贾隆嘉 , 张邦佐
, 张邦佐
Jia Longjia, Zhang Bangzuo
中图分类号: TP391.1
通讯作者:
收稿日期: 2018-01-2
修回日期: 2018-04-3
网络出版日期: 2018-07-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】通过一种特征加权方法解决高校新浪微博主题分类研究所面临的高维性和稀疏性问题。【方法】计算特征属于类别的概率,进一步预测文档属于类别的概率,使得特征由基于词的表示转换为基于类别的表示,最终采用支持向量机对转换后的特征矩阵进行分类。【结果】传统tf, tf×idf以及tf×rf三种方法在结合本文提出的方法后,在微平均F1/宏平均F1方面分别提升:7.2%/7.8%,7.5%/7.9%以及6.4%/5.7%。【局限】仅针对主题分类中特征加权方法进行探索,未对主题分类中其他部分展开研究。【结论】在高校网路舆情主题分类中,该方法可以有效地降低特征矩阵维度,同时提升分类能力与分类效率。
关键词:
Abstract
[Objective] This paper introduces a term weighting method to classify topics of Sina Weibo posts by college students, aiming to solve the high dimension and sparsity issues. [Methods] First, we calculated the probability of a term’s falling to specific categories and then predicted the probability of a document’s category. Then, we converted the word-based features to a class-based matrix, which was classified by the support vector machine. [Results] Our new method increased the MicroF1/MacroF1values of the traditional tf, tf×idf and tf×rf methods by 7.2%/7.8%, 7.5%/7.9% and 6.4%/5.7%, respectively. [Limitations] More research is needed to explore topic classification methods other than the term weighting one in this paper. [Conclusions] The proposed method could effectively reduce the dimension of feature matrix and improve the classification efficiency for Internet public opinion studies.
Keywords:
互联网使得信息的传播速度以及规模达到了空前水平, 人们通过互联网表达政治诉求、参与政治生活以及对公共权力的监督越来越直接、快捷与公开化, 互联网成为网民表达民意、民情不可或缺的平台。根据中国互联网络信息中心(CNNIC)发布的《第40次中国互联网络发展状况统计报告》[1]显示, 截至2017年6月, 中国网民规模达到7.51亿, 占全球网民总数的五分之一。互联网普及率为54.3%, 超过全球平均水平4.6个百分点。2017年5月, 新浪微博发布使用新浪微博的学生群体用户高达5200万, 其中高度活跃用户占70%。学生队伍的不断扩大, 逐渐成为网络舆情传播的中坚力量, 学生在网上的声音也让政府能够快速直接地了解民情、民意以及社会的发展状况。高校群体既有较强的公民责任感, 又具备组织行动的天然优势, 遇到某些敏感热门话题, 极易激发他们的社会责任感和民族情怀, 进而引发大规模的网络舆情。因此, 面向高校网络舆情安全的分析研究具有广阔的应用前景以及较强的实用价值与现实意义。当前, 有较多关于网络舆情安全的研究主要有以下方面。
(1) 基于统计分析方法研究网络舆情安全。廖海涵等[2]利用从新浪微博采集到的用户发布数、评论数、转发数等信息特征, 借助数据的相关分析、偏相关分析、回归分析等方法研究用户行为关系。罗泰晔[3]基于Logistic模型建立预测模型, 并采用新浪微博实例证明该模型可以有效预测自组织状态下微博舆情热点的发展。
(2) 基于机器学习方法研究网络舆情热点预测。王亚民等[4]采用BTM建模, 结合改进的tf×idf特征加权算法, 对微博文本进行特征提取与相似性度量, 最终采用K-means聚类方法发现热点话题。胡悦等[5]通过改进的粒子群优化算法对模糊神经网络进行优化, 用于预测微博话题的发展趋势。
(3) 基于Hadoop平台研究网络舆情主题分类。作为网络舆情分析和主题追踪中的关键技术, 部分学者对网络舆情主题分类展开了研究。张宸等[6]利用Hadoop平台可并行处理分布式数据存储的优良特性, 在舆情主题分类方面提出HSVM_WNB分类算法。马宾等[7]为解决舆情获取耗时长问题, 利用Hadoop平台分布式数据存储与并行处理的优良特性, 改进朴素贝叶斯算法, 实现网络舆情主题快速分类。
