何跃, 丰月, 赵书朋 , 马玉凤
, 马玉凤
四川大学商学院 成都 610064
He Yue, Feng Yue, Zhao Shupeng, Ma Yufeng
中图分类号: 分类号: G206.3
通讯作者:
收稿日期: 2018-01-18
修回日期: 2018-01-18
网络出版日期: 2018-09-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
展开
摘要
【目的】通过研究知乎用户的社交行为, 为用户更精准地推荐相关内容。【方法】提出基于关联规则-LDA主题模型内容推荐方法, 通过构建特定话题下的共享子话题网络, 并结合LDA模型提取子话题下的主题词, 最终将相关子话题的内容精确推送给用户。【结果】实证研究发现, 知乎平台的物流话题下存在多个具有高度共现性的子话题, 其置信度均达到65%以上。【局限】收集的数据缺乏全面性, 可能会对推荐结果产生影响。【结论】运用关联规则-LDA主题模型分析, 能够为内容推荐提供新的研究思路。
关键词:
Abstract
[Objective] This research analyzes the social behaviors of Zhihu (https://www.zhihu.com/) users, aiming to recommend relevant contents more effectively. [Methods] First, we proposed a content recommendation method based on association rules-LDA topic model. Then, we constructed a network of shared sub-topics for specific topics and extracted keywords of the sub-topics with the LDA model. Finally, we pushed contents of the relevant topics for the users. [Results] Our study found that many sub-topics with high degrees of cooccurrence under the topic of logistics, and their confidence levels were above 65%. [Limitations] More comprehensive data is needed in future studies.[Conclusions] The association rule-LDA model provides new directions for content recommendation.
Keywords:
随着互联网的普及, UGC(User Generated Content)内容逐渐丰富, 在线问答(Online Question & Answering, Online Q&A)社区得到大力发展, 成为除搜索引擎外的重要信息平台。在线问答社区给人们提供了一个发布问题和提供答案的平台[1], 可以快速吸引各行各业的精英, 他们因为拥有共同的话题或是相似的兴趣而聚集, 每个人都在自己擅长的话题下进行回答反馈, 如知乎、Quora等, 其独特的社区定位和群体认同感吸引了许多高质量的忠实用户[2]。
在如今信息过载的时代, 快速高效地获得高质量的信息成为人们的一大需求, 国内衍生出的知乎平台可以满足大量用户的这种需求。借助知乎上某一特定话题的相关热门问题回答, 同时结合用户的行为数据, 可以分析知乎该话题下用户关注的问题, 并提取其中的主题, 了解用户对该话题的真正关注点。
