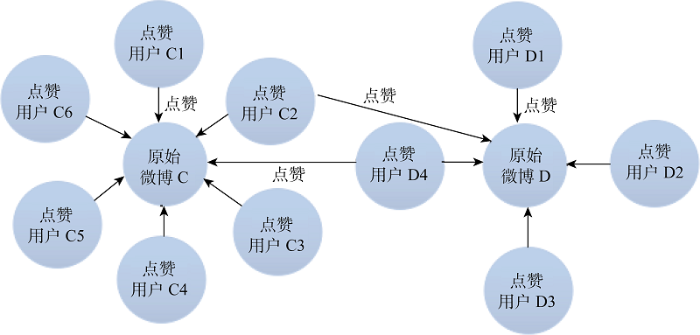
(2) “原始微博-点赞用户”2-模网络
提取图3中原始微博和点赞用户两类节点, 连线代表节点间的点赞关系, 连线方向代表点赞方向。由于用户对同一条微博只能发生一次点赞行为, 因此连线线值为1。图5为“原始微博-点赞用户” 2-模网络结构, 该网络呈“网状”结构, 用户间因点赞了同一微博而建立联系, 同时, 不同原始微博之间因被同一用户点赞而建立联系。该网络的网络规模取决于点赞用户节点个数, 不仅在一定程度上表征了原始微博的热度, 也表达了用户对原始微博的赞同强度。
(3) “评论微博-点赞用户”2-模网络
现实生活中, 对评论和原始微博点赞的用户可能存在交集, 但由于难以获取对评论进行点赞的用户的具体信息, 因此本文假设对评论点赞的用户群和对原始微博点赞的用户群不存在交集。提取图3中的评论微博和点赞用户两类节点, 以其之间的点赞关系为连线, 连线的方向代表点赞的方向。由于用户对同一条评论只能发生一次点赞行为, 因此连线线值为1。图6为该2-模网络模型结构, 与图5所示网络不同点在于: 该网络会因原始微博的不同而形成不同的子群, 子群内的网络密度高于子群间的网络密度, 即对同一条原始微博的不同评论进行点赞的用户的重合度更高。评论微博节点数量和点赞用户节点数量在一定程度上表征了原始微博热度, 点赞用户节点数量体现了评论微博被赞同的强度。
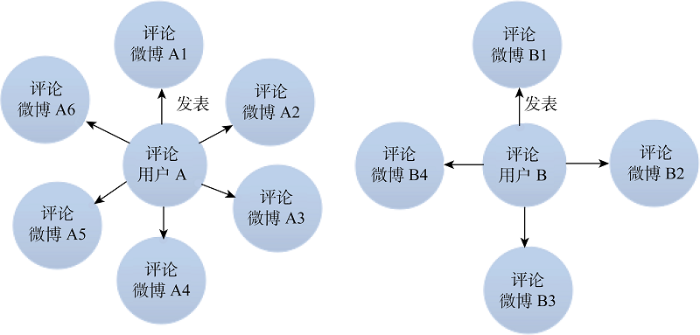
(4) “评论微博-评论用户”2-模网络
提取图3中的评论微博和评论用户两类节点, 以它们之间的发表关系作为连线, 连线方向代表发表关系的方向。虽然用户可以就同一个原始微博发表多次评论, 但由于本文将每条评论视作一条单独的微博, 所以评论用户与评论微博间也是一一对应关系, 即连线的线值为1。图7为“评论微博-评论用户”2-模网络模型, 同图4所示网络类似, 由一个个不连通的“星型”子网络构成, 以“评论用户”为子网络的中心节点, 外围的“评论微博”必须通过中心节点才能建立联系, 即评论微博与评论微博之间因由同一用户发表才建立了联系。评论是一种行为成本较高的用户行为, 因此网络规模, 即外围评论微博节点个数, 在很大程度上表征了用户的活跃程度。
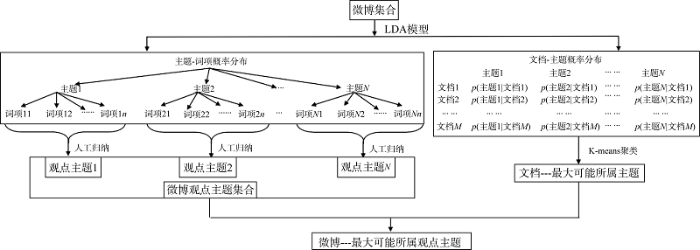
LDA模型认为文档是由主题按一定概率组成的, 而每个主题又是若干词项的概率分布。利用LDA模型进行主题的抽取是上述文档生成过程的逆过程, 通过LDA模型可以得到“主题-词项”概率分布和“文档-主题”概率分布。由于本文选取的研究对象是带有观点倾向性的评论微博和原始微博, 因此对LDA模型抽取出来的微博主题词项进行归纳, 组织成句, 即视为微博观点主题。微博观点主题抽取过程如图8所示。
其中, 利用LDA主题模型进行微博舆情观点抽取的过程主要包括文本预处理、文本建模、主题特征词提取、主题词合并归纳等步骤, 最终得到主题-词项概率分布, 同时得到文档-主题分布, 表现形式如下。
$\begin{matrix} p(z1|d1) & p(z2|d1) & \cdots & p(zk|d1) \\ p(z1|d2) & p(z2|d2) & \cdots & p(zk|d2) \\ \vdots & \vdots & \ddots & \vdots \\ p(z1|dM) & p(z2|dM) & \cdots & p(zk|dM) \\\end{matrix}$
利用该文档-主题分布得到每条微博文本的最大可能所属观点主题, 实现微博聚类。对于第n个文本, 即矩阵的第n行, 若有$\bar{t}=\arg \underset{1\le t\le k}{\mathop{\max }}\,p({{z}_{t}}|{{d}_{n}})$, 则将第n个文本归入主题t中。
