涂海丽 , 唐晓波
, 唐晓波
Tu Haili, Tang Xiaobo
中图分类号: G35
通讯作者:
收稿日期: 2016-12-7
修回日期: 2017-05-4
网络出版日期: 2017-09-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】构建社会化电子商务环境下基于标签的个性化商品推荐模型。【方法】综合考虑用户使用标签的频率和时间因素计算用户的兴趣偏好; 基于标签层次特征和电子商务网站中关于商品特征的检索条件, 构建某一主题商务社区中商品本体; 利用本体规范化用户标签语义, 并对商品进行分类; 寻找含有用户偏好的类簇, 计算该类簇中商品与用户偏好商品的相似度, 将用户未标注过的商品与用户偏好相似度高的商品推荐给用户。【结果】从翻东西网站上随机选取200个活跃用户关于热门商品的标注信息进行分析, 验证该模型的有效性。【局限】在计算用户兴趣偏好时, 只考虑用户使用标签的频率和时间因素, 未考虑其他因素。【结论】该模型相对于利用标签进行协同过滤推荐方法具有较优的效果, 计算时间和空间复杂度更小。
关键词:
Abstract
[Objective] This paper proposes a personalized product recommendation model based on tags in the social e-commerce environment. [Methods] First, we calculated users’ interests and preferences with the help of tagging frequency and time. Then, we constructed a product ontology of the commercial community based on the tag features and searching conditions of the e-commerce website. Third, we used the ontology to standardize tag semantics, and to classify goods. Fourth, we found clusters containing user preferences, and calculated the similarity between their tags of goods and user preference in the cluster. Finally, we identified the goods which were not tagged but preferred by a specific user. [Results] We examined the model with information of 200 randomly selected active users of popular items from the website of FanDongXi. [Limitations] Only used the frequency and time factor of the users’ tags to calculate their interests and preferences. [Conclusions] The proposed method has better performance than the collaborative filtering recommendation based methods.
Keywords:
商品推荐的目标是综合运用各种方法建立用户兴趣偏好与商品之间的关联, 并主动呈现给用户。商品标签是用户关于商品描述的元数据, 本文研究的标签对象是社会化电子商务中用户自由标注的标签, 具有可挖掘的重要信息: 用户主动标注物品的行为反映了用户的认知模式和兴趣偏好; 标签能够反映物品特征。大量用户为物品添加描述性标签, 高频标签代表用户对相同物品特征的广泛认同; 标签具有可检索性。作为用户和物品间的桥梁, 标签系统一般提供通过标签检索物品的链接。社会化电子商务中由购物达人或普通用户自由标注的标签居多, 但会出现一词多义或一义多词的现象, 使标签的词表变得庞大。由于标签的大众化特征, 同一社区的很多标签都是杂乱无章的, 标签与用户、标签与物品之间可以是多对多的关系, 加大标签组织和利用的难度, 使得标签相似度计算不准确。因此, 作为一种原生态的自然语言, 标签语义的模糊性(即一词多义)、标签形式的多样性(即一义多词)和标签结构的扁平化(缺乏直接的层次逻辑关系), 极大地限制了其在个性化推荐中的作用, 在基于标签的推荐系统中, 推荐准确性低, 用户体验差。如何减少标签冗余和歧义给推荐带来的干扰、在扁平化的标签列表中发现它们之间的关联, 从而明确标签所表达的语义和主题, 是更好地将标签应用于商品推荐的关键。本文主要讨论社会化电子商务中UGC标签的应用, 研究如何利用本体序化用户标签及商品标签, 从中获取用户偏好及商品特征的主题描述, 探讨如何建立用户偏好与商品特征之间的关联, 从而为用户推荐个性化商品。
根据推荐算法的不同, 国内外对基于标签的推荐研究方法主要归纳为以下几种。
(1) 矩阵分解。将用户、用户标注的资源以及标注的标签三者之间的三元关系矩阵分解成两两组合的二维矩阵, 先发现两两之间的关系, 再进行综合, 找到三者的对应关系, 这样既可以减少矩阵计算复杂性, 也能够实现标签或资源的推荐[1-3], 该方法是基于标签的推荐系统中的研究热点之一。
(2) 张量分解。该方法不进行三元矩阵分解, 而是利用奇异值分解的方法进行降维, 然后排序标签, 实现标签推荐; 也可以根据标签与资源的关联关系, 向用户推荐资源。
(3) 聚类方法。将标签、用户和资源分别进行聚类, 具体如下:
①用户聚类。根据现有标签或资源的相似可以推测用户兴趣的相似, 相似用户会有更多潜在共性, 甚至可以结成一个特殊的社群[4-5]。
②资源聚类。通过资源聚类发现资源中的“睡美人”, 提高资源推荐的覆盖率。
③标签聚类。这是当前标签推荐或利用标签的资源推荐需要聚类时的首选。主要是依据标签共现次数聚类标签, 常用的聚类算法有K-means、Markov等, 利用聚类结果中标签之间的关联, 计算对应资源间的相似度, 进行资源推荐[6]。Niwa等[7]在利用TF-IDF公式计算标签权重的基础上聚类标签, 据此计算用户偏好资源与聚类中标签对应资源的相似度, 实现资源推荐。Gemmell等[8]对标签进行层次聚类, 基于此构建用户兴趣模型。杨丹等[9]通过标签聚类计算用户与标签的相似度, 实现网页推荐。
