陈远, 王超群, 胡忠义 , 吴江
, 吴江
武汉大学信息管理学院 武汉 430072
Chen Yuan, Wang Chaoqun, Hu Zhongyi, Wu Jiang
中图分类号: G353
通讯作者:
收稿日期: 2017-11-24
修回日期: 2018-01-5
网络出版日期: 2018-04-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】充分利用网站多源评测指标, 研究恶意网站的评估和识别问题。【方法】在广泛收集网站多源评测指标的基础上, 采用主成分分析法对恶意网站进行多维度评估, 并在此基础上利用随机森林分类算法构建恶意网站识别模型。【结果】所构建方法可以有效提取权威、引用、访问量、排名、链接5个评估维度; 同时, 基于主成分分析法和随机森林的恶意网站识别模型具有较高的准确率和识别效率。【局限】受数据获取的限制, 本研究样本大多属于国外网站, 所提取的维度可能与国内恶意网站有一定差异; 同时没有考虑恶意网站与正常网站的数量存在不均衡问题。【结论】所构建的基于主成分分析和随机森林的模型既可以提取具有较好解释性的网站评价维度, 又具有较高的识别准确率和效率, 对后续恶意网站的评估与识别研究具有借鉴意义。
关键词:
Abstract
[Objective] This study aims to assess and identify malicious websites with the help of multi-source evaluation metrics. [Methods] We used the principal component analysis (PCA) to conduct a multi-dimensional assessment of malicious websites based on multi-source metrics of websites. Then, we built a malicious site identification model using random forest based on the assessment. [Results] We found that the PCA could effectively extract five assessment dimensions: authority, references, website traffic, ranking, and links. Meanwhile, the identification model was accurate and efficient. [Limitations] Most of the samples in this study were foreign websites, which means the extracted dimensions may be different from those in China. Additionally, we did not study the ratio of malicious to normal websites. [Conclusions] The proposed model could effectively extract dimensions for website assessment and then identifies the malicious ones.
Keywords:
近年来, 互联网产业尤其是移动互联网产业的发展迅猛, 以互联网和移动网络为平台的电子商务、社会化商务、网络金融等各种应用层出不穷, 人们开始利用互联网进行在线交易和事务处理。但是, 在电子商务及电子金融产业日渐兴盛的同时, 各种网络安全问题也越来越普遍。病毒、盗号、木马、钓鱼等黑客行为对互联网环境造成极其恶劣的影响, 根据互联网安全组织的网络监控报告, 恶意网站攻击已经超过传统的恶意攻击而成为当前网络攻击面临的最大威胁。
为了最大程度地减小用户损失, 国内外学者已经提出很多不同的识别恶意网站的方法。典型的方法是采用黑白名单识别技术, 这种技术可以容易地以浏览器插件的形式提供服务。但由于恶意网站数量的激增, 使得建立一份完整的黑白名单的难度越来越大, 几乎成为不可能的事[1,2]。因此有学者开始从URL异常特征、网页内容特征、互联网评测数据等角度借助先进机器学习技术进行建模, 并且取得了较好的识别效果[3,4,5]。然而, 在构建恶意网站识别模型前, 对恶意网站进行有效评估, 对于理解恶意网站存在形式、构建有效的识别模型是非常重要的。目前只有少数文献针对恶意代码对网站进行分析评估[6], 但该评估方式仅仅分析网站代码, 不够全面且分析效率也有待提高。
本文利用互联网上可以公开获取的多源网站评测指标(如知名互联网公司测评的域名评测数据、社交平台关注数据等), 采用主成分分析法, 对众多网站指标进行因子提取, 找到评估恶意网站的主要因子成分, 并在此基础上基于随机森林算法对恶意网站进行识别, 以对提取的主因子在识别恶意网站上的有效性进行验证。
鉴于恶意网站严重的危害性、传播的快速性及地域的广泛性, 高效和准确地识别恶意网站是至关重要的。综合以往文献, 可以将现有恶意网站识别研究分为基于黑白名单的识别技术和基于机器学习的识别技术。其中, 基于黑白名单的识别技术根据事先维护的黑白名单列表验证目前访问的网站是否是恶意网站。然而, 恶意网站存活周期较短, 伪装手段或样式变化多端, 维护和更新囊括所有恶意网站的黑白名单列表是非常不现实的, 因而基于黑白名单的技术在识别恶意网站时效果欠佳[1-2, 7]。
随着数据挖掘和机器学习技术的快速发展, 基于先进机器学习的恶意网站识别技术得到广泛关注。在这类研究中, 通过提取并选择有助于识别恶意网站的重要特征变量, 并采用机器学习技术构建恶意网站识别模型, 进而利用训练的模型对未知网站进行检测。依据不同的特征变量, 基于机器学习的识别方法包括基于URL异常特征的识别技术、基于网页内容和评测数据的识别技术等。
