张红丽, 刘济郢, 杨斯楠, 徐健
中山大学资讯管理学院 广州 510006
Zhang Hongli, Liu Jiying, Yang Sinan, Xu Jian
中图分类号: G350
通讯作者:
收稿日期: 2017-05-31
修回日期: 2017-07-19
网络出版日期: 2017-08-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】通过网络用户评论, 为评论网站构建有效的评分预测机制。【方法】提出基于网络用户评论的评分预测模型, 该模型包括4个模块: 网络用户评论获取模块、预测变量获取模块、预测分析模块以及预测结果评价模块。抓取30部不同类型的电影评论数据, 27部用于构建模型, 3部用于检验模型。【结果】使用逐步回归方法筛选出变量: 参与评分人数、参与评论人数、想要观看人数和电影正向评论情感均值, 构建评分预测模型。使用3部电影验证, 预测评分与IMDb评分相差最大值为0.0644, 最小值为0.0227。【局限】在数据样本量、情感特征提取精度、模型普适性验证等方面有待进一步提升。【结论】该模型能够依据用户评论对评分进行有效预测, 在网络水军探测方面也能发挥一定的作用。
关键词:
Abstract
[Objective] This study aims to build an effective prediction mechanism for online ratings, with the help of Web surfers’ comments. [Methods] We proposed a model with the following modules: Web users’comment acquisition, predictive variable acquisition, prediction analysis and the prediction results evaluation. We retrieved 30 movies of different types and user’s comments from the Web. 27 movies were used to build the model, which were then examined with the remaining movies. [Results] We employed the stepwise regression to select variables, which included the number of raters, the number of participants posting comments, the number of people who wanted to watch the moive and the sentiment value of the positive comments. The prediction results were quite close to the IMDb scores, and the maximum and the minimum differences were 0.0644 and 0.0227. [Limitations] The sample size, the accuracy of sentiment features, and compatibility of the model could be improved. [Conclusions] The proposed model effectively predicts movie scores and detects the “water army” online.
Keywords:
随着Web2.0的发展, 每一位网络用户都可以通过互联网发表个人对产品的观点并为产品打分, 专门的产品评分网站也应运而生。同时, 越来越多的消费者将评分网站上的用户评分作为消费决策的重要参考。但由于信息发布的门槛降低, 评分网站上的评分易受到非正常手段干扰, 面对评分网站上纷繁的产品宣传和产品评价, 如何从网络中识别真实的产品评价及评分成为网民们关注的问题。如今评分网站在引导消费上起到极其关键的作用, 但是其存在两个问题使得产品的真实性大打折扣: 一是消费者评论具有混杂性, 二是用户恶意刷分行为影响了产品的真实评分。普通用户只能通过网络评分辨别产品的优劣, 而一个不具有公信力的评分很大程度上会误导用户判断。另外, 网络评分在产品发布之后一段时间才趋于稳定, 存在滞后性的特点。
针对上述评分网站的问题, 本文通过选取网络用户评论的相关指标, 提出一种基于网络用户评论的评分预测模型。由于网络评论中包含用户对产品的意见和情感倾向, 因此, 基于用户的评论内容, 利用情感分析技术分析评论文本的情感倾向性, 将情感指标作为辅助预测指标, 以提高模型的预测效果。对于个人, 可以通过评分预测模型得到更客观公正的评分, 为消费决策提供建议; 对于商家, 可以收到最真实的使用反馈, 以改进产品质量; 对于网站管理方, 可以用来探测评分异常值存在, 及时发现“网络水军”[1], 维护网站正常运营。
目前对网络用户评论的相关研究已经取得了较多的成果, 主要研究方向集中在评论的有用性、评论对产品销量的影响和评论文本挖掘三个方面。
(1) 评论的有用性是指用户产生的能够帮助潜在消费者购买决策的产品评价[2]。只有消费者认为有用的评价才具有实际价值, 研究者主要从评论内容和评论用户的角度对评论的有用性进行探索。Chen等[3]抓取亚马逊网站用户评论数据, 提出网络用户评论的有用性与评论用户、评论效用和评论获支持数存在较强的关联性。吴江等[4]从评论信息的相关性、及时性、客观性、真实性4个维度出发, 构建评论有用性影响因素模型。Kuan等[5]利用亚马逊评论数据探索出评论语句的长度、可读性程度、情感极性、评论用户的信誉对评论的有用性具有影响。
(2) 评论对产品销量的影响涉及的产品领域众多, 主要包括电子产品类、音像图书类、旅游酒店类、电影类等。王文君等[6]通过对在线手机评论研究发现, 评论长度、评论时效性、评论数量、负面评论和产品价格对在线手机销量有显著性影响。龚诗阳等[7]分析了当当网上的图书评论, 研究显示评论数量对图书销量有正向影响。评论数量对销量的影响程度随着图书上线的时间变长而减弱。Torres等[8]研究美国178家酒店在TripAdvisor上的评分排名与在线评论数量对酒店在线交易产生的影响, 分析发现评论数量和评分排名对酒店在线预订交易具有积极影响。Chintagunta等[9]测量了评论效用、评论数量对电影票房的影响。
