刘俊婉, 杨波 , 王菲菲
, 王菲菲
北京工业大学经济与管理学院 北京 100124
Liu Junwan, Yang Bo, Wang Feifei
中图分类号: G353.1
通讯作者:
收稿日期: 2017-11-20
修回日期: 2018-02-2
网络出版日期: 2018-04-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】针对多样化评价指标导致评价体系庞大、计算繁琐、结论模糊等问题, 研究一套公正、有效、快速的学术影响力排名机制。【方法】结合Word2Vec算法、TF-IDF算法和PageRank算法, 提出一种基于引证行为与学术相似度的学者影响力领域排名方法。【结果】改进后的排序算法综合了学者学术关系层面与学者学术产出层面的学术影响力, 在有效性维度表现优异: PR值与特征向量中心度、H指数的相关性分别为0.872、0.617, 对传统评价指标具有优秀的替代作用; 同时, 在固定排名区间内学者的平均H指数与平均被引频次均有所提高, 前百名学者的平均H指数提高1.087, 平均被引频次提高2.080, 排名效果优于原始PageRank算法。【局限】算法时间复杂度与空间复杂度虽然在可接受范围之内, 但相对原始PageRank算法效率有所降低。【结论】改进算法适用于具有大量节点的学者学术网络, 节点PR值随着网络质量扩大而更趋于准确, 因此在多学科、大量学者等场景下的学术影响力评价中, 改进排名算法对原有评价指标具有一定的替代性, 且效果表现较改进前表现优异。
关键词:
Abstract
[Objective] This study aims to establish a fair and objective evaluation mechanism for academic impacts, aiming to solve the issues like huge appraisal system, complicated calculation and vague conclusion. [Methods] We proposed a ranking method for each scholar’s impacts based on citation behavior and academic similarity, as well as with the help of Word2Vec, TF-IDF, and PageRank algorithms. [Results] The proposed method combined the influence of a researcher’s scholarly relationship and academic outputs. It has excellent performance in the validity dimension: the relevance of H index and the center of the feature vector with the PR value were 0.872 and 0.617, respectively. The proposed evaluation index could replace the traditional metrics. The average H-index and citation frequency of the scholars within the fixed-ranking interval both increased. The average H-index of the top 100 scholars increased by 1.087 and the average cited frequency increased by 2.080, which were better than the original PageRank algorithm. [Limitations] The efficiency of the proposed algorithm was lower than the PageRank algorithm. [Conclusions] Our new algorithm could be used to analyze academic networks with a large number of nodes. The node’s PR value will be more accurate as the network quality expands. Therefore, the new ranking algorithm could effectively evaluate the academic impacts of many scholars from multi-disciplinary fields, and has better performance than the existing ones.
Keywords:
科研文献是学者阶段性研究成果的主要载体, 是科学知识在学术共同体中更新、传播和交流的主要形式, 是学者重要科研产出载体之一。基于科研文献对学者进行学术影响力追踪与评价是已被证实切实可行的解决方案。对学者科研论文进行学术评价的传统方法与指标主要有同行评议法、发文数量指标(总发文数量、年均发文数量)、引用数量指标(总引文数量、年均引文数量、发文期刊影响因子)、综合发文和引文的评价指标(H指数、G指数)等。Nature Neuroscience通过比较开放式同行评议与传统同行评议, 发现开放式同行评议能够在公平、公正、公开的原则基础上提出更加客观、直接、具有建设性的意见, 其结果更具有可读性[1]。H指数也衍生出基于文献引证视角的CH指数, 以及综合多种常用引文评价指标并致力于消除学科差异影响的通用指标[2]。这些传统文献计量学指标对科技和人才的定量、客观评价产生了巨大的推动作用。然而, 近年来评价工作实践中的“指标异化”“过度使用”“狭隘评价”等问题频频出现, 引发人们对于科研价值导向偏移、单纯文献计量指标评价有效性的担忧与质疑。例如2013年《关于研究评价的旧金山宣言》(The San Francisco Declaration on Research Assessment, DORA)[3]甚至提出“停止使用影响因子评价科学家或科研机构”的倡议, 引发学界关于如何“让科研学术评价更加科学”的激烈讨论。
