李杰 , 杨芳
, 杨芳
Li Jie, Yang Fang
中图分类号: TP311
通讯作者:
收稿日期: 2017-08-24
修回日期: 2018-02-10
网络出版日期: 2018-07-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】在电子商务个性化推荐中考虑商品销售的时间动态性和序列模式问题, 提高推荐效果。【方法】提出一种改进的个性化推荐算法: 引入时间系数和热门系数, 改进评分相似性函数, 提出新的用户兴趣相似度计算方法; 加入商品序列模式, 给出二项序列模式挖掘算法, 用序列模式对推荐结果进行筛选排序。【结果】利用2004年-2005年亚马逊图书评论数据进行测试, 与基于修正余弦的协同过滤算法相比较, 改进算法的推荐准确率和F值分别提高1.89%和0.73%。【局限】该算法没有考虑用户评价分数高低个人倾向的影响。【结论】改进的相似性函数和通过序列模式对结果进行筛选两个方面均能提高个性化推荐效果。
关键词:
Abstract
[Objective] This study is to improve the effectiveness of merchandise recommendation based on temporal dynamics and sequential patterns of sales. [Methods] We developed an improved personalized recommendation algorithm for electronic commerce. First, we introduced a new similarity calculation function with time and hot coefficients. Then, we proposed an algorithm with the two-item sequential pattern, which modified the recommended list based on the sequential patterns. [Results] We examined the new method with book review data of Amazon.com from 2004-2005, and found its precision and F values were 1.89% and 0.73% higher than the collaborative filtering algorithm with adjusted cosine similarity. [Limitations] The proposed model did not examine the violations of consumers’ review scores. [Conclusions] Both the similarity function and sequential patterns can improve the effectiveness of personalized recommendation algorithms for e-commerce.
Keywords:
个性化推荐是根据用户已有购买情况推测用户可能感兴趣的产品并向用户进行推荐[1]。个性化推荐系统提高了人们检索各种信息或产品的效率[2], 也提高了商品的点击率和转化率。但是, 现有个性化推荐算法的推荐效果不够理想, 也存在一些问题。例如, 没有充分考虑用户兴趣的动态变化、推荐不准确[3]。
在个性化推荐算法中, 应用最广泛的是协同过滤算法[4]。各大电子商务公司主要基于协同过滤算法进行改进, 从而给顾客推荐他们感兴趣的内容[5]。协同过滤算法是基于用户间的兴趣相似性进行推荐。现有算法虽然考虑了用户的多兴趣[6]、用户间的信任关系[7]、标签使用频率[8]、用户偏好与商品属性的匹配[9]等问题, 但忽视了用户兴趣在一定程度上会随着时间的迁移和商品的购买而发生复杂的变化。例如, 用户购买儿童玩具时, 其关注的玩具种类会随着孩子年龄的成长而发生变化。较近的购买更能反映用户近期的兴趣和需求[10]。另外, 不同种类的儿童玩具在购买热度以及商品购买先后关系序列上也有显著不同。例如, 用户购买过普通积木型玩具后很少重复多次购买, 而乐高拼插型玩具则通常能吸引用户多次购买。此外, 用户一旦购买了高年龄段的乐高小颗粒玩具, 便通常意味着对低年龄段的大颗粒产品不再关注, 这说明用户在购买商品时存在序列模式。因此, 区分已购商品的购买热度、挖掘商品的购买序列模式, 可避免向用户频繁推荐不再需要的商品。
本文重点考虑个性化推荐中的以下问题:
(1) 协同过滤算法中计算相似性时, 在时间上离现在越近的评分应该有越高的权重; 越陈旧的评分价值越小, 权重也应该降低。因此, 本文引入时间系数, 调整不同时间的评价作用的重要程度。
(2) 协同过滤算法中的余弦相似性系数只考虑向量的夹角而不考虑向量的长度, 造成与现实严重不一致的问题。例如当一个用户的向量是(1, 1, 1)时, 另一个用户向量是(5, 5, 5), 那么他们的向量夹角是0, 是完全相似的, 而现实含义恰恰相反。因此, 应该对用户评分相似性函数进行改进, 解决上述问题。
(3) 商品热度和季节性对推荐算法产生影响, 会降低满足用户个性化需求但非热门大众商品的推荐度。因此, 应该对商品热度进行调节, 减少商品热度的影响。
(4) 传统协同过滤算法没有考虑商品之间的序列模式。例如, 人们在购买程序设计类书籍时, 往往遵循从入门到中级再到高级的进阶过程, 从而形成序列模式。因此, 本文引入序列模式挖掘, 通过序列模式进一步优化推荐列表, 提高推荐效果。
针对上述问题, 本文提出一种综合考虑时间动态性、评分相似性、商品热度和需求序列模式的改进协同过滤推荐算法。根据用户的购买历史变化规律, 引入时间系数、评分系数和热度系数, 改进用户兴趣相似性函数, 并基于不同商品销售的先后顺序进行序列模式挖掘, 修正用户的推荐结果。最后, 通过大规模 的亚马逊图书销售评价数据, 验证上述两方面改进的效果。
推荐算法的好坏直接决定了整个推荐系统的优劣。协同过滤算法简单实用, 是电子商务领域应用最广泛的推荐系统[11]。协同过滤算法在不断改进数据稀缺性和冷启动问题[12,13]的同时, 其研究热点也从最初用户的单一兴趣[14]发展到多兴趣[6]以及用户需求的时间动态性变化研究[15]。