(3) 评论文本挖掘主要包括产品特征挖掘和用户情感的判断。对评论中产品特征的挖掘是从产品自身的角度进行分析, Liu等[10]首先提出应用关联规则分类方法提取英文评论中的产品特征。杜思奇等[11]引入汉语组块分析, 结合支持向量机、Apriori 算法获取频繁项集、TF-IDF停用词过滤实现评论文本中产品特征的提取。用户情感的判断主要通过挖掘用户网络评价的情感倾向分析用户对评价对象的褒贬态度。单晓红等[12]采用情感分析方法对苹果手机用户的网络评论进行分析, 为用户购买决策提供依据。吴维芳等[13]利用Word2Vec对TripAdvisor酒店评论进行特征抽取和降维, 结合情感分析技术, 构建计量经济模型分析酒店特征评价与用户满意度的关系。
另外, 在评分预测方面, 马春平等[14]提出一种基于词向量的方法挖掘用户评论信息, 并结合协同过滤的方法设计新的推荐算法, 该算法有效地提高了推荐系统的评分预测性能。Kamath等[15]利用 MG- LDA[16]算法对评论进行主题分析生成主题词表, 利用主题词表将用户评论表示成特征向量, 利用机器学习算法建模进行评分预测。马松岳等[17]对豆瓣电影的用户评价进行情感分析得到综合情绪值, 发现评论评价的综合情绪值与打分评价相关性较高, 根据评论评价构建预测打分模型。但该模型变量只涉及综合情绪值和评论总数, 没有考虑评论的其他因素。
综上所述, 目前虽然有很多关于网络用户评论的研究, 但研究主要集中于评论效用和挖掘技术方面。在评分预测方面, 结合情感分析, 并用于评论分数预测方面的相关研究较少。本文在网络用户评论相关变量基础上, 引入情感特征因素作为辅助预测变量, 提出基于网络用户评论的评分预测模型, 旨在利用情感分析和回归分析手段实现对产品评分网站客观评分的有效预测。
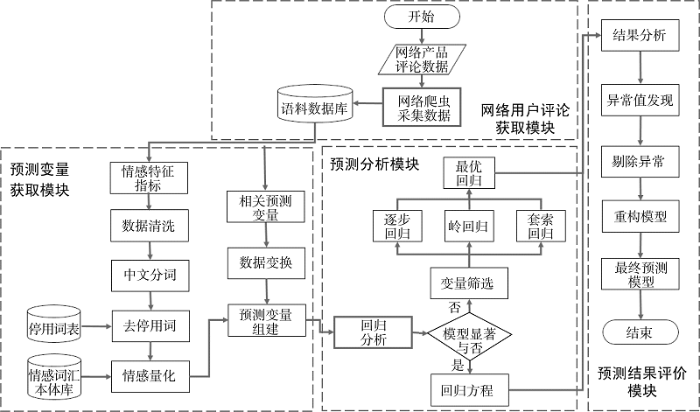
本文提出一种基于网络用户评论的评分预测模型, 预测评分网站中产品的客观评分。借助情感分析的手段, 提取用户语料中的情感特征, 使之成为辅助预测指标, 并寻找行业内最客观公正的评分作为预测对比变量。同时结合相关联的预测指标以及情感分析指标作为自变量, 通过回归分析构建评分预测模型。该模型主要由4个部分构成: 网络用户评论获取模块、预测变量获取模块、预测分析模块以及预测结果评价模块, 如图1所示。
(1) 网络用户评论获取模块主要包括网络评论来源的筛选以及网络评论数据的获取。质量高的数据源有助于模型的有效建立, 选定具有代表性的网站作为网络评论数据源[18]; 选取行业客观评分数据来源; 采集所需数据并存储在数据库中。
(2) 预测变量获取模块主要包括网络用户评论相关预测指标和情感特征指标。获取网络用户评论相关预测指标, 对数量级大的变量进行对数缩放操作, 防止数据的量级差距导致模型失真。情感特征指标提取包括数据清洗、中文分词、去停用词以及情感量化[19]。对网络用语化且非结构化的网络用户评论进行数据清洗, 剔除评论中的网络链接、表情等非规范信息, 只保留文本内容; 进行文本分词和去停用词处理, 减少情感量化的计算量; 通过情感值计算的方式对语料数据进行量化。
(3) 预测分析模块主要针对预测变量, 采用多元线性回归分析方法构建预测模型[20], 并对模型进行结果分析。若P值不显著, 则采用不同的回归分析方法筛选变量, 重构模型, 观察各个变量P值是否显著(小于0.05), 倘若不显著说明模型建立失败。若P值显著, 再对R方(R-square)和调整R方(Adjusted R-square)进行比较, 选取值较高的回归模型, 该数值越大, 预测值与实际值越接近。
(4) 预测结果评价模块主要包括对回归模型的预测结果进行可视化解析, 通过拟合预测分数与客观评分, 观察预测效果。倘若预测中出现异常值和不显著的变量, 分析其差异性的缘由, 进行剔除后, 重新构建回归方程, 并采用预测数据检验模型的实际预测效果, 以证明预测模型的有效性。
为验证评分预测模型的有效性, 以电影评分网站为例, 通过网络用户评论预测模型来预测电影评分。
(1) 豆瓣电影影评数据源
豆瓣电影是国内热门的电影评分网站, 收录了十分齐全的国内外电影数据, 用户数量及电影评论数据量巨大, 是一个理想的网络评论源。豆瓣的影评主要以两种形式存在: 短评和长评。短评字数限制在140字以内, 主要是豆瓣用户对于电影较为宏观或者某个方面的评价。长评多为篇幅型影评内容, 内容繁杂, 很多电影之外的内容, 例如有些会介绍拍摄过程、拍摄手法或者演职人员等。因此, 本文选取豆瓣电影评分网站的短评作为网络用户评论语料。
以近年来的电影为样本, 为保障数据的多样化, 选取时尽量兼顾电影上映月份和不同类型的电影题材, 如动作类、喜剧类、科幻类等。共计选择30部电影, 部分电影如表1所示。
表1 电影样本(部分)
| 编号 | 电影名称 | 国内上 映日期 | 类型 | 制作地区 |
|---|---|---|---|---|
| 1 | 小时代4 | 2015/7/9 | 爱情、剧情、青春 | 中国内地、 中国台湾 |
| 2 | 小时代2 | 2013/8/8 | 青春、剧情、爱情 | 中国内地、 中国台湾 |
| 3 | 恶棍天使 | 2015/12/24 | 喜剧、荒诞、爱情 | 中国 |
| 4 | 万物生长 | 2015/4/17 | 爱情、剧情、校园 | 中国 |
| 5 | 捉妖记 | 2015/7/16 | 剧情、喜剧、奇幻 | 中国 |
| 6 | 湄公河行动 | 2016/9/30 | 动作、警匪 | 中国 |
| 7 | 驴得水 | 2016/10/28 | 喜剧、剧情 | 中国 |
| 8 | 功夫熊猫3 | 2016/1/29 | 动画, 喜剧、动作 | 美国、中国 |
| 9 | 百鸟朝凤 | 2016/5/6 | 剧情、文化 | 中国 |
| 10 | 七月与安生 | 2016/9/14 | 剧情、爱情、青春 | 中国 |
(2) 客观评分数据源
互联网电影数据库(IMDb)是目前信息量较大、使用人数较多、影响范围较广、影响力较大的电影网站之一[21]。IMDb的影片得分采取统计学的计算方法, 并结合部分专家的评分意见, 保障电影的评分不受极端行为的影响。为保障电影评分的客观性, 本文选取IMDb的评分系统作为评分预测模型的客观评分来源。
