张志强 , 范少萍
, 范少萍
Zhang Zhiqiang, Fan Shaoping
中图分类号: G350
通讯作者:
收稿日期: 2017-12-27
修回日期: 2018-01-9
网络出版日期: 2018-01-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】了解并梳理大数据驱动的知识发现新范式下, 生物医学信息学的最新进展, 并给出生物医学信息学未来发展的建议。【方法】通过文献调研与平台试用, 总结近几年生物医学信息学在大数据资源体系建设、数据分析平台、数据分析方法、辅助临床决策应用等方面的发展现状。【结果】未来可将加强生物医学大数据体系建设、创新大数据分析基础理论与方法研究、推进知识分析工具与平台开发、促进临床转化应用以及培养高层次专门人才等作为生物医学信息学的重点发展方面。【局限】限于篇幅, 未全面涉及生物医学数据资源、方法与应用案例等。【结论】本文针对精准医学大数据知识发现环境下生物医学信息学发展提出5方面建议, 可辅助该学科进一步顺应科学大数据的发展趋势, 满足领域知识发现的需求。
关键词:
Abstract
[Objective] This paper reviews the latest Biomedical Informatics studies and indicates some future directions for data-driven knowledge discovery in precision medicine. [Methods] We summarized the developments of data resources, data analysis platforms and methods, clinical decision-making applications in Biomedical Informatics through literature review and service trials. [Results] Future directions of Biomedical Informatics include building better big data management system, proposing theories and methods for big data analysis, developing new tools and platforms, clinical application of research findings, as well as training senior personnel. [Limitations] More biomedical data resources, methods, and case studies should be added. [Conclusions] This study identifies the future developments of Biomedical Informatics in precision medicine, which utilizes big data analytics to discover more knowledge.
Keywords:
自2015年1月20日美国总统奥巴马在国情咨文中提出“精准医学计划”(Precision Medicine Initiative, PMI)[1]并于当月正式启动以来, 各国政府迅速跟进。澳大利亚、法国、韩国以及我国政府正式启动国家层面的“精准医学研究”计划, 预示着全球“精准医学”时代的到来。所谓精准医学(Precision Medicine, PM)是一种考虑个体在基因、环境和生活方式等方面差异的创新方法, 为医疗专业人员治疗疾病提供有针对性的治疗方案, 进而发展医学研究, 保证人类健康[2]。精准医学概念的正式提出, 为传统的医疗和医学模式指明了新方向, 借助组学与大数据技术进一步开展尚无法治疗的疾病的研究, 以解决人类健康问题。
生物医学信息学(Biomedical Informatics)是包括生物信息学、医学信息学在内的综合性交叉学科, 是研究和探讨分子生物学、临床医学和健康数据采集、处理、储存、分发、分析、解释和可视化等在内的所有方面的科学, 是综合运用计算机科学、生物学、信息学等各种技术, 以展示或挖掘数据所包含的意义, 进而辅助生物医学研究与应用的科学[3,4]。由于生物医学信息学是研究如何利用医学领域相关数据并使其产生价值的科学, 对精准医学的发展具有重要的作用与意义。Gonzalez等[5]认为精准医学将彻底改变人类治疗和预防疾病的方式, 对可应用于精准医学研究的文本挖掘和数据挖掘的基本方法与最新进展进行梳理, 以推动其在精准医学方面的应用。Barbolosi等[6]分析了数学模型在肿瘤靶向给药方面的研究进展, 得到计算肿瘤学对使用数学模型计算抗癌药物的药代动力学和药效学关系是未来发展的新趋势。Chen等[7]在介绍各种已有药物相关数据库基础上, 对现有各种预测药物靶标关联的计算模型进行分析与对比, 并讨论了基于计算网络的药物发现发展方向。同时, 对国际主要生物医学数据库[8]、数据分析平台[9]等的介绍性文章也得到生物医学领域的广泛关注。上述研究阐述了生物医学信息学在精准医学中的应用前景, 进一步说明在精准医学倡导的大数据、多组学、强关联时代发展生物医学信息学的必要性与紧迫性。
精准医学时代是生物医学信息学发展的加速期与关键期, 同时也对生物医学信息学提出了更高要求与更多挑战。本文在梳理近年生物医学信息学在数据资源建设、数据分析平台、数据分析方法、辅助临床决策应用等方面发展的基础上, 探究生物医学信息学的机遇与挑战, 并给出未来生物医学信息学发展建议。
本文从数据资源体系建设与变化、数据分析工具与平台、数据分析方法与技术、关键应用领域4个方面介绍生物医学信息学的发展现状。
(1) 数据资源体系建设
根据精准医学需求, 需采集的数据类型既包括电子病历中结构化和非结构化的临床数据、生命体征与既往病史数据、医疗保险数据、生物样本组学数据、地理和环境数据、调查与观察数据等[10]医学临床诊疗数据, 又包括科学文献、药物研发专利等文本数据。随着生物医学领域数据资源体系的发展, 已覆盖基因、蛋白、通路、疾病、表型、药物等全过程, 数据类型丰富、数据量大且增长迅速。
梳理国际生物医学信息学领域有重要影响的三家研究机构(美国国立生物技术信息中心(NCBI)、欧洲生物信息学研究所(EBI)、瑞士生物信息学研究所(SIB))的数据资源体系, 结合目前生物医学领域主流数据库特点, 可以将生物医学数据资源主要分为以下类型:
①核酸数据库: 指DNA、RNA序列的数据资源库, 如GenBank、miRBase、EMBL等。
②蛋白质数据库: 指存储蛋白质信息的数据资源库, 如Swiss-Port、PDB、TrEMBL等。
③药物数据库: 指存储药物数据(如化学数据、药理数据、靶点信息等)的数据资源库, 如DrugBank、PharmGKB、PubChem等。
④通路数据库: 指存储物种内各项反应及生物学路径的数据库, 如Reactome、KEGG、BiGG等。
⑤基因/突变-疾病数据库: 指存储与疾病相关的遗传变异信息的数据库, 如ClinVar、OMIM、TCGA等。
⑥文献数据库: 指存储各种生物医学文献等科学知识的数据库, 如PubMed、Medline、ClinicalKey、中国生物医学文献服务系统SinoMed、万方医学网等。
⑦临床试验数据库: 指存储公共或私人资助的关于人类受试者参与的临床试验的过程和结果的数据库, 如ClinicalTrials.gov、中国临床试验注册中心ChiCTR等。
(2) 数据资源体系变化
①机构数据库的数据变化
Nucleic Acids Research期刊每年都进行相关数据库的统计分析, 2017年第1期“数据库特刊”中介绍到, 过去一年生物医学领域新建54个数据库, 98个数据库数据进行了更新[11]。其中, 美国国立生物技术信息中心(NCBI)的6大类数据库: 文献、健康、基因组、基因、蛋白质和化合物的数据量均有不同幅度的增加, 如表 1所示。这些数据量的快速增长对数据存储、处理与分析工具提出更高的要求。
表1 NCBI部分数据库的数据量及增长量(截至2016年9月3日)[
| 数据库名称 | 数据量 | 年增长量 |
|---|---|---|
| PubMed | 26 413 966 | 4.7% |
| MeSH | 265 382 | 2.4% |
| ClinVar | 159 184 | 27.4% |
| dbVar | 6 147 903 | 37.2% |
| SNP | 819 309 474 | 16.1% |
| Taxonomy | 1 617 350 | 13.3% |
| Gene | 24 351 351 | 13.8% |
| Protein | 307 799 547 | 37.7% |
| PubChem Compound | 91 679 397 | 50.9% |
②主题数据库的数据变化
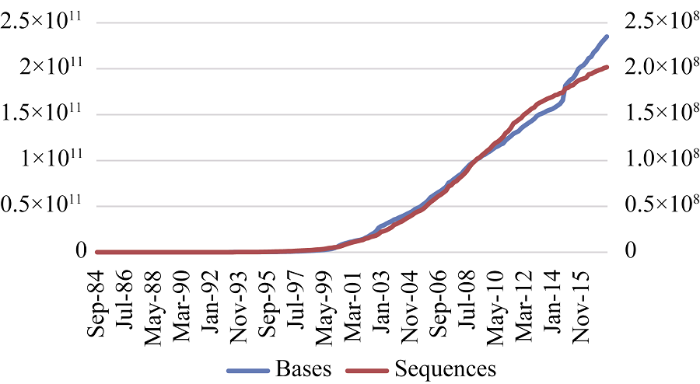