(4) 图论方法。该方法利用网络图表达用户、用户标注的资源以及标注的标签三者之间的关系, 利用社会网络分析方法进行用户偏好建模, 从而实现基于内容的资源推荐或资源协同推荐[10-11]。图论方法中的典型代表是Hotho等[12]研究出的FolkRank算法。该算法利用无向图表达用户、用户标注的资源以及标注的标签三者之间的关系。图中的节点是三者的并集, 边是两两之间的共现值, 通过对图中各元素的关联度分析, 找出重要标签并排序, 将重要标签对应的资源推荐给用户。构图只是基础, 重要的是对图的分析, 社会网络分析方法才是图论方法的核心, 受到学者们的重点关注。
此外, 还有一些其他的研究视角和方法。如 Schmitz等[13]利用数据挖掘技术中的关联规则挖掘研究对象的分类结构特征, 进行人员、标签和项目的推荐。曹高辉等[14]认为每个标签可以看成一个概念, 标签集合构成概念空间, 并具有层次结构, 通过构建标签层次结构实现资源的个性化推荐。田莹颖[15]认为用户标注行为存在兴趣漂移的问题, 提出利用TF-IDF和后控词表, 给用户最近标注的标签设置较高的时间权重, 计算用户之间的相似度, 找出共同标注的信息资源, 并通过标签对用户与资源进行匹配, 将相匹配的信息推荐给目标用户。邓双义[16]将标签作为媒介, 利用WordNet语义, 计算用户偏好的标签集与资源的标签集的相似度, 将相似度高的标签分别对应的用户和资源进行比对, 并将相匹配的资源推荐给用户。还有将以上主要方法相结合的混合推荐方法, Rafailidis等[17]先对标签、用户和资源三阶矩阵利用张量分解方法降维, 然后对标签聚类, 既解决了三元矩阵计算复杂度高的问题, 也避免了稀疏矩阵对相似度计算的影响, 对两种方法扬长避短, 实现了资源的个性化推荐。还有根据标签的流行度、时间特征或标签的代表性、用户与标签的亲和力等刻画用户对资源的偏好, 采用梯度下降法对用户-资源矩阵进行分解, 利用分解后的特征矩阵对目标用户进行预测并推荐[18-19]。
虽然学者们从多个视角研究了基于标签的推荐算法来解决推荐研究中固有的问题, 并试图避免标签本身的缺陷带来的新问题。但是, 这些基于标签的推荐算法仍然存在如下不足:
(1) 不管是矩阵方法还是图论方法, 计算复杂度都很高;
(2) 虽然标签总量较大, 但部分单个用户所标注标签数目较少, 难以准确获取用户偏好, 限制了推荐的效果;
(3) 标签语义存在歧义, 造成数据的噪音干扰;
(4) 目前大部分研究在进行推荐时假设用户兴趣是不变的, 这不符合现实情况, 虽然最近有些研究考虑了时间等情境因素对用户标注行为的影响, 但很少考虑多方面因素的综合影响, 且研究成果较少。
因此, 在前人研究基础上, 本文提出一种社会化电子商务环境下利用社会化标签的个性化商品推荐模型, 该模型综合考虑用户使用标签的频率和时间因素计算用户的兴趣偏好, 并基于标签特征和电子商务网站中商品检索条件, 构建某一主题商务社区中商品本体, 利用本体规范化用户标签语义, 并对商品进行分类, 寻找含有用户偏好的类簇, 计算该类簇中商品与用户偏好商品的相似度, 并将用户未标注过的与用户偏好相似的商品推荐给用户。本文方法旨在对算法计算的复杂度、标签语义规范化、以及综合考虑不同因素对标签作用的影响三方面进行改进。
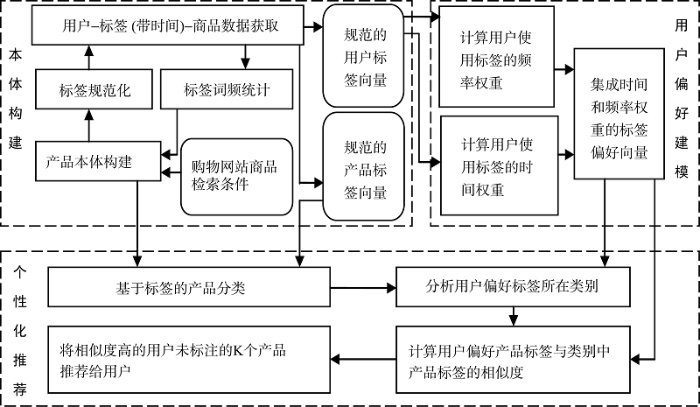
根据以上的思路, 构建基于标签的商品推荐模型, 如图1所示。
(1) 标签数据获取及词频统计
在社会化电子商务网站中, 每一个注册用户可以自由管理感兴趣的商品信息。很多社会化电子商务网站提供了用户分类表达自己兴趣内容的工具: 如“喜欢”、“兴趣”、“关注”、“分享”等分类夹。翻东西网让用户将自己满意的试穿效果图放在“哇晒”分类夹中, 而将自己在其他购物网站看到并喜欢的商品通过复制网址的方式分享于“喜欢”分类夹中, 在“帮我挑”中分享自己的购物经验, 用户也可以关注其他用户或品牌。由于用户标注数量相差较大, 大部分用户标签稀疏, 本文对商务社区中标签的理解不单是“喜欢”分类夹中的标签, 而是所有分类夹中用户对商品的标注, 以全面获取用户兴趣偏好。
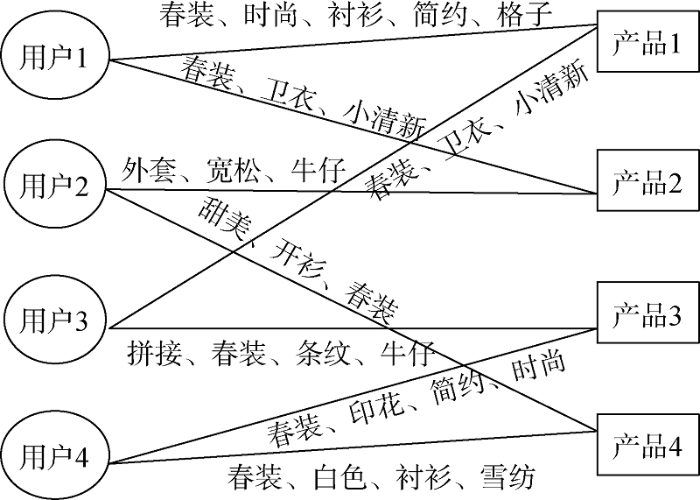
购物社区中的用户标签不仅是用户利用简短关键词对商品名称和商品特征的个性表达, 也是用户与商品之间的纽带。通过观察不同用户对同一商品的标注关系以及一个用户对多个商品的标注关系组成的集合, 可以看出用户、标签和资源三者之间的关联。这样可以通过合适的方法, 将标签作为中介和分析对象, 发现用户关于商品的兴趣偏好, 如图2所示。
社会化电子商务网站提供了用户给商品添加标签的功能, 并通过积分奖励的办法鼓励他们将自己喜欢的商品和标注的标签分享给网站中其他的注册用户, 当然这些分享信息非注册用户也可以看到。这些标签都在用户的“喜欢”、“晒单”、“兴趣”、“分享”主题下,显示了用户感兴趣的商品及偏好主题, 那么形式化表达用户-标签-商品之间的关系是用户偏好获取的前提。
本文先利用网络爬取工具从商务社区爬取用户、用户标注的商品标签及其时间(各标签之间用空格分开)、该用户标注过的商品信息, 并将其保存在电子文档中。将标签分别表示为用户标签(某用户标注的所有商品标签)和商品标签(不同用户给同一个商品的标注), 用户标签初始表示为i((tag1, time1), (tag2, time2),…, (tagn, timen)), i为用户集合I中的元素, n为用户i所使用的标签数, time为对应标签标注的时间。商品标签初始表示为p((tag1, freq1), (tag2, freq2), …, (tagm, freqm)), p为商品集合P中的元素, m为商品p所使用的非重复标签数, freq为对应标签使用的次数。将电子文档中标签一列单独取出, 利用中国科学院计算技术研究所的ICTCLAS3.0分词系统对其进行词频统计, 并按词频大小排序标签。
(2) 商品本体构建方法
本体能够表达概念之间的语义层次关系, 利用标签本体可以规范标签语义, 也可以进行标签分类。本文构建标签本体的目的是对商品类型和商品属性等信息进行规范化的再组织, 以提高商品推荐的效果。遗憾的是, 由于本体构建本身的难度, 到目前为止, 很少有将本体应用于基于标签的商品推荐中的研究成果, 说明基于标签的推荐与本体相结合的研究还很少见。
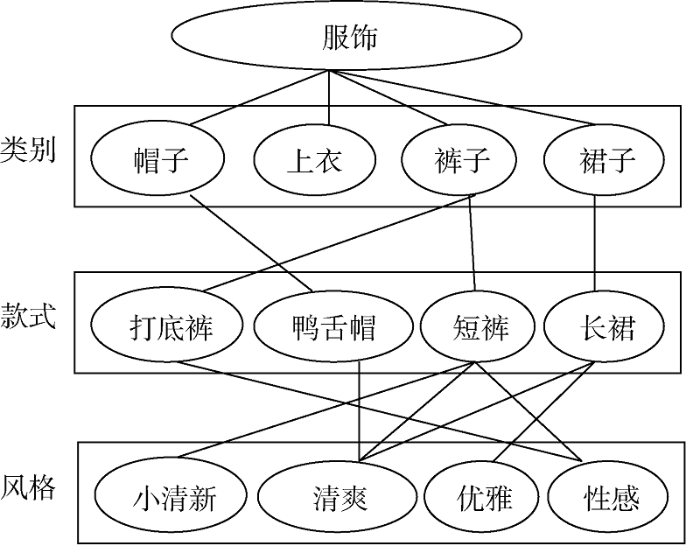
标签不仅能够表达用户偏好, 也标注了商品属性和类别, 隐含表达了各种商品及其属性的层次关系和对应关系。本文实验研究的是服饰类商品的标签本体和推荐问题, 图3表示商品和标签的层次及对应结构示意图。其表达的意思是, 一个大类下面有多个小的类别, 如服饰与帽子、上衣; 每一个小类可以有多个实例, 如裤子小类中包含打底裤、短裤等; 每一个实例可以有多个特征, 如用户可以对一条长裙标注清新、优雅等多个标签, 这些大类、小类、实例和特征之间具有层次关系, 标注它们的标签也应该具有层次关系。
一个商品可以用多个标签标注, 而标签之间的层次及对应关系可以表达出来。那么, 在基于标签的商品推荐中, 通过这种层次结构对商品分类, 并基于标签计算商品之间的相似度时, 具有以下规律:
①描述不同商品特征共用的标签越多, 而共用标签标注的商品越少, 这些商品越相似。图3中, “打底裤”和“短裤”两款商品共用的标签是“性感”, 而“鸭舌帽”、“短裤”、“长裙”三款商品共用的标签是“清爽”, 因此sim(打底裤, 短裤)>sim(长裙, 短裤);