随着社会网络分析方法的不断发展, 该方法被广泛用于学者评价研究。科研人员通过合作发文、互相引用而形成学者合作网络、学者引文网络, 通过社会网络分析图论知识可以研究学者的节点中心度指标进而达到学者评价的目的。刘璇等[4]将社会网络分析方法与传统方法相结合, 弥补了传统学术评价中存在的引用偏见、马太效应、引用曲解等不足。这些方法主要是通过测评学者之间的合作情况、引用情况, 同时依据学者节点的度中心性、中介中心性、特征向量中心性等网络指标测度学者在合作网络、引文网络关系中的影响力。科学计量学是以科学文本为研究对象, 以科研学者为目标人群, 通过计量学手段定量描绘科学活动投入、产出和过程的一门学科。学科发展过程中形成了两种研究范式: 内容无涉的客观文本范式和内容有关的社会认知构建范式[5]。引文网络分析将客观文本范式发挥到极致, 但随着研究的不断深入开展, 单纯的客观文本范式已经无法满足学科发展需要, 学者与其所发表文献内容组合作为学术共同体的研究势在必行。因此, 本文在Word2Vec算法的基础上结合TF-IDF算法创建Auth2Vec算法以获取学者主体的主题向量, 通过这种方法对学者的研究方向进行量化表示, 从而在学者评价中达到内容相关的目的。
近年来, 以文献、期刊、学者和机构为网络节点的社会网络排名与评价研究飞速发展。为了测度网络中某个节点的影响力, Google创始人Page等[6]在1999年引入网络出入度与链接价值概念, 通过邻居节点价值均分传递的思想实现网页排名PageRank算法。但该算法存在两个弊端: PageRank算法中不能存在悬点, 即网络必须是强联通的。李仲谋[7]针对该方法的弊端引入Scholar Node并结合原有PageRank算法的“随机浏览”策略, 令此节点与网络图中任意其他节点均具有双向链接, 从而证实该方法在学术网络中不但能够客观地反映包括悬点在内的论文学术影响力, 同时能挖掘出被引用次数不高的高质量论文。网页排名PageRank算法的另一个弊端是节点输出的PageRank值在不同形态的邻居节点中是均分的, 这种网页引用链接一视同仁的思想严重影响了网页的排序质量。鉴于此, 本文在结合Word2Vec算法与TF-IDF算法提出针对学者主题发现的Auth2Vec算法的基础上, 提出一种基于学者间学术相似度进行PageRank值非均匀分配的学者学术领域排名方法和机制。
PageRank是一种应用于搜索引擎上的根据网页间错综复杂的超链接关系计算网页排名的一种面向应用的排名技术。互联网上各个网页之间的链接关系可以看成是一个有向图, 一个网页的重要性由链接到该网页的其他网页投票, 一个较多链入的页面会有比较高PageRank值(简称PR值), 表示网页越重要。反之如果一个页面没有链入或链入较少则拥有较低的PR值, 表示网页重要性较低。综上所述, 网页的PR值即为网页重要性, 其计算如公式(1)所示。
$PR(u)=\frac{1-d}{N}+d\sum\limits_{v\in {{B}_{u}}}{\frac{PR(v)}{C(v)}}$ (1)
其中, Bu表示链入网页u的网页集合, C(v)表示网页v的出链数, d表示阻尼系数, N表示网页的总数量。
为解决PageRank算法排名下沉现象, Brin等[8]引入阻尼系数, 表示用户跟随网页链接向后浏览的概率, 1-d则表示用户在所有网页中重新随机选择一个新网页继续浏览的概率。阻尼系数即为通常意义上的“随机浏览”策略。
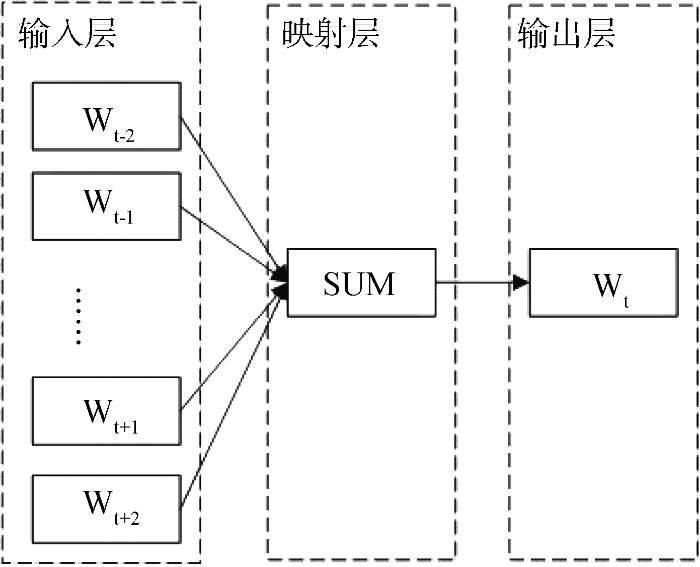
目前, 学术界最广泛使用的文档量化表示方法几乎都基于词袋模型(Bag Of Words)[9,10], 词袋法将文档看成是一些词的集合, 在该集合中, 每个词的出现是相互独立的, 且不考虑词的顺序、语法和语义等信息。但该方法存在很多问题: 向量维度太高; 向量维度稀疏; 向量各维度彼此独立; 无法区分“同词异义”的单词组等。随着深度学习的快速发展, Mikolov等[11,12]在2013年提出Word2Vec模型, Word2Vec模型利用词的上下文信息将一个词转化成一个低维实数向量, 越相似的词在向量空间中越相近。Word2Vec模型有两种, 分别是CBOW模型和Skip-gram模型。两种模型都利用人工神经网络作为分类算法, 包含输入层、映射层和输出层, 以文本集为输入, 通过训练输出每个词对应的词向量。CBOW模型根据上下文窗口词汇词向量预测当前词汇词向量, 而Skip-gram则与此相反, 它是由当前词汇预测上下文窗口内的其他词汇。本文使用Python实现CBOW模型, 如图1所示。
输入层即为某个单词A周围的n-1个单词的词向量。如果n取值为5, 则词A(可记为wt)前两个和后两个的单词为wt-2, wt-1, wt+1, wt+2。相对应地, 4个单词的词向量记为${{v}_{{{w}_{t-2}}}},\ {{v}_{{{w}_{t-1}}}},{{v}_{{{w}_{t+1}}}},\ \ {{v}_{{{w}_{t+2}}}}$。输入层到映射层是将词上下文窗口内的词向量求和, 输出层是以训练语料库中出现过的词作叶子节点, 以各词在语料库中出现的次数作为权值构造出的一棵Huffman树, 从根节点开始, 映射层的值需要沿着Huffman树不断进行Logistic分类, 并且不断修正各中间向量和词向量。模型训练结果为训练集中的每个词对应一个固定维数的向量vt, 其中向量维数在模型训练开始前作为参数输入。
通过Word2Vec算法可以获得训练集中所有词所对应固定维度的特征向量。但是该向量仅仅表征该词的语义分布, 并没有体现出该词在数据集中的重要性。为此, 改进算法同时引入TF-IDF方法。TF-IDF方法是Salton等[13]于1973年提出的一种统计方法, 用以评估一个词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加, 但同时会随着它在语料库中出现的频率成反比下降[14]。
假设学者发表文献的单词集合为D, 学者数量为M, 则Di表示学者集合中第i个学者所发表文献的单词集合, 其中$i\in (1,2,\cdots ,M)$。$v=({{v}_{1}},{{v}_{2}},{{v}_{3}},\cdots ,{{v}_{n}})$为该学者发表文献集中某个词的词向量。对于该词TF与IDF的计算分别如公式(2)-公式(3)所示。
$T{{F}_{w}}=\frac{{{m}_{w}}}{{{c}_{i}}}$ (2)
$ID{{F}_{w}}=\log \left( \frac{M}{{{n}_{w}}+1} \right)$ (3)
