俞琰 , 赵乃瑄
, 赵乃瑄
Yu Yan, Zhao Naixuan
中图分类号: G250
通讯作者:
收稿日期: 2017-10-26
修回日期: 2017-12-5
网络出版日期: 2018-04-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】解决专利文本分析中主题模型向高频词倾斜、区分度低的问题。【方法】提出基于词权重方法, 形成加权专利文本主题模型, 给不同的词分配不同的权重, 改变生成模型生成词的概率。【结果】相较于传统的专利文本主题模型, 本文提出的加权专利主题模型能够增加主题间的区分度。【局限】加权算法需要更多数据集验证, 并不断优化。【结论】通过专利文本数据验证了该方法的可行性与有效性。
关键词:
Abstract
[Objective] This study aims to address the issues facing the topic model of patent text analysis such as the inclining to high frequency words and low discrimination rates. [Methods] First, we proposed a word weighting method for the traditional topic model. Then, the modified model assigned different weights to the words, and changed the probability of generating new words. [Results] Compared with traditional methods, the weighted patent topic model could identify the subjects more effectively. [Limitations] The weighting algorithm needs to be validated and optimized with more datasets. [Conclusions] The proposed model could effectively analyze the patent texts.
Keywords:
在科技飞速发展的今天, 创新是企业生存与发展的关键。创新设计是一种由问题驱动, 综合运用大量知识与经验的复杂的创造性实践活动。专利文本蕴含丰富的各种领域问题的解决方案, 对创新设计具有重要的借鉴意义。有效的专利文本分析能够判断领域技术热点、识别领域核心技术、预测领域技术发展趋势, 帮助研发人员从中获得启发与借鉴, 从而缩短创新设计时间、节约创新设计经费。因此, 专利文本分析具有重要的研究意义。
传统的专利文本分析方法通常使用专利文本中的词语直接作为主题或概念, 进而利用主题或概念建模, 分析领域技术状况[1,2,3,4,5]。然而, 专利作为一种被保护的文献, 专利申请者为了扩大所申请专利的保护范围和提高专利授权的可能性, 往往会使用一些模糊或者抽象的表达。因此, 从专利文本所表达的潜在语义层面理解专利文本, 才能得到更好的专利文本分析效果。不同于传统的专利文本分析方法, 主题模型通过分析文本集合中词语共现的概率分布, 挖掘文本隐含的语义信息, 因而被广泛应用于文本分析之中, 并取得较好的效果。随着主题模型的逐步完善, 研究者开始尝试将主题模型应用于专利文本分析之中, 以揭示专利文本深层次知识结构[3, 6-14]。
虽然主题模型可有效地挖掘专利文本中隐含的语义信息, 并取得了较好的分析效果, 然而, 在主题学习过程中, 学习得到的主题分布向高频词倾斜。这些词通常是一些出现频率高但无实际意义的停用词, 不能很好地刻画主题特征, 如中文的“的”、“是”, 英文的“of”、“the”等词。在生成主题模型的迭代过程中, 由于这些高频词频繁出现在多个主题中, 导致主题分布摇摆不停, 不能明显区别各个主题, 收敛速度变慢。研究表明文本中的高频词对主题模型会产生负面的影响[15]。为了避免这种情况, 通常在构建专利文本主题模型之前借助停用词表, 预先删除停用词这种高频词。但是, 这种方法并不能完全过滤掉表意性较差的词语。以专利文本分析为例, 专利文本中常出现“方法”、“包含”、“发明”等非停用词, 这些词通过主题建模, 出现在多个主题之中, 使得主题间的区分度低, 不能很好地表示专利文本的语义信息。
专利文本主题模型同等地对待每个词, 假设每个词都是同等重要的。然而, 无论是从信息论还是从语言学来看, 该假设与现实并不吻合。因此, 本文提出一种加权专利文本主题模型。该模型根据每个词在每个专利文本中的重要程度, 为专利中的每个词分配不同的权重, 然后将其融入专利文本主题模型之中, 形成加权专利文本主题模型, 改变专利主题模型生成词的概率, 以更好地区分专利文本主题。
近年来, 研究者尝试将主题模型应用于专利文本分析之中, 以挖掘专利文本深层次知识结构。但主题模型采用词袋形式表示文本, 学习得到的主题向高频词倾斜, 导致能够代表专利主题的词被高频词所淹没, 降低了模型对专利文本信息的描述能力。为此, 通常借助停用词表或其他人工预先编写好的单词表, 去掉这些高频词。如, 吴菲菲等[12]为揭示专利文本中隐含的主题演化, 首先对专利文本进行预处理, 去除停用词、专利描述常用词(如“comprise”、“include”、“claim”等)以及学术词汇(如“method”、“advantage”等)。Chen等[8]使用主题模型评估大量专利权力要求书中隐藏的主题。在主题模型建模之前, 使用三个模块移除专利集中常见单词。首先, 使用斯坦福大学的停用词列表, 移除停用词; 利用维基百科相关信息移除专利权力要求书中高频单词(如“claimed”、“comprising”、“invention”等); 使用诺丁汉大学提供的通用学术单词列表, 去除使用最频繁的100个学术单词(如“research”、“approach”等)。Kim等[3]使用主题模型进行专利文本分析之前, 排除如“this”、“method”、“invention”、“part”等不相关词语。