近年, 基于用户需求的时间动态性推荐算法研究已取得了一定成果。从时间变化测量的方式上可大致划分为三类:
(1) 以时间窗口方式, 设定需求随时间变化的 阶段性阈值, 从时间距离的角度对用户可参考的购买评价数据或需求变化函数进行分类, 以提高推荐准 确度[16,17];
(2) 借鉴心理学的记忆周期和遗忘规律, 模拟遗忘曲线函数作为时间衰减函数, 以修正用户评分随时间的变化[18];
(3) 运用线性函数和非线性函数度量时间对推荐的影响, 引入用户评分时间[19], 修正用户或项目相似性的计算[20], 使得距离当前时间越近的评分, 对预测项目的评分影响越大。
上述研究采用不同的时间函数在不同程度上提高了协同过滤算法的推荐准确度, 也充分说明基于时间变化的商品推荐比传统协同过滤推荐算法更符合用户兴趣变化的客观实际。然而, 现有文献在普遍关注兴趣随用户自身记忆遗忘、兴趣转移等因素变化的同时, 却鲜有文献研究商品自身的属性特征如商品热度和商品使用时间先后序列关系的影响。
不同商品之间在使用过程中的先后顺序关系可以用序列模式表示。序列模式已被应用在个性化推荐的多个不同领域, 如车辆行驶路径序列模式挖掘及推 荐[21]、图书馆用户借阅序列模式分析[22]、基于网页浏览序列模式的信息推荐[23]、基于序列模式的学习材料的推荐[24]等。为提高推荐效果, 本文挖掘用户购买商品之间的序列模式, 并用其对协同过滤的推荐列表进行筛选和优化。
本文提出一种改进的个性化推荐算法, 构造评分的时间系数和商品热度系数, 改进用户评分相似性函数, 提出综合时间、热度和评分相似度的用户兴趣相似性函数, 并对于商品之间存在的序列模式进行挖掘, 用序列模式对推荐结果进行筛选和过滤, 提高个性化推荐效果。
用户兴趣的相似性计算是协同过滤算法的关 键[13]。常用的相似性函数有余弦相似性、修正余弦相似性和相关相似性[12]。传统的相似性函数中, 效果最优的是修正余弦相似性[25]。因此, 本文以修正余弦相似性为基础, 引入时间系数T、评分系数L和热门系数TFIDF, 对协同过滤算法的相似性函数进行改进, 提高推荐效果。
用户的需求和兴趣会随着时间而发生变化。最新的购买评价比过去的评价更能反映消费者现在及未来的需求特征。评论发布的时间距离当前越久远, 对用户兴趣的反映程度越低。因此, 在计算用户兴趣的相似性时引入时间权重, 对最近的评分赋予较大的权重。本文采用一个随时间递减的函数Ti作为商品i评分的时间系数, 如公式(1)所示。
${{T}_{i}}=\frac{1}{1+\alpha ({{T}_{0}}-{{{\bar{t}}}_{i}})}$ (1)
其中, ${{\bar{t}}_{i}}$是商品i的平均评分时间, T0是当前时间, $\alpha $是时间衰减参数。$\alpha$的大小决定了该时间系数T随时间的递减速度, 通过适当调整$\alpha$值, 可以使该系数适应各种商品。快速出现并消失的短期商品可将$\alpha$值调大, 而稳定性较强的商品适合较小的$\alpha $值。
传统协同过滤推荐算法中效果最好的是修正余弦相似函数, 将用户对M种商品的评分数据看成是一个M维向量, 通过计算向量间的夹角衡量用户之间兴趣的相似程度。修正余弦方法的不足在于只考虑向量的夹角而未考虑向量的长度。例如, 用户X的评分向量是(1, 1), 用户Y的评分向量是(5, 5), 则两者的向量夹角为0, 即认为二人对两种商品的评价完全相同。然而, 用户X对这两种商品的评分都是1, 说明对这两种商品很不满意, 而用户Y很喜欢这两种商品。不难看出, 对于5种不同的评分向量(1,1)、(2,2)、(3,3)、(4,4)、(5,5), 用余弦函数计算相似度, 得出的结果是这些评分向量均完全相同。显然, 这与事实严重不符。因此, 修正余弦函数无法正确衡量这种情况下两个用户兴趣的相似度。
对于个性化推荐问题来说, 用户之间共同喜欢某些商品比共同讨厌某些商品具有更重要的参考价值。也就是说, 如果X和Y都喜欢某些商品, 则如果一种新商品受到X的喜爱, 可以推断Y也会喜欢该商品, 进而向Y进行推荐。反之, 则不能够成立。因此不能说如果X和Y都讨厌某些商品, 则X喜欢的商品Y也会喜欢。
基于上述逻辑, 针对余弦函数存在的问题, 本文提出一种改进的评分相似性函数L, 满足以下要求:
(1) 向量方向相同时, 长度越长越相似, 例如(5,5)和(5,5)的相似度要比(4,4)和(4,4)的相似度高, 而且(5,5)和(1,1)的相似度很低;
(2) 向量方向不同时, 评分相近的相似度高, 而且评分高的更相似, 例如(5,4)和(5,3)的相似度要比(4,3)和(4,2)的相似度高;
(3) 任意向量的模为0时, 相似度都为0。
针对以上特点, 提出用户X和Y的评分相似性函数, 如公式(2)所示。
$L(X,Y)=\sqrt{\sum\limits_{i=1}^{M}{{{(\frac{{{x}_{i}}{{y}_{i}}}{1+{{({{x}_{i}}-{{y}_{i}})}^{2}}})}^{2}}}}$ (2)
其中, xi是用户X对第i个商品的评分, yi是用户Y对第i个商品的评分, M为商品种数。
根据公式(2)计算不同评分向量之间的相似性, 验证该函数是否克服了余弦函数的不足。对于第一种情况, 如果两个顾客的评分均为(5,5), 则相似性程度约为35.36; 如果两个顾客的评分均为(4,4), 则相似性程度约为22.63; 如果两个顾客的评分均为(1,1), 则相似性程度约为1.41。因此, 改进的评分相似性函数满足上面提到的第一个要求。对于第二种情况, 评分向量(5,4)和(5,3)的相似度约为25.71, 评分向量(4,3)和(4,2)的相似度约为16.28, 前者大于后者, 满足第二个条件。显然, 上述公式同样满足第三个条件。
按照协同过滤推荐算法, 热门商品或季节性商品销量大, 被消费者评论次数多, 被推荐的可能性也就更大。相反, 对于冷门商品, 被推荐的可能性很低。这种热门商品更可能被推荐的问题, 放大了大众流行趋势或季节性对推荐结果的影响, 削弱了用户需求个性化特征的作用。为了增加销量, 各电子商务平台往往会将热门商品放到首页或显眼的位置, 已经给予了足够的重视。在进行个性化推荐时, 不应该再次受到 热门商品的影响, 而应该更多考虑用户的个性化需求特征。