②共同标签离商品越远, 商品之间越不相似, 反之越相似。图3中商品“打底裤”、“短裤”的最近共同标签是“裤子”, 商品“短裤”、“长裙”的最近共同标签是“服饰”, 而“裤子”是“服饰”的子节点, 因此sim(打底裤, 短裤)>sim(长裙, 短裤);
③由于标签是对商品的全方位描述, 理论上, 商品的标签差异性越大, 商品越不相似, 反之越相似。但由于有些标签会重复使用, 实际的差异性可能比按相似度计算出来的更大。
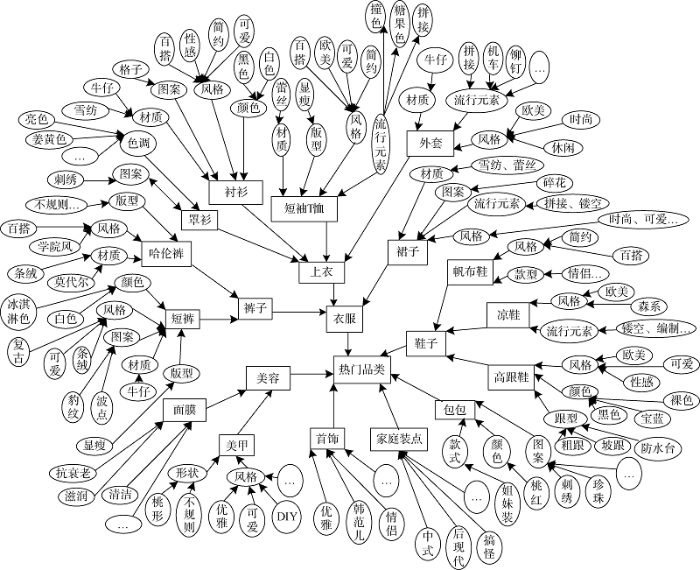
社会化电子商务网站中的用户标注的标签随意性很大, 也很难看出其层次对应关系, 因此, 本文参照电子商务购物网站淘宝网的服饰类搜索条件, 构建服饰类商品标签本体的品种及其属性关系。如输入“服饰”, 其下品类有“衣服”、“鞋子”、“首饰”、“包包”等; “衣服”品类下有“上衣”、“裙子”、“裤子”等, 而关于“裙子”特征的检索条件又有“材质”、“图案”、“风格”、“流行元素”。再根据社会化电子商务网站翻东西中“大家淘”版块的热点标签中用户给服饰类商品标注的标签的词频统计, 构建商品本体。如在裙子的“流行元素”特征描述中, 高频词有“拼接”、“镂空”等, “风格”特征描述的高频词有“时尚”、“可爱”等。结合淘宝网和翻东西网上的热点标签构建的商品标签概念本体, 如图4所示。
(3) 标签的规范化处理
根据本体中不同商品类型及其属性描述词汇, 特别是关于商品特征的描述词汇, 将用户随意使用的属性词汇用本体中意思相同或最相近的属性描述词替换。这里参照电子商务网站的检索条件和社会化电子商务网站高频词, 通过人工综合分析来替换。如以上的服饰商品中, 对上衣风格的描述有“卡通”、“甜美”、“小清新”、“萌”、“可爱”, 其中“卡通”是本体中没有的, 但根据同义词典, 这些词都与“可爱”意思相近, 因此用“可爱”替代。类似的还有“百搭”与“混搭”, 将“混搭”统一替换为“百搭”, 等等。将所有规范化的标签更新电子文档中的初始标签, 并将同一用户关于不同商品的标签和不同用户关于同一商品的标签分别表示为标签向量, 作为下一步用户偏好建模的输入数据。
根据标签构建用户偏好模型的目的是从标签中获取用户对商品的隐性需求或偏好。综合考虑标签标注时间和标签使用频率对用户偏好的影响, 分别计算用户使用标签的时间权重和用户使用标签的频率权重, 集成这两个影响因子权重计算基于标签的用户偏好。
(1) 用户使用标签的频率权重计算
用户使用的商品标签能够反映该用户对商品的兴趣偏好。用户对某些标签使用越多, 说明对其情有独钟, 也说明对这些标签共同描述的商品的喜爱。对于商品而言, 不管多少个用户对一件商品进行标注, 标注的标签可以反映该商品的特征。某些标签使用的频率越高, 它们就越能代表这个商品的特征。
在构建用户偏好模型时, 重点考虑用户使用过的标签。当用户在浏览网上资源时, 对自己喜欢的资源选择相应的标签进行标注。标签的类别可以从一定程度上反映用户的喜好类型, 比如用户“好男人”采用的标签中, 经常出现“外套”、“休闲”等短语, 那么“好男人”可能喜欢外套或休闲类服饰。并且“好男人”使用的标签中“休闲”这一标签出现的频率较高时, 可能因为用户更加喜欢休闲类服装。也就是说, 用户使用的标签频率可以反映用户的喜好程度。但有学者提出, 如果用户高频率使用标注系统中低频率出现的标签, 则表明该标签内容更能反映用户对商品的偏好。故此通过计算标签与用户间的关联程度可以判断标签内容是否真正与用户兴趣相吻合。这也是传统TF-IDF算法的要义, 进而引入TF-IDF算法可以计算标签与用户的关联程度。
假设U表示用户集合, T表示标签集合, P表示商品集合。
①对uU, Pu表示用户u标注过的商品集合, Tu表示用户u使用过的标签集合。
②对tT, Pt表示用标签t标注过的所有商品集合, Ut表示用过标签t的用户集合。
③对pP, Tp表示标注了商品p的标签集合, Up表示标注了商品p的用户集合。
因此, 三元组(u, p, t)表示用户u用标签t标注了商品p。
每个用户的标签集通过使用一个标签向量Tu=(t1u( f1), t2u(f2), …, tmu( fm ))来表示。其中, m是标签的个数, tmu表示用户u的第m个标签, fm表示用户u的第m个标签的频率。tmu( fm)描述标签tm表示的用户偏好程度, fm用TF-IDF公式计算, 如公式(1)所示。
${{t}_{m}}u({{f}_{m}})=T{{f}_{u}}({{f}_{m}})\times ID{{F}_{u}}({{f}_{m}})$ (1)
对三元组进一步挖掘, 将用户u使用的标签t的次数记为count(u, t), 使用标签t标注商品p的用户集合记为UserCount(t, p)。由用户使用的标签t的次数及所有用户使用标签t的次数, 可以得出用户u使用标签t的频率, 用Tfu( ft )表示该频率, 如公式(2)所示。
$T{{f}_{u}}({{f}_{t}})=\frac{UserCount(u,t)}{\sum\limits_{k\in {{U}_{t}}}{UserCount(u,k)}}$ (2)
其中, k表示用户标注过的某个标签, 如公式(3)所示。
$IDFu({{f}_{t}})=\log \frac{N}{{{n}_{t}}}$ (3)
其中, N表示用户总数, nt表示收藏和使用标签t的用户总数。
将公式(2)和公式(3)带入公式(1)得出用户与标签的联系程度, 如公式(4)所示。
${{t}_{m}}u({{f}_{m}})=\frac{UserCount(u,t)}{\sum\limits_{k\in {{U}_{t}}}{UserCount(u,k)}}\times \log \frac{N}{{{n}_{t}}}$ (4)
商品的各个标签的使用频率也可以用标注该商品某标签的使用次数除以该商品的所有标签数。那么标签与商品的相关程度的计算方法如公式(5)所示。
$relate(t,p)=\frac{UserCount(t,p)}{\sum\limits_{q\in {{\text{P}}_{t}}}{UserCount(t,q)}}$ (5)
其中, q表示由标签t标注的某个产品, relate(t, p)值越大, 说明表示用该标签标注的同一产品的用户越多, 该标签与产品的相关度越大, 标签t越能代表产品p, 在标签t下产品p得到推荐的优先级就越高。这样, 产品的标签向量可以表示为Tp=(t1p(relate(t1, p)), t2p(relate (t2, p)), …, tmp(relate(tm, p)))。
(2) 用户标注标签的时间权重计算