基于3.4节微博聚类结果及3.3节用户与微博的对应关系, 构建“用户-所属观点主题”2-模网络, 如图9所示。该网络模型说明一个观点主题的受支持程度取决于表达该观点主题的评论用户数与赞同该观点的点赞用户数之和。
基于内容维度提取出微博舆情观点主题后, 为了得到网民最支持的观点, 还需要加入用户维度, 从社会网络的视角对各观点主题的受支持程度做进一步分析。由于图9所示的网络模型中只涉及由用户节点指向观点主题节点的单向弧, 本文选取节点入度作为观点主题支持度的测量指标。观点主题节点的入度可细分为绝对观点支持度和相对观点支持度, 其中, 绝对观点支持度计算如公式(1)所示。
${{s}_{D}}({{o}_{k}})=\sum\limits_{i}{{{C}_{ik}}}+\sum\limits_{j}{{{C}_{jk}}}=\sum\limits_{i}{{{C}_{ki}}}+\sum\limits_{j}{{{C}_{kj}}}$ (1)
其中, ${{o}_{k}}$表示“用户-所属观点主题”网络中的观点主题节点, ${{C}_{\cdot k}}$的取值范围为$\{0,1\}$, ${{C}_{ik}}$取1时表示点赞用户赞同该观点主题k, ${{C}_{jk}}$取1时表示评论用户发布表达该观点主题的相关评论。为进一步分析不同时间段(每天)的观点支持度演化情况, 需要对观点支持度进行标准化处理, 以做不同网络间的比较。观点主题的相对观点支持度计算如公式(2)所示。
${{S}_{R}}({{o}_{k}})=\frac{{{S}_{D}}({{o}_{k}})}{{{N}_{U}}}$ (2)
其中, ${{N}_{U}}$表示网络中的用户节点总数。
观点支持度反映了用户对该观点主题的支持程度, 入度越大代表有越多的用户赞同、支持该观点, 该观点主题就越有可能为主流观点, 在舆论引导过程中就越应该引起政府与企业的重视。
以“双汇进口美国猪肉”事件为例, 选取目前受众较广泛的新浪微博作为研究平台, 以“双汇 猪肉”为关键词, 检索并收集发布时间在2016年4月1日-2016年4月15日的所有微博与评论, 得到有效原始微博和评论微博共计215条, 进行舆情观点主题识别的实验。
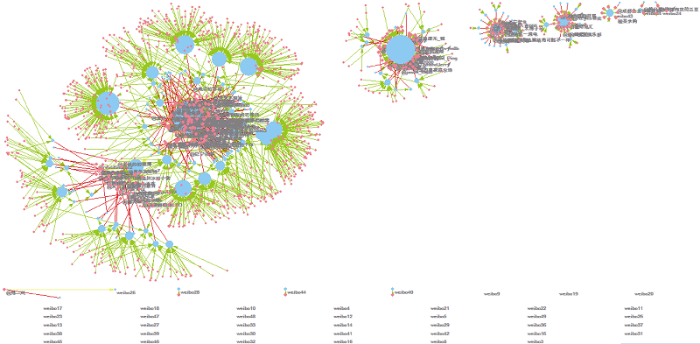
基于3.3节构建“用户-微博”2-模网络, 利用Pajek软件对其实现可视化, 效果如图10所示。
粉色节点表示用户类节点, 蓝色节点表示微博类节点, 节点大小在一定程度上表征了微博热度。由于本文选取的舆情事件规模较小, 使得不同微博间的评论用户群重合度低, 网络整体呈现不连通状态。
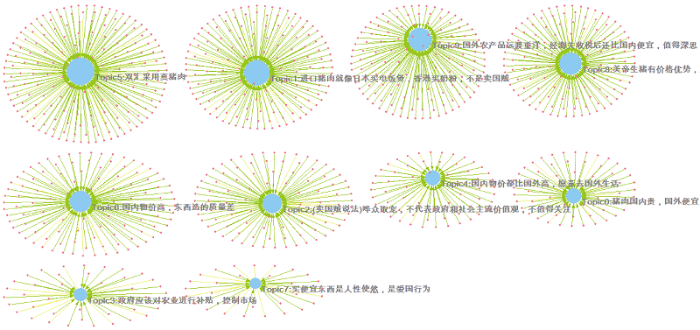
以“天”为时间单位, 将微博离散到不同的时间窗口, 选用开源的JGibbLDA实现每日微博主题的抽取, 主题及其词项分布结果(以2016年4月7日为例)如图11所示。根据主题及各主题下最优词项的抽取结果, 对词项进行合并、归纳得到观点主题, 结果如表1所示(以2016年4月7日为例)。
表1 “双汇进口美国猪肉”事件观点主题(2016-4-7)
| 观点主题 | |
|---|---|
| 1. | 猪肉国内贵, 国外便宜 |
| 2. | 进口猪肉就像日本买电饭煲, 香港买奶粉, 不是卖国贼 |
| 3. | (卖国贼说法)哗众取宠, 不代表政府和社会主流价值观, 不值得关注 |
| 4. | 政府应该对农业进行补贴, 控制市场 |
| 5. | 国内物价都比国外高, 愿意去国外生活 |
| 6. | 双汇采用真猪肉 |