主题模型采用词袋形式表示文本, 假设词袋中的每个词语都是同等重要的。然而, 从信息论或语言学来看, 不同词语对文本贡献程度不同。加权主题模型在一些非专利文本问题中得到研究。如, Wilson和Chew[16]根据信息理论, 认为词语的贡献与其出现频率成反比, 根据词语所属种类的不同, 提出使用词语的点互信息来度量词语对文档的贡献。巴志超等[17]采用点互信息词加权方法对不同文献单元上的关键词赋予不同的权值, 并扩展至主题模型。唐晓波等[18]提出微博热度的概念, 并将其引入到主题模型的热点挖掘中, 构建基于微博热度的主题模型。李湘东等[19]为改善图书和期刊的分类性能, 综合考虑图书书目文本信息不同要素差异并构造复合权值, 将特征加权扩展至主题模型之中, 使获取的特征词不局限于高频词而更能代表书目的文本信息。郝洁等[20]针对现有情感分析方法主题间区分较低的问题, 提出一种词加权主题模型算法, 实现无监督的主题提取和情感分析。Yu等[21]结合文本和社交网络关注关系, 提出主题模型, 利用基于用户的相似性度量作为权重策略, 以识别社交网络中的领域专家。
由此可见, 针对专利文本分析中主题模型向高频词倾斜、区分度低的问题, 通常采用去除停用词或者手工去除高频词完成, 效果不尽理想。而由于专利文本的特殊性, 其他领域中的加权主题模型不能直接应用于专利文本主题模型建模之中。因此, 本文探索用于专利文本分析的加权专利文本主题模型。
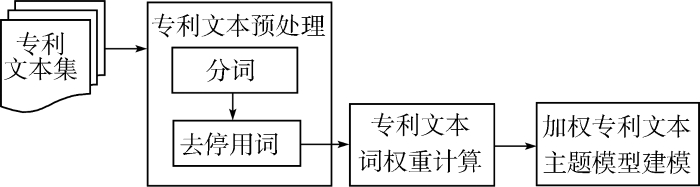
针对主题模型学习得到的主题分布向高频词倾斜的问题, 本文基于传统的专利文本主题模型, 提出加权专利文本主题模型。该模型包括三个步骤: 专利文本预处理、专利文本词权重计算和加权专利文本主题模型建模, 如图1所示。
(1) 将专利数据库检索得到的专利文本集进行预处理, 主要包括分词和去停用词两个部分。分词将一个句子按照其词的含义进行切分。去停用词将根据停用词表, 删除文本内容识别意义不大、但出现频率很高的停用词。
(2) 专利文本词权重计算根据每个词在每个专利文本中的重要程度, 为专利文本中的每个词分配不同的权重。
(3) 加权专利文本主题模型建模将词的权重信息融入到基本专利文本主题模型之中, 形成加权专利文本主题模型, 提高专利文本主题模型主题之间的区分度。
本文将专利文本词权重计算分解为两个部分, 一部分是局部权重, 记作LW(i, j), 表示词wi在专利文本dj中的重要程度; 另一部分是全局权重, 记作GW(i), 表示词wi在专利文本集中区分文本语义的能力。因此, 将词权重W(i, j)表示为公式(1)所示。
$W(i,j)=LW(i,j)\times GW(i)$ (1)
(1) 局部权重
局部权重强调某一词语在某一文本中的重要性, 最简单的方法是将词频TF作为局部权重。词频指某一词语在该文本中出现的频率。对每个文本的词频作归一化处理, 即文本dj中词wi出现的词频tf (i, j)除以该文本中所有词的词频之和。基于词频的局部权重计算如公式(2)[22]所示。
$L{{W}_{TF}}(i,d)=\frac{tf(i,j)}{\sum\nolimits_{w\in {{d}_{j}}}{tf(w,j)}}$ (2)
在专利文本中, 不同位置出现的词往往具有不同的重要性, 如在专利标题中出现的词通常更能有效地表示专利的主要内容。为了区别专利文本中不同位置词语的贡献程度, 本文假设在专利文本中出现越早的词语越重要。考虑词语的位置信息因素, 每个词的贡献程度与其出现的位置成反比。因此, 定义词wi在文本dj中贡献度C(i, j)为该词在文本中出现位置倒数之和。例如, 如果一个词分别出现在一个文本的第2、5和10位置, 则它对该文本的贡献度C=$\frac{1}{2}+\frac{1}{5}+\frac{1}{10}=$ $0.8$。对每个文本作归一化处理, 得到位置局部权重。本文对基于词频的局部权重进行改进, 提出基于位置的局部权重, 计算如公式(3)所示。
$L{{W}_{P}}(i,j)=\frac{C(i,j)}{\sum\nolimits_{w\in {{d}_{j}}}{C(w,j)}}$ (3)
(2) 全局权重
全局权重强调某一词语在整个文本集中的重要性。词全局权重一般通过统计方法计算获得。最有代表性的是IDF。IDF权重认为文本集包含某词语的文档数目越多, 该词语对文本的贡献越小, 这样的词语需要受到抑制; 相反, 文本集中包含某词语的文本数目越少, 则该特征对文本的贡献越大, 这样的词语需要被放大。基于IDF的全局权重定义如公式(4)[22]所示。
$G{{W}_{IDF}}(i)={{\log }_{2}}(\frac{M}{{{M}_{i}}}+0.01)$ (4)
其中, M为语料中文本数量; Mi表示出现词wi的文本数量。
然而, IDF仅关注词在文本中是否出现, 而忽略词在文本中的频率信息。词在文本中出现具有一定的不确定性。当词在文本间分布不均匀时, 表示词能够表达的信息较多。若词在部分文本中大量出现, 则表示该词具有代表性, 区分文本能力越强, 全局权重应当越高; 反之, 若词在大部分文本中均匀出现, 则表示该词不具有代表性, 区分文本能力越弱, 全局权重应当越低。这种不均匀性可以用特征词的信息熵度量。信息熵是信息论中重要的概念, 用来度量信息的不确定程度。词wi的信息熵E(i)的计算如公式(5)[23]所示。
$E(i)=-\sum\nolimits_{{{d}_{j}}}{\frac{tf(i,j)}{tf(i)}\times {{\log }_{2}}\frac{tf(i,j)}{tf(i)}}$ (5)
其中,$tf(i,j)$表示在文档dj中词语wi的频次,$tf(i)$表示词wi在文本集中出现的总频次。当词只出现在单个文本中时, 它的区分力最大, 信息熵E(i)最小, 为0。当特征词在所有文本中均匀分布时, 它的区分力最小, 而信息熵E(i)达到最大值Emax。通过归一化处理, 得到基于信息熵的全局词权重。本文对信息熵进行归一化处理, 提出基于信息熵的全局词权重, 其计算如公式(6)所示。显然有0≤GWE (i)≤1.0。
