张涛 , 马海群
, 马海群
Zhang Tao, Ma Haiqun
中图分类号: 分类号: TP391
通讯作者:
收稿日期: 2018-03-12
修回日期: 2018-03-12
网络出版日期: 2018-09-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】利用LDA主题模型有效提升政策文本聚类精准度。【方法】通过对政策文本模拟数据的预处理、导入政策词表、LDA模型生成基础数据、利用加权算法进行文本计算等步骤对政策文本聚类。【结果】实验数据表明: k=4时, 加权后的政策文本聚类结果G值最大, 与初始人工分类数量吻合, Purity值和F值较高, 因此验证该方法是合理有效的。【局限】实验中每步操作结果的精度都会对政策文本聚类的准确性产生影响。【结论】通过运用该方法的整体性设计, 可对未来新政策的制定及对已有政策的反向评价检验和双向互动生成机制的形成提供借鉴。
关键词:
Abstract
[Objective] This research aims to improve the effectiveness of clustering policy texts with the help of LDA topic model. [Methods] First, we pre-processed the policy texts with the LDA model to generate the training data set. Then, we used the weighted algorithm to determine the optimal number of topics and then clustered the policy texts. [Results] We found that the G value of the weighted clustering results reached peak while the k value was 4. Our results, which were consistent with those of the manual classification, also obtained higher purity and F values. Therefore, the proposed method is effective. [Limitations] Results of each operation in our study will influence the accuracy of the final policy text clustering. [Conclusions] The proposed method could provide directions for the making of new policies, the evaluation of current policies, and the mechanism of two-way interactions.
Keywords:
政策文本是一类特殊文本形式, 它是在政策制定与实施中所产生的过程性文件, 主要包含三个层面内容: 各级权力或行政机关以文件形式颁布的法律、法规、规章制度等官方文献; 政策制定者或政治领导人在政策制定过程中形成的研究、咨询或决议等资料; 政策实施过程中相关演说、报道、评论等。政策文本是政策协同研究的重要工具和载体[1]。
文本聚类的最初提出主要依据著名的聚类假设: 同类文档相似度大, 不同类文档相似度小[2]。文本聚类是利用相似度概念将文本划分成若干个有意义的簇, 从而对样本进行分簇操作, 其目的是为了加快文本检索速度, 提高检索精度。随着机器语言学习技术的快速发展, 政策文本研究多借助技术手段[3], 文本聚类就成为政策文本研究领域一个重要方向。由于政策文本具有数据量大、规范严谨、数据多样性的特点, 而且在不同语境下政策词语的内涵差别较大[4], 因此采用传统聚类方法无法解决数据稀疏及隐含在词语背后的语义的问题, 对政策文本中存在的同义词和多义词更加无法有效判定[5]。在实际政策文本中, 同一含义的词语往往会有多种政策用词, 因此语义分析就成为提高聚类精准度的重要环节, 而语义分析的利器是构建主题模型。