为了解决热门商品和季节性商品对推荐算法的影响, 本文基于TF-IDF算法思想引入一种热门系数对协同过滤算法的相似性函数进行调整。TF-IDF算法由谷歌提出, 用来解决搜索引擎对关键词的搜索准确性问题[26]。TF (Term Frequency)是关键词出现的频率, 用于衡量两个用户共同评价商品数量的比例。IDF (Inverse Document Frequency)是逆文本频率指数, 目的是让“的”、“和”、“应用”等这种普遍出现的词权重降低, 在本文中的含义是热门商品的重要度应该适当降低。综合上述两个指标, 给出TFIDF公式如公式(3)所示。
$TFIDF(X,Y)=\sum\limits_{i=1}^{M}{(\frac{{{W}_{i}}}{{{T}_{x}}}\log \frac{D}{{{D}_{i}}})}$ (3)
其中, X和Y为两个顾客对M种商品的评分向量。Tx为用户X购买的商品品种总量。Wi表示第i种商品是否被X和Y评分, 如果被两个人同时评分, 则取值为1, 否则取值为0。D为该电子商务网站本大类商品的用户总数量。Di为第i种商品的用户总数量。通过log函数[27], 当某一商品被很多用户购买过时, 它的权重就会降低。
在协同过滤推荐中, 用户相似度计算不应该仅仅基于用户打分, 需要综合考虑商品的热门系数、两个用户评分的相似性程度以及评分的时间, 提高个性化推荐的针对性和时效性。基于前面的分析, 提出衡量两个用户相似性程度的综合相似性函数SIM(X,Y), 如公式(4)所示。
$SIM(X,Y)=TFIDF(X,Y)\cdot \sqrt{\sum\limits_{i=1}^{M}{{{T}_{i}}{{(\frac{{{x}_{i}}{{y}_{i}}}{1+{{({{x}_{i}}-{{y}_{i}})}^{2}}})}^{2}}}}$(4)
其中, X和Y为两个顾客对M种商品的评分向量。TFIDF考虑了两个用户同时评价商品的数量和商品的热门程度。两个用户共同评价的商品数量越多, 两者的兴趣越相似。商品热门度越高, 重要度越低。公式(4)中的后半部分将商品的时间系数Ti融入到评分相似性函数计算中, 越新的评价作用越重要。改进的评分相似性函数克服了余弦相似性函数的不足, 与用户打分的实际含义更加一致, 能够更好地衡量用户兴趣的相似性。
传统的协同过滤没有考虑商品的序列模式问题, 往往向买了鼠标的用户推荐电脑, 向买了《Java高级编程》的用户推荐《Java入门教程》。针对这一问题, 本文通过挖掘购买商品之间的序列关联规则得到序列模式, 再基于序列模式对推荐结果进行筛选和重新排序。
通过对序列模式挖掘的分析, 发现二项序列模式可以代替全序列模式的信息, 因此提出二项序列模式挖掘的改进算法, 减少数据库扫描次数和冗余分析, 提高序列模式挖掘的效率。首先使用二项序列模式挖掘算法产生一组序列模式, 然后对推荐结果集进行筛选。例如, 有很多用户都是买了手机之后去买屏幕贴膜, 根据算法会产生序列模式: 手机→屏幕贴膜。当协同过滤算法产生推荐结果集的时候, 如果用户买了屏幕贴膜, 推荐结果集里一定会有手机, 但是根据序列模式产生的规则, 屏幕贴膜在手机的后面, 所以对手机的推荐权重进行降低即可。
二项序列模式挖掘基于用户购买商品的数据库D展开, 从中挖掘出频繁二项商品序列模式。数据库D包含商品i、购买用户Uik(购买商品i的第k个用户)和购买时间Tik。二项序列模式挖掘算法TSPM (Two-items Sequential Patterns Mining)的输入、输出及算法步骤如下:
输入: 用户购买商品数据库D, 最小支持度minsup, 最小置信度minconf
输出: 二项序列模式集合SP
(1) 计算商品支持度: 扫描数据库D, 计算购买第i种商品的用户数量ci, $i=1,2,\cdots M$, M为商品品种数量;
(2) 构建频繁1项集: 如果${{c}_{i}}>minsup$, 则第i种 商品为频繁1-序列, 所有的频繁1-序列构成频繁1项集L1;
(3) 构建频繁2项集: 对L1中的商品进行两两组合, 并计算先购买i再购买j的用户数量cij。如果${{c}_{ij}}>minsup$, 则该组合进入频繁2项集L2。否则, 该组合不进入L2。
(4) 构建2项序列模式: 根据每个频繁2项集, 生成候选2项序列模式$\to j$。计算候选二项序列模式的支持度$conf\mathrm{(}i\to j\mathrm{)}=\frac{{{C}_{ij}}}{{{C}_{i}}}$。如果$conf\mathrm{(}i\to j\mathrm{)}>minconf$, 则$i\to j$为二项序列模式, 加入二项序列模式集合SP。否则, 该序列模式不进入SP。
本算法从两个方面进行改进: 改进协同过滤推荐的相似性函数, 加入热门系数和时间系数, 改进评分相似性函数, 提出新的相似度计算方法; 提出二项序列模式挖掘算法, 用二项序列模式对协同过滤推荐结果进行筛选和排序, 提高推荐效果。改进算法步骤如下:
输入: 交易评价数据库D, 其中包含商品编号、购买用户编号、评分、时间; 邻居用户数量q; 向用户推荐的商品数量N; 最小支持度minsup; 最小置信度minconf
输出: 对用户的TopN推荐列表
(1) 用户相似性计算
根据公式(4)计算用户之间的相似性。根据相似性的大小排序, 和用户k最相似的前q个用户作为该用户的最近邻居集Neibk。
(2) 生成候选推荐结果集
为用户k推荐商品, 寻找邻居用户购买过而用户k没有购买的商品, 根据相似度进行加权计分, 得到每个商品的预测评分。计算方法如公式(5)所示。
${{P}_{ik}}=\frac{\sum\limits_{j=1}^{q}{{{S}_{kj}}\cdot {{R}_{ji}}}}{{{N}_{i}}}$ (5)
其中, Pik为预测该用户k对第i个商品的评分, Skj 是该用户k和第j个用户的相似度, Rji是第j个用户对 第i个商品的评分, Ni是购买第i个商品的总人数。根 据公式(5), 可以计算出该用户对每个商品的预测评分。根据评分的大小排序, 就得到候选推荐结果集CTopN。
(3) 按照本文第4节的算法TSPM挖掘二项序列模式, 得到二项序列模式集SP。
(4) 基于二项序列模式进行推荐结果筛选, 得到TopN。
从二项序列模式集合SP中找出包含候选推荐商品的二项模式, 并按照模式的先后顺序筛选推荐商品, 得到新的推荐顺序列表。如果二项序列模式与推荐商品一致, 则增加该商品的推荐权重。例如, 挖掘出的序列模式是$A\to B$, 用户已经购买了A, 尚未购买B, 且$B\in CTopN$, 则增加推荐B的权重。如果二项序列模式与推荐商品不一致, 则降低对该商品的推荐权重。例如, 挖掘出的序列模式是$A\to B$, 用户已经购买了B, 尚未购买A, 且$A\in CTopN$, 则用户购买A的可能性很小, 将A的推荐权重降低。
