施晓华 , 卢宏涛
, 卢宏涛
Shi Xiaohua, Lu Hongtao
中图分类号: G252
通讯作者:
收稿日期: 2017-04-10
修回日期: 2017-07-4
网络出版日期: 2017-09-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】在科学合作网络的发展及主要社区发现方法的基础上, 提出发现合作网络社区信息的方法。【方法】以情报领域部分相关期刊2012年-2016年发表论文的共著网络为实验数据, 基于贝叶斯对称非负矩阵分解方法, 结合自动相关确定稀疏压缩原理, 实现社区数量的自动获取, 并在分解过程中应用对称矩阵分解原理。【结果】通过与现有方法的比较与分析, 本文方法得到较好的实验结果。【局限】网络数据获取中未引入学者甄别的优化方法。【结论】本文提出的方法能有效解决合作网络社区发现需求。
关键词:
Abstract
[Objective] This study proposes and examines a new method to identify the communities in collaboration network of scientific researchers. [Methods] First, we retrieved the need data from information science journal articles published from 2012 to 2016. Then, we used the Automatic Relevance Determination to find the target community with the Bayesian Symmetric Non-negative Matrix Factorization method. Finally, we compared the performance of our method with the existing ones. [Results] The proposed method got better results than others. [Limitations] Did not optimize our data with the researcher identifications. [Conclusions] The proposed method could effectively find communities from the scientific collaboration network.
Keywords:
社区发现是进行社会网络分析的重要方法之一, 通过对大型复杂网络内部的社区发现, 可以利用已有信息了解网络的运行情况, 有效理解和分析整体网络的属性, 进而发现最有关联性的网络内部组织来简化全局结构, 理解网络的拓扑属性。网络中的社区可以通过图分割法[1]不断最小化社区之间的连接数获取; 也可以通过如基于某个目标函数(如模块度)随机优化[2]及统计推理[3]等方法来实现。
随着知识和科学技术不断全球化发展, 科学研究涉及学科领域不断增多, 使得合作研究成为科学研究
的主流方式。在科学网络(Scientific Network)中[4-6], 科学家或研究学者成为关键节点, 他们通过各种不同的关联方式形成以科学协作为主的相互联系, 如共同发表论文、发表文献的相互引用、在相同领域学科杂志或会议上发表成果等。通过将科学网络进行有效社区发现和聚类, 进而简化整个庞大、复杂的科学知识系统; 可以将作者聚类至不同研究社区中, 社区内的人员有相同的研究方向或兴趣(强关联性), 不同社区之间的人员有不同的研究兴趣(弱关联性), 进而通过对不同社区的特性进行分析, 获取不同作者所在的科学知识社区, 理解科研人员的合作和交流模式, 挖掘科研人员的研究兴趣; 并可进一步应用图分析和可视化功能, 从网络分析角度对合作数据有更加深入的揭示。
本文将提出一种基于矩阵分解学习的优化社区发现算法, 从整体网络中发现内在的多个社区, 并在实际网络中取得了良好的社区发现效果; 同时通过基于贝叶斯推理的稀疏压缩方法, 自动获取社区的数量, 解决了一般矩阵分解学习中无法自动确定分解维度的问题。
科学网络研究主要研究知识体系中科学家之间的社区特性, 分析其相互关联性和演化趋势, 常见的科学网络有出版物引文网络[7]、期刊共引[8]和耦合网络[9]、共词网络[10]和共著网络[11]。在共著网络中, 学者成为网络中的每一个节点, 学者u和v共同完成的科学成果成为之间的链接(如论文、图书、报告及基金项目等)。对应的链接权重w(u,v)等于u和v共同贡献的作品数量。在合作网络中, 一般认为u和v对于作品的贡献是相同的, 因此该网络是一个无向图, 即w(u, v)= w(v, u)。