基于URL异常特征的识别技术借助URL特征构建恶意网站识别模型。黄华军等[3]通过分析恶意网站URL地址的结构和词汇特征, 提出一种基于异常特征的恶意网站 URL 检测方法。曾传璜等[8]从URL中提取敏感特征, 并基于改进AdaCostBoost算法构建恶意网站分类识别器, 并取得较好的检测结果。Abdelhamid[9]根据URL特征, 提出基于多标记规则的恶意网站识别算法, 并且生成其他算法无法找到的新的隐藏知识(规则)。Abutair等[10]基于案例推理的方法设计恶意网站检测系统, 该系统主要利用从URL中提取的特征进行识别。Moghimi等[11]基于正常网站与恶意网站之间的汉明距离识别恶意网站, 并设计轻量级的网络钓鱼检测系统。Yang等[12]使用URL特征构建基于C4.5算法的恶意网站识别模型, 取得较好的识别效果。但是网站URL 特征比较容易模仿且数量有限, 因此仅通过URL特征识别恶意网站存在较大风险。
基于网页内容的识别技术通常从标题、关键字、描述信息等网页内容中提取有效特征以进行恶意网站的识别。Chiew等[4]利用网站Logo以及谷歌图片搜索功能识别正常网站和恶意网站。Tan等[13]基于关键词、域名特征等提出PhishWHO的恶意网站识别方法, 并且所提出的系统优于传统的网络钓鱼检测方法。庄蔚蔚等[14]提取标题、关键字等特征进行分类器模型的构建, 实现对恶意网站的智能检测。魏玉良[15]提出网页视觉块选择算法, 将网页分为不同种类的视觉区域, 并提出基于区域匹配的网页相似度评价方法, 进而识别虚假网站。杨明星[16]提出利用网站Logo图标进行恶意网站识别的思想。与传统页面相似度的比较检测技术不同, 该研究不再直接提取Logo特征图, 而是通过对局部页面进行比较, 达到提高识别精确度的目的。朱百禄[17]提出一种基于Web社区的恶意网站识别技术。利用网页之间的关联性, 该研究构建恶意网站相互依赖的一个社区关系, 并且在该社区中通过对目标网页的搜索, 得到该网页的依赖关系, 并根据此关系判别该网站是否是恶意网站。Zhang等[18]利用网页的空间布局特征, 提出基于空间布局相似性的恶意网站检测方法。该方法借助R-tree索引合法网页库的空间布局特征, 并进行快速相似性检测以确定该网站是否是恶意网站。Islam等[19]利用页面头信息和网页主体提取的特征变量构建恶意网站识别模型。Hu等[5]通过融合多源网络评测数据, 构建并比较多种基于机器学习的钓鱼网站识别模型, 并验证了模型的有效性。
然而, 以上研究侧重于恶意网站的识别, 忽略对恶意网站本身的评估。而通过对恶意网站进行多角度的评估有助于更清晰地评测恶意网站, 进而指导和提升恶意网站识别模型的构建。目前只有少数研究关注恶意网站的分析评估, 如马威[6]利用网络爬虫、基于行为的恶意代码识别技术等多项先进技术, 尝试对恶意网站进行分析评估。但是该评估方式仅仅考虑网站代码, 不够全面且分析效率有待提高, 而且对所需捕获的行为还有商榷的余地。
因此, 本文利用互联网上可以公开获取的多源网站评测指标(如知名互联网公司的域名评测数据、社交平台关注数据等), 采用主成分分析法对众多网站指标进行因子提取[20], 找到评估恶意网站的主要因子成分, 并在此基础上基于随机森林算法对恶意网站进行识别, 进而验证所提取主因子在识别恶意网站上的有效性。
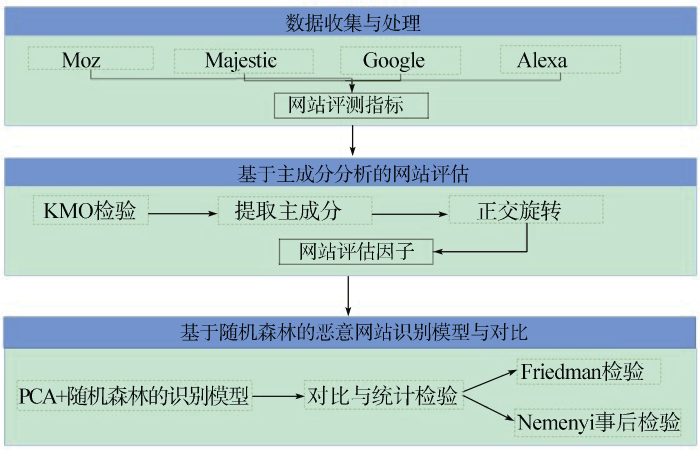
为了对恶意网站进行有效的评估与识别, 本文提出混合主成分分析与随机森林的评估识别模型, 如图1所示。该模型总体上分为数据收集与处理、基于主成分分析的网站评估、基于随机森林的恶意网站识别三部分。
(1) 数据收集与处理
从Moz、Majestic、Google、Alexa等第三方知名网站测评平台收集网络评测数据, 经数据清理、筛选、抽取等处理后得到网站评测指标。
(2) 基于主成分分析的网站评估
从多个来源收集到的测评指标存在信息冗余, 不仅不利于清晰地评估恶意网站, 还会增加恶意网站识别模型的复杂度, 因此, 借助主成分分析法对多源测评指标进行精炼与降维。
主成分分析(Principal Component Analysis, PCA)[20]也称主分量分析, 是考察多个变量间相关性的一种多元统计方法。它通过少数几个主成分来揭示多个变量间的内部结构, 即从原始变量中提取出少数几个主成分, 使它们尽可能多地保留原始变量的信息, 且彼此间互不相关。采用主成分分析法, 可以从收集的众多网络评测指标中提取少数几个主成分, 不仅可以避免测评指标间的信息重复, 又可以简化和抓住主要评估维度, 客观高效地对恶意网站进行评估与识别。
(3) 基于随机森林的恶意网站识别
随机森林(Random Forest, RF)是采用随机策略构建众多决策树的一种集成学习方法。该方法由Breiman提出[21], 将Bagging和随机特征选择结合起来。随机森林在构建决策树时, 首先从原始的数据集中进行有放回的抽样, 构造子数据集。其次与数据集的随机选取类似, 每棵决策树的特征都是从所有特征中随机选取的子特征集, 并未用到所有的特征。这样使得随机森林中的决策树都能够彼此不同, 大大提升了系统的多样性, 从而提升集成模型的分类性能。
随机森林是集成学习模型中的佼佼者, 在以往研究中取得了较好的效果[5]。在主成分分析提取的主成分基础上构建基于随机森林的识别模型, 可以有效提高模型的训练效率和准确性。为了验证该模型的识别性能, 该部分采用分类指标和统计检验进行对比分析。
本研究分别从PhishTank(https://www.phishtank. com/)和Alexa(http: //www.alexa.com/)随机抓取恶意网站URL和合法网站URL各1 000条。各网站的评测数据采集自Moz(https: //moz.com/)、Majestic(https: //zh.majestic.com/)、Google(https: //www.google.com)、Alexa(http: //www.alexa.com/)等4家知名网站。经处理, 得到16个评测指标, 如表1所示。