其中, mw表示词w在学者单词集合Di中出现的频次, ci表示Di的词频总数, nw表示D中包含词w的学者文献集的数量, $i\in (1,2,3,\cdots ,n)$。合并TF与IDF值并做归一化处理后得到TF-IDF如公式(4)所示。
$K(w,{{D}_{i}})=\frac{T{{F}_{w}}\times ID{{F}_{w}}}{\sqrt{\sum\limits_{w\in {{D}_{i}}}{{{(T{{F}_{w}}\times ID{{F}_{w}})}^{2}}}}}$ (4)
综上所述, Word2Vec算法计算结果为单词语义分布vw, TF-IDF计算结果为单词对于所属文献集的重要程度$K(w,{{D}_{i}})$, 通过两个因素结合可以获得学者的主题分布向量di。该向量为学者实体对应在固定维度上的主题分布, 学者主题向量计算如公式(5)所示, 其中$i\in (1,2,\cdots ,M)$。
${{d}_{i}}=\frac{\sum\limits_{w\in {{D}_{i}}}{{{v}_{w}}\times K(w,{{D}_{i}})}}{{{c}_{i}}}$ (5)
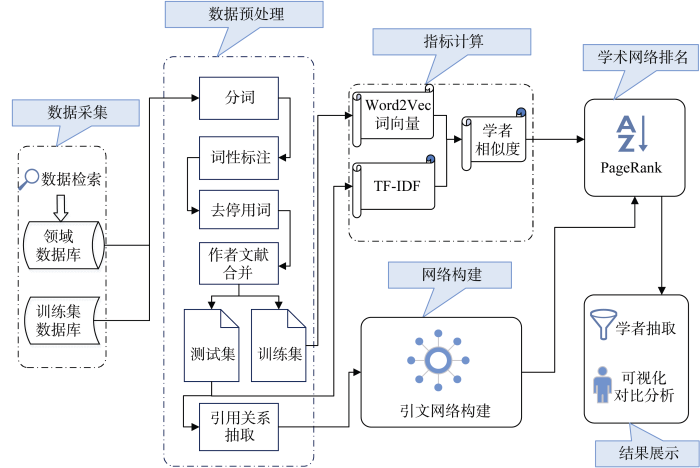
为了准确且高效地测度学者的学术影响力, 为学术合作、学术交流提供切实可靠的指导, 本文提出基于引证行为与学术相似度的学术影响力排名方法。该方法的流程如图2所示, 主要包括6大部分: 数据采集、数据预处理、指标计算、网络构建、学术网络排名和结果展示。
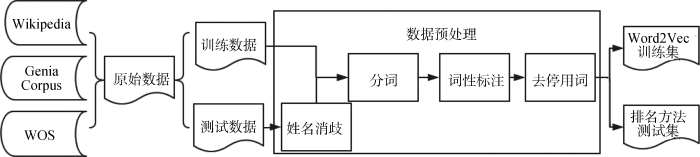
本文使用的原始数据有两部分: 第一部分的训练数据用于Word2Vec模型训练; 第二部分的测试数据为该领域学者发表的科研文献集合。数据采集与预处理的流程如图3所示。
原始数据有三部分主要来源: Wikipedia(维基百科)、Genia Corpus(生物学词性标注语料库)、WOS(Web of Science)。其中, Wikipedia数据为训练数据, Genia Corpus用于优化分词与词性标注、WOS数据为测试数据。
Word2Vec算法作为神经网络模型的一种, 是一种有监督的机器学习算法。有监督的算法特性决定了该领域排名方法需要足够庞大的数据训练集。训练集数据经过分词、词性标注、去停用词等数据预处理工作后, 最终以如图4所示的形式作为Word2Vec算法模型的训练输入。每一行代表一段文本数据预处理后的所有词汇, 词汇之间以空格分隔, 不同行代表不同文本。
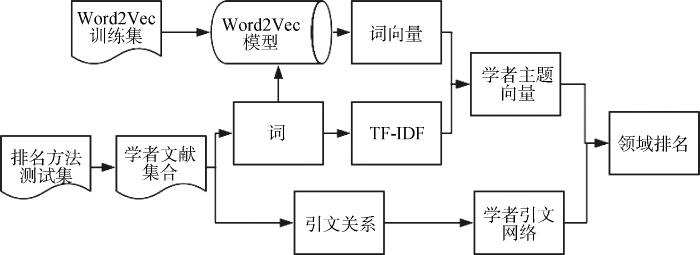
在数据预处理完成后, 需要对数据集分别进行两方面的后续处理: 指标计算与引文网络构建。指标计算与网络构建流程如图5所示。
根据预处理后的训练集数据库, 应用Word2Vec模型进行训练, 训练结果为每个词对应唯一词向量; 运用领域数据库计算不同作者所对应文献集中每个词的TF-IDF数值; 综合Word2Vec词向量与词的TF-IDF值计算出Auth2Vec数值作为学者的主题分布向量。两学者间的学术相似度计算采用Jensen-Shannon距离进行衡量。Wang等[18]通过实证分析验证JS距离相对欧式距离、余弦距离等在学者主题向量的区分度方面更具优势。设$\Theta $为学者集D在向量空间的全体离散概率分布, 则对任意$P,Q$空间, JS距离的计算如公式(6)所示。
$\begin{align} & J(P|Q)=\frac{1}{2}\left[ F(P|Q)+F(Q|P) \right] \\ & \ \ \ \ \ \ \ \ \ \ \ \ =\frac{1}{2}\left( {{p}_{i}}\ln \frac{2\times {{p}_{i}}}{{{p}_{i}}+{{q}_{i}}}+{{q}_{i}}\ln \frac{2\times {{q}_{i}}}{{{p}_{i}}+{{q}_{i}}} \right) \\ \end{align}$ (6)
其中, n为向量维度, F为KL散度[19]。学者学术相似度Si, j的计算如公式(7)所示, 其中$i,j\in $ $(1,2,3,\cdots ,M)$。
$S_{i,j}=1-J(d_{i}|d_{j})$ (7)
根据已抽取的学者间引用关系构建学者引文网络, 研究选取文献著录的全作者作为研究对.象。Zhao等[20]和Persson[21]研究发现, 相比于第一作者引文网络, 全作者引文网络能够更好地遴选出研究领域内所有相关学者, 网络结构探测更为准确、精细。学者引文网络为有向网络, 边IJ的初始权重为在限定时间窗口的目标领域内学者I引用学者J的频次, 表示为Ki, j。
学者间的引用行为通常代表了对被引学者在相关研究中所作出贡献的肯定。在引文网络中, 学者被引用频次越高则代表该学者研究成果在该领域内具有更高的权威, 其自身在学术圈内具有更高的学术影响力[22]。同时, 引文网络中不同引用之间是有区别且价值不等的。通常认为, 来自于高质量、权威、研究方向相似学者的引用在影响力评估中应具有更高的权重[22]。基于上述两个观点本研究创造性地将已经获得的学者学术相似度Si, j与学者引用频次Ki, j相结合最终获得引文网络边权Wi, j, 该权重结合两个方面因素: 学者在其学术圈内的关系层面影响力, 学者学术产出量层面的学术影响力。其计算如公式(8)所示。
${{W}_{i,j}}={{S}_{i,j}}\times {{K}_{i,j}}\ \ \ \ i,j\in (1,2,3,\cdots ,M)$ (8)
最终PageRank算法的输入数据包含三个数据项: Source(施引学者)、Target(被引学者)、Weight(Wsource, target)。PageRank算法输出为学者对应的PR值, 根据PR值的大小可对领域内学者进行学术影响力排名, PR值越大排名越靠前。
本实验选用阿里云服务器作为实验设备, 通过Python脚本全程进行数据处理和算法实施。服务器配置为16核、32GB内存、100M带宽, Python版本为2.7.10。选取专业壁垒较高的遗传学领域作为实证研究对象, 高专业壁垒对象可以使得获取到的该领域内文献集映射到对应作者上更加完整, 避免跨领域研究所带来的影响。自1866年由孟德尔依据长达8年的豌豆杂交实验为代表的遗传学理论兴起[23], 如今已发展为细胞遗传学、基因组学、动物遗传学、植物育种遗传学等多分支共生。我国以谈家桢、李汝祺、李璞等为代表的的科研团队已在该领域世界范围内占据了重要地位[24]。因此该领域排名对于我国学科评价、院校学科建设等具有一定的参考价值和现实意义。实验选取VOSviewer和Gephi软件实现数据可视化。