由于用户兴趣存在偏移现象, 用户所使用的标签会随时间而变化。例如, 用户u过去用众多“春装”的标签去标注相关商品, 也许因为那时是春秋季节, 此人想购买当季的服装。随着季节变化, 用户可能会关注其他季节的服装。再如, 当用户计划旅游时, 会关注旅游地以及旅游景点进而对这些信息有较多的标注, 当用户选择一个旅游景点后, 可能会关注当地的宾馆、小吃、特产以及娱乐场所等。因此应更关注用户近期的标注, 这种近期标签相比历史标签更能反映用户兴趣热点, 对用户未来行为预测更有帮助。所以, 时间是标注行为中的重要信息因素, 引入时间信息能更好地获取用户最新兴趣热点, 使用户获得高匹配的个性化推荐。
通常, 用户关注资源的时间距当前越近, 该资源就越有价值, 即与用户当前兴趣热点相关性越高。另外, 用户对标签的兴趣偏好与用户对同一标签关注时间长度正相关, 关注时间持续越长, 用户对标签越感兴趣, 标签与用户当前兴趣热点吻合度越高。Cheng等[20]考虑到用户兴趣热点会随时间偏移, 采用自适应指数衰减函数来处理这一问题, 而指数遗忘函数是利用时间效应建模中广泛使用的一种函数, 这种方法通过弱化用户历史行为影响以强化近期行为的作用。本文将指数遗忘函数引用到通过用户对标签使用时间来挖掘用户标签偏好中, 结合时间信息计算用户标注的标签权重, 如公式(6)所示。
${{P}_{time}}({{u}_{m}},{{p}_{n}})=\exp \{-\ln 2\times time({{u}_{m}},{{p}_{n}})/h{{l}_{u}}\}$ (6)
其中, Ptime(um, pn)是通过时间因素计算出来的用户um对产品pn的标签权重, 揭示了用户um对产品pn的偏好。其中time(um, pn)是一个非负整数值, 当用户um对产品pn的标注行为是用户um的标注行为的最后一天, 那么time(um, pn)被设置成0, 若是倒数第二天, 则设置为1, 以此类推。$hlu$代表用户的生命周期, 其计算方法如公式(7)所示。
$hlu=Dat{{e}_{last}}-Dat{{e}_{begin}}$ (7)
其中, $Dat{{e}_{last}}$是用户最后一次标注标签的时间, $Dat{{e}_{begin}}$是用户第一次标注标签的时间。
长生命周期用户的兴趣因稳定性好而下降缓慢, 故对其近期兴趣不宜过高偏重。而短生命周期用户兴趣因不成熟性而变化较快, 生命周期短的用户的兴趣变化大, 故对其近期兴趣应给更多倚重。本文赋予近期行为权重高于之前历史行为权重, 借助时间效应更好地识别出用户当前兴趣热点。
使用时间权重对每个用户的标签集进行量化表示, 通过使用一个标签向量Tu=(t1u(time1), t2u(time2), …, tmu(timem))表示。其中, m是标签的个数, tmu表示用户u的第m个标签, timem表示用户u的第m个标签的时间权重, tmu(timem)描述标签tm在多大程度上体现近期用户u的兴趣爱好。
(3) 集成频率与时间的用户偏好表达
加权标签能更好地将用户对商品的意见与兴趣表现出来, 其丰富信息有助于构建更全面和更精确的用户模型。用户对标签内容偏好程度与用户使用标签的频率正相关, 用户越频繁使用某些标签, 说明用户越偏爱这些标签所标注的商品; 用户当前兴趣与标签使用时间负相关, 即标签使用时间距当前时间越远, 越不能反映用户当前兴趣, 最新使用的标签则更能反映用户的当前兴趣。该模型利用上述两点提出频率权标签偏好和时间权标签偏好, 最后将两者融合提出最终的用户标签偏好向量, 使个性化推荐系统具有更好的可扩展性和实时性特征。
本文不仅利用用户对标签使用次数的多少评判其标签偏好, 也考虑用户标注时间因素, 即二者的集成。如果用户高频率使用某标签, 说明此标签所标注的商品对用户具有高兴趣度, 而标注的时间权重越大, 越能够反映用户的最近兴趣。因此, 本文用标签的频率权重与时间权重相乘得到用户最终的兴趣标签。利用上述公式对用户u的标签向量进行修正后的结果如公式(8)所示。
Tu=(t1u(f1)×t1u(time1), t2u(f2)×t2u(time2), …,tmu(fm)×tmu(timem)) (8)
本文提出的基于标签-本体的商品推荐在建立商品标签本体和用户偏好模型后, 利用本体中概念之间的关系分类商品标签, 并将分类后的商品标签集与用户偏好标签匹配, 找到相匹配的商品标签集后, 进一步计算各匹配标签集中的商品标签与用户偏好标签的相似度, 将相似度高的若干商品标签所标注的商品推荐给用户。
(1) 基于本体的商品分类
本体中实体之间的关联关系以及实体与其属性之间的层次关系可以直观显示, 而商品标签也非直观表达了商品的类型、风格等信息, 商品的标签和分类之间存在联系。可以将商品标签遍历本体的这些关系, 将商品进行归类, 每一个类代表一个主题。利用标签本体对商品进行归类后, 每一个商品属于一个分类簇, 将所有的商品分配到一个单独的类簇(即主题), 有若干个处在本体描述的关系结构树的不同位置的类簇。
本文提出基于标签的商品推荐是一个跨主题的推荐, 对每一个用户标签, 在各类簇中查找与其匹配的商品标签, 至少有一个与用户标签相同。找到匹配的类簇后, 计算该类簇中用户未标注的各商品标签与用户标签的相似度, 相似度越高越优先推荐。
(2) 同类别的商品标签与用户标签的相似度计算
用户对某个物品打上标签, 说明用户对此物品存在某种兴趣。用户对该标签内容兴趣越高, 使用频率越大。利用标签为特定用户进行物品推荐计算时, 先通过计算与目标用户的相似性挖掘出相似用户, 再借助用户协同推荐算法为目标用户提供含有N个供选物品的推荐列表。本文中用户将获得与自身偏好相似度高的商品推荐, 并计算商品标签用户偏好之间的相似度。
上文已将用户标签及商品标签进行了权重表达, 用户标签向量如公式(9)所示。
Tu=(t1u(f1)×t1u(time1), t2u(f2)× t2u(time2), …,tiu(fm)×tiu(timei)) (9)
商品标签向量如公式(10)所示。
Tp=(t1p(relate(t1, p)), t2p(relate(t2, p)), …,tjp(relate(tj, p))) (10)
先将全体物品标签与加权后用户标签采取向量表示, 利用余弦相似度方法进行匹配主题内商品pj的标签和用户ui的标签之间的相似度计算, 如公式(11)所示。
$si{{m}_{ij}}({{u}_{i}},{{p}_{j}})=\frac{\overset{\to }{\mathop{u_{i}^{*}}}\,\times \overset{\to }{\mathop{p_{j}^{*}}}\,}{\left\| \overset{\to }{\mathop{u_{i}^{*}}}\, \right\|\ \left\| \overset{\to }{\mathop{p_{j}^{*}}}\, \right\|}$ (11)
设定预设阈值为e, 如果simij(ui, pj)>e, 则商品与用户偏好相似。
(3) 相似度排序与商品推荐
根据计算的用户标签偏好向量与商品标签向量的相似度, 当二者的相似性大于阈值时, 则将该商品作为候选推荐对象, 得出所有的候选商品后, 按相似度值从大到小排序, 最终选取TOP-K 形成推荐商品列表, 推荐给用户。
