胡家珩 , 吴承尧
, 吴承尧
Hu Jiaheng, Wu Chengyao
中图分类号: G202 F832.5
通讯作者:
收稿日期: 2018-02-9
修回日期: 2018-02-9
网络出版日期: 2018-10-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】为特定领域情感分析任务构建一个适用的情感词典。【方法】以金融领域为例, 结合语料库和知识库的特点, 提出一种全新的构建情感词典的方法: 利用词向量方法将文本信息映射到向量空间, 借助已有的通用情感词典, 自动标引训练语料, 按照9:1的比例构建训练集和预测集。使用Python构建深度神经网络分类器, 判断特定领域候选情感词的情感极性, 构成情感词典。【结果】本文构建的神经网络分类器的训练集准确度为95.02%, 预测集准确度为95.00%, 同时证明了利用本文方法所构建的情感词典在金融领域中的表现优于其他已有方法。【局限】抽取种子词的方法需要进一步优化。【结论】本文方法解决了训练神经网络分类器中训练语料不足的问题, 同时解决了词向量的语义相关性无法区分情感信息的问题。在构建面向特定领域情感词典上具有较好的表现, 为该领域其他研究提供参考依据。
关键词:
Abstract
[Objective] This paper proposes a new method to construct a working sentiment dictionary for sentiment analysis in the field of finance. [Methods] Our method built a sentiment dictionary based on the characteristics of corpus and knowledge base. It also mapped the textual information into vector space using word vector method. With the help of existing general sentiment dictionary, we automatically indexed the training corpus, and created training and forecasting sets with a ratio of 9: 1. Finally, we used Python to establish the neural network classifier of deep learning, and evaluated the emotional polarity of the candidate words in the new dictionary. [Results] The accuracy of the proposed neural network classifier with the training set was 95.02%, while the accuracy with the forecasting set was 95.00%. Our results are better than the existing models. [Limitations] The method of extracting seed words could be further optimized. [Conclusions] The proposed method increases the size of corpus to train the neural network classifiers more effectively. It also extracts the emotion information from the semantic relevance of word vectors. The new sentiment dictionary provides possible directions for future research.
Keywords:
Web2.0时代, 各行各业皆借助互联网快速发展, 如金融行业由原本单一的线下交易逐渐发展成为线上线下同步交易的局面。同时, 大量的财经媒介信息借助互联网在投资者之间相互传播。对媒介信息的情感分析研究不但能够更好地了解金融市场走势, 而且能够为投资者制定良好的投资决策提供参考依据。对金融文本的情感分析方法主要有基于机器学习的方法和基于情感词典的方法, 二者都需要一个合适的情感词典。基于机器学习的方法需要情感词典对训练语料进行特征标注, 从而提高分类器的性能; 基于情感词典的方法主要依据情感词典对文本直接进行情感分析。但是, 已有的情感词典, 如中国台湾大学情感词典, 知网HowNet情感词典等都是通用的情感词典, 在金融领域情感分析任务中无法准确判断某些金融领域特有词汇的情感极性, 从而影响情感分析的准确度。因此, 构建一个面向金融领域的情感词典以提高情感分析的性能极为重要。同时, 随着深度学习的快速发展, 词向量模型等的提出恰好为相关研究提供了契机。