对网络舆情信息进行主题分类对用户具有重要意义。一方面, 用户可以分门别类地查询和统计各类事件信息, 形成呈送简报;另一方面, 由于同一事件在网络上会有多篇不同新闻报道, 主题分类可以为用户判断不同来源的同一事件提供技术支持。当前研究人员对于舆情主题分类问题大多是采用向量空间模型表示方法, 特征加权一直是主题分类的瓶颈, 特征加权的效果直接影响分类器的分类性能。此外, 数据稀疏与数据高维也是当前网络舆情安全主题分类中所面临的主要问题[8]。传统的降维方法在数据维数较高时, 很难表现出好的分类效果[9]。因此, 针对高校网络舆情安全中主题分类问题, 亟需一种既可以为语料库中特征赋予恰当权重又可以降低特征矩阵维度的方法模型。为解决以上问题, 本文在分析传统特征加权算法与降维算法的基础上, 提出一种新的特征加权算法, 方法通过将基于词的特征转换为基于类别的特征, 使数据集的特征维度由原始成千上万维降低到与数据集的类别数相同的维度。使得特征表示矩阵不再是稀疏矩阵, 相比其他方法, 本文的方法不但可以提升主题分类的精度, 而且可以有效地提升分类速度、降低分类时间。
在向量空间模型中, 文档的内容被表示为特征空间中的一个向量。如$d=({{w}_{1}},{{w}_{2}},\ldots ,{{w}_{i}},\ldots ,{{w}_{k}})$, 其中d代表文档, k为训练集中的特征数目。不同的特征具有不同的重要性, wi代表第i个特征的权重。向量空间模型是当前主题分类领域中最常采用的文档表示模型。
本文针对向量空间模型, 提出一种基于类别信息的特征加权方法, 提出的方法不但可以解决主题分类中数据稀疏与数据高维的问题, 而且可以大幅度提高主题分类性能。由于特征矩阵的维度被急剧降低到与数据集中类别数目相同的维度, 因此在分类时可以显著提升分类速度、降低分类时间。
特征加权中常用符号及其含义: 给定一个特征t, N: 整个数据集中的文档数量; a: 在正类中包含特征t的文档数量; b: 在正类中不包含特征t的文档数量; c: 在负类中包含特征t的文档数量; d: 在负类中不包含特征t的文档数量。图1为在数据集中包含某个特征的文档数量分布示例。
基于上述符号, 简要介绍相关特征加权方法 如下。
(1) 词 频
词频(Term Frequency, tf)指在一篇文档中, 某一特征t出现的次数[10,11,12]。二进制表示是tf的一种特殊形式, 如公式(1)所示。
$tf=\left\{ \begin{matrix} 0,\ 当前特征在文档中未出现 \\ 1,\ 当前特征在文档中有出现 \\\end{matrix} \right. \quad \quad\quad\quad\quad\quad(1)$
(2) 逆文档频率
逆文档频率(Inverse Document Frequency,idf)主要思想是文档频率低的特征被认为比文档频率高的特征更重要[13,14,15]。具体计算方法如公式(2)所示。
$idf=\log \frac{N}{a+c}$ (2)
结合tf后, 构成的tf×idf特征加权如公式(3)所示。
$tf\times idf=tf\times \log \frac{N}{a+c}$ (3)
(3) 相关频率
相关频率(Relevance Frequency, rf)由兰曼等[16]在2005年提出, 如公式(4)所示。
$tf\times rf=tf\times \log (2+\frac{a}{\max (1,c)})$ (4)
(1) 研究背景及目的
在主题分类中, 特征加权的目标是为了提高分类器性能, 根据数据集中所有特征对分类结果所起到的作用, 为它们标记适当的权重。本文提出一种新的基于类别信息的特征加权方案, 称为“相关频率概率(Probability of Relevance Frequency, prf)”。提出方法的核心思想为: 相比在负类别中, 在正类别中分布越集中的特征, 它们对于将此正类与负类分开的能力就越强, 如Bi-Normal Separation(BNS)特征选择算法认为如果一个特征频繁出现在正类中, 则该特征拥有较多的正类信息; 特殊情况下, 如果一个特征仅仅出现在一个类中, 则该特征是一个能够明确代表该类的特 征[17]。基于上述思想, 通过将基于词的特征转换为基于类别的特征, 数据集的维数由原始成千上万可以急剧降低到与类别数相同的维度, 使得提出的方法相比原始特征加权方法不但在分类精度上有所提高, 而且可以大幅度提升分类速度。
(2) 算法实现
在本文提出的特征加权方法中, 定义了如下参数: ta: 在正类别文档中当前特征的权重和; tb: 在正类别文档中除了当前特征的其他特征的权重和; tc: 在负类别文档中当前特征的权重和; td: 在负类别文档中除了当前特征的其他特征的权重和。根据上述参数, 本文提出的“相关频率概率”如公式(5)所示。
$prf=\frac{ta}{ta+tc}$ (5)
如果特征在正类中相比在负类中越集中, 那么它们对于区分正类别与负类别所做出的贡献将会越大。换句话说, 如果一个特征对于某个类别有更高的权重值, 那么它将会对区分这个类别有更大的能力。
在公式(5)中, 特征对于某个类别的区分能力直接取决于在正类别文档中当前特征的权重和与数据集所有文档中当前特征的权重和之比, 这个比值也代表当前特征在整个数据集中属于此正类别的概率, 比值越大, 特征属于此类别的概率也就越大, 反之亦然。因此, 每个特征对于每一个类别都有相应的概率, 测试集中文档的类别是未知的, 在本研究中将训练集合中特征对应每一个类别的概率同等赋给测试集中的特征。
ta和tc不但可以代表原始词频, 在某种情况下它们也可以代表加权后的特征权重值。下面基于提出的加权方法prf, 以tf×idf_prf为例, 阐述ta和tc是的计算方法。
假设有训练集D={d1, d2, d3, d4}, 共计4条微博文档, 属于3个类别; 其中微博文档d1和d2属于类别c1, 微博文档d3属于类别c2, 微博文档d4属于类别c3。假设类别c1为当前的正类别, 类别c2、c3属于负类别。特征矩阵如公式(6)所示。