$G{{W}_{E}}(i)=1-\frac{E(i)}{{{E}_{\max }}+0.01}$ (6)
(1) 基本专利主题模型
LDA(Latent Dirichlet Allocation)模型[24]是一种常用的主题模型, 由于其参数简单, 不产生过拟合现象, 逐渐成为主题模型的研究热点。因此本文使用LDA模型对专利文本进行建模。LDA是一个三层贝叶斯概率模型, 由词、主题和文本三层构成。该模型假设每个文本包含若干隐含主题, 每个主题包含特定的词。文本和词间的关系通过隐含主题体现。隐含主题之间是相互独立的, 这些主题被文本集中所有文本共享, 而每个文本有一个特定的主题分布。模型通常采用Gibbs采样方法估计主题的后验分布, 计算如公式(7)[25]所示。
$p({{z}_{ij}}=k|{{z}^{_{-ij}}},w,\alpha ,\beta \propto \frac{n_{i(\cdot )k}^{-ij}+\beta }{n_{(\cdot )(\cdot )k}^{-ij}+V\beta }\times \frac{n_{(\cdot )jk}^{-ij}+\alpha }{n_{(\cdot )j(\cdot )}^{-ij}+K\alpha }$(7)
其中, zij表示文本dj中词wi的主题变量; -ij表示排除文本dj中的词wi; nijk表示文档dj中的词wi分配给主题k的次数; (·)表示对应维度(词语、文本、主题)所有次数之和, β表示词的Dirichlet先验分布, $\alpha $表示主题的Dirichlet先验分布, K表示主题数, V表示集合中总的词语数。一旦获得每个文本中每个词的主题, 就可以得到LDA模型中θ和φ的后验估计值, 计算如公式(8)[25]和公式(9)[25]所示。
${{\theta }_{jk}}=\frac{{{n}_{(\cdot )jk}}+\alpha }{{{n}_{(\cdot )j(\cdot )}}+K\alpha }$ (8)
${{\varphi }_{ki}}=\frac{{{n}_{i(\cdot )k}}+\beta }{{{n}_{(\cdot )(\cdot )k}}+V\beta }$ (9)
其中, θjk表示文本dj包含主题k的概率; φki表示主题k中词语wi的概率。
由此可见, Gibbs采样的基本思想是利用已经采样得到的所有主题在词上的分布和文本在主题上的分布推断当前采样词所属的主题, 反复迭代得到所有隐变量的过程。分配一个词到一个主题受两个概率影响: 一个是词在主题中的概率, 另一个是词所在文本拥有的主题概率。由于高频词在主题和文本中所占的比例都比较大, 从而导致主题的分配向高频词主题倾斜。
(2) 加权专利文本主题模型
主题模型同等地对待每个词, 假设每个词都是同等重要的。然而, 无论是从信息论还是从语言学来看, 该假设与现实并不吻合。因此, 将3.1节计算得到的词权重与Gibbs采样公式相结合, 给不同的词分配不同的权重, 改变生成模型生成词的概率, 使得Gibbs 采样公式变为公式(10)。
$\begin{align} & p({{z}_{ij}}=k|{{z}^{_{-ij}}},\alpha ,\beta \\ & \propto \frac{\sum\nolimits_{j=1}^{M}{W(i,j)n_{ijk}^{-ij}}+\beta }{\sum\nolimits_{i=1}^{V}{\sum\nolimits_{j=1}^{M}{W(i,j)n_{ijk}^{-ij}}}+V\beta }\times \frac{\sum\nolimits_{i=1}^{V}{W(i,j)n_{ijk}^{-ij}}+\alpha }{\sum\nolimits_{k=1}^{K}{\sum\nolimits_{i=1}^{V}{W(i,j)n_{ijk}^{-ij}}}+K\alpha } \\ \end{align}$ (10)
因此, 整个模型的文档-主题分布θ和主题-词汇分布φ分别如公式(11)和公式(12)所示。
${{\theta }_{jk}}=\frac{\sum\nolimits_{i=1}^{V}{W(i,j)}{{n}_{ijk}}+\alpha }{\sum\nolimits_{k=1}^{K}{\sum\nolimits_{i=1}^{V}{W(i,j){{n}_{ijk}}}}+K\alpha }$ (11)
${{\varphi }_{ki}}=\frac{\sum\nolimits_{j=1}^{M}{W(i,j){{n}_{ijk}}}+\beta }{\sum\nolimits_{i=1}^{V}{\sum\nolimits_{j=1}^{M}{W(i,j){{n}_{ijk}}}}+V\beta }$ (12)
此时, 专利主题模型不再仅仅是根据词出现频次累加1的nijk值, 而是累加词权重W(i, j)。通过这种方法, 可以降低专利文本中意义不大的词的贡献, 从而提高专利主题之间的区分度。
为了验证该模型的有效性, 分别选取3D打印与智能语音相关专利文本进行实验。3D打印是一项新兴制造技术, 其在某种程度上颠覆了传统制造业的生产方式, 带来制造业数字化和智能化的革命, 因而受到各国学术界和产业界的广泛关注, 在近年来取得快速发展。智能语音是人机交互模式的新选择。借助于移动互联网、机器学习领域中深度学习技术以及大数据语料库的积累, 智能语音技术的实用化发展突飞猛进, 在电信、金融、汽车电子、家电、教育、玩具、智能手机、移动互联网等领域已得到广泛应用。
本文选取中国国家知识产权局专利数据库, 分别以“3D打印 or 快速成型 or 增材制造 or 三维打印 or 增量制造 or 添加制造 or 智能制造 or 数字化制造”和“智能语音 or 语音识别 or 语音合成 or 自然语言理解 or 语音交互 or 语音技术 or 语音控制”作为检索式, 检索2013年1月1日至2017年8月1日(检索日期)相关专利文献。通过数据清洗、去重后, 最终分别将7 790条3D打印、5 272条智能语音发明公开专利标题和摘要作为待分析的专利文本。