目前, 大量研究者试图对金融文本进行情感分析, 并借此分析投资者决策, 从而预测股票市场波动。Smailović等[1]提出金融文本中的积极情感概率的变化可以作为股票收盘价格的指示器, 通过对Twitter的金融文本进行情感分析, 借助格兰杰因果分析验证假设,进一步说明以金融文本情感分析预测股票市场的波动是有意义的。Li等[2]从新闻的情感角度入手, 应用已有的情感词典和情感分析框架, 将新闻映射到情感空间中, 分析其对股票价格的影响。Nguyen等[3]对社交媒体信息进行情感分析并预测股价。Wu等[4]分别基于机器学习和基于词典的方法, 探究评论情感与股票价格波动趋势的关系, 其中采用的情感词典为HowNet。
上述研究表明, 对金融领域进行情感分析具有一定价值和意义。通过对金融文本进行情感分析预测股票市场走势, 能够为投资者决策提供参考依据, 同时有利于维护股票市场的稳定。而情感词典作为情感分析研究的基础是必不可少的, 构建一个领域适用的情感词典能够大大提高情感分析的性能。根据王科等[5]对情感词典构建方法的研究, 目前构建词典的方法主要有两大类。
(1) 语义知识库包含人类对词语相关语义知识成果的集合, 如WordNet等。通用情感词典(如HowNet)等也是一种语义知识库。完备的语义知识库, 通过挖掘词与词之间的关系(如同义词、反义词等)能够构建情感词典。Hu等[6]人工构建少量积极与消极情感词集合(形容词)作为种子集, 在WordNet中根据同义和反义关系分别对情感词集合进行扩充, 最终得到一定规模的情感词典。Strapparava等[7]在形容词基础上, 在种子集中加入部分名词、动词和副词, 提出WordNet-Affect构建更全面的情感词典。Kamps等[8]认为, 意思越相近的两个词通过同义词迭代所需的次数越少, 于是借助WordNet判断候选词的情感极性。Hassan等[9]根据WordNet构建词间关系图, 通过候选词移动到不同已知情感的词语的次数确定其情感极性。柳位平等[10]以HowNet情感词典为基准, 从中挑选出部分常用情感词, 构建基础情感集合, 采用“知网的语义相似度方法”构建情感词典。此外, 寻找词和释义中词的关系也能为情感词典的构建提供帮助。Andreevskaia等[11]使用情绪标签提取程序(STEP)从WordNet中提取情感词扩展种子词集, 遍历所有释义, 对释义中含有种子词的词进行过滤消歧, 添加到情感词典中。Esuli等[12]假设同义词的释义包含同样极性的词, 利用PageRank方法对词的情感极性进行确定。综上所述, 完备的语义知识库, 能够快速构建通用性较强的情感词典, 对词典的精度要求不高的情况下, 这种方法较为实用。中文语义知识库的不足以及领域的限制使得该方法在构建面向金融领域情感词典中表现不佳。
(2) 语料库是在实际使用中真实出现过的语言材料的集合。基于语料库构建情感词典的方法有很多, 其中最经典的方法是利用语句中的连词判断前后词语的情感极性。Kanayama等[13]确定初始情感词集和所需的语料库, 并制定连词约束, 设置阈值, 利用无监督的方法自动生成情感词典。Xia等[14]考虑利用连词确定形容词的情感极性, 并利用贝叶斯模型以概率的方式处理极性消歧任务。殷春霞等[15]利用自由评论中词汇之间的上下文信息建模一个情感倾向性网络关系, 判断词汇的情感倾向。另外, 有部分研究者还提出用词共现法构建情感词典, 即经常一起出现的两个词之间存在一定的相关性, 并依此判断情感极性。其中, 用逐点互信息(PMI)衡量两个词之间的相关性的方法使用较多。Turney[16]利用逐点互信息和信息检索提出一种PMI-IR算法衡量词间的相似性, 之后Turney[17]通过计算候选词语不同种子词的PMI的差值判断候选词的情感极性。Wawer[18]基于Turney的思想, 重点研究种子集的生成方法, 利用生成的种子集确定候选词的情感极性。Krestel等[19]利用LDA抽取情感词, 并结合PMI确定情感极性。钟敏娟等[20]提出基于关联规则挖掘的情感词抽取与识别, 并且结合PageRank模型和PMI语义过滤, 引入词汇间的混合相关关系, 研究词汇的原始情感倾向, 有效构建情感词典。语料库相对于语义知识库而言, 其优点是容易获得且数量充足, 构建的词典在语料所属的领域内表现较好, 但是构建的成本较高, 需要对语料进行预处理, 另外, 所构建的词典的准确率相对不高。