$D=\left[ \begin{matrix} {{w}_{11}} & {{w}_{12}} & ... & \begin{matrix} {{w}_{1j}} & ... & {{w}_{1n}} \\\end{matrix} \\ {{w}_{21}} & {{w}_{22}} & ... & \begin{matrix} {{w}_{2j}} & ... & {{w}_{2n}} \\\end{matrix} \\ {{w}_{31}} & {{w}_{32}} & ... & \begin{matrix} {{w}_{3j}} & ... & {{w}_{3n}} \\\end{matrix} \\ {{w}_{41}} & {{w}_{42}} & ... & \begin{matrix} {{w}_{4j}} & ... & {{w}_{4n}} \\\end{matrix} \\\end{matrix} \right]$ (6)
其中, wij代表特征tj在微博文档di中使用tf×idf特征加权方法获得的特征权重值。对于特征t1的ta和tc的值可以分别通过公式(7)和公式(8)计算。
$ta={{w}_{11}}+{{w}_{21}}$ (7)
$tc={{w}_{31}}+{{w}_{41}}$ (8)
文档包含特征, 特征决定文档所属的类别, 对于一个给定包含n个特征的微博文档d, 微博文档d属于第i个类别的概率(PDCi)被定义为公式(9)所示。
$PD{{C}_{i}}=\frac{1}{n}\sum\limits_{j=1}^{n}{pr{{f}_{ij}}}$ (9)
其中, n代表当前微博文档d包含的特征数量, i代表类别编号。文档包含特征, 特征对文档所属的类别及分类起决定作用, 根据特征j属于类别i的概率prfij, 可以得到当前文档d属于类别i的概率。假设数据集中有m个类别, 通过公式(9)计算后, 每一条文档将有m个与之对应的PDC值, 即分别代表当前文档属于某个类别的概率; m个PDC值构成的向量, 表示文档在特征空间中的概率分布。将所有prfij值加和后的结果对n求平均, 主要原因是为了消除文档长度对结果的影响, 最终文档d属于第i个类别的概率值将由此文档包含的所有特征共同决定, 即遍历每一个特征属于第i个类别的概率值, 将所有值求和后, 除以特征数n所得到的最终结果, 则代表此文档属于第i个类别的概率值。在本文提出的方法中, 将根据m个PDC值, 将文档表示为一维向量, 文档向量的表示方法被定义为公式(10)。
$\begin{align} & vector\_Document= \\ & \text{ (}PD{{C}_{\text{1}}}\text{,}PD{{C}_{\text{2}}}\text{,}...\text{,}PD{{C}_{\text{m-1}}}\text{,}PD{{C}_{\text{m}}}\text{)} \\ \end{align}$ (10)
其中, m代表数据集中的类别数。由此可以看出, 每一条文档被表示为m维向量(与类别数目相同), 相比原来的数据规模, 特征矩阵的维度被急剧降低。
本文提出的方法相比公式(3)和公式(4)主要有两个方面改进。
(1) 引入类别信息, 解决了因高频特征词所在文档不属于同一个类别时, 同样会被赋予较高权重的不足。
(2) 重新定义了特征权重的度量单元。即将基于词的特征转换为基于类别的特征, 使得在计算特征权重的过程中, 各个类别对于分类所起到的作用均被考虑到其中。与此同时, 数据集的特征维度被急剧降低, 解决了数据稀疏与数据高维问题。
本文提出的相关频率概率特征加权算法的描述如下所示。
输入:
fea_tf×idf: 经过加权的向量空间矩阵(这里以经tf×idf特征加权方法加权后的向量空间矩阵为例);
gnd: 向量空间矩阵中每一篇文档对应的类别标签列向量(gnd要求从1到x, x为正整数, 测试文档标签默认为-1);
trainIdx: 测试集编号(与gnd和fea_tf×idf对应);
输出:
fea_prf: 经prf特征加权算法加权后的向量空间矩阵;
①通过fea_tf×idf获得数据集中特征维数columnNum;
②通过gnd获得数据集文档数量documentNum及类别数量categoryNum;
③通过trainIdx获得训练集文档数trainNum;
④通过fea_tf×idf、gnd、trainIdx分别获得训练集特征矩阵feaTrain、训练集类别标签列向量gndTrain;
⑤for i = 1 to columnNum
for j = 1 to trainNum
ta (i,gndTrain(j)) = ta (i,gndTrain(j)) + feaTrain(j,i);
end for
end for
⑥for i = 1 to columnNum
for j = 1 to trainNum
ta_and_tc (i) = ta_and_tc (i)+ feaTrain(j,i);
end for
end for
⑦for i = 1 to columnNum
for j = 1 to categoryNum
prf(i,j) = ta (i, j) / ta_and_tc (i)
end for
end for
⑧for i = 1:documentNum
for j = 1:columnNum
for k = 1:categoryNum
PDC(i,k) = PDC(i,k) + prf (j,k)
end for
if(fea_tf×idf >0)
terms_numbers = terms_numbers + 1
end if
end for
for t= 1: categoryNum
PDC(i,t) = PDC(i,t) / terms_numbers
end for
terms_numbers = 0
end for