核酸数据库以美国GenBank数据库的数据量变化为例。GenBank是NCBI建立的DNA序列数据库, 其中的数据资源被分为12个类别、5个高通量类别和专利序列(PAT)等, 共计20种分类。数据库中Base和Sequences数据在1982年12月-2017年6月的增长情况如图 1所示。可见, 自2002年以后, 呈明显指数级增长。
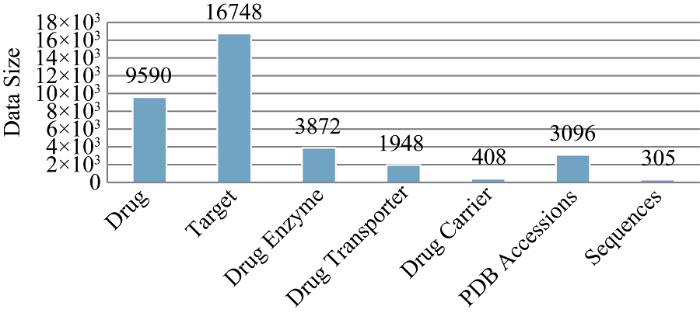
药物数据库以加拿大的DrugBank为例。DrugBank在2006年首次发布, 包含丰富的注释资源, 结合了详细的药物数据(如, 化学数据、药理数据、药物数据)和药物靶点信息(如, 序列、结构和作用途径)。截至2017年9月, 数据库存储各类型数据的数量信息如图 2所示。虽然DrugBank数据库总量较其他数据库相比较小, 但每条药物信息均经过人工编审, 附加了其他相关的靶点等信息, 进一步提高了数据的准确率与可用性。
临床试验数据库以美国的ClinicalTrials.gov为例。ClinicalTrials.gov是由美国国立卫生研究院(NIH)和美国食品药物管理局(FDA)维护的临床医学数据注册和结果数据库, 为患者、病人家属、医护人员、研究人员和公众提供有关疾病和病情的公开和私人支持的临床研究信息。截至2017年9月, ClinicalTrials.gov已经注册了200多个国家的255 356项研究。数据库累积注册临床试验数量自2007年后增长迅速[15], 不仅说明科研人员对临床试验项目的规范化管理与重视, 更表明临床试验活动的广泛开展。
从上述数据量变化中可以看出, 无论是机构数据库亦或是主题数据库, 存储数据在2000年之后均呈现较明显的增长趋势, 且近年的年均增长速度较快。数据的快速增长反映了学科领域本身的快速发展, 对数据存储与处理也提出了更高要求。
多源异构海量生物医学数据的出现, 对数据分析工具与平台的要求与日俱增。为应对领域科学大数据的挑战, 从繁多的数据中发现更有价值和意义的生物医学知识, 领域专家开发了用于生物医学数据分析的工具与平台, 典型应用工具与平台如下。
(1) 生物医学数据分析工具
国际三大生物信息学研究机构(NCBI、EBI、SIB)在推出自己数据库的同时, 也给出了相应的数据分析工具, 以辅助科研人员更好地利用已有数据和资源。如NCBI提供的BLAST(Basic Local Alignment Search Tool)。BLAST可以迅速与公开数据库中的序列进行相似度比较, 按照评分高低、序列相似度对结果进行排序, 也是目前采用最多的序列相似度分析工具之一。在此基础上, 已开发了Primer-BLAST(引物特异性验证)、Genome BLAST等工具[16]。EBI在其数据基础上, 开发了EMBOSS系列工具, 如EMBOSS Backtranambig、EMBOSS Cpgplot、EMBOSS Newcpgreport等[17]。SIB根据资源类型对其分析工具进行分类, 如可用于基因与基因组序列比对分析的Codon Suite、LALIG; 用于蛋白质序列分析与识别的LALIGN、Translate; 用于结构分析的SwissDock等[18]。此外, 用于数据库检索的工具: ChEMBL BLAST Search; 文献数据管理的工具: EndNote、NoteExpress; 通用数据分析工具: SPSS、R等, 均为生物医学数据管理与分析提供了极大便利, 能够更有效地挖掘与使用已有数据资源。
(2) 生物医学数据分析平台
①DisGeNET知识发现平台
DisGeNET是一个公开可用的基因-变异与人类疾病关系的知识发现平台[9], 集成了领域专家编审数据、GWAS目录、动物模型和科学文献数据等多个公共数据源和文献信息, 旨在解决各种有关人类疾病的遗传学问题。上述数据依据受控词表和领域本体进行标注, 确保数据的标准化与唯一性。DisGeNET通过抽取全部来源数据中基因-疾病、变异-疾病间存在的关系, 并根据证据等级计算关系的得分, 实现基因-疾病、变异-疾病间关系的抽取与预测。DisGeNET (v5.0)中包含561 119条基因-疾病关系和135 588条变异-疾病关系[19]。
②IPA平台
Ingenuity Pathway Analysis(IPA)是一款一体化的云端数据分析平台, 可以实现基因表达、miRNA和SNP微阵列及代谢组学、蛋白质组学和RNA-seq等实验数据的分析和生物学解释, 以帮助研究人员快速分析和理解实验数据[20]。IPA建有自己的数据本体, 通过多源数据获取(文献数据、临床诊疗数据、生物数据库数据等), 将从文献中获得的生物信息转变成知识库中统一标准的信息数据, 在人工编审基础上, 发现疾病、基因、药物、病人表型、分子机制等方面的内容与关系, 且具有多种数据分析功能[21](如, 疾病或功能视图、通路设计、毒性清单和毒性作用、网络分析等)。
此外, 相关生物医学数据分析与知识发现平台还有NIH资助斯坦福大学开发的药物遗传学和药物基因组学知识库(Pharmacogenetics and Pharmacogenomics Knowledge Base, PharmGKB)[22]、美国国立环境卫生科学研究所(NIEHS)资助北卡罗莱纳州立大学开发的比较毒理基因组学数据库(Comparative Toxicogenomics Database, CTD)[23]、Wolters Kluwer (威科集团)开发的UpToDate临床顾问数据库[24]等。上述分析平台的开发与利用, 为生物医学研究与临床诊疗提供了极大的便利。
领域数据是支持学科信息学发展的基础, 数据分析方法与技术是推动学科信息学发展的引擎。学科信息学领域研究常用的信息科学与计算技术的各种学科的方法与技术[25], 同样适用于生物医学信息学。
信息科学中的统计学方法是生物医学研究中常用的数据分析方法。如MutSig、MuSic、InVex等癌症基因组分析方法[26], 充分运用了信息学理论与方法, 重点关注基因突变在样本数据中的频率。此外, 机器学习与人工智能方法由于具有强大的特征提取、复杂模型的学习与构建等能力, 在生物医学领域得到了广泛关注与应用, 特别是深度学习方法的兴起与发展, 为突破大数据处理效率与精度瓶颈提供了现实方案。例如, 深度学习在阿尔茨海默病研究中, 可以用于判断具有轻度认知障碍的病人的类型以及预测医疗干预的效果。美韩两国都在使用深度学习模型, 基于核磁共振成像技术和正电子发射断层扫描图, 进行阿尔茨海默病的分类研究, 效果良好[27]。
同时, 生物云计算(Biomedical Cloud Computing)[28]的出现为解决生物医学大数据环境下的数据存储与计算等问题提供了解决思路。国内外生物医学大数据分析平台及应用主要有美国的Amazon Elastic Compute Cloud(EC2)、Google Compute Engine和Microsoft HealthVault以及中国的浪潮云海等。这些云平台均有服务于生物大数据分析的序列比对、聚类、关联分析等功能[29]。
(1) 肿瘤治疗领域
美国癌症研究所(NCI)自2014年关注精准医学研究, 已启动一系列精准医学临床试验。NCI领导的精准肿瘤学的重点是扩大精准医学临床试验, 克服耐药性, 开发新的实验室研究模型, 并研发国家肿瘤知识系统[30]。该系统整合了肿瘤基因组信息和临床反应数据(如, 肿瘤缩小)、结果信息(如, 生存时长)等, 为科学家、健康管理专家和病人提供资源。目前已经开发和推出基因组数据共享计划(Genomic Data Commons), 建立了一个独立的可扩展知识库; 推出肿瘤基因组学云试点(Cancer Genomics Cloud Pilots), 为数据共享提供基于云的数据和计算框架; 定义用于肿瘤基因组数据交换的标准接口, 包括基因组API。
IBM Watson肿瘤解决方案是一种认知计算系统, 使用自然语言和机器学习分析海量的非结构化医疗数据, 为癌症病人提供私人定制的、以症状为依据的治疗建议。目前已帮助5大洲13个国家的50多家医院的多位医生提供肿瘤治疗方案[31]。
(2) 罕见病治疗领域
罕见病是指患病率低于万分之七的疾病, 约95%的罕见病尚没有特效治疗药物, 是当今医学的重大难点问题之一。利用精准医学思路与方法, 通过结合临床表型与组学信息的创新诊断方法可以实现某些罕见病的早期诊断和干预。基于此, 全国20余家研究单位将合作建立首个国家罕见病注册登记系统, 开展超过50种、不少于5万例罕见疾病的注册登记, 整合临床信息及生物组学信息, 并在此基础上开展大型队列研究。国家罕见病注册系统及其相关队列研究的建立将极大地推动我国罕见病及精准医学研究跨越式进入国际先进行列, 是健康中国建设的重要战略实践[32]。
(3) 其他疾病治疗领域
在精神分裂症治疗领域, Xu等[33]开发了PhenoPredict系统, 该系统可通过知识库推断表型相似疾病的治疗药物对精神分裂症的治疗效果。在慢性病管理与治疗领域, 生物医学信息学方法与技术已成功应用到2型糖尿病与心血管病发生率研究[34]中, 充分发挥了其大数据分析与知识发现的功能与作用。