综上所示, 笔者发现基于知识库或者基于语料库构建词典各有优劣: 基于知识库构建的词典通用且准确度高, 但是领域适用性差; 基于语料库能利用大规模语料构建情感词典, 但是成本高且准确度低。近年来, 随着神经网络和深度学习的快速发展, 词向量(Word Embedding)成为自然语言处理领域的热点, 其中最有名的便是Word2Vec。Word2Vec是谷歌在2013年发布的一款将词表征为实数值向量的高效开源工具, 利用深度学习思想, 结合语言模型, 通过无监督训练, 将对文本内容的处理简化为k维向量空间中的向量运算, 而向量空间上的相似度可以用来表示文本语义上的相关性。Word2Vec中用来构建词向量的模型有两种, 一种是CBOW模型(Continuous Bag-of-Words Model), 另一种是Skip-Gram模型(Continuous Skip-Gram Model)。CBOW模型的原理是通过周围的词语预测中间的词语, Skip-Gram模型则是通过中间的词语预测周围的词语。因此CBOW模型更适用于小规模数据集, 能够对很多分布式信息进行平滑处理, 而Skip-Gram模型则比较适合用于大规模数据集。
目前, 使用深度学习训练词向量并借助其构建情感词典成为一种趋势, 如杨小平等[21]使用Word2Vec对大规模中文语料进行训练并得到词向量, 在确定情感种子集的基础上, 基于转换约束集得到候选词的情感极性和情感强度, 得到包含10个情感标注的多维汉语情感词典SentiRuc; 冯超等[22]提出一种基于词向量相似度的半监督情感极性判断算法(SO-WV), 并依据该算法设计出一种跨领域的中文情感词典构建方法。
将词语成功转换成词向量之后, 已有研究[21]借助词向量能够保留语义的特点, 构造积极种子词集合和消极种子词集合, 并制定相应的约束, 直接根据向量相似度计算方法获得情感词典。这种方法存在一定的弊端, 因为词向量保留的是语义信息而不是情感信息, 不同情感极性的词语在语义上可以保持高度相似, 导致词语的情感极性分类不准确。
因此本文结合知识库和语料库的优点, 并借助深度学习的方法将词语转换成为词向量, 同时利用神经网络构造情感极性分类器, 判断词语的情感极性, 从而避免分类不准确情况的产生, 最后提出一种自动化构建面向金融领域情感词典的方法。
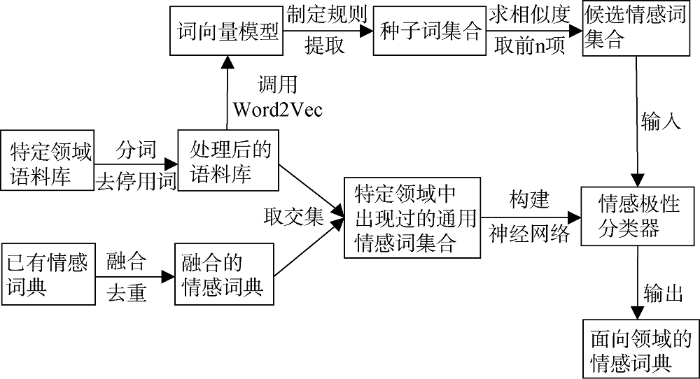
本文设计的领域词典构建流程如图1所示, 主要分为4部分。
(1) 数据预处理, 主要包括特定领域语料库的获取, 以及对现有情感词典的整合。
(2) 词向量模型的构建, 主要借助深度学习中的Word2Vec模型将词语转换成为词向量, 为后续神经网络分类器的构建奠定基础。
(3) 神经网络分类器的构建, 主要通过笔者准备的语料库和融合后的情感词典, 构建训练所需的语料, 同时借助词向量模型将词语转换成为向量进行神经网络的训练, 最后得到情感分类器。
(4) 领域情感词典的构建。情感词典主要由两部分组成: 获得的融合情感词典; 获取特定领域的候选情感词。利用训练好的神经网络分类器对其情 感极性进行判断, 最后整理得到所需的领域情感 词典。
数据预处理阶段包括语义知识库的处理和语料库的处理。语义知识库的处理主要指对已有通用情感词典的融合。本文收集到的通用词典有: 台湾大学情感词典(NTUSD)[23]; 清华大学李军情感词典[24]; 知网HowNet情感词典中的正负情感词语[25]; 大连理工大学情感词汇本体(DUTIR)[26]。首先, 分别提取上述词典中的积极词集合和消极词集合, 去除重复出现的词语, 进行融合。若某词语同时出现在多个词典中, 但是标注的情感极性不同, 则对该词语的极性进行人工判断。在实验过程中, 并未发现有词性标注不一致的词语, 融合后的情况如表1所示。
表1 通用情感词典情况
| 词典名称 | 积极词数量 | 消极词数量 |
|---|---|---|
| NTUSD | 2 811 | 8 277 |
| 清华大学李军 | 5 567 | 4 469 |
| 知网HowNet情感词典 | 836 | 1 254 |
| DUTIR | 11 229 | 10 783 |
| 总计 | 20 443 | 24 783 |
| 融合后的词典 | 16 157 | 19 559 |
语料库的处理主要指对语料进行预处理, 包括数据清洗, 去除语料库中不完整的数据和重复的数据, 保证语料皆属于同一领域; 对语料进行分词, 去除停用词、特殊符号, 为下文的实验奠定基础。
神经网络训练分类器的方法属于监督学习, 需要已标注的语料进行训练, 已标注语料的获取成为神经网络分类器训练的关键之一。本文提出一种弱标引的方法自动构建分类器所需的训练语料。根据已有的特定领域语料以及融合后的通用情感词典, 获得两者的交集, 作为训练语料。在特定领域中, 虽然不是所有的通用情感词都会出现, 但是在特定领域中必然存在通用情感词, 而这一部分情感词都是语义知识库中已经确定情感极性的词语, 因此能够作为本文神经网络分类器所需的训练语料。用该训练语料训练得到的情感分类器能够判断情感词的情感极性, 主要对那些情感极性未知的领域情感词进行情感极性判断, 使得这些词语最后能够添加到情感词典之中。
