
 , 龙志昕, 王菲菲
, Long Zhixin, Wang Feifei
, 龙志昕, 王菲菲
, Long Zhixin, Wang Feifei
【目的】对新兴主题关联机会的发现方法进行实验性研究, 提供一种有效的新兴主题关联机会发现方法。【方法】以深度学习研究领域发表的文献集合为研究对象, 通过LDA主题模型方法挖掘文献内在特征, 进而以主题为节点, 通过链路预测对新兴主题关联机会进行预测。【结果】深度学习研究领域主题共现网络的最优指标为AA指标; 未来深度学习领域的大数据分析研究最有可能与生物医疗领域主题研究及深度学习算法自身机理改进主题研究产生关联。【局限】链路预测方法对连通性较差的网络预测结果欠佳。【结论】利用主题模型与链路预测相结合的方法进行未来新兴主题关联机会发现具有一定的有效性与可靠性。
[Objective] This paper proposes a new method to discover collaboration opportunities from emerging issues. [Methods] We used literature corpus of deep learning as the research object. Firstly, we explored the intrinsic characteristics of these literature with the LDA topic model. Then, we calculated their weights, and used topics as nodes to build topic co-occurrence network. Finally, we applied link prediction to find the potential opportunities. [Results] The optimal index of topic co-occurrence network in deep learning was AA. The big data analysis research in deep learning were more likely associated with the biomedical studies and the improvement of related algorithms. [Limitations] Link prediction generated poor results for badly connected networks. [Conclusions] The LDA topic model and link prediction method could help us find new collaboration opportunities from emerging issues.
随着大数据时代的到来, 科研活动中学科交叉现象愈发频繁, 从海量信息中高效掌握领域研究前沿、探索领域新兴主题与新兴主题关联机会也愈发困难。通过科学手段对未来可能发生关联的主题进行关联发现研究, 可以避免在单一学科主题领域中科研过度专业化而导致的“知识分裂”[1], 解决跨学科领域的主题科研合作选择过程中跨学科领域知识匮乏的问题, 有理由相信建立新的新兴主题关联将大大增加科研合作机会的发现, 产生新的科研合作成果。
近年来, 新兴主题发现的研究受到越来越多关注, 成为信息管理、情报研究和文本挖掘等相关领域的研究热点[2]。新兴主题指一个领域中重要的、处于成长阶段但还不是研究热点的主题[3], 研究方法主要有文献计量法、共引聚类网络分析法以及机器学习法[4]。Morris等[5]以炭疽主题相关的文献为研究对象, 通过对文献集群时间线的构造、探索和解释从而发现新兴主题。张晗等[6]通过共词分析与主题聚类对生物信息学关键词进行聚类, 识别出生物信息学研究热点。Chen[7]应用CiteSpace工具对发现的新兴主题进行可视化, 进而研究新兴主题发展趋势。吴霞等[8]详细阐述了共词分析法及共引网络法的发展历程与一般应用流程, 揭示这两种方法在知识挖掘领域的有效性。殷蜀梅[9]比较分析新兴主题研究趋势的多种指标方法, 主要包括文献计量法、神经网络法及文献共引聚类网络分析法, 认为获得更好的新兴研究趋势探测效果有赖于信息抽取和命名实体识别技术。靖继鹏等[10]通过关键词等外部信息, Glänzel[11]通过文献耦合分析、文本挖掘以及核心文献的互相引用, Guo 等[12]通过突现词, Tu等[3]应用新颖性指数(Novelty Index, NI)和公布的容积指数(Published Volume Index, PVI), 黄鲁成等[13]基于文献多属性测度模型, 继承并发展以往文献计量、共引网络等方法, 相继对新兴主题识别做出卓越 贡献。
知识关联指知识单元(包括文献、概念、主题等)之间存在的各种关系的总和[14]。这种关联在不同科学主题之间、科研实体之间以及科学主题与科学实体之间普遍存在。揭示和利用知识关联是知识组织、知识管理、知识发现和知识创造的起点[15,16]。目前知识关联挖掘的研究已渗透到信息处理分析理论及应用研究过程的各个环节, 在知识分类、知识组织、知识检索、知识发现、知识网络、知识地图和知识图谱等应用过程中均发挥着至关重要的作用[17]。但知识关联通常具有累积性、动态性、隐性、间接性等特点, 新知识的引入使原有知识结构和知识关联不断改变并推陈出 新[18]。复杂的知识关联关系通常无法用事先规定的知识符号系统来表达和反映, 需要利用一些科学方法、信息技术和知识工具挖掘这些潜在的知识关联。情报学、信息管理和计算机科学等领域均已在基于知识关联的知识发现和挖掘研究中取得了一定研究成果。如温有奎等[19]利用知识元间共引关系建立知识元模型挖掘隐含关联关系, 发现了脑疾病与饮食领域间的关联关系。张玲玲等[20]通过对关联规则结果的二次挖掘, 有效地减少关联规则数量, 提高规则的新颖性和精确度。郭秋萍等[21]通过构建多重共现超网络模型, 揭示科技文献网络节点的同质或异质关联关系, 为揭示科技文献间的隐性关联提供新的研究方法和范式。