(5) 向用户k推荐TopN商品。
本文收集亚马逊网上评论数据作为测试数据①(①http://snap. stanford.edu/data/index.html.)。因为书籍类的时间特征比较明显, 一般用户都会先买入门级书籍再买比较高级的书籍, 因此选用书籍类数据进行测试。选取2004年-2005年的图书数据进行推荐算法的验证。数据属性包括商品编号、购买用户编号、评分和时间。共有110多万条记录, 涉及到22万名用户和5万种图书。
对数据进行预处理, 删除评论次数少于2次的用户数据和被评论次数少于2次的书籍数据。处理后的数据包含4 582位用户, 24 398种商品, 共52 234条评论数据。
本算法测试环境如下: Intel® Core™ i5-4200M CPU @2.50GHz处理器, DDR3 RAM 4.00GB内存, 1TB硬盘, Microsoft Windows 8.1操作系统, 算法基于Java语言自主开发。
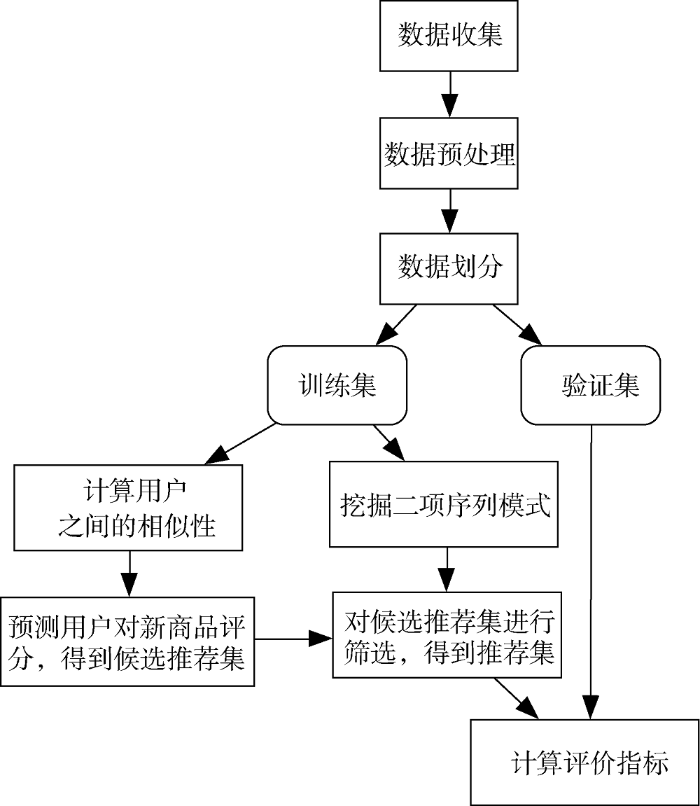
对改进的个性化推荐算法进行实验测试的步骤如图1所示。
将预处理后的数据划分为训练集和验证集。首先对每个用户所有的评分数据按评论时间进行升序排序,然后将其前80%数据作为训练集,将其后20%的数据作为验证集。例如,一个用户一共评价了10个商品,按照时间顺序,前8个商品的评论作为测试集,后2个商品的评论作为验证集。得到的训练集包含4 582个用户, 23 313种商品, 共43 211条评论数据;验证集中包含4 582个用户, 6 653种商品, 9 023条评论数据。。
基于训练集数据, 根据公式(4)计算用户兴趣的相似性程度, 并根据公式(5)预测用户对验证集中商品的评分, 根据评分从高到低的顺序得到候选推荐商品集合。考虑到商品购买之间存在的序列关系, 应用TSPM算法挖掘训练集中存在的二项序列模式。根据得到的二项序列模式, 对候选推荐集中的商品进行筛选, 删除与序列模式不一致的商品, 调整推荐顺序, 得到商品推荐列表。最后, 将验证集与推荐列表相比较, 计算出准确率、召回率和F值[28], 对推荐结果进行评价。
本文比较的基准算法是协同过滤算法。对基准算法的测试, 与图1的差异在于: 一是基于传统相似性函数计算用户之间的相似性, 本文分别测试了皮尔逊相似性函数、余弦相似性函数和修正余弦相似性函数。二是对于基准协同过滤推荐算法, 不进行二项序列模式的挖掘, 也不用二项序列模式对推荐商品集合进行筛选和调整。
应用基准协同过滤算法和本文改进的个性化推荐算法, 对亚马逊图书数据进行测试, 从以下两方面对改进的个性化推荐算法进行验证:
(1) 验证本文提出的改进相似性函数的应用效果。
比较皮尔逊相关系数、余弦相似性、修正余弦相似性和本文提出的改进相似性函数的应用效果, 从准确率、召回率和F值三个方面验证改进相似性函数的性能。
(2) 验证序列模式的应用对推荐效果的提升。
比较使用序列模式进行筛选和不使用序列模式的推荐效果。使用本文提出的改进推荐算法计算出推荐结果集, 对推荐结果集使用序列模式进行过滤筛选后, 再用TopN进行推荐, 将推荐结果和不使用序列模式的结果进行比较, 证明序列模式对推荐效果的影响是正向的。
对皮尔逊相似性函数、余弦相似性函数、修正余弦相似性函数与本文提出的改进相似度计算函数进行比较, 并比较TopN分别为5、10、20时不同函数的推荐效果, 结果如表1所示。可以看出, 在传统的三个相似性函数中, 修正余弦相似性函数的性能普遍好于皮尔逊相关系数和余弦相似函数。因此, 改进的相似性函数只需要与修正余弦函数进行比较。从TopN的不同取值来看, 所有相似度计算函数在TopN选10的时候推荐准确率最高。当TopN取10的时候, 本文的改进函数推荐准确率和F值均高于修正余弦函数。说明本文的改进相似性计算函数优于修正余弦函数。需要特别指出, 本文测试使用的是亚马逊的大规模真实评分记录, 个性化推荐准确率提升1%就会给企业增加可观的销售额。因此, 相似性函数的改进具有较大的现实意义。
表1 相似度计算函数比较
| TopN | 相似度函数 | 准确率 | 召回率 | F值 |
|---|---|---|---|---|
| 5 | 皮尔逊 | 7.25% | 6.33% | 6.76% |
| 余弦相似 | 7.98% | 8.06% | 8.02% | |
| 修正余弦 | 8.26% | 8.11% | 8.18% | |
| 本文改进函数 | 8.24% | 9.34% | 8.76% | |
| 10 | 皮尔逊 | 10.38% | 9.96% | 10.17% |
| 余弦相似 | 11.24% | 10.01% | 10.59% | |
| 修正余弦 | 12.22% | 11.88% | 12.05% | |
| 本文改进函数 | 13.58% | 11.79% | 12.62% | |
| 20 | 皮尔逊 | 10.38% | 10.48% | 10.43% |
| 余弦相似 | 11.24% | 10.84% | 11.04% | |
| 修正余弦 | 11.98% | 12.65% | 12.43% | |
| 本文改进函数 | 11.79% | 13.05% | 12.39% |
基于改进的相似性计算函数, TopN取值为10, 比较使用序列模式进行推荐结果筛选和不使用序列模式的推荐效果, 结果如表2所示。
由表2可以看出, 使用序列模式进行推荐时, 准确率和F值均得到提升。因此, 通过对二项序列模式的挖掘并对推荐结果进行筛选, 能够提高个性化推荐的准确率和F值, 推荐效果更好。尽管准确率和F值的提高幅度不大, 但对于大规模的电商平台来说, 仍会增加可观的收入。另外, 序列模式的提升效果不可能太大, 因为序列模式只存在于用户多次购买同类商品的情况, 属于交易记录中的少数。
总之, 结合改进的相似度函数和序列模式, 与基于修正余弦的协同过滤算法相比较, 改进算法的推荐准确率和F值分别提高1.89%和0.73%。在技术越来越成熟的情况下, 从细微的角度对推荐算法进行深入改进, 是提高个性化推荐效果、增加电商企业销售收入的有效途径。