为了验证提出算法的有效性, 本文应用网络爬虫技术, 从新浪微博抓取50 000条高校微博文档数据。根据以下规则从源数据中抽取出具有分类价值的微博文档: 选取纯文本类型的微博文档; 选取大于120个字符的微博文档。通过这两条规则, 共筛选出29 093条微博文档。根据《2016年中国高校政务新媒体发展报告》, 校园学生发微博排在前10位的类型分别是: 休闲娱乐、人文艺术、科技科普、教育、交通服务、新闻资讯、读书写作、运动健身、公益、情感。实验中将以上10个类别作为目标类别, 采用以下方式对抽取到的数据进行标注: 对所有数据进行两次标注, 工作由4人完成, 将两次标注的结果逐一核对, 微博内容相同但是标注类别不同的文档需筛选出来, 进行单独讨论, 同时, 丢弃难以确认类别的微博文档。经过标注后的数据集共包含21 056条微博文档。本文数据分词采用NLPIR-ICTCLAS 2016系统①(①http://ictclas.nlpir.org/.), 并使用由“哈尔滨工业大学停用词词库”、“四川大学机器学习智能实验室停用词库”以及“百度停用词表”三个停用词词表构成的中文停用词词表②(②http://download.csdn.net/download/qq280929090/10034648.)(共1 598个停用词)去除助词、介词以及语气词等没有实际含义的词。
在分类中, 精确率和召回率仅可以度量分类器对单个类别的局部分类性能。当对分类器的全局分类性能评估时, 通常采用微平均值(Micro-average)和宏平均值(Macro-average)。在计算微平均和宏平均的时候, 首先需要依据每个类别的列联表(见表1)得到全局列联表, 如表2所示。
表2 全局列联表
| 类别集合 C={c1,c2,…ci,…c|c|} | 样本数据的实际情况 | ||
|---|---|---|---|
| 属于类别C | 不属于类别C | ||
| 分类器 预测结果 | 属于类别C | $TP=\sum\limits_{\text{i}=1}^{|C|}{T{{P}_{\text{i}}}}$ | $FP=\sum\limits_{\text{i}=1}^{|C|}{F{{P}_{\text{i}}}}$ |
| 不属于类别C | $FN=\sum\limits_{i=1}^{|C|}{F{{N}_{\text{i}}}}$ | $TN=\sum\limits_{i=1}^{|C|}{T{{N}_{\text{i}}}}$ | |
根据表2计算后的各项值, 微平均F1值与宏平均F1值计算如公式(11)-公式(16)所示。
$Micro\_p=\frac{\sum\limits_{i=1}^{|C|}{T{{P}_{i}}}}{\sum\nolimits_{i=1}^{|C|}{(T{{P}_{i}}+F{{P}_{i}})}}$ (11)
$Micro\_r=\frac{\sum\limits_{i=1}^{|C|}{T{{P}_{i}}}}{\sum\nolimits_{i=1}^{|C|}{(T{{P}_{i}}+F{{N}_{i}}})}$ (12)
$Micro{{F}_{1}}=\frac{2\times Micro\_p\times Micro\_r}{Micro\_p+Micro\_r}$ (13)
$Macro\_p=\frac{\text{1}}{\text{ }\!\!|\!\!\text{ }C\text{ }\!\!|\!\!\text{ }}\sum\limits_{i=1}^{|C|}{{{p}_{i}}}$ (14)
$Macro\_r=\frac{\text{1}}{\text{ }\!\!|\!\!\text{ }C\text{ }\!\!|\!\!\text{ }}\sum\limits_{i=1}^{|C|}{{{r}_{i}}}$ (15)
$Macro{{F}_{1}}=\frac{2\times macro\_p\times macro\_r}{macro\_p+macro\_r}$ (16)
其中, |C|代表训练集中类别的数量、p代表精确率、r代表召回率。
宏平均是每个类别性能指标的算术平均, 在度量宏平均时, 均等对待每个类别, 相比微平均值, 宏平均值的结果极易受到小样本类别的影响。微平均是各个文档性能指标的算术平均。微平均均等对待每一篇文档, 因此它的值主要受到数据集中文档数较多的类别影响。微平均F1值与宏平均F1值作为两个可以综合度量分类性能的评价指标, 在分类研究中被广泛应用[18,19,20]。
本文采用主题分类中较为常用并且性能较好的分类器: 支持向量机分类器。由于支持向量机采用结构风险最小化原则, 使其在分类的时候常常展现出较好的性能, Leopold和Kindermann[21]指出相比改变核函数, 应用特征加权方法可以有效地提高支持向量机的性能。一些文献也指出支持向量机的线性核函数性能优于非线性核函数[22]。此外, 考虑到实验数据的特征数目和样本数目都较大, 本文在使用支持向量机时选用线性核函数, 并且将其他参数设置为默认, 实验中采用LibSVM工具包[23]。
本文将分别使用tf、tf×idf、tf×rf三个特征加权方法, 以及与本文提出的主题分类特征加权方法prf结合后的tf_prf、tf×idf_prf、tf×rf_prf三个方法, 共6个特征加权方法在微平均F1值以及宏平均F1值两方面进行综合比较。
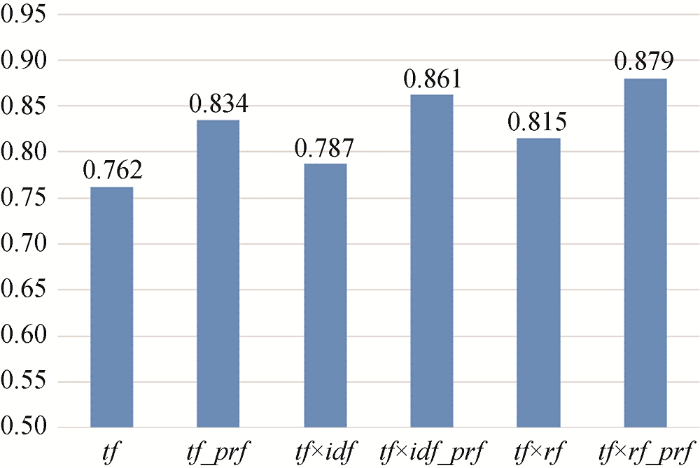
图2展示了采用6个特征加权方法与支持向量机分类器获得的微平均F1值结果; 图3展示了采用6个特征加权方法与支持向量机分类器获得的宏平均F1值结果。横轴代表不同的特征加权方法, 纵轴代表微平均或宏平均F1值。
通过观察6个特征加权方法取得的微平均F1值和宏平均F1值结果, 可以得到: tf和tf×idf两种特征加权方法取得的微平均F1值和宏平均F1值结果都是较差的, 主要是由于两种特征加权方法在计算的过程中, 没有度量特征的类别信息, 即没有根据特征所属的类别考虑特征在数据集中的分布情况, 并且它们的部分理论假设不符合实际情况: 方法单纯地认为词频高的特征和文档频率低的特征, 对于分类起到的作用就高, 文档频率高的特征对于分类起到的作用就低, 显然这并不是完全正确的。比如某些未被定义为停用词的对于分类不起作用并且词频较高的特征, 按照tf和tf×idf两种特征加权方法计算, 将会得到相对高的特征权重, 但这些特征对于分类结果是无用的, 甚至起到负面作用; 某些文档频率较高的特征, 假如特征所出现的文档属于同一个类别, 那么无论特征的文档频率有多高, 这类特征对于分类都有至关重要的作用, 然而依据tf×idf特征加权方法计算, 这类特征将不会被赋予相对高的权重。