在知乎上, 有专门的物流话题分区, 使用户能够有针对性地进行提问、回答、评论等操作。物流作为知乎上一个较为专业性的领域, 聚集了较多关注物流行业发展和对物流有深刻兴趣的人, 大家在上面共享经验、交流信息, 形成一个较为稳固的知识社交圈子。因此, 研究知乎上物流话题下用户的社交行为, 可以发现用户讨论的热点话题, 并构建相应的话题关联性体系。尽管知乎已经有自己的话题结构树, 有明确的父话题和子话题的分类, 但具有平级关系的子话题并没有得到很好地区分。通过关联规则分析, 可以得出一些隐藏的关联规律, 便于知乎话题分类推荐, 即基于知乎的子话题结构, 发现知乎话题下话题标签的关联规律。
社交问答社区相关研究主要从三个角度开展: 内容、用户、网络[3]。内容是知乎这类社交问答社区吸引用户的核心。目前主要从问题内容的分类、推荐、检索及质量评估4个方向进行研究[4]。在问题的分类自动化处理方法上, 有许多模型(如词袋模型、朴素贝叶斯、支持向量机和LDA等语言模型)被广泛应用[5,6,7,8]。Cai等则结合Wikipedia文本语义进行问题的有效分类[9]。一般而言, 对问题进行分类, 然后排序, 这本质上就是问题推荐。Chang等认为用户回答问题、产生评论行为和点赞都对知乎问题的推荐有影响[10]。除了个性化推荐, 问答社区重要的目的是让用户在最快的时间内找到需求问题的答案, 因此搜索功能完备性对用户体验及用户忠诚度有很大影响。Wu等对问答社区中用户使用短文本检索的问题, 提出基于用户意图预测的语言模型[11]。由于问答社区公开、自由的机制, 信息质量难免参差不齐, 无法保证信息的权威和可靠性。Paul等提出在评估答案的质量时, 最佳的考虑因素为赞成度、态度、幽默和努力程度, 其次为回答内容的效用[12]。Chen等研究发现答案的排列名次、回答者的权威性或者人气等因素影响答案的质量[13]。
在研究社交问答用户方面, 主要是探究用户在社区的角色, 分析用户使用心理动机, 根据用户行为寻找意见领袖等。在问答社区中, 用户一般分为两类: 一种是主动参与用户, 经常参与公共编辑, 并且将自己的经验知识贡献出来; 另一种是只索取不付出的用户, 只浏览不做任何回应反馈, 研究发现贡献越大的人, 其他人对其回报也越多[14,15]。
社交网络是指网络中的人及其关系的集合。Jurczyk 等提出在特定主题的话题中, 可以依据社交网络中用户的链接识别权威用户[16]。Gazan发现, 社会资本在问答社区微协作中起重要作用, 社会资本高的用户能带来更多的潜在协作者, 还可能带来更多的浏览量和回答量[17]。
以用户为中心, 根据用户的个性化需求开展具有针对性和主动性的信息服务, 是提高信息服务质量和信息资源使用率的重要手段[18]。根据用户的偏好和行为习惯, 将相关内容通过各种网络和终端主动推送给用户, 是一种动态的个性化服务模式, 传统的内容推荐模式主要有基于内容、协同过滤以及情景等三种, 然而部分学者认为这些方法是从关键词匹配或者用户评价的角度进行推荐, 不能准确表达语义信息[19], 同时也无法充分挖掘用户的潜在信息需求[20]。
许多学者将LDA主题模型及其改进后的方法应用于这一领域。基于LDA 主题模型的推荐可以捕捉文本资源内的语义信息, 有效解决一词多义、异形同义等问题, 这对于提高推荐的准确性具有重要意义。Kim等提出基于LDA模型的推荐系统, 通过抓取用户最近的Twitter信息, 然后进行LDA分析, 实现用户的个性化推荐[21]。Ramage等通过定义LDA主题与用户标签一一对应的关系, 将文本的标签引入到主题建模中, 同时提出Labeled LDA模型, 解决了语料库中的信用归因问题[22]。考虑到主题不仅与关键词有关, 同时也与时间有关, 所以在生成主题的同时, Wang等考虑了时间因素, 提出改进后的ToT模型[23]。