LDA利用词语、主题、文本之间的关系解决文本聚类中语义挖掘的问题[6]。引入Dirichlet分布的概念, 在满足Dirichlet先验分布的多项式分布基础上, 所有主题对应相应文档, 通过不停地迭代, 可以估计合理参数。LDA模型的联合概率具体表示如公式(1)[7]所示。
$p(\theta ,z,w|\alpha ,\beta )=p(\theta |\alpha )\prod\limits_{n=1}^{N}{p({{z}_{n}}|\theta )p({{w}_{n}}|{{z}_{n}},\beta )}$ (1)
政策文本聚类的核心要义在于根据政策活动本身所产生的客观意义上的记录文献, 实现政府间、多政府部门间政策协同及辅助政策制定者提升政策制定的科学性和有效性。政策文本聚类的关键在于通过引入政策词表提升政策分词的准确度, 同时通过优化聚类算法减少操作误差提升聚类结果的精确度。因此, 本文提出一种基于LDA主题模型的政策文本聚类方法, 以期为新政策制定、政策评价检验和双向互动生成机制的形成提供借鉴。
国内外相关学者针对于主题模型及聚类方法开展大量的研究工作, 文献研究证实文本聚类结果与主题抽取有直接关系, 主要包括三类方法。
(1) Deerwester等[8]提出LSA(Latent Semantic Analysis)模型, 主要用于挖掘文本与词语之间潜在的语义关联。随后Hofmann[7]对LSA进行改进, 提出PLSA(Probabilistic Latent Semantic Analysis)模型, 是对LSA的延伸, 用概率模型的方式对文本进行聚类能够有效避免复杂计算。但是PLSA概率模型不够完备, 随着文本和词语个数的增加, 模型变得十分庞大, 计算也变得更复杂。
(2) Blei等[9]提出基于LDA(Latent Dirichlet Allocation)主题模型的聚类方法, 通过选取困惑度(Perplexity)[10]指标确定主题的最优数目, 从而对文本进行聚类, 但该方法选取的主题数目往往过大, 致使抽取的主题之间有较高的相似度, 从而影响政策制定及政策评价检验的效率。
(3) LDA模型结合其他方法对文本进行聚类, 如曹娟等[11]提出一种基于密度的自适应最优LDA模型选择方法, 证明当主题之间的相似度最小时模型最优; 王鹏等[12]提出基于LDA 模型利用Jensen-Shannon距离作为文本的相似性度量, 采用层次聚类法进行聚类; 王婷婷等[13]利用LDA和Word2Vec模型形成相关性的T-WV矩阵, 并将传统LDA模型的主题数目选择问题转化为聚类效果评价问题, 计算主题聚类数目的最优解; 阮光册等[14]利用聚类中心最近的主题的描述词作为聚类标签进行文本聚类。但以上研究普遍存在模型复杂度高且研究方法局限于某些主题等问题。
综上所述, 国内外对文本聚类的研究较多, 而对政策文本聚类的研究相对较少, 本文基于政策文本的特点并结合文本聚类中存在的问题, 通过引入政策词表及LDA模型加权算法的方式, 提升政策文本聚类的精准度。
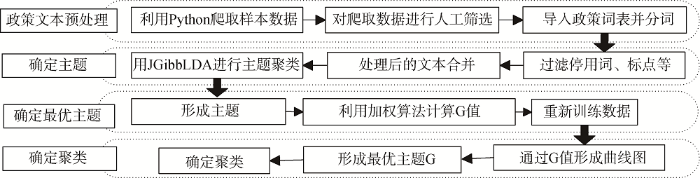
政策文本聚类主要包括文本预处理、确定主题数量、确定最优主题、最优聚类等环节, 图1为政策文本聚类流程。
政策文本具有严谨、规范等特点, 因此在预处理过程中需要导入政策词表, 预处理过程主要包括以下步骤。
(1) 收集政策文本相关语料;
(2) 对政策文本进行人工筛选;
(3) 导入政策词表;
(4) 对政策文本语料进行分词处理, 该步骤尽量做到精准;
(5) 对政策文本进行剔除停用词、标点、标注处理;
(6) 形成待处理政策文本。
政策文本语料的选择与数据预处理是文本聚类的最重要环节之一, 文本聚类结果的精度及效率都与该过程有着密切相关, 因此从政策文本语料的选择-分词-去停用词的每步操作都要保证结果最优, 这样才可能最大限度保证实验结果的准确性。
基于LDA主题模型所形成的基础数据, 通过计算确定主题数量。在LDA模型中确定主题数量是一个困难的问题, 传统采用按经验设置主题数量, 根据数据量的大小估算, 此方式合理性较差, 如何科学地确定主题数是研究关键, 本文通过计算文本-主题最大平均分布概率和主题-词语平均相似度概率的加权数值的方法确定最优主题数量[15], 具体过程如下。
参数设置: d代表文本, n代表文本数, z代表主题, w代表主题词, k代表主题数目, 设dn是文本集D中的一个文本, 如公式(2)所示, zk是主题集合Z中的一个主题, 如公式(3)所示, E代表主题与文本最大平均分布概率, T代表主题间平均相似度, G代表加权后的主题间的相似度。