表1 网站评测指标体系
| 指标来源 | 指标名称 | 指标含义 |
|---|---|---|
| Moz | Moz’s Domain Authority | Moz公司对域名在搜索引擎中排名的预测 |
| Moz’s total backlinks | 网站的所有反向链接 | |
| MozRank | 链接流行度评分 | |
| Majestic | Majestic’s Citation Flow | 通过引用排名, 度量引用来源 |
| Majestic’s Trust Flow | 通过衡量一个网站和可信赖网站的亲密程度, 度量信任来源 | |
| Majestic’s backlinks | 网站反向链接的指标 | |
| Majestic’s reference domains | 外部链接指向当前网站的个数 | |
| Google’s Page Rank | Google通过网站之间的超链接关系确定的网站排行榜 | |
| Google’s Page Speed | Google评估网页加载速度的指标 | |
| Alexa | Alexa’s rank | 通过网站的访问量确定网站排名 |
| Alexa’s 1 month reach | 网站最近1个月的平均每天访问量 | |
| Alexa’s 3 month reach | 网站最近3个月的平均每天访问量 | |
| Alexa’s median load | 使用Alexa特有的算法计算出的页面的平均加载速度 | |
| 社交网站 | Facebook shares | 在Facebook的受欢迎程度 |
| Twitter tweets | 在Twitter的受欢迎程度 | |
| Google plus shares | 在Google Plus的受欢迎程度 |
这些指标主要关注网站域名的三个方面, 分别是网站域名的受欢迎度、社交媒体指标和网站的性能指标。但是, 在收集不同来源的16个指标中可能存在一些高度的冗余性, 比如Moz’s total backlinks和Majestic’s backlinks都反映网站的反向链接数; Google’s Page Speed和Alexa’s median load都反映网站的加载速度等。这些冗余的指标不仅会增加恶意网站评估的复杂度, 而且也会降低恶意网站识别的效率。因此, 本文将采用主成分分析法对这些指标变量进行归类整合, 以更简洁直观的指标评估恶意网站。
(1) KMO检验
主成分分析的目的是从众多的变量中综合出少数具有代表性的因子, 这必定有一个潜在的前提条件, 即原有变量之间应该有较强的相关关系。所以在进行主成分分析之前需要首先对原有变量是否相关进行研究[22]。本文采用KMO(Kaiser-Meyer-Olkin)检验探究原有变量之间的相关关系。
KMO检验通过比较变量间的简单相关系数和偏相关系数分析变量间的相关性[22]。其数学定义如公式(1)所示。
$\text{KMO=}\frac{\sum{\sum\limits_{i\ne j}{r_{ij}^{2}}}}{\sum{\sum\limits_{i\ne j}{r_{ij}^{2}}}+\sum{\sum\limits_{i\ne j}{p_{ij}^{2}}}}$ (1)
其中, rij是变量xi和xj间的简单相关系数, pij是变量xi和xj在控制剩余变量下的偏相关系数。KMO数值越接近1, 变量间相关性越强。根据KMO检验度量标准, KMO 数值在[0.7, 1.0]之间适合进行主成分分析[22]。本文通过对16个互联网指标运用R语言psych包中的KMO( )方法进行KMO检验, 结果显示KMO值为0.82, 因此适合做主成分分析。
(2) 提取主成分
本研究借助R语言psych包中的相关函数对收集的网站测评指标进行主成分分析, 包括的主要步骤如下。
①对各指标变量进行零均值标准化处理, 以中心化数据;
②计算标准化数据后的特征值和特征向量, 并根据特征值大于1的标准或采用平行分析法保留特征根及其特征向量;
③使用principal( )进行主成分的提取以及正交旋转。
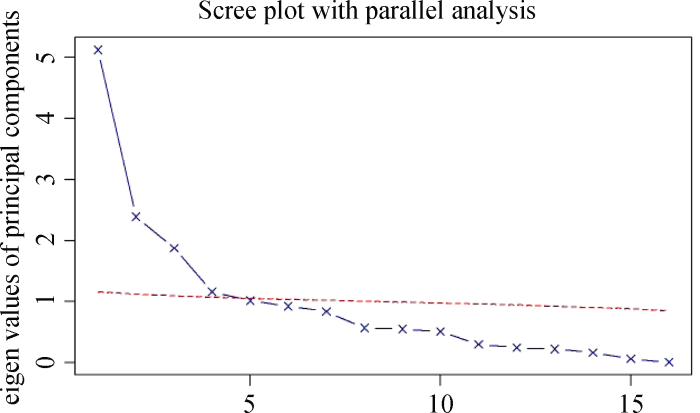
表2显示提取出的16个特征值及其贡献率, 并将特征值按降序排序。根据特征值大于 1的标准, 保留前5个特征值, 且累积方差贡献率已达到72%, 因此可以用这5个主成分表征原有的16个变量。此外, 图2展示用于平行分析的碎石图。平行分析法会生成多组(本文选取100组)与初始矩阵相同结构的随机数据矩阵, 通过将随机矩阵的平均特征值(虚线)与实际数据的特征值(实线)进行对比, 根据交叉点来判断应提取的主成分个数。基于图2可以看出, 主成分数为5时, 随机矩阵的平均特征值与实际数据的特征值基本持平。鉴于此, 本文选取5个主成分。主成分提取及正交旋转后结果如表3所示。
表2 特征值及其贡献率
| 变量 | 特征值 | 贡献率 | 累积贡献率 |
|---|---|---|---|
| 1 | 5.12214596 | 0.3201341227 | 0.3201341 |
| 2 | 2.39191511 | 0.1494946944 | 0.4696288 |
| 3 | 1.87757791 | 0.1173486195 | 0.5869774 |
| 4 | 1.16274401 | 0.0726715004 | 0.6596489 |
| 5 | 1.01827300 | 0.0636420626 | 0.7232910 |
| 6 | 0.92795486 | 0.0579971785 | 0.7812882 |
| 7 | 0.83805885 | 0.0523786779 | 0.8336669 |
| 8 | 0.57201780 | 0.0357511122 | 0.8694180 |
| 9 | 0.55509074 | 0.0346931711 | 0.9041111 |