(3) 电影影评时间区间选取
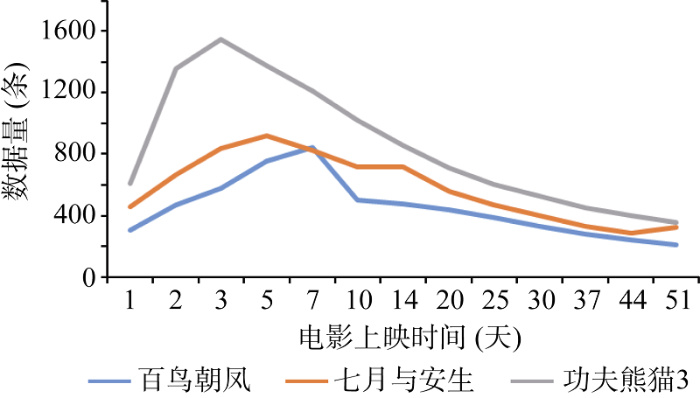
由于电影的影评数据时间轴较长, 通过观察电影影评趋于稳定状态的时长, 确定选取数据的时间区间。一般来说, 多数电影的上映期限为一个月。选取不同类型的电影《百鸟朝凤》、《七月与安生》、《功夫熊猫3》, 对其上映后获取的数据量进行分析, 如图2所示。
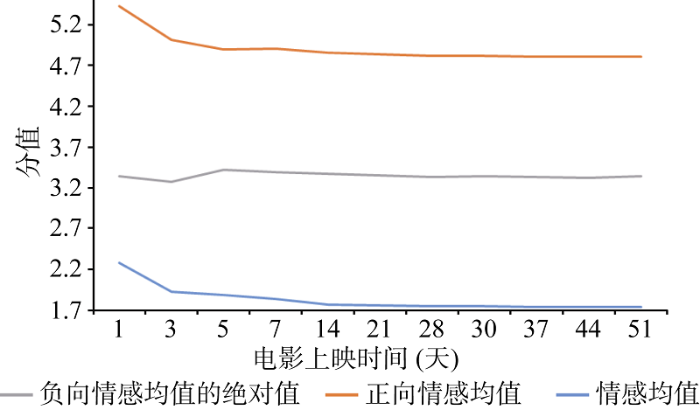
从图2可知, 三部电影的评论数据在上映后一周达到顶峰, 在30天后评论数据波动不再明显, 并趋于稳定。此外, 在分析三部电影的豆瓣电影短评情感倾向性方面出现类似现象, 如《七月与安生》, 正向评论情感值和负向评论情感值在第一周内波动较为明显, 随着上映时间的推移, 情感值均在30天左右逐渐趋于稳定。电影上映第30天, 情感值均值稳定在1.7左右, 浮动很小, 如图3所示。
综上所述, 若评论数据的波动性太大, 会导致情感量化结果出现偏差, 实际预测结果失真。因此, 在模型构建时, 要选取能够反映稳定情感的数据源。本实验中选取电影上映之后30天内的豆瓣电影评论数据作为语料数据来源。
使用爬虫软件“集搜客”[22]抓取豆瓣电影影评(包括短评用户名、短评内容、评论时间、获得支持数及评分数)作为实验数据集, 选用IMDb为客观评分来源。共抓取30部电影1 469 660条电影短评, 数据去重后选取电影上映后30天内的短评数据, 共计513 788条。
(1) 网络用户评论相关预测指标
网络评论预测变量通过豆瓣电影页面相关数据选取: 评分人数(criticNum)指参与该电影评分的用户数; 参与评论人数(commentNum)指参与该电影的文字评论的用户数; 标记看过人数(watchedNum)指已经看过该部电影的用户数; 想看的人数(desireNum)指在豆瓣上标记了对这部电影感兴趣或者想要观看的用户数。其中, 开始选择想看的用户, 看过电影后改为看过, 将不再在想看那组, 即两组互斥。根据所获得数据延展出两个变量: 参与电影评论的比例(comment Ratio)和想看人数比例(desireRatio), 计算方法如公式(1)和公式(2)所示。
$commentRatio=\frac{commentNum}{watchedNum}$ (1)
$desireRatio=\frac{desireNum}{(desireNum+watchedNum)}$ (2)
commentRatio是评论人数在看过人数中的占比, 表示想表达对电影观点的影迷占比情况。很多影迷在未观看电影前先对电影进行标记, 表明对电影有极大的兴趣, desireRatio表示想看人数占想看人数和已看过人数之和的比例, 可反映对电影的喜爱程度。由于获取的数据量级比较大, 为避免模型失真, 本文采用底数为10的对数缩放方法对数据进行变换, 例如criticNum变换后的变量名为LcriticNum。
(2) 情感特征指标
本文情感量化采用基于情感词典的方式, 使用大连理工大学的情感词汇本体库[23]。本体库中词汇的情感强度1、3、5、7、9级别分别对应1、2、3、4、5分, 正向情感为正数, 负向情感为负数, 中性词为零。例如, “阻力”在本体库中被标注为负向情感词并且情感强度为3, 其对应的情感分数为-2分。sentimentScore代表某条评论的情感分数, i代表评论中正向词的序列数, Pi代表该词对应的正向情感分数。j代表评论中负向词的序列数, Nj代表该词对应的负向情感分数, 假设评论中共有n个正向情感词, m个负向情感词, 情感分数计算如公式(3)所示。
$sentimentScore=\sum\limits_{i=1}^{n}{{{P}_{i}}+}\sum\limits_{i=1}^{m}{{{N}_{j}}}$ (3)
对30天的电影评论数据的情感进行量化, 并求出情感均值(sentimentmeanScore)。为更好地表达电影的情感倾向, 在情感均值的基础上, 计算正向情感均值(posmeanScore)和负向情感均值(negmeanScore)。正向情感均值为30天电影评分数据正向评价的算术平均值, 负向情感均值为30天电影评分数据负向评价的算术平均值。i、j、k分别指代某条评论数据; a表示正向评论数量; b表示负向评论数量; n指总数量, 即n=a+b; pos(i)指第i条评论的正向情感值; neg(j)指第j条评论的负向情感值; sentimentScore(k)指第k条评论的情感值。计算如公式(4)-公式(6)所示。
$posmeanScore=\frac{\sum\limits_{i=1}^{a}{pos(i)}}{a}$ (4)
$negmeanScore=\frac{\sum\limits_{j=1}^{b}{neg(j)}}{b}$ (5)
$sentimentmeanScore=\frac{\sum\limits_{k=1}^{n}{sentimentScore(k)}}{n}$ (6)
提取完所有电影的情感特征后, 组建出所有的预测变量及含义(见表2), 并归纳整理变量数据(部分数据见表3)。
表2 预测变量及含义
| 预测变量名称 | 实际含义 |
|---|---|
| LcriticNum | 参与评分的人数以10为底对数值 |
| LcommentNum | 参与评论的人数以10为底对数值 |
| LwatchedNum | 已经看过的人数以10为底对数值 |
| LdesireNum | 想要观看的人数以10为底对数值 |
| commentRatio | 评论人数占评分人数的比例 |
| desireRatio | 想要观看人次占看过和想看人次的比例 |
| sentimentmeanScore | 电影评论情感均值 |
| posmeanScore | 电影正向评论情感均值 |
| negmeanScore | 电影负向评论情感均值 |
| doubanScore | 豆瓣电影评分 |
表3 预测变量值表(部分)
| 编号 | 电影名称 | Lcritic Num | Lcomment Num | Lwatched Num | Ldesire Num | comment Ratio | desireRatio | sentiment meanScore | posmean Score | negmean Score | douban Score |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 小时代4 | 4.9019 | 4.5759 | 4.9563 | 3.9654 | 0.4720 | 0.0927 | 0.6022 | 4.3345 | -3.7442 | 4.6 |