D={d1, d2, d3,···dn} (2)
Z={z1, z2, z3,···zk} (3)
①设定主题个数为k, 得到初始模型。
②通过公式(1)计算得出主题与文本的分布概率和词语在主题上的分布概率。
③本文提出利用最大平均值的方法获取主题与文本最大平均分布概率, 如公式(4)所示, 并得出E值。
E = $\frac{1}{n}\sum\limits_{n}{\text{max }\!\!\{\!\!\text{ }p\text{(}{{z}_{i}}\text{ }\!\!|\!\!\text{ }{{d}_{n}}):i=\text{1,}\cdots \text{,}k\text{ }\!\!\}\!\!\text{ }}$ (4)
④利用余弦相似性定理计算主题与主题之间的平均相似度[16]。t代表主题矩阵, j代表文本中词的数量, m代表语料集中去重后词语总数, 公式(5)主要基于余弦相似性定理计算两个主题相似度。
sim(z1,z2) =$\frac{\sum\limits_{j=1}^{m}{{{t}_{1j}}\ {{t}_{2j}}}}{\sqrt{\sum\limits_{j=1}^{m}{t_{1j}^{2}}}\sqrt{\sum\limits_{j=1}^{m}{t_{2j}^{2}}}}$ (5)
本文提出通过计算一维数组的平均相似度的方法得到多主题相似度, 如公式(6)所示, 并最终得到T值。
$\begin{align} & T=\frac{2}{k(k-1)}\sum\limits_{k(k-1)/2}{\text{ }\!\!\{\!\!\text{ sim(}{{z}_{\text{1}}}\text{,}{{z}_{\text{2}}}\text{),}\ \text{sim(}{{z}_{1}}\text{,}{{z}_{\text{3}}}\text{),}} \\ & \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \text{sim(}{{z}_{\text{2}}}\text{,}{{z}_{\text{3}}}\text{)}\cdots \text{ sim(}{{z}_{k-\text{1}}}\text{,}{{z}_{k}}\text{) }\!\!\}\!\!\text{ } \\ \end{align}$ (6)
⑤对公式(4)和公式(6)数值进行加权, 形成加权后的G值, 如公式(7)所示。
G = $\frac{E}{T}$ (7)
⑥调整k值, 对政策文本进行重新训练。
⑦重复步骤②, 当G值最大, 即得到最优k值。
定义1: 每个文本对应一个出现概率最高的特征主题, 由所有出现概率最高特征主题的平均概率加权主题间平均相似度得到最大值作为文本的最优聚类。
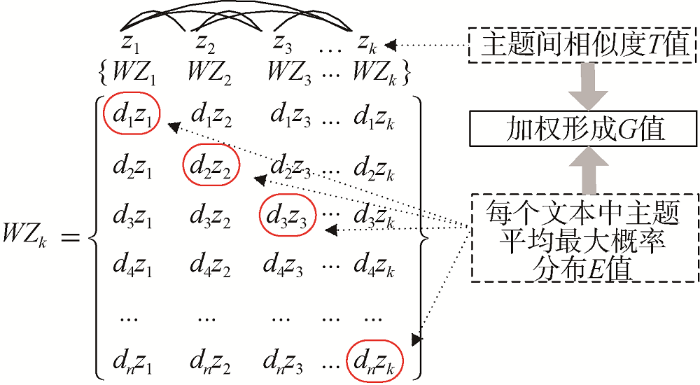
假设: W表示文本和主题概率的二维矩阵[17], 如公式(8)所示。
W= DT×Z =$\left\{ \begin{matrix} {{d}_{1}}{{z}_{1}} & {{d}_{1}}{{z}_{2}} & {{d}_{1}}{{z}_{3}} & ... & {{d}_{1}}{{z}_{k}} \\ {{d}_{2}}{{z}_{1}} & {{d}_{2}}{{z}_{2}} & {{d}_{2}}{{z}_{3}} & ... & {{d}_{2}}{{z}_{k}} \\ {{d}_{3}}{{z}_{1}} & {{d}_{3}}{{z}_{2}} & {{d}_{3}}{{z}_{3}} & ... & {{d}_{3}}{{z}_{k}} \\ {{d}_{4}}{{z}_{1}} & {{d}_{4}}{{z}_{2}} & {{d}_{4}}{{z}_{3}} & ... & {{d}_{4}}{{z}_{k}} \\ ... & ... & ... & ... & ... \\ {{d}_{n}}{{z}_{1}} & {{d}_{n}}{{z}_{2}} & {{d}_{n}}{{z}_{3}} & ... & {{d}_{n}}{{z}_{k}} \\\end{matrix} \right\}$ (8)