相比tf和tf×idf, tf×rf特征加权方法取得了较好的分类结果, tf×rf在计算过程中考虑类别信息, 方法基于一个核心思想度量特征的分布情况: 在正类中分布越集中的特征对于分类所起到的作用就越高。由于实验数据的特殊性, 微博文档数据非常短, 同时数据量大, 使得数据集的特征矩阵极度稀疏, 导致tf×rf特征加权方法也未取得理想的结果。
本文提出的方法适用于此问题。从图2和图3的结果中可以看出, 与本文提出的prf方法结合后的特征加权方法(tf_prf, tf×idf_prf, tf×rf_prf ), 相比原始特征加权方法(tf,tf×idf, tf×rf )所获得的微平均F1值和宏平均F1值结果均有不同程度的提升。并且从结果中可以看出tf_prf和tf×idf_prf所取得的微平均F1值和宏平均F1值都高于tf×rf 特征加权方法所取得的结果, 说明prf方法可以适当地弥补tf和tf×idf 两个特征加权方法的不足, 也从侧面证明本文提出prf方法的有效性。
笔者提出的方法首先遍历数据集中的每一个特征, 计算各个特征的prf值, 即特征属于各个类别的概率值, 然后, 依次遍历各个类别, 对于每一条微博文档, 将所包含特征属于此类别的概率求和, 除以微博文档包含的特征数, 即代表该微博文档属于此类别的概率。依次遍历所有类别后, 即求得微博文档属于各个类别的概率值, 最后, 微博文档的表示由原始依据特征的表示, 转换为由该微博文档属于各个类别的概率值表示, 使得特征表示矩阵不再是稀疏矩阵。提出的prf方法计算特征权重时, 度量特征在数据集中分布情况的同时, 将基于词的特征转换为基于类别的特征, 与此同时, 没有产生因降维而丢失特征信息的情况, 从而可以有效地提升主题分类性能。
主题分类是高校网络舆情安全中的重要研究领域, 对于网络舆情倾向性分析和网络舆情话题检测与追踪有重要意义。本文提出的方法对于高校网络舆情主题分类中的特征加权问题效果明显, 创新点如下: 该方法可以通过将基于词的特征转换为基于类别的特征, 将数据集的特征维度由原始几万甚至几十万维降低到与数据集中类别数相同的维度, 解决了数据特征矩阵高维和稀疏问题。实验结果表明, 该方法可以获得较好的分类结果。提出的方法在一定程度上满足了网络舆情主题分类中特征加权及降维问题的现实需求, 可以为高校网络舆情分析提供一定的技术方法支持。然而, 高校网络舆情安全正处于探索阶段, 本文仅研究主题分类中特征加权及降维技术, 对于主题分类中其他相关步骤有待进一步研究。
贾隆嘉: 提出研究思路, 设计实验方案, 论文起草, 数据采集、清洗和分析数据;
张邦佐: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: jialongjia@nenu.edu.cn。
[1] 贾隆嘉. weibo21056.csv. 经过标注后的21 056条微博文档.
[2] 贾隆嘉. NLPIR-ICTCLAS2016.zip.NLPIR-ICTCLAS2016分词系统.
[3] 贾隆嘉.stopwords1598.txt.三个停用词词表构成的中文停用词词表.
[4] 贾隆嘉. prf.py.基于类别信息的特征加权算法实现程序.
| [1] |
第40次中国互联网络发展状况统计报告 [R/OL]. .The 40th Statistical Report on the Internet Development in China [R/OL]. |
| [2] |
网络舆情事件中微博用户行为特征和关系分析——以新浪微博“雾霾调查: 穹顶之下”为例 [J].https://doi.org/10.3969/j.issn.1002-0314.2016.03.002 URL [本文引用: 1] 摘要
文章在对社交媒体研究现状与重点及难点分析的基础上,选择以国内最具影响力的SNS网站新浪微博为研究平台,爬取与处理在微博平台上传播的有关舆情事件的关键字段信息,分析信息中所揭示舆情事件传播中的用户行为特征。并进一步从采集到的用户发布数、评论数、转发数等信息特征入手,借助数据的相关分析、偏相关分析、回归分析等方法研究用户行为关系。最后,提出具有一定参考价值的研究建议。
Analysis on the Characteristics and Relationships of Weibo Users’ Behaviors in Internet Public Opinion Incidents —— A Case Study of Sina Weibo Survey on Haze: Under Domes [J].https://doi.org/10.3969/j.issn.1002-0314.2016.03.002 URL [本文引用: 1] 摘要
文章在对社交媒体研究现状与重点及难点分析的基础上,选择以国内最具影响力的SNS网站新浪微博为研究平台,爬取与处理在微博平台上传播的有关舆情事件的关键字段信息,分析信息中所揭示舆情事件传播中的用户行为特征。并进一步从采集到的用户发布数、评论数、转发数等信息特征入手,借助数据的相关分析、偏相关分析、回归分析等方法研究用户行为关系。最后,提出具有一定参考价值的研究建议。
|
| [3] |
基于Logistic模型的微博舆情热点发展预测研究 [J].
微博是网络舆情的重要平台。微博舆情热点的发展一般经历发生、扩散、缓解、消退等阶段。相应地,在舆情规模上成"S"形走势。由此,建立基于Logistic模型的预测模型,并用新浪微博实例证明了该模型能够有效预测自组织状态下微博舆情热点的发展。
Study on the Prediction of Hotspot Development of Weibo Public Opinion Based on Logistic Model [J].