| 2 | 小时代2 | 5.1045 | 4.7196 | 5.1774 | 3.8624 | 0.4121 | 0.0462 | 0.6174 | 4.2995 | -3.7318 | 5 |
| 3 | 恶棍天使 | 4.8992 | 4.6329 | 4.9357 | 3.8567 | 0.5416 | 0.0769 | 0.3044 | 4.1802 | -3.6735 | 4 |
| 4 | 万物生长 | 4.9530 | 4.5765 | 5.0190 | 3.9803 | 0.4202 | 0.0838 | 0.5267 | 4.1363 | -3.8332 | 5.9 |
| 5 | 捉妖记 | 5.3677 | 4.9937 | 5.4185 | 4.2924 | 0.4226 | 0.0696 | 1.2405 | 4.3430 | -3.4054 | 6.8 |
| 6 | 湄公河行动 | 5.3412 | 5.0007 | 5.3659 | 4.5103 | 0.4565 | 0.1224 | 1.4745 | 4.6532 | -3.5063 | 8.1 |
| 7 | 驴得水 | 5.1235 | 4.7927 | 5.1492 | 4.4252 | 0.4668 | 0.1588 | 0.4241 | 4.3093 | -4.1345 | 8.3 |
| 8 | 功夫熊猫3 | 5.1937 | 4.7917 | 5.2385 | 4.0827 | 0.3962 | 0.0653 | 1.7018 | 4.6260 | -3.0234 | 7.7 |
| 9 | 百鸟朝凤 | 4.9233 | 4.5974 | 4.9611 | 4.3204 | 0.4722 | 0.1861 | 2.1067 | 5.5629 | -3.3765 | 8 |
| 10 | 七月与安生 | 5.2082 | 4.8858 | 5.2441 | 4.2882 | 0.4760 | 0.0997 | 1.7458 | 4.8169 | -3.3355 | 7.6 |
回归分析方法可以用来判别客观事物数量的依存关系, 可以用来处理多个变量之间相互关系。回归分析是研究相关关系的一种数学方法, 是寻找不完全确定的变量间的数学关系式并进行统计推断的一种方法[24]。常见的回归预测有多元线性回归(Multiple Regression)[25]、逐步回归(Stepwise Regression)[26]、岭回归(Ridge Regression)[27]、套索回归(Lasso Regression)[28]等方法。
针对上述的数据变量, 分别使用多元线性回归、逐步回归、岭回归以及套索回归方法对模型进行变量选择, 构建预测模型, 确定最优回归方程。采用30部电影中27部电影数据作为模型构建数据, 3部电影作为检验数据。
由于数据涉及到多个变量, 但无法判断各变量在模型中关联程度的大小, 因此使用多元线性回归, 观察各变量P值的大小, 结果如表4所示。
表4 多元线性回归各变量P值
| 变量名 | P值 |
|---|---|
| LcriticNum | 0.142 |
| LcommentNum | 0.217 |
| LwatchedNum | 0.304 |
| LdesireNum | 0.151 |
| commentRatio | 0.359 |
| desireRatio | 0.308 |
| sentimentmeanScore | 0.824 |
| posmeanScore | 0.427 |
| negmeanScore | 0.820 |
当所有变量加入到多元线性回归时, 最大值wacthedNum为0.75, 远大于0.05; 最小值LcriticNum也达到0.142, 所有变量的P值均大于0.05。构建多元线性回归模型失败, 需要对变量进行筛选。
使用逐步回归、岭回归以及套索回归分别对模型进行变量选取, 并观察各个变量的P值, 如表5所示。
表5 三种回归方法各变量P值
| 回归方法 | 变量名 | P值 |
|---|---|---|
| 逐步回归 | LcriticNum | 0.0320 |
| LcommentNum | 0.0046 | |
| LwacthedNum | 0.0728 | |
| LdesireNum | 0.0027 | |
| posmeanScore | 0.0020 | |
| 岭回归 | LdesireNum | 0.0001 |
| commentRatio | 0.0336 | |
| posmeanScore | 0.0020 | |
| 套索回归 | LdesireNum | 0.0001 |
| sentimentmeanScore | 0.0003 |
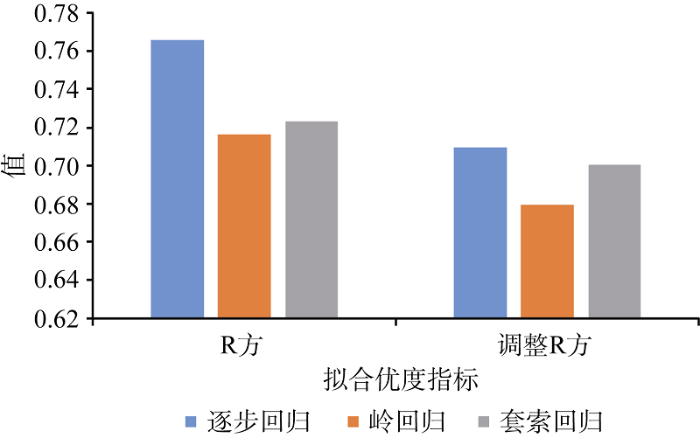
通过对比逐步回归、岭回归、套索回归三种回归分析的统计量来分析上述三种模型的实际预测效果, 各P值均表示模型显著, 进一步探索三种模型R方和调整R方, 如图4所示。
岭回归在两个指标上都是最弱的, 且调整R方的值与逐步回归、套索回归的差距非常大。对于调整R方, 逐步回归的值和套索回归的值相对较高, 但是逐步回归的R方值最高, 达到0.7656, 拟合效果较佳。因此, 最优选择为逐步回归方法构建的回归方程, 如公式(7)所示。
$\begin{align} & Y\text{=}-\text{12}\text{.9328+35}\text{.7904}\times LcriticNum-\text{11}\text{.5032}\times \\ & \ \ \ \ \ LcommentNum-\text{24}\text{.6262}\times LwacthedNum\text{+} \\ & \ \ \ \ \ \text{2}\text{.9563}\times LdesireNum\text{+}\ \text{1}\text{.2417}\times posmeanScore \\ \end{align}$ (7)
预测分析后, 还需对得到的预测模型进行评价。若出现异常值, 需分析原因, 剔除异常值后重构模型, 并用检验数据对模型进行检验。