Newman在2004年分析了生物、物理和数学三个不同学科的论文数据, 分析共同发表论文的作者关系(Coauthorship), 分析作者之间协作关系的社区结构, 以及不同学科科学协作网络的差异, 同年他还提出基于模块度的层次社区结构分类方法[12]; 王福生等针对《图书情报工作》杂志2001年-2006年的论文数据, 构建, 并分析作者科研合作网络模型的分布与演化过程[13]; Mimno通过建立文献社区-作者-主题模型(Community-Author-Topic)提取科学家合作网络中的研究社区, 并对NIPS会议上发表的论文数据进行科学社区发现的实验分析[14]; Erfanmanesh等通过对 Scientometrics 期刊1980年-2012年的3 125篇文章进行共著作者分析研究, 发现其中的活跃、中心和协同节点[15]。
随着复杂网络学科的不断发展, 众多学者提出用以解释各种物理现象的网络模型, 例如小世界模型、无标度网络以及随机网络等; 同时伴随海量数据分析与挖掘为宗旨的数据挖掘技术研究的深入, 计算机科学家根据信息网络的规模巨大性等特点, 设计出高效率并具有一定智能的鲁棒社区分类算法, 这些方法主要为基于图论的社区发现算法, 包括谱聚类分割、层级社区发现算法和基于随机行走的聚类算法等。目前常用的网络处理工具有UCINET、iGraph、Gephi、Pajek和CytoScape等, 不仅可以实现网络中节点和链接的定量分析, 并支持简单的社区发现功能。网络社区发现根据聚合原理主要有以下方法[16]:
(1) 图分割法。网络的社区发现就是将网络按其内在的社团结构划分成一个个子网络的过程。在计算机科学领域, 这类问题一般称作图分割(Graph Partitioning)。基于图分割的社区发现算法利用节点间关系的信息, 其隐含的基本假设是: 子社区内部的交互要远远比子社区之间的交互更为紧密。开源工具的CFinder和NetworkX使用CPM(Clique Percolation Method)[17]完全子图过滤方法实现社区发现, 其他的图分割方法主要还有层次聚类如BGLL算法[18]和矩阵分解学习方法等。
(2) 分裂方法。网络的社团结构分析往往要求算法能够准确、自动地确定网络的社团个数并给出相应社团的“自然”分割。近年来有大量的更适合网络社团分析的有效算法被提出。Newman等提出一种通过边移除按层次地分解网络的社团分析方法[2], 这项工作被认为是现代社区结构分析方法的开创性工作, 引起了各领域研究人员的广泛兴趣。
(3) 合并方法。在合并方法中, 模块度(Modularity)[19]标准被提出并用于衡量社团结构划分好坏。网络的某种划分对应模块度值越高往往表明该划分越可能是符合网络社团结构的划分, 一般社区的模块度都在0.3至1之间。模块度是基于随机网络不存在社团结构的假定, 以所有节点的度值与给定网络相同但边随机连接的网络为参考模型, 比较给定网络的所有社团内部边的数量与相对应的社团内部边的期望数量。Le Martelot等提出基于模块度优化的快速迭代社区发现方法[20], 通过对已有社区不断增加节点, 发现更高模块度的新社区分配。
尽管在理论和实践上基于图分割的社区方法取得了一定的成功, 但仍然有一些不足。这些算法通常等价于一个特征值分解问题, 而社区可以从生成特征向量确定, 然而这些关键的特征向量并没有具体的物理含义。通常来讲, 所有的网络结构均可以通过关系图来表示, 其主要结构表征即为其邻接矩阵(Adjacency Matrix), 由于邻接矩阵的非负特性(所有元素为1或0), 因此在机器学习领域研究的热点非负矩阵分解(Non-negative Matrix Factorization, NMF)得到了很好的应用。NMF是一种比较新的矩阵分解算法, 主要用于数据聚类应用, 于1999年才被开始提出[21], 它克服了传统矩阵分解的很多问题, 通过寻找上下文有意义的解决方法, 提供解释数据的更深入看法, 为人类处理大规模数据提供一种新的途径。因此将NMF应用到社区发现中, 在分解过程中保持网络的非负性, 往往能达到表示社区的局部之间相关关系的效果; 并从全局出发, 快速发现不同社区的信息, 取得更好的社区分类效果[21]。
NMF的基本思想可以简单描述为: 对于任意给定的一个非负矩阵X, NMF算法能够寻找到一个非负矩阵U和一个非负矩阵V, 使得满足X和UV之间的最优近似, 从而将一个非负的矩阵分解为左右两个非负矩阵的乘积, $X\approx U{{V}^{T}}$。NMF初始被应用于图像分类、文本挖掘等领域, 近年来有不少研究者开始将这种方法应用于各种网络的社区发现中[22], 其中包括大量的科学网络数据。Wang等[23]通过对第0-12卷的NIPS会议论文数据进行合著网络分析, 有效发现社区中的重要作者节点(Superstars)。Zhang等[24]使用贝叶斯NMF三分解对Newman等的网络科学合作网络和高能理论合作网络进行社区发现实验。Mankad等[25]使用加入L1范数稀疏约束的NMF方法对2003 KDD Cup提供的引文网络数据进行社区发现。Yang等[26]通过NMF方法从大规模DBLP(计算机科学协作网络)网络中有效发现其中的重叠社区结构。
Xie等[27]通过调研社区发现方法, 提出NMF处理社区发现问题时, 其分解维度设置和复杂度简化是主要问题:
(1) NMF是一种无监督的方法, 通常社区的数量K是未知的, 因此需要有效判断社区数量K;
(2) 对于一些特殊网络, 如合著网络, 源图是一个无向图, 需要充分利用网络结构优化分解算法, 提升算法效率。
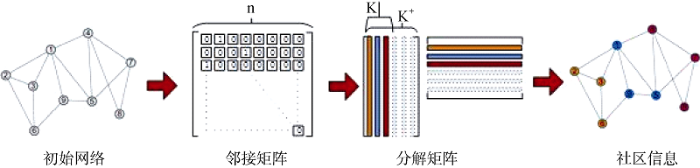
如图1所示, 本文将以自动收割到的期刊发文与作者数据为基础, 生成合著网络(对称网络), 并以邻接矩阵形式表示, 并通过贝叶斯对称非负矩阵分解(Bayesian Symmetric NMF, BSNMF)[28-29]进行实际的社区发现实验。
(1) 通过贝叶斯假设和Automatic Relevance Determination(ARD)稀疏方法[30], 有效判断获取社区的数量K。ARD是一种基于贝叶斯推断的模型选择方法, 它通过超参数的应用, 表示模型对应不同特性的相关性, 并通过定义一些参数来描述这些特性的偏差范围。如果偏差为零, 则相应的特性对模型预测不起任何作用。因此, ARD可以自动发现模型中相关的一些关键元素, 在社区发现中, 即为分解出来的主要社区属性。
(2) 设定分解的两个矩阵是对称的, 既$U={{V}^{T}}$, 大大简化计算过程。
BSNMF的算法过程如下:
输入网络邻接矩阵$X\in R_{+}^{N\times N}$, 初始化K, 固定超参数a,b;
定义矩阵$B\in R_{+}^{K\times K}$是一个对角线为${{\beta }_{k}}$的对角矩阵;
① 初始化矩阵S0
② 从i=1到niter
③$S\leftarrow \left( \frac{S}{1\times S+S\times B} \right)\cdot \left[ \left( \frac{X}{S\times {{S}^{T}}} \right)\times {{S}^{T}} \right]$
④${{\beta }_{k}}\leftarrow \frac{N+a-1}{\sum{_{i}s_{ij}^{2}+b}}$
⑤ 结束
⑥${{K}_{*}}\leftarrow $S中非零的列数
⑦${{S}_{*}}\leftarrow $去.除S中全零列
⑧ 返回K*和S*
其中, X为输入的网络邻接矩阵, K为初始设置的社区数, S为分解后的目标矩阵, S*和K*是对S去除全零向量后的结果; a,b是模型的超参数, 通过多次实验比较确认, niter为迭代次数。
通过抽取, 建立网络矩阵X, 在MATLAB下运行BSNMF算法, 不仅自动获取到社区的数目K*, 对于返回的S*的维度为N×K*, 取S*中每一列的最大值c=argmaxcS*ic, 即为第i个点所属的社区信息, 自动获取每个社区的信息。
通过中国期刊网的RSS聚合源, 获取《情报资料工作》、《情报理论与实践》、《情报科学》和《情报杂志》4种情报领域期刊的2012年-2016年的论文和作者信息[31], 共计6 254篇论文, 对应作者14 312个。再通过网页抓取方法, 获取论文对应的单位信息, 以作者姓名结合作者单位作为去重条件, 去重后得到7 625个作者。每两个作者有合作发表论文, 则两点之间有边相连, 边权重为两个作者合作的篇数; 据此形成一个7 625个节点、12 672条边的大规模科学合作网络, 其中每个节点平均度为1.66, 即5年中每人平均和1.66人次同行进行合作发文。
表1显示了发表论文最多的10位作者在合作网络中的度数信息。由于不同人员合作发表论文的情况不同, 若一位作者全部以独立作者进行发文时, 其在合著网络中表示为一个独立节点, 经计算, 在此网络中共有665个孤立节点, 因此在进行社区发现应用之前, 先将这些孤立节点删除, 以提升整体社区发现的效果。形成新的合作网络X包含6 960个节点, 边数仍然为12 672条。
表1 发表论文前10的作者信息
| 姓名 | 单位 | 发表次数 | 网络度数 |
|---|---|---|---|
| 邱均平 | 武汉大学 | 50 | 66 |
| 朱庆华 | 南京大学 | 41 | 83 |
| 黄鲁成 | 北京工业大学 | 40 | 118 |
| 赵蓉英 | 武汉大学 | 36 | 49 |
| 陈福集 | 福州大学 | 35 | 48 |
| 王国华 | 华中科技大学 | 30 | 89 |
| 谢阳群 | 淮北师范大学 | 27 | 48 |
| 娄策群 | 华中师范大学 | 26 | 44 |
| 张玉峰 | 武汉大学 | 26 | 37 |
| 孙建军 | 南京大学 | 25 | 42 |
结合生成的合作网络, 将现有的多个社区发现方法进行模块度结果比较。
(1) CPM完全子图过滤方法[16], 使用3-Clique发现网络中的完全子图数量, 未发现的节点作为独立节点来计算整体模块度;
(2) GN算法[18], 基于聚类中的分裂原理, 使用边介数作为相似度的度量方法;
(3) BGLL层次化社团结构的凝聚算法[17];