选取Genia Corpus作为数据预处理中词性标注的辅助语料库。Genia语料库是为Genia项目编写并标注的最初生物医学文献集合。这个语料库是为了发展和评估分子生物学信息检索及文本挖掘系统而创建的, 包含1 999条MedLine的摘要, 这些摘要是由PubMed以human、blood cells以及transcription factors三个医学主题词搜索得到。这个语料库已经被按照不同级别的语言信息、语义信息进行标注, 可以避免在依据单词词性进行去停用词过程中的误删操作。
选取Wikipedia英文语料库作为Word2Vec训练集, 语料库共计11.6GB, 包含375万XML压缩格式的英文文章。将XML的wiki数据转换为text格式, 这里利用Python第三方工具包gensim中的Wikipedia处理类WikiCorpus, 此处默认进行英文单词的词干化操作。该步骤花费3.74小时, 最终得到一个12GB的文本文件。之后使用自编脚本对初步处理的该文件进行分词、词性标注、去停用词等数据预处理操作, 得到Word2Vec训练集。
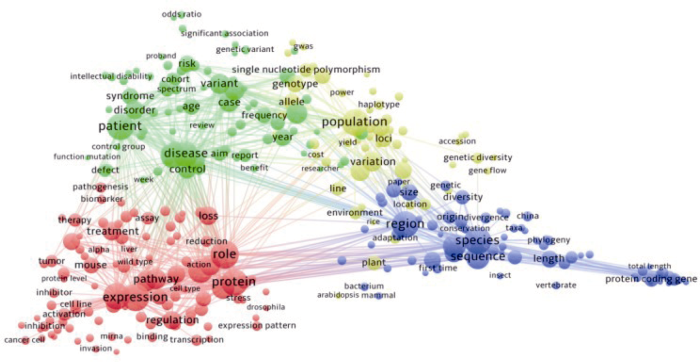
选取WOS作为领域学者学术文献来源。在WOS核心数据库中以 ((SU=genetics& hereditism) AND 语种: (English) AND文献类型: (Article))作为高级检索式, 共获得463 214篇文献作为研究测试集。由于WOS数据库收录的早期文献无法提供摘要及引文信息, 因此在总样本中剔除该类文献。经过分词、词性标注和去停用词等过程, 研究测试集最终保留310 369篇领域内文献, 867 294名学者信息, 780多万个词汇。通过抽取的学者对应机构信息、引文信息、合作者信息等指标, 运用DBSCAN聚类算法进行姓名消歧, 消除重名原因引起的噪声干扰。同时, 从发文量前5 000学者的热点词汇分布图可以初步看出(如图6所示), 词汇聚类主要分为4个部分, 以disease、patient、risk为代表的病毒遗传学; 以population、variation为代表的群体遗传学; 以species、region为代表的物种遗传学; 以expression、pathway为代表的细胞遗传学。WOS数据库自1987年对其收录的每篇文献提供DOI号作为唯一标识ID, 并详细记录文献引用其他文献的DOI及作者姓名、机构等信息。现如今, 学科发展中的学科互动, 能够在原有学科的科学空白区内形成、诞生新交叉学科的知识颗粒凝聚点[25], 因此遗传学领域文献引用其他领域文献是不可避免的。为了达到领域内学者引文网络构建更加真实和标准, 研究通过DOI识别去除非遗传学领域内的引用。
数据预处理完成后得到Word2Vec训练集与遗传学领域文献测试集。针对训练集, Word2Vec模型参数设置中迭代次数iter=5, 特征向量维度size= 100, 最小单词频次min_count=5, 词汇预测路径长度window=5。训练后模型结果为每个单词对应唯一固定100维向量。针对测试集, 计算领域内每个学者文献集内的单词的TF-IDF值。TF-IDF值运用Python的sklearn包中的TfidfTransformer与CountVectorizer两个模块进行优化计算, 结果为每个单词对应的重要性权重。最终根据公式(5)得到学者学术相似度。自引是反映科学研究连续性、继承性、相关性的重要体现。但毫无节制的高自引乱象会使得科学计量出现不可控误差[26]。鉴于此, 本研究去除自引链接, 例如Durbin Richard虽然有34篇自引论文, 但计算结果标示其与自身学术相似度为None, 表1为Durbin Richard与其他学者之间的学术相似度与引用频次的部分展示。
表1 遗传学领域学者间学术相似度样例表
| 施引学者 | 被引学者 | 学术相似度 | 引用频次 | ||
|---|---|---|---|---|---|
| 姓名 | 机构 | 姓名 | 机构 | ||
| Durbin Richard | Wellcome Trust Sanger Inst | Prokopenko Inga | Univ Oxford | 0.56292 | 7 |
| Durbin Richard | Wellcome Trust Sanger Inst | Muzny Donna | Baylor Coll Med | 0.85074 | 1 |
| Durbin Richard | Wellcome Trust Sanger Inst | Raitakari Olli | Univ Turku | 0.58119 | 3 |
| Durbin Richard | Wellcome Trust Sanger Inst | Durbin Richard | Wellcome Trust Sanger Inst | None | 34 |
| Durbin Richard | Wellcome Trust Sanger Inst | Biesecker Leslie | NHGRI | 0.61436 | 1 |
通过抽取学者间在数据集中的引用关系构建遗传学领域发文量前5 000学者的引文网络, 如图7所示。可以看出, 遗传学引文网络聚类后主要分为4个子团, 除位于较远边界的子团外, 其余三个子团彼此间联系同样非常紧密。原始学者引文网络中节点间的边权是指引文关系的发出者引用被引者的频次。在此基础上, 根据公式(8), 本研究将学者学术相似度作为学者相似度的另一层权重。权重修改后运用PageRank算法对该5 000名学者进行学术影响力排名(如表2所示)。图7中具有较高影响力的学者通常处于子团的交汇处, 这些作者不仅自身具有较高的学术创造力, 同时也在遗传学不同方向的学术交流中扮演学术桥梁与媒介的作用。
表2 遗传学领域学者影响力前20排名表
| 排名 | 姓名 | PR | 排名 | 姓名 | PR |
|---|---|---|---|---|---|
| 1 | boerwinkle, eric | 0.004715 | 11 | eriksson, johan g | 0.003537 |
| 2 | de jager, philip l. | 0.004254 | 12 | ophoff, roel a | 0.003181 |
| 3 | meitinger, thomas | 0.004173 | 13 | raitakari, olli t | 0.003118 |