新兴主题识别的现有研究虽然对机器学习方法应用较少, 但已有较好的研究成效, 知识关联发现在自身领域也有较好发展。现有对新兴主题的研究主要针对特定领域单一新兴主题的直接发现和识别, 忽略了在高度关联的知识网络中潜在的大量可能富有价值的知识关联。基于新兴主题、知识关联的概念及可能存在的研究空白, 本文提出新兴主题关联机会这一概念。新兴主题关联机会指不同学科或领域中, 处于成长阶段的不同主题之间可能存在的有用的知识关联机会。发现新兴主题关联机会有利于发现学科领域主题间潜在的富有价值的合作机会, 有利于科研人员探索发现新的知识关联领域并实现新的知识创造。
本文采用机器学习中LDA主题模型与链路预测相结合的方法, 以“深度学习”领域的文献为研究对象, 探索深度学习领域关联知识网络中未来的新兴主题关联机会, 验证LDA主题模型与链路预测相结合的方法探索关联知识网络中未来新兴主题关联机会的有效性, 为深度学习领域专家未来研究的合作方向提供决策参考。
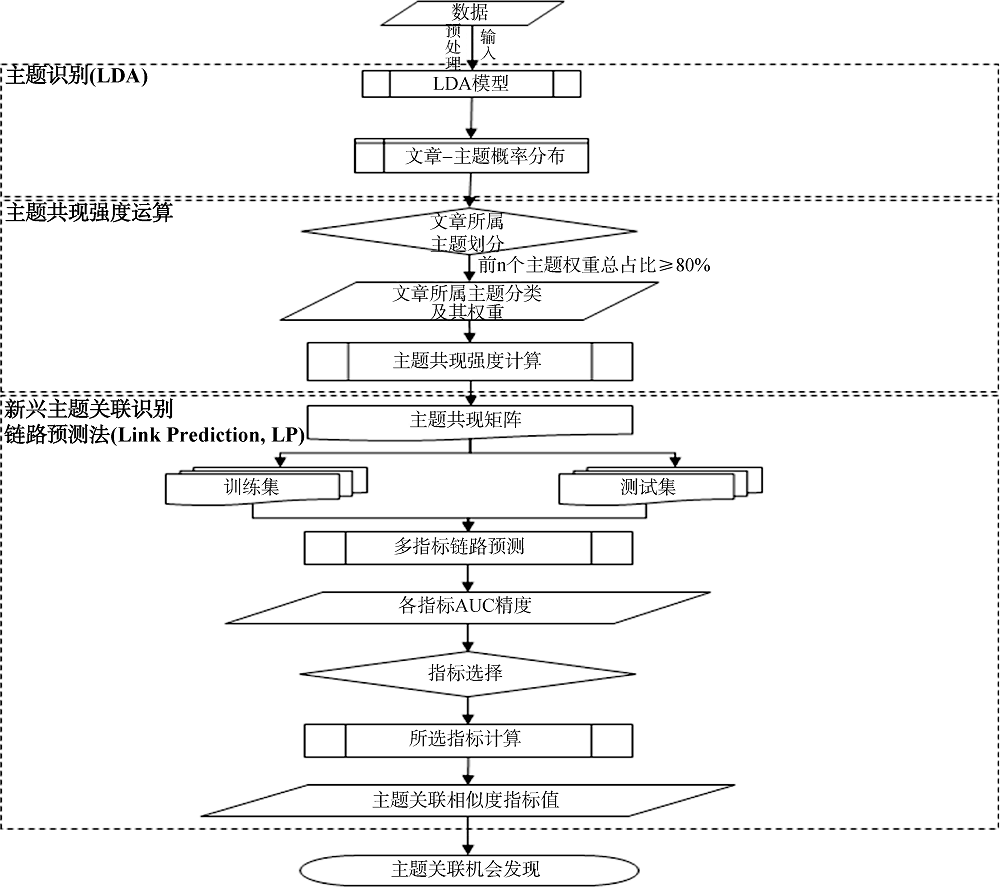
通过LDA主题模型法, 以深度学习领域近10年发表的所有文献摘要部分为分析对象, 挖掘文献内部主题特征, 并对该领域研究主题进行细分。计算各主题间的共现强度, 以挖掘出的主题为节点、主题共现强度为边权, 构建深度学习领域主题共现网络。考虑不同领域知识网络结构特征的差异性, 构建训练集与测试集计算链路预测(Link Prediction, LP)中各相似度指标的准确度, 选取准确度最大的指标作为该网络最优指标, 计算未知主题节点之间的相似度。最后结合定量分析结果对各节点在未来产生关联的可能性进行诠释, 识别未来新兴主题的关联机会。具体技术路线如图1所示。
通过检索Web of Science英文文献数据库建立深度学习领域的文献集合, 具体文献集合获取方法及其基本情况见3.1节。因本研究需要对文献摘要信息进行领域文献主题特征挖掘, 故剔除不包含摘要信息的文献记录。对剔除后的文献集合进行文本预处理, 对各文献摘要部分进行去停用词和分词处理, 得到各文献的分词文本。分词处理过程中, 需注意分词文本中单词的聚合, 消除单词不同语态(主动语态、被动语态等)、时态(一般过去时、现在进行时等)及属性(名词、动词、形容词、副词等)对后期研究的影响。
文献主题是对一篇文献内容的精炼表述, 反映文献内在特征。LDA主题模型作为挖掘文献内在主题的一种建模方法, 近年来在主题挖掘领域表现优异, 通过对主题的挖掘, 实现了自动文摘、微博用户推荐、作者合作倾向研究等方面的应用[22,23,24,25]。
LDA(Latent Dirichlet Allocation)主题模型是一种三层贝叶斯文档主题生成模型, 基本思想是假设语料库中有若干个独立的隐含主题, 根据这些主题的概率分布生成语料库各文档中的全部词语, 从而将文档理解成特定隐含主题的分布, 克服了基于传统向量空间模型(Vector Space Model, VSM)建模时文本位数过高且极度稀疏、忽略文本语义信息等缺陷, 其基本流程如图2[26]所示。
其中,
表1中, 每行代表一篇文献的主题概率分布, 每行所有
表2中, 每行代表一个主题的词概率分布, 每行所有
根据“文献-主题”概率分布计算主题间共现强度, 并以主题为节点、主题共现强度为边权构建领域主题共现网络。
主题共现强度可以反映不同主题之间的关联程度。主题共现强度越大, 说明主题间关联越紧密; 反之则说明主题间关联薄弱, 有待发展或加强。共现强度通常指主题间的共现次数, 共现次数越多, 主题间共现强度越大。根据以往的LDA主题模型实验结果, 一篇文献中各主题概率差异较大, 计算主题共现强度时不宜直接使用共现次数。且各文献“文献-主题”概率分布中仅有少数主题占较大比重, 多数主题概率趋于零。因此本文根据帕累托法则, 选取前
$P\text{(}{{T}_{i}}{{T}_{j}}\text{)}=P\text{(}{{T}_{i}}\text{)}\times P\text{(}{{T}_{j}}\text{)}$ (1)
进一步扩展到全文数据中, 任意关联的两个主题间共现强度计算如公式(2)所示。
$\begin{align} & {{I}_{ij}}=\underset{a=1}{\overset{n}{\mathop \sum }}\,P({{T}_{ai}}{{T}_{aj}})=\underset{a=1}{\overset{n}{\mathop \sum }}\,P({{T}_{ai}})\times P({{T}_{aj}}) \\ & i,j\in a文献抽取的前t个主题集合 \\ \end{align}$ (2)
其中,
得到各主题间共现强度后, 以主题为节点, 主题共现强度为边权, 构建领域无向加权网络
UCINET[27]是一种功能强大的社会网络分析软件, 具有很强的矩阵分析功能; NetDraw是UCINET中可进行一维与二维数据分析的集成软件。
链路预测(Link Prediction, LP)是一种通过已知网络节点及网络结构等信息预测网络中尚未产生连边的两个节点间产生链接可能性的方法。链路预测法对复杂网络预测的准确性较高, 在科研合作伙伴推荐、网络演化趋势等研究中[28,29,30,31,32]均有较好成效。需要注意的是, 链路预测法包含多种不同指标, 不同指标对不同网络的适应性存在差异。因此, 在应用链路预测法预测复杂网络时, 需依据不同网络自身结构信息等特征选择链路预测指标, 使网络预测效果达到最佳。