采用中国科学院计算技术研究所的ICTCLAS分词系统进行分词, 采用哈尔滨工业大学的停用词表对专利文本进行停用词筛选。在LDA建模过程中, 参数估计采用Gibbs采样算法。根据经验设置$\alpha =50\text{/K}$、β=0.01, Gibbs采样迭代次数为2 000, 保存迭代参数为1 000。主题数K的选取通过计算基本专利主题模型(3.2节)的困惑度选取最优值, 采用五折交叉验证。根据计算, 实验设定3D打印数据集的主题数K=15、智能语音数据集的主题数K=10。
实验借助主题与主题的平均KL(Kullback-Leribler)距离定量描述主题的区分性。KL距离常用来衡量两个概率分布的距离。平均KL距离avg_KL的定义如公式(13)所示。
$avg\_KL=\frac{\sum\nolimits_{i=1}^{K}{\sum\nolimits_{j=1}^{K}{KL({{\varphi }_{i}}||{{\varphi }_{j}})}}}{{{K}^{2}}}$ (13)
其中, $\text{KL}({{\varphi }_{i}}||{{\varphi }_{j}})=\sum\nolimits_{v=1}^{V}{{{\varphi }_{iv}}\log \frac{{{\varphi }_{iv}}}{{{\varphi }_{jv}}}}$。由于KL距离是不对称的, 但是${{\varphi }_{i}}$和${{\varphi }_{j}}$相似性度量是对称的, 故将公式进行调整, 采用对称的Jensen-Shannon距离度量两个主题词分布的相似性, 具体计算如公式(14)所示。
$JS({{\varphi }_{i}},{{\varphi }_{j}})=\frac{KL({{\varphi }_{i}},{{\varphi }_{j}})+KL({{\varphi }_{j}},{{\varphi }_{i}})}{2}$ (14)
此时, avg_KL值越大, 表明主题与主题之间的距离越远, 主题的可区分性越高。
(1) 加权算法对比
为了比较提出的加权主题模型在专利文本分析中的有效性, 本文对专利文本进行预处理, 即, 分词和移除停用词后, 分别采用如下LDA模型进行比较:
①LDA: 不考虑权重的LDA模型;
②TF-IDF-LDA: 局部权重使用TF方法LWTF, 全局权重使用IDF方法GWIDF;
③P-IDF-LDA: 局部权重使用位置感知的方法LWP, 全局权重采用IDF方法GWIDF;
④TF-E-LDA: 局部权重使用TF方法LWTF, 全局权重采用基于信息熵的词加权策略GWE;
⑤P-E-LDA: 局部权重采用位置感知词权重LWP, 全局权重采用基于信息熵词的加权策略GWE。
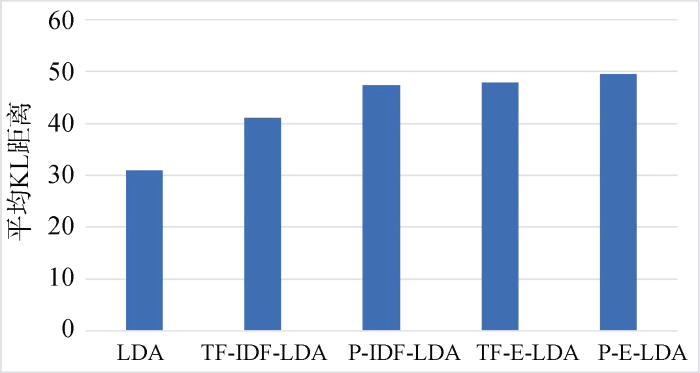
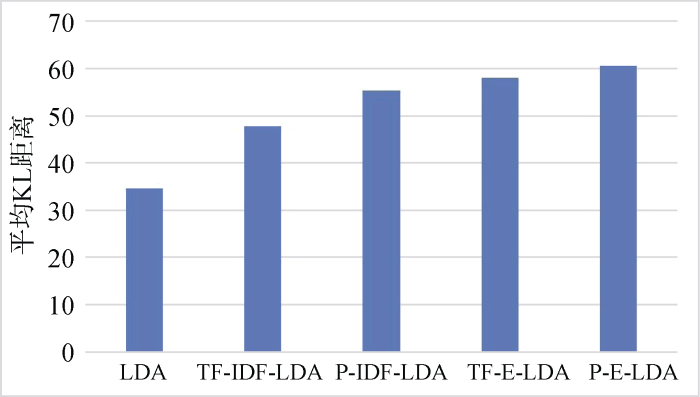
实验中分别使用上述5种方式生成的主题模型。实验结果如图2和图3所示。
图1和图2显示, 在3D打印专利文本和智能语音专利文本主题建模中, 使用4种词权重的LDA方法(TF-IDF-LDA、P-IDF-LDA、TF-E-LDA、P-E-LDA)得到的平均KL距离均高于标准的LDA模型。这表明使用合适的加权策略比不采用加权策略的主题模型能够更好地区分主题。这是由于词权重能够将不同贡献的词区分对待, 从而提升主题建模效果。在4种词加权主题建模方法中, P-IDF-LDA、TF-E-LDA、P-E-LDA模型主题间的平均KL距离均高于TF-IDF-LDA模型, 特别地, P-E-LDA模型取得了最高平均KL距离。这表明使用信息熵方法优于IDF权重方法, 能够更好地区分词语的全局权重, 同时考虑词在专利文本中的位置, 优于词频局部权重方法, 能够进一步提高主题的建模效果, 获得更好的主题区分能力, 使得各个主题更具有代表性和区分性。
为了直观比较加权方法的主题分布, 分别给出使用传统LDA和P-E-LDA模型在3D打印专利文本和在智能语音专利文本模型每个主题中的前5个词分布。结果如表1和表2所示。可见, 在LDA主题模型中, 常出现一些表意性较差的词(用粗体表示), 如“发明”、“包括”、“技术”、“方法”等。相比于传统LDA方法, P-E-LDA模型通过降低这些词的权重, 从而区分不同的主题, 使得主题一致性较强, 更易于理解。
表1 LDA与P-E-LDA在3D打印专利文本中主题词比较
| 主题 | LDA | P-E-LDA |
|---|---|---|
| 0 | 装置 控制系统 单元 打印机 发明 | 喷头 材料 打印机 喷嘴 连接 |
| 1 | 喷头 加热 打印机 装置 基础 | 原料 食品 食物 奶油 香气 |
| 2 | 结构 形成 发明 具有 电极 | 定位 固定 患者 手术 牙 |
| 3 | 机构 安装 打印机 平台 移动 | 电极 基板 导电 芯片 柔性 |
| 4 | 支架 生物 发明 修复 组织 | 驱动 平台 组件 安装 电机 |
| 5 | 制备材料 方法 复合材料 混合 应用 | 支架 生物 修复 多孔 细胞 |
| 6 | 模块 打印机 包括 系统 发明 | 模具 部件 主体 内部 墙体 |
| 7 | 发明 技术 3D 领域 涉及 | 工艺 外壳 处理 彩色 混凝土 |
| 8 | 金属 粉末 方法 激光 制备 | 打印机 模块 单元 装置 检测 |
| 9 | 打印 3D 发明 材料 方法 | 复合材料 混合 纳米 碳纤维 聚合物 |
| 10 | 成型 固化 树脂 材料 发明 | 三维 模型 数据 图像 信息 |
| 11 | 连接 固定 结构 设置 包括 | 金属 粉末 激光 成型 合金 |
| 12 | 三维 模型 方法 数据 扫描 | 快速 机械 机器人 原材料 焊接 |
| 13 | 制造 方法 加工 工艺 模具 | 材料 重量 原料 强度 塑料 |