借助Python以及开源工具包gensim构建本文所需的词向量模型。词向量是词语特征的分布式表示, 词向量维度的取值与语料库的大小相关, 过低的维度无法捕获词语间的语义差别, 过高的维度将捕获到一些对泛化能力没有用的噪音, 即高方差问题。另外维度越大, 构建词向量所需的成本越高。通常, 当语料库的大小小于100MB时, 使用默认的参数100维即可。由于本文使用的语料库规模并不大, 因此采用CBOW模型构建词向量, 同时词向量的维度选定为100维。
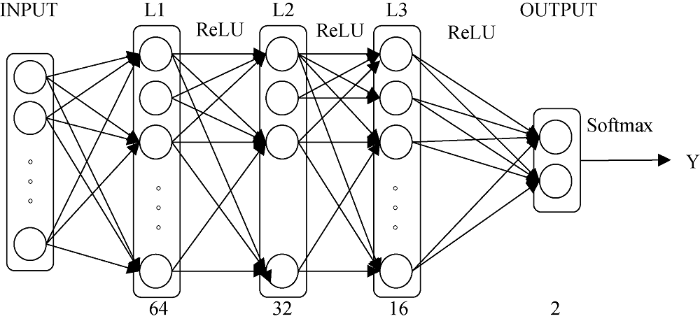
本文使用神经网络构建一个词语情感的二元分类器(判断词语情感是积极还是消极)。已知训练语料为情感词语, 对应的标记为情感词语的极性, 其中每个情感词语均通过Word2Vec转换成100维的词向量。由于本文的训练语料是词语对应的词向量, 并不是序列数据, 因此不需要采用RNN(循环神经网络); 另外, 词向量维度为100维, 使用CNN(卷积神经网络)对特征进行进一步抽取并没有太大意义。而且词语的情感极性判断属于分类问题, 因此, 本文使用全连接神经网络构建分类器, 网络结构如图2所示。
经过多次实验, 最终确定一个4层全连接的神经网络。图2中下方的数字表示每层的神经元节点个数, 如L1层的节点个数为64; 层与层之间的文字代表所使用的激励函数。激励函数的作用主要有两个: 加入非线性因素, 解决非线性问题; 可以用来组合训练数据的特征。最常用的激励函数是线性整流函数(ReLU), 又称修正线性单元。针对二分类问题, 在输出层通常采用归一化指数函数(Softmax)作为激励函数。损失函数用来估计模型的预测值和真实值的不一致程度, 损失函数越小, 模型的鲁棒性就越好。针对二分类问题, 损失函数通常采用交叉熵。优化函数的作用是利用反向传播优化参数使得损失下降。目前效果最好的优化函数是Adam, 它主要的优点在于经过偏置校正后, 每一次迭代的学习率都有个确定的范围, 使得参数变化比较平稳。学习率表示参数变化的情况, 学习率低, 训练会变得更加可靠, 但是优化会花费较长的时间; 学习率高, 训练可能不会收敛, 甚至会发散, 所以一般设定学习率为0.01。因此, 本文构建的神经网络前几层的激励函数选择ReLU, 输出层的激励函数选择Softmax, 损失函数选择交叉熵, 优化函数选择Adam, 学习率设置为0.01, 最后将训练语料按照9:1的比例分为训练集和预测集, 其中训练集用来训练模型, 预测集用来判断模型的效果。
(1) 确定种子词集合。根据所选领域的特点, 制定相应的选择标准, 抽取语料库中的词语作为种子词, 加入到种子词集合中;
(2) 确定候选情感词集合。首先将种子词转换成对应的词向量, 根据相似度计算公式(向量的余弦计算公式)求得与每个种子词最相似的n个词语作为候选情感词集合;
(3) 利用训练好的情感分类器判断每个候选词的情感极性。最后整合上述分类器输出的带有情感极性的候选词语, 添加到面向特定领域的情感词典中。
为了验证该方法的有效性, 本文设计实验进行验证, 主要验证以下两点假设:
假设1: 本文提出以词向量训练分类器判断词语情感极性的方法优于直接利用词向量的语义相似度判断词语情感极性。
在情感分析领域, 大部分常规机器学习方法, 如决策树、支持向量机等, 都能够构建分类器来判断词语的情感极性。由于自然语言的特殊性(直接特征不足, 需要转换成词向量进行分析, 特征数即为词向量的维度), 使得支持向量机的表现优于其他机器学习算法。
假设2: 深度学习中, 神经网络训练的分类器在判断词语情感极性任务中的性能优于支持向量机(SVM)训练的分类器。
实验使用的语义知识库包括NTUSD; 清华大学李军情感词典; HowNet情感词典中的正负情感词语以及DUTIR。语料库的获取主要借助Python所编写的爬虫程序, 采集2017年4月19日-2017年10月9日的新浪财经新闻, 共计9 422篇, 每篇新闻均以txt的形式进行存储。
对语料库进行数据预处理(去停用词、去无关符号)与分词(构建自定义词典: 将所有股票名称和股票代码作为一个词典, 防止分词时被切分)。抽取融合词典与语料库的交集词汇作为训练语料, 结果如表2所示。最后以语料库为对象, 使用Word2Vec方法生成词向量模型, 其中每个词向量的维度为100。
基于准备好的训练语料, 按照实验设计方案构建神经网络分类器。经过6 700次训练后, 得到训练集准确度为95.02%, 预测集准确度为95.00%。显然, 模型的效果良好, 并没有出现过拟合和欠拟合的现象。
接着确定种子词集合。由于本文重点不在于研究种子词抽取规则, 因此不作深入探讨。通过信息检索, 参考相关论文及结合本文语料库, 选择20个能够代表金融领域的词汇作为种子词集合, 如表3所示。
表3 金融领域种子词集合
| 金融领域种子词集合 |
|---|
| 大涨, 大跌, 股票, 平仓, 牛市, 熊市, 走高, 拉升, 雄起, 利好, 利空, 清仓, 套牢, 抄底, 反弹, 减持, 乏力, 退市, 撤离, 亏 |