针对电子商务个性化推荐中存在的时间动态性特征、商品间存在序列关系以及修正余弦相似性函数不考虑向量长度的问题, 提出改进的个性化推荐算法, 从两大方面进行改进。一方面, 在相似性计算函数中引入时间系数和热门系数, 改进评分相似性函数, 提出新的相似度计算方法; 二是提出二项序列模式挖掘算法, 用二项序列模式对协同过滤推荐结果进行筛选和排序, 提高推荐效果。最后, 采用2004年-2005年的亚马逊图书评分真实数据, 对两方面改进效果进行测试验证。结果表明, 改进的相似性计算方法和序列模式两个方面均能够提高推荐的准确率和F值, 具有比较重要的现实意义。
李杰: 提出研究思路, 设计研究方案, 提出算法改进思路, 论文最终版本修订;
杨芳: 提出算法改进思路, 论文起草及最终版本修订;
徐晨曦: 收集、清洗数据, 编写算法程序代码, 算法测试及结果分析。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: ljrsch@163.com。
[1] 李杰. 2004.csv. 2004年亚马逊图书评分数据集.
[2] 李杰. 2005.csv. 2005年亚马逊图书评分数据集.
| [1] |
面向个性化推荐的强关联规则挖掘 [J].https://doi.org/10.3321/j.issn:1000-6788.2009.08.017 URL Magsci [本文引用: 1] 摘要
<FONT face=Verdana>提出了适用于个性化推荐的强关联规则的概念,并给出一种基于矩阵的强关联规则挖掘算法.强关联规则集合能够以较少数量的规则表示全部有效关联信息,便于管理和应用.给出的强关联规则挖掘算法只需对交易数据库进行一次扫描,在挖掘过程中不断删除非频繁项使矩阵规模逐渐减小,并且避免了对冗余规则的挖掘, 从而提高了挖掘效率.通过对三组数据的实验表明:强关联规则集合包括的规则数量平均仅为规则总数的26.2{\%},有效解决了规则数量过多的问题.<BR></FONT>
Strongest Association Rules Mining for Personalized Recommendation [J].https://doi.org/10.3321/j.issn:1000-6788.2009.08.017 URL Magsci [本文引用: 1] 摘要
<FONT face=Verdana>提出了适用于个性化推荐的强关联规则的概念,并给出一种基于矩阵的强关联规则挖掘算法.强关联规则集合能够以较少数量的规则表示全部有效关联信息,便于管理和应用.给出的强关联规则挖掘算法只需对交易数据库进行一次扫描,在挖掘过程中不断删除非频繁项使矩阵规模逐渐减小,并且避免了对冗余规则的挖掘, 从而提高了挖掘效率.通过对三组数据的实验表明:强关联规则集合包括的规则数量平均仅为规则总数的26.2{\%},有效解决了规则数量过多的问题.<BR></FONT>
|
| [2] |
云计算环境下基于协同过滤的个性化推荐机制 [J].https://doi.org/10.7544/issn1000-1239.2014.20130056 URL Magsci [本文引用: 1] 摘要
随着云计算时代的到来,应用数据量剧增,个性化推荐技术日趋重要.然而由于云计算的超大规模以及分布式处理架构等特点,将传统的推荐技术直接应用到云计算环境时会面临推荐精度低、推荐时延长以及网络开销大等问题,导致推荐性能急剧下降.针对上述问题,提出一种云计算环境下基于协同过滤的个性化推荐机制RAC.该机制首先制定分布式评分管理策略,通过定义候选邻居(candidate neighbor, CN)的概念筛选对推荐结果影响较大的项目集,并构建基于分布式存储系统的2个阶段评分索引,保证推荐机制快速准确地定位候选邻居;在此基础上提出基于候选邻居的协同过滤推荐算法(candidate neighbor-based distribited collaborative filtering algorithm, CN-DCFA),在候选邻居中搜索目标用户已评分项目的k近邻,预测目标用户的推荐集top-N.实验结果表明,在云计算环境下RAC拥有良好的推荐精度和推荐效率.
A Collaborative Filtering Recommendation Mechanism for Cloud Computing [J].https://doi.org/10.7544/issn1000-1239.2014.20130056 URL Magsci [本文引用: 1] 摘要
随着云计算时代的到来,应用数据量剧增,个性化推荐技术日趋重要.然而由于云计算的超大规模以及分布式处理架构等特点,将传统的推荐技术直接应用到云计算环境时会面临推荐精度低、推荐时延长以及网络开销大等问题,导致推荐性能急剧下降.针对上述问题,提出一种云计算环境下基于协同过滤的个性化推荐机制RAC.该机制首先制定分布式评分管理策略,通过定义候选邻居(candidate neighbor, CN)的概念筛选对推荐结果影响较大的项目集,并构建基于分布式存储系统的2个阶段评分索引,保证推荐机制快速准确地定位候选邻居;在此基础上提出基于候选邻居的协同过滤推荐算法(candidate neighbor-based distribited collaborative filtering algorithm, CN-DCFA),在候选邻居中搜索目标用户已评分项目的k近邻,预测目标用户的推荐集top-N.实验结果表明,在云计算环境下RAC拥有良好的推荐精度和推荐效率.
|
| [3] |
Combining Content-Based and Collaborative Recommendations: A Hybrid Approach Based on Bayesian Networks [J].https://doi.org/10.1016/j.ijar.2010.04.001 URL [本文引用: 1] |
| [4] |
协同过滤推荐技术综述 [J].https://doi.org/10.3969/j.issn.1003-6059.2014.08.007 URL Magsci [本文引用: 1] 摘要
协同过滤是推荐系统中广泛使用的推荐技术,研究人员对如何完善协同过滤推荐技术开展大量工作,但是相应的研究总结较少.文中对协同过滤的相关研究进行全面回顾,首先阐述协同过滤的内涵及其存在的主要问题,包括稀疏性、多内容及可扩展性,然后详细介绍国内外学者针对以上问题的解决方案,最后指出协同过滤下一步的研究重点.文中介绍一个相对完整的协同过滤知识框架,对理清协同过滤的研究脉络,为后续研究提供参考,推进个性化信息服务的发展具有一定意义.