为获得更好的新兴主题关联预测效果, 本文采用多种不同的相似性指标分析深度学习领域主题共现网络, 将现有数据划分为训练集与测试集, 计算训练集中尚未产生连接的主题节点在未来产生链接可能性的预测精度, 比较20项不同指标(其中主要包括基于共同邻居、路径、随机游走的三大类相似性。第一大类, 基于局部信息的相似性指标有: 共同邻居指标(Common Neighbors, CN)、余弦相似性指标(Salton)、Jaccard指标、Sorenson指标、大度节点有利指标(Hub Promoted Index, HPI)、大度节点不利指标(Hub Depressed Index, HDI)、LHN指标、优先链接指标(Preferential Attachment, PA)、Adamic-Adar指标(AA)、Resource-Allocation指标(RA)、TSCN指标、LNBCN指标、LNBAA指标、LNBRA指标; 第二大类, 基于路径的相似性指标有: 局部路径指标(Local Path, LP)、Katz指标; 第三大类, 基于随机游走的相似性指标有: 平均通勤时间指标(Average Commute Time, ACT)、基于随机游走的余弦相似性指标(Cos+)、SimRank指标(SimR), 以及其他一些相似性指标MFI。各指标定义如表3所示。比较20项不同指标的预测精度, 选择适合该领域知识网络的最优指标。以现有领域所有数据为数据集, 预测并计算其在未来时间节点产生的新兴主题关联机会及其可能性。具体实验步骤如下。
①将领域知识网络中的已知连边
②对训练集
③进行
④比较
⑤根据
⑥比较各个指标的AUC平均值及方差, 选择适应领域知识网络的最优指标;
⑦应用最优指标对该领域完整数据集进行链路预测。
步骤③中使用的评价标准AUC(Area Under the ROC Curve)是最常用的精度衡量指标之一, 从整体上衡量链路预测算法中各指标的精确度[46]。其计算方式如下。
①分别从测试集、不存在边的集合中各随机选取一条边;
②比较两条边的相似度值, 判断从测试集中选取的边的相似度值(
③如果
④重复步骤①-步骤③的独立比较过程
$AUC=\frac{{n}'+0.5{n}''}{n}$ (3)
其中,
单独应用AUC指标对链路预测指标进行评价时, AUC均值准确性较好, 方差量级极小, 因此通常仅依赖AUC指标值进行方法选择, 而忽略指标方差。本文综合考虑指标AUC值及其方差, 根据各项指标均值
$\delta =\frac{\sqrt{\sigma }}{\mu }$ (4)
深度学习(Deep Learning, DL)由Hinton等于2006年提出[50], 是一种通过组合低层特征以发现数据高层属性类别和特征的方法。本文选取深度学习领域文献为研究对象, 展示以LDA主题模型与链路预测相结合的方法预测领域未来新兴主题关联机会的过程与研究结果。研究结果有助于推演深度学习领域未来发展趋势, 为科技决策者制定科技战略和研究人员掌握未来发展趋势提供支撑。
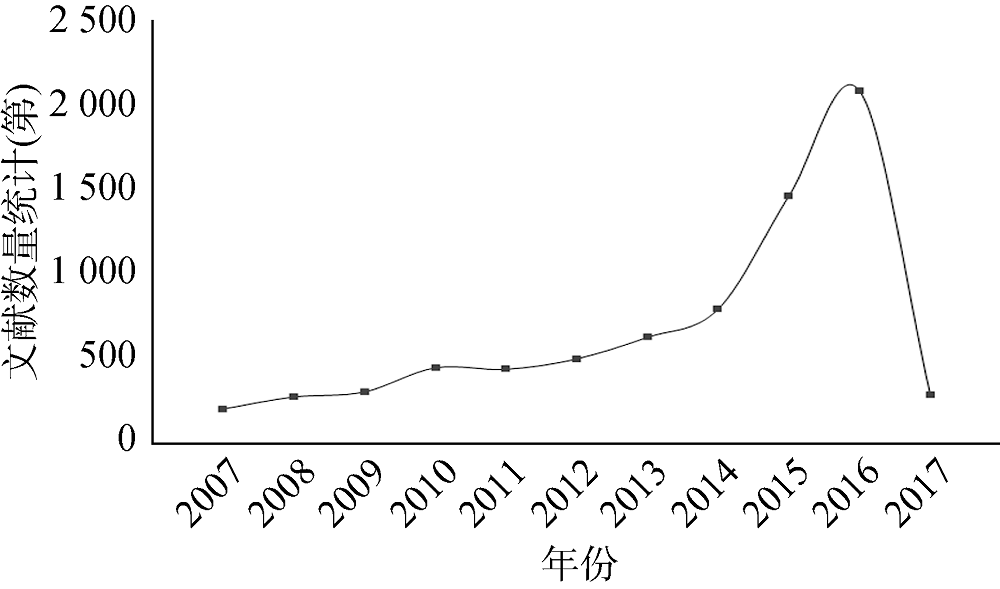
研究数据来自Web of Science核心数据库, 利用检索式“TS =(deep* learn*) AND PY=(2007-2017)”检索深度学习领域的研究文献, 获得深度学习领域12 665篇文献, 去除不包含摘要信息的冗杂数据, 共获得深度学习领域SCI文献7 379篇。其中, 美国发表文献数量约占文献总数的27.4%; 中国发表文献数量约占文献总数的24.5%; 其他发表文献较多的国家依次是德国、西班牙、澳大利亚, 发表文献数量均约占文献总数的4%-5%。可以看出, 美国对深度学习领域的研究处于领先地位, 中国在深度学习领域也取得了丰厚的研究成果。2007年-2017年深度学习领域文献的时序分布如图3所示。
自2007年以来, 深度学习领域文献数量近似呈指数型增长趋势(数据采集时间为2017年3月, 因此2017年文献数据不具代表性), 表明该领域正处于蓬勃发展时期, 发现深度学习领域新兴主题关联机会, 有助于科技战略布局和未来发展趋势预测。
在Python中应用NLTK库对原始数据进行文本预处理, 得到所需文献数据集, 用LDA主题模型挖掘深度学习领域文献主题。依照前人研究经验[43], 设定先验参数
经实验得到深度学习领域“文献-主题”概率分布表和深度学习领域“主题-词”概率分布表。
(1)深度学习领域“文献-主题”概率分布表: 描述各主题在文献中所占比率。本文主题聚类个数K=49, 得到一个7379×49的“文献-主题”分布矩阵, 该矩阵为7 379篇文献分别在49个主题上的概率分布。部分“文献-主题”分布矩阵如表4所示。
(2) 深度学习领域“词-主题”分布矩阵: 描述各个词在主题中所占比率, 选取各主题词概率最大的前10个词, 结合文献标题、摘要、关键词等总结49个主题名称, 部分主题信息汇总结果如表5所示。
根据表5的主题信息汇总结果, LDA模型能够较为准确地抽取深度学习领域的相关主题研究, 其中包含深度学习算法自身的研究、深度学习在特征识别领域的应用研究及深度学习在医疗、生物、社会、教育教学等多方面的跨学科应用与辅助研究。
深度学习算法已经在众多领域崭露头角, 以其更快捷自动化的运转方式促进了社会生产与社会建设, 人工智能在生活生产中的初步成功应用也印证了深度学习的价值。深度学习算法的研究应用虽然已具备一定广度, 但仍有很多的领域应用还较为匮乏。因此对深度学习领域新兴主题关联机会进行发现极具实际应用意义, 有助于促进深度学习在各个研究领域的进一步发展与应用。
根据“文献-主题”概率分布, 随机抽取数据集中部分文献, 应用Gephi软件绘制“文献-主题”概率累积图, 如图5所示。
依据帕累托法则, 取趋势线上主题累积概率值为0.8的点, 对应累积主题数为3.06 607, 取整数约为3。因此每篇文献选取各自主题概率占比最大的前三个主题, 这三个主题能较好地反映文献内在主题特征, 且三个主题间存在较强关联关系。共获得680对主题共现, 部分主题共现强度计算结果如表6所示。