| 14 | 材料 重量 原料 强度 发明 | 装置 成型 固化 树脂 打印机 |
表2 LDA与P-E-LDA在智能语音专利文本中主题词比较
| 主题 | LDA | P-E-LDA |
|---|---|---|
| 0 | 发明 技术 状态 问题 自动 | 音频 文本 网络视频 字幕 转换 |
| 1 | 交互 机器人 图像 视频 发明 | 模型 特征 参数 训练 神经网络 |
| 2 | 方法 语音 检测 环境 发明 | 输入 检测 通话模式 电子设备 |
| 3 | 模块 语音 技术 系统 计算机 | 装置 开关 电机 壳体 显示屏 |
| 4 | 装置 语音 输入 输出 显示 | 信号 指令 控制系统 智能家居 |
| 5 | 信息 用户 语音 方法 获取 | 输出 传感器 处理器 蓝牙 报警 |
| 6 | 本体 智能 发明 设置 电机 | 导航 车辆 车载 汉语 外语 |
| 7 | 文本 方法 内容 文字 文件 | 语义 数据库 翻译 搜索 关键词 |
| 8 | 模型 特征 方法 合成 语言 | 客户端 移动 服务器 匹配 云端 |
| 9 | 语音 方法 实施 发明 电子设备 | 机器人 交互 智能终端 摄像头 语音系统 |
(2) 保留停用词
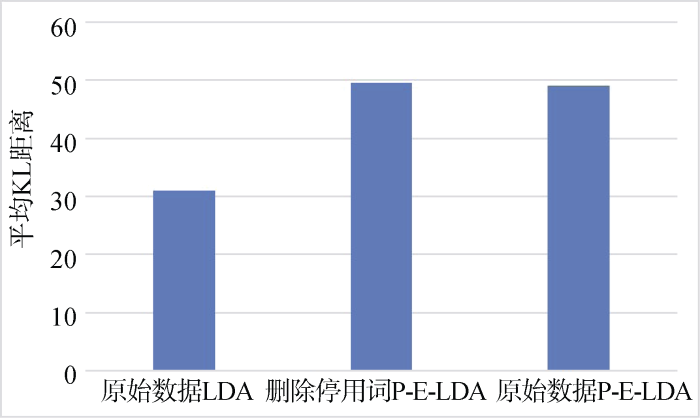
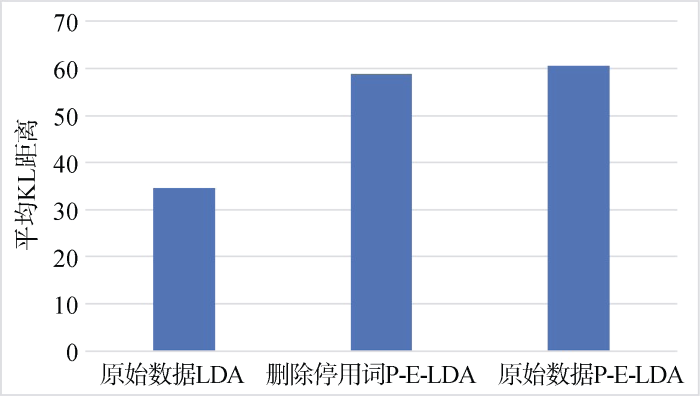
实验进一步地比较删除停用词和保留停用词情况下的P-E-LDA模型的主题区分能力。仍然采用上述3D打印、智能语音专利文本。实验环境与前面相同, 并将传统LDA在不去除停用词的原始数据上的结果作为参照。实验结果如图4和图5所示。
图4、图5表明在两个数据集的实验中, 在不删除停用词使用原始数据情况下进行P-E词加权主题建模, 主题间平均KL距离得到了和删除停用词相似的结果, 这表明即使在预处理步骤中不删除停用词, 通过P-E-LDA加权主题模型, 降低了高频词在各个主题中高概率的分布影响, 也能得到较好的性能, 使得各主题更具代表性和可区分性。
表3列出3D打印和智能语音数据集前10个高频词, 其中停用词使用粗体表示。
表4、表5分别列出基本LDA模型和P-E-LDA模型在不删除停用词的原始数据集上每个主题的前5个词分布。可见, 由于数据集没有去除停用词, LDA模型生成的主题中的前5个词中包含一些高频停用词(使用粗体表示), 造成主题之间语义区分度低; 而P-E-LDA模型能够根据词在专利文本中的重要性赋予词不同的权重, 使得P-E-LDA在原始数据上生成的主题中的前5个词并没有出现停用词, 从而获得较好的区分度。
表4 LDA与P-E-LDA在原始3D打印专利文本中主题词比较
| 主题 | LDA | P-E-LDA |
|---|---|---|
| 0 | 制备 方法 将 材料 的 | 支架 模具 生物 修复 纤维 |
| 1 | 的 打印 发明 本 技术 了 | 机构 平台 组件 驱动 电机 |
| 2 | 的 与 和 本 定位 | 装置 三维 系统 打印设备 部件 |
| 3 | 三维 模型 的 进行 对 | 电极 导电 成型 冷却 沉积 |
| 4 | 的 支架 和 本 发明 | 复合材料 石墨 改性 塑料 强度 |
| 5 | 的 金属 激光 粉末 方法 | 打印机 控制 检测 温度 传感器 |
| 6 | 的 有 装置 喷头 与 | 定位 骨 牙 手术 移植 |
| 7 | 的 了 一 本 发明 | 激光 制造 加工 零件 工艺 |
| 8 | 装置 系统 打印机 模块 的 | 结构 表面 外壳 主体 填充 |
| 9 | 打印 3D 的 成型 固化 打印机 | 金属 粉末 陶瓷 合金 混合 |
| 10 | 的 层 结构 在 一 表面 | 数据 图像 扫描 信息 区域 |
| 11 | 机构 轴 装置 在 安装 | 组合 生产 快速 制品 搅拌 |
| 12 | 材料 重量 3D 种 及其 | 喷头 加热 喷嘴 壳体 进料 |
| 13 | 一 的 和 包括 于 | 树脂 固化 基板 光敏 柔性 |
| 14 | 的 用于 该 在 或 | 连接 固定 支撑 设置 底板 |
表5 LDA与P-E-LDA在原始智能语音专利文本中主题词比较
| 主题 | LDA | P-E-LDA |
|---|---|---|
| 0 | 语音 识别 一 信号 第 | 指令 终端 操作 移动 命令 |
| 1 | 模块 控制 与 连接 和 | 特征 模型 合成 提取 语言 |
| 2 | 的 设置 有 一 在 | 技术 领域 计算机 汉语 方案 |
| 3 | 的 方法 特征 模型 进行 | 信号 输入 处理 音频 输出 |
| 4 | 的 语音 装置 一 包括 | 文本 内容 生成 匹配 文字 |
| 5 | 的 设备 在 该 用于 | 单元 交互 机器人 显示 图像 |
| 6 | 信息 的 方法 数据 用户 | 连接 电路 无线 控制器 传感器 |
| 7 | 的 模块 语音 系统 本 | 数据 检测 步骤 判断 存储 |
| 8 | 语音 控制 的 指令 用户 | 服务器 智能 网络 手机 通话 |
| 9 | 系统 的 智能 和 本 | 设置 智能 开关 安装 本体 |
本文针对专利文本分析中主题模型学习得到的主题分布向高频词倾斜, 使得主题间区分度低的问题, 提出词权重计算方法, 并将该词权重融入传统的主题模型, 形成加权主题模型。实验表明通过该方法可以有效地提高中文专利文本分析中主题模型的主题间的区分度, 从而更好地表示中文专利文本的语义信息。在将来的工作中, 尝试将加权专利文本主题模型应用于英文专利之中, 以提高英文专利文本主题模型的主题区分度, 更好地表示英文专利文本的语义信息。
俞琰: 设计并实现算法, 采集数据, 撰写论文;
赵乃瑄: 提供研究思路, 分析实验结果, 修改论文。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: yuyanyuyan2004@126.com。
[1] 俞琰. 3D打印专利文本集.xls. 测试数据.