微博是网络舆情的重要平台。微博舆情热点的发展一般经历发生、扩散、缓解、消退等阶段。相应地,在舆情规模上成"S"形走势。由此,建立基于Logistic模型的预测模型,并用新浪微博实例证明了该模型能够有效预测自组织状态下微博舆情热点的发展。
|
| [4] |
基于BTM的微博舆情热点发现 [J].https://doi.org/10.3969/j.issn.1002-1965.2016.11.022 URL [本文引用: 1] 摘要
[目的/意义]作为一种新兴的社交新闻媒体,近年来,微博在许多热点事件的发布和传播中发挥了重要作用。但由于其文本的特殊性,传统方法不能有效地对其进行建模发现热点话题。因此,如何高效、准确地从微博数据中发现并提取有意义的热点信息是一个很有价值的研究课题。[方法/过程]提出一种基于BTM模型的微博舆情热点发现方法。首先,对微博文本采用BTM建模,改进TF-IDF权重计算算法,以适应微博短文本的特征。并将BTM建模结果与改进的TF-IDF权重算法结合对微博文本进行特征提取及相似性度量,然后采用K-means聚类方法发现热点话题。[结果/结论]通过对新浪微博数据集的对比实验及结果分析验证了本方法的有效性。本方法能够有效解决传统模型在文本建模中所面临的高维度和稀疏性问题,显著改善热点话题的发现质量。
Discovery of Public Opinion Hotspot in Weibo Based on BTM [J].https://doi.org/10.3969/j.issn.1002-1965.2016.11.022 URL [本文引用: 1] 摘要
[目的/意义]作为一种新兴的社交新闻媒体,近年来,微博在许多热点事件的发布和传播中发挥了重要作用。但由于其文本的特殊性,传统方法不能有效地对其进行建模发现热点话题。因此,如何高效、准确地从微博数据中发现并提取有意义的热点信息是一个很有价值的研究课题。[方法/过程]提出一种基于BTM模型的微博舆情热点发现方法。首先,对微博文本采用BTM建模,改进TF-IDF权重计算算法,以适应微博短文本的特征。并将BTM建模结果与改进的TF-IDF权重算法结合对微博文本进行特征提取及相似性度量,然后采用K-means聚类方法发现热点话题。[结果/结论]通过对新浪微博数据集的对比实验及结果分析验证了本方法的有效性。本方法能够有效解决传统模型在文本建模中所面临的高维度和稀疏性问题,显著改善热点话题的发现质量。
|
| [5] |
基于模糊神经网络的微博舆情趋势预测方法 [J].
【目的/意义】微博舆情对社会各领域的影响与日俱增,但由于其影响因素众多,呈现出非线性且复杂的变化。因此,如何快速、准确地预测其发展趋势是一个很有价值的研究课题。【方法/过程】以微博话题的博文总数作为微博话题发展趋势的量化指标,考虑话题发展的复杂性和非线性的特点,采用模糊神经网络来预测微博话题的发展趋势。并通过改进的粒子群优化算法对模糊神经网络的参数进行优化以更好的发挥模糊神经网络在处理非线性、模糊性等复杂问题上的优越性。【结果/结论】通过对新浪微博数据集的对比实验,验证了本文所提方法的有效性和准确性。本文方法有效解决了微博舆情趋势预测中遇到的模型参数复杂、易陷入局部最优的问题,提高了微博舆情发展趋势预测的准确性。
New Forecasting Method of Weibo Public Opinion Based on Fuzzy Neural Network [J].
【目的/意义】微博舆情对社会各领域的影响与日俱增,但由于其影响因素众多,呈现出非线性且复杂的变化。因此,如何快速、准确地预测其发展趋势是一个很有价值的研究课题。【方法/过程】以微博话题的博文总数作为微博话题发展趋势的量化指标,考虑话题发展的复杂性和非线性的特点,采用模糊神经网络来预测微博话题的发展趋势。并通过改进的粒子群优化算法对模糊神经网络的参数进行优化以更好的发挥模糊神经网络在处理非线性、模糊性等复杂问题上的优越性。【结果/结论】通过对新浪微博数据集的对比实验,验证了本文所提方法的有效性和准确性。本文方法有效解决了微博舆情趋势预测中遇到的模型参数复杂、易陷入局部最优的问题,提高了微博舆情发展趋势预测的准确性。
|
| [6] |
大数据环境下基于SVM-WNB的网络舆情分类研究 [J].https://doi.org/10.13546/j.cnki.tjyjc.2017.14.010 URL [本文引用: 1] 摘要
当前网络舆情信息存在数据量大、流动快及数据非结构化等特点,难以实现对其快速、准确的分类。SVM算法和朴素贝叶斯算法都是性能优秀的传统分类算法,但无法满足快速处理海量数据。文章利用Ha-doop平台可并行处理分布式数据存储的优良特性,提出了HSVM_WNB分类算法,将采集的舆情文档依照HDFS架构进行本地化存储,并通过MapReduce进程完成并行分类处理。最后利用实验验证,本算法能够有效提升网络舆情分类能力与分类效率。
Study on Network Public Opinion Classification Based on SVM-WNB in Big Data Environment [J].https://doi.org/10.13546/j.cnki.tjyjc.2017.14.010 URL [本文引用: 1] 摘要
当前网络舆情信息存在数据量大、流动快及数据非结构化等特点,难以实现对其快速、准确的分类。SVM算法和朴素贝叶斯算法都是性能优秀的传统分类算法,但无法满足快速处理海量数据。文章利用Ha-doop平台可并行处理分布式数据存储的优良特性,提出了HSVM_WNB分类算法,将采集的舆情文档依照HDFS架构进行本地化存储,并通过MapReduce进程完成并行分类处理。最后利用实验验证,本算法能够有效提升网络舆情分类能力与分类效率。
|
| [7] |
一种基于Hadoop平台的并行朴素贝叶斯网络舆情快速分类算法 [J].A Fast Classification Algorithm of Public Opinion Based on Parallel Naive Bayesian Network Based on Hadoop Platform [J]. |
| [8] |
突发公共事件网络舆情研究综述 [J].https://doi.org/10.13366/j.dik.2014.02.111 URL [本文引用: 1] 摘要
对突发公共事件网络舆情研究现状进行了较为详尽的回顾,目前有关突发公共事件网络舆情的研究点主要集中在网络舆情的相关概念、特点、影响因素、生命周期、网络舆情技术与系统和突发事件网络舆情的管理控制等方面,研究发现当前突发公共事件网络舆情面临以下问题和挑战:理论与实践有待进一步融合,缺乏量化分析的体系与框架,微观层面分析有待深入,缺少网民社会结构和群体行为研究,可视化展示和监测技术将大有作为。
Review of the Research on Internet Public Opinions of Public Emergencies [J].https://doi.org/10.13366/j.dik.2014.02.111 URL [本文引用: 1] 摘要
对突发公共事件网络舆情研究现状进行了较为详尽的回顾,目前有关突发公共事件网络舆情的研究点主要集中在网络舆情的相关概念、特点、影响因素、生命周期、网络舆情技术与系统和突发事件网络舆情的管理控制等方面,研究发现当前突发公共事件网络舆情面临以下问题和挑战:理论与实践有待进一步融合,缺乏量化分析的体系与框架,微观层面分析有待深入,缺少网民社会结构和群体行为研究,可视化展示和监测技术将大有作为。
|
| [9] |
An Improved Global Feature Selection Scheme for Text Classification [J].https://doi.org/10.1016/j.eswa.2015.08.050 URL [本文引用: 1] 摘要