综合以上关于内容推荐的研究, 发现现有的个性化推荐系统只考虑文本语义和用户行为数据中的单个因素, 并没有将两种数据之间的关联性同时应用起来。而在社交问答社区的实际文本中, 不仅问题下的子话题之间存在关联性, 回答文本中也存在内容的关联性, 即用户行为数据的关联性。因此本文考虑问答文本中的两重关联, 将关联规则与LDA主题模型结合起来, 以提高内容推荐的准确性。
首先利用八爪鱼采集器获取知乎平台上物流话题下的相关问题和回答。针对这两种数据不同的特性, 利用正则表达式及Excel VBA等方法对源数据进行清洗和预处理。其次, 对预处理操作后的数据进行深度挖掘, 使用Python对知乎回答的文本进行预处理。通过关联规则分析方法, 分析出物流话题下支持度和置信度都较高的子话题, 并构建共享话题网络, 应用LDA主题模型提取所有回答文本的主题, 发现用户回答的讨论热点。最后根据用户关注的内容结合共享话题网络和话题主题进行精准的关联性内容推荐, 提升用户体验。
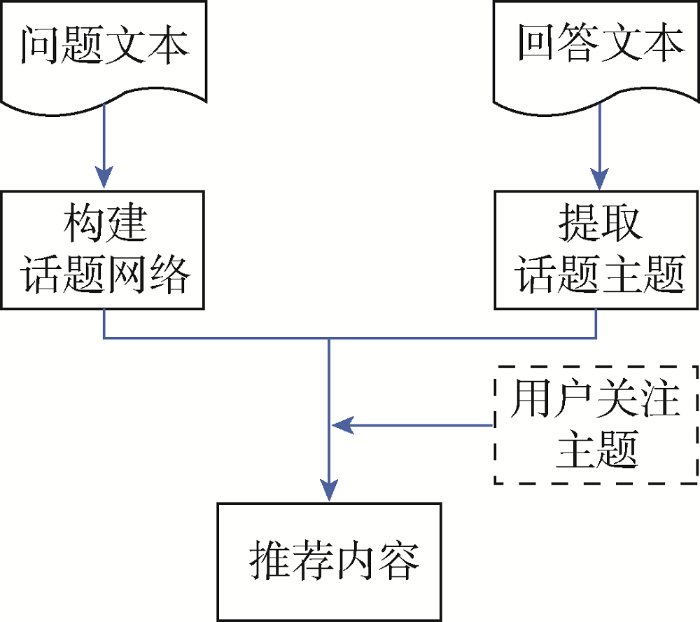
本文提出的内容推荐机制如图1所示。
本文主要工作是基于知乎平台获取关于物流话题下精华回答对应问题的文本分析, 因此需要采集大量的关于精华回答及其问题文本的信息。选取八爪鱼采集器获取知乎数据。
以知乎为数据收集平台, 选取物流话题下, 精华回答中前100个问题为研究对象, 爬取问题文本和回答文本的信息。为了清除原始数据中的干扰噪声, 需要对数据进行预处理, 主要包括三个部分: 数据清洗、文本分词及停用词过滤。
(1) 数据清洗流程主要去除无效和无意义的信息:去除匿名用户回答内容; 当用户有多个回答时, 只保留赞数最高的回答, 删除其他回答; 去除图片地址、URL地址等无效信息; 去除英文字母、数字及一些特殊字符, 如表情符号和分割线等。
(2) 中文不似英文有空格分隔词汇, 所以必须将句子分离成词或词组。中文分词是文本分类、信息检索、摘要自动生成等中文信息处理的关键步骤之一, 也是信息处理的基础和难点。在实现上, 可通过现有的集成分词软件实现。
(3) 为了提高搜索效率并提升文本分类精准率, 在处理数据时应当过滤掉停用词。针对中文去停用词, 比较常用的停用词表有“哈工大停用词词表”和“百度中文停用词表”等。
知乎上每个问题都会设置几个话题, 而话题与话题之间又有父子关系。本文基于物流话题提取知乎数据, 每个物流问题下有3-5个子话题标签, 由于问题都属于同一物流话题, 因此会出现问题不同但其话题标签却是相似的情况, 而且许多标签之间是成对出现的, 具有一定的规律。
通过收集问题话题标签数据, 获取话题标签矩阵, 在给定最小支持度和置信度后, 通过关联规则的方法, 便可以得到频繁出现的话题标签。关联规则过程如图2所示。
X即前项, 其内容是问题所在的一种话题标签。Y即后项, 其内容也是问题的话题标签。某一个X和Y组合出现的概率既是这条话题规则的支持度, 其概率值越大表明这种组合在整体样本中越频繁, 两种话题标签越可能同时出现, 说明X与Y总是相关的, 支持度越高, 说明规则占总样本的比重越大, 越应该得到重视。当X发生时, Y出现的概率即为规则的置信度。如果置信度达到80%或某个较高阈值, 则X和Y可以进行捆绑推荐, 或对子话题进行整合, 用一个子话题代替另一个子话题, 避免冗余; 如果置信度值较小, 说明话题X的出现对话题Y是否出现影响较小。
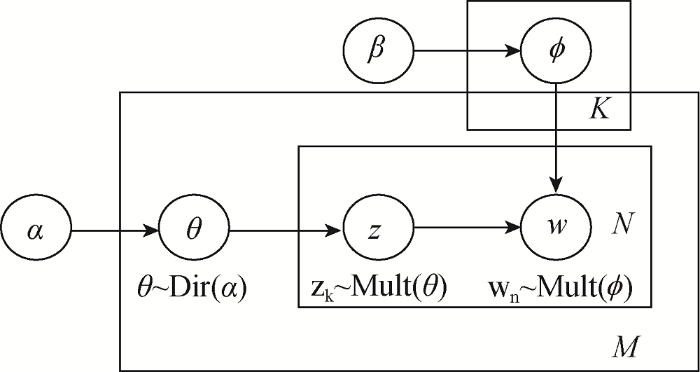
LDA(Latent Dirichlet Allocation)模型, 也被称为潜在狄利克雷分布模型, 在2003年由Blei等提出[24]。其本质是对自然语言进行建模处理, 挖掘文本相应的主题及词汇分布。LDA可以概括为“文本-主题-词汇”三层贝叶斯的概率模型, 如图3所示。