词向量最大的特点是将语义信息用向量的形式进行分布式表示。词向量之间的余弦值能够表示词语之间的相关性程度。通常直接利用词向量构建情感词典的方式为: 判断种子词的情感极性, 利用词向量找出与种子词最相似的词语集合, 与积极种子词相似的词语被认为是积极情感词, 与消极种子词相似的词语被认为是消极情感词, 从而构建情感词典。本文对上述种子词集合中的种子词的情感极性进行人工判断, 找出与每个种子词最相似的词语(取相似度最高的前10个词语)。对金融语料的研究发现, 绝大部分金融领域的情感词词性为形容词或者动词, 因此在取相似度最高的词语的过程中加入词性过滤, 仅选择形容词和动词, 最后对积极和消极的词语分别去重, 得到情感词典(消极词语61个, 积极词语41个)。
笔者认为仅根据词向量的相似度判断词语情感极性的判断并不准确。因为词向量仅仅保留语义信息, 而语义信息并不能代表情感信息, 存在情感极性相反的词语在语义关系比较相似, 如“跌”显然表示消极情感, 但是它也出现在积极情感词集合中。因此, 本文提出一种全新的利用词向量构建情感词典的方法: 在得到种子词集合的基础上, 利用词向量能保留语义信息的特点, 得到候选情感词(取相似度最高的前10个词语, 并进行词性过滤), 之后借助分类器判断候选词的情感词性, 最后构建得到情感词典(93个)。两个词典的性能比较如表4所示。
为了评估所生产词典的性能, 本文引入4个指标。假设预测为积极, 实际为积极词的数量为TP; 预测为消极, 实际为消极词的数量为TN; 预测为积极, 实际为消极词的数量为FP; 预测为消极, 实际为积极词的数量为FN; 词的总数为M; 那么准确度=(TP+TN)/M; 精确率=TP/(TP+FP); 召回率=TP/(TP+FN); F1=2×TP/ (2×TP+FP+TN)。
根据表4, 直接利用词向量相似度构建情感词典的方法从各项指标上都不如利用词向量训练分类器, 再构建情感词典的方法, 从而验证假设1。
在验证不同分类器的性能之前, 考虑抽取相似度最高的TopN候选情感词时, N的大小可能会影响分类器的性能。因此将N的阈值分别设为10, 20, 30, 40, 最后得到的候选情感词集合的情况如表5所示。
针对相同的训练数据, 利用SVM构建一个分类器。分类器的训练集精度为76.60%, 预测集精度为75.08%, 虽然没有明显过拟合和欠拟合的情况, 但是精度明显不如神经网络构建的分类器。
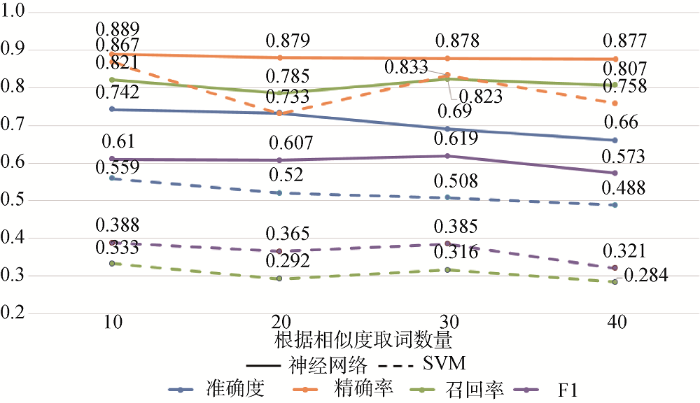
利用本文构建的神经网络分类器和SVM分类器确定候选词的情感极性, 成功构建面向金融领域的情感词典。分别计算上述不同阈值情况下, 神经网络分类器和SVM分类器所构建的情感词典的各个指标的值, 如图3所示。
从图3可以看到, 神经网络分类器的准确度随着取词数量的变大而减少。准确度可以衡量所选候选词是否为情感词。当阈值变大时, 某些与种子词不那么相似的词语也被抽取为候选情感词, 就会导致准确度下降, 说明准确度随阈值的升高而下降是合理的。但是精确率和召回率没有随着阈值的变化而明显变化, 说明本文构建的神经网络分类器能够较好地判断候选情感词的情感极性。另外, 其F1指数普遍都在60%左右, 进一步说明本文构建的情感词典具有良好的性能。比较神经网络分类器和SVM分类器, 显然本文构建的神经网络分类器的各项指标均优于SVM构建的分类器, 从而验证假设2。
此外, 从词典内容来看, 本文构建的面向金融领域的情感词典能够准确识别金融领域特有情感词的情感极性, 如积极词: 增持、高涨、分红、利好、牛市等; 消极词: 跳水、停牌、暴跌、跌停等。综上, 本文提出的面向领域构建情感词典的方法是可行的、有效的。
本文基于深度学习方法, 提出一种自动构建领域情感词典的方法。该方法充分利用知识库和语料库的优点, 并提出一种弱标引方法构建训练语料。另外, 使用深度学习理论中的词向量模型及神经网络模型构建情感极性分类器, 用来判断情感极性。避免直接使用词向量判断情感极性中, 不同情感极性的词语具有高度语义相关性所导致的分类不准确问题。最后根据语义相似度计算获得候选情感词, 从而生成领域情感词典。本文通过实证研究, 从数据上证明该方法的有效性, 为情感词典构建研究提供新思路。未来研究工作能够进一步优化该方法, 比如设计分类效果更佳的神经网络模型, 或者设计更加合理的候选情感词抽取方法等。总而言之, 本文提出的自动构建面向领域的情感词典方法能够为后续的情感分析研究提供良好的基础, 具有一定的价值和意义。
胡家珩: 完善研究思路, 采集、清洗、分析数据, 负责实验, 论文起草及修订;
岑咏华: 提出研究方向与目标, 设计研究思路和方案, 修改论文;
吴承尧: 设计研究思路和方案, 修改论文。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: 540421844@qq.com。
[1] 胡家珩, 岑咏华, 吴承尧. sina_news.txt. 新浪财经新闻数据.