| 10 | 0.51360908 | 0.0321005675 | 0.9362117 |
| 11 | 0.30381803 | 0.0189886270 | 0.9552003 |
| 12 | 0.24950388 | 0.0155939926 | 0.9707943 |
| 13 | 0.22731629 | 0.0142072679 | 0.9850016 |
| 14 | 0.16495318 | 0.0103095735 | 0.9953112 |
| 15 | 0.06485261 | 0.0040532884 | 0.9993645 |
| 16 | 0.01016870 | 0.0006355439 | 1.0000000 |
表3 方差极大法旋转之后的主成分结果
| 变量 | RC1 | RC2 | RC3 | RC4 | RC5 | h2 | u2 |
|---|---|---|---|---|---|---|---|
| MozDomain Authority | 0.88 | 0.09 | 0.09 | -0.01 | 0.03 | 0.80 | 0.2034 |
| MozTotalBacklinks | 0.08 | 0.13 | -0.02 | -0.04 | 0.88 | 0.80 | 0.1994 |
| MozRank | 0.86 | 0.06 | 0.03 | 0.08 | 0.04 | 0.74 | 0.2556 |
| GooglePageRank | 0.91 | 0.07 | 0.08 | -0.01 | 0.00 | 0.83 | 0.1695 |
| FacebookShares | -0.02 | 0.79 | 0.02 | 0.04 | -0.10 | 0.64 | 0.3572 |
| TwitterTweets | 0.08 | 0.78 | -0.01 | 0.00 | -0.11 | 0.62 | 0.3798 |
| GooglePlusShares | 0.32 | 0.13 | -0.08 | -0.24 | -0.30 | 0.27 | 0.7308 |
| AlexaMedianLoad | 0.53 | 0.04 | 0.11 | 0.53 | -0.03 | 0.57 | 0.4283 |
| AlexaRanks | 0.00 | 0.00 | -0.05 | 0.90 | 0.00 | 0.81 | 0.1931 |
| Alexa1MthReach | 0.09 | -0.01 | 0.99 | 0.00 | 0.00 | 0.99 | 0.0097 |
| Alexa3MthReach | 0.08 | 0.00 | 0.99 | 0.00 | 0.00 | 0.99 | 0.0110 |
| GooglePageSpeed | 0.42 | -0.03 | -0.03 | 0.18 | -0.03 | 0.21 | 0.7901 |
| MajesticCitation Flow | 0.93 | 0.16 | 0.05 | -0.03 | 0.08 | 0.90 | 0.1026 |
| MajesticTrustFlow | 0.92 | 0.15 | 0.08 | -0.07 | 0.07 | 0.88 | 0.1170 |
| MajesticBacklinks | 0.17 | 0.73 | -0.02 | -0.04 | 0.40 | 0.73 | 0.2710 |
| MajesticReference domains | 0.21 | 0.77 | -0.02 | -0.05 | 0.40 | 0.79 | 0.2088 |
①第一个主因子在Moz’s Domain Authority、MozRank、GooglePageRank、Majestic’s CitationFlow、Majestic’s TrustFlow这些变量上的载荷大, 这些变量主要反映一个网站的权威值以及与其他可靠网站的引用关系, 因此可以将第一个主因子定义为权威因子。
②第二个主因子在FacebookShares、TwitterTweets、Extbacklinks、Refdomains变量上的载荷相对较大, 这些变量都可以理解为外部环境对于该域名的引用情况, 包括社交平台对于该域名的分享, 以及其他网站引用该域名的情况, 因此可以将该因子定义为引用因子。
③第三个主因子主要由Alexa1MthReach、Alexa3 MthReach解释, 因此可以将该因子定义为访问量因子。
④第四个因子主要由AlexaRanks解释, 因此可以将这个因子定义为排名因子。
⑤第五个因子主要由MozTotalLinks解释, 因此可以将这个因子定义为链接因子。
相较于原有的16个测评指标, 由5个主因子所代表的5个维度可以更加简洁、综合地评估网站信息, 有助于了解恶意网站的主要特征和主要模式, 而且有助于高效地构建恶意网站识别模型。
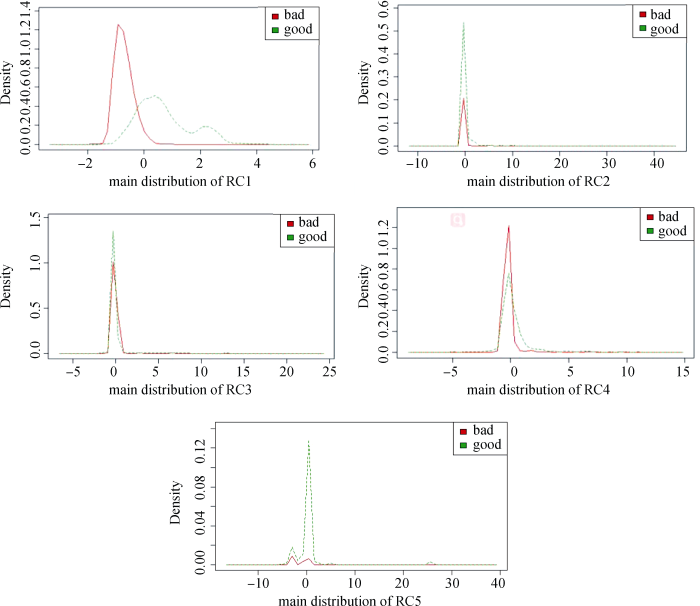
为了验证提取的因子是否能够有效区分恶意网站与正常网站, 本文分别绘制各个因子在正常网站与恶意网站下的核密度分布, 如图3所示。
由图3可知, 第一主因子在正常网站和恶意网站下的核密度分布存在显著的差异, 恶意网站下第一主因子的得分集中分布在[-2, 0]之间, 而正常网站的第一主因子得分主要分布在[-1, 3]之间, 一定程度上可以较好地区分正常网站与恶意网站。第五主因子的分布差异也比较明显, 正常网站的第五主因子得分集中在[0, 1]之间, 而恶意网站的得分则相对比较分散。第二、三、四因子的分布有差异但并不大。总的来看, 虽然5个因子可以从不同维度评价网站, 但依据这5个主因子还不能够很好地进行恶意网站的识别。因此, 基于各网站在5个因子上的得分, 接下来采用随机森林构建恶意网站识别模型, 验证本文提取因子的有效性。
(1) 模型评价指标
为了有效检验恶意网站识别模型的效果, 本文基于二分类问题的混淆矩阵计算各准确性指标, 如表4所示。考虑到实际中恶意网站的错分代价更高, 因此, 在该混淆矩阵中, 恶意网站被视为正类。