因此, 对于LDA文档中每个词语的概率可以通过公式(1)表示。
$p(词语|文本)=\sum\nolimits_{主题}{p(词语|主题)}\times p(主题|文本)$(1)
其中, p(词语|文本)表示文本中每一个词语的概率分布, p(词语|主题)描述每个主题中每个词语的概率分布, p(主题|文本)是每个文本中每个主题出现的概率。
假设定义由m篇文本构成的集合为文本集D, 其共包含K个主题z, N个词汇w, 那么LDA模型生成一篇文本的步骤如下:
(1) 在狄利克雷分布中, 对每个文本d∈D确定一个参数$\alpha$, 进而为文本隐含的主题z生成多项式分布$\theta $, 其中$\theta$服从Dirichlet分布($\theta \tilde{\ }\text{Dir(}\alpha \text{)}$)。
(2) 同理, 对每个主题z确定一个参数$\beta $, 进而为主题下词汇w生成多项式分布$\phi $, 其中$\phi $服从Dirichlet分布($\phi \tilde{\ }\text{Dir(}\beta \text{)}$)。
(3) 对文本中的第n个词汇wn:
因为主题zk服从多项分布(zk~Mult(θ )), 所以得到主题zk;
因为词汇wn服从多项分布(wn~Mult(ϕ )), 所以得到词汇wn。
笔者采集2016年12月15日至12月27日知乎上物流话题精华回答所在的前100个问题。采集之初, 知乎物流话题下有7 538个问题, 精华回答999个, 关注者27 000位。通过八爪鱼采集器获得每个问题的题目和该问题的子话题标签。同时利用八爪鱼采集器在知乎物流话题下获取100个精华回答所在问题的所有回答, 共计11 943次回答, 去除匿名用户后剩余10 249次回答, 这些回答由9 764人贡献, 只回答一次有9 383人, 回答两次及以上有381人; 重复回答的381人中, 共贡献866个回答。平均每个人回答2.2次, 由于回答需要与用户一一对应, 因此选取获得点赞数高的回答作为重复回答用户的回答文本。
获取每个用户的唯一回答文本后, 针对文本进行预处理。替换文本中的特殊字符, 去除替换后只有图片的回答或者内容为空的文本, 剩余9 676个回答文本, 并以此作为后续的研究对象。
采用Python的jieba组件进行分词, 在分词同时调用stopword停用词表去除停用词, 该方法既能保持分词速度, 也能保持原有文档格式。在去除停用词阶段, 笔者整合“哈工大停用词词表”、“四川大学机器学习停用词表”和“百度中文停用词表”, 得出一个较为全面的停用词表stopword.txt。原始文本数据预处理流程如表1所示。
表1 原始文本数据预处理示例
| 处理流程 | 内容 |
|---|---|
| 原始文本 | 那回北京飞常州, 原定20.00起飞, 流量管制到23.00登机, 结果排队起飞排了3个点, 轮到我们的时候机长亲切地说: 旅客朋友们你们好, 由于我们排队期间滑行时间过长, 飞机燃油不足需要加油, 我们将重新排队.......好气啊!! <img data-rawwidth="143" data-rawheight="89" src="https://pic1.zhimg.com/8efad7894eef191114b0e2779e98132c_b.jpg" class="content_image" width="143"> |
| 数据清洗 | 那回北京飞常州, 原定, 起飞, 流量管制到, 登机, 结果排队起飞排了个点, 轮到我们的时候机长亲切地说, 旅客朋友们你们好, 由于我们排队期间滑行时间过长, 飞机燃油不足需要加油, 我们将重新排队, , , , , , , 好气啊, , , , |