精准医学是一个多学科、多领域、多技术融合的医疗体系[35], 通过大数据技术, 能够将基因组、转录组、蛋白质组、代谢组等方面的数据进行全面整合, 深入挖掘其生物学和医学价值[36]。生物医学信息学是生物学、医学和信息学等融合发展的交叉学科, 需要建设与维护海量多源生物医学数据资源, 需要大数据技术、计算技术和互联网技术的支持。因此, 在精准医学蓬勃发展、快速推进的过程中, 对生物医学信息学学科发展提出了更高要求。针对精准医学与生物医学信息学二者的相同点以及生物医学信息学在精准医学时代的发展特点, 本文提出生物医学信息学发展的几点建议。
(1) 加强国家生物医学信息学大数据体系建设与开放共享
实施国家生物医学大数据国家战略, 持续加强生物医学数据资源与资源体系建设与维护, 推进生物医学数据标准化工作, 促进数据整合与共享, 服务领域大数据知识发现和应用。我国生物、医学资源极其丰富, 并具有特殊性, 因此建立我国自己的生物医学大数据体系, 具有重要的战略意义。以世界三大生物信息学中心NCBI、EBI、SIB为例, 拥有的基因、蛋白、化合物、结构等不同类型数据库已达数百种。随着测序技术的发展、多组学数据的交叉融汇, 未来将会有更多类型、更大数量的生物医学数据待加工、存储与利用。如此海量多源的生物医学数据资源种类与数量, 在更新维护、存储管理等方面需要投入大量的人财物等资源。同时, 面对生物医学领域数据的指数级增长, 建立国际通用的标准化数据规范, 对国际间医疗组织、科研团体等之间的数据共享、资源整合、学术交流、医疗合作等方面具有广阔前景, 也是实现精准医学的前提与保障。例如, 为规范国际上基因组数据的描述、交换和整合, 成立了基因标准联盟(The Genomic Standards Consortium, GSC), 该联盟制定了一系列基因序列格式标准(如, MIGS[37]、MIMARKS[38]等)。MeSH主题词表在PubMed、Medline等生物医学文献标引、领域本体建设、领域知识图谱构建等方面发挥了重要作用, 极大地促进了文献数据的共享, 提高了语义查询的准确率。
(2) 推进生物医学信息学大数据分析的基础理论和方法研究
创新生物医学数据分析方法, 加强大数据分析、云计算、机器学习、人工智能等理论与技术的研发、推广与应用, 支撑和推动多维海量数据的精准分析工作, 挖掘数据潜藏的巨大价值。当前, 高通量DNA测序和质谱仪技术的进步使得科学家和医疗人员能够对人体的细胞和组织、体液等采样, 综合个人健康档案等信息既可以全面了解个人的健康状况, 又可以根据疾病发病开展有针对性的预防与治疗。但如何有效地利用和整合、计算与分析这些数据是最主要的挑战[39]。如今, 人工智能、机器学习, 特别是深度学习等理论和方法在生物医学大数据和精准医学发展中有巨大的发展潜力[40], 已在医学文本的命名实体识别[41]、关系抽取[42]、图像识别[43]、预测癌症治疗反应[44]、疾病分型分类[45]等多个方面得到较好的应用。云计算的计算资源是动态、可伸缩、被虚拟化的, 并以服务的方式提供, 是解决精准医学大数据分析问题的强大动力[46]。其中MapReduce、Hadoop等高扩展性、高性能的并行计算模型, 分布式海量数据的处理框架和关键技术, 使得生物医学大数据的存储、计算、分析等成为现实。同时, 云计算平台具有运行成本低、并行可扩展的优势, 可以为更复杂多样的海量数据挖掘提供新的技术和工具支撑。
(3) 开发生物医学信息学大数据分析的专用分析工具和知识分析平台
大力推进生物医学专用分析工具和软件开发, 推动基于大数据技术与方法的精准医学知识库建设, 加强临床决策支持平台的开发与应用。开发新的、可扩展的生物医学分析工具, 更新并完善现有工具功能与数据容量, 加载新的数据分析方法, 增加数据的语义检索、多维数据的综合检索与展示功能等, 都将是生物医学数据挖掘与可视化的助推剂。已有平台如IPA、UpToDate等已经基本实现多源异构数据的整合、标准化、关联与挖掘工作, 但平台数据量有限, 需要投入较多人力进行编审以保证数据质量与可靠性, 限制了数据覆盖面与更新频率。因此, 推动基于大数据技术与方法的精准医学知识库建设, 利用先进技术理论与方法解决数据关联、维护、更新等方面遇到的瓶颈是未来一段时期的优选策略。
临床决策支持平台可以整合患者的电子病例、电子健康档案、组学检测数据等与患者健康相关的数据, 综合为医生提供临床决策支持服务, 是精准医学知识库的延伸与临床应用, 是生物医学信息学成果系统化应用的平台与手段。如, 已开发的分子图谱与可行治疗方法整合系统(Integrating Molecular Profiles with Actionable Therapeutics, IMPACT), 可用于临床上依据外显子测序数据预测可干预药物[47]。这些平台的使用, 将为临床医生提供更加全面细致的疾病诊断与治疗方案, 推动精准医学发展。
(4) 加快推进生物医学信息学研究成果的临床转移与转化应用, 实现临床精准治疗
生物医学信息学应发挥学科优势与特点, 在患者临床分子分型、个人全面信息、组学、影像学等数据的收集、整合、存储、分析与挖掘等数据生命周期全链条中发挥作用。根据数据分析结果, 向临床医生推荐高度个体化和疾病特异性的治疗方案, 包括分子靶向治疗、抗体靶向治疗、精准免疫治疗以及个体化细胞治疗等策略[48], 以实现疾病的预警、筛查和诊断, 指导治疗方案的选择、以及治疗敏感性、疾病预后和转归的预测。加速生物医学信息学研究成果的临床转化与推广, 是实现精准治疗、发展生物医学信息学学科以实现全民健康的关键途径。
(5) 完善生物医学信息学课程体系设计, 培养复合型高层次专业人才
积极顺应大数据科学研究范式发展的要求, 改革并完善高校生物医学信息学学科设置和人才培养模式。例如, 加拿大充分重视生物信息学和计算生物学的发展, 2015年出台了国家层面的《加拿大生物信息学和计算生物学战略框架》(Canadian Bioinformatics and Computational Biology Strategic Framework)[49], 大学开设生物医学信息学本科和研究生课程体系, 培养可以胜任生物医学信息学研发工作的复合型人才, 以应对大规模生物医学数据带来的挑战。我国应坚持以科学发展需求和解决科学问题为导向, 建立并完善生物医学信息学复合型人才培养体制与机制, 不断适应生命科学、物理科学、工程科学、认知科学等学科的交叉融合发展趋势[50], 建设一支大数据科学范式背景下生物医学信息学知识发现研究与应用的复合型人才队伍, 以适应生物医学大数据时代数据分析和知识发现的巨大需求。
有理由相信, 精准医学时代是生物医学信息学发展的黄金机遇期, 更要充分发挥学科优势, 以加快精准医学的持续发展, 为建设健康中国服务。
张志强: 提出研究思路, 设计研究方案, 论文修改;
范少萍: 论文撰写与修改;
陈秀娟: 资料收集, 论文撰写。
所有作者声明不存在利益冲突关系。
| [1] |
|
| [2] |
|
| [3] |
Biomedical Informatics and Outcomes Research: Enabling Knowledge-driven Healthcare [J].https://doi.org/10.1161/CIRCULATIONAHA.108.795526 URL PMID: 2814875 [本文引用: 1] 摘要
Abstract The conduct of outcomes research is an information-intensive endeavor and therefore benefits from the application of biomedical informatics approaches, resources, and platforms. It is our contention that a tighter integration of biomedical informatics, clinical care, healthcare policy, and outcomes research can advance improvements in healthcare research and practice. As the preceding overview of the current state of knowledge in these domains illustrates, such integration will require at the most basic level the development of teamscience approaches to outcomes research that include clinicians, researchers, and biomedical informaticians. However, the formation and support of such teams will not be possible without addressing some of the barriers and requirements summarized here. Building on the recent and ongoing advances in biomedical informatics and addressing the issues raised above create a tremendous opportunity to link research, healthcare delivery, and policy in such a way as to have a direct and emonstrable impact on the health and quality of life of the public.