深度学习领域全部主题共现强度的最大值为46.877 14, 最小值为0.000 079, 平均共现强度为 1.377 02。其中145对主题共现大于平均贡献强度, 535对主题共现小于平均共现强度。从主题共现强度数据统计中可以看出, 只有约五分之一的主题共现强度较大(大于平均值)。多数主题间的共现强度仍然小于平均合作强度1.377 02, 处于较低的水平, 凸显了深度学习领域主题关联机会识别发现的必要性。
以LDA主题模型识别出的49个主题为深度学习领域主题共现网络中的节点, 主题名称为网络中共现主题标签, 主题共现强度为网络中节点间权重, 应用UCINET及NetDraw构建并绘制深度学习领域主题共现网络, 如图6所示。
应用CN、Salton等20种指标计算深度学习领域包含主题之间的相似度, 通过100次独立伯努利试验及10 000次独立比较, 得到链路预测各指标AUC精度均值
其中, CN、Salton、Jaccard等14项链路预测指标均有很好的预测效果, AUC指数在97%以上, 平均精度高达98.792%, 方差量级极小, 均在1.00×10-6左右; LNBCN、LNBAA等6项指标的AUC精度欠佳, 甚至部分AUC值仅有1%左右。
各指标变异系数如表8所示。对比各指标变异系数, 发现AA指标预测效果最佳, 因此本文选择AA指标对深度学习领域知识网络中未产生连边的节点在未来产生连边的可能性进行链路预测。
AA指标是一种基于共同邻居度的指标。与最为常见的CN指标不同, AA指标考虑两节点共同邻居的度的信息, 其基本思想是共同邻居节点的度越小, 其贡献越大。假如
加权AA[38]指标定义为如公式(5)所示。
${{s}_{ij}}=\underset{z\in \Gamma \left( i \right)\bigcap \Gamma \left( j \right)}{\mathop \sum }\,\frac{{{w}_{iz}}+{{w}_{zj}}}{2\log (1+{{s}_{z}})}$ (5)
其中,
在无向不含权网络
${{s}_{z}}=\sum\nolimits_{i=1}^{n}{{{w}_{iz}}}$ (6)
深度学习领域潜在新兴主题关联组合、AA指标值以及其归一化后相对相似性指标值如表9所示。新兴主题关联组合相似性越大, 这两个主题间在未来产生关联的可能性越大。
从表9中的实验结果可以看出, 深度学习领域在未来几年中最有可能产生的新兴主题关联研究机会主要包含深度学习模型算法自身的机理与改进研究和深度学习的数据分析及其在生物医学领域的应用研究两方面。
(1) 深度学习模型算法自身的机理与改进研究。
与其他浅层模型相比, 深度学习模型在数据处理与分析上已有更好的成效, 但作为仍处于高速发展状态的新技术, 仍有许多不足有待研究与改进。因此关于深度学习模型算法自身的机理与改进研究是未来深度学习领域所需关注的重点之一。依据实验结果, 笔者认为这方面的研究将与限制玻尔兹曼机及GPU加速器息息相关。
(2) 深度学习的数据分析相关研究及其在生物医学领域的应用研究。
近年来, 生物医学进入大数据时代, 癌症基因组图谱(The Cancer Genome Atlas, TCGA)计划等多项国家乃至国际重大项目不断充实着越来越多的数据。与一般领域数据相比, 生物医学数据具有维数更高、结构更复杂的特点, 对数据分析模型提出严峻挑战。应时代需求产生的深度学习模型蕴含更多隐层及更多非线性变换, 正适应生物医学领域中数据分析的应用需求, 因此深度学习与生物医学领域的合作交叉势在必行。从数据分析结果可以看出, 现有的深度学习研究成果已经在生物医学领域有较为广泛的应用, 其中包括神经科学、生物化学分子生物学、工程生物医学、放射核医学影像学、遗传学、药理药剂学等众多生物医学领域相关主题, 且上述相关主题领域的研究文献数量增长迅猛。从表9中7项新兴主题关联组合及其AA指标值、相对相似性的结果可以看出, “生物神经学与药理学研究”一词在7对新兴主题关联组合中出现频率高达三次, 且出现该词的新兴主题关联组合均位于AA指标值与相对相似性值最大的前三个新兴主题关联组合中, 与其相匹配的新兴主题关联分别涉及深度学习领域中“基于机器/深度学习数据分析”、“GPU加速器相关研究”、“机器学习与人工智能”三个方面。因此预测“生物神经学与药理学研究”将在未来与上述深度学习领域的三个方面产生新兴主题关联机会, 成为深度学习领域与生物医学领域研究相结合的热点。另外, 根据表9, “动物神经行为研究”与“机器学习与人工智能”、“医疗手术相关研究”与“基于文本的语义学习”这两对新兴主题关联组合未来也可能在深度学习领域与生物医学领域的交叉融合研究中出现。
深度学习领域在生物医学领域的理论与应用研究已快速崛起, 但仍处于起步阶段, 未来一段时期仍将是深度学习模型的研究热点, 推动深度学习领域的研究对推动生物医学领域研究也有重大意义。
中国科学院计算机网络信息中心赵地在2017年全国深度学习技术应用大会上发表的“深度学习与医疗影像大数据分析”讲演[51], 以及自本文数据采集时间节点至今发表的深度学习在生物医学领域相关研究应用的文献与新闻报道, 均与本文得到的新兴主题关联有较好的一致性, 印证了应用主题模型与链路预测相结合的方法预测新兴主题关联机会是合理有效的, 可以为新兴主题关联机会发现提供参考。
本文以深度学习领域文献为研究对象, 以Web of Science为数据源, 采集2007年-2017年以深度学习为研究主题的核心文献, 采用主题模型与链路预测相结合的方法预测新兴主题关联。考虑深度学习领域主题间共现强度, 构建深度学习领域无向加权网络, 利用AUC指标及变异系数检验链路预测算法各指标准确性, 最终选取AA指标对深度学习领域在未来可能产生关联的新兴主题进行预测。得到结论如下:
(1) 深度学习领域主题共现网络的最优指标为AA指标;
(2) 未来深度学习领域的大数据分析研究将最有可能与生物医疗领域主题研究及深度学习算法自身机理改进主题研究产生关联;