| 7. | 国内物价高, 东西造的质量差 |
| 8. | 双汇收购是因为美帝生猪有价格优势 |
| 9. | 买便宜东西是人性使然, 是爱国行为 |
| 10. | 国外农产品远渡重洋, 经海关收税后还比国内便宜, 值得深思 |
为评价LDA主题抽取效果, 研究对所收集的215条微博进行内容分析, 人工总结其观点主题。通过与人工总结的主题进行比对发现, LDA主题抽取效果较好。但利用LDA进行观点主题抽取主要存在两个不足。
(1) 利用LDA模型抽取出来的不同主题可能表达的是同一个含义。如表1所示的观点主题2与观点主题9都表达了“双汇进口美国猪肉没错, 不是卖国贼”的意思, 但LDA模型将其视为不同的两个主题, 而人工总结时则会将两者视为同一主题。
(2) 文档预处理阶段, 如“是”、“不是”这类字眼会被过滤掉, 导致对LDA模型提取出来的词项进行人工归纳概括时很有可能出现总结出来的观点与实际观点恰恰相反的情况。如用户评论内容为“双汇不是卖国贼”, 而LDA提取出的词项则是“双汇”、“卖国贼”, 这就导致在人工归纳时, 有可能将这一观点主题总结为“双汇是卖国贼”。
为进一步分析各观点主题受支持程度, 需利用公式(1)实现微博与观点主题间的映射, 即完成微博-观点主题聚类。表2展示了2016年4月7日的部分聚类结果。
表2 “双汇进口美国猪肉”事件部分聚类结果(2016-4-7)
| 微博编号 | 所属观点 主题编号 | 微博编号 | 所属观点 主题编号 |
|---|---|---|---|
| 1 | Topic2 | 115 | Topic2 |
| 2 | Topic1 | 116 | Topic7 |
| 3 | Topic2 | 117 | Topic6 |
| 4 | Topic9 | 118 | Topic8 |
| 5 | Topic6 | 119 | Topic5 |
| 6 | Topic10 | 120 | Topic4 |
对每日微博进行人工观点分类, 将得到的LDA聚类结果进行对比, 结果一致用数字1表示, 结果不一致用数字0表示。用对比结果一致的数量与总数之比表示聚类结果的准确率, 计算得到每日微博聚类准确率, 如表3所示。
从表3可以看出, 用单一的LDA模型直接聚类方法得到的聚类结果并不十分准确, 究其原因可能为: LDA模型本身高度依赖词频; 同一评论可能表达多种观点, 而该聚类方式默认将评论只归为某一种观点主题。
基于3.5节构建的“用户-所属观点主题” 2-模网络, 利用Pajek软件可视化, 效果如图12所示(以2016年4月7日为例)。
图12中粉色节点代表用户节点, 蓝色节点代表观点主题节点, 蓝色节点的大小表征了2016年4月7日当天观点主题的受支持度情况。由于在3.3节中假设点赞用户群体间不存在交集, 因此该网络形成多个以各观点主题为中心的网络子群, 整体呈不连通状态。对单日“用户-所属观点主题”网络的分析无法得到观点主题是如何随时间变化的, 因此还需进一步的观点主题演化分析。
根据3.6节对观点主题支持度的描述, 利用节点入度求得观点主题支持度, 并做归一化处理, 处理结果如表4所示(以2016年4月7日为例)。可以看出, 利用LDA模型仅基于内容维度提取出的主题排名与加入社会化数据后得到的主题排名并不一致, 这说明对网络舆情的研究不能缺少对用户行为、用户关系等社会化数据的分析。在实际舆情监测中, 需要加强对支持度高的观点主题的关注, 尤其是当支持度高的观点为负面倾向时, 更应引起政府和企业的重视, 及时做好舆情引导工作, 以免这些支持度高的负面观点影响网民整体情感倾向和负面情绪的二次爆发。
表4 “双汇进口美国猪肉”事件观点主题编号及其相对支持度(2016-4-7)
| 观点主题编号 | 节点入度归一化 | 观点主题 |