(4) Louvain贪婪优化方法[19], 在迭代中不断优化分类社区的模块度;
(5) NMF[20], 利用非负矩阵方法的聚类功能实现社区发现;
(6) SNMF[22], 对称非负矩阵方法处理无向网络的社区发现;
(7) BSNMF, 本文提出的贝叶斯对称非负矩阵分解方法。
BSNMF方法设置初始社区数为节点总数的五分之一, 初始设置超参数a=5, b=2, 运行niter=500次迭代以保证收敛。在获得矩阵S中, 对应的非零列共有702列, 即共分成702个社区。由于方法2、方法5、方法6需要初始设置社区数, 实验设定为由BSNMF方法获取的社区数702。
经验证, 在表2的已有算法中, Louvain 算法取得了比较好的社区发现效果, 而BSNMF方法发现的社区结果模块度达到0.9664, 得到最高的网络分区效果, 同时, 相比方法5和方法6, BSNMF中的对称矩阵分解方法和贝叶斯方法都取得了更好的实验结果。
表2 社区发现结果模块度比较
| 方法 | 模块度 |
|---|---|
| 3-Clique | 0.3579 |
| GN | 0.5530 |
| BGLL | 0.8294 |
| Louvain | 0.9165 |
| NMF | 0.4209 |
| SNMF | 0.8165 |
| BSNMF | 0.9664 |
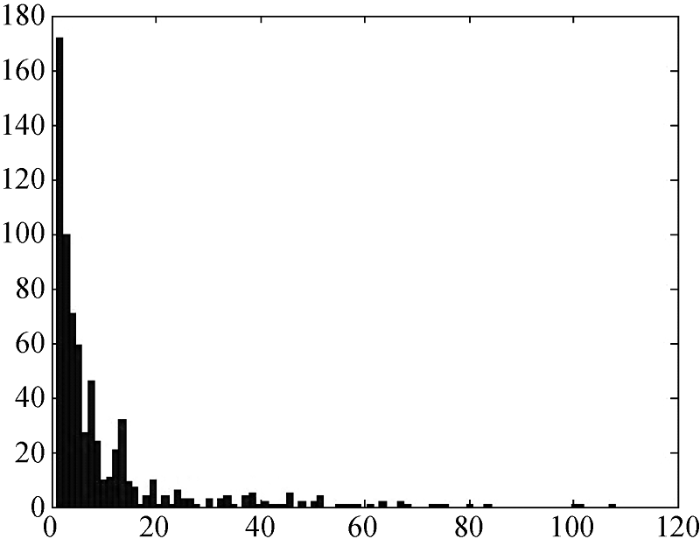
图2为BSNMF发现的702个社区的节点直方图, 其中紧密的前6个大型社区在表3中显示, 在这些社区中的节点人员通过共同发表论文关系, 形成不同紧密的作者合著社区或合著小组, 在这些社区中的作者具有类似的研究兴趣或方向, 今后这些作者之间有更大的可能性来继续合作发表论文。
表3 其中发现的几个主要社区及节点信息
| 社区 | 节点数 | 节点度和 | 主要节点人员 (度大于10, 下划线为大于20) |
|---|---|---|---|
| 1 | 103 | 200 | 孙建军, 俞立平, 郑彦宁, 潘云涛, 武夷山, 丁堃, 姜春林, 刘志辉 |
| 2 | 100 | 192 | 朱庆华, 袁勤俭, 宗乾进, 赵宇翔, 刘璇 |
| 3 | 100 | 220 | 黄鲁成, 翟东升, 苗红, 吴菲菲, 张杰, 娄岩 |
| 4 | 89 | 159 | 毕强, 彭洁, 滕广青, 黄微 |
| 5 | 84 | 194 | 王国华, 曾润喜, 钟声扬, 陈强, 王 雅蕾, 杨腾飞, 徐晓林, 张韦, 闵晨 |
| 6 | 84 | 177 | 张海涛, 徐宝祥, 张连峰, 崔金栋, 武慧娟, 王欣, 王丹, 许孝君, 宋拓 |
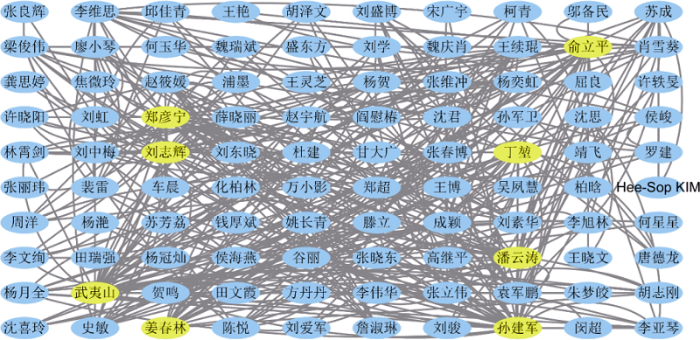
图3通过网格图显示了社区1的主要节点作者关系图, 形成了以孙建军、俞立平、郑彦宁等为中心节点的紧密合作社区。通过分析发现, 从社区1共同发表的140篇论文中抽取得到的关键主题词有“情报”(34次)、“评价”(26次)、“网络”(22次)以及“信息”(21次)。
如图4形成的网络合作发文主题词云图所示, 在社区1中的人员更加关注情报学相关的网络评价和信息管理方法领域, 同时人员之间也有更高的合作发文趋势。
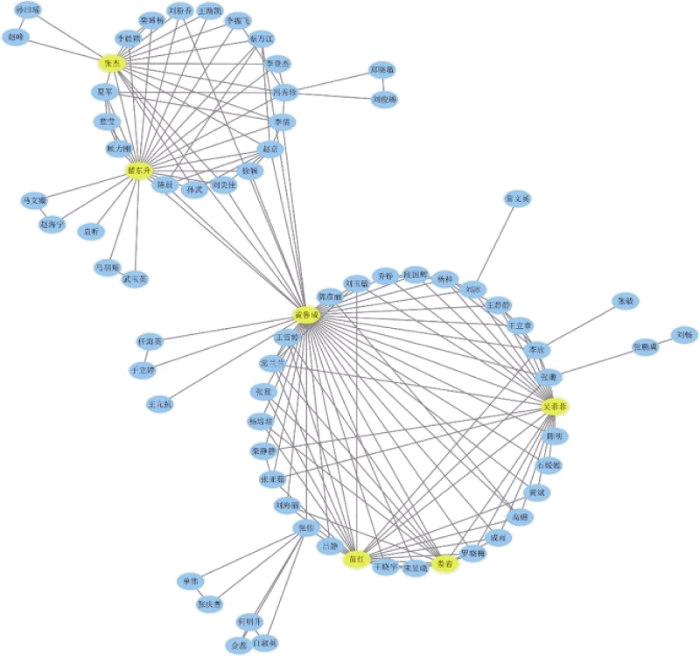
图5通过环形图显示了社区3的主要节点作者关系图, 形成以黄鲁成为中心节点的紧密合作社区。通过分析社区3共同发表的116篇论文, 其中69篇集中发表在同一类期刊上, 抽取到的关键主题词为“专利”(38次), 说明社区3中主要的研究领域是专利分析为中心的相关文献计量和技术应用研究。
图3的社区1分布结构与图5社区3有所不同, 社区3基于节点“黄鲁成”分成两个不关联社区, 分别是以“翟东升”为共同主要节点和以“苗红, 吴菲菲”为共同主要节点的两个独立社区, 因此后续可以使用重叠社区分区方法, 将“黄鲁成”同时分布在两个不同社区, 以达到更好的社区分类效果。
科学网络社区发现可以在大量文献中, 有效发现潜在的学者关联社区, 对基于网络科学的文献计量有很好的技术支撑作用, 应用贝叶斯非负矩阵方法能快速有效发现相关社区信息, 自动确定社区数量, 并以情报学领域合作网络中进行应用实验, 对比其他的社区发现方法, 取得了更高的模块度值。同时一些节点可能同时出现在不同社区(见图5), 出现重叠现象(Overlapping), 如何能自动、有效发现重叠社区, 可以进一步拓展应用。在合作网络分析中, 如何自动有效甄别作者身份信息[32], 形成和自然人的一一对应, 是合作网络的数据清洗的关键, 也是实现在跨学科、交叉领域学者社区发现的关键, 需要在数据处理过程加入更多专家经验和智能化手段以取得新的突破。
施晓华: 采集、清洗和分析数据, 完成实验, 撰写论文;
卢宏涛: 提出研究思路, 修改论文。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: xhshi@sjtu.edu.cn。
[1] 施晓华. Raw_data.xlsx. 合作社区原始数据.