(3) 利用主题模型与链路预测相结合的方法进行未来新兴主题关联机会发现具有一定的有效性、可靠性及应用价值。
相较于最大似然估计、马尔科夫链等方法, 基于相似性的链路预测法在保证预测精度的前提下, 有远优于传统方法的计算速度, 尤其在大型复杂网络分析中具有高效性。本文通过LDA主题模型与链路预测相结合的方法获得的预测结果与实际产生的新兴主题关联科研成果较一致, 佐证了基于LDA主题模型与链路预测相结合的方法对新兴主题关联机会进行发现的有效性。
应用LDA主题模型与链路预测相结合的方法预测新兴主题关联机会的局限性在于链路预测需要目标网络的结构特征显著才能得到较好的预测效果, 对于联通效果较差的网络预测效果欠佳。因此在应用此方法进行新兴主题关联预测时, 需先依据现有数据进行训练测试, 选择适合研究领域网络特征的指标, 以获得较好的预测效果。对链路预测算法性能与网络结构特征之间的研究是未来需要解决的重点问题之一。
刘俊婉: 提出研究思路, 论文起草、修订;
龙志昕: 设计研究方案, 进行数据采集及实验分析, 论文最终版本修订;
王菲菲: 论文修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: long941026@163.com。
[1] 龙志昕. Dpdata.xlsx. Web of Science2007-2017年深度学习领域相关文献.
[2] 龙志昕. LDAresult.xlsx. LDA主题模型分派结果.
[3] 龙志昕. LPresult.xlsx. 链路预测训练结果.
[4] 龙志昕. AA.xlsx. AA指标计算结果.
| [1] |
文章对关联文献知识发现的发展历程、技术变迁及发展方向进行了深 入分析,按知识发现过程所采用技术的不同特点将其分为两个阶段,并根据充满争议的研究话题提出了下一代关联文献知识发现的发展方向.研究表明:第一代的关 联文献知识发现分析以标题和摘要字段为主,采用词频过滤技术,结果评估以Swanson 1986年的案例为标准;第二代技术的文本分析范围从标题和摘要字段扩展到了叙词表和医学主题词表,分析单元从单词短语扩展到概念、语义,同时筛选采用语 义过滤方法,评价采取四步法.下一代技术的发展方向有:关联文献知识发现结果的评价或审查标准研究;关联文献知识发现的成果仅仅是知识增量还是彻底的知识 发现或创新的讨论;对自动化地从大量知识发现候选者中筛选出少量真正知识发现的技术研究.
URL
[本文引用:1]
|
| [2] |
发现和追踪领域新兴主题是研究人员发现和追踪本领域内最新研究趋势和研究方向的一个重要途径。新兴主题探测可以探测、识别、发现这些新兴趋势和新兴主题。本文对ISIWebofScience数据库中收录的关于新兴主题研究的文献进行收集,然后从文献计量学的角度进行定量分析;利用CiteSpaceU对国家、机构、作者的合作关系做出对应的知识图谱;并对共被引文献的关键节点文献进行了研读和分析;最后利用CiteSpaceⅡ生成的本研究领域中的研究主题聚类图、时序图对研究内容及现状进行了分析和预测。
|
| [3] |
Emerging topic detection is a vital research area for researchers and scholars interested in searching for and tracking new research trends and topics. The current methods of text mining and data mining used for this purpose focus only on the frequency of which subjects are mentioned, and ignore the novelty of the subject which is also critical, but beyond the scope of a frequency study. This work tackles this inadequacy to propose a new set of indices for emerging topic detection. They are the novelty index (NI) and the published volume index (PVI). This new set of indices is created based on time, volume, frequency and represents a resolution to provide a more precise set of prediction indices. They are then utilized to determine the detection point (DP) of new emerging topics. Following the detection point, the intersection decides the worth of a new topic. The algorithms presented in this paper can be used to decide the novelty and life span of an emerging topic in a specific field. The entire comprehensive collection of the ACM Digital Library is examined in the experiments. The application of the NI and PVI gives a promising indication of emerging topics in conferences and journals.