(1) 预测结果分析
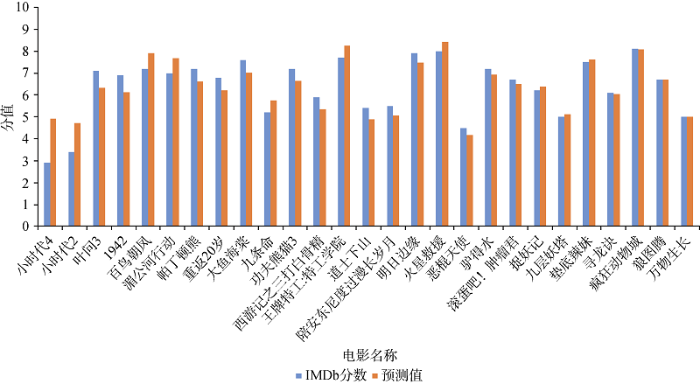
使用最优回归方程公式(7)对各电影评分进行预测, 结果如图5所示。
通过拟合IMDb分数与评分预测值, 可以发现大部分电影之间的差距很小, 误差值在很小的范围内, 说明预测模型整体上是有效的。其中有几部电影差距较为明显, 例如《小时代2》和《小时代4》预测分数明显大于其IMDb分数。
(2) 异常值发现
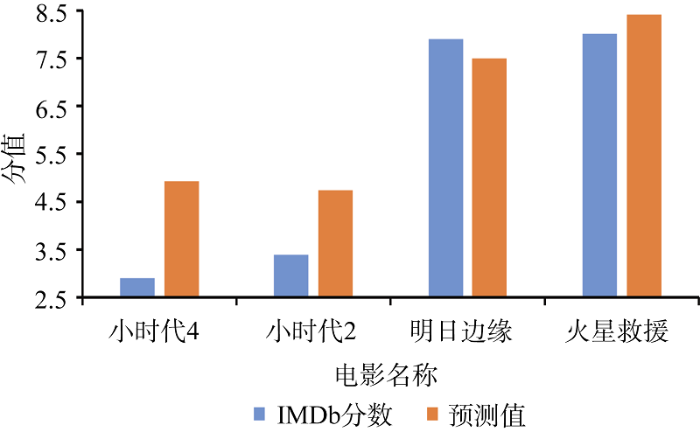
从模型的预测结果来看, 正常电影评分预测值和IMDb值之间差距往往不超过1分, 本文定义预测值与IMDb值差距超过1分的为异常值, 如图6所示。
从图6可知, 拟合正常情况下的电影如《明日边缘》、《火星救援》, 预测值与IMDb分数的差距很小。而《小时代2》、《小时代4》 预测值与IMDb值差距超过1分, 甚至2分。可以判断这两部电影的评论数据情感倾向具有非真实性。通过查阅新闻和文献证实两部电影确实存在刷分行为, 说明本模型不仅具有评分预测的作用, 在“网络水军”探测方面也发挥一定的作用。
(3) 剔除异常值并重构模型
为避免异常值对模型的干扰, 剔除《小时代2》和《小时代4》的数据, 利用逐步回归的方法重新构建预测方程。此外, 新的回归模型剔除了P值略高的LwatchedNum, 仅使用LcriticNum、LcommentNum、LdesireNum以及posmeanScore, 这些变量的P值都具有极高的显著性, 如表6所示, 构建回归方程如公式(8)所示。
$\begin{align} & Y\text{=}-\text{11}\text{.1349+7}\text{.4531}\times LcriticNum-\text{7}\text{.4636}\times LcommentNum \\ & \ \ \ \ \ +\text{2}\text{.3371}\times LdesireNum\text{+1}\text{.1499}\times posmeanScore \\ \end{align}$ (8)
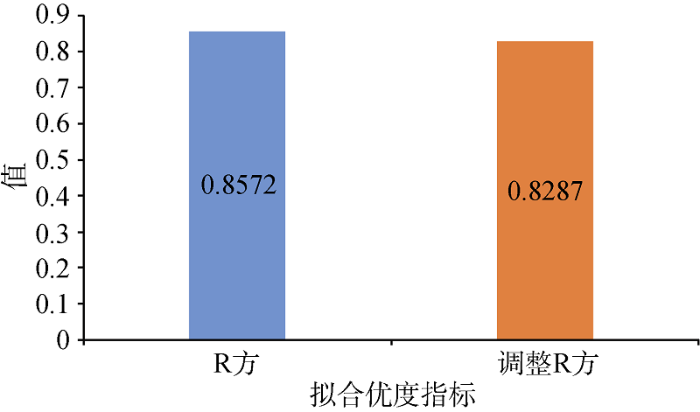
新的回归分析结果的统计量如图7所示, 剔除异常值后的R方和调整R方明显提升, R方的值达到0.8572, 调整R方的值达到0.8287, 模型的预测效果较好。
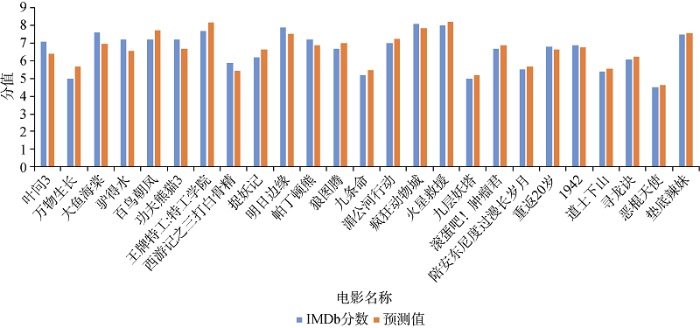
对比新模型拟合的预测值与IMDb分数如图8所示, 可以明显看出, 各个电影的预测值和IMDb值之间差距较小, 最大差距的为《叶问3》, 差值为0.7分; 最小差距的为《垫底辣妹》, 差值仅为0.05分。因此, 公式(8)具有较好的预测效果, 根据方程中的变量要求, 仅需要其电影的LcriticNum、LcommentNum、LdesireNum和posmeanScore就可以对电影的客观评分进行预测。
(4) 模型检验
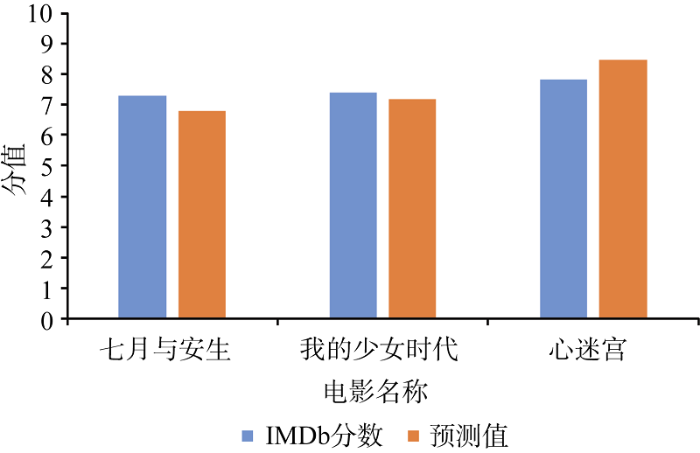
为了检验模型实际效果, 使用预留的三部电影数据进行评分预测, 分别为《心迷宫》、《七月与安生》以及《我的少女时代》, 相关变量如表7所示。
表7 评分预测模型检验数据
| 电影名称 | LcriticNum | LcommentNum | LdesireNum | posmeanNum |
|---|---|---|---|---|
| 心迷宫 | 5.1247 | 4.7244 | 4.6835 | 4.9646 |
| 七月与安生 | 5.2082 | 4.8858 | 4.2882 | 4.8169 |
| 我的少女时代 | 5.3919 | 5.0585 | 4.4110 | 4.8415 |
利用公式(8)对三部电影的评分进行预测, 结果如图9所示。
可以看出三部电影的评分预测值与IMDb实际值都很接近且误差很小, 《七月与安生》的误差为0.0522, 《我的少女时代》的误差为0.0227, 《心迷宫》的误差为0.0644, 因此, 模型的实际预测效果较理想。
互联网环境下, 评分网站不容忽视, 一方面为潜在消费者选购商品提供决策参考, 另一方面为商家提供商机。评分网站由于开放性导致产品评分失真, 客观的评分网站需求愈发迫切。本文提出基于网络用户评论的评分预测模型来预测客观评分, 该模型主要包括网络用户评论获取、预测变量获取、预测分析以及预测结果评价4个模块。为验证评分预测模型的有效性, 以“豆瓣电影”的评论内容作为语料来源, 以IMDb作为客观评分来源。对近年来30部不同类型的电影影评进行实证研究, 结果显示, 在评分预测模型中, 电影上映30天时的评论数据稳定性最高, 最适合用作预测数据源。在回归分析中, 逐步回归方式筛选出变量构建的回归方程预测效果最优。在预测分数和IMDb分数拟合阶段, 发现异常值, 说明本模型不仅具有评分预测的作用, 在“网络水军”探测方面也有一定的作用。剔除异常值后, 仅需要其电影的LcriticNum、LcommentNum、LdesireNum和posmeanScore变量就可以对电影的客观评分进行预测, 重构模型之后利用三部电影对模型评分预测效果进行检验, 预测评分效果较佳。
本文存在以下不足之处: 数据样本量较少, 可考虑通过增加数据量优化模型预测效果; 此外, 在情感分析技术方面, 主要是基于词典技术进行情感特征提取, 未来可尝试结合机器学习方法或者其他前沿的情感分析技术进一步精确提取情感特征; 除了以电影评分网站作为实例外, 可选取其他类型评分网站的数据进行实证研究, 以验证模型的普适性。
徐健: 提出研究思路, 设计研究方案;
刘济郢: 采集、清洗和分析数据, 进行实验;
张红丽: 论文起草;
张红丽, 杨斯楠, 徐健: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据[1-3]见期刊网络版http://www.infotech.ac.cn; 支撑数据[4-7]由作者自存储, E-mail: issxj@mail.sysu.edu.cn。
[1] 张红丽, 刘济郢, 杨斯楠, 徐健. movies.docx. 30部电影选取完整表.
[2] 张红丽, 刘济郢, 杨斯楠, 徐健. variable list.docx. 各电影相关数据一览表.
[3] 张红丽, 刘济郢, 杨斯楠, 徐健. 停用词表.docx. 去除停用词用的停用词表.