| 4 | hirschhorn, joel n. | 0.003937 | 14 | hakonarson, hakon | 0.002978 |
| 5 | aung, tin | 0.003816 | 15 | montgomery, grant w | 0.002938 |
| 6 | alkuraya, fowzan s. | 0.003772 | 16 | daly, mark j | 0.002913 |
| 7 | shin, hyoung doo | 0.003658 | 17 | munnich, arnold | 0.002875 |
| 8 | majewski, jacek | 0.003624 | 18 | de bakker, paul i. w | 0.002837 |
| 9 | robert, catherine | 0.003564 | 19 | martin, nicholas g | 0.002638 |
| 10 | palotie, aarno | 0.003561 | 20 | illig, thomas | 0.002637 |
排名方法的评价主要由时间维度、空间维度以及有效性三部分。空间维度方面, 本实证研究方法所涉及的所有操作均可在8GB内存的服务器运行。如若数据集继续扩大, 可采用分布式计算降低内存使用。时间维度方面, 各步骤时间消耗详细数据如表3所示。
表3 领域排名方法各操作步骤消耗时间量统计表
| 数据 | 操作 | 时间 | |
|---|---|---|---|
| 数量 | 单位 | ||
| 训练集数据 | 数据预处理 | 3.74 | 小时 |
| Word2Vec模型训练 | 7.46 | 小时 | |
| 测试集数据 | 数据预处理 | 27.13 | 分钟 |
| TF-IDF运算 | 2.52 | 分钟 | |
| Auth2Vec学术相似度计算 | 4.12 | 分钟 | |
| 引文网络构建 | 12.79 | 分钟 | |
| PageRank排名 | 4.42 | 分钟 | |
训练集数据为一次性处理, 后续可以对模型追加训练数据并多次重复使用, 因数据集庞大, 处理时间较长, 总计约11个小时; 测试集数据应针对研究对象的不同而重新采集, 数据预处理与引文网络构建时间消耗相对较长, 但总体时间消耗较低。
鉴于目前国内科学研究各领域并没有官方排名结果, 因此有效性评价主要从以下4个方面进行: PR值与学者引文网络特征向量中心度的相关性; PR值与学者H指数的相关性; 高排名学者的发文情况统计; 改进后排名算法与未加入Auth2Vec学者学术相似度权值因素的PageRank算法(简称原始PageRank算法)结果对比。其中特征向量中心度体现学者在学术圈内关系层面的学术影响力; H指数体现学者自身在学术产出数量与质量层面的学术影响力; 高排名学者的发文情况则在一定程度上能够反映排名方法在寻找领域高水平学者方面的准确性; 与原始PageRank算法的对比则可以评价改进策略的有效性。
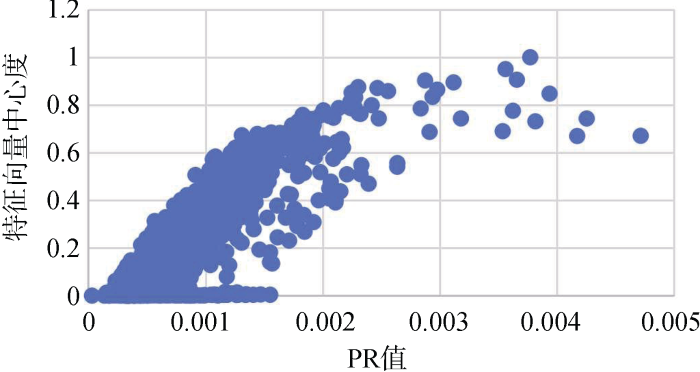
随着研究不断衍伸, 基于复杂网络的中心性指标由于能够为网络节点提供基于网络全局的重要性测度而备受重视。特征向量中心性理论认为, 一个节点的重要程度与其相连其他节点的重要程度息息相关, 即对于一个节点来说, 如果该节点与很多本身具有较高中心度的点相连接, 那么该点就具有较高的重要程度[27]。基于此, 研究选取特征向量中心度作为排名结果有效性的对照指标之一。图8为特征向量中心度与改进排名方法PR值的散点分布图, 两指标呈现正相关关系, 随着PR值的增长, 节点的特征向量中心度也随之增长。
如表4所示, 两指标的Pearson相关系数为0.872, 在P值为0.01级别(双尾)相关性显著。因此, 可以证明排名结果对特征向量中心性指标具有一定替代作用。
表4 各指标相关性分析表
| PR值 | H指数 | 特征向量中心度 | ||
|---|---|---|---|---|
| PR值 | Pearson相关系数 | 1 | .617** | .872** |
| 显著性(双尾) | 0 | 0 | 0 |
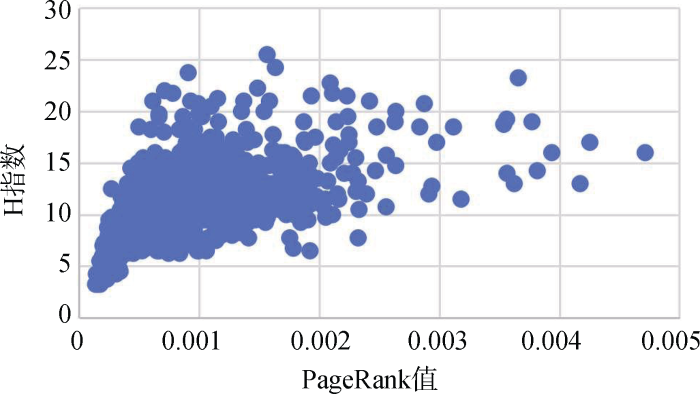
H指数是一个混合量化指标, 可用于评估研究人员的学术产出数量与学术产出水平。H指数是2005年由美国加利福尼亚大学圣地亚哥分校的物理学家Hirsch[2]提出的。一个人的H指数是指在一时间段内学者发表的论文至少有H篇被引频次不低于H次。图9为H指数与改进排名方法PR值的散点分布图, 两指标呈正相关关系, 随着PR值的增长, 节点的H指数也随之增长。通过表4可以看出, 两指标的Pearson相关系数为0.617, 在P值为0.01级别(双尾)相关性显著。因此, 可以证明排名结果对H指数具有一定替代作用。
通过改进排名方法找到的前5学者发文情况如表5所示。
表5 遗传学领域排名前5的研究学者发文情况统计表
| 姓名 | 论文数量 | 总被引频次 | 平均被引频次 | 最高单篇被引频次 | Nature或Science论文 |
|---|---|---|---|---|---|
| Boerwinkle, Eric | 240 | 14 722 | 61.34 | 1 441 | 15 |
| de Jager, Philip l | 97 | 5 143 | 53.02 | 820 | 11 |
| Meitinger, Thomas | 173 | 13 386 | 77.38 | 1 441 | 11 |
| Hirschhorn, Joel N | 146 | 9 428 | 64.58 | 1 441 | 13 |
| Aung, Tin | 53 | 3 168 | 59.77 | 340 | 1 |
5位学者最低平均被引频次为53.02, 最低论文发表数量为53。排名前5的学者在Nature或Science中均有论文发表。排名第一的Boerwinkle, Eric在这两个世界顶级期刊中发表论文15篇。经统计发现, Boerwinkle, Eric、Meitinger, Thomas、Hirschhorn, Joel N三位学者存在合作关系, 三者被引频次最高的论文均为三者合作发表的《Association Analyses of 249, 796 Individuals Reveal 18 New Loci Associated with Body Mass Index》, 三者两两合作发表论文超过300篇, 这直接证明领域顶尖学者在学术研究中具有组团现象。通过以上分析可以看出, 5名学者无论在发文数量亦或发文质量上都具有相当高的水平, 这说明本项研究提出的改进排名方法在寻找领域高水平学者方面具有较高的准确性。