|---|---|---|
| 6 | 0.19 | Topic5 |
| 7 | 0.15 | Topic1 |
| 8 | 0.13 | Topic9 |
| 9 | 0.13 | Topic8 |
| 10 | 0.11 | Topic6 |
| 11 | 0.10 | Topic2 |
| 12 | 0.06 | Topic4 |
| 13 | 0.06 | Topic0 |
| 14 | 0.04 | Topic3 |
| 15 | 0.03 | Topic7 |
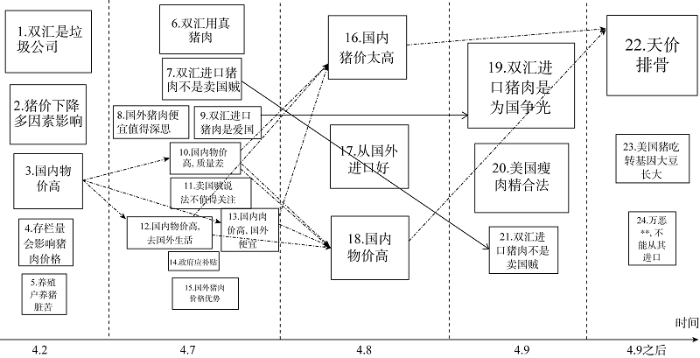
本文以“天”为时间粒度, 对各个观点主题相对支持度的变化情况进行分析。为更直观地得到各观点主题的变化情况, 对其演化过程进行可视化展示, 如图13所示。
从图13可以看出, 观点主题会随时间的推进而不断变化, 但关乎人们自身利益的观点, 如人们对物价高的抱怨, 会贯穿事件始终。因此当这种关乎公众利益的观点出现, 尤其是表现为负面情感倾向时, 应该立刻引起政府和企业的重视, 及时做好舆情引导工作, 避免这种负面观点的继续蔓延。此外, 网民观点受其自身认知影响, 如, 有网民盲目希望所有东西都从国外进口, 也有网民能理性地提出美国瘦肉精合法而质疑进口猪肉的质量。当“瘦肉精”相关观点被提出后, 又有用户紧接着提出了“美国使用转基因大豆作为猪饲料”这一观点, 说明用户观点会受其他用户影响。
本文基于社会网络视角, 利用LDA主题模型, 多方面、多维度地提出一种网络舆情观点主题识别模型。实验整体效果显示, 本文所构建的网络舆情观点主题识别模型能有效识别网络舆情中的观点主题, 把握网民主体的主流观点。本研究尚处于初探阶段, 结合模型本身及实验效果来看, 本文构建的观点主题识别模型还缺少对主题数、词向量个数的确定方法的研究, 缺少对主题抽取结果及聚类效果的科学评价。今后, 笔者将就上述不足对模型进行不断完善, 同时考虑将用户属性引入到观点主题识别的方法体系中, 多方位地识别网络舆情观点主题, 以期帮助政府和企业了解社情民意, 把握网络舆论倾向, 做出正确决策。
丁晟春: 提出研究思路, 设计研究方案;
李真: 具体设计研究, 论文起草;
王楠: 参与设计研究方案, 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: todingding@163.com。
[1] 李真, 丁晟春, 王楠. weibo&comments.xlsx. 观点主题抽取微博及评论语料.
| [1] |
Automatic Generation of Personalized Annotation Tags for Twitter Users [C]// |
| [2] |
Discovery and Analysis of Evolving Topical Social Discussions on Unstructured Microblogs[A]// Advances in Information Retrieval [M]. |
| [3] |
Discovering Hot Topics Using Twitter Streaming Data Social Topic Detection and Geographic Clustering [C]// |
| [4] |
Privacy-preserving Discovery of Topic-based Events from Social Sensor Signals: An Experimental Study on Twitter [J].https://doi.org/10.1155/2014/204785 URL PMID: 24955388 [本文引用: 1] 摘要