[4] 张红丽, 刘济郢, 杨斯楠, 徐健. 爬虫代码.docx. 集搜客豆瓣影评爬虫规则.
[5] 张红丽, 刘济郢, 杨斯楠, 徐健. 分词代码.docx. Python下结巴中文词源代码.
[6] 张红丽, 刘济郢, 杨斯楠, 徐健. 情感值代码.docx. Python下情感量化源代码.
[7] 张红丽, 刘济郢, 杨斯楠, 徐健. 回归分析代码.docx. R语言回归分析源代码.
| [1] |
“网络水军”的传播学分析 [J].
因特网已渗入到社会生活的每个角落,其高度的双向互动性弥补了传统媒体的不足,大大提高了一般受众的媒介信息传播地位,尤其是博客、论坛等的兴起,使受众真正实现了各抒己见。网络舆论似乎正处于一个高度自由、自发有序的状态,然而看似平静的网络环境下却隐藏着一股不易觉察的"暗流"——"网络水军",这股暗流在很大程度上操纵着网络舆论,且有愈演愈烈之势。本文拟以理论和案例相结合的方式,从传播学角度分析"网络水军"泛滥的原理机制,阐释"网络水军"造成的危害,并对如何打击这一现象提出一些相应的措施。
A Communicational Analysis of the “Water-forces in the Network” [J].
因特网已渗入到社会生活的每个角落,其高度的双向互动性弥补了传统媒体的不足,大大提高了一般受众的媒介信息传播地位,尤其是博客、论坛等的兴起,使受众真正实现了各抒己见。网络舆论似乎正处于一个高度自由、自发有序的状态,然而看似平静的网络环境下却隐藏着一股不易觉察的"暗流"——"网络水军",这股暗流在很大程度上操纵着网络舆论,且有愈演愈烈之势。本文拟以理论和案例相结合的方式,从传播学角度分析"网络水军"泛滥的原理机制,阐释"网络水军"造成的危害,并对如何打击这一现象提出一些相应的措施。
|
| [2] |
What Makes a Helpful Online Review? A Study of Customer Reviews on Amazon.com [J].https://doi.org/10.1007/s10107-008-0244-7 URL [本文引用: 1] 摘要
Customer reviews are increasingly available online for a wide range of products and services. They supplement other information provided by electronic storefronts such as product descriptions, reviews from experts, and personalized advice generated by automated recommendation systems. While researchers have demonstrated the benefits of the presence of customer reviews to an online retailer, a largely uninvestigated issue is what makes customer reviews helpful to a consumer in the process of making a purchase decision. Drawing on the paradigm of search and experience goods from information economics, we develop and test a model of customer review helpfulness. An analysis of 1,587 reviews from Amazon.com across six products indicated that review extremity, review depth, and product type affect the perceived helpfulness of the review. Product type moderates the effect of review extremity on the helpfulness of the review. For experience goods, reviews with extreme ratings are less helpful than reviews with moderate ratings. For both product types, review depth has a positive effect on the helpfulness of the review, but the product type moderates the effect of review depth on the helpfulness of the review. Review depth has a greater positive effect on the helpfulness of the review for search goods than for experience goods. We discuss the implications of our findings for both theory and practice.
|
| [3] |
Analysis of Review Helpfulness Based on Consumer Perspective [J].https://doi.org/10.1109/TST.2015.7128942 URL [本文引用: 1] 摘要
When consumers make purchase decisions, they generally refer to the reviews generated by other consumers who have already purchased similar products in order to get more information. Online transaction platforms provide a highly convenient channel for consumers to generate and retrieve product reviews. In addition, consumers can also vote reviews perceived to be helpful in making their decision. However, due to diverse characteristics, consumers can have different preferences on products and reviews. Their voting behavior can be influenced by reviews and existing review votes. To explore the influence mechanism of the reviewer, the review, and the existing votes on review helpfulness, we propose three hypotheses based on the consumer perspective and perform statistical tests to verify these hypotheses with real review data from Amazon. Our empirical study indicates that review helpfulness has significant correlation and trend with reviewers, review valance, and review votes. In this paper, we also discuss the implications of our findings on consumer preference and review helpfulness.
|
| [4] |
基于信息采纳理论的在线商品评论有用性影响因素研究 [J].A Research of Factors Affecting the Perceived Helpfulness of Online Product Based on the Information Adoption Theory [J]. |
| [5] |
What Makes a Review Voted? An Empirical Investigation of Review Voting in Online Review Systems [J].
AbstractMany online review systems adopt a voluntary voting mechanism to identify helpful reviews...
|
| [6] |
电子商务网站在线评论对手机销量影响的实证研究 [J].https://doi.org/10.7535/hbgykj.2016yx03002 URL [本文引用: 1] 摘要
采用数据抓取方法获取京东商城在线评论数据,使用SPSS软件对数据进行多元回归,通过评论数量、负面评论、评论长度和评论时效性4个维度,研究了在线评论对电子商务网站产品销量的影响,并按照品牌的热门程度将产品分类,进一步分析了品牌对负面评论和评论时效性是否具有调节作用。研究发现,评论长度、评论时效性对销量具有显著的正向影响,而评论数量、负面评论和产品价格对销量具有显著的负向影响。在品牌的调节作用下,评论时效性的影响力减弱,而负面评论对销量的影响则增强。根据研究结果,提出改善电子商务网站在线评论机制的针对性建议。
An Empirical Study of the Impact of Online Reviews on Mobile Phone Sales in E-commerce [J].https://doi.org/10.7535/hbgykj.2016yx03002 URL [本文引用: 1] 摘要
采用数据抓取方法获取京东商城在线评论数据,使用SPSS软件对数据进行多元回归,通过评论数量、负面评论、评论长度和评论时效性4个维度,研究了在线评论对电子商务网站产品销量的影响,并按照品牌的热门程度将产品分类,进一步分析了品牌对负面评论和评论时效性是否具有调节作用。研究发现,评论长度、评论时效性对销量具有显著的正向影响,而评论数量、负面评论和产品价格对销量具有显著的负向影响。在品牌的调节作用下,评论时效性的影响力减弱,而负面评论对销量的影响则增强。根据研究结果,提出改善电子商务网站在线评论机制的针对性建议。
|
| [7] |
线上消费者评论如何影响产品销量?——基于在线图书评论的实证研究 [J].How do Online Consumer Reviews Influence Product Sales? —An Empirical Study Based on Online Book Reviews .[J] |
| [8] |
Consumer Reviews and the Creation of Booking Transaction Value: Lessons from the Hotel Industry [J].https://doi.org/10.1016/j.ijhm.2015.07.012 URL [本文引用: 1] 摘要
In recent years, much has been said about online consumer-generated feedback. Concern typically emerges regarding consumer decision-making as well as the preservation of an organization's image. Additionally, a company's financial performance can be affected by customer online ratings. The present study explores the impact of a hotel's rating and number of reviews on the value generated through online transactions. Through collaboration with consulting company Travel Click, the research team gathered a sample of 178 hotels representing various companies and brands within the United States. Research results demonstrate that TripAdvisor ratings as well as the number of reviews had positive relationship with the average size of each online booking transaction. The paper concludes with theoretical and practical implications.