| 分 词 | 那回/ 北京/ 飞/ 常州/ 原定/ 起飞/ 流量/ 管制/ 到/ 登机/ 结果/ 排队/ 起飞/ 排/ 了/ 个/ 点/ 轮到/ 我们/ 的/ 时候/ 机长/ 亲切/ 地说/ 旅客/ 朋友/ 们/ 你们好/ 由于/ 我们/ 排队/ 期间/ 滑行/ 时间/ 过长/ 飞机/ 燃油/ 不足/ 需要/ 加油/ 我们/ 将 /重新/ 排队/ 好气/ 啊/ |
| 停用词过滤 | 那回/ 北京/ 飞/ 常州/ 原定/ 起飞/ 流量/ 管制/ 登机/ 排队/ 起飞/ 排/ 轮到/ 机长/ 亲切/ 地说/ 旅客/ 朋友/ 你们好/ 排队/ 期间/ 滑行/ 时间/ 过长/ 飞机/ 燃油/ 不足/ 需要/ 加油/ 重新/ 排队/ 好气/ |
对选取的前100个热门回答所在问题进行研究, 获取每个问题上所属的子话题, 通过数据预处理, 去重后得到184个话题, 将话题与问题建立一一映射关系, 从而形成问题共享话题网络, 也同时得到问题-话题关注矩阵。矩阵的行为100个问题的ID, 记为1,2,3···100, 列为得到的184个话题, 如生活、电子商务旅行等。如果问题属于某个话题, 则在矩阵相应位置标为T, 如果问题不属于某个话题, 则标为F, 以此得到100×184的问题-话题关注矩阵, 示例如表2所示。
通过分析问题所属子话题, 运用关联规则算法, 可以分析出热门问题所对应的相关子话题的出现规则, 同时发现不同子话题在同一问题中出现的相关性, 进而可以预测知乎上关于物流问题的话题出现的相关性, 帮助用户在提问物流相关问题时进行智能推荐。在得到问题-话题关注矩阵后, 导入SPSS Clementine软件, 创建话题关联规则的流节点。
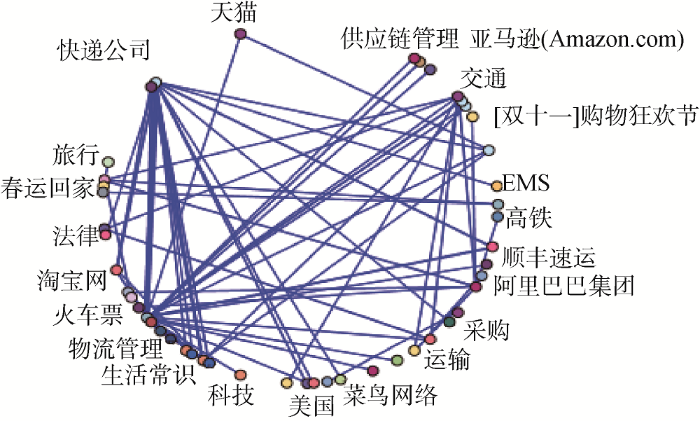
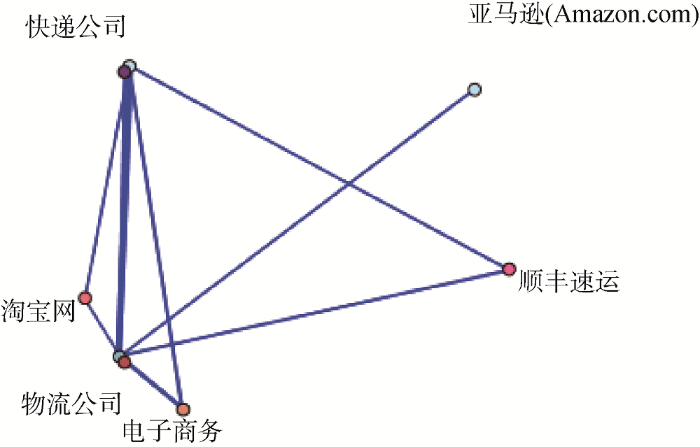
运行网络图的流节点后, 生成一个话题之间关联程度的网络图。当最小链接数为2时, 显示如图4所示, 线的粗细深浅代表联系的强弱。再调节链接数量, 当最小链接数为3时, 如图5所示, 可以直观地看到快递公司和物流公司、电子商务的联系程度比较强。
按照关联规则算法的相关计算公式, 同时设置最小规则支持度为5%, 最小规则置信度为60%。在不指定前项和后项的情况下得到4条规则, 具体如表3所示, 按照规则置信度从大到小进行排序, 置信度可以反映出预测的准确率。当中规则支持度表示项集{前项, 后项}在总项集里出现的概率, 支持度是前项在总项中出现的概率。
表3 物流问题和话题关联结果
| 规则 | 前项 | 后项 | 规则支持度(%) | 支持度(%) | 规则置信度(%) | Lift |
|---|---|---|---|---|---|---|
| 1 | 快递公司 | 快递 | 5.94 | 6.93 | 85.72 | 2.705 |
| 2 | 快递公司 | 物流 | 4.95 | 6.93 | 71.43 | 1.535 |
| 3 | 电子商务 | 物流 | 8.91 | 12.84 | 69.23 | 1.488 |
| 4 | 快递公司+快递 | 物流 | 3.96 | 5.94 | 66.67 | 1.433 |
从表3结果可以看到, 在物流话题热门问题的子话题中, 子话题前项为“电子商务”, 后项为“物流”的记录最多, 占比12.84%。而当一个问题的子话题为“电子商务”时, 另外子话题中有“物流”子话题的概率为69.23%, 表明此规则的相关性很强。Lift值是指提升值, 表示前项与后项同时出现的比例与出现后项的比例的比值, 反映了前项子话题与后项子话题的相关性, 其值越大, 规则的相关度越强。对规则进行整体性分析, 将置信度和Lift值作为选择规则的标准。
本文采用LDA模型对物流主题下回答文本进行主题划分, 并采取Gibbs抽样算法对模型进行参数估计和统计推理。其中采样迭代次数设置为100次, α和β设为0.1。调用Python代码, 在重复试验多次后, 发现当主题为7类时, 特征词在每一类的概率相对较高, 而且能较好地区分每一类主题。因此, 将主题数目设置为7个。