|
| [4] |
Biomedical Informatics and Translational Medicine [J].https://doi.org/10.1186/1479-5876-8-22 URL PMID: 20187952 [本文引用: 1] 摘要
Biomedical informatics involves a core set of methodologies that can provide a foundation for crossing the "translational barriers" associated with translational medicine. To this end, the fundamental aspects of biomedical informatics (e.g., bioinformatics, imaging informatics, clinical informatics, and public health informatics) may be essential in helping improve the ability to bring basic research findings to the bedside, evaluate the efficacy of interventions across communities, and enable the assessment of the eventual impact of translational medicine innovations on health policies. Here, a brief description is provided for a selection of key biomedical informatics topics (Decision Support, Natural Language Processing, Standards, Information Retrieval, and Electronic Health Records) and their relevance to translational medicine. Based on contributions and advancements in each of these topic areas, the article proposes that biomedical informatics practitioners ("biomedical informaticians") can be essential members of translational medicine teams.
|
| [5] |
Recent Advances and Emerging Applications in Text and Data Mining for Biomedical Discovery [J].https://doi.org/10.1093/bib/bbv087 URL PMID: 4719073 [本文引用: 1] 摘要
Precision medicine will revolutionize the way we treat and prevent disease. A major barrier to the implementation of precision medicine that clinicians and translational scientists face is understanding the underlying mechanisms of disease. We are starting to address this challenge through automatic approaches for information extraction, representation and analysis. Recent advances in text and data mining have been applied to a broad spectrum of key biomedical questions in genomics, pharmacogenomics and other fields. We present an overview of the fundamental methods for text and data mining, as well as recent advances and emerging applications toward precision medicine.
|
| [6] |
Computational Oncology - Mathematical Modeling of Drug Regimens for Precision Medicine [J].https://doi.org/10.1038/nrclinonc.2015.204 URL PMID: 26598946 [本文引用: 1] 摘要
Computational oncology is a generic term that encompasses any form of computer-based modelling relating to biology and therapy. Mathematical modelling can be used to probe the pharmacokinetics and pharmacodynamics relationships of the available anticancer agents in order to improve treatment. As a result of the ever-growing numbers of druggable molecular targets and possible drug combinations, obtaining an optimal toxicity-efficacy balance is an increasingly complex task. Consequently, standard empirical approaches to optimizing drug dosing and scheduling in patients are now of limited utility; mathematical modelling can substantially advance this practice through improved rationalization of therapeutic strategies. The implementation of mathematical modelling tools is an emerging trend, but remains largely insufficient to meet clinical needs; at the bedside, anticancer drugs continue to be prescribed and administered according to standard schedules. To shift the therapeutic paradigm towards personalized care, precision medicine in oncology requires powerful new resources for both researchers and clinicians. Mathematical modelling is an attractive approach that could help to refine treatment modalities at all phases of research and development, and in routine patient care. Reviewing preclinical and clinical examples, we highlight the current achievements and limitations with regard to computational modelling of drug regimens, and discuss the potential future implementation of this strategy to achieve precision medicine in oncology.