其中, 恶意网站样本为 P, 正常网站样本为 N, FP指将正常网站错分成恶意网站的样本数目, FN指将恶意网站错分成正常网站的样本数目, TP和TN分别表示恶意网站和正常网站被正确分类的样本数目。
据此得到4类性能评价指标, 算法的准确率、恶意网站样本的查全率(召回率)、恶意网站的查准率、恶意网站的查全率与查准率的调和平均值(F值)分别如公式(2)-公式(5)所示。
Accuracy = (TP+TN)/(TP+TN+FP+FN) (2)
Recall = TP/(TP+FN) (3)
Precision = TP/(FP+TP) (4)
F-measure =(2×Recall×Precision)/(Recall+Precision) (5)
由公式(5)可知, 性能指标 F-measure既考虑恶意网站样本的查全率又考虑查准率, 只有在查全率和查准率的值都比较大的前提下, F-measure值才会很大。因此, 它能综合地体现出分类器对正常网站和恶意网站的分类效果, 而且侧重于体现恶意网站样本的分类效果。
(2) 实验过程和分析
采用随机森林对提取的5个主成分因子进行恶意网站的识别研究, 并且采用10折交叉验证的方法进行训练和测试, 每组实验均重复10次以防止随机影响, 最后计算10次实验结果的统计平均值。基于随机森林的识别模型采用R语言中randomForest包实现, 模型中决策树个数取值500, 即共计构建了500棵决策树, 并采用投票法进行投票得到最终识别结果。实验结果如表5所示。
可以看出, 基于提取的5个主成分因子构建的随机森林识别模型在各性能指标上均大于90%, 具有较好的识别效果, 这表明所构建的基于主成分分析和随机森林的混合模型是有效的。
(3) 统计检验分析
为了验证基于主成分分析和随机森林模型取得的效果同基于所有变量取得效果的区别, 对结果进行了统计检验。
本文选取决策树、支持向量机(SVM)、K近邻法、朴素贝叶斯、人工神经网络、AdaBoost、Bagging和随机森林等8种经典的机器学习技术在原始数据上构建识别模型。这些模型在数据挖掘和机器学习领域得到广泛应用, 而且是恶意网站识别研究中的常用技术[5]。另外, 各模型均采用十折交叉验证技术得到准确率、查全率、查准率、F值等4种评价指标。
为了检验各方法性能的统计性差异, 本文分两个阶段进行统计检验[23]。首先使用Friedman检验所有算法的性能是否相同, 如果拒绝原假设, 之后使用Nemenyi检验进一步对算法进行两两对比。这两个统计检验方法都是非参数检验, 对待检验数据的分布情况没有严格要求。其中, Friedman检验是利用秩实现对多个总体分布是否存在显著差异的非参数检验方法, 其原理假设是: 多个配对样本来自的多个总体分布无显著差异。在进行Friedman检验时, 首先以行为单位将数据按升序排序, 并求得各变量值在各自行中的秩; 然后, 分别计算各组样本下的秩总和与平均秩。
Nemenyi检验是一个事后检验, 旨在发现在多重比较的统计检验(例如Friedman检验)已经拒绝零假设之后数据组之间的是否有显著差异。
具体来说, 首先独立重复30次交叉验证, 获得每个算法的30个F-measure值, 每个算法的F-measure均值如表6所示。并在此基础上进行Friedman检验比较原始数据的8个分类模型和基于主成分分析的随机森林模型共9个分类模型取得的效果是否有显著差异。此次检验使用了R语言stats包中的friedman.test()进行检验, 检验结果中p-value值远小于0.05, 所以在显著性水平为0.05时, Friedman检验的结果拒绝原假设, 即认为这9个模型取得的效果存在显著性差异, 因此需要进一步做事后检验。
表6 各算法的F-measure均值
| 算法 | F值 |
|---|---|
| 混合模型 | 0.91 |
| AdaBoost | 0.94 |
| Bagging | 0.92 |
| 朴素贝叶斯 | 0.80 |
| 随机森林 | 0.94 |
| 决策树 | 0.89 |
| K近邻法 | 0.91 |
| 神经网络 | 0.88 |
| SVM | 0.91 |
为了进一步验证本文提出的基于主成分分析与随机森林的混合模型与其他8个模型的显著性差异, 再进行Nemenyi事后检验, 结果如表7 所示。检验结果表明, 在显著性水平为0.05的情况下, 基于主成分分析和随机森林的识别模型与表7中的前4个模型存在显著差异, 而且由表6所知, 本文构建的混合模型的识别效果优于朴素贝叶斯在原始数据集的表现, 略差于AdaBoost、Bagging、随机森林。另外, 构建的混合模型的识别效果与决策树、K近邻法、神经网络和SVM的识别效果差异不大。总的来看, 基于主成分分析和随机森林的混合模型不仅能有效地从5个维度评估网站, 还能在此基础上较为有效地识别恶意网站。
表7 Nemenyi事后检验结果
| 算法对比 | p值 |
|---|---|
| 混合模型-AdaBoost | 0.00** |
| 混合模型-Bagging | 2.56E-04** |
| 混合模型-朴素贝叶斯 | 1.67E-04** |
| 混合模型-随机森林 | 0.00** |
| 混合模型-决策树 | 0.55 |
| 混合模型-K近邻法 | 0.74 |
| 混合模型-神经网络 | 0.24 |
| 混合模型-SVM | 0.13 |
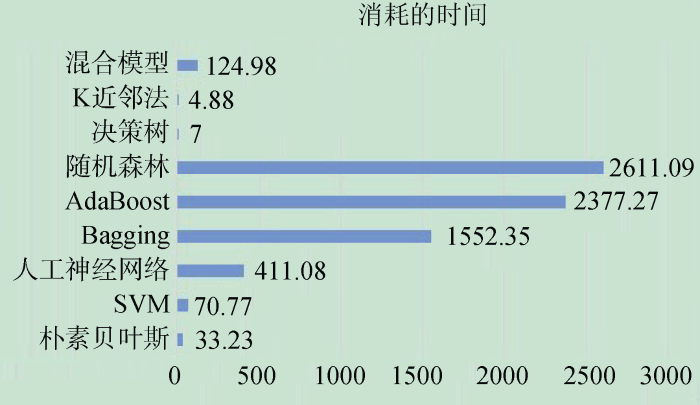
另外, 本文计算各算法运行时消耗在应用程序(非操作系统部分)执行的时间, 结果如图4所示。
可以看出, 所提出的混合主成分分析与随机森林的模型比K近邻法、决策树、SVM和朴素贝叶斯等单一模型消耗较多的时间, 这主要是因为随机森林模型是一种集成学习模型, 它在训练中构建很多子模型, 因而相对单一模型而言, 耗时较多。但是, 同AdaBoost、Bagging和随机森林等三种集成模型和人工神经网络比, 本文构建的混合模型时间消耗大大缩减, 这充分说明所提模型在采用主成分分析法进行主成分提取后, 有效降低了原有数据的维度, 进而提高了模型效率。