[2] 俞琰. 智能语音专利文本集.xls. 测试数据.
[3] 俞琰. 哈尔滨工业大学停用词表.txt. 预处理数据.
[4] 俞琰. 实验结果对比.xls. 实验运行结果数据.
| [1] |
A Text-mining-based Patent Network: Analytical Tool for High-technology Trend [J].https://doi.org/10.1016/j.hitech.2003.09.003 URL [本文引用: 1] 摘要
Patent documents are an ample source of technical and commercial knowledge and, thus, patent analysis has long been considered a useful vehicle for R&D management and technoeconomic analysis. In terms of techniques for patent analysis, citation analysis has been the most frequently adopted tool. In this research, we note that citation analysis is subject to some crucial drawbacks and propose a network-based analysis, an alternative method for citation analysis. By using an illustrative data set, the overall process of developing patent network is described. Furthermore, such new indexes as technology centrality index, technology cycle index, and technology keyword clusters are suggested for in-depth quantitative analysis. Although network analysis shares some commonality with conventional citation analysis, its relative advantage is substantial. It shows the overall relationship among patents as a visual network. In addition, the proposed method provides richer information and thus enables deeper analysis since it takes more diverse keywords into account and produces more meaningful indexes. These visuals and indexes can be used in analyzing up-to-date trends of high technologies and identifying promising avenues for new product development.
|
| [2] |
基于领域知识的专利自动分类 [J].https://doi.org/10.3969/j.issn.1000-3428.2005.23.019 URL [本文引用: 1] 摘要
根据改进的词语权重计算方法构造给定文本的特征向量,并用之从专利分类的领域知识――国际分类表IPC中直接提取类别的概念向量和待分类专利文本的特征向量,然后采用向量空间模型实现专利的自动分类,该方法不需要大量的训练样本,具有较高的分类正确率和执行速度.
A Patent Classification Method Based on Domain Knowledge [J].https://doi.org/10.3969/j.issn.1000-3428.2005.23.019 URL [本文引用: 1] 摘要
根据改进的词语权重计算方法构造给定文本的特征向量,并用之从专利分类的领域知识――国际分类表IPC中直接提取类别的概念向量和待分类专利文本的特征向量,然后采用向量空间模型实现专利的自动分类,该方法不需要大量的训练样本,具有较高的分类正确率和执行速度.
|
| [3] |
Generating Patent Development Maps for Technology Monitoring Using Semantic Patent- Topic Analysis [J].https://doi.org/10.1016/j.cie.2016.06.006 URL [本文引用: 3] 摘要
The method consists of 1) collecting and preprocessing patents, 2) structuring each patent into a term vector, 3) identifying the technological taxonomies of patents by applying latent Dirichlet allocation, and 4) visualizing the development paths among patents through sensitivity analyses based on semantic patent similarities and citations. This method is illustrated using patents related to 3D printing technology. This method contributes to quantifying PDM generation and, in particular, will become a useful monitoring tool for effective understanding of the technologies including massive patents.
|
| [4] |
共现分析在专利地图中的应用研究 [J].https://doi.org/10.3969/j.issn.1008-0821.2009.07.011 URL [本文引用: 1] 摘要
本文对专利情报研究中的共现分析方法作了分类,将其分为共引、共词与共类分析3种。并结合专利地图分析探讨了3种分析方法的主要功能、作用及结果表现形式,通过制作专利地图,对3种共现分析所产生的结果作了解释,并对这3种共现分析方法的优缺点作了评述。
The Application Study of Co-occurrence Analysis in Patent Map [J].https://doi.org/10.3969/j.issn.1008-0821.2009.07.011 URL [本文引用: 1] 摘要
本文对专利情报研究中的共现分析方法作了分类,将其分为共引、共词与共类分析3种。并结合专利地图分析探讨了3种分析方法的主要功能、作用及结果表现形式,通过制作专利地图,对3种共现分析所产生的结果作了解释,并对这3种共现分析方法的优缺点作了评述。
|
| [5] |
基于专利共词分析的RFID领域技术主题研究 [J].Technology Topic in RFID Based on Patent Co-word Analysis [J]. |
| [6] |
PatentMiner: Topic-driven Patent Analysis and Mining [C]// |
| [7] |
Identifying Technological Topics and Institution-Topic Distribution Probability for Patent Competitive Intelligence Analysis: A Case Study in LTE Technology [J].https://doi.org/10.1007/s11192-014-1342-3 URL 摘要
An extended latent Dirichlet allocation (LDA) model is presented in this paper for patent competitive intelligence analysis. After part-of-speech tagging and defining the noun phrase extraction rules, technological words have been extracted from patent titles and abstracts. This allows us to go one step further and perform patent analysis at content level. Then LDA model is used for identifying underlying topic structures based on latent relationships of technological words extracted. This helped us to review research hot spots and directions in subclasses of patented technology in a certain field. For the extension of the traditional LDA model, another institution-topic probability level is added to the original LDA model. Direct competing enterprises distribution probability and their technological positions are identified in each topic. Then a case study is carried on within one of the core patented technology in next generation telecommunication technology-LTE. This empirical study reveals emerging hot spots of LTE technology, and finds that major companies in this field have been focused on different technological fields with different competitive positions.
|
| [8] |
A Fuzzy Approach for Measuring Development of Topics in Patents Using Latent Dirichlet Allocation [C]// |
| [9] |
Firms’ Knowledge Profiles: Mapping Patent Data with Unsupervised Learning [J].https://doi.org/10.1016/j.techfore.2016.09.028 URL 摘要
Patent data has been an obvious choice for analysis leading to strategic technology intelligence, yet, the recent proliferation of machine learning text analysis methods is changing the status of traditional patent data analysis methods and approaches. This article discusses the benefits and constraints of machine learning approaches in industry level patent analysis, and to this end offers a demonstration of unsupervised learning based analysis of the leading telecommunication firms between 2001 and 2014 based on about 160,000 USPTO full-text patents. Data were classified using full-text descriptions with Latent Dirichlet Allocation, and latent patterns emerging through the unsupervised learning process were modelled by company and year to create an overall view of patenting within the industry, and to forecast future trends. Our results demonstrate company-specific differences in their knowledge profiles, as well as show the evolution of the knowledge profiles of industry leaders from hardware to software focussed technology strategies. The results cast also light on the dynamics of emerging and declining knowledge areas in the telecommunication industry. Our results prompt a consideration of the current status of established approaches to patent landscaping, such as key-word or technology classifications and other approaches relying on semantic labelling, in the context of novel machine learning approaches. Finally, we discuss implications for policy makers, and, in particular, for strategic management in firms.