| [1] |
Stream-based Active Learning for Sentiment Analysis in the Financial Domain [J].https://doi.org/10.1016/j.ins.2014.04.034 URL [本文引用: 1] 摘要
Studying the relationship between public sentiment and stock prices has been the focus of several studies. This paper analyzes whether the sentiment expressed in Twitter feeds, which discuss selected companies and their products, can indicate their stock price changes. To address this problem, an active learning approach was developed and applied to sentiment analysis of tweet streams in the stock market domain. The paper first presents a static Twitter data analysis problem, explored in order to determine the best Twitter-specific text preprocessing setting for training the Support Vector Machine (SVM) sentiment classifier. In the static setting, the Granger causality test shows that sentiments in stock-related tweets can be used as indicators of stock price movements a few days in advance, where improved results were achieved by adapting the SVM classifier to categorize Twitter posts into three sentiment categories of positive, negative and neutral (instead of positive and negative only). These findings were adopted in the development of a new stream-based active learning approach to sentiment analysis, applicable in incremental learning from continuously changing financial tweet streams. To this end, a series of experiments was conducted to determine the best querying strategy for active learning of the SVM classifier adapted to sentiment analysis of financial tweet streams. The experiments in analyzing stock market sentiments of a particular company show that changes in positive sentiment probability can be used as indicators of the changes in stock closing prices.
|
| [2] |
News Impact on Stock Price Return via Sentiment Analysis [J].https://doi.org/10.1016/j.knosys.2014.04.022 URL [本文引用: 1] 摘要
Financial news articles are believed to have impacts on stock price return. Previous works model news pieces in bag-of-words space, which analyzes the latent relationship between word statistical patterns and stock price movements. However, news sentiment, which is an important ring on the chain of mapping from the word patterns to the price movements, is rarely touched. In this paper, we first implement a generic stock price prediction framework, and plug in six different models with different analyzing approaches. To take one step further, we use Harvard psychological dictionary and Loughran cDonald financial sentiment dictionary to construct a sentiment space. Textual news articles are then quantitatively measured and projected onto the sentiment space. Instance labeling method is rigorously discussed and tested. We evaluate the models prediction accuracy and empirically compare their performance at different market classification levels. Experiments are conducted on five years historical Hong Kong Stock Exchange prices and news articles. Results show that (1) at individual stock, sector and index levels, the models with sentiment analysis outperform the bag-of-words model in both validation set and independent testing set; (2) the models which use sentiment polarity cannot provide useful predictions; (3) there is a minor difference between the models using two different sentiment dictionaries.
|
| [3] |
Sentiment Analysis on Social Media for Stock Movement Prediction [J].https://doi.org/10.1016/j.eswa.2015.07.052 URL [本文引用: 1] 摘要
The goal of this research is to build a model to predict stock price movement using the sentiment from social media. Unlike previous approaches where the overall moods or sentiments are considered, the sentiments of the specific topics of the company are incorporated into the stock prediction model. Topics and related sentiments are automatically extracted from the texts in a message board by using our proposed method as well as existing topic models. In addition, this paper shows an evaluation of the effectiveness of the sentiment analysis in the stock prediction task via a large scale experiment. Comparing the accuracy average over 18 stocks in one year transaction, our method achieved 2.07% better performance than the model using historical prices only. Furthermore, when comparing the methods only for the stocks that are difficult to predict, our method achieved 9.83% better accuracy than historical price method, and 3.03% better than human sentiment method.
|
| [4] |
A Decision Support Approach for Online Stock Forum Sentiment Analysis [J].https://doi.org/10.1109/TSMC.2013.2295353 URL [本文引用: 1] 摘要
The Internet provides the opportunity for investors to post online opinions that they share with fellow investors. Sentiment analysis of online opinion posts can facilitate both investors' investment decision making and stock companies' risk perception. This paper develops a novel sentiment ontology to conduct context-sensitive sentiment analysis of online opinion posts in stock markets. The methodology integrates popular sentiment analysis into machine learning approaches based on support vector machine and generalized autoregressive conditional heteroskedasticity modeling. A typical financial website called Sina Finance has been selected as an experimental platform where a corpus of financial review data was collected. Empirical results suggest solid correlations between stock price volatility trends and stock forum sentiment. Computational results show that the statistical machine learning approach has a higher classification accuracy than that of the semantic approach. Results also imply that investor sentiment has a particularly strong effect for value stocks relative to growth stocks.