Survey of Recommendation Based on Collaborative Filtering [J].https://doi.org/10.3969/j.issn.1003-6059.2014.08.007 URL Magsci [本文引用: 1] 摘要
协同过滤是推荐系统中广泛使用的推荐技术,研究人员对如何完善协同过滤推荐技术开展大量工作,但是相应的研究总结较少.文中对协同过滤的相关研究进行全面回顾,首先阐述协同过滤的内涵及其存在的主要问题,包括稀疏性、多内容及可扩展性,然后详细介绍国内外学者针对以上问题的解决方案,最后指出协同过滤下一步的研究重点.文中介绍一个相对完整的协同过滤知识框架,对理清协同过滤的研究脉络,为后续研究提供参考,推进个性化信息服务的发展具有一定意义.
|
| [5] |
基于情境聚类和用户评级的协同过滤推荐模型 [J].
协同过滤是电子商务推荐系统中广泛应用的推荐技术, 但面临着严重的用户评分数据高维化和稀疏性问题. 同时, 传统协同过滤中的相似度度量方法没有考虑用户评分行为对其他用户的影响, 因而对评分预测的精度影响较大. 此外, 在移动环境下, 传统协同过滤未结合情境信息, 导致推荐质量下降. 对此, 提出一种基于情境聚类和用户评级的协同过滤模型. 首先, 根据情境信息对用户进行聚类, 降低用户评分数据维度和稀疏性; 然后, 引入社会网络理论分析用户间关系, 建立用户评级模型用于评价用户推荐能力, 并结合评级指标进行评分预测. 通过MovieLens和NetFlix数据集对基于该模型的SlopeOne算法和其它三种方法的比较验证结果表明: 本模型在所有数据集上都获得了最高的预测精度, 同时还具有最佳的推荐覆盖度, 可显著提高预测精度, 更适用于移动电子商务环境下的个性化推荐问题.
Improved Collaborative Filtering Model Based on Context Clustering and User Ranking [J].
协同过滤是电子商务推荐系统中广泛应用的推荐技术, 但面临着严重的用户评分数据高维化和稀疏性问题. 同时, 传统协同过滤中的相似度度量方法没有考虑用户评分行为对其他用户的影响, 因而对评分预测的精度影响较大. 此外, 在移动环境下, 传统协同过滤未结合情境信息, 导致推荐质量下降. 对此, 提出一种基于情境聚类和用户评级的协同过滤模型. 首先, 根据情境信息对用户进行聚类, 降低用户评分数据维度和稀疏性; 然后, 引入社会网络理论分析用户间关系, 建立用户评级模型用于评价用户推荐能力, 并结合评级指标进行评分预测. 通过MovieLens和NetFlix数据集对基于该模型的SlopeOne算法和其它三种方法的比较验证结果表明: 本模型在所有数据集上都获得了最高的预测精度, 同时还具有最佳的推荐覆盖度, 可显著提高预测精度, 更适用于移动电子商务环境下的个性化推荐问题.
|
| [6] |
一种改进的协同过滤推荐算法 [J].https://doi.org/10.3969/j.issn.1007-2373.2010.03.019 URL [本文引用: 2] 摘要
电子商务的蓬勃发展,使网站中能够提供的商品种类日益繁多,如何迎合客户的兴趣来推荐商品,成为当前电子商务亟待解决的重点问题.协同过滤作为目前推荐系统应用中最为成功的个性化推荐技术,也得到了越来越多研究者的关注.文章在简要介绍传统协同过滤推荐算法的基础上,重点对推荐算法无法适用于用户多兴趣下的推荐问题进行了剖析,提出了一种基于用户多兴趣的协同过滤推荐改进算法.通过实验仿真,验证了该算法的有效性.
An Adaptive Algorithm for Collaborative Filtering Recommendation [J].https://doi.org/10.3969/j.issn.1007-2373.2010.03.019 URL [本文引用: 2] 摘要
电子商务的蓬勃发展,使网站中能够提供的商品种类日益繁多,如何迎合客户的兴趣来推荐商品,成为当前电子商务亟待解决的重点问题.协同过滤作为目前推荐系统应用中最为成功的个性化推荐技术,也得到了越来越多研究者的关注.文章在简要介绍传统协同过滤推荐算法的基础上,重点对推荐算法无法适用于用户多兴趣下的推荐问题进行了剖析,提出了一种基于用户多兴趣的协同过滤推荐改进算法.通过实验仿真,验证了该算法的有效性.
|
| [7] |
基于用户间信任关系改进的协同过滤推荐方法 [J].Improving Collaborative Filtering Recommendation Based on Trust Relationship Among Users [J]. |
| [8] |
基于标签的商品推荐模型研究 [J].Building Product Recommendation Model Based on Tags [J]. |
| [9] |
基于用户偏好与商品属性情感匹配的图书个性化推荐研究 [J].
【目的】识别并获取细粒度的用户偏好信息,优化图书个性化推荐的效果。【方法】使用情感分析方法对用户图书评论进行属性层文本挖掘,通过用户本身的图书评论获取用户对图书属性的偏好;基于每本图书的所有评论的情感计算获得其属性评分;将用户偏好矩阵、图书属性得分矩阵进行匹配,从而实现用户对图书属性情感偏好的个性化推荐。【结果】利用亚马逊图书评论数据作为数据来源分别对传统的协同过滤方法与本文提出的推荐方法进行实验对比。结果表明,本文提出的方法在准确性、召回率、覆盖率上分别提高了0.030、0.097、0.2812。【局限】未考虑时间因素对用户偏好的影响,并且属性类型的全面程度受亚马逊图书评论数量和质量的限制。【结论】本文计算用户对图书属性的情感得分,得到细粒度的用户偏好信息,并通过与图书属性的得分进行匹配,提升了图书个性化推荐的效果。
Personalized Book Recommendation Based on User Preferences and Commodity Features [J].