|
| [7] |
Drug-Target Interaction Prediction: Databases, Web Servers and Computational Models [J].https://doi.org/10.1093/bib/bbv066 URL PMID: 26283676 [本文引用: 1] 摘要
Abstract Identification of drug-target interactions is an important process in drug discovery. Although high-throughput screening and other biological assays are becoming available, experimental methods for drug-target interaction identification remain to be extremely costly, time-consuming and challenging even nowadays. Therefore, various computational models have been developed to predict potential drug-target associations on a large scale. In this review, databases and web servers involved in drug-target identification and drug discovery are summarized. In addition, we mainly introduced some state-of-the-art computational models for drug-target interactions prediction, including network-based method, machine learning-based method and so on. Specially, for the machine learning-based method, much attention was paid to supervised and semi-supervised models, which have essential difference in the adoption of negative samples. Although significant improvements for drug-target interaction prediction have been obtained by many effective computational models, both network-based and machine learning-based methods have their disadvantages, respectively. Furthermore, we discuss the future directions of the network-based drug discovery and network approach for personalized drug discovery based on personalized medicine, genome sequencing, tumor clone-based network and cancer hallmark-based network. Finally, we discussed the new evaluation validation framework and the formulation of drug-target interactions prediction problem by more realistic regression formulation based on quantitative bioactivity data. The Author 2015. Published by Oxford University Press. For Permissions, please email: journals.permissions@oup.com.
|
| [8] |
Overview of the BioBank Japan Project: Study Design and Profile [J].https://doi.org/10.1016/j.je.2016.12.005 URL PMID: 28189464 [本文引用: 1] 摘要
The BBJ Project has constructed the infrastructure for genomic research for various common diseases. This clinical information, coupled with genomic data, will provide important clues for the implementation of personalized medicine.
|
| [9] |
DisGeNET: A Comprehensive Platform Integrating Information on Human Disease-associated Genes and Variants [J].https://doi.org/10.1093/nar/gkw943 URL PMID: 27924018 [本文引用: 2] 摘要
The information about the genetic basis of human diseases lies at the heart of precision medicine and drug discovery. However, to realize its full potential to support these goals, several problems, such as fragmentation, heterogeneity, availability and different conceptualization of the data must be overcome. To provide the community with a resource free of these hurdles, we have developed DisGeNET (http://www.disgenet.org), one of the largest available collections of genes and variants involved in human diseases. DisGeNET integrates data from expert curated repositories, GWAS catalogues, animal models and the scientific literature. DisGeNET data are homogeneously annotated with controlled vocabularies and community-driven ontologies. Additionally, several original metrics are provided to assist the prioritization of genotype henotype relationships. The information is accessible through a web interface, a Cytoscape App, an RDF SPARQL endpoint, scripts in several programming languages and an R package. DisGeNET is a versatile platform that can be used for different research purposes including the investigation of the molecular underpinnings of specific human diseases and their comorbidities, the analysis of the properties of disease genes, the generation of hypothesis on drug therapeutic action and drug adverse effects, the validation of computationally predicted disease genes and the evaluation of text-mining methods performance.
|
| [10] |
精准医学相关的数据管理与知识服务 [J].Precision Medicine Related Data Management and Knowledge Service [J]. |
| [11] |
The 24th Annual Nucleic Acids Research Database Issue: A Look Back and Upcoming Changes [J].https://doi.org/10.1093/nar/gkw1188 URL PMID: 5210597 [本文引用: 1] 摘要
This year's Database Issue ofNucleic Acids Researchcontains 152 papers that include descriptions of 54 new databases and update papers on 98 databases, of which 16 have not been previously featured inNAR. As always, these databases cover a broad range of molecular biology subjects, including genome structure, gene expression and its regulation, proteins, protein domains, and protein–protein interactions. Following the recent trend, an increasing number of new and established databases deal with the issues of human health, from cancer-causing mutations to drugs and drug targets. In accordance with this trend, three recently compiled databases that have been selected byNARreviewers and editors as ‘breakthrough’ contributions,denovo-db, the Monarch Initiative, and Open Targets, cover humande novogene variants, disease-related phenotypes in model organisms, and a bioinformatics platform for therapeutic target identification and validation, respectively. We expect these databases to attract the attention of numerous researchers working in various areas of genetics and genomics. Looking back at the past 12 years, we present here the ‘golden set’ of databases that have consistently served as authoritative, comprehensive, and convenient data resources widely used by the entire community and offer some lessons on what makes a successful database. The Database Issue is freely available online at thehttps://academic.oup.com/narweb site. An updated version of theNARMolecular Biology Database Collection is available athttp://www.oxfordjournals.org/nar/database/a/.
|
| [12] |
Database Resources of the National Center for Biotechnology Information [J].https://doi.org/10.1109/HAPTIC.2010.5444654 URL [本文引用: 1] 摘要
The response of a tactile sensor system (consisting of the sensors themselves and the material covering them) was characterized via robotic experiments. A point spread function model of this response was developed for typical interaction forces, allowing the use of graphics and imaging techniques respectively for simulating and interpreting tactile sensor readings. This model was implemented in software as a generic artificial tactile sensor simulator, and its accuracy at approximating the output of our test system is demonstrated.
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
Tools & Databases [EB/OL]. [ |
| [18] |
Databases & Tools [EB/OL].[2017-08-30]. . |
| [19] |
DisGeNET Database Information [EB/OL]. [ |
| [20] |
Ingenuity Pathway Analysis [EB/OL]. [ |
| [21] |
|
| [22] |
|
| [23] |
CTD (Comparative Toxicogenomics Database) [EB/OL]. [ |
| [24] |
UpToDate [EB/OL]. [ |
| [25] |
论学科信息学的兴起与发展 [J].https://doi.org/10.3772/j.issn.1000-0135.2015.010.001 URL [本文引用: 1] 摘要
随着数据密集型科学研究新范式的出现与日臻发展,科学研究日益成为数据驱动的知识发现活动,Dscience(数据驱动的科学)时代来临.以数据计量分析为核心的一系列专门学科领域的“学科信息学”获得了快速发展和应用,有关的概念、技术和方法等已经得到了相应学科领域的认可.同时,支撑专门领域学科信息学发展的信息分析和应用的一般性知识体系不断完善,为一般学科信息学的产生奠定了坚实的基础.本文基于科学研究新范式的时代背景,提出一个全新的概念——“学科信息学”(Subject Informatics).文章首先从分析专门学科信息学出发,介绍了学科信息学的缘起,总结了一般学科信息学的内涵;其次,明确了学科信息学的主要研究内容、学科体系及其关键技术与方法;最后,重点剖析了学科信息学在促进学科知识创新和知识发现、催生数据科学兴起与应用、推动知识计算理论与方法发展以及促进学科情报分析与战略研究计算化、定量化发展等方面所起的作用.本研究对发展学科信息学理论体系、完善学科信息学研究内容、促进学科信息学发展应用、推动知识创新以及发展领域知识发现研究等具有重要意义.
On the Emergence and Development of Subject Informatics [J].https://doi.org/10.3772/j.issn.1000-0135.2015.010.001 URL [本文引用: 1] 摘要
随着数据密集型科学研究新范式的出现与日臻发展,科学研究日益成为数据驱动的知识发现活动,Dscience(数据驱动的科学)时代来临.以数据计量分析为核心的一系列专门学科领域的“学科信息学”获得了快速发展和应用,有关的概念、技术和方法等已经得到了相应学科领域的认可.同时,支撑专门领域学科信息学发展的信息分析和应用的一般性知识体系不断完善,为一般学科信息学的产生奠定了坚实的基础.本文基于科学研究新范式的时代背景,提出一个全新的概念——“学科信息学”(Subject Informatics).文章首先从分析专门学科信息学出发,介绍了学科信息学的缘起,总结了一般学科信息学的内涵;其次,明确了学科信息学的主要研究内容、学科体系及其关键技术与方法;最后,重点剖析了学科信息学在促进学科知识创新和知识发现、催生数据科学兴起与应用、推动知识计算理论与方法发展以及促进学科情报分析与战略研究计算化、定量化发展等方面所起的作用.本研究对发展学科信息学理论体系、完善学科信息学研究内容、促进学科信息学发展应用、推动知识创新以及发展领域知识发现研究等具有重要意义.