Social network services (e.g., Twitter and Facebook) can be regarded as social sensors which can capture a number of events in the society. Particularly, in terms of time and space, various smart devices have improved the accessibility to the social network services. In this paper, we present a social software platform to detect a number of meaningful events from information diffusion patterns on such social network services. The most important feature is to process the social sensor signal for understanding social events and to support users to share relevant information along the social links. The platform has been applied to fetch and cluster tweets from Twitter into relevant categories to reveal hot topics.
|
| [5] |
Mining Hot Topics from Twitter Streams [J].https://doi.org/10.1016/j.procs.2012.04.224 URL [本文引用: 1] 摘要
Mininghottopicsfrom twitter streamshas attractedalotof attentionin recent years.Traditionalhottopicmining from InternetWeb pages were mainly basedontext clustering.However, comparedtothetextsinWeb pages, twitter texts are relatively short with sparse attributes. Moreover,twitter data often increase rapidly withfast spreading speed, whichposesgreat challengetoexistingtopicmining models.Tothisend,we propose,inthispaper, a04exible stream mining approach for hot twitter topic detection. Speci03cally, we propose to use the FrequentPattern stream mining algorithm (i.e. FP-stream) to detect hot topics from twitter streams. Empirical studies on real world twitter data demonstrate the utility of the proposed method.
|
| [6] |
多媒体微博评论信息的主题发现算法研究 [J].