在W行向量中选取文本中出现概率最高的主题, 如图2所示, 通过1到n的循环, 最终在通过与主题相似度加权确定文本聚类。
在文本聚类过程中, 每个文本会对应多个主题, 但是每个文本会对应一个出现概率最高的特征主题, 通过计算这个特征主题最大概率平均值, 就可以确定E值。通过词语在主题上被选中的概率计算主题间的相似度, 每个主题间平均相似度为T值, T值越小, 主题间相似度越低, 说明聚类越优, 反之聚类则越差。本文设想利用一种E值和T值加权后的聚类方法形成G值, 不断训练出最大G值, 最终确定最优聚类。
对于评估政策文本聚类效果, 采用Purity值和F值做为评价指标[18]。
(1) Purity值计算方法相对简单但适用性较强, 具体公式如下。
Purity(Ω,D)= $\frac{1}{N}\sum\limits_{k}{\text{max }\!\!|\!\!\text{ }{{\omega }_{k}}\bigcap {{d}_{j}}|}$ (9)
其中, Ω={ω1,ω2,ω3···ωk}是聚类的集合, ωk 表示第k个聚类的集合。D={d1,d2,d3···dj}是文本的集合, dj表示第j个文本。该方法只计算正确聚类的文本占总文本的数量, Purity值介于0-1间, 该值越高代表聚类效果越好, 反之则越差。
(2) F值(F-Score)用于定量评价, 主要包括查准率P(Precision)、查全率R(Recall)[19], 如公式(10)-公式(12)所示。查准率用以评估抽取的有效主题中正确主题所占的比例, 查全率用以评估抽取的正确主题占评判的领域研究主题的比例, 而F值(F-Score)为二者的调和平均值。
$P(Precision)=\frac{TP}{TP+FP}$ (10)
$R(Recall)=\frac{TP}{TP+FN}$ (11)
$F(F\text{-}score)=\frac{2PR}{P+R}$ (12)
本实验通过Python在百度搜索引擎中按照信息安全、体育、旅游、文化等类目, 抽样爬取出部分开放的政策文本语料, 从中选取50篇施政过程中的报道、评论相关文本, 实验目的是通过LDA主题模型对这些政策文本进行有效聚类, 具体操作过程如下。
(1) 导入政策词表, 通过收集整理相关领域政策关键词所形成的词表;
(2) 利用ICTCLAS[20]对采样文本进行分词, 分词的精确度对聚类结果有重要影响;
(3) 进行去除停用词、词性、标点等操作;
(4) 形成分词后的政策文本样本;
(5) 把处理后的政策文本文档导入LDA模型。
实验使用开源软件JGibbLDA实现, 在LDA模型中α设置为50/k, β设置为0.01, 主题数目k从2-50每隔固定数值开始训练, 采样数设置为1 000, 迭代次数设置为1 000, 关键词设置为20[21]。通过LDA模型生成基础数据后, 按照公式(4)-公式(8), 利用Java语言进行程序设计, 最终形成实验结果数据[22]。
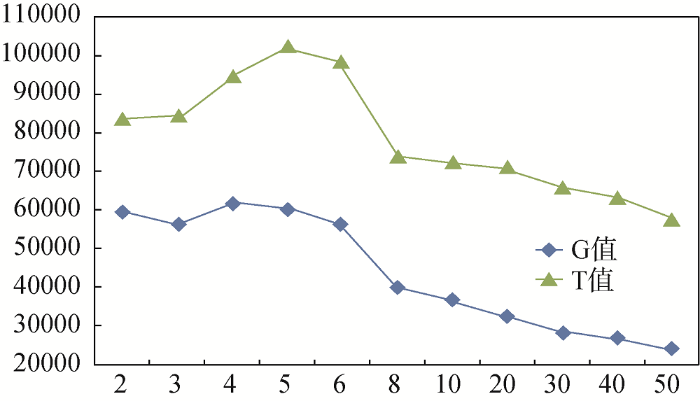
通过实验结果数据分析, 如图3所示, 横坐标代表k值, 纵坐标代表G值和T值, k从2到50不断重复训练, 当k=4时G=62 074, 数值最大, 随后随着k值逐渐增加, G值逐渐减小至收敛, 因此证实该样本最优主题数为4, 最优主题数确定与政策文本语料的预初始化有直接关系。
在主题挖掘结果中选取部分分布概率较大的词语, 如表1所示。可见, 每个主题区分比较明显。
表1 主题挖掘结果
| 主题1 | 主题2 | 主题3 | 主题4 |
|---|---|---|---|
| 旅游0.0213613 | 信息安全 0.0204932 | 传统 0.0323346 | 体育 0.0316222 |
| 城市0.0099187 | 数据 0.0168339 | 工艺 0.0225906 | 发展 0.0255651 |
| 发展0.0087745 | 信息 0.0133837 | 计划 0.0172757 | 工作 0.0160342 |
| 休闲0.0082023 | 技术 0.0126518 | 文物 0.0168327 | 建设 0.0097989 |
| 注意0.0076302 | 大数据 0.0116063 | 专业 0.0148396 | 体育产业 0.0096209 |
| 消费0.0066767 | 网络 0.0116063 | 传承人 0.0135109 | 社会 0.0075722 |