|
| [4] |
We explore the possibility of using co-citation clusters over three time periods to track the emergence and growth of research areas, and predict their near term change. Data sets are from three overlapping six-year periods: 1996-2001, 1997-2002 and 1998-2003. The methodologies of co-citation clustering, mapping, and string formation are reviewed, and a measure of cluster currency is defined as the average age of highly cited papers relative to the year span of the data set. An association is found between the currency variable in a prior period and the percentage change in cluster size and citation frequency in the following period. The conflating factor of “single-issue clusters” is discussed and dealt with using a new metric called in-group citation.
|
| [5] |
Research fronts, defined as clusters of documents that tend to cite a fixed, time invariant set of base documents, are plotted as time lines for visualization and exploration. Using a set of documents related to the subject of anthrax research, this article illustrates the construction, exploration, and interpretation of time lines for the purpose of identifying and visualizing temporal changes in research activity through journal articles. Such information is useful for presentation to members of expert panels used for technology forecasting.
|
| [6] |
本文应用共词分析的方法对生物信息学的主题词进行聚类,得到其研究的热点内容,然后利用战略坐标进一步定量地分析了各热点的发展阶段.
|
| [7] |
|
| [8] |
URL
[本文引用:1]
|
| [9] |
通过分析国外相关机构开发的新兴研究趋势探测系统,总结在新兴研究趋势探测上已有系统所采用的技术方法,分析其实现特点和设计思路,为后续新兴研究趋势探测系统的设计和实现提供重要的有参考价值的依据。
|
| [10] |
[本文引用:1]
|
| [11] |
|
| [12] |
|
| [13] |
对新兴主题的识别有助于科研人员把握相关领域的研究方向。针对目前新兴主题识别以关键词词频判断为主的局限性,构建文献多属性测度模型,利用高关注度、高成长潜力度以及高关联度指标对关键词进行有效识别并筛选,最终确定新兴主题。并以精密单点定位技术为例,说明此方法的实施步骤以及可行性。研究结果表明,根据多属性测度得到的精密单点定位的新兴主题更加明确,指示性强,与该领域现实研究状况(实时精密定点定位、定位误差修正以及模糊度固定等方面)具有较高的吻合度。
URL
[本文引用:1]
|
| [14] |
Abstract Information science emerged as the third subject, along with logic and philosophy, to deal with relevance-an elusive, human notion. The concern with relevance, as a key notion in information science, is traced to the problems of scientific communication. Relevance is considered as a measure of the effectiveness of a contact between a source and a destination in a communication process. The different views of relevance that emerged are interpreted and related within a framework of communication of knowledge. Different views arose because relevance was considered at a number of different points in the process of knowledge communication. It is suggested that there exists an interlocking, interplaying cycle of various systems of relevances.
|
| [15] |
文章将关联规则挖掘引入共词分析领域。通过试验发现,设置合理的最小支持度和最小置信度阈值,可以有效揭示目标领域的核心二元词组和多元词组间的关联关系。相比传统的共词分析方法,在精确计量词组内部术语间语义关系的强度和方向上具有明显优势。进而提出基于关联规则的信息检索系统知识推荐思路。
URL
[本文引用:1]
|
| [16] |
[本文引用:1]
|
| [17] |
[本文引用:1]
|
| [18] |
知识关联是指知识单元(包括文献、人脑等知识载体和概念、词语等知识内容)之间存在的各种关系的总和。知识关联具有相互性、普遍性、传递性、隐含性、结构性、累积性等特征,是我们认识和利用知识关联的基础。知识关联有多种类型,其中显性知识关联、隐性知识关联、学科知识关联、主题知识关联、知识载体关联和知识内容关联具有重要的意义。
URL
[本文引用:1]
|
| [19] |
面对现代科研环境e-Science,知识合作和新知识发现成为严峻的挑战.本文提出了基于共引知识元间语义关联的隐含知识发现方法.该方法将文献单元分解成知识元,以资源描述框架模式(RDFS)建立由性质P为中心的知识元本体模型,利用知识元间的共引关系挖掘知识元间隐含关联关系,通过隐含关联实现新知识发现.软件试验表明这一方法鼓舞人心.
|
| [20] |
本文针对传统关联规则挖掘算法产生大量冗余规则,提出了对关联规则结果进行二次挖掘,并设计了算法对挖掘出的关联规则进行聚类,然后基于已有领域知识对聚类后的关联规则进行新颖度评价,对于新颖度较高价值较大的关联规则可以存储于领域知识库用于决策使用或再次挖掘过程。该算法有效的减少的规则的数量,提高了规则的新颖性和精确度,对商业应用具有很高的价值。文章最后使用UCI开源数据进行了实验分析,并验证了该算法的有效性。
|
| [21] |
[目的/意义]科技文献之间各式各样的关联关系形成错综复杂的网络,其结构具有多层性、多重性和嵌套性,可以采用超网络描述和揭示。[方法/过程]构建基于作者—关键词—引文3个子网的多重共现超网络模型,来揭示多层、多重、嵌套的异质共现关系,并以图书馆、情报与文献学学科领域的"知识服务"主题为例进行实证分析。[结果/结论]该模型能够揭示科技文献网络同质节点的同质关联关系和异质节点的异质关联关系,为揭示科技文献间的隐性关联提供新的研究方法和范式。
|
| [22] |
[本文引用:1]
|
| [23] |
近年来概率主题模型受到了研究者的广泛关注,LDA(Latent Dirichlet Allocation)模型是主题模型中具有代表性的概率生成模型之一,它能够检测文本的隐含主题。提出一个基于LDA模型的主题特征,该特征计算文档的主题分布与句子主题分布的距离。结合传统多文档自动文摘中的常用特征,计算句子权重,最终根据句子的分值抽取句子形成摘要。实验结果证明,加入LDA模型的主题特征后,自动文摘的性能得到了显著的提高。
|
| [24] |
潜在狄利克雷分配(LDA)主题模型可用于识别大规模文档集中潜藏的主题信息,但是对于微博短文本的应用效果并不理想。为此,提出一种基于LDA的微博用户模型,将微博基于用户进行划分,合并每个用户发布的微博以代表用户,标准的文档-主题-词的三层LDA模型变为用户-主题-词的用户模型,利用该模型进行用户推荐。在真实微博数据集上的实验结果表明,与传统的向量空间模型方法相比,采用该方法进行用户推荐具有更好的效果,在选择合适的主题数情况下,其准确率提高近10%。
|
| [25] |
Scientific collaboration and endorsement are well-established research topics which utilize three kinds of methods: survey/questionnaire, bibliometrics, and complex network analysis. This paper combines topic modeling and path-finding algorithms to determine whether productive authors tend to collaborate with or cite researchers with the same or different interests, and whether highly cited authors tend to collaborate with or cite each other. Taking information retrieval as a test field, the results show that productive authors tend to directly coauthor with and closely cite colleagues sharing the same research interests; they do not generally collaborate directly with colleagues having different research topics, but instead directly or indirectly cite them; and highly cited authors do not generally coauthor with each other, but closely cite each other.