[2] 施晓华. Adjacent_Matrix.mat. 社区邻接矩阵数据.
| [1] |
Community Detection: Topological vs. Topical [J].https://doi.org/10.1016/j.joi.2011.02.006 URL [本文引用: 1] 摘要
The evolution of the Web has promoted a growing interest in social network analysis, such as community detection. Among many different community detection approaches, there are two kinds that we want to address: one considers the graph structure of the network (topology-based community detection approach); the other one takes the textual information of the network nodes into consideration (topic-based community detection approach). This paper conducted systematic analysis of applying a topology-based community detection approach and a topic-based community detection approach to the coauthorship networks of the information retrieval area and found that: (1) communities detected by the topology-based community detection approach tend to contain different topics within each community; and (2) communities detected by the topic-based community detection approach tend to contain topologically-diverse sub-communities within each community. The future community detection approaches should not only emphasize the relationship between communities and topics, but also consider the dynamic changes of communities and topics.
|
| [2] |
Finding and Evaluating Community Structure in Networks [J].https://doi.org/10.1103/PhysRevE.69.026113 URL PMID: 14995526 [本文引用: 2] 摘要
We propose and study a set of algorithms for discovering community structure in networks-natural divisions of network nodes into densely connected subgroups. Our algorithms all share two definitive features: first, they involve iterative removal of edges from the network to split it into communities, the edges removed being identified using any one of a number of possible "betweenness" measures, and second, these measures are, crucially, recalculated after each removal. We also propose a measure for the strength of the community structure found by our algorithms, which gives us an objective metric for choosing the number of communities into which a network should be divided. We demonstrate that our algorithms are highly effective at discovering community structure in both computer-generated and real-world network data, and show how they can be used to shed light on the sometimes dauntingly complex structure of networked systems.
|
| [3] |
Uncovering Community Structures with Initialized Bayesian Nonnegative Matrix Factorization [J].https://doi.org/10.1371/journal.pone.0107884 URL PMID: 4182427 [本文引用: 1] 摘要
Uncovering community structures is important for understanding networks. Currently, several nonnegative matrix factorization algorithms have been proposed for discovering community structure in complex networks. However, these algorithms exhibit some drawbacks, such as unstable results and inefficient running times. In view of the problems, a novel approach that utilizes an initialized Bayesian nonnegative matrix factorization model for determining community membership is proposed. First, based on singular value decomposition, we obtain simple initialized matrix factorizations from approximate decompositions of the complex network’s adjacency matrix. Then, within a few iterations, the final matrix factorizations are achieved by the Bayesian nonnegative matrix factorization method with the initialized matrix factorizations. Thus, the network’s community structure can be determined by judging the classification of nodes with a final matrix factor. Experimental results show that the proposed method is highly accurate and offers competitive performance to that of the state-of-the-art methods even though it is not designed for the purpose of modularity maximization.
|
| [4] |
一个中国科学家合作网的实证分析 [J].https://doi.org/10.3969/j.issn.1672-3813.2009.01.003 URL [本文引用: 1] 摘要
研究了由《科学通报》过去20年间发表文章的作者所构建的科学家合作网络。按照统计学方法和 基于复杂网络理论的实证分析表明,科学家产量满足幂律分布,而合作规模分布则是指数衰减的。合作网中存在一个明显的最大连通子图,该子图具有高聚类和小世 界特性,并呈现社团结构和等级结构。网络的度分布介于指数与幂律之间,近似服从对数正态分布,社团规模分布亦显示出长尾特性。此外,还应用3种不同的指标 研究了Hub节点的影响力。
Empirical Analysis of a China Scientists Collaboration Network [J],https://doi.org/10.3969/j.issn.1672-3813.2009.01.003 URL [本文引用: 1] 摘要
研究了由《科学通报》过去20年间发表文章的作者所构建的科学家合作网络。按照统计学方法和 基于复杂网络理论的实证分析表明,科学家产量满足幂律分布,而合作规模分布则是指数衰减的。合作网中存在一个明显的最大连通子图,该子图具有高聚类和小世 界特性,并呈现社团结构和等级结构。网络的度分布介于指数与幂律之间,近似服从对数正态分布,社团规模分布亦显示出长尾特性。此外,还应用3种不同的指标 研究了Hub节点的影响力。
|
| [5] |
The Scientific Network of Surfactants: Structural Analysis [J].https://doi.org/10.1002/asi.20362 URL 摘要
The scientific network of the surfactants and related subjects has been analyzed with the CoPalRed knowledge system. The actors studied have been countries, research centers and laboratories, researchers, and journals. The thematic map of the major research areas has been established. Most of the research areas, and those that have the greatest representation in terms of number of documents, are related to physics and chemistry. However, biochemistry and cell biology, medicine (pediatrics and pulmonary physiology), and, to a lesser extent, veterinary medicine and food science and technology are also noteworthy in the field of surfactants, which presents a markedly multidisciplinary profile.