|
| [9] |
The Effects of Online User Reviews on Movie Box Office Performance: Accounting for Sequential Rollout and Aggregation Across Local Markets [J].https://doi.org/10.2139/ssrn.1331124 URL [本文引用: 1] 摘要
Our objective in this paper is to measure the impact of national online user reviews (valence, volume and variance) on Designated Market Area (DMA) level local
|
| [10] |
Opinion Observer: Analyzing and Comparing Opinions on the Web [C]// |
| [11] |
汉语组块分析在产品特征提取中的应用研究 [J].Research of Chinese Chunk Parsing in Application of the Product Feature Extraction [J]. |
| [12] |
网络产品评论挖掘研究 [J].https://doi.org/10.3969/j.issn.1003-3254.2014.02.001 URL Magsci [本文引用: 1] 摘要
以有效分析和挖掘网络产品评论中的用户观点从而为消费者和商家均提供有价值的信息为目的,提出了网络产品评论挖掘的步骤和方法,并在用户产品评论分析的基础上,进一步对产品特征词的关注度和极性进行分析,实现了更加全面地产品评论挖掘。最后以iphone 4s为例对所提出的方法进行了实验,验证了该方法的可行性。
Research on Online Product Review Mining [J].https://doi.org/10.3969/j.issn.1003-3254.2014.02.001 URL Magsci [本文引用: 1] 摘要
以有效分析和挖掘网络产品评论中的用户观点从而为消费者和商家均提供有价值的信息为目的,提出了网络产品评论挖掘的步骤和方法,并在用户产品评论分析的基础上,进一步对产品特征词的关注度和极性进行分析,实现了更加全面地产品评论挖掘。最后以iphone 4s为例对所提出的方法进行了实验,验证了该方法的可行性。
|
| [13] |
评论文本对酒店满意度的影响: 基于情感分析的方法 [J].
【目的】通过对评论文本进行文本分析,研究影响酒店用户满意度的因素,为酒店管理者提供建议。【方法】利用word2Vec对Tripadvisor.com酒店评论进行特征抽取和降维,结合情感分析技术,提取每类特征对应的情感,构建计量经济模型分析酒店特征评价与用户满意度的关系。【结果】研究结果表明:(1)评论文本的情感表达越积极满意度越高,但这种影响并非线性的,而是呈现“u”形的;(2)用户评论文本中提到的特征类别数越多,该用户越有可能倾向不满意;(3)消费者对豪华型酒店和经济型酒店特征类别的关注存在显著差异,消费者对前者更关注员工服务,对后者更注重清洁度;(4)对豪华型酒店,消费者满意度受到网络(Intemet)这个特征维度的显著影响,而对于经济型酒店该维度的影响则不显著。【局限】样本的选择不够全面,未来可爬取多个城市数据进行更全面分析。【结论】从评论文本角度建立了酒店特征与消费者满意度的联系,为酒店在线口碑研究提供了理论依据。
The Impacts of Reviews on Hotel Satisfaction: A Sentiment Analysis Method [J].
【目的】通过对评论文本进行文本分析,研究影响酒店用户满意度的因素,为酒店管理者提供建议。【方法】利用word2Vec对Tripadvisor.com酒店评论进行特征抽取和降维,结合情感分析技术,提取每类特征对应的情感,构建计量经济模型分析酒店特征评价与用户满意度的关系。【结果】研究结果表明:(1)评论文本的情感表达越积极满意度越高,但这种影响并非线性的,而是呈现“u”形的;(2)用户评论文本中提到的特征类别数越多,该用户越有可能倾向不满意;(3)消费者对豪华型酒店和经济型酒店特征类别的关注存在显著差异,消费者对前者更关注员工服务,对后者更注重清洁度;(4)对豪华型酒店,消费者满意度受到网络(Intemet)这个特征维度的显著影响,而对于经济型酒店该维度的影响则不显著。【局限】样本的选择不够全面,未来可爬取多个城市数据进行更全面分析。【结论】从评论文本角度建立了酒店特征与消费者满意度的联系,为酒店在线口碑研究提供了理论依据。
|
| [14] |
基于评论主题分析的评分预测方法研究 [J].A Review Topic Analysis Method for Rating Prediction [J]. |
| [15] |
Understanding Rating Behaviour and Predicting Ratings by Identifying Representative Users [OL].
Online user reviews describing various products and services are now abundant on the web. While the information conveyed through review texts and ratings is easily comprehensible, there is a wealth of hidden information in them that is not immediately obvious. In this study, we unlock this hidden value behind user reviews to understand the various dimensions along which users rate products. We learn a set of users that represent each of these dimensions and use their ratings to predict product ratings. Specifically, we work with restaurant reviews to identify users whose ratings are influenced by dimensions like 'Service', 'Atmosphere' etc. in order to predict restaurant ratings and understand the variation in rating behaviour across different cuisines. While previous approaches to obtaining product ratings require either a large number of user ratings or a few review texts, we show that it is possible to predict ratings with few user ratings and no review text. Our experiments show that our approach outperforms other conventional methods by 16-27% in terms of RMSE.
|
| [16] |
Modeling Online Reviews with Multi-grain Topic Models [C]// |
| [17] |
基于评论情感分析的用户在线评价研究——以豆瓣网电影为例 [J].https://doi.org/10.13266/j.issn.0252-3116.2016.10.013 URL [本文引用: 1] 摘要
[目的/意义]鉴于网络用户评价已成为人们选择产品或服务时的重要参考指标,旨在了解打分评价和评论评价之间的关系,同时为仅有评论评价的网站提供符合潜在分值的排序和推荐功能.[方法/过程]通过抓取豆瓣电影的用户评价,使用ROST EA工具进行情感分析得到评论评价的综合情绪值,将其与打分评价进行相关分析,并考虑评论文本的情感强度赋权对结果造成的差异,在此基础上通过回归分析构建回归模型并对其进行检验.[结果/结论]发现评论评价的综合情绪值与打分评价相关性较高,情感强度的赋权情况对结果影响不大,说明可以根据评论评价预测打分,据此给出相应的回归模型.
Study on User Online Evaluation Based on Sentiment Analysis of Comments: Taking Douban.com Movie as an Example [J].https://doi.org/10.13266/j.issn.0252-3116.2016.10.013 URL [本文引用: 1] 摘要
[目的/意义]鉴于网络用户评价已成为人们选择产品或服务时的重要参考指标,旨在了解打分评价和评论评价之间的关系,同时为仅有评论评价的网站提供符合潜在分值的排序和推荐功能.[方法/过程]通过抓取豆瓣电影的用户评价,使用ROST EA工具进行情感分析得到评论评价的综合情绪值,将其与打分评价进行相关分析,并考虑评论文本的情感强度赋权对结果造成的差异,在此基础上通过回归分析构建回归模型并对其进行检验.[结果/结论]发现评论评价的综合情绪值与打分评价相关性较高,情感强度的赋权情况对结果影响不大,说明可以根据评论评价预测打分,据此给出相应的回归模型.
|
| [18] |
面向网络游记时间特征的情感分析模型 [J].A Sentiment Analysis Model Based on Temporal Characteristics of Travel Blogs [J]. |
| [19] |
在线中文用户评论研究综述: 基于情感计算的视角 [J].Research on Online Users’ Reviews in Chinese: Basing on the Perspective of Affective Computing [J]. |
| [20] |
多元线性回归统计预测模型的应用 [J].
文章以俄亥俄州(Ohio)的气象、臭氧监测数据为基础,对其中一个监测点数据进行了分析处理;运用多元线性回归方法,建立臭氧含量与气象的回归方程;以F值检验回归关系的显著性,并作预测评价,预测结果的误差较小,符合实际情况,能够较好地解决实际问题。
Application of Multivariate Linear Regression Statistical Prediction Model [J].