为有效评估与识别恶意网站, 本文构建混合主成分分析法与随机森林的评估与识别模型。基于收集的16个网络评测指标, 该混合模型首先采用主成分分析法提取出5个维度特征, 以降低指标体系的冗余性和复杂性, 并提高恶意网站的评估效率; 然后在此基础上利用随机森林算法构建恶意网站识别模型, 并与其他多种常见机器学习算法进行对比。实验结果表明, 基于主成分分析法提取的主成分具有很好的解释性, 便于对恶意网站进行多维度评价; 在所提取主成分的基础上构建的随机森林识别模型能较好地识别恶意网站, 并有效地降低了模型维度, 大大提高了模型训练效率。
然而, 受数据获取的限制, 本研究的样本大多属于国外的网站, 所提取的维度可能与国内恶意网站有一定差异, 未来将尝试收集更多国内的恶意网站。本研究主要利用采集于互联网的多源评测指标对恶意网站进行评估与识别, 未来会尝试融合包括URL特征、页面信息、网络评测指标等更多不同来源的特征变量, 以进一步探寻恶意网站的伪装模式。此外, 实际生活中的恶意网站与正常网站的比例是不均衡的, 在之后的研究中将针对这一类别不均衡问题, 研究更先进的机器学习技术与识别模型。
陈远, 王超群, 胡忠义: 提出研究思路, 设计研究方案;
王超群, 胡忠义: 数据处理, 模型构建及实验验证, 论文撰写;
陈远, 胡忠义, 吴江: 论文修改。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: zhongyi.hu@whu.edu.cn。
[1] 陈远, 王超群, 胡忠义, 吴江. Malicious_sites.csv. 网站列表及评测指标.
| [1] |
An Empirical Analysis of Phishing Blacklists [C]// |
| [2] |
Phinding Phish: Evaluating Anti-phishing Tools [C]// |
| [3] |
基于异常特征的钓鱼网站 URL 检测技术 [J].Detection of Phishing URL Based on Abnormal Feature [J]. |
| [4] |
Utilisation of Website Logo for Phishing Detection [J].https://doi.org/10.1016/j.cose.2015.07.006 URL [本文引用: 2] 摘要
Phishing is a security threat which combines social engineering and website spoofing techniques to deceive users into revealing confidential information. In this paper, we propose a phishing detection method to protect Internet users from the phishing attacks. In particular, given a website, our proposed method will be able to detect if it is a phishing website. We use a logo image to determine the identity consistency between the real and the portrayed identity of a website. Consistent identity indicates a legitimate website and inconsistent identity indicates a phishing website. The proposed method consists of two processes, namely logo extraction and identity verification. The first process will detect and extract the logo image from all the downloaded image resources of a webpage. In order to detect the right logo image, we utilise a machine learning technique. Based on the extracted logo image, the second process will employ the Google image search to retrieve the portrayed identity. Since the relationship between the logo and domain name is exclusive, it is reasonable to treat the domain name as the identity. Hence, a comparison between the domain name returned by Google with the one from the query website will enable us to differentiate a phishing from a legitimate website. The conducted experiments show reliable and promising results. This proves the effectiveness and feasibility of using a graphical element such as a logo to detect a phishing website.