“翻东西”是国内典型的第三方社会化电子商务网站, 网站中聚集了大量的用户, 他们以“标签+图片”的形式分享自己喜欢、感兴趣以及购买过商品信息, 其他用户也可以关注自己或自己的标签, 也可以评论用户分享的商品。目前, 该网站聚集了大量用户, 热门标注的商品接近30万件, 热门标签约75万个。本文从热门标注的商品中随机择取近期最活跃的200个用户作为目标用户, 主要涉及服饰类商品, 标签总数超过8万。对用户及其标注的信息进行采集, 获取的字段包括用户名、标签、标注的时间、商品名称, 以电子文档保存。
按用户将数据集随机分成10份, 选取1份作为测试集, 另外9份组成训练集。按照本文构建的推荐模型的思路和方法进行实验。实验工具有: 八爪鱼采集器、Protégé、Excel、ICTCLAS3.0。
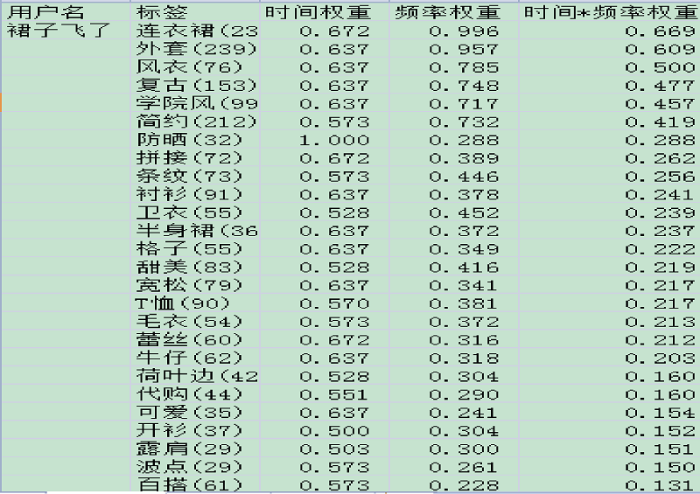
分别计算用户标签的使用频率权重系数和标注时间权重系数, 并将其乘积作为用户标签权重, 也即用户标签偏好值。图5是测试集中用户“裙子飞了”的标签权重计算结果。
根据建立的商品本体, 将训练集中商品按商品主题分类, 找到用户标签匹配的主题。笔者通过计算测试集中用户标签偏好值与训练集中匹配主题下的商品标签的相似度, 将相似度高(本文取相似度阈值为0.5, 即将相似度不小于0.5的商品作为候选推荐商品)的若干商品推荐给用户。
为了检验本文方法(TFT-Based), 将其与只考虑标签时间权重的推荐(TT-Based)、只考虑标签频率权重的推荐(FT-Based)和不考虑标签权重的推荐方法(T-Based)进行比较。参照利用标签进行资源推荐的两篇文章的评价方法[21-22], 以准确率(Precision)、召回率(Recall)和F-Measure值三个指标作为本文推荐方法结果的度量。准确率表示用户对所推荐商品感兴趣的概率, 召回率表示用户感兴趣的商品被推荐的概率。两个概率值越高, 表示该方法推荐的质量越好。对于用户u, 令P(u)为给用户u的长度为N的推荐列表, 令D(u)是测试集中用户u实际打过标签的物品集合。
计算如公式(12)-公式(14)所示。
$Precision\text{=}\frac{\sum\limits_{u\in U}{\left| P(u)\bigcap D(u) \right|}}{\sum\limits_{u\in U}{\left| P(u) \right|}}$ (12)
$Recall\text{=}\frac{\sum\limits_{u\in U}{\left| P(u)\bigcap D(u) \right|}}{\sum\limits_{u\in U}{\left| D(u) \right|}}$ (13)
$F\text{-}Measure\text{=}\frac{2\times Precision\times Recall}{Precision+Recall}$ (14)
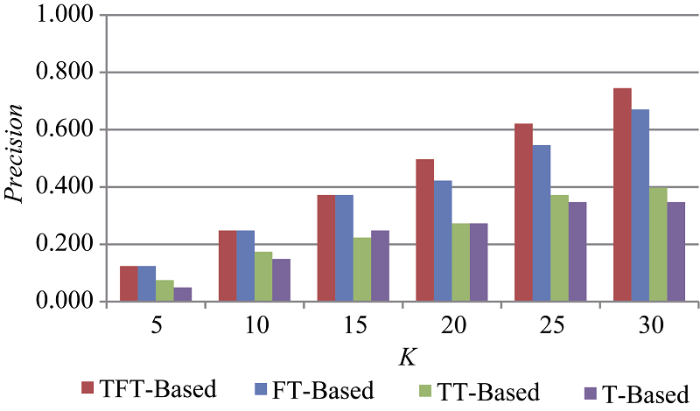
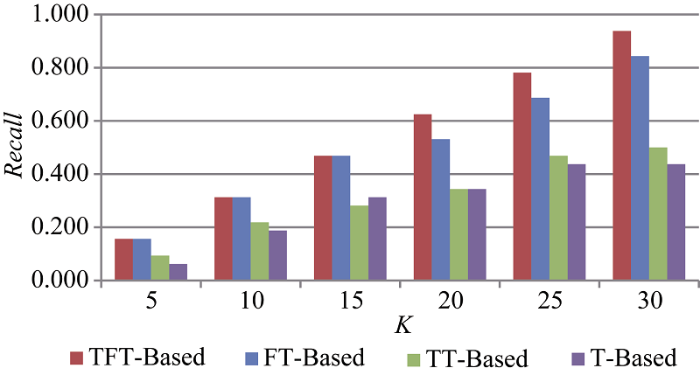
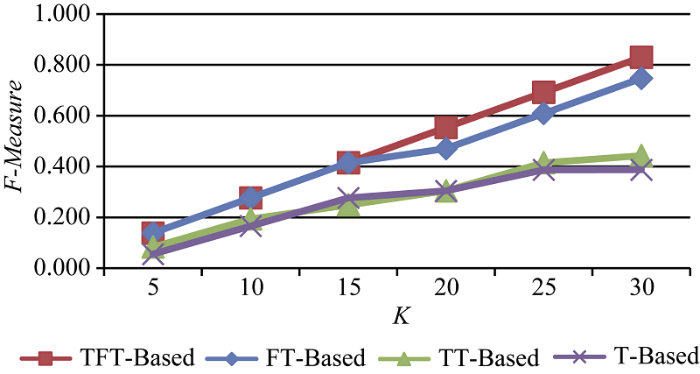
根据公式(12)-公式(14)的计算方法, 分别计算TFT-Based、TT-Based、FT-Based和T-Based 4种推荐方法的Precision、Recall和F-Measure值, 并用直观图形显示, 如图6-图8所示, 其中横坐标表示推荐结果靠前(TopK)的K的不同取值。
从图6可知, 4种方法推荐的准确率随着K值的增加缓慢提高, 最高的是本文的推荐方法。但当K≤15时, 4种推荐方法的准确率都不高, 这可能与用户用词的趋同性有关。本来是截然不同的两个物品, 在用户没有标注细粒度品类特征的情况下, 所描述的属性特征却可能相同, 这样会导致与目标用户兴趣不同的物品可能会被推荐, 降低商品推荐的准确率。如一件夏季的蕾丝衬衫和一件秋季的蕾丝外套, 都标注“蕾丝、时尚、韩范儿”的标签, 被认为是相同或相似度很高的两件衣服会被推荐给目标用户, 但欲购买秋装的目标用户可能不喜欢, 这也证实了基于文本分析的推荐的弊端。实际上, 用户喜欢用图文并茂的形式分享自己喜欢的物品, 如果能够识别图片中物品的特征, 在研究时将其添加到标签中, 或直接提取图片中物品的识别特征, 在此基础上进行推荐, 将会大大提高基于标签或关键词的推荐准确度。
随着K值的增加, 各种方法的Precision都有所提高。提高最快的是本文方法TFT-Based, 不稳定且最慢的是不考虑标签频率权重的方法T-Based。另外TFT- Based相对于单纯考虑标签频率权重的FT-Based方法在推荐数目≤15时, 准确率相同; 当推荐数目>15时, TFT-Based的准确率比FT-Based高。而单纯考虑时间权重的TT-Based方法与T-Based的准确率相近, 却明显低于TFT-Based和FT-Based。这说明, 考虑标签频率和时间对用户偏好的影响是必要的, 标注频率对用户偏好的影响比标注时间对用户偏好的影响更大。本文数据是按最新优先的顺序获取的, 这也说明在没有特殊情况下, 用户对某一领域的兴趣偏好在短期内变化不大, 需要进一步关注和分析拐点时间对用户兴趣偏好的影响。
从图7可知, 4种方法推荐的召回率在K≤10时也均较低, 最高的也只有不到40%, 这可能与用户标注标签的自由、随意有关。同样一件物品, 不同的人看问题的视角不同, 兴趣点也不同, 所以对同一个特征所用词汇不同, 同一件物品所标注的特征也不同。因此, 虽然目标用户与推荐用户喜欢并描述了同一个物品, 由于标注的标签大相径庭, 因而该物品得不到推荐。这给基于标签的商品推荐提出了很大的挑战, 如何对同一物品的不同标签实现统一标注, 目前还没有很好的方法。结合图片的物品语义特征的分析也许会是一个不错的方案, 但如何在体量如此大的标签系统中实现, 还需要利用图像技术和大数据处理技术进行尝试。但图7中的4种方法的召回率随着K值的不断增加也呈现上升趋势。而横向来看, 本文提出的方法整体上较其他三种方法的召回率都有更好的表现。虽然当K≤15时, TFT-Based与FT-Based的召回率相同, 变化趋势相同; 但当K>15时, TFT-Based的召回率大于FT-Based, 并且差距有不断扩大的趋势。而FT-Based的召回率也明显高于TT-Based方法, 说明标注频率对推荐召回率的影响大于标注时间对推荐召回率的影响, 考虑标注频繁度更能提高用户喜欢的物品被推荐的概率。另外, 考虑标注时间对用户偏好的影响对推荐结果的召回率作用不明显。在同一K值下, TT-Based与T-Based的召回率相差不大, 有时TT-Based略高, 有时T-Based略高; 在不同K值下, 这两种方法相差也不大, 但总体上, TT-Based较T-Based有更好的表现。