【目的】发现微博中图片或视频等多媒体内容的主题特征。【应用背景】多媒体微博的文本内容普遍简短且主题通常蕴含在图片或视频等多媒体内容中,传统的文本挖掘方法不适用于这种多媒体类微博。【方法】通过热点评论扩充该多媒体微博的文本空间,并使用LDA主题模型进行分类推断与主题特征挖掘,使用“主题标签一特征词”的形式表达微博多媒体内容的主题特征。【结果琐用爬虫工具采集的99823条新浪微博构建训练集,151条热门多媒体微博及其所有评论构建测试集进行实验,构建的分类目录中标签完善,主题标签推断准确率达到88.6%,相关特征词挖掘准确率为76.0%。【结论】实验结果表明本文的算法可以有效且显著地发现多媒体微博的主题特征。
Topic Discovery Algorithm for Multimedia Microblog Comments Information [J].
【目的】发现微博中图片或视频等多媒体内容的主题特征。【应用背景】多媒体微博的文本内容普遍简短且主题通常蕴含在图片或视频等多媒体内容中,传统的文本挖掘方法不适用于这种多媒体类微博。【方法】通过热点评论扩充该多媒体微博的文本空间,并使用LDA主题模型进行分类推断与主题特征挖掘,使用“主题标签一特征词”的形式表达微博多媒体内容的主题特征。【结果琐用爬虫工具采集的99823条新浪微博构建训练集,151条热门多媒体微博及其所有评论构建测试集进行实验,构建的分类目录中标签完善,主题标签推断准确率达到88.6%,相关特征词挖掘准确率为76.0%。【结论】实验结果表明本文的算法可以有效且显著地发现多媒体微博的主题特征。
|
| [7] |
基于文本聚类与LDA相融合的微博主题检索模型研究 [J].
伴随着微博的日趋流行,对微博信息的检索逐渐成为人们获取第一消 息的手段.其中文本聚类和主题发现是信息检索领域的有效方法,采用适当的方法是影响微博短文本信息检索质量的关键因素.文章针对文本聚类和LDA主题模型 的互补特征,综合考虑了微博特殊文体和短文本聚类效率问题,提出了基于频繁词集的文本聚类和基于类簇的LDA主题挖掘相融合的微博检索方法,给出了针对微 博文体的一种新的主题检索模型.实验表明,该方法不仅能有效地划分微博文本,并且能清晰地挖掘类簇中潜在主题.
Micro Blog Topic Retrieval Model Research Based on Text Clustering and LDA [J].
伴随着微博的日趋流行,对微博信息的检索逐渐成为人们获取第一消 息的手段.其中文本聚类和主题发现是信息检索领域的有效方法,采用适当的方法是影响微博短文本信息检索质量的关键因素.文章针对文本聚类和LDA主题模型 的互补特征,综合考虑了微博特殊文体和短文本聚类效率问题,提出了基于频繁词集的文本聚类和基于类簇的LDA主题挖掘相融合的微博检索方法,给出了针对微 博文体的一种新的主题检索模型.实验表明,该方法不仅能有效地划分微博文本,并且能清晰地挖掘类簇中潜在主题.
|
| [8] |
基于EM-LDA综合模型的电商微博热点话题发现 [J].Research on Hot Topic Discovery of Microblog Based on EM-LDA Comprehensive Model [J]. |
| [9] |
基于本体的网络群体性事件主题发现研究 [J].
将本体论和语义计算的相关技术引入到网络群体性事件的主题发现研究中,并通过构建食品安全领域本体进行实证研究。实验结果表明,该方法能够有效地获取主题信息,有助于实现网络群体性事件的主题发现。
Topic Discovery of Network Group Events Based on Ontology [J].