【目的】识别并获取细粒度的用户偏好信息,优化图书个性化推荐的效果。【方法】使用情感分析方法对用户图书评论进行属性层文本挖掘,通过用户本身的图书评论获取用户对图书属性的偏好;基于每本图书的所有评论的情感计算获得其属性评分;将用户偏好矩阵、图书属性得分矩阵进行匹配,从而实现用户对图书属性情感偏好的个性化推荐。【结果】利用亚马逊图书评论数据作为数据来源分别对传统的协同过滤方法与本文提出的推荐方法进行实验对比。结果表明,本文提出的方法在准确性、召回率、覆盖率上分别提高了0.030、0.097、0.2812。【局限】未考虑时间因素对用户偏好的影响,并且属性类型的全面程度受亚马逊图书评论数量和质量的限制。【结论】本文计算用户对图书属性的情感得分,得到细粒度的用户偏好信息,并通过与图书属性的得分进行匹配,提升了图书个性化推荐的效果。
|
| [10] |
结合项目类别和动态时间加权的协同过滤算法 [J].Collaborative Filtering Algorithm Combining Item Category and Dynamic Time Weighting [J]. |
| [11] |
Search Recommendation Model Based on User Search Behavior and Gradual Forgetting Collaborative Filtering Strategy [J]. |
| [12] |
基于项目之间相似性的兴趣点推荐方法 [J].https://doi.org/10.3969/j.issn.1001-3695.2012.01.032 URL [本文引用: 2] 摘要
针对评分数据稀疏的情况下传统相似性计算的不足,提出了一种基于项目之间相似性的协同过滤算法。该算法结合用户对项目的评分和项目之间的兴趣度进行项目之间的相似性计算,在一定程度上减小了评分数据稀疏的负面影响。实验结果表明,该算法在评分数据稀疏的情况下,能使推荐系统的推荐质量明显提高。
Point of Interest Recommendation Method Based on Similarity Between Items [J].https://doi.org/10.3969/j.issn.1001-3695.2012.01.032 URL [本文引用: 2] 摘要
针对评分数据稀疏的情况下传统相似性计算的不足,提出了一种基于项目之间相似性的协同过滤算法。该算法结合用户对项目的评分和项目之间的兴趣度进行项目之间的相似性计算,在一定程度上减小了评分数据稀疏的负面影响。实验结果表明,该算法在评分数据稀疏的情况下,能使推荐系统的推荐质量明显提高。
|
| [13] |
Spreading Code Design for Downlink Space-Time-Frequency Spreading CDMA [J].https://doi.org/10.1109/TVT.2008.917234 URL [本文引用: 2] 摘要
In this paper, we analyze the recently proposed downlink space-time-frequency spreading code-division multiple-access (STFS-CDMA) scheme. A spreading code design criterion is first derived for STFS-CDMA. From the spreading code design criterion, we can see that the two original spreading codes adopted in STFS-CDMA, i.e., the Walsh-Hadamard code (WHC) and the double-orthogonal code (DOC), both cannot achieve full space and frequency diversity, no matter how many users exist in the system. Then, a novel spreading code, i.e., permutated DOC (PDOC), is proposed. PDOC-coded STFS-CDMA (PDOC-STFS-CDMA) can obtain full space and frequency diversity when the number of users in the system is only one, but it cannot obtain full space and frequency diversity when the number of users is larger than one. To mitigate this problem, a zero-padded rotary fast Fourier transform code (ZPRFC) is proposed. Compared with WHC-coded STFS-CDMA (WHC-STFS-CDMA), DOC-coded STFS-CDMA (DOC-STFS-CDMA), and PDOC-STFS-CDMA, ZPRFC-coded STFS-CDMA (ZPRFC-STFS-CDMA) cannot only always obtain full space and frequency diversity but can also result in a low-complexity receiver at the cost of the reduction of the number of supporting users. Finally, the simulation results are given to compare with the performances of WHC-STFS-CDMA, DOC-STFS- CDMA, PDOC-STFS-CDMA, and ZPRFC-STFS-CDMA.
|
| [14] |
Recommender System [J]. |
| [15] |
Collaborative Filtering with Temporal Dynamics [J].https://doi.org/10.1145/1721654.1721677 URL [本文引用: 1] 摘要
ABSTRACT Customer preferences for products are drifting over time. Product perception and popularity are constantly changing as new selection emerges. Similarly, customer inclinations are evolving, leading them to ever redefine their taste. Thus, modeling temporal dynamics is essential for designing recommender systems or general customer preference models. However, this raises unique challenges. Within the ecosystem intersecting multiple products and customers, many different characteristics are shifting simultaneously, while many of them influence each other and often those shifts are delicate and associated with a few data instances. This distinguishes the problem from concept drift explorations, where mostly a single concept is tracked. Classical time-window or instance decay approaches cannot work, as they lose too many signals when discarding data instances. A more sensitive approach is required, which can make better distinctions between transient effects and long-term patterns. We show how to model the time changing behavior throughout the life span of the data. Such a model allows us to exploit the relevant components of all data instances, while discarding only what is modeled as being irrelevant. Accordingly, we revamp two leading collaborative filtering recommendation approaches. Evaluation is made on a large movie-rating dataset underlying the Netflix Prize contest. Results are encouraging and better than those previously reported on this dataset. In particular, methods described in this paper play a significant role in the solution that won the Netflix contest.
|
| [16] |
时间窗口对个性化推荐算法的影响研究 [J].Effect of the Time Window on the Personalized Recommendation Algorithm [J]. |
| [17] |
时间加权的混合推荐算法 [J].Time-Weighted Hybrid Recommender Algorithm [J]. |
| [18] |
基于动态时间的个性化推荐模型 [J].https://doi.org/10.6054/j.jscnun.2017015 URL [本文引用: 1] 摘要
在推荐系统中,往往会存在数据的非实时性、稀疏性和冷启动性等问题,文中通过引入遗忘曲线来跟踪用户对资源偏好程度随时间变化情况,提出一种改进的K-Means聚类算法对用户集进行聚类,根据改进的个性化推荐算法对用户进行推荐,建立了一种基于动态时间的个性化推荐模型.通过实验验证,该个性化推荐模型能够获取准确的用户偏好信息,并缓解冷启动问题,降低算法计算的时间空间复杂度,提高个性化推荐算法的推荐质量.