通过LDA基于文本主题模型提取所得到的7大主题是在物流话题下用户回答中出现频次较高, 且能代表研究主题的特征词所构成的集合。根据词语所占的概率高低进行排序。同时选择每个主题内具有最高概率的20个词语, 表4列出了7个主题和每个主题的前10个主题词。
表4 7大主题的特征词分布
| 主题 | 特征词 | 标签 |
|---|---|---|
| 1 | 司机(0.0113), 车(0.0096), 走(0.0061), 跑(0.0047), 飞机(0.0046), 开(0.0043), 看到(0.0036), 货车(0.0036), 机场(0.0030), 延误(0.0029) | 车辆运输 |
| 2 | 转运(0.0129), 公司(0.0098), 价格(0.0069), 物流(0.0067), 买(0.0063), 服务(0.0058), 比较(0.0057), 亚马逊(0.0056), 东西(0.0055), 海淘(0.0054) | 海淘 |
| 3 | 外卖(0.0155), 送(0.0122), 觉得(0.0080), 天气(0.0077), 工作(0.0073), 小哥(0.0056), 恶劣(0.0051), 不要(0.0050), 钱(0.0038), 辛苦(0.0037) | 恶劣天气 外卖 |
| 4 | 问题(0.0080), 铁路(0.0050), 北京(0.0044), 回家(0.0040), 中国(0.0035), 社会(0.0033), 春运(0.0033), 不能(0.0028), 需要(0.0027), 高铁(0.0027) | 春运铁路 |
| 5 | 物流(0.0091), 公司(0.0078), 企业(0.0073), 问题(0.0066), 采购(0.0056), 供应链(0.0055), 行业(0.0048), 成本(0.0048), 中国(0.0042), 管理(0.0042) | 物流企业 |
| 6 | 快递(0.0404), 顺丰(0.0180), 快递员(0.0097), 公司(0.0082), 东西(0.0067), 送(0.0066), 寄(0.0065), 邮政(0.0063), 电话(0.0061), 打电话(0.0054) | 快递服务 |
| 7 | 小时(0.0174), 火车(0.0126), 坐(0.0118), 硬座(0.0112), 吃(0.0077), 买(0.0071), 车厢(0.0058), 站(0.0052), 睡(0.0052), 时间(0.0050) | 坐火车 |
7大主题中, 第一个词为该主题中概率分布最高的词。第6类主题中“快递”的概率最高, 为0.0404; 次之为第7类主题, “小时”的概率为0.0174; 第4类主题, “问题”概率最小, 为0.0080。通过LDA主题模型得到的每个主题其实都可以视为知乎物流话题下回答的一个讨论热点。
(1) 内容推荐示例
通过对问题文本的话题标签进行关联分析来构建话题网络, 以及对回答文本提取其话题主题, 可以得到特定子话题下某一主题的若干关键词, 再结合用户的关注主题, 即可以针对平台用户进行更加精准的内容推荐。
通过4.2节构建的物流共享话题网络结果可知, 当用户关注“快递公司”这个子话题时, 分别有85.72%和71.43%的概率会关注“快递”和“物流”这两个子话题, 当用户关注“电子商务”这一子话题时, 有69.23%的概率会关注“物流”这一子话题, 当用户关注“快递公司+快递”这个子话题时, 有66.67%的概率会关注“物流”这个子话题。再根据4.3节回答内容的文本主题提取结果, 可得到在物流话题下用户回答中出现频次较高的若干关键词。综上, 可以向关注“快递公司”、“电子商务”、“快递公司+快递”等子话题的用户推荐关键词为“司机”、“转运”、“外卖”等相关的内容。另外, 在实际内容推荐中, 还需要根据具体的概率要求选取主题词, 并根据内容的数量要求进行相应推荐。