通过上述三个指标可以看出, 特征向量中心度与H指数两个影响力指标随着排名的提高而逐渐提高, 同时排名靠前学者具有非常高的发文质量与发文数量。因此可以看出本排名方法的排名结果具有较高的准确性。为了验证改进后排名方法相较于原始PageRank算法效果的提升, 本文统计两种排序算法排名分别处于1-100, 1-300, 1-500, 1-1000, 1-5000五个区间内的学者的特征向量中心度(f)、H指数(h)、平均被引频次(c)指标的平均值。并分别计算改进后排序算法三个指标与原始PageRank算法三个指标的差值DF、DH、DC。在区间[1, n]中DF、DH、DC计算分别如公式(9)-公式(11)所示, 其中${{f}_{i}},{{h}_{i}},{{c}_{i}}$分别对应改进后排名算法排名第i位学者的特征向量中心度、H指数、平均被引频次, ${{{f}'}_{i}},{{{h}'}_{i}},{{{c}'}_{i}}$分别对应原始PageRank算法排名第i位学者的特征向量中心度、H指数、平均被引频次。
$DF=\frac{\sum\limits_{i=1}^{n}{{{f}_{i}}-\sum\limits_{i=1}^{n}{{{{{f}'}}_{i}}}}}{n}$ (9)
$DH=\frac{\sum\limits_{i=1}^{n}{{{h}_{i}}-\sum\limits_{i=1}^{n}{{{{{h}'}}_{i}}}}}{n}$ (10)
$DC=\frac{\sum\limits_{i=1}^{n}{{{c}_{i}}-\sum\limits_{i=1}^{n}{{{{{c}'}}_{i}}}}}{n}$ (11)
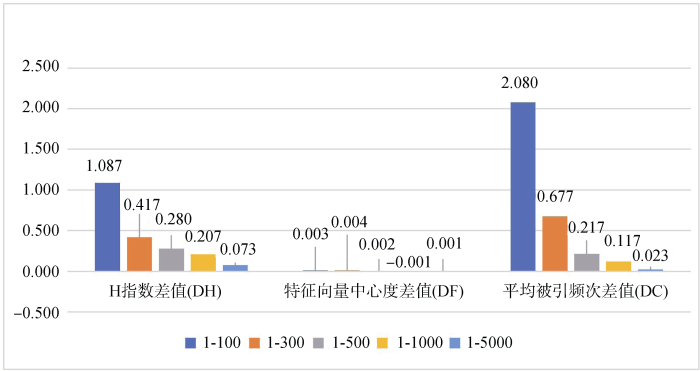
分别计算5个区间内的DF、DH、DC指标, 其分布如图10所示。
可以看出, 对于排名1-100区间内学者的平均H指数指标, 改进后排序算法结果要高出原始PageRank排序算法结果1.087, 且随着排名区间的扩大而不断下跌接近于0, 但均为正值; 同样地, 对于排名1-100区间内学者的平均被引频次指标, 改进后排序算法结果要高出原始PageRank排序算法结果2.080, 随着排名区间的扩大而不断跌近于0, 但均为正值; 对于特征向量中心度指标, 由于两种算法都是基于引文网络结构, 因此两种算法在各个区间上的表现没有太大差异, 且随着排名区间范围的扩大没有表现出递增或递减的规律性, 总体来看改进后算法优于原始PageRank算法的区间个数相对较多。综上所述, 改进后算法在以H指数、平均被引频次为代表的学者学术产出层面的影响力测度表现明显优于原始PageRank算法; 在以特征向量中心度为代表的学者学术关系层面的影响力测度表现基本持平, 改进后算法略优于原始PageRank算法。
本文提出一种基于学术相似度的PageRank值非均匀分配的学术领域排名方法和机制。通过Word2Vec算法与TF-IDF算法相结合, 从语义的角度出发计算学者在特定领域内的学术相似度。在遗传学全作者引文网络中, 将引用频次与学术相似度相结合作为边权, 运用PageRank算法对该领域内学者的学术影响力进行排名。实验结果证明, 改进的PageRank算法在时间维度、空间维度和有效性三个方面均具有良好实验效果。该排名方法结果与特征向量中心度、H指数指标都具有较高的相关性, 因此该排名结果综合了学者学术圈内关系层面的学术影响力与学术产出数量与质量层面的学术影响力, 评价结果优于原有单一指标, 在今后大范围的学术影响力评价领域对原有指标具有优越替代性。同时排名方法在领域高水平学者发现方面也具有优异表现, 可用于领域学者推荐与领域研究前沿追踪等研究的尝试。与原始PageRank算法相比, 改进后算法在学者学术产出层面的影响力测度方面表现更加优异。
由于学术网络权重计算较为复杂, 算法时间复杂度与空间复杂度虽然控制在可接受范围之内, 但相对原有PageRank算法效率降低。通过分析可知算法空间占用峰值与大部分时间占用处在数据预处理阶段, 因此可以通过建立一个持续、长期、不断更新、分布式的学者主题分布数据库的方法使算法空间与时间占用分摊的策略提高算法效率。同时, 本研究仅运用遗传学领域学者的WOS数据作为研究对象, 未来将扩展研究领域以进一步评价该改进排名方法的可行性。
刘俊婉: 提出与设计研究命题, 分析数据;
杨波: 采集、清洗数据, 程序设计, 数据分析, 论文起草;
王菲菲: 设计研究方案, 修改论文。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: 396122554@qq.com。
[1] 杨波. wos_data.txt. WOS核心数据库遗传学领域1980-2017年文献数据集.
[2] 杨波. GENIAcorpus3.02.pos.txt. Genia语料库标注数据.
[3] 杨波. Wikipedia-en-html.txt. Wikipedia英文语料库.
[4] 杨波. Name_disambiguation.py. 姓名消歧算法脚本.
[5] 杨波. Auth_to_vec.py. 学者对应主题向量计算脚本.
[6] 杨波. Similarity.py. 学者间主题相似度计算脚本.
[7] 杨波. Pagerank_new.py. 改进算法排序脚本.
| [1] |
Pros and Cons of Open Peer Review [J].https://doi.org/10.1038/6295 URL PMID: 10195206 [本文引用: 1] 摘要
Editorial. Examines the advantages and disadvantages of open peer review in the field of neuroscience. Primary role of review process; Bias against female applicants in grant review; Conflicts of interest.
|
| [2] |
An Index to Quantify an Individual’s Scientific Research Output [J].https://doi.org/10.1073/pnas.0507655102 URL [本文引用: 2] |