|
| [26] |
Systematic Analysis of Somatic Mutations Impacting Gene Expression in 12 Tumour Types [J].https://doi.org/10.1038/ncomms9554 URL PMID: 4600750 [本文引用: 1] 摘要
We present a novel hierarchical Bayes statistical model, xseq, to systematically quantify the impact of somatic mutations on expression profiles. We establish the theoretical framework and robust inference characteristics of the method using computational benchmarking. We then use xseq to analyse thousands of tumour data sets available through The Cancer Genome Atlas, to systematically quantify somatic mutations impacting expression profiles. We identify 30 novelcis-effect tumour suppressor gene candidates, enriched in loss-of-function mutations and biallelic inactivation. Analysis oftrans-effects of mutations and copy number alterations with xseq identifies mutations in 150 genes impacting expression networks, with 89 novel predictions. We reveal two important novel characteristics of mutation impact on expression: (1) patients harbouring known driver mutations exhibit different downstream gene expression consequences; (2) expression patterns for some mutations are stable across tumour types. These results have critical implications for identification and interpretation of mutations with consequent impact on transcription in cancer. Assessing functional impact of mutations in cancer on gene expression can improve our understanding of cancer biology and may identify potential therapeutic targets. Here, Dinget al. describe a novel statistical model named xseq for a systematic survey of how mutations impact transcriptome landscapes across 12 different tumour types.
|
| [27] |
生物医学数据分析中的深度学习方法应用 [J].
生物医学数据的积累速度史无前例,为生物医学研究带来机遇的同时,也让传统数据分析技术面临巨大挑战.本文综述了深度学习方法应用在生物医学数据分析中的最新研究进展.首先阐述了深度学习方法,列举深度学习方法的主要实现模型,随后总结了目前生物医学数据分析中的深度学习方法应用情况,分析了在数据处理、模型构建和训练方法等方面共有问题的解决方法,最后给出了深度学习方法应用于生物医学数据分析时可能存在的问题及建议.
Applications of Deep Learning in Biological and Medical Data Analysis [J].
生物医学数据的积累速度史无前例,为生物医学研究带来机遇的同时,也让传统数据分析技术面临巨大挑战.本文综述了深度学习方法应用在生物医学数据分析中的最新研究进展.首先阐述了深度学习方法,列举深度学习方法的主要实现模型,随后总结了目前生物医学数据分析中的深度学习方法应用情况,分析了在数据处理、模型构建和训练方法等方面共有问题的解决方法,最后给出了深度学习方法应用于生物医学数据分析时可能存在的问题及建议.
|
| [28] |
Biomedical, Cloud, Computing, with Amazon, Web, Services [J].https://doi.org/10.1371/journal.pcbi.1002147 URL PMID: 2020202202011202020202020202020202073100214720 [本文引用: 1] 摘要
by Vincent A. Fusaro, Prasad Patil, Erik Gafni, Dennis P. Wall, Peter J. Tonellato
|
| [29] |
Big Data for Biomedical Research: Current Status and Prospective [J].https://doi.org/10.1360/N972014-00895 URL [本文引用: 1] 摘要
At the frontier of cross-disciplinary sciences, biomedical research combines theory with methods, and biomedical sciences with computation. The recent in-depth integration of advanced equipment and information technology in biotechnology has led to an explosion of data collection, and thus there is a great need for data storage and analysis. Furthermore, the big data era is impacting greatly on biomedical research. In particular, research is transforming from hypothesis-driven to data-driven investigations. For decades, molecular biology research has been hypothesis driven, but the availability of massive biomedical data now allows researchers to directly explore the regularity contained in the data, make assumptions, and draw conclusions. With the fast accumulation of biomedical data, many problems that were unsolvable in the past can now be solved by carefully designed data analysis methods. At the same time, many new problems in biomedical research have emerged. Examples of big data technologies and applications include personalized genomics, transcriptomic and proteomic studies, genotyping and phenotyping of single cells, microbial community research, and biomedical imaging. All these applications are both data intensive and computation intensive, and thus advanced storage and analysis strategies characterized as being high throughput, high efficiency and high accuracy, are urgently needed to process these massive biological data. In this article, we summarize and review several aspects of biomedical big data(data generation, management, and analysis) and focus on data analysis and the application prospects of newly emerging data including human microbiota, the phenotype and genotype of single cells, and biomedical imaging. We conclude that biomedical big data is gaining momentum, although current hardware and software platforms for data-driven analysis remain a significant hurdle. We expect that as big data analysis breaks through this bottleneck, the in-depth research of biomedical big data will make a more significant contribution to clinical diagnosis and treatment.
|
| [30] |
|
| [31] |
|
| [32] |
中国国家罕见病注册系统及其队列研究: 愿景与实施路线 [J].https://doi.org/10.3760/cma.j.issn.1000-6699.2016.12.001 URL [本文引用: 1] 摘要
罕见病是当今医学重大瓶颈问题,其研究具有独特的科学、社会学、伦理学价值。结合临床表型与组学信息的创新诊断方法可以实现某些罕见病的早期诊断和干预,有效改善疾病预后。罕见病研究对新药研发也起到支撑作用,在解释药物作用机制、发现常见疾病治疗靶点、探索创新性治疗方法、推动制药产业发展上均具有重要意义。由于罕见病患病率低且随访困难,病例注册登记系统及大型队列的建立对罕见病的临床服务和研究至关重要。中国国家罕见病注册系统及其队列研究将为此提供关键支持。全国20余家研究单位将合作建立首个国家罕见病注册登记系统,开展超过50种、不少于5万例罕见疾病的注册登记,整合临床信息及生物组学信息,并在此基础上开展大型队列研究。本项目将首次获得中国人群特异性的罕见病基本信息,为罕见病相关政策制定提供依据,系统性阐释中国人群疾病发病机制,提高罕见病诊疗总体水平,助力新药研发,推动相关健康产业进一步发展。国家罕见病注册系统及其相关队列研究的建立将极大地推动我国罕见病及精准医学研究跨越式进入国际先进行列,是健康中国建设的重要战略实践。
The National Rare Diseases Registry System of China and the Related Cohorts Studies: Vision and Roadmap [J].https://doi.org/10.3760/cma.j.issn.1000-6699.2016.12.001 URL [本文引用: 1] 摘要
罕见病是当今医学重大瓶颈问题,其研究具有独特的科学、社会学、伦理学价值。结合临床表型与组学信息的创新诊断方法可以实现某些罕见病的早期诊断和干预,有效改善疾病预后。罕见病研究对新药研发也起到支撑作用,在解释药物作用机制、发现常见疾病治疗靶点、探索创新性治疗方法、推动制药产业发展上均具有重要意义。由于罕见病患病率低且随访困难,病例注册登记系统及大型队列的建立对罕见病的临床服务和研究至关重要。中国国家罕见病注册系统及其队列研究将为此提供关键支持。全国20余家研究单位将合作建立首个国家罕见病注册登记系统,开展超过50种、不少于5万例罕见疾病的注册登记,整合临床信息及生物组学信息,并在此基础上开展大型队列研究。本项目将首次获得中国人群特异性的罕见病基本信息,为罕见病相关政策制定提供依据,系统性阐释中国人群疾病发病机制,提高罕见病诊疗总体水平,助力新药研发,推动相关健康产业进一步发展。国家罕见病注册系统及其相关队列研究的建立将极大地推动我国罕见病及精准医学研究跨越式进入国际先进行列,是健康中国建设的重要战略实践。
|
| [33] |
PhenoPredict: A Disease Phenome-wide Drug Repositioning Approach Towards Schizophrenia Drug Discovery [J].https://doi.org/10.1016/j.jbi.2015.06.027 URL PMID: 26151312 [本文引用: 1] 摘要
Schizophrenia (SCZ) is a common complex disorder with poorly understood mechanisms and no effective drug treatments. Despite the high prevalence and vast unmet medical need represented by the disease, many drug companies have moved away from the development of drugs for SCZ. Therefore, alternative strategies are needed for the discovery of truly innovative drug treatments for SCZ. Here, we present a disease phenome-driven computational drug repositioning approach for SCZ. We developed a novel drug repositioning system, PhenoPredict, by inferring drug treatments for SCZ from diseases that are phenotypically related to SCZ. The key to PhenoPredict is the availability of a comprehensive drug treatment knowledge base that we recently constructed. PhenoPredict retrieved all 18 FDA-approved SCZ drugs and ranked them highly (recall 1.0, and average ranking of 8.49%). When compared to PREDICT, one of the most comprehensive drug repositioning systems currently available, in novel predictions, PhenoPredict represented clear improvements over PREDICT in Precision-Recall (PR) curves, with a significant 98.8% improvement in the area under curve (AUC) of the PR curves. In addition, we discovered many drug candidates with mechanisms of action fundamentally different from traditional antipsychotics, some of which had published literature evidence indicating their treatment benefits in SCZ patients. In summary, although the fundamental pathophysiological mechanisms of SCZ remain unknown, integrated systems approaches to studying phenotypic connections among diseases may facilitate the discovery of innovative SCZ drugs.