|
| [10] |
基于LDA模型的专利信息聚类技术 [J].URL 摘要
针对传统专利情报采集的方式不能适应专利信息快速增加的问题,通过研究适用于专利信息聚类的主题模型和聚类算法,提出了将潜在狄利克雷分配(LDA)主题模型和OPTICS算法相结合的解决方案。该方案采用LDA主题模型将专利信息在词汇空间的高维表达转换到在主题空间的低维表达,高效地实现了对专利信息的降维,进而采用OPTICS算法及k近邻准则对专利信息进行聚类分析,达到收集感兴趣的专利情报信息的目的。理论分析和实验验证表明,提出的解决方案不仅能通过降维,提高专利聚类效率,而且能对专利信息分析提供帮助。
Patent Information Clustering Technique Based on Latent Dirichlet Allocation Model [J].URL 摘要
针对传统专利情报采集的方式不能适应专利信息快速增加的问题,通过研究适用于专利信息聚类的主题模型和聚类算法,提出了将潜在狄利克雷分配(LDA)主题模型和OPTICS算法相结合的解决方案。该方案采用LDA主题模型将专利信息在词汇空间的高维表达转换到在主题空间的低维表达,高效地实现了对专利信息的降维,进而采用OPTICS算法及k近邻准则对专利信息进行聚类分析,达到收集感兴趣的专利情报信息的目的。理论分析和实验验证表明,提出的解决方案不仅能通过降维,提高专利聚类效率,而且能对专利信息分析提供帮助。
|
| [11] |
基于LDA主题模型的专利内容分析方法 [J].URL 摘要
主题模型是一种有效提取大规模文本隐含主题的建模方法。本文将Latent Dirichlet Allocation(LDA)主题模型引入专利内容分析领域,实现专利主题划分,解决以往专利主题分类过于粗泛、时效性差、缺乏科学性等问题。并在原有模型基础上构建LDA机构-主题模型,对专利知识主体和客体联合建模,实现专利主题和机构之间内在关系分析。最后,以通信产业LTE技术领域为例,验证该模型可以有效用于专利主题划分,实现各主题下专利知识主体竞争态势测度。
Patent Analysis Method Based on LDA Topic Model [J].URL 摘要
主题模型是一种有效提取大规模文本隐含主题的建模方法。本文将Latent Dirichlet Allocation(LDA)主题模型引入专利内容分析领域,实现专利主题划分,解决以往专利主题分类过于粗泛、时效性差、缺乏科学性等问题。并在原有模型基础上构建LDA机构-主题模型,对专利知识主体和客体联合建模,实现专利主题和机构之间内在关系分析。最后,以通信产业LTE技术领域为例,验证该模型可以有效用于专利主题划分,实现各主题下专利知识主体竞争态势测度。
|
| [12] |
基于AToT模型的技术主题多维动态演化分析——以石墨烯技术为例 [J].https://doi.org/10.13266/j.issn.0252-3116.2017.05.013 URL [本文引用: 1] 摘要
[目的 /意义]基于AToT模型的多维动态演化分析,不仅可以全面地了解技术主题的动态变化,把握不同时期不同企业的技术布局变化,还可以掌握产业链各环节的技术发展状态,为企业创新提供强有力的决策支持。[方法 /过程]首先提取专利文献摘要中的名词或者名词短语,然后利用AToT模型揭示专利文献中隐含的主题演化及专利权人的技术关注点,最后结合产业链信息把握产业各个环节的发展状况。[结果/结论]实验结果证明,该方法能够高效地分析专利的内容,揭示企业技术主题的动态演化过程。
Multi-dimension Dynamic Evolution Analysis of Technology Topics Based on AToT by Taking Graphene Technology as an Example [J].https://doi.org/10.13266/j.issn.0252-3116.2017.05.013 URL [本文引用: 1] 摘要
[目的 /意义]基于AToT模型的多维动态演化分析,不仅可以全面地了解技术主题的动态变化,把握不同时期不同企业的技术布局变化,还可以掌握产业链各环节的技术发展状态,为企业创新提供强有力的决策支持。[方法 /过程]首先提取专利文献摘要中的名词或者名词短语,然后利用AToT模型揭示专利文献中隐含的主题演化及专利权人的技术关注点,最后结合产业链信息把握产业各个环节的发展状况。[结果/结论]实验结果证明,该方法能够高效地分析专利的内容,揭示企业技术主题的动态演化过程。
|
| [13] |
基于LDA模型和分类号的专利技术演化研究 [J].
Research on Patent Technology Evolution Based on LDA Model and Classification Number [J].
|
| [14] |
层次主题模型在技术演化分析上的应用研究 [J].https://doi.org/10.13266/j.issn.0252-3116.2017.05.014 URL [本文引用: 1] 摘要
[目的/意义]采用hLDA从专利语料库中抽取层次主题,以描述隐藏在专利文本中的技术结构,并基于层次主题随时间变化情况进行技术演化分析。[方法/过程]从专利术语中获取闭频繁项集,并基于此建立关联规则网络来度量术语的重要性和术语间语义关系强弱,进而对语料库进行重构,并对不同时间片段的专利集合进行层次主题结构抽取。[结果/结论]将本方法应用于硬盘驱动器磁头领域的专利数据分析,实证结果表明该方法是一种可行和有效的技术演化分析方法。
Research on Application of Hierarchical Topic Model on Technological Evolution Analysis [J].https://doi.org/10.13266/j.issn.0252-3116.2017.05.014 URL [本文引用: 1] 摘要
[目的/意义]采用hLDA从专利语料库中抽取层次主题,以描述隐藏在专利文本中的技术结构,并基于层次主题随时间变化情况进行技术演化分析。[方法/过程]从专利术语中获取闭频繁项集,并基于此建立关联规则网络来度量术语的重要性和术语间语义关系强弱,进而对语料库进行重构,并对不同时间片段的专利集合进行层次主题结构抽取。[结果/结论]将本方法应用于硬盘驱动器磁头领域的专利数据分析,实证结果表明该方法是一种可行和有效的技术演化分析方法。
|
| [15] |
Topic Modeling: Beyond Bag-of-Words [C]// |
| [16] |
Term Weighting Schemes for Latent Dirichlet Allocation [C]// |
| [17] |
共现分析中的关键词选择与语义度量方法研究 [J].Research on Keyword Selection and Semantic Measurement of Co-word Analysis [J]. |
| [18] |
基于LDA模型和微博热度的热点挖掘 [J].https://doi.org/10.13266/j.issn.0252-3116.2014.05.010 URL [本文引用: 1] 摘要
分析传统LDA模型在进行微博热点挖掘时所得概率结果抽象且难以结合实际解释的缺点;考虑到微博本身的数据特点和信息论中信息量的观点,提出微博热度的概念,并将其引入到LDA模型的热点挖掘研究中,构建基于微博热度的LDA模型;通过API采集微博数据上的实验,证明新方法与旧方法具有相同的性能,而且能得到更直观的微博热度表,并得出更具有说服力的挖掘结论。
Hotspot Mining Based LDA Model and Microblog Heat [J].https://doi.org/10.13266/j.issn.0252-3116.2014.05.010 URL [本文引用: 1] 摘要
分析传统LDA模型在进行微博热点挖掘时所得概率结果抽象且难以结合实际解释的缺点;考虑到微博本身的数据特点和信息论中信息量的观点,提出微博热度的概念,并将其引入到LDA模型的热点挖掘研究中,构建基于微博热度的LDA模型;通过API采集微博数据上的实验,证明新方法与旧方法具有相同的性能,而且能得到更直观的微博热度表,并得出更具有说服力的挖掘结论。