F-Measure值是Precision和Recall的综合, 从图8可看出, 随着K值的增加, 4种方法的F-Measure值都呈上升趋势。其中本文方法几乎为线性变化, 当K≤15时, TFT-Based与FT-Based的F-Measure值变化线重合; 当K>15时, 后者的变化曲线低于TFT-Based, 即其F-Measure值小于TFT-Based。而TT-Based的F-Measure与T-Based相近, 其变化规律也与准确率和召回率的相似。但TFT-Based的F-Measure值相对于其他方法总体来看最高, FT-Based次之, TT-Based和T-Based较小。
综合来看, 虽然4种推荐方法在K值较小时的准确率、召回率和F-Measure值都较低, 但三种指标值都呈现随K值增加而上升的趋势, 且本文方法的三种指标的表现略高于考虑标注频率对用户偏好影响的推荐方法, 这说明用户标注频率对用户偏好的影响显著。但考虑标注时间对用户偏好影响的推荐方法的表现与不考虑标签权重的影响的推荐方法相当, 也就是说, 标注时间对用户偏好的影响很小, 当然, 这也许还与获取的标签的时间范围有关。因此, 考虑标注时间周期长短以及时间拐点对用户偏好的影响, 是需要进一步研究的方向。另外, 除了时间因素和标注频率因素, 是否还有其他因素(如标注习惯、标签获取方式)的影响, 以至于会产生不同的推荐效果, 也有待进一步探索。
本文针对现有基于标签的推荐研究中推荐精确度不高的问题, 提出一种结合商品标签本体与标签权重的推荐方法。在构建本体时, 参照用户标注的标签信息和相关电子商务网站关于商品检索条件, 构建基于标签的商品本体。在进行用户偏好建模时, 同时考虑用户使用标签的频率与用户兴趣随时间变化两个权重, 作为标签对用户重要度权重, 也即用户对商品标签的偏好值。之后, 计算用户偏好商品标签与商品标签的相似度, 用户将获得相似度最高的K个商品推荐。实验结果表明, 该方法相对于利用标签进行协同过滤推荐方法具有较优的效果, 计算的时间和空间的复杂度更小。社会化电子商务中用户自由标注的商品标签不仅可以描述商品特征而且隐含了用户的偏好, 但社会化标签在赋予用户自由、自愿管理自己感兴趣的资源权利的同时, 也给标签数据的处理带来了巨大的挑战。用户标签用词随意、语义模糊, 而整体数量庞大, 使得在进行推荐时需要大量工作以规范化标签语义。本文使用商品标签本体来序化标签、优化标签语义, 但本体构建本身是一个复杂的工程, 还没有通用的、面对动态数据的本体构建方法, 这将是进一步研究的方向。
涂海丽: 数据采集, 进行实验, 结果分析, 论文起草;
唐晓波: 提出研究思路, 设计研究方案及框架, 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: 69417380@qq.com。
[1] 涂海丽.tag.txt. 用户、商品及其标签数据。
| [1] |
结合社交与标签信息的协同过滤推荐算法 [J].https://doi.org/10.3969/j.issn.1000-1220.2013.11.010 URL Magsci [本文引用: 1] 摘要
传统的协同过滤推荐算法大部分只考虑单一的用户相似度,而忽略了用户其他特征,随着Web2.0和社交网络等互联网新概念模式的发展,用户对个性化推荐技术的要求越来越高.针对上述情况,提出一种结合社交与标签信息的协同过滤推荐算法.首先,定义了小众重叠度和个体重要度的概念,并描述了"个体-小众-社区"的形成过程;然后,分析"用户-项目-标签"三元组信息获得用户间的相似度,并结合社区中的个体重要度,最终得到目标用户的偏好预测和个性化推荐.采用Last.fm公共数据集进行一系列对比实验,实验结果表明,新算法在一定程度上提高了推荐准确度.
Collaborative Filtering Recommendation Algorithm Using Social and Tag Information [J].https://doi.org/10.3969/j.issn.1000-1220.2013.11.010 URL Magsci [本文引用: 1] 摘要
传统的协同过滤推荐算法大部分只考虑单一的用户相似度,而忽略了用户其他特征,随着Web2.0和社交网络等互联网新概念模式的发展,用户对个性化推荐技术的要求越来越高.针对上述情况,提出一种结合社交与标签信息的协同过滤推荐算法.首先,定义了小众重叠度和个体重要度的概念,并描述了"个体-小众-社区"的形成过程;然后,分析"用户-项目-标签"三元组信息获得用户间的相似度,并结合社区中的个体重要度,最终得到目标用户的偏好预测和个性化推荐.采用Last.fm公共数据集进行一系列对比实验,实验结果表明,新算法在一定程度上提高了推荐准确度.
|
| [2] |
Collaborative Tagging in Recommender Systems [C]//
|
| [3] |
Collaborative Tag Recommendations [EB/OL]. [ |
| [4] |
Tag-based Contextual Collaborative Filtering [J].
In this paper, we introduce a new Collaborative Filtering (CF) model which takes into consideration users' context based upon tagging information such as available from recently popular social tagging systems. In numerous implementations, traditional CF systems have been proven to work well under certain circumstances. However, CF systems still suffer a weakness: They do not take context into consideration. Yet recently, social tagging systems have become popular09”these systems provide a well suited combination of context clues through tags as well as important social connectivity among users. Thus, we combine the features of these two systems to create a Tag-Based Contexual Collaborative Filtering model.
|
| [5] |
Improved Recommendation Based on Collaborative Tagging Behaviors [C]// |
| [6] |
Towards Effective Recommendation in Asocial Annotation System Through Group Extraction [EB/OL]. [ |