Personalized Recommendation Model Based on Dynamic Time [J].https://doi.org/10.6054/j.jscnun.2017015 URL [本文引用: 1] 摘要
在推荐系统中,往往会存在数据的非实时性、稀疏性和冷启动性等问题,文中通过引入遗忘曲线来跟踪用户对资源偏好程度随时间变化情况,提出一种改进的K-Means聚类算法对用户集进行聚类,根据改进的个性化推荐算法对用户进行推荐,建立了一种基于动态时间的个性化推荐模型.通过实验验证,该个性化推荐模型能够获取准确的用户偏好信息,并缓解冷启动问题,降低算法计算的时间空间复杂度,提高个性化推荐算法的推荐质量.
|
| [19] |
基于用户评分时间改进的协同过滤推荐算法 [J].
【目的】改进基于用户的协同过滤算法以缓解因数据稀疏、用户共同评分稀少所导致的问题,进而提高评分预测的精度。【方法】提出结合用户打分时间发现具有相似打分行为的用户,并将用户评分方差相似性融入到相似度的计算中,使得目标用户在最近邻的选取上更加合理。【结果】实验结果表明,相较基于用户的协同过滤算法,新算法的平均绝对误差降低约2%,在一定程度上改善了推荐系统的推荐效果。【局限】该算法仅在MovieLens数据集上进行了实验测试,还需要在其他数据集上进行检验。【结论】本文算法能够有效地提高推荐精度,具有一定的可行性和现实意义。
New Collaborative Filtering Recommendation Algorithm Based on User Rating Time [J].
【目的】改进基于用户的协同过滤算法以缓解因数据稀疏、用户共同评分稀少所导致的问题,进而提高评分预测的精度。【方法】提出结合用户打分时间发现具有相似打分行为的用户,并将用户评分方差相似性融入到相似度的计算中,使得目标用户在最近邻的选取上更加合理。【结果】实验结果表明,相较基于用户的协同过滤算法,新算法的平均绝对误差降低约2%,在一定程度上改善了推荐系统的推荐效果。【局限】该算法仅在MovieLens数据集上进行了实验测试,还需要在其他数据集上进行检验。【结论】本文算法能够有效地提高推荐精度,具有一定的可行性和现实意义。
|
| [20] |
基于多权值的Slope One协同过滤算法 [J].Slope One Collaborative Filtering Algorithm Based on Multi-Weights [J]. |
| [21] |
面向个性化交通信息服务的车辆行驶路径关联规则挖掘 [J].https://doi.org/10.3969/j.issn.1000-6788.2013.12.027 URL Magsci [本文引用: 1] 摘要
为了向驾驶者自动提供个性化的交通服务信息,需要对车辆行驶路径进行分析和预测.面向基于RFID的个性化交通服务系统,提出改进的车辆行驶路径关联规则挖掘方法,挖掘车辆历史行驶路径数据中的频繁序列模式,由频繁序列模式产生序列关联规则,根据当前行程车辆已行驶的路径,实现对车辆未来行驶路径的预测.本方法主要通过0-N数据结构和候选2-序列产生方法的改进,提高车辆行驶路径序列模式挖掘的效率.最后,通过数据测试验证了改进算法在运行效率上与GSP相比的性能优越性.
Association Rules Mining of Vehicle Routing for Personalized Traffic Information Service [J].https://doi.org/10.3969/j.issn.1000-6788.2013.12.027 URL Magsci [本文引用: 1] 摘要
为了向驾驶者自动提供个性化的交通服务信息,需要对车辆行驶路径进行分析和预测.面向基于RFID的个性化交通服务系统,提出改进的车辆行驶路径关联规则挖掘方法,挖掘车辆历史行驶路径数据中的频繁序列模式,由频繁序列模式产生序列关联规则,根据当前行程车辆已行驶的路径,实现对车辆未来行驶路径的预测.本方法主要通过0-N数据结构和候选2-序列产生方法的改进,提高车辆行驶路径序列模式挖掘的效率.最后,通过数据测试验证了改进算法在运行效率上与GSP相比的性能优越性.
|
| [22] |
基于序列模式挖掘的图书馆用户借阅行为分析 [J].Analysis of Library Users Borrowing Behaviors Based on Sequential Patterns Mining [J]. |
| [23] |
A Web Recommendation System Considering Sequential Information [J].https://doi.org/10.1016/j.dss.2015.04.004 URL [本文引用: 1] 摘要
With the rapid growth of information technology, the current era is witnessing an exponential increase in the generation and collection of web data. Projecting the right information to the right person is becoming more difficult day by day, which in turn adds complexity to the decision making process. Recommendation systems are intelligent systems that address this issue. They are widely used in e-commerce websites to recommend products to users. Most of the popular recommendation systems consider only the content information of users and ignore sequential information. Sequential information also provides useful insights about the behavior of users. We have developed a novel system that considers sequential information present in web navigation patterns, along with content information. We also consider soft clusters during clustering, which helps in capturing the multiple interests of users. The proposed system has utilized similarity upper approximation and singular value decomposition (SVD) for the generation of recommendations for users. We tested our approach on three datasets, the MSNBC benchmark dataset, simulated dataset and CTI dataset. We compared our approach with the first order Markov model as well as random prediction model. The results validate the viability of our approach.
|
| [24] |
Ghoushchi M B G. Personalized Recommendation of Learning Material Using Sequential Pattern Mining and Attribute Based Collaborative Filtering [J].https://doi.org/10.1007/s10639-012-9245-5 URL [本文引用: 1] |
| [25] |
协同过滤算法中的相似性度量方法研究 [J].https://doi.org/10.3778/j.issn.1002-8331.1204-0749 URL Magsci [本文引用: 1] 摘要
衡量用户的相似性是协同过滤算法的核心内容,用户间相似性的准确率对个性化推荐的结果会有显著影响。通过对用户-项目评分记录的分析,在比较pearson和jaccard相似性的基础上对相似性度量方法进行改进,并将该改进方法应用于MovieLens站点提供的数据集进行实证分析。实证研究表明,改进后的算法可以提高个性化推荐的准确性,并在一定程度上克服数据稀疏性对推荐质量的影响。
Research on Method of Similarity Measurement in Collaborative Filter Algorithm [J].https://doi.org/10.3778/j.issn.1002-8331.1204-0749 URL Magsci [本文引用: 1] 摘要
衡量用户的相似性是协同过滤算法的核心内容,用户间相似性的准确率对个性化推荐的结果会有显著影响。通过对用户-项目评分记录的分析,在比较pearson和jaccard相似性的基础上对相似性度量方法进行改进,并将该改进方法应用于MovieLens站点提供的数据集进行实证分析。实证研究表明,改进后的算法可以提高个性化推荐的准确性,并在一定程度上克服数据稀疏性对推荐质量的影响。
|
| [26] |
Luk R W P, Wong K F, et al. Interpreting TF-IDF Term Weights as Making Relevance Decisions [J]. |
| [27] |
|
| [28] |
|

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}