| 过程0.0061045 | 数据安全 0.0101426 | 技艺 0.0124036 | 国家 0.0071268 |
| 适应0.0059138 | 企业 0.0086788 | 青瓷 0.0115178 | 学校 0.0070377 |
| 环境0.0057231 | 系统 0.0085743 | 艺术 0.0104105 | 开展活动 0.0063251 |
主题1中分类是旅游、城市、休闲等相关词语; 主题2中分类是信息安全、大数据、数据安全相关的词语; 主题3中分类是传统、工艺、文物等相关的词语; 主题4中分类是体育、体育产业相关的词语。从表1可以看到有部分与主题不相符的特征词, 如: 主题1中的“注意”、“过程”, 主题3中的“计划”, 主题4中的“发展”和“工作”等, 这与模型参数设定及政策文本语料预初始化有关系。
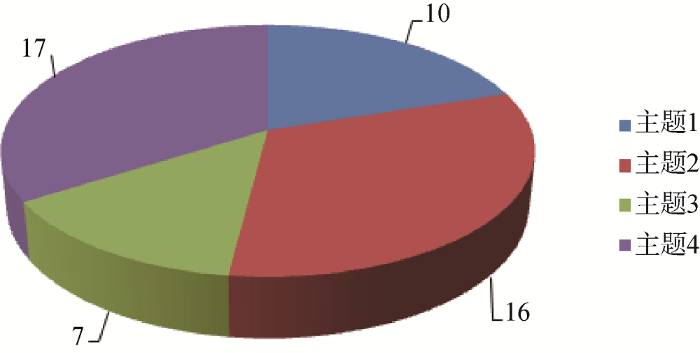
图4为当k=4主题与文本聚类图, 文本在主题上最大分布概率超过90%, 是样本30与主题4之间的概率关系, 说明主题与文本契合度极高, 通过寻找契合度高的文本集, 就可以快速索引到这一聚类下的所有文本。最小概率为0.3589, 是样本38与主题1之间的概率关系, 在该文本上与主题4的分布概率是0.3435, 说明该文本中包含两个出现概率较高的主题, 政策制定者可以通过此类文档寻找差异性关键词, 是主题和文本确实不相关, 还是政策文本存在不同主题间的存在一定的协同关系。图4中有10个文本归属于主题1, 16个文本归属于主题2, 7个文本归属于主题3, 17个文本归属于主题4。如果测试的文本集较大, 利用此方法还可以实现大规模文本的降维, 对降维后的结果重复该模型, 再次形成细化聚类。
通过计算LDA主题模型中的Purity值和F值(F-Score)作为聚类评价指标, 如果文本和主题吻合度较高, 判定聚类正确。采用加权后的文本聚类结果为k=4时, G值最大, 与初始分类数量吻合。通过计算k=4时Purity值、P、R和F值。最终计算得出Purity值为0.88, F值为0.83。聚类结果如图5所示。
利用LDA模型中计算T值相似度的方法进行聚类, 当k=5时, T值最大, 与人工对比聚类结果, 与初始4个分类存在偏差。通过Perplexity指标进行聚类, 此方法聚类结果数值过大, 和原始分类偏差较大。
因此, 基于Purity值和F值的计算及与其他LDA聚类方法对比分析, 可证实该方法合理有效且效果较好。
本文旨在通过加权LDA模型中数据处理算法, 提出一种新的政策文本聚类方法, 使其更好地服务于政策的解读与分析。政策文本是一种特殊文本类型, 因此对政策文本分析要从政策语料库构建、政策概念词表收集、政策文本主题分析等方面进行深入研究。LDA模型可以对政策文本集进行降维处理, 尤其针对采样数据量大的文本, 降维之后再套模型, 这样可以大大减少计算量且提高执行效率, 并可以实现精细聚类。本文提出一种基于文本-主题最大平均分布概率和主题-词语平均相似度概率的加权数值的方法对政策文本进行聚类, 最后通过数据分析及评价指标数值验证该方法合理有效且效果较好。希望未来能有更多的研究者通过大规模政策文本语料对此方法进行优化、验证和改进。
政策文本精准聚类有助于提升政策协同效率。政策协同是政策制定过程中的一项重要内容, 它要确保协商机制、信息交流和共享机制等方面的内在一致性, 使跨区域政策比较具备可行性, 政策协同研究可以减少政策制定的失误率。政策文本精准聚类为政策制定起指导及科学预测的作用, 并为政策制定提供技术层面的支撑, 通过聚类后的文本分析可使政策制定更加科学化, 也可对已有政策执行效果进行考量, 避免出现政策缺失及不客观的现象。政策文本聚类有助于提升政策协同效率, 可促使政策文件双向互动机制的形成, 并为已制定的政策文件反向评价检验提供借鉴。
LDA主题模型具有较强的扩展性, 该模型的应用对政策协同和政策评价有着重要科学指导意义, 在未来工作中将基于该模型继续在政策情感分析、政策协同分析、政府行为预测等方面做更精细化的研究。
张涛: 提出研究方法, 进行实验, 论文起草和修订;
马海群: 设计总体思路, 审阅并修改论文。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: zhangtao@hlju.edu.cn。
[1] 张涛. test. txt. 分词、去重、去停用词后的LDA测试文档.