(2) 内容推荐模型评价
本文使用F-measure评价指标来评价内容推荐模型的推荐效果, F值越高, 则推荐效果越好[25]。相关计算如公式(2)至公式(4)所示。
$F=\frac{2\times P\times R}{P+R}$ (2)
$P=\frac{推荐并被接受的内容条数}{推荐的内容总条数}$ (3)
$P=\frac{推荐并被接受的内容条数}{用户接受的内容总条数}$ (4)
选择50个知乎平台上关注物流话题的用户, 分别基于LDA主题模型和关联规则-LDA模型内容推荐方法进行内容推荐, 并设定推荐的主题词概率阈值为0.01, 推荐的内容数量为N条。
在用户的个人信息主页中, 可以收集用户的赞同、收藏、回答、点赞等行为的动态数据, 该实验中将推荐给用户并产生行为的物流话题内容作为推荐并被用户接受的内容, 用户动态中所有属于物流话题的内容作为用户接受的内容总条数。实验结果如表5所示。
表5 LDA主题模型和关联规则-LDA模型比较
| 内容推荐方法 | N | P | R | F |
|---|---|---|---|---|
| LDA | 10 | 0.09 | 0.07 | 0.08 |
| 关联规则-LDA | 0.12 | 0.10 | 0.11 | |
| LDA | 20 | 0.13 | 0.09 | 0.11 |
| 关联规则-LDA | 0.17 | 0.13 | 0.15 | |
| LDA | 30 | 0.18 | 0.14 | 0.16 |
| 关联规则-LDA | 0.24 | 0.19 | 0.21 | |
| LDA | 40 | 0.22 | 0.20 | 0.21 |
| 关联规则-LDA | 0.28 | 0.22 | 0.25 |
根据评价结果, 可以看出随着推荐内容条数N在一定范围内逐渐增大, 基于LDA主题模型和关联规则-LDA模型内容推荐方法的P值、R值和F值均逐渐增大, 而在同一N值水平上, 关联规则-LDA模型推荐方法在P值、R值和F值上均优于一般的基于LDA主题模型的推荐方法, 因此可以认为基于关联规则-LDA模型的内容推荐方法能够为用户更精准地推荐相关内容。
本文以知乎平台为基础, 采用关联规则和LDA模型共同分析, 实现了将文本语义量化后更加精准的内容推荐。使用关联规则构建共享话题网络, 在特定话题的前提下构建子话题网络, 再利用LDA模型提取子话题下的主题词, 即结合子话题和主题词进行内容精准定位。发现快递公司与物流, 电子商务与物流, 其支持度达到6%以上, 规则置信度都达到了65%以上。未来知乎可以在用户提问时对要设置的子话题进行相关推荐, 当两个子话题相关度较高时, 可以用一个子话题代替另一个子话题, 以减少冗余。
该研究虽然具有一定的创新性, 但同时也存在局限性和不足。由于基于物流话题进行研究, 未搜集到具有代表性的知乎全网的用户数据和文本数据, 因此未来可以采用一定随机抽样方法获取知乎全网数据。当然, 也可以搜索不同话题, 分析多个话题下用户行为之间的差异。
何跃: 提出研究思路, 设计研究方案以及实验方法;
丰月: 采集、清洗和分析数据, 对文章进行整理;
赵书朋: 协助数据分析, 论文最终版本修订;
马玉凤: 协助研究思路的展开, 论文的起草。
所有作者声明不存在利益冲突关系。
支撑数据见本刊网站http://www.infotech.ac.cn。
[1] 丰月. 2016年12月知乎平台文本数据. excel. 个人用户数据汇总.
[2] 丰月. 2016年12月知乎平台物流话题. excel. 精华问题汇总.