|
| [26] |
[本文引用:1]
|
| [27] |
[本文引用:1]
|
| [28] |
直接建立演化模型推测影响网络演化的因素是目前研究网络演化机制的常用方法, 但由于可供比较 的结构特征量太多, 不同的模型之间难以进行定量化的比较. 链路预测是指利用网络的结构或者节点的属性 信息预测未产生连接的两个节点间产生连接的可能性. 其本质是挖掘网络产生连边的原因和驱动力, 这同时 也是网络演化模型所关心的问题. 实际上, 一个演化模型原则上都可以对应于一种链路预测的算法. 因此, 借 助链路预测的理论框架和评价方法可以定量化地对不同演化模型所对应的链路预测算法进行评价, 从而间接 地对演化模型的表现进行定量比较. 本文首先介绍基于节点接近性的链路预测方法, 然后讨论利用链路预测 推测网络演化机制的基本框架. 在以中国城市航空网络为例的实证分析中发现, 当单独利用结构(共同邻居数 目)和节点属性(地理位置,人口,GDP 和第三产业产值)作为定义接近性的因素时, 基于共同邻居的算法预测 准确度最高, 暗示网络演化主要受结构因素影响, 其次才是外在因素. 而将四种基于节点属性的算法与基于 结构的算法耦合进行计算时, 共同邻居配合第三产业产值效果最好, 与偏相关分析和因果分析的结论一 致. 本文为研究网络演化模型提供了全新的视角和分析工具.
|
| [29] |
[本文引用:1]
|
| [30] |
78 Link prediction has found applications in network analysis and reconstruction. 78 We give a comprehensive survey on physical and machine learning methods. 78 We emphasize the statistical physical methods like maximum likelihood methods. 78 We outline promising directions for further research and some open problems.
|
| [31] |
The problem of missing link prediction in complex networks has attracted much attention recently. Two difficulties in link prediction are the sparsity and huge size of the target networks. Therefore, the design of an efficient and effective method is of both theoretical interests and practical significance. In this Letter, we proposed a method based on local random walk, which can give competitively good prediction or even better prediction than other random-walk-based methods while has a lower computational complexity.
|
| [32] |
[目的/意义]从科研合作网络"小世界现象"和"无标度特性"出发,对网络中的未知链路产生连接的可能性进行预测。[方法/过程]采用Katz指标和cosine距离计算网络中的路径相似性和研究者科研兴趣相似性;在此基础上,构建加权预测算法,并采用AUC指标和F1度量确定节点相似性在算法中所占的比重。[结果/结论]通过实证研究发现,在路径相似性基础上,引入一定权重的节点相似性,可以达到较好的预测效果。[局限]在节点相似性计算时,仅考虑了研究者科研兴趣因素,暂未考虑研究者地理位置对合作关系的影响。
|
| [33] |
The aim of this paper is to understand the interrelations among relations within concrete social groups. Social structure is sought, not ideal types, although the latter are relevant to interrelations among relations. From a detailed social network, patterns of global relations can be extracted, within which classes of equivalently positioned individuals are delineated. The global patterns are derived algebraically through a ‘functorial’ mapping of the original pattern. Such a mapping (essentially a generalized homomorphism) allows systematically for concatenation of effects through the network. The notion of functorial mapping is of central importance in the ‘theory of categories,’ a branch of modern algebra with numerous applications to algebra, topology, logic. The paper contains analyses of two social networks, exemplifying this approach.
|
| [34] |
[本文引用:1]
|
| [35] |
[本文引用:1]
|
| [36] |
[本文引用:1]
|
| [37] |
of highly integrated modules have a high topological overlap with their neighbors, and we found that the larger the overlap between two substrates within the E. coli metabolic network, the more likely it is that they belong to the same functional class.As the topological overlap matrix is ex- pected to encode the comprehensive en- zyme catalyzed functional relatedness of the substrates forming the metabolic net- work, we investigated whether potential functional modules encoded in the network topology can be uncovered automatically. Initial application of an average-linkage hi- erarchical clustering algorithm (22) to the overlap matrix of the small hypothetical network shown in Fig. 3A placed those nodes that have a high topological overlap close to each other (Fig. 3B). Also, the method identified the three distinct mod- ules built into the model of Fig. 3A, as illustrated by the fact that the EFG and HIJK modules are closer to each other in a topological sense, with the ABC module being farther from both (Fig. 3B). Applica- tion of the same technique on the E. coli overlap matrix OT(i, j) provides a global topologic representation of E. coli metabo- lism (Fig. 4A). Groups of metabolites form- ing tightly interconnected clusters are visual- ly apparent, and on closer inspection, the hierarchy of nested topologic modules of in- creasing sizes and decreasing interconnected- ness is also evident. To visualize the relation between topological modules and the known functional properties of the metabolites, we color-coded the branches of the derived hier- archical tree according to the predominant biochemical class of the substrates it produc- es, using the classification of metabolism based on standard, small molecule biochem- istry (15). As shown in Fig. 4A, and in the three-dimensional representation in Fig. 4B, most substrates of a given small molecule class are distributed on the same branch of the tree (Fig. 4A) and correspond to relatively well delimited regions of the metabolic net- work (Fig. 4B). Therefore, there are strong correlations between shared biochemical classification of metabolites and the global topological organization of E. coli metabo- lism (Fig. 4A, bottom) (16).To correlate the putative modules ob- tained from our graph theory- based analy- sis to actual biochemical pathways, we con- centrated on the pathways involving the pyrimidine metabolites. Our method divid- ed these pathways into four putative mod- ules (Fig. 4C), which represent a topologi- cally well-limited area of E. coli metabo- lism (Fig. 4B, blue-shaded region). As shown in Fig. 4D, all highly connected metabolites (Fig. 4D, red-outlined boxes) correspond to their respective biochemical reactions within pyrimidine metabolism,
|
| [38] |
Missing link prediction in networks is of both theoretical interest and practical significance in modern science. In this paper, we empirically investigate a simple framework of link prediction on the basis of node similarity. We compare nine well-known local similarity measures on six real networks. The results indicate that the simplest measure, namely Common Neighbours, has the best overall performance, and the Adamic-Adar index performs second best. A new similarity measure, motivated by the resource allocation process taking place on networks, is proposed and shown to have higher prediction accuracy than common neighbours. It is found that many links are assigned the same scores if only the information of the nearest neighbours is used. We therefore design another new measure exploiting information on the next nearest neighbours, which can remarkably enhance the prediction accuracy.