[2] 张涛. data. xls. LDA模型计算后的数据.
| [1] |
政策文本计算: 一种新的政策文本解读方式 [J].Policy Text Computing: A New Methodology of Policy Interpretation [J]. |
| [2] |
|
| [3] |
Information Retrieval Models: A Survey [J]. |
| [4] |
用文献计量研究重塑政策文本数据分析——政策文献计量的起源、迁移与方法创新 [J].Remolding the Policy Text Data Through Documents Quantitative Research: The Formation, Transformation and Method Innovation of Policy Documents Quantitative Research [J]. |
| [5] |
一种政策语篇拟合度递归下降评估算法 [J].Recursive Descent Evaluation Algorithm on Policy Context Similarity [J]. |
| [6] |
Summarization of Changes in Dynamic Text Collections Using Latent Dirichlet Allocation Model [J].https://doi.org/10.1016/j.ipm.2015.06.002 URL [本文引用: 1] |
| [7] |
Unsupervised Learning by Probabilistic Latent Semantic Analysis [J].https://doi.org/10.1023/A:1007617005950 URL [本文引用: 2] |
| [8] |
Indexing by Latent Semantic Analysis [J].https://doi.org/10.1002/(ISSN)1097-4571 URL [本文引用: 1] |
| [9] |
Latent Dirichlet Allocation [J]. |
| [10] |
Finding Scientific Topics [J].https://doi.org/10.1073/pnas.0307752101 URL [本文引用: 1] |
| [11] |
一种基于密度的自适应最优LDA模型选择方法 [J].https://doi.org/10.3321/j.issn:0254-4164.2008.10.012 URL [本文引用: 1] 摘要
主题模型(topic models)被广泛应用在信息分类和检索领域.这些模型通过参数估计从文本集合中提取一个低维的多项式分布集合,用于捕获词之间的相关信息,称为主题(topic).针对模型参数学习过程对主题数目的指定和主题分布初始值非常敏感的问题,作者用图的形式阐述了LDA(Latent Dirichlet Allocation)模型中主题产生的过程,提出并证明当主题之间的相似度最小时模型最优的理论;基于该理论,提出了一种基于密度的自适应最优LDA模型选择方法.实验证明该方法可以在不需要人工调试主题数目的情况下,用相对少的迭代,自动找到最优的主题结构.
A Method of Adaptively Selecting Best LDA Model Based on Density [J].https://doi.org/10.3321/j.issn:0254-4164.2008.10.012 URL [本文引用: 1] 摘要
主题模型(topic models)被广泛应用在信息分类和检索领域.这些模型通过参数估计从文本集合中提取一个低维的多项式分布集合,用于捕获词之间的相关信息,称为主题(topic).针对模型参数学习过程对主题数目的指定和主题分布初始值非常敏感的问题,作者用图的形式阐述了LDA(Latent Dirichlet Allocation)模型中主题产生的过程,提出并证明当主题之间的相似度最小时模型最优的理论;基于该理论,提出了一种基于密度的自适应最优LDA模型选择方法.实验证明该方法可以在不需要人工调试主题数目的情况下,用相对少的迭代,自动找到最优的主题结构.
|
| [12] |
基于LDA模型的文本聚类研究 [J].