|
| [5] |
Identifying Malicious Web Domains Using Machine Learning Techniques with Online Credibility and Performance Data [C]// |
| [6] |
网站恶意性评估系统设计与实现 [D].The Design and Implementation of Website Malice Assessing System [D]. |
| [7] |
Examining the Effectiveness of Phishing Filters Against DNS Based Phishing Attacks, Information & Computer Security [J].https://doi.org/10.1108/ICS-02-2013-0009 URL [本文引用: 1] 摘要
Abstract Purpose – This paper aims to report on research that tests the effectiveness of anti-phishing tools in detecting phishing attacks by conducting some real-time experiments using freshly hosted phishing sites. Almost all modern-day Web browsers and antivirus programs provide security indicators to mitigate the widespread problem of phishing on the Internet. Design/methodology/approach – The current work examines and evaluates the effectiveness of five popular Web browsers, two third-party phishing toolbar add-ons and seven popular antivirus programs in terms of their capability to detect locally hosted spoofed websites. The same tools have also been tested against fresh phishing sites hosted on Internet. Findings – The experiments yielded alarming results. Although the success rate against live phishing sites was encouraging, only 3 of the 14 tools tested could successfully detect a single spoofed website hosted locally. Originality/value – This work proposes the inclusion of domain name system server authentication and verification of name servers for a visiting website for all future anti-phishing toolbars. It also proposes that a Web browser should maintain a white list of websites that engage in online monetary transactions so that when a user requires to access any of these, the default protocol should always be HTTPS (Hypertext Transfer Protocol Secure), without which a Web browser should prevent the page from loading.
|
| [8] |
AdaCostBoost 算法的网络钓鱼检测 [J].
针对日益严重的网络钓鱼攻击, 提出机器学习的方法进行钓鱼网站的检测和判断. 首先, 根据URL提取敏感特征, 然后, 采用AdaBoost算法进行训练出分类器, 再用训练好的分类器对未知URL检测识别. 最后, 针对非平衡代价问题, 采用了改进后的AdaBoost算法--AdaCostBoost, 加入代价因子的计算. 实验结果表明, 文中提出的网络钓鱼检测方法, 具有较优的检测性能.
Phishing Detection System Based on AdaCostBoost Algorithm [J].
针对日益严重的网络钓鱼攻击, 提出机器学习的方法进行钓鱼网站的检测和判断. 首先, 根据URL提取敏感特征, 然后, 采用AdaBoost算法进行训练出分类器, 再用训练好的分类器对未知URL检测识别. 最后, 针对非平衡代价问题, 采用了改进后的AdaBoost算法--AdaCostBoost, 加入代价因子的计算. 实验结果表明, 文中提出的网络钓鱼检测方法, 具有较优的检测性能.
|
| [9] |
Multi-label Rules for Phishing Classification [J].https://doi.org/10.1016/j.aci.2014.07.002 URL [本文引用: 1] 摘要
Generating multi-label rules in associative classification (AC) from single label data sets is considered a challenging task making the number of existing algorithms for this task rare. Current AC algorithms produce only the largest frequency class connected with a rule in the training data set and discard all other classes even though these classes have data representation with the rule body. In this paper, we deal with the above problem by proposing an AC algorithm called Enhanced Multi-label Classifiers based Associative Classification (eMCAC). This algorithm discovers rules associated with a set of classes from single label data that other current AC algorithms are unable to induce. Furthermore, eMCAC minimises the number of extracted rules using a classifier building method. The proposed algorithm has been tested on a real world application data set related to website phishing and the results reveal that eMCAC accuracy is highly competitive if contrasted with other known AC and classic classification algorithms in data mining. Lastly, the experimental results show that our algorithm is able to derive new rules from the phishing data sets that end-users can exploit in decision making.
|
| [10] |
Using Case-Based Reasoning for Phishing Detection [J].https://doi.org/10.1016/j.procs.2017.05.352 URL [本文引用: 1] 摘要
Abstract Many classifications techniques have been used and devised to combat phishing threats, but none of them is able to efficiently identify web phishing attacks due to the continuous change and the short life cycle of phishing websites. In this paper, we introduce a Case-Based Reasoning (CBR) Phishing Detection System (CBR-PDS). It mainly depends on CBR methodology as a core part. The proposed system is highly adaptive and dynamic as it can easily adapt to detect new phishing attacks with a relatively small data set in contrast to other classifiers that need to be heavily trained in advance. We test our system using different scenarios on a balanced 572 phishing and legitimate URLs. Experiments show that the CBR-PDS system accuracy exceeds 95.62%, yet it significantly enhances the classification accuracy with a small set of features and limited data sets.
|
| [11] |
New Rule-based Phishing Detection Method [J].https://doi.org/10.1016/j.eswa.2016.01.028 URL [本文引用: 1] 摘要
In this paper, we present a new rule-based method to detect phishing attacks in internet banking. Our rule-based method used two novel feature sets, which have been proposed to determine the webpage identity. Our proposed feature sets include four features to evaluate the page resources identity, and four features to identify the access protocol of page resource elements. We used approximate string matching algorithms to determine the relationship between the content and the URL of a page in our first proposed feature set. Our proposed features are independent from third-party services such as search engines result and/or web browser history. We employed support vector machine (SVM) algorithm to classify webpages. Our experiments indicate that the proposed model can detect phishing pages in internet banking with accuracy of 99.14% true positive and only 0.86% false negative alarm. Output of sensitivity analysis demonstrates the significant impact of our proposed features over traditional features. We extracted the hidden knowledge from the proposed SVM model by adopting a related method. We embedded the extracted rules into a browser extension named PhishDetector to make our proposed method more functional and easy to use. Evaluating of the implemented browser extension indicates that it can detect phishing attacks in internet banking with high accuracy and reliability. PhishDetector can detect zero-day phishing attacks too.
|
| [12] |
Phishing Website Detection Using C4.5 Decision Tree [ |
| [13] |
PhishWHO: Phishing Webpage Detection via Identity Keywords Extraction and Target Domain Name Finder [J].https://doi.org/10.1016/j.dss.2016.05.005 URL [本文引用: 1] 摘要
This paper proposes a phishing detection technique based on the difference between the target and actual identities of a webpage. The proposed phishing detection approach, called PhishWHO, can be divided into three phases. The first phase extracts identity keywords from the textual contents of the website, where a novel weighted URL tokens system based on the N-gram model is proposed. The second phase finds the target domain name by using a search engine, and the target domain name is selected based on identity-relevant features. In the final phase, a 3-tier identity matching system is proposed to determine the legitimacy of the query webpage. The overall experimental results suggest that the proposed system outperforms the conventional phishing detection methods considered.
|
| [14] |
基于分类集成的钓鱼网站智能检测系统 [J].