Feature selection is known as a good solution to the high dimensionality of the feature space and mostly preferred feature selection methods for text classification are filter-based ones. In a common filter-based feature selection scheme, unique scores are assigned to features depending on their discriminative power and these features are sorted in descending order according to the scores. Then, the last step is to add top- N features to the feature set where N is generally an empirically determined number. In this paper, an improved global feature selection scheme (IGFSS) where the last step in a common feature selection scheme is modified in order to obtain a more representative feature set is proposed. Although feature set constructed by a common feature selection scheme successfully represents some of the classes, a number of classes may not be even represented. Consequently, IGFSS aims to improve the classification performance of global feature selection methods by creating a feature set representing all classes almost equally. For this purpose, a local feature selection method is used in IGFSS to label features according to their discriminative power on classes and these labels are used while producing the feature sets. Experimental results on well-known benchmark datasets with various classifiers indicate that IGFSS improves the performance of classification in terms of two widely-known metrics namely Micro-F1 and Macro-F1.
|
| [10] |
网络舆情观点主题识别研究 [J].A Study on Theme Recognition of Internet Public Opinion [J]. |
| [11] |
基于网络舆情分类的舆情应对研究 [J].https://doi.org/10.3969/j.issn.1002-1965.2013.05.001 URL [本文引用: 1] 摘要
正针对不同类型的网络舆情,政府相应的可采取以下5种应对策略:(1)"淡化式"网络舆情应对策略。先由事件主体自行处理,在适当时候介入,调停事件矛盾,有利于避免网络舆情过早、过多的给政府施加责任或将舆情指向转至政府。(2)"萌芽式"网络舆情应对策略。一是第一时间通报网络舆情,主动了解事件真相,协调有关部门处置;二是转入网络舆情监测工作,观察后续舆情动态和事件处置效果。(3)"强力式"
Research on Public Opinion Based on Internet Public Opinion Classification [J].https://doi.org/10.3969/j.issn.1002-1965.2013.05.001 URL [本文引用: 1] 摘要
正针对不同类型的网络舆情,政府相应的可采取以下5种应对策略:(1)"淡化式"网络舆情应对策略。先由事件主体自行处理,在适当时候介入,调停事件矛盾,有利于避免网络舆情过早、过多的给政府施加责任或将舆情指向转至政府。(2)"萌芽式"网络舆情应对策略。一是第一时间通报网络舆情,主动了解事件真相,协调有关部门处置;二是转入网络舆情监测工作,观察后续舆情动态和事件处置效果。(3)"强力式"
|
| [12] |
Developing a Successful SemEval Task in Sentiment Analysis of Twitter and Other Social Media Texts [J].https://doi.org/10.1007/s10579-015-9328-1 URL [本文引用: 1] |
| [13] |
基于改进的TF*IDF方法分析学科研究热点——以情报学为例 [J].Analysis of Discipline Research Hotspots Based on Improved TF×IDF Method —— A Case Study of Information Science [J]. |
| [14] |
A Bayesian Classification Approach Using Class-Specific Features for Text Categorization [J].https://doi.org/10.1109/TKDE.2016.2522427 URL [本文引用: 1] 摘要
In this paper, we present a Bayesian classification approach for automatic text categorization using class-specific features. Unlike conventional text categorization approaches, our proposed method selects a specific feature subset for each class. To apply these class-specific features for classification, we follow Baggenstoss's PDF Projection Theorem (PPT) to reconstruct the PDFs in raw data space from the class-specific PDFs in low-dimensional feature subspace, and build a Bayesian classification rule. One noticeable significance of our approach is that most feature selection criteria, such as Information Gain (IG) and Maximum Discrimination (MD), can be easily incorporated into our approach. We evaluate our method's classification performance on several real-world benchmarks, compared with the state-of-the-art feature selection approaches. The superior results demonstrate the effectiveness of the proposed approach and further indicate its wide potential applications in data mining.