| [3] |
Impact Factor Distortions [J].https://doi.org/10.1126/science.1240319 URL [本文引用: 1] |
| [4] |
基于合著网络的学术人才评价方法研究 [J].Study on Evaluation Methods of Academic Talents Based on Co-author Network [J]. |
| [5] |
科学文本研究的神化范式及其转变 [J].The Deification Paradigm of Scientific Text Research and Its Transformation [J]. |
| [6] |
The PageRank Citation Ranking: Bringing Order to the Web [R/OL]. |
| [7] |
ScholarRank: 一种新的评价学术论文影响力的方法 [J].
针对将PageRank应用到学术论文评价中存在的不能解决悬点与要求引文网络强联通两个问题,通过引入Scholar Node,建立一种能同时克服以上缺点的评价学术论文影响力的方法——ScholarRank。通过对模型的验证分析,证实ScholarRank不但能够客观地反映包括悬点在内的论文学术影响力,同时能挖掘被引用次数不多的高质量论文。
ScholarRank: A New Method for Evaluating the Influence of Academic Papers [J].
针对将PageRank应用到学术论文评价中存在的不能解决悬点与要求引文网络强联通两个问题,通过引入Scholar Node,建立一种能同时克服以上缺点的评价学术论文影响力的方法——ScholarRank。通过对模型的验证分析,证实ScholarRank不但能够客观地反映包括悬点在内的论文学术影响力,同时能挖掘被引用次数不多的高质量论文。
|
| [8] |
The Anatomy of a Large-scale Hypertextual Web Search Engine [J].https://doi.org/10.1016/S0169-7552(98)00110-X URL [本文引用: 1] 摘要
In this paper, we present Google, a prototype of a large-scale search engine which makes heavy use of the structure present in hypertext. Google is designed to crawl and index the Web efficiently and produce much more satisfying search results than existing systems. The prototype with a full text and hyperlink database of at least 24 million pages is available at To engineer a search engine is a challenging task. Search engines index tens to hundreds of millions of web pages involving a comparable number of distinct terms. They answer tens of millions of queries every day. Despite the importance of large-scale search engines on the web, very little academic research has been done on them. Furthermore, due to rapid advance in technology and web proliferation, creating a web search engine today is very different from three years ago. This paper provides an in-depth description of our large-scale web search engine -- the first such detailed public description we know of to date. Apart from the problems of scaling traditional search techniques to data of this magnitude, there are new technical challenges involved with using the additional information present in hypertext to produce better search results. This paper addresses this question of how to build a practical large-scale system which can exploit the additional information present in hypertext. Also we look at the problem of how to effectively deal with uncontrolled hypertext collections where anyone can publish anything they want.
|
| [9] |
Topic Modeling: Beyond Bag-of-Words [C]// |
| [10] |
Real-time Bag of Words, Approximately [C]// |
| [11] |
Distributed Representations of Words and Phrases and Their Compositionality [C]// |
| [12] |
Efficient Estimation of Word Representations in Vector Space [OL].