在Web2.0时代,网络文本数据呈现爆炸式增长,传统的文本聚类模型存在数据维数过高,数据稀疏,缺乏语义理解等问题。针对以上问题,本文提出了一种基于LDA模型,通过Gibbs算法估计文本的主题概率分布,利用JS(Jensen-Shannon)距离作为文本的相似性度量,然后采用层次聚类法进行聚类。实验得到较高的聚类纯度(Purity)和Fscore值,表明该方法是有效的。
Research on LDA Model Based on Text Clustering [J].
在Web2.0时代,网络文本数据呈现爆炸式增长,传统的文本聚类模型存在数据维数过高,数据稀疏,缺乏语义理解等问题。针对以上问题,本文提出了一种基于LDA模型,通过Gibbs算法估计文本的主题概率分布,利用JS(Jensen-Shannon)距离作为文本的相似性度量,然后采用层次聚类法进行聚类。实验得到较高的聚类纯度(Purity)和Fscore值,表明该方法是有效的。
|
| [13] |
LDA模型的优化及其主题数量选择研究——以科技文献为例 [J].Optimizing LDA Model with Various Topic Numbers: Case Study of Scientific Literature [J]. |
| [14] |
基于主题模型的检索结果聚类应用研究 [J].Research on Clustering of Retrieval Results Based on Topic Model [J]. |
| [15] |
科技情报分析中LDA主题模型最优主题数确定方法研究 [J].Identifying Optimal Topic Numbers from Sci-Tech Information with LDA Model [J]. |
| [16] |
基于LDA 的中文词语相似度计算 [J].Chinese Word Similarity Computing Based on the Latent Dirichelet Allocation(LDA) Model [J]. |
| [17] |
一种基于加权LDA模型和多粒度的文本特征选择方法 [J].A Text Feature Selection Method Based on Weighted Latent Dirichlet Allocation and Multi-granularity [J]. |
| [18] |
聚类质量的评价方法 [J].Method of Quality Evaluation for Clustering [J]. |
| [19] |
查全率与查准率之间关系的理论研究 [J].Theoretical Study of the Relationship Between Recall and Precision Ratio [J]. |
| [20] |
ICTCLAS2016 [EB/OL].[ |
| [21] |
基于LDA模型的文本分类研究 [J].https://doi.org/10.3778/j.issn.1002-8331.2011.13.043 URL Magsci [本文引用: 1] 摘要
针对传统的降维算法在处理高维和大规模的文本分类时存在的局限性,提出了一种基于LDA模型的文本分类算法,在判别模型SVM框架中,应用LDA概率增长模型,对文档集进行主题建模,在文档集的隐含主题-文本矩阵上训练SVM,构造文本分类器。参数推理采用Gibbs抽样,将每个文本表示为固定隐含主题集上的概率分布。应用贝叶斯统计理论中的标准方法,确定最优主题数T。在语料库上进行的分类实验表明,与文本表示采用VSM结合SVM,LSI结合SVM相比,具有较好的分类效果。 <BR>
Research on Text Categorization Based on LDA [J].https://doi.org/10.3778/j.issn.1002-8331.2011.13.043 URL Magsci [本文引用: 1] 摘要
针对传统的降维算法在处理高维和大规模的文本分类时存在的局限性,提出了一种基于LDA模型的文本分类算法,在判别模型SVM框架中,应用LDA概率增长模型,对文档集进行主题建模,在文档集的隐含主题-文本矩阵上训练SVM,构造文本分类器。参数推理采用Gibbs抽样,将每个文本表示为固定隐含主题集上的概率分布。应用贝叶斯统计理论中的标准方法,确定最优主题数T。在语料库上进行的分类实验表明,与文本表示采用VSM结合SVM,LSI结合SVM相比,具有较好的分类效果。 <BR>
|
| [22] |
基于LDA模型的移动投诉文本热点话题识别 [J].Identifying Hot Topics from Mobile Complaint Texts [J]. |

/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}