近来,通过仿冒真实网站的URL地址及其页面内容的“钓鱼网站”已严重威胁到互联网用户的隐私和财产安全.为了应对这种威胁,该文通过对大量已知正常网站和钓鱼网站的学习,解析其对应的网页内容,提取相应的网页标题、网页关键字、网页描述信息等8种特征来描述这些网站,然后基于不同的特征表达方法构建了相应的分类器;对于待检测的网站,采用分类集成的方法综合各个分类模型的预测结果,达到对钓鱼网站智能检测的目标.基于上述方法,构建了钓鱼网站智能检测系统IPWDS,并将其集成于金山安全产品中.在大量、真实数据集的基础上,实验结果表明IPWDS系统对钓鱼网站的检测效果优于现有常见的钓鱼网站检测方法和常用的反钓鱼软件.
Intelligent Phishing Website Detection Using Classification Ensemble [J].
近来,通过仿冒真实网站的URL地址及其页面内容的“钓鱼网站”已严重威胁到互联网用户的隐私和财产安全.为了应对这种威胁,该文通过对大量已知正常网站和钓鱼网站的学习,解析其对应的网页内容,提取相应的网页标题、网页关键字、网页描述信息等8种特征来描述这些网站,然后基于不同的特征表达方法构建了相应的分类器;对于待检测的网站,采用分类集成的方法综合各个分类模型的预测结果,达到对钓鱼网站智能检测的目标.基于上述方法,构建了钓鱼网站智能检测系统IPWDS,并将其集成于金山安全产品中.在大量、真实数据集的基础上,实验结果表明IPWDS系统对钓鱼网站的检测效果优于现有常见的钓鱼网站检测方法和常用的反钓鱼软件.
|
| [15] |
基于主动探测的仿冒网站检测系统设计与实现 [D].Design and Implementation Phishing Detecting System Based on Active Detection [D]. |
| [16] |
基于登录页面及Logo图标检测的反钓鱼方案 [D].An Anti- phishing Scheme Based on Login Page Detection and Logo Identification [D]. |
| [17] |
基于Web社区的钓鱼网站检测研究 [D].A Method of Phishing Detection Based on Web Community [D]. |
| [18] |
Web Phishing Detection Based on Page Spatial Layout Similarity [J].
Web phishing is becoming an increasingly severe security threat in the web domain. Effective and efficient phishing detection is very important for protecting web users from loss of sensitive private information and even personal properties. One of the keys of phishing detection is to efficiently search the legitimate web page library and to find those page that are the most similar to a suspicious phishing page. Most existing phishing detection methods are focused on text and/or image features and have paid very limited attention to spatial layout characteristics of web pages. In this paper, we propose a novel phishing detection method that makes use of the informative spatial layout characteristics of web pages. In particular, we develop two different options to extract the spatial layout features as rectangle blocks from a given web page. Given two web pages, with their respective spatial layout features, we propose a page similarity definition that takes into account their spatial layout characteristics. Furthermore, we build an R-tree to index all the spatial layout features of a legitimate page library. As a result, phishing detection based on the spatial layout feature similarity is facilitated by relevant spatial queries via the R-tree. A series of simulation experiments are conducted to evaluate our proposals. The results demonstrate that the proposed novel phishing detection method is effective and efficient. Povzetek: Opisana je detekcija spletnega ribarjenja na osnovi podobnosti strani. 1
|
| [19] |
A Multi-tier Phishing Detection and Filtering Approach [J].https://doi.org/10.1016/j.jnca.2012.05.009 URL [本文引用: 1] |
| [20] |
主成分分析综合评价应该注意的问题 [J].https://doi.org/10.3969/j.issn.1002-4565.2013.08.004 URL [本文引用: 2] 摘要
将主成分分析用于多指标的综合评价较普遍,但因缺乏应用条件的考虑而导致评价结果不具合理性甚至错误,故应深入研究其应用条件。本文应用因子分析法因子载荷阵的简单结构、加权算术平均数的合理性,得出主成分分析综合评价的应用条件是:指标是正向、标准化的,主成分载荷阵达到更好的简单结构,主成分正向,主成分与变量显著相关;并结合2010年广东省各市对外贸易国际竞争力的评价实例提出了一些建议。
Some Problems in Comprehensive Evaluation in the Principal Component Analysis [J].https://doi.org/10.3969/j.issn.1002-4565.2013.08.004 URL [本文引用: 2] 摘要
将主成分分析用于多指标的综合评价较普遍,但因缺乏应用条件的考虑而导致评价结果不具合理性甚至错误,故应深入研究其应用条件。本文应用因子分析法因子载荷阵的简单结构、加权算术平均数的合理性,得出主成分分析综合评价的应用条件是:指标是正向、标准化的,主成分载荷阵达到更好的简单结构,主成分正向,主成分与变量显著相关;并结合2010年广东省各市对外贸易国际竞争力的评价实例提出了一些建议。
|
| [21] |
Random Forests [J].https://doi.org/10.1023/A:1010933404324 URL [本文引用: 1] |
| [22] |
|
| [23] |
Statistical Comparisons of Classifiers over Multiple Data Sets [J]. |

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}