|
| [6] |
Selection in Scientific Networks [J].https://doi.org/10.1007/s13278-011-0043-7 URL [本文引用: 1] |
| [7] |
|
| [8] |
Community Structure of the Physical Review Citation Network [J].https://doi.org/10.1016/j.joi.2010.01.001 URL [本文引用: 1] 摘要
We investigate the community structure of physics subfields in the citation network of all Physical Review publications between 1893 and August 2007. We focus on well-cited publications (those receiving more than 100 citations), and apply modularity maximization to uncover major communities that correspond to clearly identifiable subfields of physics. While most of the links between communities connect those with obvious intellectual overlap, there sometimes exist unexpected connections between disparate fields due to the development of a widely applicable theoretical technique or by cross fertilization between theory and experiment. We also examine communities decade by decade and also uncover a small number of significant links between communities that are widely separated in time.
|
| [9] |
作者耦合分析; 一种新学科知识结构发现方法的探索性研究 [J].https://doi.org/10.3969/j.issn.1001-8867.2012.02.001 URL Magsci [本文引用: 1] 摘要
对作者耦合分析中的基本理论、方法和问题进行综述,在此基础上力求探寻一种新的学科知识结构发现方法。利用作者耦合对图书情报学的知识结构进行可视化分析,并与作者同被引分析得到的图书情报学知识结构进行比较研究。研究证实:作者耦合分析能够较好地挖掘一个学科的“前沿知识结构”,它与作者同被引相结合可以更科学、更全面地发现一个学科的知识结构。讨论了作者耦合分析的一些细节问题,如影响因素、研究样本的选择和可视化分析中应注意问题等。图2。表2。参考文献15。
Author Coupling Analysis: An Exploratory Study on a New Approach to Discover Intellectual Structure of a Discipline [J].https://doi.org/10.3969/j.issn.1001-8867.2012.02.001 URL Magsci [本文引用: 1] 摘要
对作者耦合分析中的基本理论、方法和问题进行综述,在此基础上力求探寻一种新的学科知识结构发现方法。利用作者耦合对图书情报学的知识结构进行可视化分析,并与作者同被引分析得到的图书情报学知识结构进行比较研究。研究证实:作者耦合分析能够较好地挖掘一个学科的“前沿知识结构”,它与作者同被引相结合可以更科学、更全面地发现一个学科的知识结构。讨论了作者耦合分析的一些细节问题,如影响因素、研究样本的选择和可视化分析中应注意问题等。图2。表2。参考文献15。
|
| [10] |
共词网络的结构与演化: 概念与理论进展 [J].https://doi.org/10.3969/j.issn.1002-1965.2014.07.019 URL [本文引用: 1] 摘要
共词网络方法在知识网络研究中应用普遍。首先回顾了共词分析和共词网络之间的联系与区别;然后从共词网络的拓扑结构、社区识别及其演化、增长动力学以及改造共词网络这4个方面对相关研究进行梳理和总结;最后从方法和内容两个方面指出了当前研究的不足和未来的研究重点。
Structure and Evolution of Co-word Network: Concept and Research Review [J].https://doi.org/10.3969/j.issn.1002-1965.2014.07.019 URL [本文引用: 1] 摘要
共词网络方法在知识网络研究中应用普遍。首先回顾了共词分析和共词网络之间的联系与区别;然后从共词网络的拓扑结构、社区识别及其演化、增长动力学以及改造共词网络这4个方面对相关研究进行梳理和总结;最后从方法和内容两个方面指出了当前研究的不足和未来的研究重点。
|
| [11] |
科学家合作网络中的社区发现 [J].https://doi.org/10.3772/j.issn.1000-0135.2011.12.011 URL [本文引用: 1] 摘要
从科学家合作网络中发现隐含的研究社区对于理解科研人员的合作和交流模式,挖掘科研人员的研究兴趣具有十分重要的意义。本文在Latent Dirichlet Allocation模型的基础上,提出了一个社区一作者一主题模型,该模型能够根据科研人员之间的合著关系和论文的内容来发现隐性的子社区,并提取出每个子社区中的研究主题以及每个子社区中有代表性的科研人员。本文还给出了基于Gibbs抽样的社区一作者一主题模型的推断算法。在NIPS数据集上的实验表明,本文提出的社区发现算法所发现的研究社区和研究主题都是有效的。
Community Detection in Scientific Collabration Network [J].https://doi.org/10.3772/j.issn.1000-0135.2011.12.011 URL [本文引用: 1] 摘要
从科学家合作网络中发现隐含的研究社区对于理解科研人员的合作和交流模式,挖掘科研人员的研究兴趣具有十分重要的意义。本文在Latent Dirichlet Allocation模型的基础上,提出了一个社区一作者一主题模型,该模型能够根据科研人员之间的合著关系和论文的内容来发现隐性的子社区,并提取出每个子社区中的研究主题以及每个子社区中有代表性的科研人员。本文还给出了基于Gibbs抽样的社区一作者一主题模型的推断算法。在NIPS数据集上的实验表明,本文提出的社区发现算法所发现的研究社区和研究主题都是有效的。
|
| [12] |
Coauthorship Networks and Patterns of Scientific Collaboration [J].https://doi.org/10.1073/pnas.0307545100 URL PMID: 14745042 [本文引用: 1] 摘要
By using data from three bibliographic databases in biology, physics, and mathematics, respectively, networks are constructed in which the nodes are scientists, and two scientists are connected if they have coauthored a paper. We use these networks to answer a broad variety of questions about collaboration patterns, such as the numbers of papers authors write, how many people they write them with, what the typical distance between scientists is through the network, and how patterns of collaboration vary between subjects and over time. We also summarize a number of recent results by other authors on coauthorship patterns.
|
| [13] |
作者科研合作网络模型与实证研究 [J].Author Collaboration Network Model and Demonstration Study [J]. |
| [14] |
Community-based Link Prediction with Text [C]// |
| [15] |
Co-authorship Network of Scientometrics Research Collaboration [J].