| [1] |
在线问答社区用户研究综述 [J].Review of Online Q & A Community Users [J]. |
| [2] |
UGC网站用户画像研究 [J].User Portrait Study on UGC Website [J]. |
| [3] |
Research Agenda for Social Q&A [J]. |
| [4] |
Using Hybrid Kernel Method for Question Classification in CQA [C]// |
| [5] |
An Evaluation of Classification Models for Question Topic Categorization [J].https://doi.org/10.1002/asi.v63.5 URL [本文引用: 1] |
| [6] |
Community Question Topic Categorization via Hierarchical Kernelized Classification [C]// |
| [7] |
基于词袋模型的关联数据融合算法改进研究 [J].Improvement of Linked Data Fusion Algorithm Based on Bag of Words [J]. |
| [8] |
基于LDA主题模型的图书网页书目信息提取研究 [J].Bibliographic Information Extraction Research of Book Pages Based on the LDA Theme Model [J]. |
| [9] |
Large-scale Question Classification in CQA by Leveraging Wikipedia Semantic Knowledge [C]// |
| [10] |
Routing Questions for Collaborative Answering in Community Question Answering [C]// |
| [11] |
Improving Search Relevance for Short Queries in Community Question Answering [C]// |
| [12] |
Who is Authoritative? Understanding Reputation Mechanisms in Quora [C]// |
| [13] |
Knowledge Market Design: A Field Experiment at Google Answers [J].https://doi.org/10.1111/jpet.2010.12.issue-4 URL [本文引用: 1] |
| [14] |
Seekers, Sloths and Social Reference: Homework Questions Submitted to a Question-Answering Community [J].https://doi.org/10.1080/13614560701711917 URL [本文引用: 1] |
| [15] |
虚拟社区用户知识共享行为影响因素研究 [J].
以 Web of Science 和 CSSCI 为数据来源, 采用文献调研法收集虚拟社区用户知识共享行为研究相关文献。归纳出研究虚拟社区用户知识共享行为的12个基础理论, 并在相关研究成果基础上提出虚拟社区用户知识共享行为研究框架。分析了目前关于虚拟社区用户知识共享行为研究已经取得的成果, 并提出未来研究需要验证的影响虚拟社区用户知识共享行为的因素和关系。
Exploring Influencing Factors of User Knowledge Sharing Behavior in Virtual Communities [J].
以 Web of Science 和 CSSCI 为数据来源, 采用文献调研法收集虚拟社区用户知识共享行为研究相关文献。归纳出研究虚拟社区用户知识共享行为的12个基础理论, 并在相关研究成果基础上提出虚拟社区用户知识共享行为研究框架。分析了目前关于虚拟社区用户知识共享行为研究已经取得的成果, 并提出未来研究需要验证的影响虚拟社区用户知识共享行为的因素和关系。
|
| [16] |
Discovering Authorities in Question Answer Communities Using Link Analysis [C]// |
| [17] |
Microcollaborations in a Social Q&A Community [J].https://doi.org/10.1016/j.ipm.2009.10.007 URL [本文引用: 1] |
| [18] |
一种自适应的协作过滤图书推荐系统研究 [J].https://doi.org/10.3969/j.issn.1002-1965.2008.05.033 URL [本文引用: 1] 摘要
在知识大爆炸、信息高速发展的年代,如何快速地将用户感兴趣或是对用户有用的信息反馈给用户是本文要解决的问题。通过介绍传统的协作过滤方法,分析其特点以及存在的不足,并基于此提出一种自适应的协作过滤图书推荐系统,以期帮助用户快速地找到需要的书籍条目。
Research on the Adaptive Collaborative Filtering Recommendation System [J].https://doi.org/10.3969/j.issn.1002-1965.2008.05.033 URL [本文引用: 1] 摘要
在知识大爆炸、信息高速发展的年代,如何快速地将用户感兴趣或是对用户有用的信息反馈给用户是本文要解决的问题。通过介绍传统的协作过滤方法,分析其特点以及存在的不足,并基于此提出一种自适应的协作过滤图书推荐系统,以期帮助用户快速地找到需要的书籍条目。
|
| [19] |
Ontology-Based News Recommendation [C]// |
| [20] |
Collaborative Topic Regression with Social Trust Ensemble for Recommendation in Social Media Systems [J].https://doi.org/10.1016/j.knosys.2016.01.011 URL [本文引用: 1] |
| [21] |
TWILITE: A Recommendation System for Twitter Using a Probabilistic Model Based on Latent Dirichlet Allocation [J].https://doi.org/10.1016/j.is.2013.11.003 URL [本文引用: 1] |
| [22] |
Labeled LDA: A Supervised Topic Model for Credit Attribution in Multi-labeled Corpora [C]// |
| [23] |
McCallum A. Topics over Time: A Non-Markov Continuous-time Model of Topical Trends [C]// |
| [24] |
Latent Dirichlet Allocation [J]. |
| [25] |
面向C2C在线情景的一种个性化三维推荐方法 [J].A Personalized Three-dimensional Recommendation Method for C2C Online Context [J]. |

/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}