|
| [19] |
一种基于加权LDA模型和多粒度的文本特征选择方法 [J].[本文引用: 1] 摘要
【目的】为改善图书和期刊书目信息的分类性能,结合书目文本的体例结构特点,提出一种基于加权LDA模型和多粒度的文本特征选择方法。【方法】在点互信息(PMI)模型的基础上,结合词性、位置等要素修正特征词的权重并扩展至LDA的生成模型中,以抽取表意性较强的粗粒度特征;结合TF-IDF计算模型采用一定策略获取细粒度特征,基于多粒度特征作为核心特征词集表征书目文本;采用KNN、SVM等算法实现书目文本的分类。【结果】在自建图书、期刊材料上进行分类实验,与LDA方法以及传统特征选择方法相比,该方法分类准确率分别平均提高3.60%和4.79%。【局限】实验材料的数量以及丰富度有待进一步扩展;需探索更多的加权策略模型进行实验,以提高书目文本的分类效果。【结论】实验结果表明,该方法是有效的、可行的,能够提高特征选择后的特征词集对文本的表示能力,从而提高文本分类的准确率。
A Text Feature Selection Method Based on Weighted Latent Dirichlet Allocation and Multi-granularity [J].[本文引用: 1] 摘要
【目的】为改善图书和期刊书目信息的分类性能,结合书目文本的体例结构特点,提出一种基于加权LDA模型和多粒度的文本特征选择方法。【方法】在点互信息(PMI)模型的基础上,结合词性、位置等要素修正特征词的权重并扩展至LDA的生成模型中,以抽取表意性较强的粗粒度特征;结合TF-IDF计算模型采用一定策略获取细粒度特征,基于多粒度特征作为核心特征词集表征书目文本;采用KNN、SVM等算法实现书目文本的分类。【结果】在自建图书、期刊材料上进行分类实验,与LDA方法以及传统特征选择方法相比,该方法分类准确率分别平均提高3.60%和4.79%。【局限】实验材料的数量以及丰富度有待进一步扩展;需探索更多的加权策略模型进行实验,以提高书目文本的分类效果。【结论】实验结果表明,该方法是有效的、可行的,能够提高特征选择后的特征词集对文本的表示能力,从而提高文本分类的准确率。
|
| [20] |
基于词加权LDA算法的无监督情感分类 [J].https://doi.org/10.11992/tis.201606007 URL [本文引用: 1] 摘要
主题情感混合模型可以有效地提取语料的主题信息和情感倾向.本文针对现有主题/情感分析方法主题间区分度较低的问题提出了一种词加权LDA算法(weighted latent dirichlet allocation algorithm,WLDA),该算法可以实现无监督的主题提取和情感分析.通过计算语料中词汇与情感种子词的距离,在吉布斯采样中对不同词汇赋予不同权重,利用每个主题下的关键词判断主题的情感倾向,进而得到每篇文档的情感分布.这种方法增强了具有情感倾向的词汇在米样过程中的影响,从而改善了主题间的区分性.实验表明,与JST(Joint Sentiment/Topicmodel)模型相比,WLDA不仅在采样中迭代速度快,也能够更好地实现主题提取和情感分类.
An Unsupervised Approach for Sentiment Classification Based on Weighted Latent Dirichlet Allocation [J].https://doi.org/10.11992/tis.201606007 URL [本文引用: 1] 摘要
主题情感混合模型可以有效地提取语料的主题信息和情感倾向.本文针对现有主题/情感分析方法主题间区分度较低的问题提出了一种词加权LDA算法(weighted latent dirichlet allocation algorithm,WLDA),该算法可以实现无监督的主题提取和情感分析.通过计算语料中词汇与情感种子词的距离,在吉布斯采样中对不同词汇赋予不同权重,利用每个主题下的关键词判断主题的情感倾向,进而得到每篇文档的情感分布.这种方法增强了具有情感倾向的词汇在米样过程中的影响,从而改善了主题间的区分性.实验表明,与JST(Joint Sentiment/Topicmodel)模型相比,WLDA不仅在采样中迭代速度快,也能够更好地实现主题提取和情感分类.
|
| [21] |
Identifying Topic-Specific Experts on Microblog [J].https://doi.org/10.3837/tiis.2016.06.010 URL [本文引用: 1] 摘要
With the rapid growth of microblog, expert identification on microblog has been playing a crucial role in many applications. While most previous expert identification studies only assess global authoritativeness of a user, there is no way to differentiate the authoritativeness in a particular aspect of topics. In this paper, we propose a novel model, which jointly models text and following relationship in the same generative process. Furthermore, we integrate a similarity-based weight scheme into the model to address the popular bias problem, and use followee topic distribution as prior information to make user"s topic distribution more precisely. Our empirical study on two large real-world datasets shows that our proposed model produces significantly higher quality results than the prior arts.
|
| [22] |
文本分类中TF-IDF方法的改进研究 [J].Improved TF-IDF Method in Text Classification [J]. |
| [23] |
VSM中词权重的信息熵算法 [J].https://doi.org/10.3969/j.issn.1000-0135.2000.04.012 URL [本文引用: 1] 摘要
本文提出一种基于Shannon信息熵的向量空间模型 (VSM )中的词权重算法。同时结合词与文献的相关权重的经典计算方法IDF(InverseDocumentFrequency) ,进一步总结了向量空间模型 (VSM)中两种词权重计算的具体公式。
A Shannon Entropy Approach to Term Weighting in VSM [J].https://doi.org/10.3969/j.issn.1000-0135.2000.04.012 URL [本文引用: 1] 摘要
本文提出一种基于Shannon信息熵的向量空间模型 (VSM )中的词权重算法。同时结合词与文献的相关权重的经典计算方法IDF(InverseDocumentFrequency) ,进一步总结了向量空间模型 (VSM)中两种词权重计算的具体公式。
|
| [24] |
Latent Dirichlet Allocation [J]. |
| [25] |
Finding Scientific Topics [J].https://doi.org/10.1073/pnas.0307752101 URL [本文引用: 3] |

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}