将本体论和语义计算的相关技术引入到网络群体性事件的主题发现研究中,并通过构建食品安全领域本体进行实证研究。实验结果表明,该方法能够有效地获取主题信息,有助于实现网络群体性事件的主题发现。
|
| [10] |
Burst Topic Discovery and Trend Tracing Based on Storm [J].https://doi.org/10.1016/j.physa.2014.08.059 URL [本文引用: 1] 摘要
With the rapid development of the Internet and the promotion of mobile Internet, microblogs have become a major source and route of transmission for public opinion, including burst topics that are caused by emergencies. To facilitate real time mining of a large range of burst topics, in this paper, we proposed a method to discover burst topics in real time and trace their trends based on the variation trends of word frequencies. First, for the variation trend of the words in microblogs, we adopt a non-homogeneous Poisson process model to fit the data. To represent the heat and trend of the words, we introduce heat degree factor and trend degree factor and realise the real time discovery and trend tracing of the burst topics based on these two factors. Second, to improve the computing performance, this paper was based on the Storm stream computing framework for real time computing. Finally, the experimental results indicate that by adjusting the observation window size and trend degree threshold, topics with different cycles and different burst strengths can be discovered.
|
| [11] |
基于依存分析与特征组合的微博情感分析 [J].https://doi.org/10.6040/j.issn.1671-9352.3.2014.074 URL 摘要
针对微博短文本存在口语化、简洁化等社交网络特征,充分利用句法依存关系以及条件随机场(conditional random fields,CRFs),抽取候选评价对象,并在基于机器学习的微博情感分类方法的基础上结合情感分析词典,引入情感值、微博标签、主题等特征,优化分类性能。在COAE(Chinese opinion analysis evaluation)微博评测数据集上,以准确率、召回率、F1值为评价指标对所提方法进行验证,证实了基于句法依存分析与CRFs相结合的评价对象抽取方法的有效性,分析了各类特征对情感分类性能的影响,最终在COAE微博观点句识别任务中准确率达91.4%。
Micro-blog Opinion Analysis Based on Syntactic Dependency and Feature Combination [J].https://doi.org/10.6040/j.issn.1671-9352.3.2014.074 URL 摘要
针对微博短文本存在口语化、简洁化等社交网络特征,充分利用句法依存关系以及条件随机场(conditional random fields,CRFs),抽取候选评价对象,并在基于机器学习的微博情感分类方法的基础上结合情感分析词典,引入情感值、微博标签、主题等特征,优化分类性能。在COAE(Chinese opinion analysis evaluation)微博评测数据集上,以准确率、召回率、F1值为评价指标对所提方法进行验证,证实了基于句法依存分析与CRFs相结合的评价对象抽取方法的有效性,分析了各类特征对情感分类性能的影响,最终在COAE微博观点句识别任务中准确率达91.4%。
|
| [12] |
Hot Topic Detection Based on Complex Networks [C]//
|
| [13] |
Latent Community Topic Analysis: Integration of Community Discovery with Topic Modeling [J].https://doi.org/10.1145/2337542.2337548 URL 摘要
This article studies the problem of latent community topic analysis in text-associated graphs. With the development of social media, a lot of user-generated content is available with user networks. Along with rich information in networks, user graphs can be extended with text information associated with nodes. Topic modeling is a classic problem in text mining and it is interesting to discover the latent topics in text-associated graphs. Different from traditional topic modeling methods considering links, we incorporate community discovery into topic analysis in text-associated graphs to guarantee the topical coherence in the communities so that users in the same community are closely linked to each other and share common latent topics. We handle topic modeling and community discovery in the same framework. In our model we separate the concepts of community and topic, so one community can correspond to multiple topics and multiple communities can share the same topic. We compare different methods and perform extensive experiments on two real datasets. The results confirm our hypothesis that topics could help understand community structure, while community structure could help model topics.
|
| [14] |
微博舆情社会网络关键节点识别与应用研究 [J].
文章在对国内外相关文献调查与梳理的基础上,从社会网络结构角度出发,设计舆情数据爬取系统,运用社会网络分析法来探索舆情网络中关键节点的识别与应用。具体应用时,以新浪微博为研究平台,通过爬虫系统抓取舆情数据并解析,构建微博舆情社会网络,运用改进PageRank算法对舆情网络中的关键节点进行识别与评价,实验结果证明本文所用算法是有效的。
Identification and Application of Microblog Public Opinion Social Network Critical Node [J].