| [7] |
Web Page Recommender System Based on Folksonomy Mining [C]// |
| [8] |
Personalizing Navigation in Folksonomies Using Hierarchical Tag Clustering [A]// Data Warehousing and Knowledge Discovery [M]. |
| [9] |
基于Web2.0的社会性标签推荐系统 [J].https://doi.org/10.3969/j.issn.1674-8425-B.2008.07.013 URL [本文引用: 1] 摘要
利用社会性书签作为用户在互联网上的操作数据,通过分析用户所做的社会性书签,来构建基于整个互联网的推荐系统,在对社会性标签数据分析的基础上,提出一种新的方法来展现用户的喜好项.实验表明,基于socialtag的网页推荐系统在很大程度上能满足用户的兴趣需求.
Web Page Recommender System Based on Social Tags in Web 2.0 [J].https://doi.org/10.3969/j.issn.1674-8425-B.2008.07.013 URL [本文引用: 1] 摘要
利用社会性书签作为用户在互联网上的操作数据,通过分析用户所做的社会性书签,来构建基于整个互联网的推荐系统,在对社会性标签数据分析的基础上,提出一种新的方法来展现用户的喜好项.实验表明,基于socialtag的网页推荐系统在很大程度上能满足用户的兴趣需求.
|
| [10] |
Personalized Recommendation via Integrated Diffusion on User-Item-Tag Tripartite Graphs [J].https://doi.org/10.1016/j.physa.2009.08.036 URL [本文引用: 1] 摘要
Personalized recommender systems are confronting great challenges of accuracy, diversification and novelty, especially when the data set is sparse and lacks accessorial information, such as user profiles, item attributes and explicit ratings. Collaborative tags contain rich information about personalized preferences and item contents, and are therefore potential to help in providing better recommendations. In this article, we propose a recommendation algorithm based on an integrated diffusion on user–item–tag tripartite graphs. We use three benchmark data sets, Del.icio.us , MovieLens and BibSonomy , to evaluate our algorithm. Experimental results demonstrate that the usage of tag information can significantly improve accuracy, diversification and novelty of recommendations.
|
| [11] |
Item Recommendation in Social Tagging Systems Using Tag Network [J].https://doi.org/10.12733/jics20102056 URL [本文引用: 1] 摘要
How to profile users and items is a key problem for recommendation in tagging systems. In contrast to tag vector based methods which ignore the semantic relations between tags, we present a novel profiling method based on a weighted tag network model to fully exploit the rich tag relations. Furthermore, by considering the extent of other users' usage of tags, we present a novel NTF-IUF-IIF method to calculate weights for tags, which can seize the user's preference accurately. Instead of a single document of traditional methods, it is the first effort to regard each user as a document collection, which enables the statistics of all items. Then the extent of other users' usage of tags can be counted via the global item information, and then used as a factor for accurate tag weighting. Finally, a Fusion Method (FM) is proposed for measuring similarities between tag networks of users and items to get the recommendation lists. Experimental results on MovieLens and CiteULike datasets validate the effectiveness of our methods.
|
| [12] |
FolkRank: A Ranking Algorithm for Folksonomies [C]// |
| [13] |
Mining Association Rules in Folksonomies[A]// Data Science and Classification [M]. |
| [14] |
基于协同标注的B2C电子商务个性化推荐系统研究 [J].