This paper examines the co-authorship network in the field of scientometrics using social network analysis techniques with the aim of developing an understanding of research collaboration in this scientific community. Using co-authorship data from 3125 articles published in the journal Scientometrics with a time span of more than three decades (1980-2012), we construct an evolving co-authorship network and calculate three centrality measures (closeness, betweenness, and degree) for 3024 authors, 1207 institutions, 68 countries and 22 academic fields in this network. This paper also discusses the usability of centrality measures in author ranking, and suggests that centrality measures can be useful indicators for impact analysis. Findings revealed that scientometrics was not dominated by a couple of key researchers as quite a significant number of popular researchers were identified. The United States occupies the topmost position in all measures except for degree centrality. The most active, central and collaborative academic discipline in scientometrics is Information & Library Science.
|
| [16] |
Community Detection in Graphs [J].https://doi.org/10.1016/j.physrep.2009.11.002 URL [本文引用: 2] |
| [17] |
Uncovering the Overlapping Community Structure of Complex Networks in Nature and Society [J].https://doi.org/10.1038/nature03607 URL PMID: 15944704 [本文引用: 2] 摘要
Abstract: Many complex systems in nature and society can be described in terms of networks capturing the intricate web of connections among the units they are made of. A key question is how to interpret the global organization of such networks as the coexistence of their structural subunits (communities) associated with more highly interconnected parts. Identifying these a priori unknown building blocks (such as functionally related proteins, industrial sectors and groups of people) is crucial to the understanding of the structural and functional properties of networks. The existing deterministic methods used for large networks find separated communities, whereas most of the actual networks are made of highly overlapping cohesive groups of nodes. Here we introduce an approach to analysing the main statistical features of the interwoven sets of overlapping communities that makes a step towards uncovering the modular structure of complex systems. After defining a set of new characteristic quantities for the statistics of communities, we apply an efficient technique for exploring overlapping communities on a large scale. We find that overlaps are significant, and the distributions we introduce reveal universal features of networks. Our studies of collaboration, word-association and protein interaction graphs show that the web of communities has non-trivial correlations and specific scaling properties.
|
| [18] |
Fast Unfolding of Communities in Large Networks [J]. |
| [19] |
Modularity and Community Structure in Networks [J].https://doi.org/10.1073/pnas.0601602103 URL [本文引用: 2] |
| [20] |
Fast Multi-scale Detection of Relevant Communities in Large-scale Networks [J]. |
| [21] |
Learning the Parts of Objects by Non- negative Matrix Factorization [J].https://doi.org/10.1038/44565 URL PMID: 10548103 [本文引用: 2] 摘要
Is perception of the whole based on perception of its parts? There is psychological and physiological evidence for parts-based representations in the brain, and certain computational theories of object recognition rely on such representations. But little is known about how brains or computers might learn the parts of objects. Here we demonstrate an algorithm for non-negative matrix factorization that is able to learn parts of faces and semantic features of text. This is in contrast to other methods, such as principal components analysis and vector quantization, that learn holistic, not parts-based, representations. Non-negative matrix factorization is distinguished from the other methods by its use of non-negativity constraints. These constraints lead to a parts-based representation because they allow only additive, not subtractive, combinations. When non-negative matrix factorization is implemented as a neural network, parts-based representations emerge by virtue of two properties: the firing rates of neurons are never negative and synaptic strengths do not change sign.
|
| [22] |
应用非负矩阵分解模型的社区发现方法综述 [J].https://doi.org/10.3778/j.issn.1673-9418.1505047 Magsci [本文引用: 2] 摘要
非负矩阵分解(nonnegative matrix factorization,NMF)在提取高维数据中隐含模式和结构方面具有良好性能,已成为数据挖掘领域的热点研究之一。NMF作为无监督学习的有效工具,在模式识别、文本处理、多媒体数据分析以及生物信息学等研究领域得到了广泛应用。目前,已有工作将NMF模型应用于网络数据挖掘,发现网络中隐含的社区结构。对基于NMF的社区发现方法进行了总结,包括无监督的社区发现方法和半监督的社区发现方法,通过在实际网络和人工网络进行实验,比较分析了不同算法的性能,进一步研究了当前基于NMF发现社区结构所面临的挑战,并对下一步研究方向进行了展望。
Survey on Community Detection Algorithms Using Nonnegative Matrix Factorization Model [J].https://doi.org/10.3778/j.issn.1673-9418.1505047 Magsci [本文引用: 2] 摘要
非负矩阵分解(nonnegative matrix factorization,NMF)在提取高维数据中隐含模式和结构方面具有良好性能,已成为数据挖掘领域的热点研究之一。NMF作为无监督学习的有效工具,在模式识别、文本处理、多媒体数据分析以及生物信息学等研究领域得到了广泛应用。目前,已有工作将NMF模型应用于网络数据挖掘,发现网络中隐含的社区结构。对基于NMF的社区发现方法进行了总结,包括无监督的社区发现方法和半监督的社区发现方法,通过在实际网络和人工网络进行实验,比较分析了不同算法的性能,进一步研究了当前基于NMF发现社区结构所面临的挑战,并对下一步研究方向进行了展望。
|
| [23] |
Community Discovery Using Nonnegative Matrix Factorization [J].https://doi.org/10.1007/s10618-010-0181-y URL [本文引用: 1] 摘要
Complex networks exist in a wide range of real world systems, such as social networks, technological networks, and biological networks. During the last decades, many researchers have concentrated on exploring some common things contained in those large networks include the small-world property, power-law degree distributions, and network connectivity. In this paper, we will investigate another important issue, community discovery, in network analysis. We choose Nonnegative Matrix Factorization (NMF) as our tool to find the communities because of its powerful interpretability and close relationship between clustering methods. Targeting different types of networks (undirected, directed and compound), we propose three NMF techniques (Symmetric NMF, Asymmetric NMF and Joint NMF). The correctness and convergence properties of those algorithms are also studied. Finally the experiments on real world networks are presented to show the effectiveness of the proposed methods.