|
| [5] |
情感词典自动构建方法综述 [J].https://doi.org/10.16383/j.aas.2016.c150585 URL Magsci [本文引用: 1] 摘要
<p>情感词典作为判断词语和文本情感倾向的重要工具, 其自动构建方法已成为情感分析和观点挖掘领域的一项重要研究内容. 本文整理了现有的中、英文情感词典资源, 同时分别从知识库、语料库、以及两者结合的角度, 归纳现有英文和中文情感词典的构建方法, 分析了各种方法的优缺点, 并总结了情感词典构建中的若干难点问题. 之后, 我们回顾了情感词典性能评估方法及相关评测竞赛. 最后总结了情感词典构建任务的发展前景以及一些亟需解决的问题.</p>
A Survey on Automatical Construction Methods of Sentiment Lexicons [J].https://doi.org/10.16383/j.aas.2016.c150585 URL Magsci [本文引用: 1] 摘要
<p>情感词典作为判断词语和文本情感倾向的重要工具, 其自动构建方法已成为情感分析和观点挖掘领域的一项重要研究内容. 本文整理了现有的中、英文情感词典资源, 同时分别从知识库、语料库、以及两者结合的角度, 归纳现有英文和中文情感词典的构建方法, 分析了各种方法的优缺点, 并总结了情感词典构建中的若干难点问题. 之后, 我们回顾了情感词典性能评估方法及相关评测竞赛. 最后总结了情感词典构建任务的发展前景以及一些亟需解决的问题.</p>
|
| [6] |
Mining and Summarizing Customer Reviews [C]// |
| [7] |
WordNet Affect: An Affective Extension of WordNet [C]// |
| [8] |
Using WordNet to Measure Semantic Orientations of Adjectives [C]// |
| [9] |
Identifying the Semantic Orientation of Foreign Words [C]// |
| [10] |
中文基础情感词词典构建方法研究 [J].
词语的情感倾向判别是文章语义情感倾向研究的基础工作。利用中文情感词建立一个基础情感词典,为专一领域情感词识别提供一个核心子集,能够有效地在语料库中识别及扩展情感词集,并提高分类效果。在中文词语相似度计算方法的基础上,提出了一种中文情感词语的情感权值的计算方法,并以HOWNET情感词语集为基准,构建了中文基础情感词典。利用该词典结合TF-IDF特征权值计算方法,对中文文本情感倾向进行判别,实验结果表明,该方法取得了不错的分类效果。
Research on Building Chinese Basic Semantic Lexicon [J].
词语的情感倾向判别是文章语义情感倾向研究的基础工作。利用中文情感词建立一个基础情感词典,为专一领域情感词识别提供一个核心子集,能够有效地在语料库中识别及扩展情感词集,并提高分类效果。在中文词语相似度计算方法的基础上,提出了一种中文情感词语的情感权值的计算方法,并以HOWNET情感词语集为基准,构建了中文基础情感词典。利用该词典结合TF-IDF特征权值计算方法,对中文文本情感倾向进行判别,实验结果表明,该方法取得了不错的分类效果。
|
| [11] |
Mining WordNet for a Fuzzy Sentiment: Sentiment Tag Extraction from WordNet Glosses [C]// |
| [12] |
Pageranking WordNet Synsets: An Application to Opinion Mining [C]// |
| [13] |
Fully Automatic Lexicon Expansion for Domain-oriented Sentiment Analysis [C]// |
| [14] |
Word Polarity Disambiguation Using Bayesian Model and Opinion-level Features [J].https://doi.org/10.1007/s12559-014-9298-4 URL [本文引用: 1] 摘要
Contextual polarity ambiguity is an important problem in sentiment analysis. Many opinion keywords carry varying polarities in different contexts, posing huge challenges for sentiment analysis research. Previous work on contextual polarity disambiguation makes use of term-level context, such as words and patterns, and resolves the polarity with a range of rule-based, statistics-based or machine learning methods. The major shortcoming of these methods lies in that the term-level features sometimes are ineffective in resolving the polarity. In this work, opinion-level context is explored, in which intra-opinion features and inter-opinion features are finely defined. To enable effective use of opinion-level features, the Bayesian model is adopted to resolve the polarity in a probabilistic manner. Experiments with the Opinmine corpus demonstrate that opinion-level features can make a significant contribution in word polarity disambiguation in four domains.
|
| [15] |
利用复杂网络为自由评论鉴定词汇情感倾向性 [J].https://doi.org/10.3724/SP.J.1004.2012.00389 Magsci [本文引用: 1] 摘要
词汇情感倾向性(Word sentiment orientation, WSO)的鉴定通常是对文本进行粗粒度意见挖掘的基础.自由评论中存在许多语法噪声, 这使得以往基于规范文本提出的WSO鉴定方法不再适合自由评论. 自由评论中的情感词汇往往是上下文敏感的, 这使得非当前鉴定的情感词汇难以适用于当前自由评论的粗粒度意见挖掘. 针对上述问题,提出一种新的利用复杂网络为自由评论鉴定WSO的方法. 该方法主要有两个部分: 1)为了利用自由评论中词汇之间的上下文信息建模一个能够有效解决上下文敏感问题且具有良好抗噪声能力的情感倾向性关系网络(Sentiment orientation relationship network, SORN),提出了两个算法:金字塔抗噪声信息模型算法和利用抗噪声信息优化调整SORN的算法; 2)为了有效利用SORN为自由评论鉴定WSO,提出了基于SORN的WSO鉴定算法. 实验表明:对于在线为自由评论鉴定WSO,本文方法不仅在精确度方面远高于Hatzivassiloglou提出的方法,且具有良好的时间效率.