针对B2C电子商务系统中“信息过载”与“信息缺失”共存的问题,在综合分析电子商务个性化推荐技术和协同标注基础上,提出采用协同标注方法构建推荐系统为顾客提供个性化的商品信息,描述了该系统的总体结构,并对系统中的概念生成器、查询分析器、商品标签地图等功能模块进行详细论述。
Research on a Collaborative Tagging System for Personalized Recommendation in B2C Electronic Commerce [J].
针对B2C电子商务系统中“信息过载”与“信息缺失”共存的问题,在综合分析电子商务个性化推荐技术和协同标注基础上,提出采用协同标注方法构建推荐系统为顾客提供个性化的商品信息,描述了该系统的总体结构,并对系统中的概念生成器、查询分析器、商品标签地图等功能模块进行详细论述。
|
| [15] |
基于社会化标签系统的个性化信息推荐探讨 [J].
<html dir="ltr"><head><title></title></head><body><font style="BACKGROUND-COLOR: #cce8cf"> 针对用户个人特征并向其提供准确恰当信息的个性化信息推荐研究,一直是学术界和产业界所关注的热点。结合后控词表,对用户分散的、个性化的标注进行处理,并将用户兴趣用向量表示,然后借鉴协同过滤算法的思想,寻找出相似用户集及其内部的资源集。在此基础上,采用相对匹配策略,提出一种基于社会化标签系统的个性化推荐方法。</font></body></html>
On Personalized Information Recommendation Based on Social Tagging System [J].
<html dir="ltr"><head><title></title></head><body><font style="BACKGROUND-COLOR: #cce8cf"> 针对用户个人特征并向其提供准确恰当信息的个性化信息推荐研究,一直是学术界和产业界所关注的热点。结合后控词表,对用户分散的、个性化的标注进行处理,并将用户兴趣用向量表示,然后借鉴协同过滤算法的思想,寻找出相似用户集及其内部的资源集。在此基础上,采用相对匹配策略,提出一种基于社会化标签系统的个性化推荐方法。</font></body></html>
|
| [16] |
基于语义的标签推荐系统关键问题研究 [D].Research on Key Problems of Tag Recommendation System Based on Semantic [D]. |
| [17] |
The TFC Model: Tensor Factorization and Tag Clustering for Item Recommendation in Social Tagging Systems [J].https://doi.org/10.1109/TSMCA.2012.2208186 URL [本文引用: 1] 摘要
In this paper, a novel Tensor Factorization and tag Clustering (TFC) model is presented for item recommendation in social tagging systems. The TFC model consists of three distinctive steps, in each of which important innovative elements are proposed. More specifically, through its first step, the content information is exploited to propagate tags between conceptual similar items based on a relevance feedback mechanism, in order to solve sparsity and “cold start” problems. Through its second step, sparsity is further handled, by generating tag clusters and revealing topics, following an innovative tf ·idf weighting scheme. Furthermore, we experimentally prove that a few number of expert tags can improve the performance of quality recommendations, since they contribute to more coherent tag clusters. Through its third step, the latent associations among users, topics, and items are revealed by exploiting the TF technique of high order singular value decomposition. This way the proposed TFC model tackles problems of real-world applications, which produce noise and decrease the quality of recommendations. In our experiments with real-world social data, we show that the proposed TFC model outperforms other state-of-the-art methods, which also exploit the TF technique of HOSVD.
|
| [18] |
融合标签流行度和时间权重的矩阵分解推荐算法 [J].
社会化标签不仅可以描述资源而且可以表征用户的偏好,因此结合社会化标签的个性化推荐正成为互联网推荐引擎中的研究热点.针对现有基于标签的推荐研究中推荐精确度不高的问题,提出一种融合标签流行度和时间权重的矩阵分解推荐算法TPTMF,该算法同时考虑用户使用标签的频率与用户兴趣随时间变化的特点,首先根据标签的流行度和时间特征刻画用户对资源的偏好,然后采用梯度下降法对用户-资源矩阵进行分解,最后利用分解后的特征矩阵对目标用户进行预测并推荐.在数据集Last.fm上的实验结果表明该算法具有较好的推荐效果.
Matrix Factorization Recommendation Algorithm Fusing Tag Popularity and Time Weight [J].
社会化标签不仅可以描述资源而且可以表征用户的偏好,因此结合社会化标签的个性化推荐正成为互联网推荐引擎中的研究热点.针对现有基于标签的推荐研究中推荐精确度不高的问题,提出一种融合标签流行度和时间权重的矩阵分解推荐算法TPTMF,该算法同时考虑用户使用标签的频率与用户兴趣随时间变化的特点,首先根据标签的流行度和时间特征刻画用户对资源的偏好,然后采用梯度下降法对用户-资源矩阵进行分解,最后利用分解后的特征矩阵对目标用户进行预测并推荐.在数据集Last.fm上的实验结果表明该算法具有较好的推荐效果.
|
| [19] |
Analysis of Tag-Based Recommendation Performance for a Semantic Wiki [C]// |
| [20] |
Model Bloggers’ Interests Based on Forgetting Mechanism [C]// |
| [21] |
基于标签和协同过滤的个性化资源推荐 [J].Personalized Resource Recommendation Based on Tags and Collaborative Filtering [J]. |
| [22] |
P2P环境下基于社会化标签的个性化推荐模型研究 [J].
【目的】利用用户使用标签的频率和时间因素计算用户的标签偏好向量,讨论用户兴趣的动态变化性对个性化推荐准确性的影响。【方法】构建P2P环境下基于社会化标签的个性化推荐模型,详细说明用户偏好的计算过程及推荐流程,并以西安某高校的P2P电影分享系统为对象进行实验验证。【结果】在随机选择的10名目标用户中,对其中8名用户的推荐命中率均高于传统基于用户评分的协同过滤推荐,说明综合用户标签使用频率和时间因素的推荐效果的优越性。【局限】由于本文主要研究用户兴趣的动态性对个性化推荐的影响,因此只在实验时人工删除无意义标签、合并相似标签,并没有引入有效的控制标签模糊性机制。【结论】在个性化推荐中,考虑用户兴趣的动态变化性,有助于提高推荐结果的准确性。
Model for Personalized Recommendation Based on Social Tagging in P2P Environment [J].
【目的】利用用户使用标签的频率和时间因素计算用户的标签偏好向量,讨论用户兴趣的动态变化性对个性化推荐准确性的影响。【方法】构建P2P环境下基于社会化标签的个性化推荐模型,详细说明用户偏好的计算过程及推荐流程,并以西安某高校的P2P电影分享系统为对象进行实验验证。【结果】在随机选择的10名目标用户中,对其中8名用户的推荐命中率均高于传统基于用户评分的协同过滤推荐,说明综合用户标签使用频率和时间因素的推荐效果的优越性。【局限】由于本文主要研究用户兴趣的动态性对个性化推荐的影响,因此只在实验时人工删除无意义标签、合并相似标签,并没有引入有效的控制标签模糊性机制。【结论】在个性化推荐中,考虑用户兴趣的动态变化性,有助于提高推荐结果的准确性。
|

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}