|
| [15] |
Supervised and Traditional Term Weighting Methods for Automatic Text Categorization [J].https://doi.org/10.1109/TPAMI.2008.110 URL PMID: 19229086 [本文引用: 1] 摘要
In vector space model (VSM), text representation is the task of transforming the content of a textual document into a vector in the term space so that the document could be recognized and classified by a computer or a classifier. Different terms (i.e. words, phrases, or any other indexing units used to identify the contents of a text) have different importance in a text. The term weighting methods assign appropriate weights to the terms to improve the performance of text categorization. In this study, we investigate several widely-used unsupervised (traditional) and supervised term weighting methods on benchmark data collections in combination with SVM and kNN algorithms. In consideration of the distribution of relevant documents in the collection, we propose a new simple supervised term weighting method, i.e. tf.rf, to improve the terms' discriminating power for text categorization task. From the controlled experimental results, these supervised term weighting methods have mixed performance. Specifically, our proposed supervised term weighting method, tf.rf, has a consistently better performance than other term weighting methods while other supervised term weighting methods based on information theory or statistical metric perform the worst in all experiments. On the other hand, the popularly used tf.idf method has not shown a uniformly good performance in terms of different data sets.
|
| [16] |
Proposing a New Term Weighting Scheme for Text Categorization [C]// |
| [17] |
A Comparison of Event Models for Naive Bayes Text Classification [C]// |
| [18] |
基于支持向量机的网络伪舆情识别研究 [J].
针对网络伪舆情的识别问题,提出一种基于支持向量机的网络伪舆情识别方法。鉴于不同的舆情信息所反映出的舆情特征不同,而舆情特征的不同又可进一步辨别舆情的真假,因此首先构建针对网络舆情真伪的评价指标;基于支持向量机的分类机理,结合网络舆情的评价指标提出基于支持向量机的网络伪舆情识别模型,采用多项式核函数以及优化之后的径向基核函数产生的分类器。通过实验证明采用支持向量机构造舆情分类器所构建的识别算法能够对网络伪舆情进行有效识别。
Pseudo-publicaire Recognition Based on Support Vector Machine [J].
针对网络伪舆情的识别问题,提出一种基于支持向量机的网络伪舆情识别方法。鉴于不同的舆情信息所反映出的舆情特征不同,而舆情特征的不同又可进一步辨别舆情的真假,因此首先构建针对网络舆情真伪的评价指标;基于支持向量机的分类机理,结合网络舆情的评价指标提出基于支持向量机的网络伪舆情识别模型,采用多项式核函数以及优化之后的径向基核函数产生的分类器。通过实验证明采用支持向量机构造舆情分类器所构建的识别算法能够对网络伪舆情进行有效识别。
|
| [19] |
大数据环境下社会舆情分析与决策支持的研究视角和关键问题 [J].Study Perspective and Key Issues on Analysis and Decision Support of Social Sentiment in Big Data Environment [J]. |
| [20] |
Two Feature Weighting Approaches for Naive Bayes Text Classifiers [J].https://doi.org/10.1007/978-3-319-11179-7_70 URL [本文引用: 1] 摘要
Recent work in supervised learning has shown that naive Bayes text classifiers with strong assumptions of independence among features, such as multinomial naive Bayes (MNB), complement naive Bayes (CNB) and the one-versus-all-but-one model (OVA), have achieved remarkable classification performance. This fact raises the question of whether a naive Bayes text classifier with less restrictive assumptions can perform even better. Responding to this question, we firstly evaluate the correlation-based feature selection (CFS) approach in this paper and find that it performs even worse than the original versions. Then, we propose a CFS-based feature weighting approach to these naive Bayes text classifiers. We call our feature weighted versions FWMNB, FWCNB and FWOVA respectively. Our proposed approach weakens the strong assumptions of independence among features by weighting the correlated features. The experimental results on a large suite of benchmark datasets show that our feature weighted versions significantly outperform the original versions in terms of classification accuracy.
|
| [21] |
Projected-prototype Based Classifier for Text Categorization [J].https://doi.org/10.1016/j.knosys.2013.05.013 URL [本文引用: 1] 摘要
Currently, the explosive increasing of data stimulates a greater demand for text categorization. The existing prototype-based classifiers, including k -NN, k NNModel and Centroid classifier, are receiving wide interest from the text mining community because of their simplicity and efficiency. However, they usually perform less effectively on document data sets due to high dimensionality and complex class structures these sets involve. In most cases a single document category actually contains multiple subtopics, indicating that the documents in the same class may comprise multiple subclasses, each associated with its individual term subspace. In this paper, a novel projected-prototype based classifier is proposed for text categorization, in which a document category is represented by a set of prototypes, each assembling a representative for the documents in a subclass and its corresponding term subspace. In the classifier training process, the number of prototypes and the prototypes themselves are learned using a newly developed feature-weighting algorithm, in order to ensure that the documents belonging to different subclasses are separated as much as possible when projected onto their own subspaces. Then, in the testing process, each test document is classified in terms of its weighted distances from the different prototypes. Experimental results on the Reuters-21578 and 20-Newsgroups corpora show that the proposed classifier based on the multi-representative-dependent projection method can achieve higher classification accuracy at a lower computational cost than the conventional prototype-based classifiers, especially for data sets that include overlapping document categories.
|
| [22] |
Intelligent Fault Diagnosis Based on a Hybrid Multi-class Support Vector Machines and Case-based Reasoning Approach [J].https://doi.org/10.1166/jctn.2013.3116 URL [本文引用: 1] |
| [23] |
LIBSVM: A Library for Support Vector Machines [J]. |

/
| 〈 |
|
〉 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}