|
| [34] |
Type 2 Diabetes and Incidence of Cardiovascular Diseases: A Cohort Study in 1.9 Million People [J].https://doi.org/10.1016/S0140-6736(15)60401-9 URL PMID: 26312908 [本文引用: 1] 摘要
The contemporary associations of type 2 diabetes with a wide range of incident cardiovascular diseases have not been compared. Previous studies have focussed on myocardial infarction and stroke, and these conditions are the usual outcomes chosen in clinical trials in type 2 diabetes, but other diseases such as heart failure and angina are also major causes of morbidity in diabetes. We aimed to study associations between type 2 diabetes and 12 initial manifestations of cardiovascular disease. We used linked electronic health records from 1997 to 2010 in the CALIBER (cardiovascular research using linked bespoke studies and electronic health records) programme to investigate the absolute and relative risks associated with type 2 diabetes in a cohort of 1·92 million patients in England. We included patients aged 30 years and older who were free from cardiovascular disease at baseline. This study is registered withClinicalTrials.gov, numberNCT01804439. We observed 11364638 first presentations of cardiovascular disease during a median follow-up of 5·5 years (IQR 2·1–10·1). 3464198 people had type 2 diabetes: 6137 experienced a first cardiovascular presentation, of which the most common were peripheral arterial disease (16·2%, n=992) and heart failure (14·1%, n=866). Type 2 diabetes was strongly positively associated with peripheral arterial disease (adjusted cause-specific hazard ratio 2·98, 95% CI 2·76–3·22), ischaemic stroke (1·72, 1·52–1·95), stable angina (1·62, 1·49–1·77), heart failure (1·56, 1·45–1·69), and non-fatal myocardial infarction (1·54 1·42–1·67), but inversely associated with abdominal aortic aneurysm (0·46, 0·35–0·59) and subarachnoid haemorrhage (0·48, 0·26–0·89). This study suggests that associations of type 2 diabetes vary with different incident cardiovascular diseases. These findings have implications for clinical risk assessment and choice of primary endpoint in trials on type 2 diabetes. Wellcome Trust, National Institute for Health Research, UK Medical Research Council.
|
| [35] |
中国在精准医学领域面临的机遇与挑战 [J].Opportunities and Challenges in Field of Precision Medicine in China [J]. |
| [36] |
中国精准医学发展的需求和任务 [J].https://doi.org/10.3969/j.issn.1005-1678.2016.04.01 URL [本文引用: 1] 摘要
精准医学是随着人类社会的健康需求提高和科学技术不断发展而兴起的新的医疗理念和模式,主要基于个体分子医学和精细医疗操作技术的研究成果,通过对患者进行组学、现代生物学、分子影像学和分子病理学检测,结合患者生活方式和生活环境,为患者制定针对个体疾病特征的最优化治疗方案,以追求最大的治疗效果和最低的副作用。精准医学的诞生经历了萌芽至兴起的历程,中国的精准医学研究与治疗正进入蓬勃发展的新阶段。本文就中国精准医学的发展与规划概况进行阐述,以期为中国精准医学领域的发展提供参考。
Precision Medicine in China [J].https://doi.org/10.3969/j.issn.1005-1678.2016.04.01 URL [本文引用: 1] 摘要
精准医学是随着人类社会的健康需求提高和科学技术不断发展而兴起的新的医疗理念和模式,主要基于个体分子医学和精细医疗操作技术的研究成果,通过对患者进行组学、现代生物学、分子影像学和分子病理学检测,结合患者生活方式和生活环境,为患者制定针对个体疾病特征的最优化治疗方案,以追求最大的治疗效果和最低的副作用。精准医学的诞生经历了萌芽至兴起的历程,中国的精准医学研究与治疗正进入蓬勃发展的新阶段。本文就中国精准医学的发展与规划概况进行阐述,以期为中国精准医学领域的发展提供参考。
|
| [37] |
The Minimum Information about a Genome Sequence (MIGS) Specification [J].https://doi.org/10.1038/nbt1360 URL PMID: 18464787 [本文引用: 1] 摘要
With the quantity of genomic data increasing at an exponential rate, it is imperative that these data be captured electronically, in a standard format. Standardization activities must proceed within the auspices of open-access and international working bodies. To tackle the issues surrounding the development of better descriptions of genomic investigations, we have formed the Genomic Standards Consortium (GSC). Here, we introduce the minimum information about a genome sequence (MIGS) specification with the intent of promoting participation in its development and discussing the resources that will be required to develop improved mechanisms of metadata capture and exchange. As part of its wider goals, the GSC also supports improving the ‘transparency’ of the information contained in existing genomic databases.
|
| [38] |
Minimum Information about a Marker Gene Sequence (MIMARKS) and Minimum Information about Any (x) Sequence (MIxS) Specifications [J].https://doi.org/10.1038/nbt.1823 URL PMID: 3367316 [本文引用: 1] 摘要
Abstract Here we present a standard developed by the Genomic Standards Consortium (GSC) for reporting marker gene sequences--the minimum information about a marker gene sequence (MIMARKS). We also introduce a system for describing the environment from which a biological sample originates. The 'environmental packages' apply to any genome sequence of known origin and can be used in combination with MIMARKS and other GSC checklists. Finally, to establish a unified standard for describing sequence data and to provide a single point of entry for the scientific community to access and learn about GSC checklists, we present the minimum information about any (x) sequence (MIxS). Adoption of MIxS will enhance our ability to analyze natural genetic diversity documented by massive DNA sequencing efforts from myriad ecosystems in our ever-changing biosphere.
|
| [39] |
The Future of Technologies for Personalised Medicine [J].https://doi.org/10.1016/j.nbt.2012.03.009 URL PMID: 23091837 [本文引用: 1] 摘要
Personalised medicine promises prediction, prevention and treatment of illness that is targeted to individuals needs. New technologies for detailed biological profiling of individuals at the molecular level have been crucial in initiating the move to personalised medicine; further novel technologies will be necessary if the vision is to become a reality. We will need to develop new technologies to collect and analyse data in a way that is not just linear but integrated (understanding system level functioning) and dynamic (understanding system in flux). Key factors in the development of technologies for personalised medicine are standardisation, integration and harmonisation. For example, the tools and processes for data collection and analysis must be standardised across research sites. Research activity at different sites must be integrated to maximise synergies, and scientific research must be integrated with healthcare to ensure effective translation. There must also be harmonisation between scientific practices in different research sites, between science and healthcare and between science, healthcare and wider society, including the ethical and regulatory frameworks, the prevailing political and cultural ethos and the expectations of patients/citizens.
|
| [40] |
基于大数据分析法的精准医疗前景 [J].Prospects of Precision Medical Based on Big Data Analysis [J]. |
| [41] |
Applying Deep Learning Techniques on Medical Corpora from the World Wide Web: A Prototypical System and Evaluation [OL].