Identifying Word Sentiment Orientation for Free Comments via Complex Network [J].https://doi.org/10.3724/SP.J.1004.2012.00389 Magsci [本文引用: 1] 摘要
词汇情感倾向性(Word sentiment orientation, WSO)的鉴定通常是对文本进行粗粒度意见挖掘的基础.自由评论中存在许多语法噪声, 这使得以往基于规范文本提出的WSO鉴定方法不再适合自由评论. 自由评论中的情感词汇往往是上下文敏感的, 这使得非当前鉴定的情感词汇难以适用于当前自由评论的粗粒度意见挖掘. 针对上述问题,提出一种新的利用复杂网络为自由评论鉴定WSO的方法. 该方法主要有两个部分: 1)为了利用自由评论中词汇之间的上下文信息建模一个能够有效解决上下文敏感问题且具有良好抗噪声能力的情感倾向性关系网络(Sentiment orientation relationship network, SORN),提出了两个算法:金字塔抗噪声信息模型算法和利用抗噪声信息优化调整SORN的算法; 2)为了有效利用SORN为自由评论鉴定WSO,提出了基于SORN的WSO鉴定算法. 实验表明:对于在线为自由评论鉴定WSO,本文方法不仅在精确度方面远高于Hatzivassiloglou提出的方法,且具有良好的时间效率.
|
| [16] |
Mining the Web for Synonyms: PMI-IR Versus LSA on TOEFL [OL]. |
| [17] |
Thumbs Up or Thumbs Down?: Semantic Orientation Applied to Unsupervised Classification of Reviews [C]// |
| [18] |
Mining Co-occurrence Matrices for SO-PMI Paradigm Word Candidates [C]// |
| [19] |
Generating Contextualized Sentiment Lexica Based on Latent Topics and User Ratings [C]// |
| [20] |
基于关联规则挖掘和极性分析的商品评论情感词典构建 [J].Opinion Lexicon Construction Based on Association Rule and Orientation Analysis for Production Review [J]. |
| [21] |
基于Word2Vec的情感词典自动构建与优化 [J].https://doi.org/10.11896/j.issn.1002-137X.2017.01.008 URL [本文引用: 2] 摘要
情感词典的构建是文本挖掘领域中重要的基础性工作。近几年,情感词典的极性标注从二元褒贬标注向多元情绪标注发展,词典的领域特性也日趋明显。但是情感类别的手工标注不但费时费力,而且情感强度难以得到准确量化,同时对领域性的过分关注也大大限制了情感词典的适用性[1]。通过神经网络语言模型对大规模中文语料进行统计训练,并在此基础上提出了基于转换约束集的多维情感词典自动构建方法;然后研究了基于词分布密度的感情色彩消歧方法,对兼具褒贬意味词语的感情极性进行区分和识别,并分别计算两种感情色彩下的情感类别与强度;最后提出基于多个语义资源的全局优化方案,得到包含10种情绪标注的多维汉语情感词典SentiRuc。实验证实该词典1)在类别标注检验、强度标注检验、情感消歧效果及情感分类任务中均具有良好的效果,其中的情感强度检验证实该词典具有极强的情感语义描述力。
Automatic Construction and Optimization of Sentiment Lexicon Based on Word2Vec [J].https://doi.org/10.11896/j.issn.1002-137X.2017.01.008 URL [本文引用: 2] 摘要
情感词典的构建是文本挖掘领域中重要的基础性工作。近几年,情感词典的极性标注从二元褒贬标注向多元情绪标注发展,词典的领域特性也日趋明显。但是情感类别的手工标注不但费时费力,而且情感强度难以得到准确量化,同时对领域性的过分关注也大大限制了情感词典的适用性[1]。通过神经网络语言模型对大规模中文语料进行统计训练,并在此基础上提出了基于转换约束集的多维情感词典自动构建方法;然后研究了基于词分布密度的感情色彩消歧方法,对兼具褒贬意味词语的感情极性进行区分和识别,并分别计算两种感情色彩下的情感类别与强度;最后提出基于多个语义资源的全局优化方案,得到包含10种情绪标注的多维汉语情感词典SentiRuc。实验证实该词典1)在类别标注检验、强度标注检验、情感消歧效果及情感分类任务中均具有良好的效果,其中的情感强度检验证实该词典具有极强的情感语义描述力。
|
| [22] |
基于词向量的跨领域中文情感词典构建方法 [J].Construction Method of Chinese Cross-Domain Sentiment Lexicon Based on Word Vector [J]. |
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}