|
| [39] |
[本文引用:1]
|
| [40] |
Abstract: Systems as diverse as genetic networks or the world wide web are best described as networks with complex topology. A common property of many large networks is that the vertex connectivities follow a scale-free power-law distribution. This feature is found to be a consequence of the two generic mechanisms that networks expand continuously by the addition of new vertices, and new vertices attach preferentially to already well connected sites. A model based on these two ingredients reproduces the observed stationary scale-free distributions, indicating that the development of large networks is governed by robust self-organizing phenomena that go beyond the particulars of the individual systems.
|
| [41] |
The Internet has become a rich and large repository of information about us as individuals. Anything from the links and text on a user’s homepage to the mailing lists the user subscribes to are reflections of social interactions a user has in the real world. In this paper we devise techniques and tools to mine this information in order to extract social networks and the exogenous factors underlying the networks’ structure. In an analysis of two data sets, from Stanford University and the Massachusetts Institute of Technology (MIT), we show that some factors are better indicators of social connections than others, and that these indicators vary between user populations. Our techniques provide potential applications in automatically inferring real world connections and discovering, labeling, and characterizing communities.
|
| [42] |
In this Brief Report, we propose an index of user similarity, namely, the transferring similarity, which involves all high-order similarities between users. Accordingly, we design a modified collaborative filtering algorithm, which provides remarkably higher accurate predictions than the standard collaborative filtering. More interestingly, we find that the algorithmic performance will approach its optimal value when the parameter, contained in the definition of transferring similarity, gets close to its critical value, before which the series expansion of transferring similarity is convergent and after which it is divergent. Our study is complementary to the one reported in [E. A. Leicht, P. Holme, and M. E. J. Newman, Phys. Rev. E 73, 026120 (2006)], and is relevant to the missing link prediction problem.
|
| [43] |
[本文引用:4]
|
| [44] |
Predictions of missing links of incomplete networks, such as protein-protein interaction networks or very likely but not yet existent links in evolutionary networks like friendship networks in web society, can be considered as a guideline for further experiments or valuable information for web users. In this paper, we present a local path index to estimate the likelihood of the existence of a link between two nodes. We propose a network model with controllable density and noise strength in generating links, as well as collect data of six real networks. Extensive numerical simulations on both modeled networks and real networks demonstrated the high effectiveness and efficiency of the local path index compared with two well-known and widely used indices: the common neighbors and the Katz index. Indeed, the local path index provides competitively accurate predictions as the Katz index while requires much less CPU time and memory space than the Katz index, which is therefore a strong candidate for potential practical applications in data mining of huge-size networks.
|
| [45] |
No abstract is available for this item.
|
| [46] |
|
| [47] |
This work presents a new perspective on characterizing the similarity between elements of a database or, more generally, nodes of a weighted and undirected graph. It is based on a Markov-chain model of random walk through the database. More precisely, we compute quantities (the average commute time, the pseudoinverse of the Laplacian matrix of the graph, etc.) that provide similarities between any pair of nodes, having the nice property of increasing when the number of paths connecting those elements increases and when the "length" of paths decreases. It turns out that the square root of the average commute time is a Euclidean distance and that the pseudoinverse of the Laplacian matrix is a kernel matrix (its elements are inner products closely related to commute times). A principal component analysis (PCA) of the graph is introduced for computing the subspace projection of the node vectors in a manner that preserves as much variance as possible in terms of the Euclidean commute-time distance. This graph PCA provides a nice interpretation to the "Fiedler vector," widely used for graph partitioning. The model is evaluated on a collaborative-recommendation task where suggestions are made about which movies people should watch based upon what they watched in the past. Experimental results on the MovieLens database show that the Laplacian-based similarities perform well in comparison with other methods. The model, which nicely fits into the so-called "statistical relational learning" framework, could also be used to compute document or word similarities, and, more generally, it could be applied to machine-learning and pattern-recognition tasks involving a relational database
|
| [48] |
[本文引用:1]
|
| [49] |
Abstract: We propose a family of graph structural indices related to the Matrix-forest theorem. The properties of the basic index that expresses the mutual connectivity of two vertices are studied in detail. The derivative indices that measure "dissociation," "solitariness," and "provinciality" of vertices are also considered. A nonstandard metric on the set of vertices is introduced, which is determined by their connectivity. The application of these indices in sociometry is discussed.
|
| [50] |
We show how to use “complementary priors” to eliminate the explaining-away effects thatmake inference difficult in densely connected belief nets that have many hidden layers. Using complementary priors, we derive a fast, greedy algorithm that can learn deep, directed belief networks one layer at a time, provided the top two layers form an undirected associative memory. The fast, greedy algorithm is used to initialize a slower learning procedure that fine-tunes the weights using a contrastive version of thewake-sleep algorithm. After fine-tuning, a networkwith three hidden layers forms a very good generative model of the joint distribution of handwritten digit images and their labels. This generative model gives better digit classification than the best discriminative learning algorithms. The low-dimensional manifolds on which the digits lie are modeled by long ravines in the free-energy landscape of the top-level associative memory, and it is easy to explore these ravines by using the directed connections to displaywhat the associativememory has in mind.
|
| [51] |
URL
[本文引用:1]
|
| [52] |
[本文引用:0]
|
| [53] |
The common-neighbor ased method is simple yet effective to predict missing links, which assume that two nodes are more likely to be connected if they have more common neighbors. In the traditional method, each common neighbor of two nodes contributes equally to the connection likelihood. In this letter, we argue that different common neighbors may play different roles and thus contributes differently, and propose a local na ve Bayes model. Extensive experiments were carried out on nine real networks. Compared with the traditional method, the present method can provide more accurate predictions.
|






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}