Abstract: BACKGROUND: The amount of biomedical literature is rapidly growing and it is becoming increasingly difficult to keep manually curated knowledge bases and ontologies up-to-date. In this study we applied the word2vec deep learning toolkit to medical corpora to test its potential for identifying relationships from unstructured text. We evaluated the efficiency of word2vec in identifying properties of pharmaceuticals based on mid-sized, unstructured medical text corpora available on the web. Properties included relationships to diseases ('may treat') or physiological processes ('has physiological effect'). We compared the relationships identified by word2vec with manually curated information from the National Drug File - Reference Terminology (NDF-RT) ontology as a gold standard. RESULTS: Our results revealed a maximum accuracy of 49.28% which suggests a limited ability of word2vec to capture linguistic regularities on the collected medical corpora compared with other published results. We were able to document the influence of different parameter settings on result accuracy and found and unexpected trade-off between ranking quality and accuracy. Pre-processing corpora to reduce syntactic variability proved to be a good strategy for increasing the utility of the trained vector models. CONCLUSIONS: Word2vec is a very efficient implementation for computing vector representations and for its ability to identify relationships in textual data without any prior domain knowledge. We found that the ranking and retrieved results generated by word2vec were not of sufficient quality for automatic population of knowledge bases and ontologies, but could serve as a starting point for further manual curation.
|
| [42] |
Clinical Relation Extraction with Deep Learning [J].https://doi.org/10.14257/ijhit.2016.9.7.22 URL [本文引用: 1] 摘要
Relations between medical concepts convey meaningful medical knowledge and patients health information. Relation extraction on Clinical texts is an important task of information extraction in clinical domain, and is the key step of building medical knowledge graph. In this research, the task of relation extraction is based on the task of concept recognition and is implemented as relation classification by the adoption of a CRF model. The proposed CRF-powered classification model depends on features of context of concepts. To remedy the problem of word sparsity, a deep learning model is applied for features optimization by the employment of auto encoder and sparsity limitation. The proposed model is validated on the data set of I2B2 2010. The experiments give the evidence that the proposed model is effective and the method of features optimization with the deep learning model shows the great potential.
|
| [43] |
Deep Learning in Medical Image Analysis [J].https://doi.org/10.1146/annurev-bioeng-071516-044442 URL PMID: 28301734 [本文引用: 1] 摘要
Abstract This review covers computer-assisted analysis of images in the field of medical imaging. Recent advances in machine learning, especially with regard to deep learning, are helping to identify, classify, and quantify patterns in medical images. At the core of these advances is the ability to exploit hierarchical feature representations learned solely from data, instead of features designed by hand according to domain-specific knowledge. Deep learning is rapidly becoming the state of the art, leading to enhanced performance in various medical applications. We introduce the fundamentals of deep learning methods and review their successes in image registration, detection of anatomical and cellular structures, tissue segmentation, computer-aided disease diagnosis and prognosis, and so on. We conclude by discussing research issues and suggesting future directions for further improvement.
|
| [44] |
|
| [45] |
A Multiclass Classification Method Based on Deep Learning for Named Entity Recognition in Electronic Medical Records [C]// |
| [46] |
基于云计算的医疗大数据挖掘平台 [J].https://doi.org/10.3969/j.issn.1673-6036.2013.05.002 URL [本文引用: 1] 摘要
介绍大数据时代医疗行业数据挖掘面临的挑战,结合云计算提出一种基于Hadoop生态环境搭建的医疗云数据挖掘平台架构,详细阐述其各层功能,包括基础层、平台层、功能层以及业务层,以期为医疗行业的大数据分析及挖掘提供新思路.
Medical Data Mining Platform Based on Cloud Computing [J].https://doi.org/10.3969/j.issn.1673-6036.2013.05.002 URL [本文引用: 1] 摘要
介绍大数据时代医疗行业数据挖掘面临的挑战,结合云计算提出一种基于Hadoop生态环境搭建的医疗云数据挖掘平台架构,详细阐述其各层功能,包括基础层、平台层、功能层以及业务层,以期为医疗行业的大数据分析及挖掘提供新思路.
|
| [47] |
IMPACT: A Whole- exome Sequencing Analysis Pipeline for Integrating Molecular Profiles with Actionable Therapeutics in Clinical Samples [J].https://doi.org/10.1093/jamia/ocw022 URL PMID: 27026619 [本文引用: 1] 摘要
Abstract OBJECTIVE: Currently, there is a disconnect between finding a patient's relevant molecular profile and predicting actionable therapeutics. Here we develop and implement the Integrating Molecular Profiles with Actionable Therapeutics (IMPACT) analysis pipeline, linking variants detected from whole-exome sequencing (WES) to actionable therapeutics. METHODS AND MATERIALS: The IMPACT pipeline contains 4 analytical modules: detecting somatic variants, calling copy number alterations, predicting drugs against deleterious variants, and analyzing tumor heterogeneity. We tested the IMPACT pipeline on whole-exome sequencing data in The Cancer Genome Atlas (TCGA) lung adenocarcinoma samples with known EGFR mutations. We also used IMPACT to analyze melanoma patient tumor samples before treatment, after BRAF-inhibitor treatment, and after BRAF- and MEK-inhibitor treatment. RESULTS: IMPACT Food and Drug Administration (FDA) correctly identified known EGFR mutations in the TCGA lung adenocarcinoma samples. IMPACT linked these EGFR mutations to the appropriate FDA-approved EGFR inhibitors. For the melanoma patient samples, we identified NRAS p.Q61K as an acquired resistance mutation to BRAF-inhibitor treatment. We also identified CDKN2A deletion as a novel acquired resistance mutation to BRAFi/MEKi inhibition. The IMPACT analysis pipeline predicts these somatic variants to actionable therapeutics. We observed the clonal dynamic in the tumor samples after various treatments. We showed that IMPACT not only helped in successful prioritization of clinically relevant variants but also linked these variations to possible targeted therapies. CONCLUSION: IMPACT provides a new bioinformatics strategy to delineate candidate somatic variants and actionable therapies. This approach can be applied to other patient tumor samples to discover effective drug targets for personalized medicine.IMPACT is publicly available athttp://tanlab.ucdenver.edu/IMPACT. The Author 2016. Published by Oxford University Press on behalf of the American Medical Informatics Association. All rights reserved. For Permissions, please email: journals.permissions@oup.com.
|
| [48] |
大数据挖掘促进精准医学发展 [J].Big Data Mining Promotes the Development of Precision Medicine [J]. |
| [49] |
|
| [50] |
Convergence: Facilitating Transdisciplinary Integration of Life Sciences, Physical Sciences, Engineering, and Beyond [M]. |

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}