Abstract: We propose two novel model architectures for computing continuous vector representations of words from very large data sets. The quality of these representations is measured in a word similarity task, and the results are compared to the previously best performing techniques based on different types of neural networks. We observe large improvements in accuracy at much lower computational cost, i.e. it takes less than a day to learn high quality word vectors from a 1.6 billion words data set. Furthermore, we show that these vectors provide state-of-the-art performance on our test set for measuring syntactic and semantic word similarities.
|
| [13] |
On the Construction of Effective Vocabularies for Information Retrieval [C]// |
| [14] |
|
| [15] |
姓名消歧方法研究进展 [J].https://doi.org/10.3772/j.issn.2095-915x.2016.01.007 URL 摘要
为应对目益严重的姓名歧义现象给提高搜索引擎查全率和查准率带来的挑战,同时给姓名消歧方法研究提供参考建议,对研究现状和主要成果进行总结。首先,介绍研究姓名消歧的目的和意义。其次,对国内外现有姓名消歧方法研究进展进行梳理,主要方法包括基于特征的、基于机器学习的、基于社会网络的、基于网络知识资源的姓名消歧等多种方法来解决姓名歧义问题。最后,文章分析各种方法的特征和不足,总结姓名消歧待解决的问题以及未来的研究方向。
Research Progress of the Method of Name Disambiguation [J].https://doi.org/10.3772/j.issn.2095-915x.2016.01.007 URL 摘要
为应对目益严重的姓名歧义现象给提高搜索引擎查全率和查准率带来的挑战,同时给姓名消歧方法研究提供参考建议,对研究现状和主要成果进行总结。首先,介绍研究姓名消歧的目的和意义。其次,对国内外现有姓名消歧方法研究进展进行梳理,主要方法包括基于特征的、基于机器学习的、基于社会网络的、基于网络知识资源的姓名消歧等多种方法来解决姓名歧义问题。最后,文章分析各种方法的特征和不足,总结姓名消歧待解决的问题以及未来的研究方向。
|
| [16] |
利用优化的DBSCAN算法进行文献著者人名消歧 [J].
Using the Optimized DBSCAN Algorithm for Disambiguation of the Names of the Authors [J].
|
| [17] |
Fast and Effective Text Mining Using Linear-time Document Clustering [C]//
|
| [18] |
Topics Over Time: A Non-Markov Continuous-Time Model of Topical Trends [C]// |
| [19] |
Similarity Measures for Text Document Clustering [C]// |
| [20] |
Last, or All Authors in Citation Analysis: A Comprehensive Comparison in the Highly Collaborative Stem Cell Research Field [J].https://doi.org/10.1002/asi.21495 URL [本文引用: 1] 摘要
Abstract How can citation analysis take into account the highly collaborative nature and unique research and publication culture of biomedical research fields? This study explores this question by introducing last-author citation counting and comparing it with traditional first-author counting and theoretically optimal all-author counting in the stem cell research field for the years 2004 2009. For citation ranking, last-author counting, which is directly supported by Scopus but not by ISI databases, appears to approximate all-author counting quite well in a field where heads of research labs are traditionally listed as last authors; however, first author counting does not. For field mapping, we find that author co-citation analyses based on different counting methods all produce similar overall intellectual structures of a research field, but detailed structures and minor specialties revealed differ to various degrees and thus require great caution to interpret. This is true especially when authors are selected into the analysis based on citedness, because author selection is found to have a greater effect on mapping results than does choice of co-citation counting method. Findings are based on a comprehensive, high-quality dataset extracted in several steps from PubMed and Scopus and subjected to automatic reference and author name disambiguation.
|
| [21] |
All Author Citations Versus First Author Citations [J].https://doi.org/10.1023/A:1010534009428 URL [本文引用: 1] 摘要
Based on a set of information science papers this study demonstrates that "all author" citationcounts should be preferred when visualizing the structure of research fields. "First author" citationstudies distort the picture in terms of most influential researchers, while the subfield structuretends to be just about the same for both methods.
|
| [22] |
基于学术异构网络的学者影响力评估算法 [D].Scholar’s Influence Evaluation Algorithm Based on Academic Heterogeneous Network [D]. |
| [23] |
|
| [24] |
|
| [25] |
情报学交叉学科的发展趋势——我国情报学期刊被引分析的启示 [J].https://doi.org/10.3969/j.issn.1008-0821.2007.01.022 URL [本文引用: 1] 摘要
学科生长点是位于原有学科科学空白区的新学科"胚胎".学科之间的学科运动产生交叉学科生长点,并发育成新的交叉学科.科技情报学、经济情报学、军事情报等已经是情报学的重要交叉学科.情报学交叉学科将朝着交叉学科广域性、学科交叉多元性的方向发展.随着情报学与其他学科的学科运动日益深化,情报学将形成庞大的交叉学科体系.
The Development Trend of Interdisciplinary Information Science - The Enlightenment of Citation Analysis of China’s Information Science Journals [J].https://doi.org/10.3969/j.issn.1008-0821.2007.01.022 URL [本文引用: 1] 摘要
学科生长点是位于原有学科科学空白区的新学科"胚胎".学科之间的学科运动产生交叉学科生长点,并发育成新的交叉学科.科技情报学、经济情报学、军事情报等已经是情报学的重要交叉学科.情报学交叉学科将朝着交叉学科广域性、学科交叉多元性的方向发展.随着情报学与其他学科的学科运动日益深化,情报学将形成庞大的交叉学科体系.
|
| [26] |
国内外引文分析研究进展综述 [J].Citation Analysis of Research Progress at Home and Abroad [J]. |
| [27] |
|

/
| 〈 |
|
〉 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}