文章在对国内外相关文献调查与梳理的基础上,从社会网络结构角度出发,设计舆情数据爬取系统,运用社会网络分析法来探索舆情网络中关键节点的识别与应用。具体应用时,以新浪微博为研究平台,通过爬虫系统抓取舆情数据并解析,构建微博舆情社会网络,运用改进PageRank算法对舆情网络中的关键节点进行识别与评价,实验结果证明本文所用算法是有效的。
|
| [15] |
面向网络评论的观点主题识别研究 [J].https://doi.org/10.3772/j.issn.1000-0135.2010.05.014 URL [本文引用: 1] 摘要
网络评论的观点分析为及时掌握广大民众的真实观点提供了渠道。观点主题识别作为观点分析的重要组成部分,用以确定观点所指的对象。本文设计了一种领域无关的观点主题识别算法,该算法以网络评论中观点主题产生的方式为依据,采用由内到外的识别过程,分四个部分完成观点主题识别:内部主题词识别、内部主题构建、外部主题识别和主题的组织。算法能够克服分词和短语类主题带来的影响,识别出语义完整的观点主题。对实际网络评论语料进行测试的结果表明,本文的算法能够有效地识别网络评论中的观点主题。
Research on the Identification of Opinion Topic Expressed in Web Comments [J].https://doi.org/10.3772/j.issn.1000-0135.2010.05.014 URL [本文引用: 1] 摘要
网络评论的观点分析为及时掌握广大民众的真实观点提供了渠道。观点主题识别作为观点分析的重要组成部分,用以确定观点所指的对象。本文设计了一种领域无关的观点主题识别算法,该算法以网络评论中观点主题产生的方式为依据,采用由内到外的识别过程,分四个部分完成观点主题识别:内部主题词识别、内部主题构建、外部主题识别和主题的组织。算法能够克服分词和短语类主题带来的影响,识别出语义完整的观点主题。对实际网络评论语料进行测试的结果表明,本文的算法能够有效地识别网络评论中的观点主题。
|
| [16] |
基于SVM的中文微博情绪分析研究 [J].SVM-based Chinese Microblog Sentiment Analysis [J]. |
| [17] |
网络舆情观点提取的LDA主题模型方法 [J].LDA Theme Model Method for the Extraction of Network Public Opinion [J]. |
| [18] |
面向微博话题的“主题+观点”词条抽取算法研究 [J].
【目的】自动抽取微博话题信息,从主题及观点两个维度整合揭示微博话题内容与观点。【方法】将主题模型应用于微博话题中,结合改进的TF-IDF算法,构建主题特征词向量;基于特征词向量中特征词之间的相关度,自动抽取主题词汇链;引入情感词典,抽取主题观点,无监督构建"主题+观点"词条。【结果】使用爬虫工具抽取2014年6月–2015年6月期间4个特定热门微博话题事件的微博共24 598条,抽取"主题+观点"词条,平均准确率达到80.3%,召回率为76.7%。【局限】数据量依旧较小,主题模型对于微博短文本的特征抽取效果仍需提高。【结论】本文算法可以准确且有效地描述话题事件内容及其相应观点。
Research on Topic Extraction Algorithm Based on “Topic + Opinion” for Microblog [J].
【目的】自动抽取微博话题信息,从主题及观点两个维度整合揭示微博话题内容与观点。【方法】将主题模型应用于微博话题中,结合改进的TF-IDF算法,构建主题特征词向量;基于特征词向量中特征词之间的相关度,自动抽取主题词汇链;引入情感词典,抽取主题观点,无监督构建"主题+观点"词条。【结果】使用爬虫工具抽取2014年6月–2015年6月期间4个特定热门微博话题事件的微博共24 598条,抽取"主题+观点"词条,平均准确率达到80.3%,召回率为76.7%。【局限】数据量依旧较小,主题模型对于微博短文本的特征抽取效果仍需提高。【结论】本文算法可以准确且有效地描述话题事件内容及其相应观点。
|

/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}