文章以俄亥俄州(Ohio)的气象、臭氧监测数据为基础,对其中一个监测点数据进行了分析处理;运用多元线性回归方法,建立臭氧含量与气象的回归方程;以F值检验回归关系的显著性,并作预测评价,预测结果的误差较小,符合实际情况,能够较好地解决实际问题。
|
| [21] |
美国电影网站IMDb的榜单文化研究 [D].An Empirical Analysis of Factors Influencing the Helpfulness of Online Consumer Reviews [D]. |
| [22] |
GooSeeker集搜客网络爬虫, 简单高效的网页采集器 [EB/OL]. [GooSeeker Web Crawler, Simple and Efficient Web Collector [EB/OL]. [ |
| [23] |
情感词汇本体的构造 [J].https://doi.org/10.3969/j.issn.1000-0135.2008.02.004 URL [本文引用: 1] 摘要
情感计算是目前人工智能领域的热门课题,而大规模的情感词汇本体的构造是准确完成文本情感识别的基础。本文首先根据目前情感分类发展的现状,确定情感分类体系,在此基础上综合现有的各种情感词汇资源构造情感词汇本体。在本体的知识获取过程中采用手工分类和自动获取相结合的方法填充词汇本体的框架。详细描述了词汇的情感类别、强度和极性等,并进一步统计了情感词汇的分布情况。
Constructing the Affective Lexicon Ontology [J].https://doi.org/10.3969/j.issn.1000-0135.2008.02.004 URL [本文引用: 1] 摘要
情感计算是目前人工智能领域的热门课题,而大规模的情感词汇本体的构造是准确完成文本情感识别的基础。本文首先根据目前情感分类发展的现状,确定情感分类体系,在此基础上综合现有的各种情感词汇资源构造情感词汇本体。在本体的知识获取过程中采用手工分类和自动获取相结合的方法填充词汇本体的框架。详细描述了词汇的情感类别、强度和极性等,并进一步统计了情感词汇的分布情况。
|
| [24] |
7 Types of Regression Techniques You Should Know! [EB/OL]. [2017-03-20]. . |
| [25] |
Evaluation of Multivariate Linear Regression and Artificial Neural Networks in Prediction of Water Quality Parameters[J/OL]. URL PMID: 3906747 [本文引用: 1] 摘要
This paper examined the efficiency of multivariate linear regression (MLR) and artificial neural network (ANN) models in prediction of two major water quality parameters in a wastewater treatment plant. Biochemical oxygen demand (BOD) and chemical oxygen demand (COD) as well as indirect indicators of organic matters are representative parameters for sewer water quality. Performance of the ANN models was evaluated using coefficient of correlation (r), root mean square error (RMSE) and bias values. The computed values of BOD and COD by model, ANN method and regression analysis were in close agreement with their respective measured values. Results showed that the ANN performance model was better than the MLR model. Comparative indices of the optimized ANN with input values of temperature (T), pH, total suspended solid (TSS) and total suspended (TS) for prediction of BOD was RMSE65=6525.102mg/L, r65=650.83 and for prediction of COD was RMSE65=6549.402mg/L, r65=650.81. It was found that the ANN model could be employed successfully in estimating the BOD and COD in the inlet of wastewater biochemical treatment plants. Moreover, sensitive examination results showed that pH parameter have more effect on BOD and COD predicting to another parameters. Also, both implemented models have predicted BOD better than COD.
|
| [26] |
Citation Impact Prediction for Scientific Papers Using Stepwise Regression Analysis [J].https://doi.org/10.1007/s11192-014-1279-6 URL [本文引用: 1] 摘要
Researchers typically pay greater attention to scientific papers published within the last 2 years, and especially papers that may have great citation impact in the future. However, the accuracy of current citation impact prediction methods is still not satisfactory. This paper argues that objective features of scientific papers can make citation impact prediction relatively accurate. The external features of a paper, features of authors, features of the journal of publication, and features of citations are all considered in constructing a paper feature space. The stepwise multiple regression analysis is used to select appropriate features from the space and to build a regression model for explaining the relationship between citation impact and the chosen features. The validity of this model is also experimentally verified in the subject area of Information Science & Library Science. The results show that the regression model is effective within this subject.
|
| [27] |
R3P-Loc: A Compact Multi-label Predictor Using Ridge Regression and Random Projection for Protein Subcellular Localization [J].https://doi.org/10.1016/j.jtbi.2014.06.031 URL PMID: 24997236 [本文引用: 1] 摘要
Locating proteins within cellular contexts is of paramount significance in elucidating their biological functions. Computational methods based on knowledge databases (such as gene ontology annotation (GOA) database) are known to be more efficient than sequence-based methods. However, the predominant scenarios of knowledge-based methods are that (1) knowledge databases typically have enormous size and are growing exponentially, (2) knowledge databases contain redundant information, and (3) the number of extracted features from knowledge databases is much larger than the number of data samples with ground-truth labels. These properties render the extracted features liable to redundant or irrelevant information, causing the prediction systems suffer from overfitting. To address these problems, this paper proposes an efficient multi-label predictor, namely R3P-Loc, which uses two compact databases for feature extraction and applies random projection (RP) to reduce the feature dimensions of an ensemble ridge regression (RR) classifier. Two new compact databases are created from Swiss-Prot and GOA databases. These databases possess almost the same amount of information as their full-size counterparts but with much smaller size. Experimental results on two recent datasets (eukaryote and plant) suggest that R3P-Loc can reduce the dimensions by seven-folds and significantly outperforms state-of-the-art predictors. This paper also demonstrates that the compact databases reduce the memory consumption by 39 times without causing degradation in prediction accuracy. For readers convenience, the R3P-Loc server is available online at url: http://bioinfo.eie.polyu.edu.hk/R3PLocServer/ .
|
| [28] |
A Risk Model for Prediction of 1-Year Mortality in Patients Undergoing MitraClip Implantation [J].https://doi.org/10.1016/j.amjcard.2017.01.024 URL PMID: 28274574 [本文引用: 1] 摘要
There is a lack of specific tools for risk stratification in patients undergoing MitraClip implantation. We aimed at combining pre-procedural variables with prognostic impact into a specific risk model for the prediction of 1-year mortality in patients undergoing MitraClip implantation. A total of 311 consecutive patients undergoing MitraClip implantation were included. A lasso-penalized Cox-proportional hazard regression model was used to identify independent predictors of 1-year all cause mortality. A nomogram (GRASP nomogram) was obtained from the Cox model. Validation was performed using internal bootstrap resampling. Forty-two deaths occurred at 1-year follow-up. The Kaplan-Meier estimate of 1-year survival was 0.845 (95% confidence interval, 0.802-0.895). Four independent predictors of mortality (mean arterial blood pressure, hemoglobin and log-transformed pro-brain natriuretic peptide levels, NYHA class IV at presentation) were identified. At internal bootstrap resampling validation, the GRASP nomogram had good discrimination (area under ROC curve of 0.78, Somers Dxy statistic of 0.53) and calibration (le Cessie-van Houwelingen-Copas-Hosmer p-value of 0.780). Conversely, the discriminative ability of the euroSCORE II and the STS-PROM was fairly modest with AUC values of 0.61 and 0.55, respectively. A treatment-specific risk model in patients undergoing MitraClip implantation may be useful for the stratification of mortality at 1 year. Further studies are needed to provide external validation and support the generalizability of the GRASP nomogram.
|

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}