|
| [24] |
Overlapping Community Detection via Bounded Nonnegative Matrix Tri-factorization [C]// |
| [25] |
Structural and Functional Discovery in Dynamic Networks with Non-negative Matrix Factorization [J].https://doi.org/10.1103/PhysRevE.88.042812 URL PMID: 24229230 [本文引用: 1] 摘要
Time series of graphs are increasingly prevalent in modern data and pose unique challenges to visual exploration and pattern extraction. This paper describes the development and application of matrix factorizations for exploration and time-varying community detection in time-evolving graph sequences. The matrix factorization model allows the user to home in on and display interesting, underlying structure and its evolution over time. The methods are scalable to weighted networks with a large number of time points or nodes and can accommodate sudden changes to graph topology. Our techniques are demonstrated with several dynamic graph series from both synthetic and real-world data, including citation and trade networks. These examples illustrate how users can steer the techniques and combine them with existing methods to discover and display meaningful patterns in sizable graphs over many time points.
|
| [26] |
Overlapping Community Detection at Scale: A Nonnegative Matrix Factorization Approach [C]// |
| [27] |
Overlapping Community Detection in Networks: The State-of-the-Art and Comparative Study [J].https://doi.org/10.1145/2501654.2501657 URL [本文引用: 1] 摘要
This article reviews the state-of-the-art in overlapping community detection algorithms, quality measures, and benchmarks. A thorough comparison of different algorithms (a total of fourteen) is provided. In addition to community-level evaluation, we propose a framework for evaluating algorithms' ability to detect overlapping nodes, which helps to assess overdetection and underdetection. After considering community-level detection performance measured by normalized mutual information, the Omega index, and node-level detection performance measured by F-score, we reached the following conclusions. For low overlapping density networks, SLPA, OSLOM, Game, and COPRA offer better performance than the other tested algorithms. For networks with high overlapping density and high overlapping diversity, both SLPA and Game provide relatively stable performance. However, test results also suggest that the detection in such networks is still not yet fully resolved. A common feature observed by various algorithms in real-world networks is the relatively small fraction of overlapping nodes (typically less than 30%), each of which belongs to only 2 or 3 communities.
|
| [28] |
Overlapping Community Detection Using Bayesian Non-negative Matrix Factorization [J].https://doi.org/10.1103/PhysRevE.83.066114 URL PMID: 21797448 [本文引用: 1] 摘要
Abstract Identifying overlapping communities in networks is a challenging task. In this work we present a probabilistic approach to community detection that utilizes a Bayesian non-negative matrix factorization model to extract overlapping modules from a network. The scheme has the advantage of soft-partitioning solutions, assignment of node participation scores to modules, and an intuitive foundation. We present the performance of the method against a variety of benchmark problems and compare and contrast it to several other algorithms for community detection.
|
| [29] |
|
| [30] |
Automatic Relevance Determination for Multi-way Models [J].https://doi.org/10.1002/cem.1223 URL [本文引用: 1] 摘要
Estimating the adequate number of components is an important yet difficult problem in multi-way modeling. We demonstrate how a Bayesian framework for model selection based on automatic relevance determination (ARD) can be adapted to the Tucker and CandeComp/PARAFAC (CP) models. By assigning priors for the model parameters and learning the hyperparameters of these priors the method is able to turn off excess components and simplify the core structure at a computational cost of fitting the conventional Tucker/CP model. To investigate the impact of the choice of priors we based the ARD on both Laplace and Gaussian priors corresponding to regularization by the sparsity promoting l 1-norm and the conventional l 2-norm, respectively. While the form of the priors had limited effect on the results obtained the ARD approach turned out to form a useful, simple, and efficient tool for selecting the adequate number of components of data within the Tucker and CP structure. For the Tucker and CP model the approach performs better than heuristics such as the Bayesian information criterion (BIC), Akaikes information criterion (AIC), DIFFIT and the numerical convex hull (NumConvHull) while operating only at the cost of estimating an ordinary CP/Tucker model. For the CP model the ARD approach performs almost as well as the core consistency diagnostic (CorConDiag). Thus, the ARD framework is a simple yet efficient tool for the estimation of the adequate number of components in multi-way models. A Matlab implementation of the proposed algorithm is available for download at www.erpwavelab.org . Copyright 漏 2009 John Wiley & Sons, Ltd.
|
| [31] |
RSS-CNKI [EB/OL]. [ |
| [32] |
A Unified Probabilistic Framework for Name Disambiguation in Digital Library [J].https://doi.org/10.1109/TKDE.2011.13 URL [本文引用: 1] 摘要
Despite years of research, the name ambiguity problem remains largely unresolved. Outstanding issues include how to capture all information for name disambiguation in a unified approach, and how to determine the number of people K in the disambiguation process. In this paper, we formalize the problem in a unified probabilistic framework, which incorporates both attributes and relationships. Specifically, we define a disambiguation objective function for the problem and propose a two-step parameter estimation algorithm. We also investigate a dynamic approach for estimating the number of people K. Experiments show that our proposed framework significantly outperforms four baseline methods of using clustering algorithms and two other previous methods. Experiments also indicate that the number K automatically found by our method is close to the actual number.
|

/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}